1/12
@minchoi
Holy sh*t
Meta just revealed Llama 4 models: Behemoth, Maverick & Scout.
Llama 4 Scout can run on single GPU and has 10M context window
https://video.twimg.com/ext_tw_video/1908628230237573120/pu/vid/avc1/720x1280/P74rnIupiit-c6E0.mp4
2/12
@minchoi
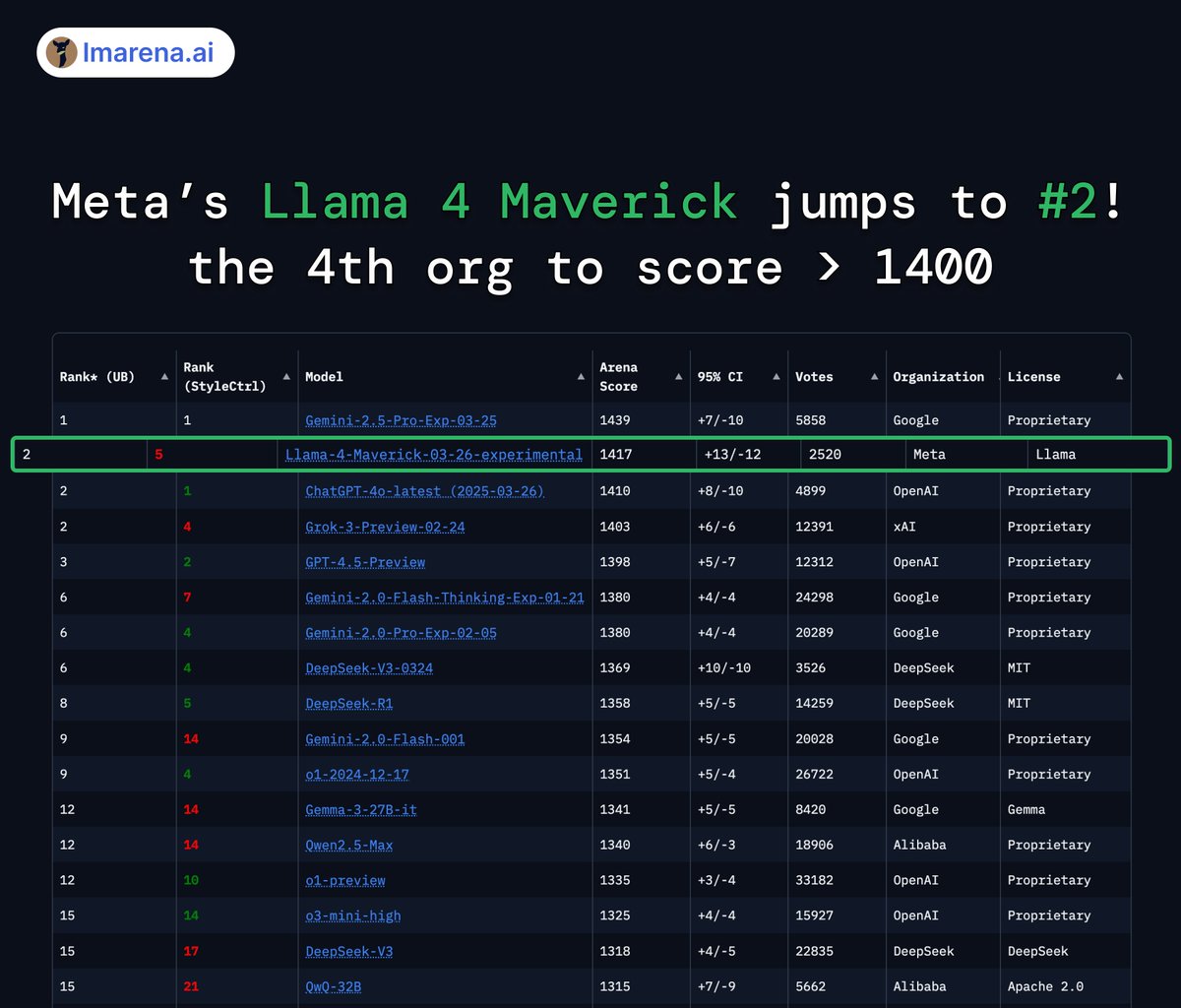
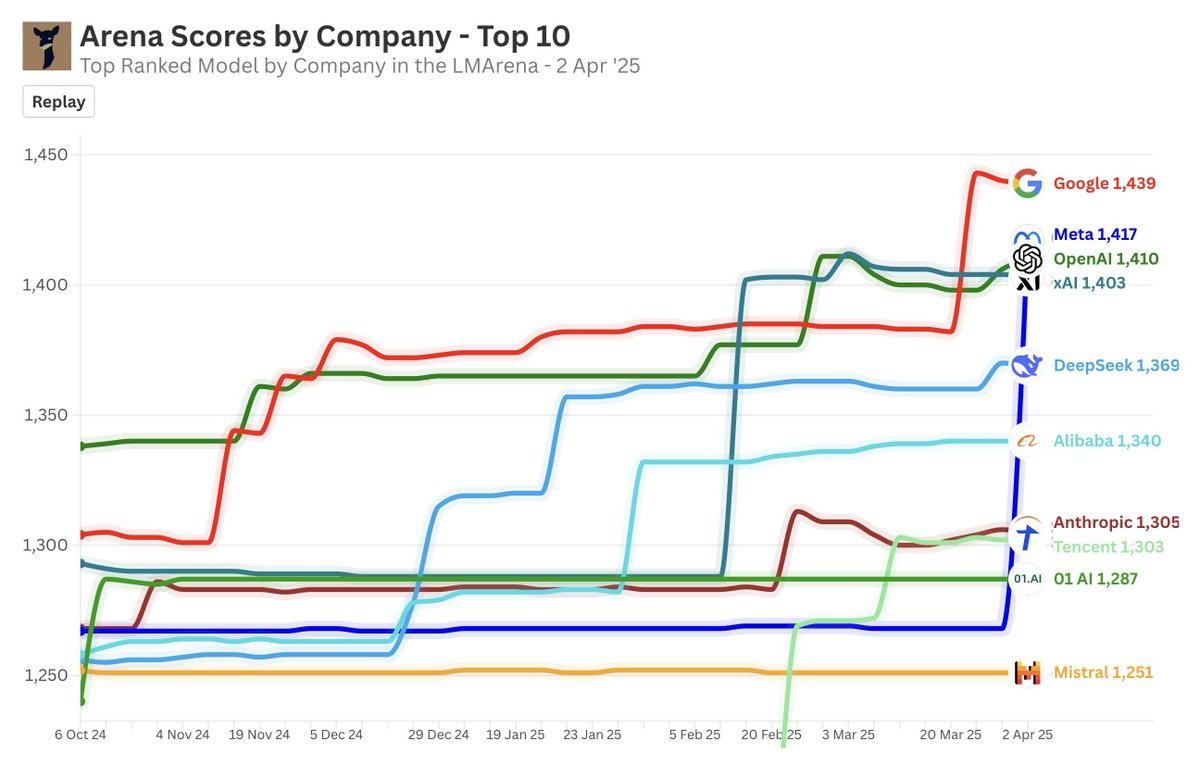
And Llama 4 Maverick just took #2 spot on Arena Leaderboard with 1417 ELO
[Quoted tweet]
BREAKING: Meta's Llama 4 Maverick just hit #2 overall - becoming the 4th org to break 1400+ on Arena!
