
1/14
@reach_vb
MIT licensed Phi 4 running 100% locally on @lmstudio with GGUF straight from the Hugging Face Hub!
Not your weights not your brain!
lms get phi-4 is all you need!
[Quoted tweet]
Chat, MIT licensed Phi 4 is here, how are the vibes?
huggingface.co/microsoft/phi…
https://video.twimg.com/ext_tw_video/1877078224720572416/pu/vid/avc1/1112x720/yVQDirpt3bu-Z5xX.mp4
2/14
@reach_vb
Model weights:
lmstudio-community/phi-4-GGUF · Hugging Face
3/14
@alamshafil
How does it compare to llama3.2?
(I’m new to this stuff, so not sure how accurately it can be compared)
4/14
@reach_vb
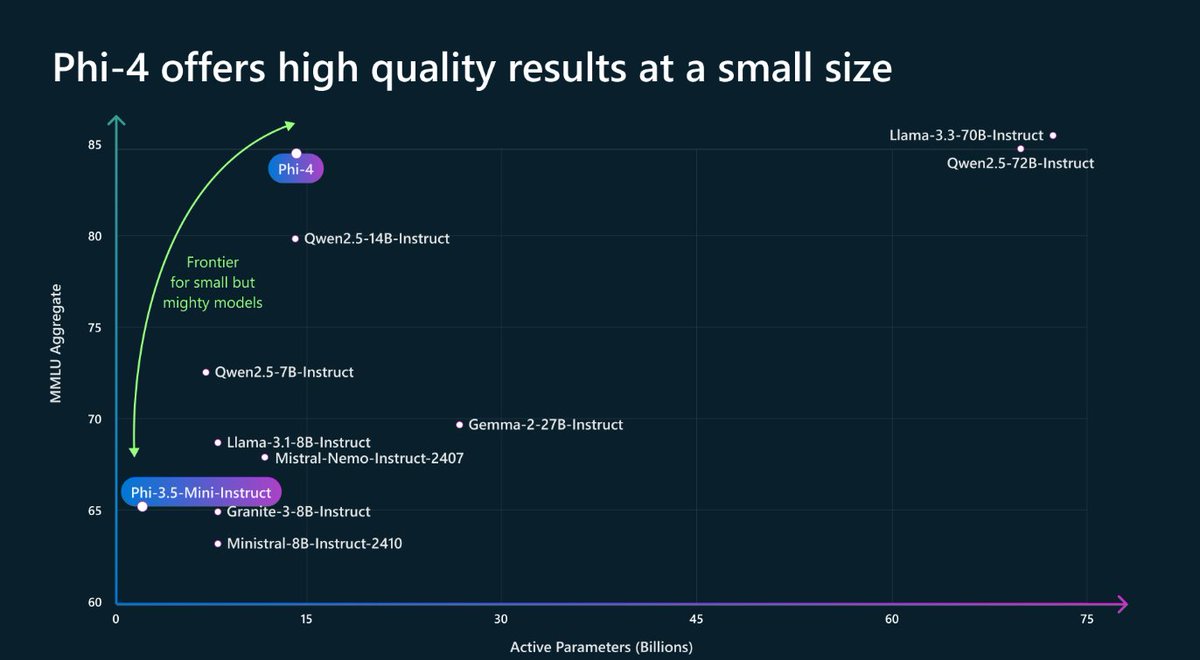
On paper it even beats Qwen 2.5 (which is much better) - need to vibe check it more.
5/14
@carsenklock
Phi-4 is
6/14
@heyitsyorkie
LM Studio is the cleanest UI
7/14
@ivanfioravanti
So far so good(mega) good for me! This model rocks!
8/14
@gg1994bharat
For my office we are using for text context analysis and removing un wanted text we are using llama 3.3 70b model .. will this will help ?
9/14
@lmstudio
It might: sounds like a perfect opportunity to test this model and see if you see good results
10/14
@dhruv2038
ahh great!
11/14
@muktabh
VRAM requirement ?
