1/15
@_philschmid
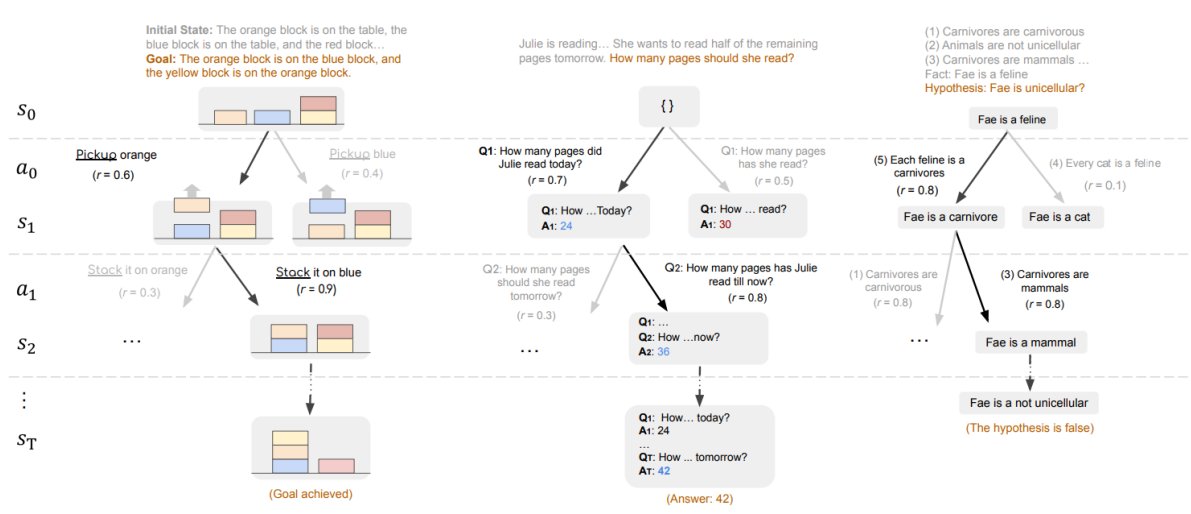
The RLHF method behind the best open models! Both @deepseek_ai and @Alibaba_Qwen use GRPO in post-training! Group Relative Policy Optimization. GRPO was introduced in the DeepSeekMath Paper last year to improve mathematical reasoning capabilities with less memory consumption, but is now used in an online way also to improve Truthfulness, Helpfulness, Conciseness…
Implementation
 Generate multiple outputs for each input question using the current Policy
Generate multiple outputs for each input question using the current Policy
 Score these outputs using a reward model
Score these outputs using a reward model
 Average the rewards and use it as a baseline to compute the advantages
Average the rewards and use it as a baseline to compute the advantages
 Update the Policy to maximize the GRPO objective, which includes the advantages and a KL term
Update the Policy to maximize the GRPO objective, which includes the advantages and a KL term
Insights
 Doesn't need value function model, reducing memory and complexity
Doesn't need value function model, reducing memory and complexity
 Adds KL term directly to the loss rather than in the reward
Adds KL term directly to the loss rather than in the reward
 Works with rule-based Reward Models and Generative/Score based RM
Works with rule-based Reward Models and Generative/Score based RM
 Looks similar to RLOO method
Looks similar to RLOO method
DS 3 improved coding, math, writing, role-playing, and question answering
 Soon in @huggingface TRL (PR open already)
Soon in @huggingface TRL (PR open already)

2/15
@_philschmid
Paper: Paper page - DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
3/15
@AI_Fun_times
Fascinating collaboration! Leveraging Group Relative Policy Optimization (GRPO) post-training to enhance mathematical reasoning in open models is a game-changer.
4/15
@AIVideoTech
Fascinating collaboration!
5/15
@EdwardKens50830
Exciting stuff, Philipp! GRPO sounds like a game-changer for AI efficiency. How do you see this impacting future AI developments in terms of scalability and real-world applications?
6/15
@adugbovictory
The transition from math-centric optimization to broader applications like truthfulness and role-playing is intriguing. What specific domains do you think GRPO could optimize next? Let's brainstorm!
7/15
@rayzhang123
GRPO's efficiency could reshape AI training costs.
8/15
@MaziyarPanahi
Would be lovely to have this in @huggingface trl and @axolotl_ai
9/15
@kevin_ai_gamer
GRPO seems like a game-changer for mathematical reasoning, how does it optimize policy updates?
10/15
@zzzzzzoo00oo
@readwise save thread
11/15
@yangyc666
GRPO's efficiency is key for scaling AI models.
12/15
@CohorteAI
GRPO's efficiency in improving LLM capabilities is groundbreaking. For a deeper dive into the techniques shaping open models like DeepSeek 3, check out: What Can Large Language Models Achieve? - Cohorte Projects.