Highlights:
- #1 open model, surpassing DeepSeek
- Tied #1 in Hard Prompts, Coding, Math, Creative Writing
- Huge leap over Llama 3 405B: 1268 → 1417
- #5 under style control
Huge congrats to @AIatMeta — and another big win for open-source! More analysis below
More analysis below
[media=twitter]1908601011989782976[/media]
3/12
@minchoi
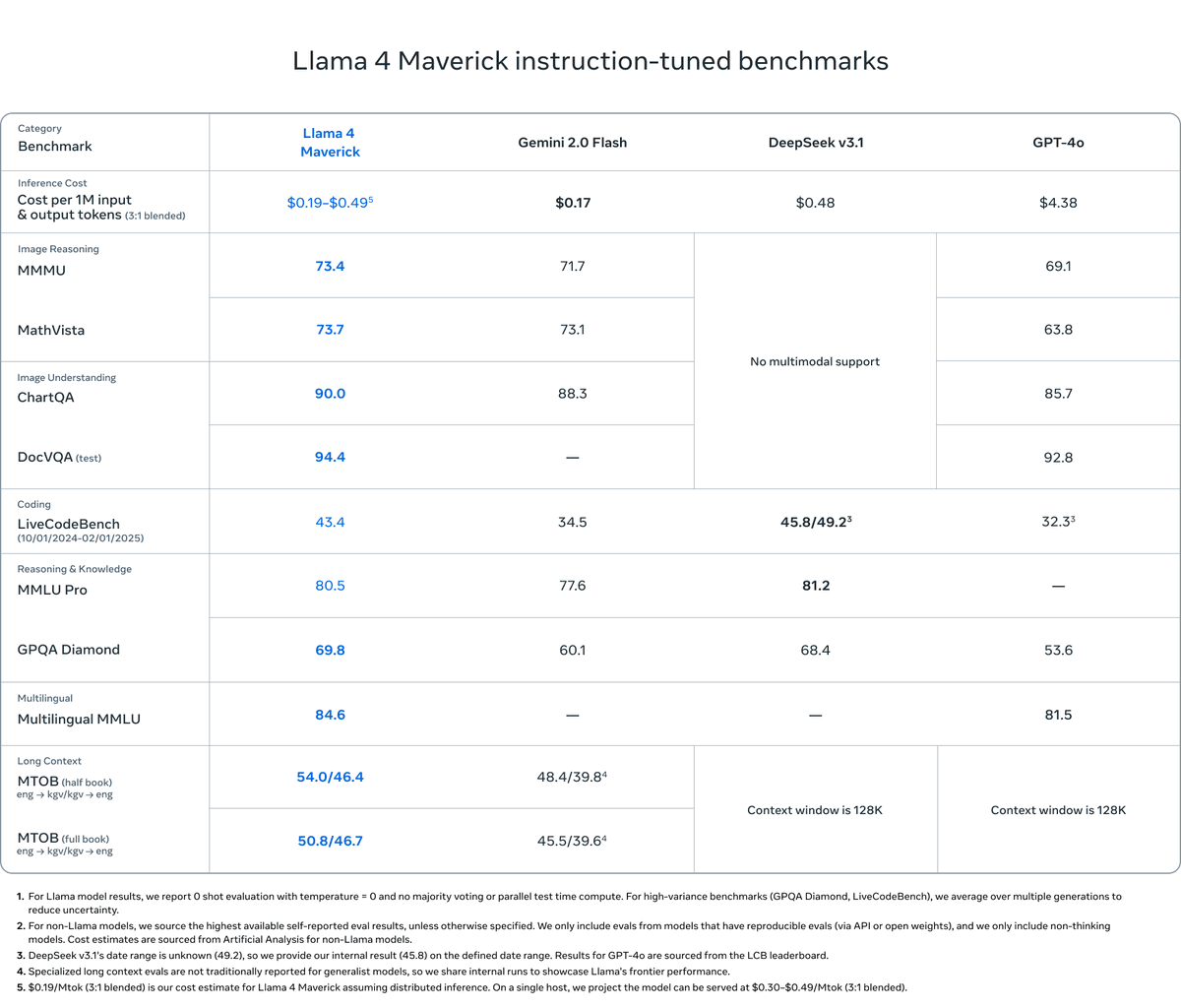
Llama 4 Maverick beats GPT-4o and DeepSeek v3.1 and reportedly cheaper
4/12
@minchoi
Llama 4 Scout handles 10M tokens, fits on 1 GPU (H100), and crushes long docs, code, and search tasks.
https://video.twimg.com/ext_tw_video/1908634008256139264/pu/vid/avc1/1280x720/v8lyumGxQL3ZzP0t.mp4
5/12
@minchoi
Official announcement
[Quoted tweet]
Today is the start of a new era of natively multimodal AI innovation.
Today, we’re introducing the first Llama 4 models: Llama 4 Scout and Llama 4 Maverick — our most advanced models yet and the best in their class for multimodality.
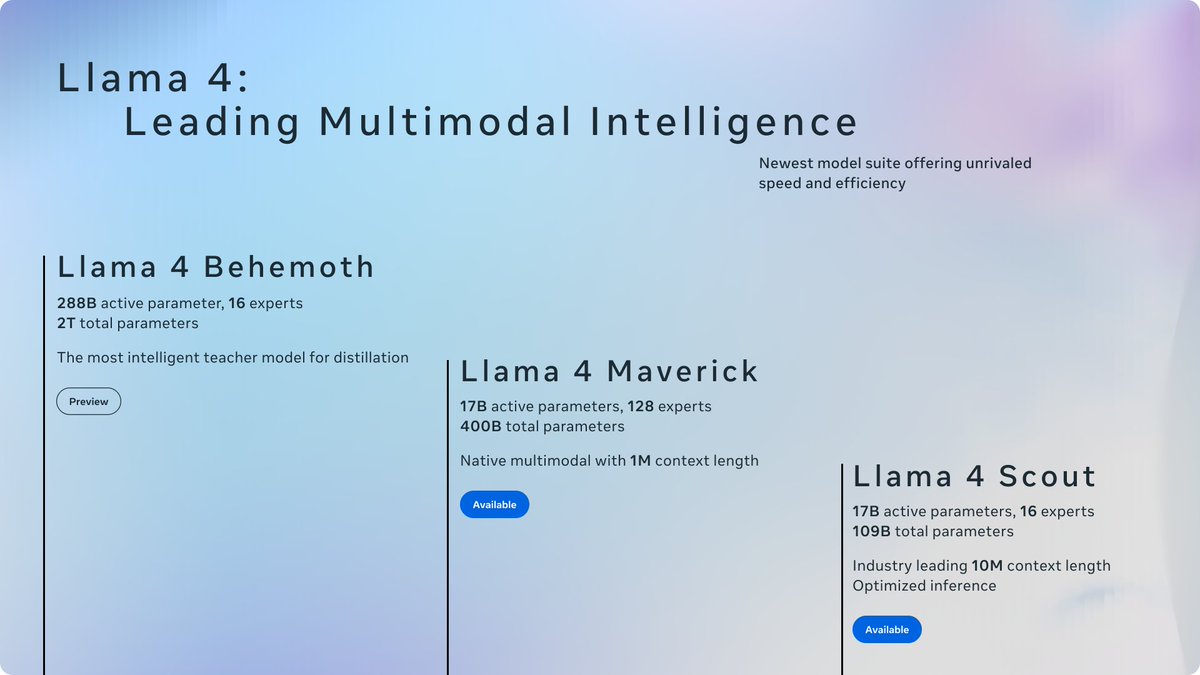
Llama 4 Scout
• 17B-active-parameter model with 16 experts.
• Industry-leading context window of 10M tokens.
• Outperforms Gemma 3, Gemini 2.0 Flash-Lite and Mistral 3.1 across a broad range of widely accepted benchmarks.
Llama 4 Maverick
• 17B-active-parameter model with 128 experts.
• Best-in-class image grounding with the ability to align user prompts with relevant visual concepts and anchor model responses to regions in the image.
• Outperforms GPT-4o and Gemini 2.0 Flash across a broad range of widely accepted benchmarks.
• Achieves comparable results to DeepSeek v3 on reasoning and coding — at half the active parameters.
• Unparalleled performance-to-cost ratio with a chat version scoring ELO of 1417 on LMArena.
These models are our best yet thanks to distillation from Llama 4 Behemoth, our most powerful model yet. Llama 4 Behemoth is still in training and is currently seeing results that outperform GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on STEM-focused benchmarks. We’re excited to share more details about it even while it’s still in flight.
Read more about the first Llama 4 models, including training and benchmarks go.fb.me/gmjohs
go.fb.me/gmjohs
Download Llama 4 go.fb.me/bwwhe9
[media=twitter]1908598456144531660[/media]
6/12
@minchoi
If you enjoyed this thread,
Follow me @minchoi and please Bookmark, Like, Comment & Repost the first Post below to share with your friends:
[Quoted tweet]
Holy sh*t
Meta just revealed Llama 4 models: Behemoth, Maverick & Scout.
