1/11
@synth_labs
Ever watched someone solve a hard math problem?
Their first attempt is rarely perfect. They sketch ideas, cross things out, and try new angles.
This process of exploration is key to human reasoning and our latest research formalizes this as Meta Chain-of-Thought
(1/8)

https://video.twimg.com/ext_tw_video/1879277172197838848/pu/vid/avc1/1080x1620/UV5F7QCG9DfLW3tJ.mp4
2/11
@synth_labs
In “Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Thought” we show that reasoning models—like @OpenAI o1—exhibit behavior resembling Meta-CoT, & propose a training pipeline to achieve similar capabilities
More details here:
Towards System 2 Reasoning in LLMs: Learning How To Think
3/11
@synth_labs
When a mathematician solves a problem, they don’t just do it in one straight go. They perform multiple trial and error stages, learning from prior mistakes. We call this true data-generating process behind how these problems are solved Meta-CoT.
Modern LLMs struggle with advanced reasoning problems because their training data consists of direct solutions, but not the actual process of how they were solved.

4/11
@synth_labs
We found that current advanced reasoning LLMs like o1 and Gemini Thinking exhibit this behavior of Meta CoT as in-context search. They explore and try different approaches to advanced problems before giving a final solution.

5/11
@synth_labs
We show how Meta-CoTs can be constructed synthetically via online search, and that teaching a model to produce Meta-CoTs is a meta-RL problem, since we are now teaching it how to approach solving a problem rather than just what to do.