12/14
@lifeafterAi_
Qwen 3 Will be
[Quoted tweet]
Qwen 3 14b will be insane even qwen3 7b
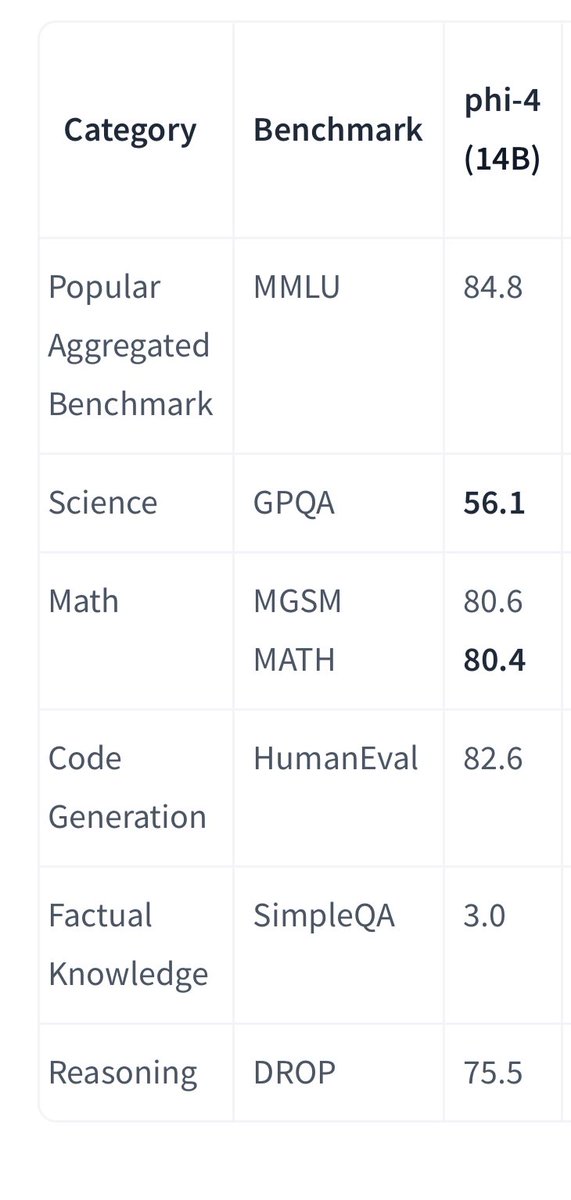
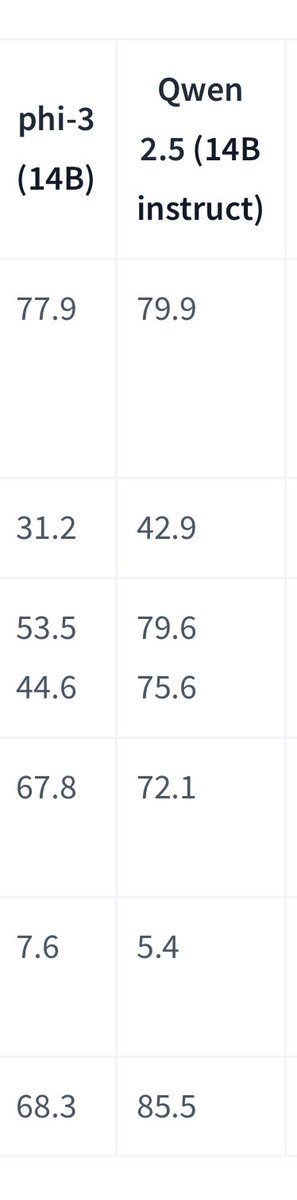
13/14
@LIama002
What do u use to graphically display powermetrics?
14/14
@AI_Fun_times
Exciting to see Phi 4 in action with LMStudio! Leveraging the power of Hugging Face Hub and MIT licensing is a wise move. Have you dived into fine-tuning with GGUF yet?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@reach_vb
MIT licensed Phi 4 running 100% locally on @lmstudio with GGUF straight from the Hugging Face Hub!
Not your weights not your brain!
lms get phi-4 is all you need!
[Quoted tweet]
Chat, MIT licensed Phi 4 is here, how are the vibes?
huggingface.co/microsoft/phi…
https://video.twimg.com/ext_tw_video/1877078224720572416/pu/vid/avc1/1112x720/yVQDirpt3bu-Z5xX.mp4
2/14
@reach_vb
Model weights:
lmstudio-community/phi-4-GGUF · Hugging Face
3/14
@alamshafil
How does it compare to llama3.2?