Llama 4 Scout can run on single GPU and has 10M context window
[media=twitter]1908629170717966629[/media]
https://video.twimg.com/ext_tw_video/1908628230237573120/pu/vid/avc1/720x1280/P74rnIupiit-c6E0.mp4
7/12
@WilderWorld
WILD
8/12
@minchoi
It's getting wild out there
9/12
@AdamJHumphreys
I was always frustrated with the context window limitations of @ChatGPTapp. Apparently Grok/Gemini is much higher that ChatGPT by a significant factor in context window.
10/12
@minchoi
Yes it's true. Now Llama 4 just topped them with 10M
11/12
@tgreen2241
If he thinks it will outperform o3 or o4 mini, he's sorely mistaken.
12/12
@minchoi
Did you mean Llama 4 Reasoning?
@minchoi
Holy sh*t
Meta just revealed Llama 4 models: Behemoth, Maverick & Scout.
Llama 4 Scout can run on single GPU and has 10M context window
https://video.twimg.com/ext_tw_video/1908628230237573120/pu/vid/avc1/720x1280/P74rnIupiit-c6E0.mp4
2/12
@minchoi
And Llama 4 Maverick just took #2 spot on Arena Leaderboard with 1417 ELO
[Quoted tweet]
BREAKING: Meta's Llama 4 Maverick just hit #2 overall - becoming the 4th org to break 1400+ on Arena!
Highlights:
- #1 open model, surpassing DeepSeek
- Tied #1 in Hard Prompts, Coding, Math, Creative Writing
- Huge leap over Llama 3 405B: 1268 → 1417
- #5 under style control
Huge congrats to @AIatMeta — and another big win for open-source!
More analysis below[media=twitter]1908601011989782976[/media]
3/12
@minchoi
Llama 4 Maverick beats GPT-4o and DeepSeek v3.1 and reportedly cheaper
4/12
@minchoi
Llama 4 Scout handles 10M tokens, fits on 1 GPU (H100), and crushes long docs, code, and search tasks.
https://video.twimg.com/ext_tw_video/1908634008256139264/pu/vid/avc1/1280x720/v8lyumGxQL3ZzP0t.mp4
5/12
@minchoi
Official announcement
[Quoted tweet]
Today is the start of a new era of natively multimodal AI innovation.
Today, we’re introducing the first Llama 4 models: Llama 4 Scout and Llama 4 Maverick — our most advanced models yet and the best in their class for multimodality.
Llama 4 Scout
• 17B-active-parameter model with 16 experts.
• Industry-leading context window of 10M tokens.
• Outperforms Gemma 3, Gemini 2.0 Flash-Lite and Mistral 3.1 across a broad range of widely accepted benchmarks.
Llama 4 Maverick
• 17B-active-parameter model with 128 experts.
• Best-in-class image grounding with the ability to align user prompts with relevant visual concepts and anchor model responses to regions in the image.
• Outperforms GPT-4o and Gemini 2.0 Flash across a broad range of widely accepted benchmarks.
• Achieves comparable results to DeepSeek v3 on reasoning and coding — at half the active parameters.
• Unparalleled performance-to-cost ratio with a chat version scoring ELO of 1417 on LMArena.
