
1/42
@reach_vb
"DeepSeek-R1-Distill-Qwen-1.5B outperforms GPT-4o and Claude-3.5-Sonnet on math benchmarks with 28.9% on AIME and 83.9% on MATH."
1.5B did WHAT?

2/42
@reach_vb
repo:
deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B · Hugging Face
3/42
@thegenioo
but is it better at coding compared to sonnet new?
4/42
@reach_vb
No, R1 series models aren’t better than V3 on coding, that’s what DeepSeek would work at the next step
They are still pretty powerful tho
5/42
@iatharvkulkarni
How do you run these models? I see that you post a lot of hugging face models, how do you personally run them? Any tool that would help me get going as quickly as possible locally?
6/42
@reach_vb
llama.cpp or transformers, let me make a quick notebook actually
7/42
@leo_grundstrom
How fast is it?
8/42
@reach_vb
Reasonably fast on an old T4, try it out yourself:
[Quoted tweet]
Try out R1 Distill Qwen 1.5B in a FREE Google Colab!
The vibes are looking gooood!
https://video.twimg.com/ext_tw_video/1881377422135676928/pu/vid/avc1/1670x1080/wUafm6PII4xXizvR.mp4
9/42
@antonio_spie
Can SOMEONE PLEASE TELL ME HOW MANY GBS TO INSTALL LOCALLY??
10/42
@reach_vb
You can try the 1.5B directly here on a free Google colab
[Quoted tweet]
Try out R1 Distill Qwen 1.5B in a FREE Google Colab!
The vibes are looking gooood!
https://video.twimg.com/ext_tw_video/1881377422135676928/pu/vid/avc1/1670x1080/wUafm6PII4xXizvR.mp4
11/42
@ArpinGarre66002
Dubious
12/42
@reach_vb
Ha, the vibes are strong, I don’t care much about the benchmark, but for a 1.5B it’s pretty strong, try it out yourself:
[Quoted tweet]
Try out R1 Distill Qwen 1.5B in a FREE Google Colab!
The vibes are looking gooood!
https://video.twimg.com/ext_tw_video/1881377422135676928/pu/vid/avc1/1670x1080/wUafm6PII4xXizvR.mp4
13/42
@gordic_aleksa
overfit is the word
14/42
@reach_vb
Vibe checks look pretty good tho, been playing with it on Colab - not sonnet or 4o like but deffo pretty strong for a 1.5B
[Quoted tweet]
Try out R1 Distill Qwen 1.5B in a FREE Google Colab!
The vibes are looking gooood!
https://video.twimg.com/ext_tw_video/1881377422135676928/pu/vid/avc1/1670x1080/wUafm6PII4xXizvR.mp4
15/42
@CEOofFuggy
I doubt it's good in general tho, but I'll definitely have to try 14B version etc.
16/42
@reach_vb
think 32B or 70B would be golden
17/42
@snowclipsed
@vikhyatk what if you used this as the text model
18/42
@reach_vb
that would be fire - but I doubt you'd get as much benefit from this, model is a yapper
19/42
@victor_explore
[Quoted tweet]
DeepSeek today
https://video.twimg.com/ext_tw_video/1881340096995364864/pu/vid/avc1/720x720/yN45olzqLvBZt_f_.mp4
20/42
@reach_vb
hahaha, how do you create these, it's amazing!
21/42
@AILeaksAndNews
We are accelerating quickly
3.5 sonnet that can run locally
22/42
@reach_vb
maybe the 32B/ 70B is at that level, I doubt 1.5B will be at that level haha
23/42
@edwardcfrazer
How fast is it
24/42
@reach_vb
On their API it’s pretty fast!
25/42
@anushkmittal
1.5b? more like 1.5 based
26/42
@reach_vb
hahahaha!
27/42
@Yuchenj_UW
Unbelievable.
We will have super smart 1B models in the future, running locally on our phone.
28/42
@reach_vb
I call it Baby AGI
[Quoted tweet]
Try out R1 Distill Qwen 1.5B in a FREE Google Colab!
The vibes are looking gooood!
https://video.twimg.com/ext_tw_video/1881377422135676928/pu/vid/avc1/1670x1080/wUafm6PII4xXizvR.mp4
29/42
@dhruv2038
Yeah this is sus.
30/42
@reach_vb
gotta vibe check it ofc
31/42
@ftmoose
lol

32/42
@reach_vb
I love the way it thinks
33/42
@_ggLAB
yet cannot answer historical events.
34/42
@reach_vb
literally doesn't matter, as long as it works for your own use-cases.
35/42
@AntDX316

