

Google Researchers Can Create an AI That Thinks a Lot Like You After Just a Two-Hour Interview
After an average of 6,000 words, Stanford and Google researchers can spin up a generative agent that will act a lot like you do.
 gizmodo.com
gizmodo.com
Google Researchers Can Create an AI That Thinks a Lot Like You After Just a Two-Hour Interview
After an average of 6,000 words, Stanford and Google researchers can spin up a generative agent that will act a lot like you do.
By Matthew Gault Published January 8, 2025 | Comments (17)
Stanford University researchers paid 1,052 people $60 to read the first two lines of The Great Gatsby to an app. That done, an AI that looked like a 2D sprite from an SNES-era Final Fantasy game asked the participants to tell the story of their lives. The scientists took those interviews and crafted them into an AI they say replicates the participants’ behavior with 85% accuracy.
The study, titled Generative Agent Simulations of 1,000 People, is a joint venture between Stanford and scientists working for Google’s DeepMind AI research lab. The pitch is that creating AI agents based on random people could help policymakers and business people better understand the public. Why use focus groups or poll the public when you can talk to them once, spin up an LLM based on that conversation, and then have their thoughts and opinions forever? Or, at least, as close an approximation of those thoughts and feelings as an LLM is able to recreate.
“This work provides a foundation for new tools that can help investigate individual and collective behavior,” the paper’s abstract said.
“How might, for instance, a diverse set of individuals respond to new public health policies and messages, react to product launches, or respond to major shocks?” The paper continued. “When simulated individuals are combined into collectives, these simulations could help pilot interventions, develop complex theories capturing nuanced causal and contextual interactions, and expand our understanding of structures like institutions and networks across domains such as economics, sociology, organizations, and political science.”
All those possibilities based on a two-hour interview fed into an LLM that answered questions mostly like their real-life counterparts.
Much of the process was automated. The researchers contracted Bovitz, a market research firm, to gather participants. The goal was to get a wide sample of the U.S. population, as wide as possible when constrained to 1,000 people. To complete the study, users signed up for an account in a purpose-made interface, made a 2D sprite avatar, and began to talk to an AI interviewer.
The questions and interview style are a modified version of that used by the American Voices Project, a joint Stanford and Princeton University project that’s interviewing people across the country.
Each interview began with the participants reading the first two lines of The Great Gatsby (“In my younger and more vulnerable years my father gave me some advice that I’ve been turning over in my mind ever since. ‘Whenever you feel like criticizing any one,’ he told me, ‘just remember that all the people in this world haven’t had the advantages that you’ve had.’”) as a way to calibrate the audio.
According to the paper, “The interview interface displayed the 2-D sprite avatar representing the interviewer agent at the center, with the participant’s avatar shown at the bottom, walking towards a goal post to indicate progress. When the AI interviewer agent was speaking, it was signaled by a pulsing animation of the center circle with the interviewer avatar.”
The two-hour interviews, on average, produced transcripts that were 6,491 words in length. It asked questions about race, gender, politics, income, social media use, the stress of their jobs, and the makeup of their families. The researchers published the interview script and questions the AI asked.
Those transcripts, less than 10,000 words each, were then fed into another LLM that the researchers used to spin up generative agents meant to replicate the participants. Then researchers put both the participants and AI clones through more questions and economic games to see how they’d compare. “When an agent is queried, the entire interview transcript is injected into the model prompt, instructing the model to imitate the person based on their interview data,” the paper said.
This part of the process was as close to controlled as possible. Researchers used the General Social Survey (GSS) and the Big Five Personality Inventory (BFI) to test how well the LLMs matched their inspiration. It then ran participants and the LLMs through five economic games to see how they’d compare.
Results were mixed. The AI agents answered about 85% of the questions the same way as the real-world participants on the GSS. They hit 80% on the BFI. The numbers plummeted when the agents started playing economic games, however. The researchers offered the real-life participants cash prizes to play games like the Prisoner’s Dilemma and The Dictator’s Game.
In the Prisoner’s Dilemma, participants can choose to work together and both succeed or screw over their partner for a chance to win big. In the Dictator’s Game, the participants have to choose how to allocate resources to other participants. The real-life subjects earned money over the original $60 for playing these.
Faced with these economic games, the AI clones of the humans didn’t replicate their real-world counterparts as well. “On average, the generative agents achieved a normalized correlation of 0.66,” or about 60%.
The entire document is worth reading if you’re interested in how academics are thinking about AI agents and the public. It did not take long for researchers to boil down a human being’s personality into an LLM that behaved similarly. Given time and energy, they can probably bring the two closer together.
This is worrying to me. Not because I don’t want to see the ineffable human spirit reduced to a spreadsheet, but because I know this kind of tech will be used for ill. We’ve already seen stupider LLMs trained on public recordings tricking grandmothers into giving away bank information to an AI relative after a quick phone call. What happens when those machines have a script? What happens when they have access to purpose-built personalities based on social media activity and other publicly available information?
What happens when a corporation or a politician decides the public wants and needs something based not on their spoken will, but on an approximation of it?
 Read more:
Read more: 