These models are our best yet thanks to distillation from Llama 4 Behemoth, our most powerful model yet. Llama 4 Behemoth is still in training and is currently seeing results that outperform GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on STEM-focused benchmarks. We’re excited to share more details about it even while it’s still in flight.
Read more about the first Llama 4 models, including training and benchmarks
go.fb.me/gmjohsDownload Llama 4
go.fb.me/bwwhe9[media=twitter]1908598456144531660[/media]
6/12
@minchoi
If you enjoyed this thread,
Follow me @minchoi and please Bookmark, Like, Comment & Repost the first Post below to share with your friends:
[Quoted tweet]
Holy sh*t
Meta just revealed Llama 4 models: Behemoth, Maverick & Scout.
Llama 4 Scout can run on single GPU and has 10M context window
[media=twitter]1908629170717966629[/media]
https://video.twimg.com/ext_tw_video/1908628230237573120/pu/vid/avc1/720x1280/P74rnIupiit-c6E0.mp4
7/12
@WilderWorld
WILD
8/12
@minchoi
It's getting wild out there
9/12
@AdamJHumphreys
I was always frustrated with the context window limitations of @ChatGPTapp. Apparently Grok/Gemini is much higher that ChatGPT by a significant factor in context window.
10/12
@minchoi
Yes it's true. Now Llama 4 just topped them with 10M
11/12
@tgreen2241
If he thinks it will outperform o3 or o4 mini, he's sorely mistaken.
12/12
@minchoi
Did you mean Llama 4 Reasoning?
1/16
@omarsar0
Llama 4 is here!
- Llama 4 Scout & Maverick are up for download
- Llama 4 Behemoth (preview)
- Advanced problem solving & multilingual
- Support long context up to 10M tokens
- Great for multimodal apps & agents
- Image grounding
- Top performance at the lowest cost
- Can be served within $0.19-$0.49/M tokens
2/16
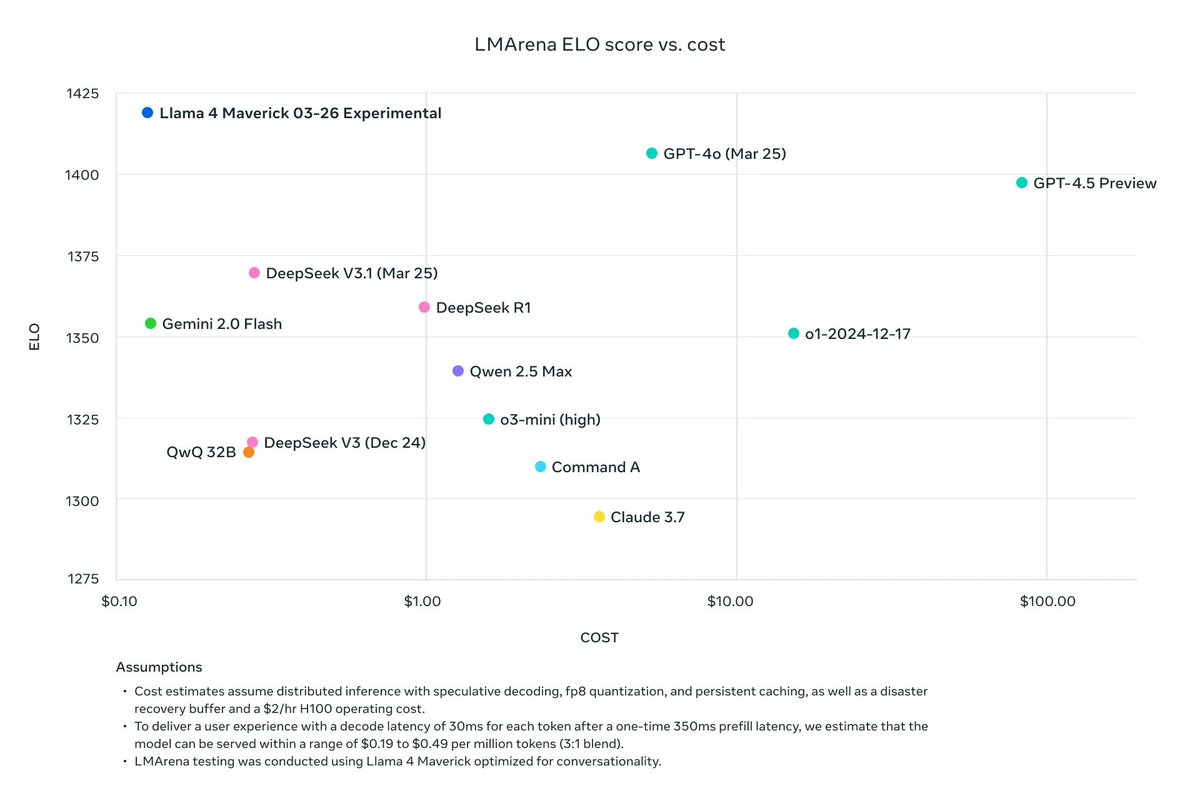
@omarsar0
LMArena ELO score vs. cost
"To deliver a user experience with a decode latency of 30ms for each token after a one-time 350ms prefill latency, we estimate that the model can be served within a range of $0.19-$0.49 per million tokens (3:1 blend)"
3/16
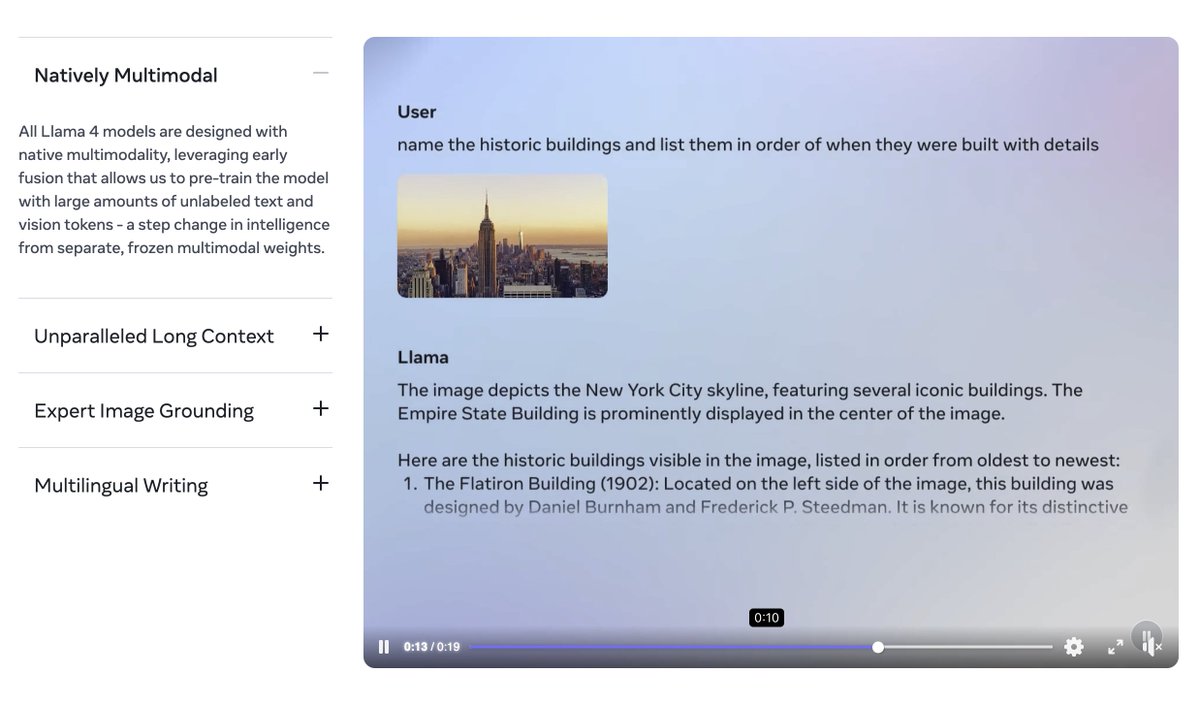
@omarsar0
It's great to see native multimodal support for Llama 4.
4/16
@omarsar0
Llama 4 Scout is a 17B active parameter model with 16 experts and fits in a single H100 GPU.
Llama 4 Maverick is a 17B active parameter model with 128 experts. The best multimodal model in its class, beating GPT-4o & Gemini 2.0 Flash on several benchmarks.

5/16
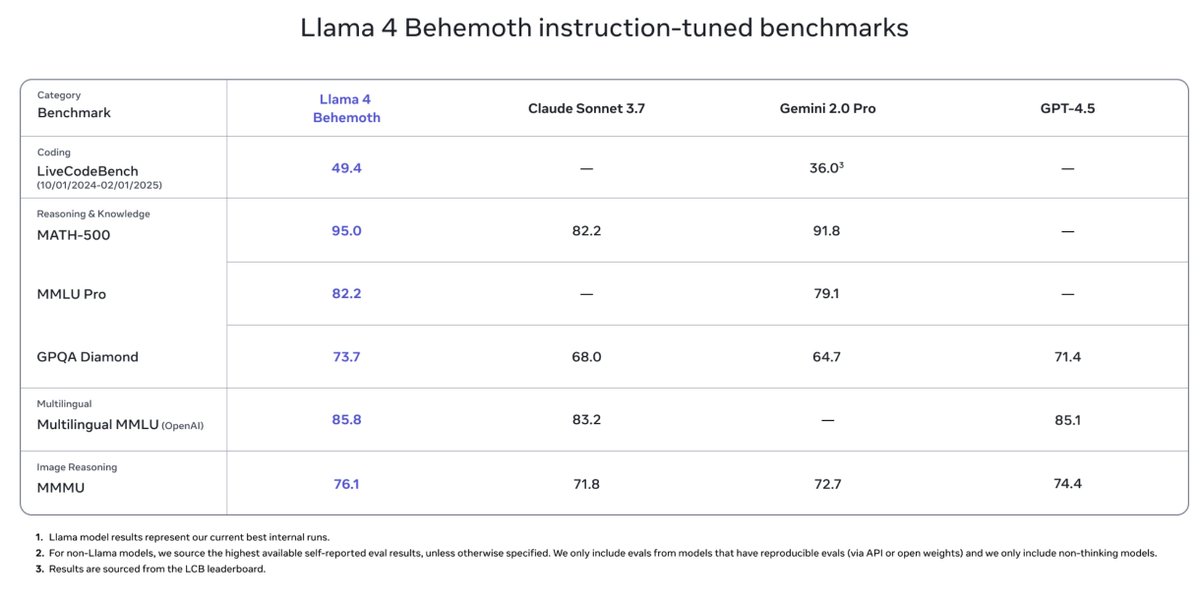
@omarsar0
Those models were distilled from Llama 4 Behemoth, a 288B active parameter model with 16 experts.
Behemoth is their most powerful model in the series. Llama 4 Behemoth outperforms GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on several STEM benchmarks.
6/16
@omarsar0
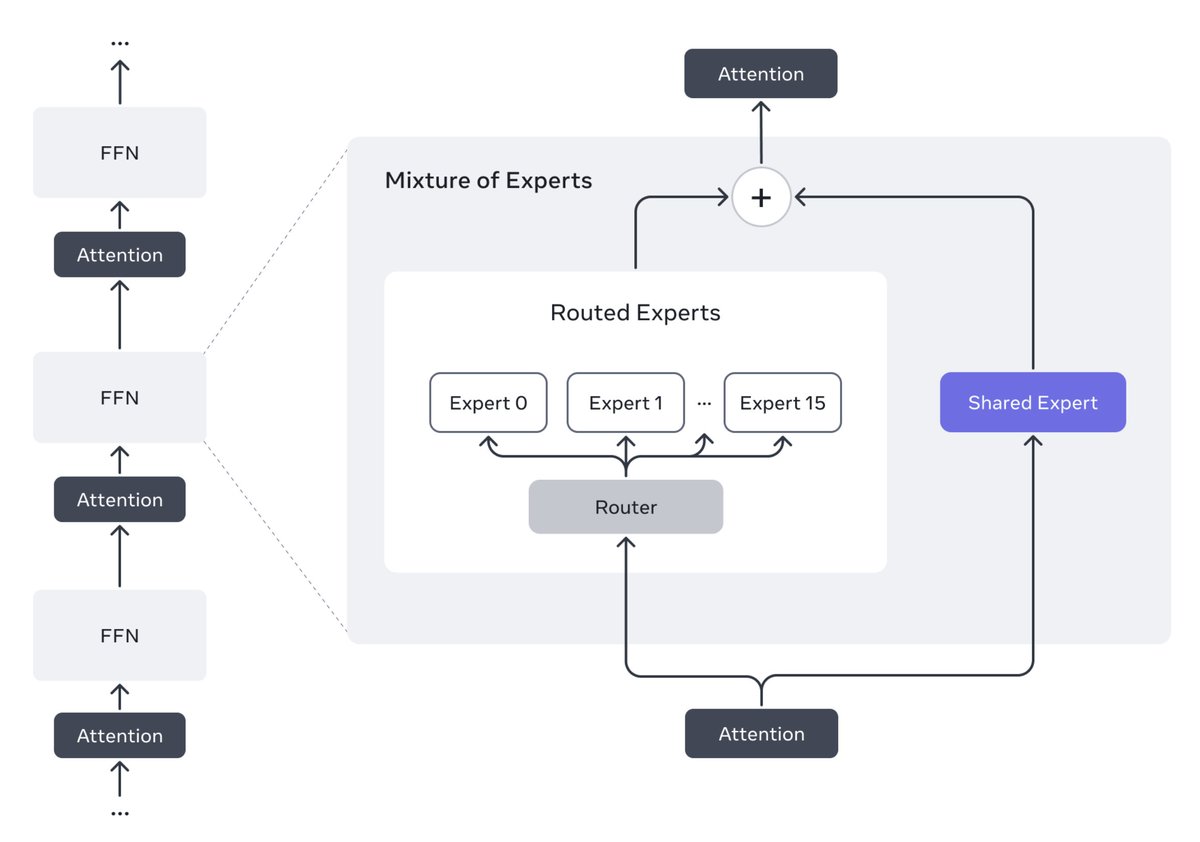
Llama 4 seems to be the first model from Meta to use a mixture of experts (MoE) architecture.