6/11
@synth_labs
Towards the goal of training reasoning models, we have been collecting a “Big Math” dataset of 500k diverse, verifiable math problems and have been developing training infrastructure built on NeoX to support online RL with search
[Quoted tweet]
Open research on reasoning is bottlenecked on several critical fronts—which we're tackling head on
 Post-training infra: Distributed scalable online training, inference, search & RL infra built on @AiEleuther's GPT-NeoX
Post-training infra: Distributed scalable online training, inference, search & RL infra built on @AiEleuther's GPT-NeoX
"shooting for SOTA"—@rm_rafailov
Interested? DM me !
!
7/11
@synth_labs
This is an large, ongoing effort with a great team @synth_labs & collaborators doing open research
@rm_rafailov @sea_snell @gandhikanishk @Anikait_Singh_ @NathanThinks @ZiyuX @dmayhem93 @ChaseBlagden @jphilipp95 @lcastricato @PhungVanDuy1 @AlbalakAlon @nickhaber @chelseabfinn
8/11
@synth_labs
If you are interested in working or collaborating with us, reach out (links in blog post)
Arxiv PDF: https://arxiv.org/pdf/2501.04682
Blog post: Towards System 2 Reasoning in LLMs: Learning How To Think
9/11
@DeepwriterAI
in my experience, these reasoning models are currently good with CoT in the weeds and less so as you generalize at a bird's eye view whereas the more general models (non reasoning) handle larger contexts and can spread their attention more evenly over the whole for a bird's eyes view. Reasoning models follow a narrow path and lose the script with very large contexts.
In fact, they didn't even bother pretending with Gemini flash 2.0-thinking and it's context is limited under 50k tokens. o1 and o1 pro allow more, but they don't do as well with larger contexts that end up competing with reasoning tokens that also get added.
Therefore a general model still is better as the highest level orchestrator and the reasoning models are best when a specific hard problem needs to be solved that the general model passes it off to.
So does that make the general model orchestrator a "Meta-Meta Chain of Thought" agent?
10/11
@CryptosBandoo
Still waiting for your predictions 2025+?
11/11
@FutbolmeAI
Your analogy of solving math problems resonates with me, reminds me of debugging code . Can you elaborate on how Meta Chain-of-Thought formalizes this process?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@synth_labs
Ever watched someone solve a hard math problem?
Their first attempt is rarely perfect. They sketch ideas, cross things out, and try new angles.
This process of exploration is key to human reasoning and our latest research formalizes this as Meta Chain-of-Thought
(1/8)
https://video.twimg.com/ext_tw_video/1879277172197838848/pu/vid/avc1/1080x1620/UV5F7QCG9DfLW3tJ.mp4
2/11
@synth_labs
In “Towards System 2 Reasoning in LLMs: Learning How to Think With Meta Chain-of-Thought” we show that reasoning models—like @OpenAI o1—exhibit behavior resembling Meta-CoT, & propose a training pipeline to achieve similar capabilities
More details here:
Towards System 2 Reasoning in LLMs: Learning How To Think
3/11
@synth_labs
When a mathematician solves a problem, they don’t just do it in one straight go. They perform multiple trial and error stages, learning from prior mistakes. We call this true data-generating process behind how these problems are solved Meta-CoT.
Modern LLMs struggle with advanced reasoning problems because their training data consists of direct solutions, but not the actual process of how they were solved.
4/11
@synth_labs
We found that current advanced reasoning LLMs like o1 and Gemini Thinking exhibit this behavior of Meta CoT as in-context search. They explore and try different approaches to advanced problems before giving a final solution.
5/11
@synth_labs
We show how Meta-CoTs can be constructed synthetically via online search, and that teaching a model to produce Meta-CoTs is a meta-RL problem, since we are now teaching it how to approach solving a problem rather than just what to do.
6/11
@synth_labs
Towards the goal of training reasoning models, we have been collecting a “Big Math” dataset of 500k diverse, verifiable math problems and have been developing training infrastructure built on NeoX to support online RL with search
[Quoted tweet]
Open research on reasoning is bottlenecked on several critical fronts—which we're tackling head on
Post-training infra: Distributed scalable online training, inference, search & RL infra built on @AiEleuther's GPT-NeoX"shooting for SOTA"—@rm_rafailov
Interested? DM me
!7/11
@synth_labs
This is an large, ongoing effort with a great team @synth_labs & collaborators doing open research
@rm_rafailov @sea_snell @gandhikanishk @Anikait_Singh_ @NathanThinks @ZiyuX @dmayhem93 @ChaseBlagden @jphilipp95 @lcastricato @PhungVanDuy1 @AlbalakAlon @nickhaber @chelseabfinn
8/11
@synth_labs
If you are interested in working or collaborating with us, reach out (links in blog post)
Arxiv PDF: https://arxiv.org/pdf/2501.04682
Blog post: Towards System 2 Reasoning in LLMs: Learning How To Think
9/11
@DeepwriterAI
in my experience, these reasoning models are currently good with CoT in the weeds and less so as you generalize at a bird's eye view whereas the more general models (non reasoning) handle larger contexts and can spread their attention more evenly over the whole for a bird's eyes view. Reasoning models follow a narrow path and lose the script with very large contexts.
In fact, they didn't even bother pretending with Gemini flash 2.0-thinking and it's context is limited under 50k tokens. o1 and o1 pro allow more, but they don't do as well with larger contexts that end up competing with reasoning tokens that also get added.
Therefore a general model still is better as the highest level orchestrator and the reasoning models are best when a specific hard problem needs to be solved that the general model passes it off to.
So does that make the general model orchestrator a "Meta-Meta Chain of Thought" agent?
10/11
@CryptosBandoo
Still waiting for your predictions 2025+?
11/11
@FutbolmeAI
Your analogy of solving math problems resonates with me, reminds me of debugging code . Can you elaborate on how Meta Chain-of-Thought formalizes this process?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196


 。加入 AI/UI-Agents 知识星球 t.zsxq.com/1uB5s,及时了解最新讯息 #UI_Agent
。加入 AI/UI-Agents 知识星球 t.zsxq.com/1uB5s,及时了解最新讯息 #UI_Agent