 .
.


 Blog: novasky-ai.github.io/posts/s…
Blog: novasky-ai.github.io/posts/s… Model weights: huggingface.co/NovaSky-AI/Sk…
Model weights: huggingface.co/NovaSky-AI/Sk…






 Built at Berkeley’s Sky Computing Lab @BerkeleySky with the amazing NovaSky team:
Built at Berkeley’s Sky Computing Lab @BerkeleySky with the amazing NovaSky team:

 This week's top AI/ML research papers:
This week's top AI/ML research papers:


 Introducing Agent Laboratory: an assistant for automating machine learning research
Introducing Agent Laboratory: an assistant for automating machine learning research







 We've developed synthetic datasets and models that significantly improve conversational AI, making interactions more human-like.
We've developed synthetic datasets and models that significantly improve conversational AI, making interactions more human-like.



 Try it, finetune it, & explore: github.com/NVIDIA/Cosmos.
Try it, finetune it, & explore: github.com/NVIDIA/Cosmos.  Dive into our 75-page tech report for all the details! research.nvidia.com/publicat…
Dive into our 75-page tech report for all the details! research.nvidia.com/publicat…













 Across extensive analyses of mathematical benchmarks, we found these overthinking patterns:
Across extensive analyses of mathematical benchmarks, we found these overthinking patterns:


 go.fb.me/3lbt4m
go.fb.me/3lbt4m




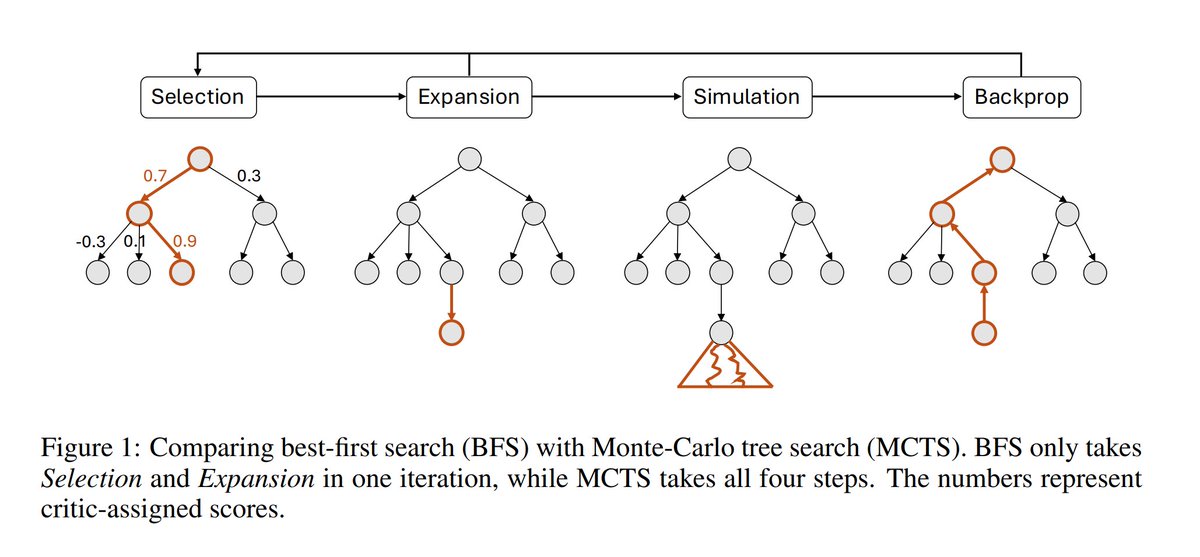


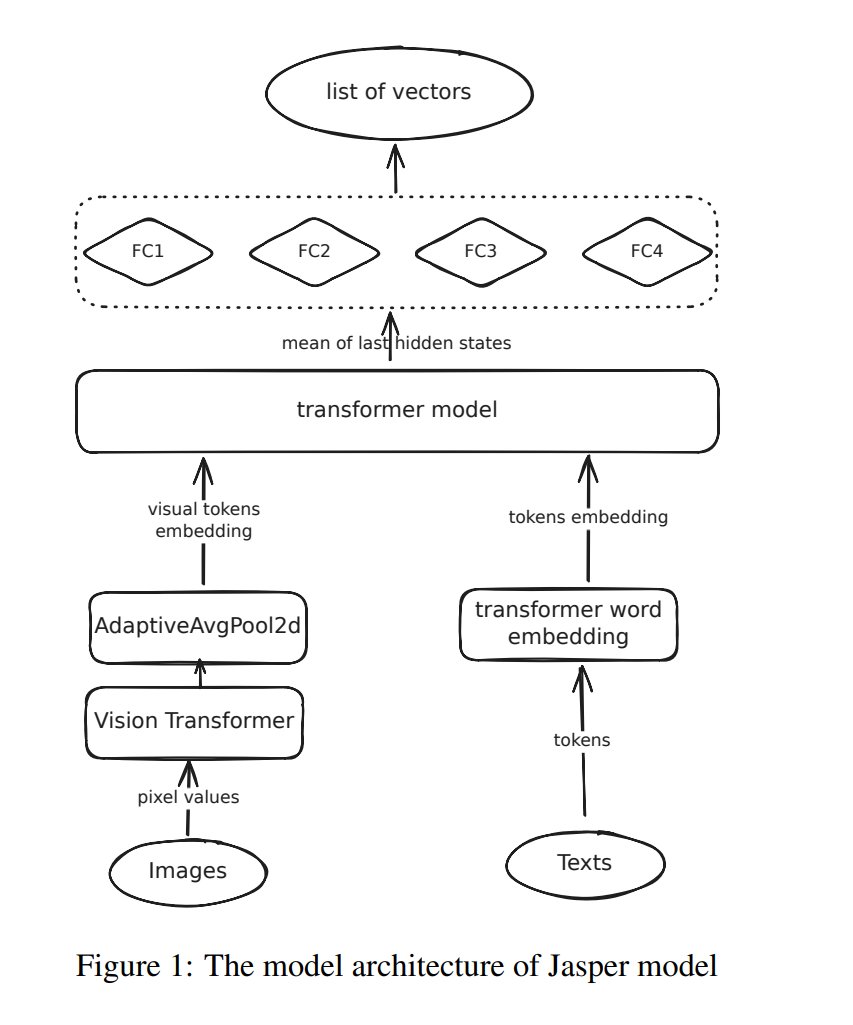


 2/n
2/n



 arxiv.org/abs/2412.10424
arxiv.org/abs/2412.10424




























 Sure, we can hope for algorithmic miracles to slash costs, but let’s not pretend that the AI fairy godmother is just waiting to sprinkle some magic dust.
Sure, we can hope for algorithmic miracles to slash costs, but let’s not pretend that the AI fairy godmother is just waiting to sprinkle some magic dust.