This makes it possible to run models like Llama 4 Maverick on a single H100 DGX host for easy deployment.
7/16
@omarsar0
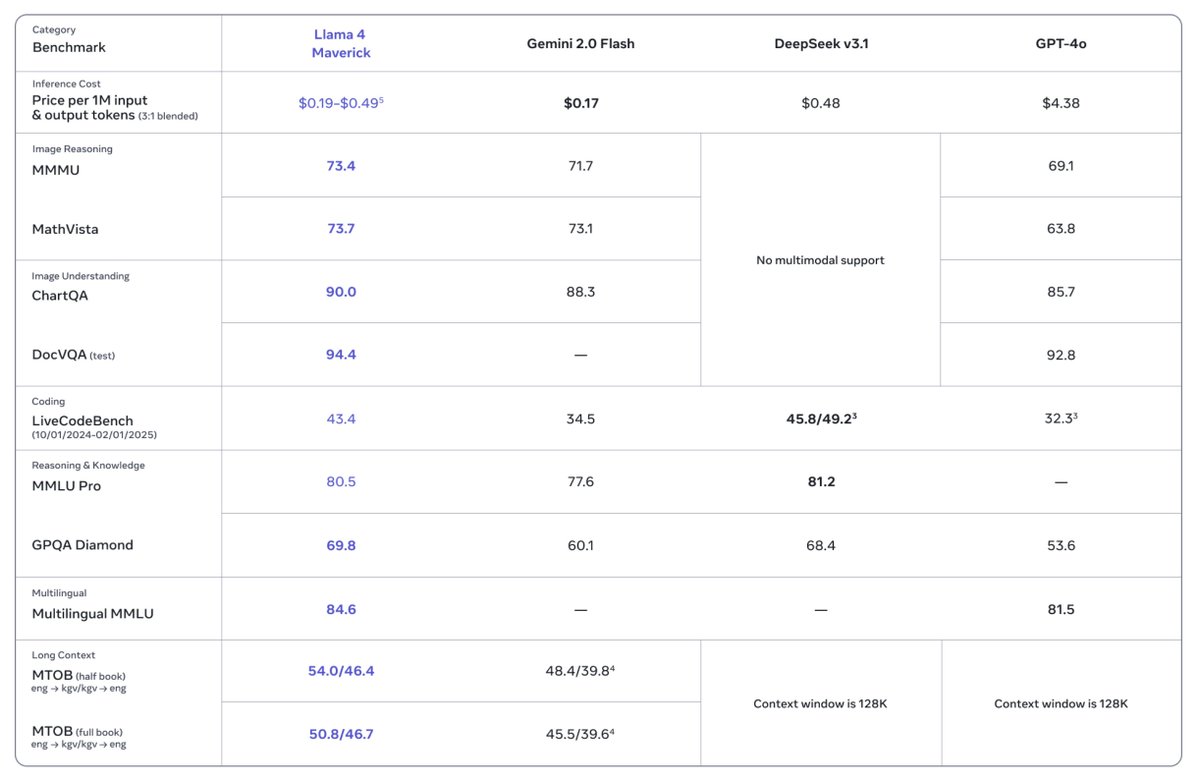
Claims Llama 4 Maverick achieves comparable results to DeepSeek v3 on reasoning and coding, at half the active parameters.
8/16
@omarsar0
The long context support is gonna be huge for devs building agents.
There is more coming, too!
Llama 4 Reasoning is already cooking!
https://video.twimg.com/ext_tw_video/1908606494527893504/pu/vid/avc1/1280x720/8gb5oYcDl093QmYm.mp4
9/16
@omarsar0
Download the Llama 4 Scout and Llama 4 Maverick models today on Llama and Hugging Face.
Llama 4 (via Meta AI) is also available to use in WhatsApp, Messenger, Instagram Direct, and on the web.
10/16
@omarsar0
HF models: meta-llama (Meta Llama)
Great guide on Llama 4 is here: Llama 4 | Model Cards and Prompt formats
Detailed blog: The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation
11/16
@omarsar0
The model backbone seems to use early fusion to integrate text, image, and video tokens.
Post-training pipeline: lightweight SFT → online RL → lightweight DPO.
They state that the overuse of SFT/DPO can over-constrain the model and limit exploration during online RL and suggest keeping it light instead.

12/16
@omarsar0
It seems to be available on Fireworks AI APIs already:
[Quoted tweet]
 llama4 launch on @FireworksAI_HQ !
llama4 launch on @FireworksAI_HQ !
Llama4 has just set a new record—not only among open models but across all models. We’re thrilled to be a launch partner with @Meta to provide easy API access to a herd of next-level intelligence!
The herd of models launched are in a class of their own, offering a unique combination of multi-modality and long-context capabilities (up to 10 million tokens!). We expect a lot of active agent development to experiment and go to production with this new set of models.
Our initial rollout includes both Scout and Maverick models, with further optimizations and enhanced developer toolchains launching soon.
You can access the model APIs below, and we can't wait to see what you build!
llama4- scout: fireworks.ai/models/firework…
llama4 - maverick: fireworks.ai/models/firework…
[media=twitter]1908610306924044507[/media]
13/16
@omarsar0
Besides the shift to MoE and native multimodal support, how they aim to support "infinite" context length is a bit interesting.
More from their long context lead here:
[Quoted tweet]
Our Llama 4’s industry leading 10M+ multimodal context length (20+ hours of video) has been a wild ride. The iRoPE architecture I’d been working on helped a bit with the long-term infinite context goal toward AGI. Huge thanks to my incredible teammates!