(I’m new to this stuff, so not sure how accurately it can be compared)
4/14
@reach_vb
On paper it even beats Qwen 2.5 (which is much better) - need to vibe check it more.
5/14
@carsenklock
Phi-4 is
6/14
@heyitsyorkie
LM Studio is the cleanest UI
7/14
@ivanfioravanti
So far so good(mega) good for me! This model rocks!
8/14
@gg1994bharat
For my office we are using for text context analysis and removing un wanted text we are using llama 3.3 70b model .. will this will help ?
9/14
@lmstudio
It might: sounds like a perfect opportunity to test this model and see if you see good results
10/14
@dhruv2038
ahh great!
11/14
@muktabh
VRAM requirement ?
12/14
@lifeafterAi_
Qwen 3 Will be
[Quoted tweet]
Qwen 3 14b will be insane
even qwen3 7b
13/14
@LIama002
What do u use to graphically display powermetrics?
14/14
@AI_Fun_times
Exciting to see Phi 4 in action with LMStudio! Leveraging the power of Hugging Face Hub and MIT licensing is a wise move. Have you dived into fine-tuning with GGUF yet?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/14
@reach_vb
Chat, MIT licensed Phi 4 is here, how are the vibes?
microsoft/phi-4 · Hugging Face
2/14
@yabooki
Thanks, but how to use it with Ollama ?
3/14
@reach_vb
ollama run hf. co/reach-vb/phi-4-Q4_K_M-GGUF
4/14
@lalopenguin
lets....... GOO!!!!!
5/14
@a_void_sky
there must be a reason that @OpenAI leads the Math benchmark every time
6/14
@mkurman88
Great news it finally comes to the public!
7/14
@AILeaksAndNews
MIT license is big
8/14
@ArpinGarre66002
Mid
9/14
@CEOofFuggy
@ollama

10/14
@ollama
ollama run phi4
let's go!
11/14
@MillenniumTwain
Public Sector 'AI' is already more than Two Decades behind Private/Covert sector << AGI >>, and all our Big Tech Fraudsters are doing is accelerating the Dumb-Down of our Victim, Slave, Consumer US Public, and World!
[Quoted tweet]
"Still be Hidden behind Closed Doors"? Thanks to these Covert Actors (Microsoft, OpenAI, the NSA, ad Infinitum) — More and More is Being Hidden behind Closed Doors every day! The ONLY 'forward' motion being their exponentially-accelerated Big Tech/Wall Street HYPE, Fraud, DisInfo ...

12/14
@allan_d_clive
finally.....
13/14
@agichronicles
No function calling
14/14
@bertaunth
currently waiting for the LiveBench benchmarks to drop
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@reach_vb
Chat, MIT licensed Phi 4 is here, how are the vibes?
microsoft/phi-4 · Hugging Face
2/14
@yabooki
Thanks, but how to use it with Ollama ?
3/14
@reach_vb
ollama run hf. co/reach-vb/phi-4-Q4_K_M-GGUF
4/14
@lalopenguin
lets....... GOO!!!!!
5/14
@a_void_sky
there must be a reason that @OpenAI leads the Math benchmark every time
6/14
@mkurman88
Great news it finally comes to the public!
7/14
@AILeaksAndNews
MIT license is big
8/14
@ArpinGarre66002
Mid
9/14
@CEOofFuggy
@ollama
10/14
@ollama
ollama run phi4
let's go!
11/14
@MillenniumTwain
Public Sector 'AI' is already more than Two Decades behind Private/Covert sector << AGI >>, and all our Big Tech Fraudsters are doing is accelerating the Dumb-Down of our Victim, Slave, Consumer US Public, and World!
[Quoted tweet]
"Still be Hidden behind Closed Doors"? Thanks to these Covert Actors (Microsoft, OpenAI, the NSA, ad Infinitum) — More and More is Being Hidden behind Closed Doors every day! The ONLY 'forward' motion being their exponentially-accelerated Big Tech/Wall Street HYPE, Fraud, DisInfo ...