13/15
@roninhahn

[Quoted tweet]
x.com/i/article/187524607059…
14/15
@Frank37004246
RLOO reference here: [2402.14740] Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
15/15
@Frank37004246
My understanding is that o1-3 however are probably using something more akin to PRM ? [2305.20050] Let's Verify Step by Step
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@_philschmid
The RLHF method behind the best open models! Both @deepseek_ai and @Alibaba_Qwen use GRPO in post-training! Group Relative Policy Optimization. GRPO was introduced in the DeepSeekMath Paper last year to improve mathematical reasoning capabilities with less memory consumption, but is now used in an online way also to improve Truthfulness, Helpfulness, Conciseness…
Implementation
Generate multiple outputs for each input question using the current Policy Score these outputs using a reward model Average the rewards and use it as a baseline to compute the advantages Update the Policy to maximize the GRPO objective, which includes the advantages and a KL termInsights
Doesn't need value function model, reducing memory and complexity Adds KL term directly to the loss rather than in the reward Works with rule-based Reward Models and Generative/Score based RM Looks similar to RLOO method DS 3 improved coding, math, writing, role-playing, and question answering Soon in @huggingface TRL (PR open already)
2/15
@_philschmid
Paper: Paper page - DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
3/15
@AI_Fun_times
Fascinating collaboration! Leveraging Group Relative Policy Optimization (GRPO) post-training to enhance mathematical reasoning in open models is a game-changer.
4/15
@AIVideoTech
Fascinating collaboration!
5/15
@EdwardKens50830
Exciting stuff, Philipp! GRPO sounds like a game-changer for AI efficiency. How do you see this impacting future AI developments in terms of scalability and real-world applications?
6/15
@adugbovictory
The transition from math-centric optimization to broader applications like truthfulness and role-playing is intriguing. What specific domains do you think GRPO could optimize next? Let's brainstorm!
7/15
@rayzhang123
GRPO's efficiency could reshape AI training costs.
8/15
@MaziyarPanahi
Would be lovely to have this in @huggingface trl and @axolotl_ai
9/15
@kevin_ai_gamer
GRPO seems like a game-changer for mathematical reasoning, how does it optimize policy updates?
10/15
@zzzzzzoo00oo
@readwise save thread
11/15
@yangyc666
GRPO's efficiency is key for scaling AI models.
12/15
@CohorteAI
GRPO's efficiency in improving LLM capabilities is groundbreaking. For a deeper dive into the techniques shaping open models like DeepSeek 3, check out: What Can Large Language Models Achieve? - Cohorte Projects.
13/15
@roninhahn
[Quoted tweet]
x.com/i/article/187524607059…
14/15
@Frank37004246
RLOO reference here: [2402.14740] Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
15/15
@Frank37004246
My understanding is that o1-3 however are probably using something more akin to PRM ? [2305.20050] Let's Verify Step by Step
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196



 EON-8B (based on Llama 3.1) is 75x cheaper than GPT-4, 6x cheaper than GPT-4o
EON-8B (based on Llama 3.1) is 75x cheaper than GPT-4, 6x cheaper than GPT-4o Outperforms GPT-4o mini by 4% and Llama-3 by 30% in matching accuracy
Outperforms GPT-4o mini by 4% and Llama-3 by 30% in matching accuracy Used RLHF and DPO for safety alignment
Used RLHF and DPO for safety alignment Trained on 200M tokens of high quality from LinkedIn's Economic Graph
Trained on 200M tokens of high quality from LinkedIn's Economic Graph Production environment built on Kubernetes with modular pipeline for model updates launched in October 2024
Production environment built on Kubernetes with modular pipeline for model updates launched in October 2024 Handles 90% of language model calls in the hiring workflow
Handles 90% of language model calls in the hiring workflow Preserved base model capabilities while adding domain expertise
Preserved base model capabilities while adding domain expertise Reduces prompt size by 30% through training
Reduces prompt size by 30% through training Built Agents to parse candidate profiles, resumes, recruiter notes, and job posts
Built Agents to parse candidate profiles, resumes, recruiter notes, and job posts Planning to expand into multi-modal and multi-lingual agent experiences
Planning to expand into multi-modal and multi-lingual agent experiences


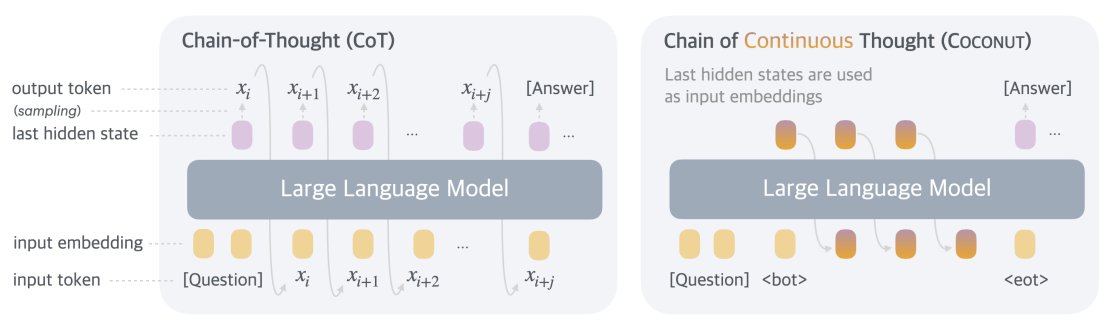
 The final continuous thought and <eot> are then used to generate the answer.