36/42
@nooriefyi
this is huge. parameter count is so last year.
37/42
@baileygspell
"few shot prompts degrade peformance" def overfit
38/42
@seo_leaders
Going to have to give that model a run up for sure
39/42
@priontific
I'm so psyched holy moly - I'm also super pumped, I think we can squeeze so much by speculative drafting w/ these tiny models. Results in a few hours once I've finished downloading -- stay tuned!!
40/42
@ionet
at first it seemed like humans being outperformed like that by AI, now AI doing the same to other AI
41/42
@joysectomy
Western cultures are bad at math, Eastern cultures teach math in a bottoms up way. Wonder how much of a factor that is in the consistent perf gap between these models
42/42
@ChaithanyaK42
This is awesome
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@reach_vb
"DeepSeek-R1-Distill-Qwen-1.5B outperforms GPT-4o and Claude-3.5-Sonnet on math benchmarks with 28.9% on AIME and 83.9% on MATH."
1.5B did WHAT?
2/42
@reach_vb
repo:
deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B · Hugging Face
3/42
@thegenioo
but is it better at coding compared to sonnet new?
4/42
@reach_vb
No, R1 series models aren’t better than V3 on coding, that’s what DeepSeek would work at the next step
They are still pretty powerful tho
5/42
@iatharvkulkarni
How do you run these models? I see that you post a lot of hugging face models, how do you personally run them? Any tool that would help me get going as quickly as possible locally?
6/42
@reach_vb
llama.cpp or transformers, let me make a quick notebook actually
7/42
@leo_grundstrom
How fast is it?
8/42
@reach_vb
Reasonably fast on an old T4, try it out yourself:
[Quoted tweet]
Try out R1 Distill Qwen 1.5B in a FREE Google Colab!
The vibes are looking gooood!
https://video.twimg.com/ext_tw_video/1881377422135676928/pu/vid/avc1/1670x1080/wUafm6PII4xXizvR.mp4
9/42
@antonio_spie
Can SOMEONE PLEASE TELL ME HOW MANY GBS TO INSTALL LOCALLY??
10/42
@reach_vb
You can try the 1.5B directly here on a free Google colab
[Quoted tweet]
Try out R1 Distill Qwen 1.5B in a FREE Google Colab!
The vibes are looking gooood!
https://video.twimg.com/ext_tw_video/1881377422135676928/pu/vid/avc1/1670x1080/wUafm6PII4xXizvR.mp4
11/42
@ArpinGarre66002
Dubious
12/42
@reach_vb
Ha, the vibes are strong, I don’t care much about the benchmark, but for a 1.5B it’s pretty strong, try it out yourself:
[Quoted tweet]
Try out R1 Distill Qwen 1.5B in a FREE Google Colab!
The vibes are looking gooood!
https://video.twimg.com/ext_tw_video/1881377422135676928/pu/vid/avc1/1670x1080/wUafm6PII4xXizvR.mp4
13/42
@gordic_aleksa
overfit is the word
14/42
@reach_vb
Vibe checks look pretty good tho, been playing with it on Colab - not sonnet or 4o like but deffo pretty strong for a 1.5B
[Quoted tweet]
Try out R1 Distill Qwen 1.5B in a FREE Google Colab!
The vibes are looking gooood!
https://video.twimg.com/ext_tw_video/1881377422135676928/pu/vid/avc1/1670x1080/wUafm6PII4xXizvR.mp4
15/42
@CEOofFuggy
I doubt it's good in general tho, but I'll definitely have to try 14B version etc.
16/42
@reach_vb
think 32B or 70B would be golden
17/42
@snowclipsed
@vikhyatk what if you used this as the text model
18/42
@reach_vb
that would be fire - but I doubt you'd get as much benefit from this, model is a yapper
19/42
@victor_explore
[Quoted tweet]
DeepSeek today
https://video.twimg.com/ext_tw_video/1881340096995364864/pu/vid/avc1/720x720/yN45olzqLvBZt_f_.mp4
20/42
@reach_vb
hahaha, how do you create these, it's amazing!
21/42
@AILeaksAndNews
We are accelerating quickly
3.5 sonnet that can run locally
22/42
@reach_vb
maybe the 32B/ 70B is at that level, I doubt 1.5B will be at that level haha
23/42
@edwardcfrazer
How fast is it
24/42
@reach_vb
On their API it’s pretty fast!
25/42
@anushkmittal
1.5b? more like 1.5 based
26/42
@reach_vb
hahahaha!
27/42
@Yuchenj_UW
Unbelievable.
We will have super smart 1B models in the future, running locally on our phone.
28/42
@reach_vb
I call it Baby AGI
[Quoted tweet]
Try out R1 Distill Qwen 1.5B in a FREE Google Colab!
The vibes are looking gooood!
https://video.twimg.com/ext_tw_video/1881377422135676928/pu/vid/avc1/1670x1080/wUafm6PII4xXizvR.mp4
29/42
@dhruv2038
Yeah this is sus.
30/42
@reach_vb
gotta vibe check it ofc
31/42
@ftmoose
lol
32/42
@reach_vb
I love the way it thinks
33/42
@_ggLAB
yet cannot answer historical events.
34/42
@reach_vb
literally doesn't matter, as long as it works for your own use-cases.
35/42
@AntDX316
36/42
@nooriefyi
this is huge. parameter count is so last year.
37/42
@baileygspell
"few shot prompts degrade peformance" def overfit
38/42
@seo_leaders
Going to have to give that model a run up for sure
39/42
@priontific
I'm so psyched holy moly - I'm also super pumped, I think we can squeeze so much by speculative drafting w/ these tiny models. Results in a few hours once I've finished downloading -- stay tuned!!
40/42
@ionet
at first it seemed like humans being outperformed like that by AI, now AI doing the same to other AI
41/42
@joysectomy
Western cultures are bad at math, Eastern cultures teach math in a bottoms up way. Wonder how much of a factor that is in the consistent perf gap between these models
42/42
@ChaithanyaK42
This is awesome
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196