12/14
@allan_d_clive
finally.....
13/14
@agichronicles
No function calling
14/14
@bertaunth
currently waiting for the LiveBench benchmarks to drop
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/11
@rasbt
The model weights of Microsoft’s phi-4 14B LLM are now finally publicly available. Thanks to a kind community contribution, it’s now also available in LitGPT already (litgpt finetune microsoft/phi-4): phi-4 by ysjprojects · Pull Request #1904 · Lightning-AI/litgpt
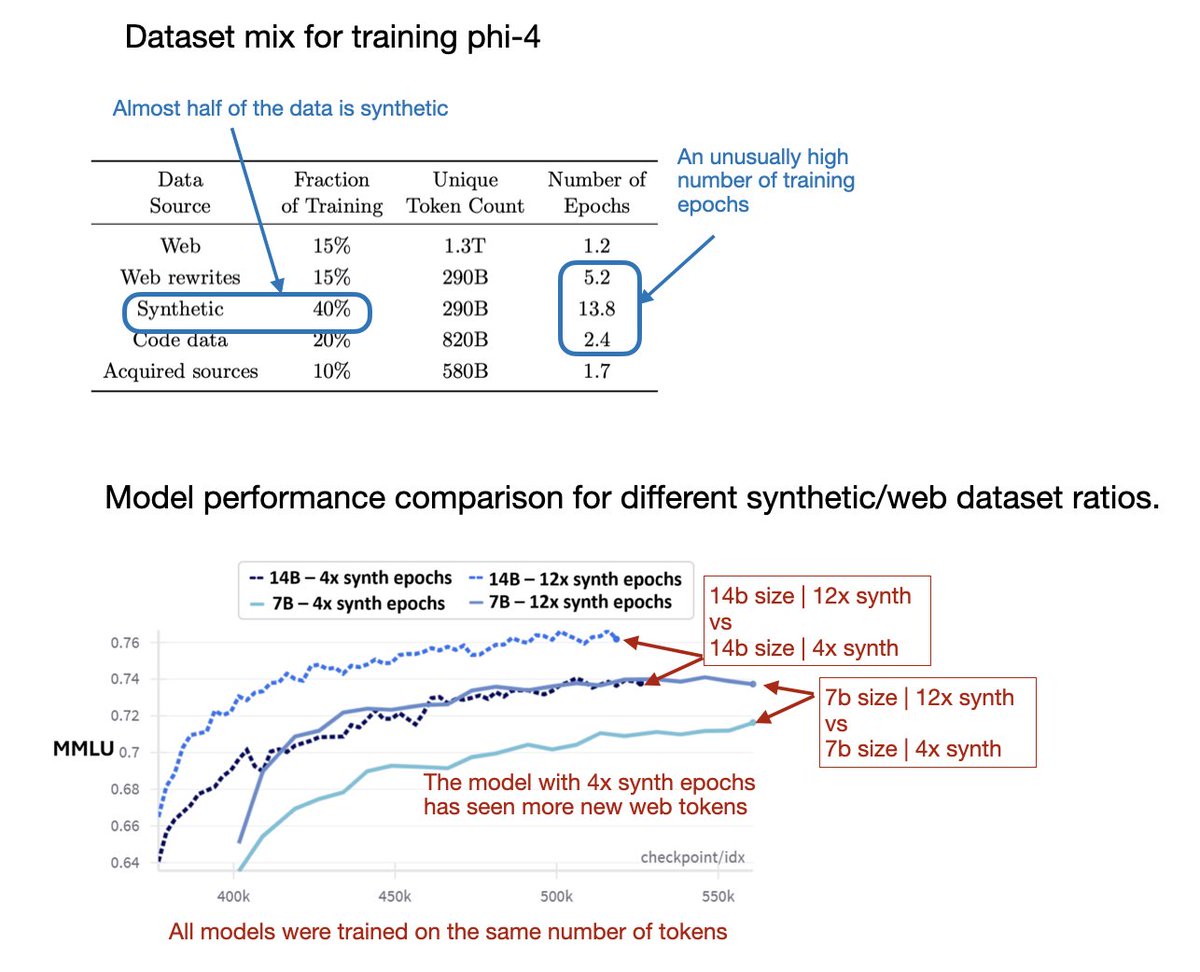
I will have more to say about phi-4 in my upcoming AI Research Review 2024 Part 2 article. The paper ([2412.08905] Phi-4 Technical Report) has a lot of interesting insights into synthetic data for pretraining. E.g., what’s interesting about phi-4 is that the training data consisted of 40% synthetic data. And the researchers observed that while synthetic data is generally beneficial, models trained exclusively on synthetic data performed poorly on knowledge-based benchmarks. To me, this raises the question: does synthetic data lack sufficient knowledge-specific information, or does it include a higher proportion of factual errors, such as those caused by hallucinations?