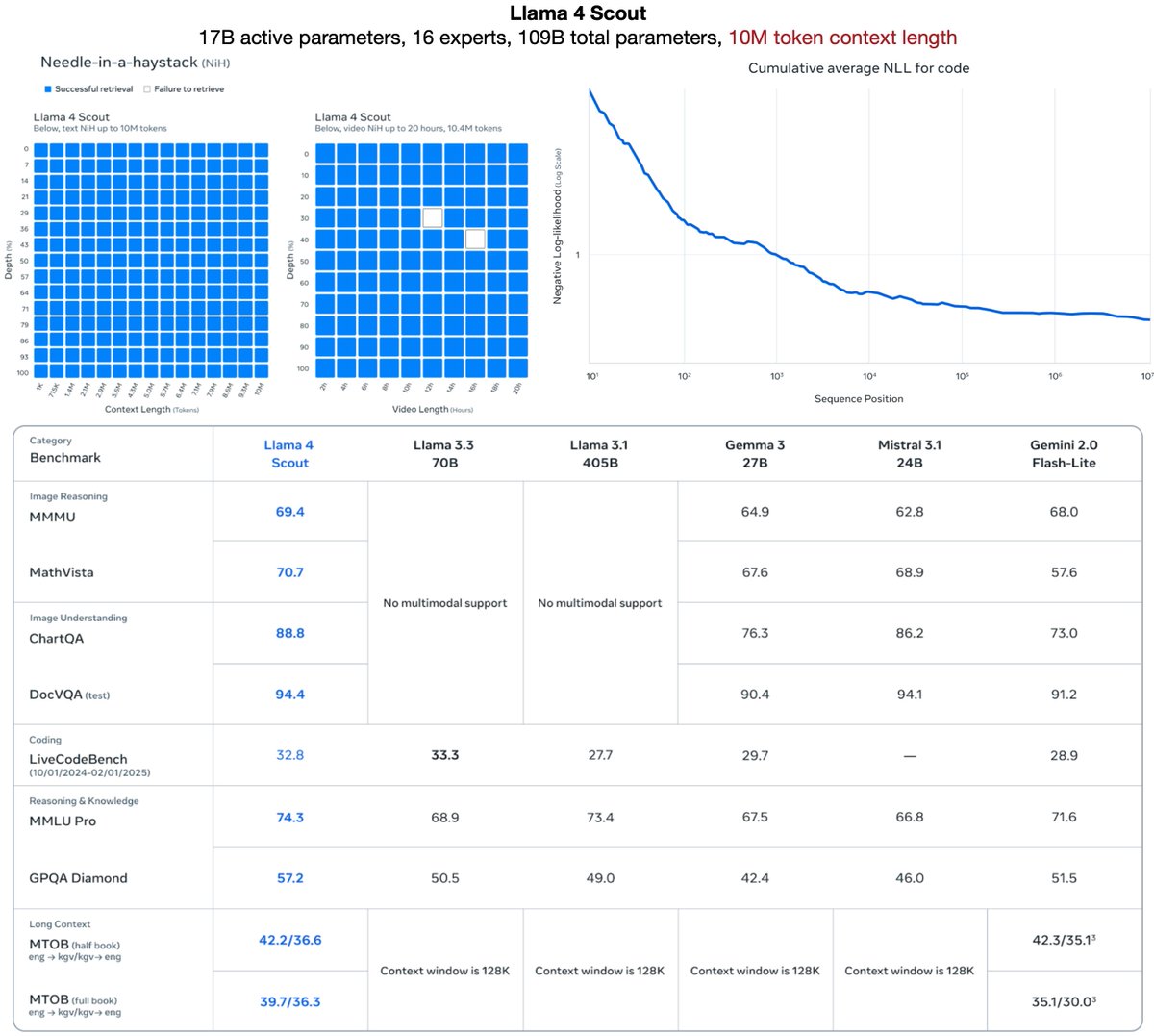
 Llama 4 Scout
Llama 4 Scout
 17B active params · 16 experts · 109B total params
17B active params · 16 experts · 109B total params
Fits on a single H100 GPU with Int4
Industry-leading 10M+ multimodal context length enables personalization, reasoning over massive codebases, and even remembering your day in video
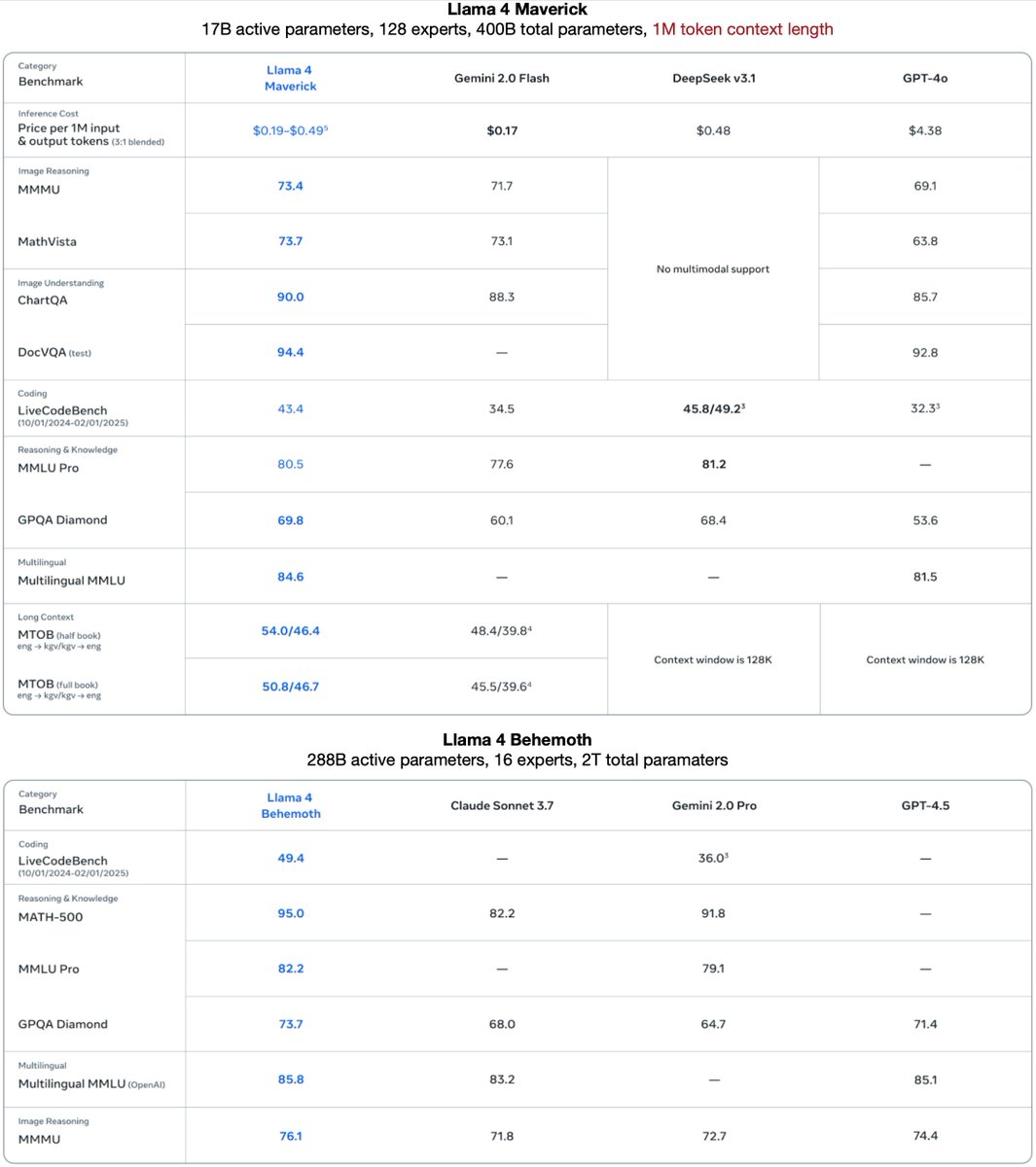
Llama 4 Maverick
17B active params · 128 experts · 400B total params · 1M+ context length
Experimental chat version scores ELO 1417 (Rank #2) on LMArena
Llama 4 Behemoth (in training)
288B active params · 16 experts · 2T total params
Pretraining (FP8) with 30T multimodal tokens across 32K GPUs
Serves as the teacher model for Maverick codistillation
All models use early fusion to seamlessly integrate text, image, and video tokens into a unified model backbone.
Our post-training pipeline: lightweight SFT → online RL → lightweight DPO. Overuse of SFT/DPO can over-constrain the model and limit exploration during online RL—keep it light.
 Solving long context by aiming for infinite context helps guide better architectures.
Solving long context by aiming for infinite context helps guide better architectures.
We can't train on infinite-length sequences—so framing it as an infinite context problem narrows the solution space, especially via length extrapolation: train on short, generalize to much longer.