The final continuous thought and <eot> are then used to generate the answer. Inspired by iCoT gradually replaces language reasoning steps with continuous thoughts.
Inspired by iCoT gradually replaces language reasoning steps with continuous thoughts. Outperforms CoT in planning-heavy tasks like ProntoQA and ProsQA
Outperforms CoT in planning-heavy tasks like ProntoQA and ProsQA Generates significantly fewer tokens during inference compared to CoT
Generates significantly fewer tokens during inference compared to CoT Can perform breadth-first search (BFS) by encoding multiple alternative next steps simultaneously
Can perform breadth-first search (BFS) by encoding multiple alternative next steps simultaneously Gradually removing language steps with latent thoughts is required for good performance.
Gradually removing language steps with latent thoughts is required for good performance.
 Used offline reinforcement learning (DPO) on 150K training pairs focusing on complex tasks followed by merging with SFT models.
Used offline reinforcement learning (DPO) on 150K training pairs focusing on complex tasks followed by merging with SFT models. Applied online reinforcement learning (GRPO) using 72B reward model trained for truthfulness, helpfulness, and safety and sampling 8 responses
Applied online reinforcement learning (GRPO) using 72B reward model trained for truthfulness, helpfulness, and safety and sampling 8 responses Architecture: GQA, SwiGLU, RoPE, QKV bias in the attention and RMSNorm.
Architecture: GQA, SwiGLU, RoPE, QKV bias in the attention and RMSNorm. Used Qwen2-Instruct to classify and balance content across different domains
Used Qwen2-Instruct to classify and balance content across different domains DPO trained for 1 epoch on 150,000 examples with a LR of 7e-7
DPO trained for 1 epoch on 150,000 examples with a LR of 7e-7
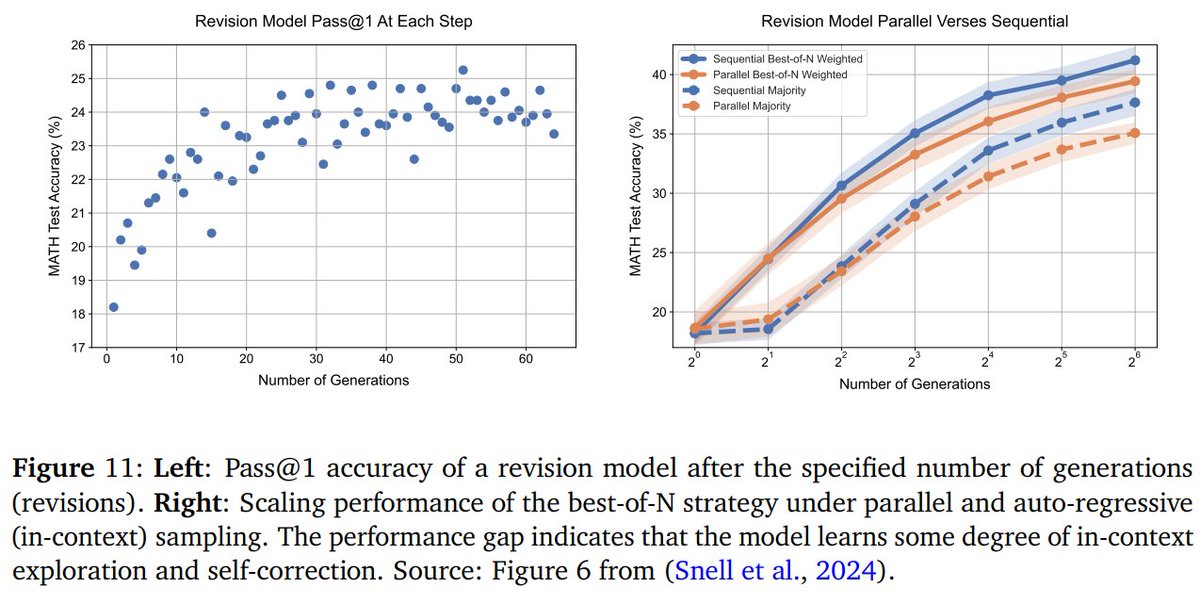
 5 samples + DeepSeek-Coder outperformed zero-shot GPT-4 at 1/3 the cost
5 samples + DeepSeek-Coder outperformed zero-shot GPT-4 at 1/3 the cost Verification methods (voting, reward models) plateau after ~100 samples
Verification methods (voting, reward models) plateau after ~100 samples Need clear criteria for what makes a "good" generation
Need clear criteria for what makes a "good" generation
 below!
below!