At the same time, the researchers found that increasing the number of training epochs on synthetic data boosted the performance more than just adding more web data, as shown in the figure below.
In any case, I will expand on this discussion soon in my “Noteworthy AI Research Papers of 2024 (Part Two)” article. Stay tuned!
2/11
@billynewport
Is it true to say that the benefit of synthetic data is in COT style training materiel to improve reasoning or test time compute rather than learning knowledge per se? It seems so far most LLMS are rote learning facts/knowledge through data but this makes reasoning hard because thats now what they trained on.
3/11
@rasbt
Yes. I think the main benefit is that it comes in a more structured or refined format compared to raw data. But the knowledge is the same as in the raw data (and may even be more hallucinated), considering that raw data was used to generate the synthetic data through a model.
4/11
@Dayder111
Maybe synthetic data hallucinates away facts that are supposed to be precise, but also it helps to generalize better and understand better connections between things?
Like, you can be generally smart, but not dedicate your neurons to remembering specific facts that much, only
5/11
@rasbt
Yeah, I think the main advantage is from the more refined nature of the synthetic data when it comes to response structure etc. Synthetic data can't really contain knowledge that raw data doesn't already include because the raw data was used to come up with the synthetic data in the first place.
6/11
@arnitly
What would you say are the best practices to ensure while creating synthetic data. How do you ensure model does not hallucinate a lot aside from setting the temperature setting to zero?
7/11
@rasbt
Since the model can't really explicitly distinguish between synthetic and non-synthetic data during training, the best way would tackle the problem at the root: ensuring that the synthetic data-generating model does not produce hallucinated contents.
8/11
@Yuchenj_UW
Interesting, getting more synthetic data seems to be the way
9/11
@rasbt
Yeah, I see it as some flavor of transfer learning (i.e., not starting from raw data). Synthetic data generated by a high-quality model (such as GPT-4o, which has already undergone extensive refinement) may serve as a kind of jumpstart to the model you are trying to train.
10/11
@yisustalone
Cool, looking forward for your analysis
11/11
@elbouzzz
Holy shyt i'm just here to say he's back!! Hallelujah!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@rasbt
The model weights of Microsoft’s phi-4 14B LLM are now finally publicly available. Thanks to a kind community contribution, it’s now also available in LitGPT already (litgpt finetune microsoft/phi-4): phi-4 by ysjprojects · Pull Request #1904 · Lightning-AI/litgpt
I will have more to say about phi-4 in my upcoming AI Research Review 2024 Part 2 article. The paper ([2412.08905] Phi-4 Technical Report) has a lot of interesting insights into synthetic data for pretraining. E.g., what’s interesting about phi-4 is that the training data consisted of 40% synthetic data. And the researchers observed that while synthetic data is generally beneficial, models trained exclusively on synthetic data performed poorly on knowledge-based benchmarks. To me, this raises the question: does synthetic data lack sufficient knowledge-specific information, or does it include a higher proportion of factual errors, such as those caused by hallucinations?
At the same time, the researchers found that increasing the number of training epochs on synthetic data boosted the performance more than just adding more web data, as shown in the figure below.
In any case, I will expand on this discussion soon in my “Noteworthy AI Research Papers of 2024 (Part Two)” article. Stay tuned!
2/11
@billynewport
Is it true to say that the benefit of synthetic data is in COT style training materiel to improve reasoning or test time compute rather than learning knowledge per se? It seems so far most LLMS are rote learning facts/knowledge through data but this makes reasoning hard because thats now what they trained on.