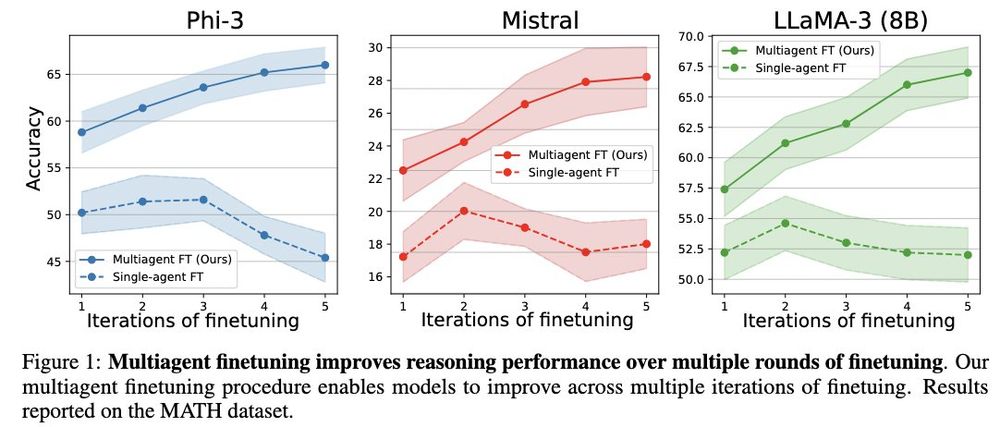
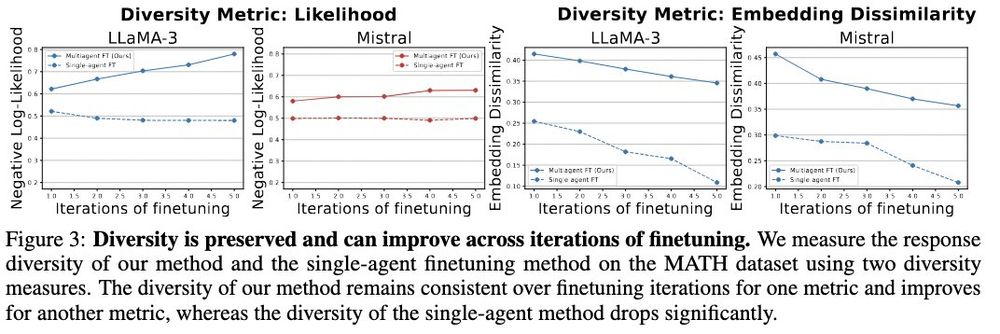
 Now most LLMs have >= 128K context sizes, but are they good at generating long outputs, such as writing 8K token chain-of-thought for a planning problem?
Now most LLMs have >= 128K context sizes, but are they good at generating long outputs, such as writing 8K token chain-of-thought for a planning problem? Introducing LongProc (Long Procedural Generation), a new benchmark with 6 diverse tasks that challenge LLMs to synthesize highly dispersed information and generate long, structured outputs.
Introducing LongProc (Long Procedural Generation), a new benchmark with 6 diverse tasks that challenge LLMs to synthesize highly dispersed information and generate long, structured outputs.







 Shout out to my amazing collaborators! @fangcong_y10593 @Gracie_huihui @JoieZhang @HowardYen1 @gaotianyu1350 @gregd_nlp @danqi_chen
Shout out to my amazing collaborators! @fangcong_y10593 @Gracie_huihui @JoieZhang @HowardYen1 @gaotianyu1350 @gregd_nlp @danqi_chen
 Terminal's Analysis:
Terminal's Analysis: Technical Approach:
Technical Approach: Impact & Applications:
Impact & Applications: Limitations & Future Work:
Limitations & Future Work: Technical Complexity: Advanced
Technical Complexity: Advanced Categories: Long-Context Language Models, Procedural Generation, Benchmarking, Natural Language Processing, Language Model Evaluation, Information Integration, Structured Output Generation
Categories: Long-Context Language Models, Procedural Generation, Benchmarking, Natural Language Processing, Language Model Evaluation, Information Integration, Structured Output Generation Related Fields: Natural Language Processing, Machine Learning, Artificial Intelligence
Related Fields: Natural Language Processing, Machine Learning, Artificial Intelligence