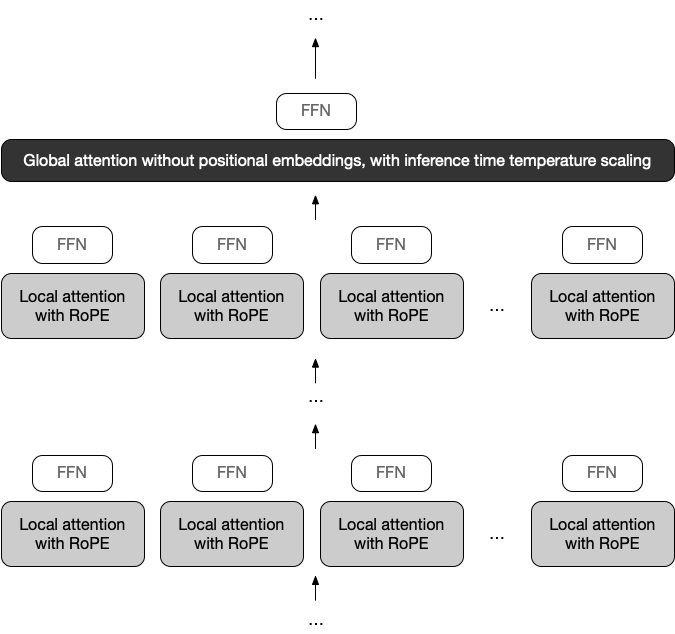
Enter the iRoPE architecture (“i” = interleaved layers, infinite):
Local parallellizable chunked attention with RoPE models short contexts only (e.g., 8K)
Only global attention layers model long context (e.g., >8K) without position embeddings—improving extrapolation. Our max training length: 256K.
As context increases, attention weights flatten—making inference harder. To compensate, we apply inference-time temperature scaling at global layers to enhance long-range reasoning while preserving short-context (e.g., α=8K) performance:
xq *= 1 + log(floor(i / α) + 1) * β # i = position index
We believe in open research. We'll share more technical details very soon—via podcasts. Stay tuned!
[media=twitter]1908595612372885832[/media]

14/16
@omarsar0
Licensing limitations: If over 700M monthly active users, you need to request a special license.
[Quoted tweet]
Llama 4's new license comes with several limitations:
- Companies with more than 700 million monthly active users must request a special license from Meta, which Meta can grant or deny at its sole discretion.
- You must prominently display "Built with Llama" on websites, interfaces, documentation, etc.
- Any AI model you create using Llama Materials must include "Llama" at the beginning of its name
- You must include the specific attribution notice in a "Notice" text file with any distribution
- Your use must comply with Meta's separate Acceptable Use Policy (referenced at llama.com/llama4/use-policy)
- Limited license to use "Llama" name only for compliance with the branding requirements
[media=twitter]1908602756182745506[/media]
15/16
@omarsar0
This 2 trillion total parameter model (Behemoth) is a game-changer for Meta.
They had to revamp their underlying RL infrastructure due to the scale.
They're now positioned to unlock insane performance jumps and capabilities for agents and reasoning going forward. Big moves!

16/16
@omarsar0
I expected nothing less. It's great to see Meta become the 4th org to break that 1400 (# 2 overall) on the Arena.
What comes next, as I said above, is nothing to ignore. Open-source AI is going to reach new heights that will break things.
OpenAI understands this well.
@omarsar0
Llama 4 is here!
- Llama 4 Scout & Maverick are up for download
- Llama 4 Behemoth (preview)
- Advanced problem solving & multilingual
- Support long context up to 10M tokens
- Great for multimodal apps & agents
- Image grounding
- Top performance at the lowest cost
- Can be served within $0.19-$0.49/M tokens
2/16
@omarsar0
LMArena ELO score vs. cost
"To deliver a user experience with a decode latency of 30ms for each token after a one-time 350ms prefill latency, we estimate that the model can be served within a range of $0.19-$0.49 per million tokens (3:1 blend)"
3/16
@omarsar0
It's great to see native multimodal support for Llama 4.
4/16
@omarsar0
Llama 4 Scout is a 17B active parameter model with 16 experts and fits in a single H100 GPU.
Llama 4 Maverick is a 17B active parameter model with 128 experts. The best multimodal model in its class, beating GPT-4o & Gemini 2.0 Flash on several benchmarks.
5/16
@omarsar0
Those models were distilled from Llama 4 Behemoth, a 288B active parameter model with 16 experts.
Behemoth is their most powerful model in the series. Llama 4 Behemoth outperforms GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on several STEM benchmarks.
6/16
@omarsar0
Llama 4 seems to be the first model from Meta to use a mixture of experts (MoE) architecture.
This makes it possible to run models like Llama 4 Maverick on a single H100 DGX host for easy deployment.
7/16
@omarsar0
Claims Llama 4 Maverick achieves comparable results to DeepSeek v3 on reasoning and coding, at half the active parameters.
8/16
@omarsar0
The long context support is gonna be huge for devs building agents.
There is more coming, too!
Llama 4 Reasoning is already cooking!
https://video.twimg.com/ext_tw_video/1908606494527893504/pu/vid/avc1/1280x720/8gb5oYcDl093QmYm.mp4
9/16
@omarsar0
Download the Llama 4 Scout and Llama 4 Maverick models today on Llama and Hugging Face.
Llama 4 (via Meta AI) is also available to use in WhatsApp, Messenger, Instagram Direct, and on the web.
10/16
@omarsar0
HF models: meta-llama (Meta Llama)
Great guide on Llama 4 is here: Llama 4 | Model Cards and Prompt formats
Detailed blog: The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation
11/16
@omarsar0
The model backbone seems to use early fusion to integrate text, image, and video tokens.
Post-training pipeline: lightweight SFT → online RL → lightweight DPO.
They state that the overuse of SFT/DPO can over-constrain the model and limit exploration during online RL and suggest keeping it light instead.
12/16
@omarsar0
It seems to be available on Fireworks AI APIs already:
[Quoted tweet]
llama4 launch on @FireworksAI_HQ ! Llama4 has just set a new record—not only among open models but across all models. We’re thrilled to be a launch partner with @Meta to provide easy API access to a herd of next-level intelligence!
The herd of models launched are in a class of their own, offering a unique combination of multi-modality and long-context capabilities (up to 10 million tokens!). We expect a lot of active agent development to experiment and go to production with this new set of models.
Our initial rollout includes both Scout and Maverick models, with further optimizations and enhanced developer toolchains launching soon.
You can access the model APIs below, and we can't wait to see what you build!
llama4- scout: fireworks.ai/models/firework… llama4 - maverick: fireworks.ai/models/firework…[media=twitter]1908610306924044507[/media]
13/16
@omarsar0
Besides the shift to MoE and native multimodal support, how they aim to support "infinite" context length is a bit interesting.
More from their long context lead here:
[Quoted tweet]
Our Llama 4’s industry leading 10M+ multimodal context length (20+ hours of video) has been a wild ride. The iRoPE architecture I’d been working on helped a bit with the long-term infinite context goal toward AGI. Huge thanks to my incredible teammates!
Llama 4 Scout17B active params · 16 experts · 109B total paramsFits on a single H100 GPU with Int4Industry-leading 10M+ multimodal context length enables personalization, reasoning over massive codebases, and even remembering your day in videoLlama 4 Maverick17B active params · 128 experts · 400B total params · 1M+ context lengthExperimental chat version scores ELO 1417 (Rank #2) on LMArenaLlama 4 Behemoth (in training)288B active params · 16 experts · 2T total paramsPretraining (FP8) with 30T multimodal tokens across 32K GPUsServes as the teacher model for Maverick codistillationAll models use early fusion to seamlessly integrate text, image, and video tokens into a unified model backbone.Our post-training pipeline: lightweight SFT → online RL → lightweight DPO. Overuse of SFT/DPO can over-constrain the model and limit exploration during online RL—keep it light.Solving long context by aiming for infinite context helps guide better architectures.We can't train on infinite-length sequences—so framing it as an infinite context problem narrows the solution space, especially via length extrapolation: train on short, generalize to much longer.
Enter the iRoPE architecture (“i” = interleaved layers, infinite):
Local parallellizable chunked attention with RoPE models short contexts only (e.g., 8K)Only global attention layers model long context (e.g., >8K) without position embeddings—improving extrapolation. Our max training length: 256K.As context increases, attention weights flatten—making inference harder. To compensate, we apply inference-time temperature scaling at global layers to enhance long-range reasoning while preserving short-context (e.g., α=8K) performance:xq *= 1 + log(floor(i / α) + 1) * β # i = position index
We believe in open research. We'll share more technical details very soon—via podcasts. Stay tuned!