3/11
@rasbt
Yes. I think the main benefit is that it comes in a more structured or refined format compared to raw data. But the knowledge is the same as in the raw data (and may even be more hallucinated), considering that raw data was used to generate the synthetic data through a model.
4/11
@Dayder111
Maybe synthetic data hallucinates away facts that are supposed to be precise, but also it helps to generalize better and understand better connections between things?
Like, you can be generally smart, but not dedicate your neurons to remembering specific facts that much, only
5/11
@rasbt
Yeah, I think the main advantage is from the more refined nature of the synthetic data when it comes to response structure etc. Synthetic data can't really contain knowledge that raw data doesn't already include because the raw data was used to come up with the synthetic data in the first place.
6/11
@arnitly
What would you say are the best practices to ensure while creating synthetic data. How do you ensure model does not hallucinate a lot aside from setting the temperature setting to zero?
7/11
@rasbt
Since the model can't really explicitly distinguish between synthetic and non-synthetic data during training, the best way would tackle the problem at the root: ensuring that the synthetic data-generating model does not produce hallucinated contents.
8/11
@Yuchenj_UW
Interesting, getting more synthetic data seems to be the way
9/11
@rasbt
Yeah, I see it as some flavor of transfer learning (i.e., not starting from raw data). Synthetic data generated by a high-quality model (such as GPT-4o, which has already undergone extensive refinement) may serve as a kind of jumpstart to the model you are trying to train.
10/11
@yisustalone
Cool, looking forward for your analysis
11/11
@elbouzzz
Holy shyt i'm just here to say he's back!! Hallelujah!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/15
@EHuanglu
Microsoft has released Phi-4
a 14 billion parameter language model, under the MIT license on Hugging Face.
fully open sourced
2/15
@EHuanglu
Huggingface link:
microsoft/phi-4 · Hugging Face