 Find Your Dream Voice with Hailuo Audio HD: A New Era in Voice Synthesis!
Find Your Dream Voice with Hailuo Audio HD: A New Era in Voice Synthesis! Limitless Voice Customization:
Limitless Voice Customization: Truly Authentic Language Expertise:
Truly Authentic Language Expertise: English (US, UK, Australia, India)
English (US, UK, Australia, India) Try It for FREE:
Try It for FREE: 




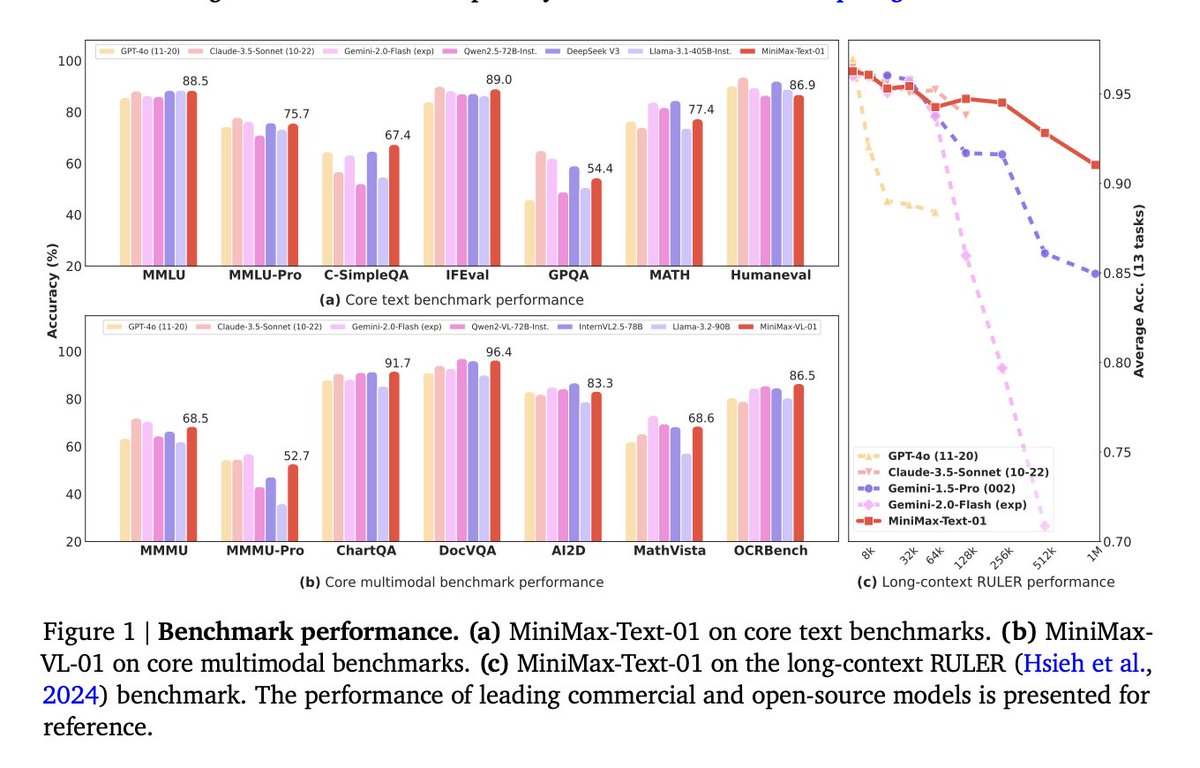
 Innovative Lightning Attention Architecture, with Top-tier Model Performance
Innovative Lightning Attention Architecture, with Top-tier Model Performance Unbeatable Cost-Effectiveness for Continuous Innovation
Unbeatable Cost-Effectiveness for Continuous Innovation Paper:
Paper: Read more:
Read more: 









 .
.
 𝙇𝙀𝙏'𝙎 𝘾𝙊𝙇𝙇𝘼𝘽𝙊𝙍𝘼𝙏𝙀
𝙇𝙀𝙏'𝙎 𝘾𝙊𝙇𝙇𝘼𝘽𝙊𝙍𝘼𝙏𝙀