[media=twitter]1908595612372885832[/media]
14/16
@omarsar0
Licensing limitations: If over 700M monthly active users, you need to request a special license.
[Quoted tweet]
Llama 4's new license comes with several limitations:
- Companies with more than 700 million monthly active users must request a special license from Meta, which Meta can grant or deny at its sole discretion.
- You must prominently display "Built with Llama" on websites, interfaces, documentation, etc.
- Any AI model you create using Llama Materials must include "Llama" at the beginning of its name
- You must include the specific attribution notice in a "Notice" text file with any distribution
- Your use must comply with Meta's separate Acceptable Use Policy (referenced at llama.com/llama4/use-policy)
- Limited license to use "Llama" name only for compliance with the branding requirements
[media=twitter]1908602756182745506[/media]
15/16
@omarsar0
This 2 trillion total parameter model (Behemoth) is a game-changer for Meta.
They had to revamp their underlying RL infrastructure due to the scale.
They're now positioned to unlock insane performance jumps and capabilities for agents and reasoning going forward. Big moves!
16/16
@omarsar0
I expected nothing less. It's great to see Meta become the 4th org to break that 1400 (# 2 overall) on the Arena.
What comes next, as I said above, is nothing to ignore. Open-source AI is going to reach new heights that will break things.
OpenAI understands this well.
 2025-02-25
2025-02-25 Biggest AI Model in Biology: Evo 2
Biggest AI Model in Biology: Evo 2 Evo 2, co-developed by Arc Institute, @Stanford, and @NVIDIA, is the largest AI model for biology, trained on 128,000 genomes across species.
Evo 2, co-developed by Arc Institute, @Stanford, and @NVIDIA, is the largest AI model for biology, trained on 128,000 genomes across species. Capabilities:
Capabilities: Key Features:
Key Features: ⃤ 🅐🅛🅔🅧 #🅓🅔🅟🅘🅝 #🅓🅔🅢🅒🅘 #🅓🅔🅢🅐🅘 #D̳̿͟͞e̳̿͟͞S̳̿͟͞c̳̿͟͞i̳̿͟͞C̳̿͟͞u̳̿͟͞l̳̿͟͞t̳̿͟͞
⃤ 🅐🅛🅔🅧 #🅓🅔🅟🅘🅝 #🅓🅔🅢🅒🅘 #🅓🅔🅢🅐🅘 #D̳̿͟͞e̳̿͟͞S̳̿͟͞c̳̿͟͞i̳̿͟͞C̳̿͟͞u̳̿͟͞l̳̿͟͞t̳̿͟͞ AI-Powered Bioengineering with Evo 2 – A New Era Begins
AI-Powered Bioengineering with Evo 2 – A New Era Begins 
 Synthetic biology has long aimed to design biological systems with engineering precision. Yet, nature’s complexity has made this difficult—until now. AI is changing the game.
Synthetic biology has long aimed to design biological systems with engineering precision. Yet, nature’s complexity has made this difficult—until now. AI is changing the game. 
 Meet Evo 2, the latest AI model from Arc Institute & NVIDIA. Trained on 128,000 genomes, it can predict mutations, generate DNA sequences, and model long-range genetic interactions.
Meet Evo 2, the latest AI model from Arc Institute & NVIDIA. Trained on 128,000 genomes, it can predict mutations, generate DNA sequences, and model long-range genetic interactions. 
 Evo 2’s 40B parameters and extended context window allow it to analyze entire genes, regulatory regions, and chromatin interactions—essential for understanding genome function.
Evo 2’s 40B parameters and extended context window allow it to analyze entire genes, regulatory regions, and chromatin interactions—essential for understanding genome function. Key capabilities of Evo 2:
Key capabilities of Evo 2: Predicts pathogenic mutations in seconds
Predicts pathogenic mutations in seconds 

 Evo 2 doesn’t just memorize data—it has learned fundamental biological concepts like:
Evo 2 doesn’t just memorize data—it has learned fundamental biological concepts like:
 Why does this matter? AI-driven genome design could revolutionize:
Why does this matter? AI-driven genome design could revolutionize:



 This breakthrough parallels AlphaFold's impact on protein folding—Evo 2 makes bioengineering more predictable, scalable, and accessible than ever before.
This breakthrough parallels AlphaFold's impact on protein folding—Evo 2 makes bioengineering more predictable, scalable, and accessible than ever before.
 Evo 2 is open-source and available for researchers via API. Could this be the beginning of AI-driven genetic design? The future of synthetic biology is here.
Evo 2 is open-source and available for researchers via API. Could this be the beginning of AI-driven genetic design? The future of synthetic biology is here. 










 now they are really going to make cat girls and Werewolves.
now they are really going to make cat girls and Werewolves. Singularity Escape Velocity
Singularity Escape Velocity







 Announcing @MistralAI Saba, our first regional language model.
Announcing @MistralAI Saba, our first regional language model. 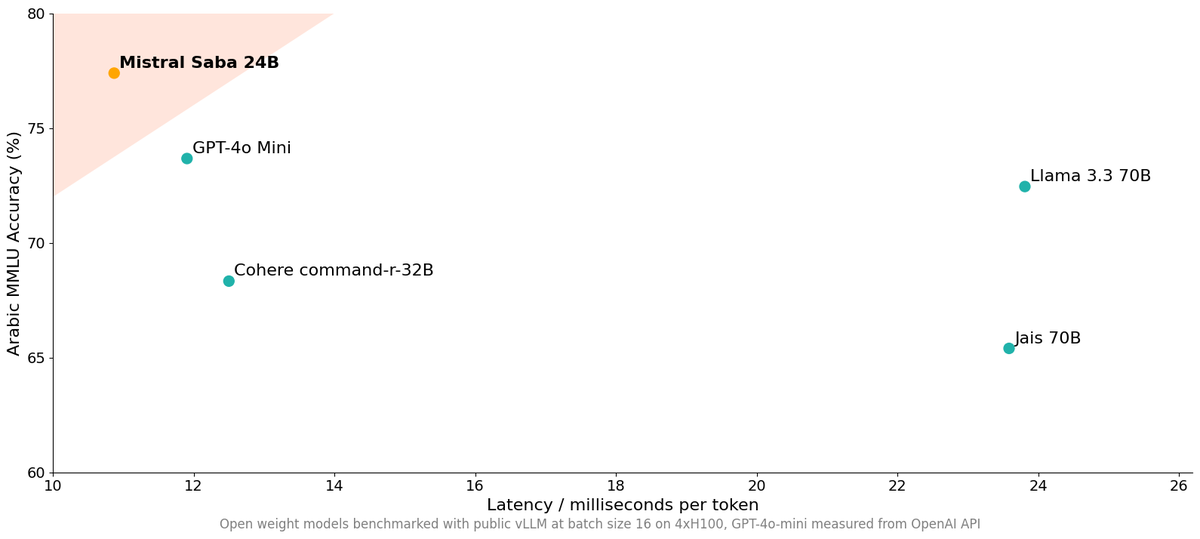











 Hope you enjoyed it
Hope you enjoyed it 



 may be we will get to see agents agencies who will rent these agents to companies based on contract
may be we will get to see agents agencies who will rent these agents to companies based on contract AI Just Broke Humanity’s Coding Record: Full o3 Officially World’s BEST Programmer!
AI Just Broke Humanity’s Coding Record: Full o3 Officially World’s BEST Programmer! 

 Just imagine—an AI model that was once 175th in coding rankings has now ascended to the very top.
Just imagine—an AI model that was once 175th in coding rankings has now ascended to the very top.




 That was faster than I thought.,...
That was faster than I thought.,...






 Those seem like pretty obvious "problems" to pop up if a system is beginning to advance rapidly.
Those seem like pretty obvious "problems" to pop up if a system is beginning to advance rapidly.