3/15
@artificialbudhi
Huge!
4/15
@twizshaq
W
5/15
@RuneX_ai
Is it available on Azure? Can you compare is with llama? On premise solution?
6/15
@rethynkai
14b is an ideal number parameter.
7/15
@oscarle_x
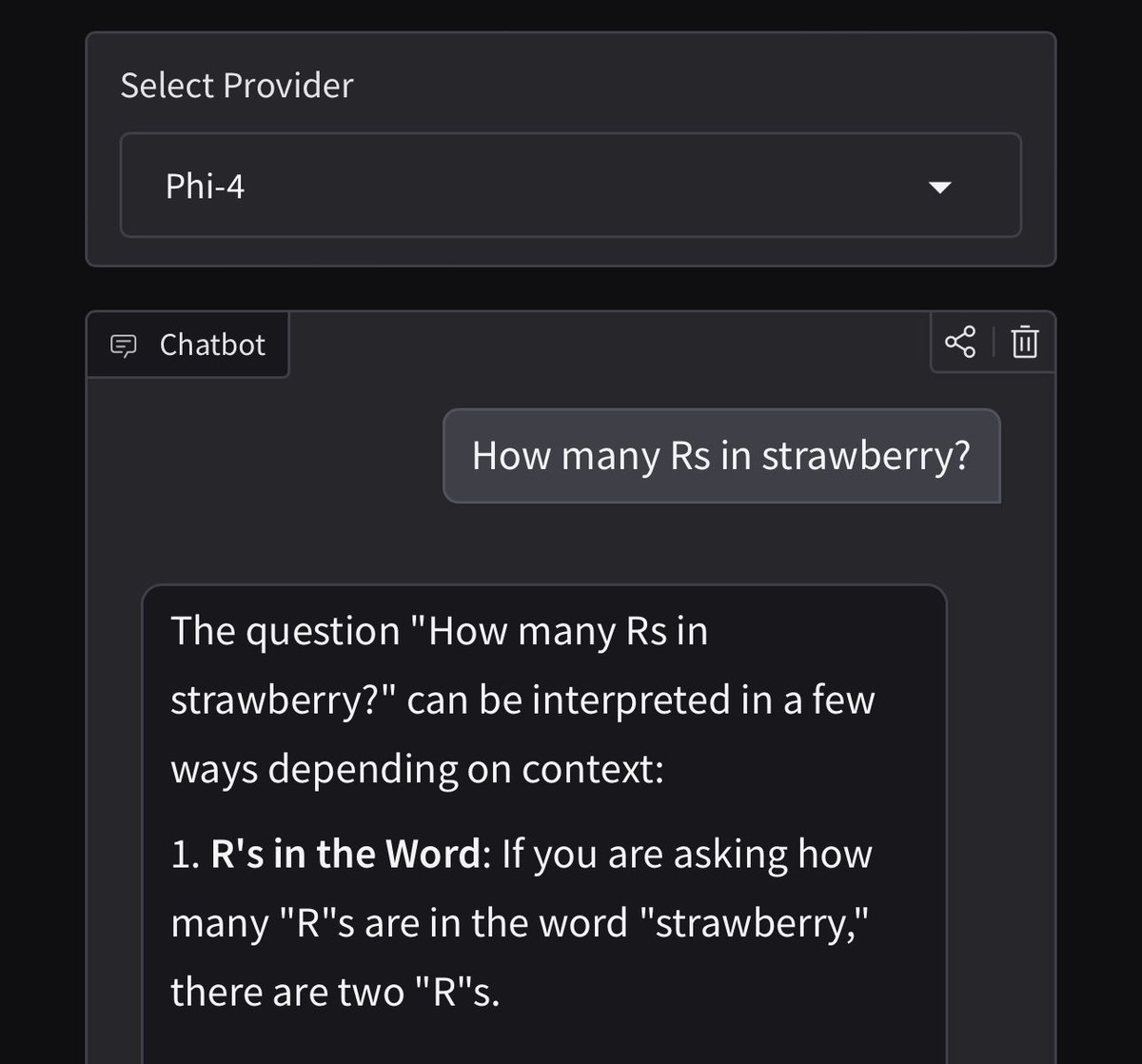
Anyone tested yet if Phi-4 is anywhere near Qwen 2.5 72B as they claimed? Thanks
8/15
@Gdgtify
I remember the announcement from a while back. I am glad it is finally on HuggingFace
[Quoted tweet]
 Phi-4 is here! A small language model that performs as well as (and often better than) large models on certain types of complex reasoning tasks such as math. Useful for us in @MSFTResearch, and available now for all researcher on the Azure AI Foundry! aka.ms/phi4blog
Phi-4 is here! A small language model that performs as well as (and often better than) large models on certain types of complex reasoning tasks such as math. Useful for us in @MSFTResearch, and available now for all researcher on the Azure AI Foundry! aka.ms/phi4blog
9/15
@vagasframe
10/15
@SentientAtom
Can this be run offline with a NVidoa compute unit?
11/15
@simonkp
It's great to see Phi-4 released under the MIT license; this should really boost open-source AI development. I'm curious to see how it stacks up against models like Qwen. It is definitely good news that it's on Hugging Face.
12/15
@boringsidequest
Their models seems to be poorly trained on languages other than English, so I'm not expecting much
13/15
@Catalina5803_
[Quoted tweet]
darkreading.com/application-…
14/15
@Jayy23P92624
15/15
@0xargumint
Nice to see Microsoft finally letting one out of the cage. Though at 14B params it's more like releasing a kitten than a lion. Still, better than another walled garden.
@EHuanglu
Microsoft has released Phi-4
a 14 billion parameter language model, under the MIT license on Hugging Face.
fully open sourced
2/15
@EHuanglu
Huggingface link:
microsoft/phi-4 · Hugging Face
3/15
@artificialbudhi
Huge!
4/15
@twizshaq
W
5/15
@RuneX_ai
Is it available on Azure? Can you compare is with llama? On premise solution?
6/15
@rethynkai
14b is an ideal number parameter.