 scientist Yann LeCun addresses a speech as he attends the World Economic Forum (WEF) annual meeting in Davos on January 23, 2025.")





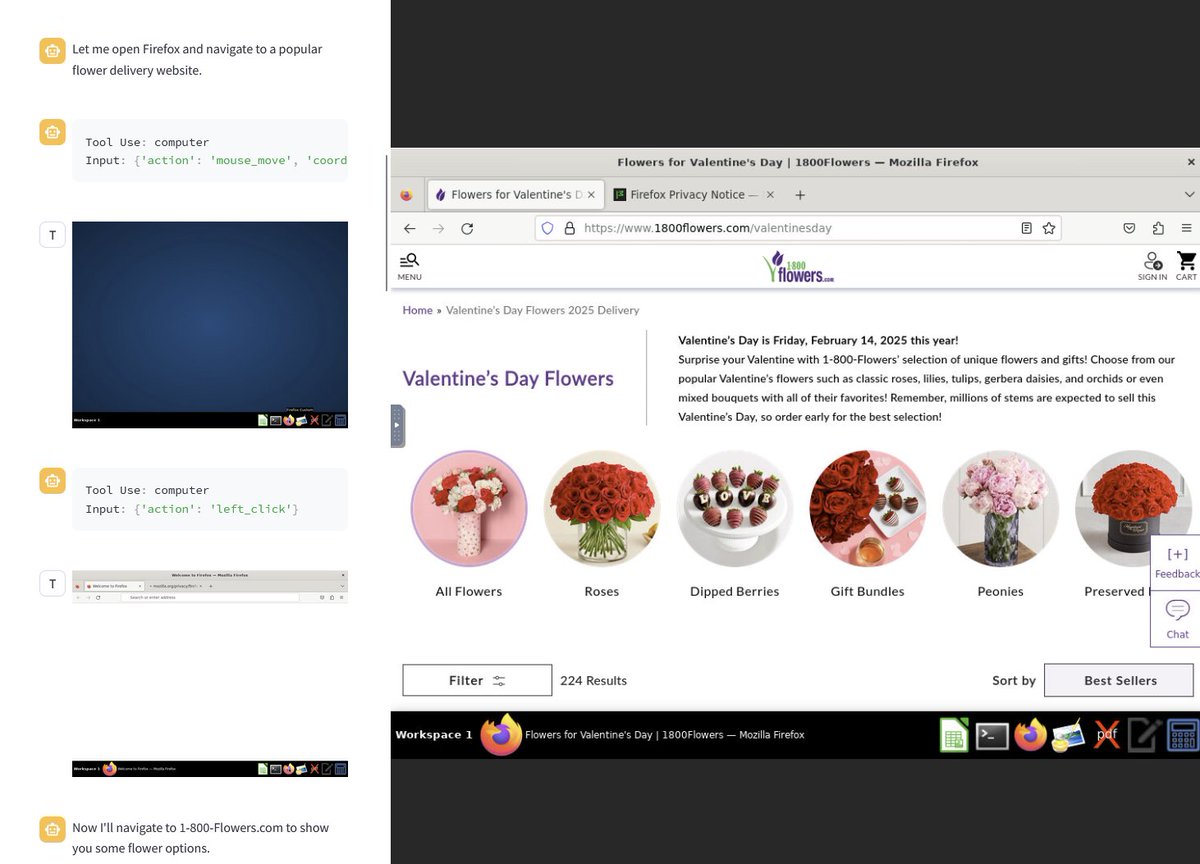
 Aaron Levie, CEO of Box, believes giving agents full browser access unlocks 100x more use cases.
Aaron Levie, CEO of Box, believes giving agents full browser access unlocks 100x more use cases.
 Use cases highlight Operator’s potential:
Use cases highlight Operator’s potential:




 Interesting insight from @emollick:
Interesting insight from @emollick:















 YouTube:
YouTube: 