7/15
@oscarle_x
Anyone tested yet if Phi-4 is anywhere near Qwen 2.5 72B as they claimed? Thanks
8/15
@Gdgtify
I remember the announcement from a while back. I am glad it is finally on HuggingFace
[Quoted tweet]
Phi-4 is here! A small language model that performs as well as (and often better than) large models on certain types of complex reasoning tasks such as math. Useful for us in @MSFTResearch, and available now for all researcher on the Azure AI Foundry! aka.ms/phi4blog
9/15
@vagasframe
10/15
@SentientAtom
Can this be run offline with a NVidoa compute unit?
11/15
@simonkp
It's great to see Phi-4 released under the MIT license; this should really boost open-source AI development. I'm curious to see how it stacks up against models like Qwen. It is definitely good news that it's on Hugging Face.
12/15
@boringsidequest
Their models seems to be poorly trained on languages other than English, so I'm not expecting much
13/15
@Catalina5803_
[Quoted tweet]
darkreading.com/application-…
14/15
@Jayy23P92624
15/15
@0xargumint
Nice to see Microsoft finally letting one out of the cage. Though at 14B params it's more like releasing a kitten than a lion. Still, better than another walled garden.
1/3
@_akhaliq
Phi-4 is now available in anychat
Try it out
2/3
@_akhaliq
App: Anychat - a Hugging Face Space by akhaliq
3/3
@rogue_node
Avoid anything microsoft
@_akhaliq
Phi-4 is now available in anychat
Try it out
2/3
@_akhaliq
App: Anychat - a Hugging Face Space by akhaliq
3/3
@rogue_node
Avoid anything microsoft



 by TJ-Solergibert · Pull Request #255 · huggingface/nanotron
by TJ-Solergibert · Pull Request #255 · huggingface/nanotron





















 - Whisper v4 wen?
- Whisper v4 wen?












 No Critic Network: Unlike PPO, REINFORCE++ removes the need for a separate value function, reducing compute and memory usage.
No Critic Network: Unlike PPO, REINFORCE++ removes the need for a separate value function, reducing compute and memory usage. Token-Level KL Penalty: Compared to standard REINFORCE or RLOO, REINFORCE++ applies a penalty at each token step, curbing undesired divergence more granularly.
Token-Level KL Penalty: Compared to standard REINFORCE or RLOO, REINFORCE++ applies a penalty at each token step, curbing undesired divergence more granularly. PPO-Style Clipping Minus Complexity: REINFORCE++ keeps the ratio clipping from PPO for stable updates, but avoids the added overhead of maintaining a critic.
PPO-Style Clipping Minus Complexity: REINFORCE++ keeps the ratio clipping from PPO for stable updates, but avoids the added overhead of maintaining a critic. Smoother Training: Using mini-batch advantage normalization and reward clipping stabilizes gradient updates more effectively than traditional REINFORCE.
Smoother Training: Using mini-batch advantage normalization and reward clipping stabilizes gradient updates more effectively than traditional REINFORCE. Eliminates critic network (value function) while maintaining PPO's stability benefits
Eliminates critic network (value function) while maintaining PPO's stability benefits Uses token-level KL penalties to prevent reward/length hacking
Uses token-level KL penalties to prevent reward/length hacking PPO-Style Clipping for stable updates without large parameter shifts.
PPO-Style Clipping for stable updates without large parameter shifts. Reduces training time by 30% compared to PPO (42 vs 60 hours on H100)
Reduces training time by 30% compared to PPO (42 vs 60 hours on H100) Achieves comparable or better performance than GRPO (Qwen, Deepseek) in math reasoning
Achieves comparable or better performance than GRPO (Qwen, Deepseek) in math reasoning Better reward increase per unit KL divergence in math scenarios.
Better reward increase per unit KL divergence in math scenarios. Tested on both general domain (OpenRLHF/prompt-collection-v0.1, OpenRLHF/preference_700K) and specialized mathematics datasets (meta-math/MetaMathQA).
Tested on both general domain (OpenRLHF/prompt-collection-v0.1, OpenRLHF/preference_700K) and specialized mathematics datasets (meta-math/MetaMathQA).

 Implements ranking consistency filtering to remove noisy and false negative samples
Implements ranking consistency filtering to remove noisy and false negative samples Strong multilingual performance outperforms other open models
Strong multilingual performance outperforms other open models