

Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku
A refreshed, more powerful Claude 3.5 Sonnet, Claude 3.5 Haiku, and a new experimental AI capability: computer use.
Introducing computer use, a new Claude 3.5 Sonnet, and Claude 3.5 Haiku
Oct 22, 2024●5 min read

Today, we’re announcing an upgraded Claude 3.5 Sonnet, and a new model, Claude 3.5 Haiku. The upgraded Claude 3.5 Sonnet delivers across-the-board improvements over its predecessor, with particularly significant gains in coding—an area where it already led the field. Claude 3.5 Haiku matches the performance of Claude 3 Opus, our prior largest model, on many evaluations for the same cost and similar speed to the previous generation of Haiku.
We’re also introducing a groundbreaking new capability in public beta: computer use. Available today on the API, developers can direct Claude to use computers the way people do—by looking at a screen, moving a cursor, clicking buttons, and typing text. Claude 3.5 Sonnet is the first frontier AI model to offer computer use in public beta. At this stage, it is still experimental—at times cumbersome and error-prone. We're releasing computer use early for feedback from developers, and expect the capability to improve rapidly over time.
Asana, Canva, Cognition, DoorDash, Replit, and The Browser Company have already begun to explore these possibilities, carrying out tasks that require dozens, and sometimes even hundreds, of steps to complete. For example, Replit is using Claude 3.5 Sonnet's capabilities with computer use and UI navigation to develop a key feature that evaluates apps as they’re being built for their Replit Agent product.
The upgraded Claude 3.5 Sonnet is now available for all users. Starting today, developers can build with the computer use beta on the Anthropic API, Amazon Bedrock, and Google Cloud’s Vertex AI. The new Claude 3.5 Haiku will be released later this month.
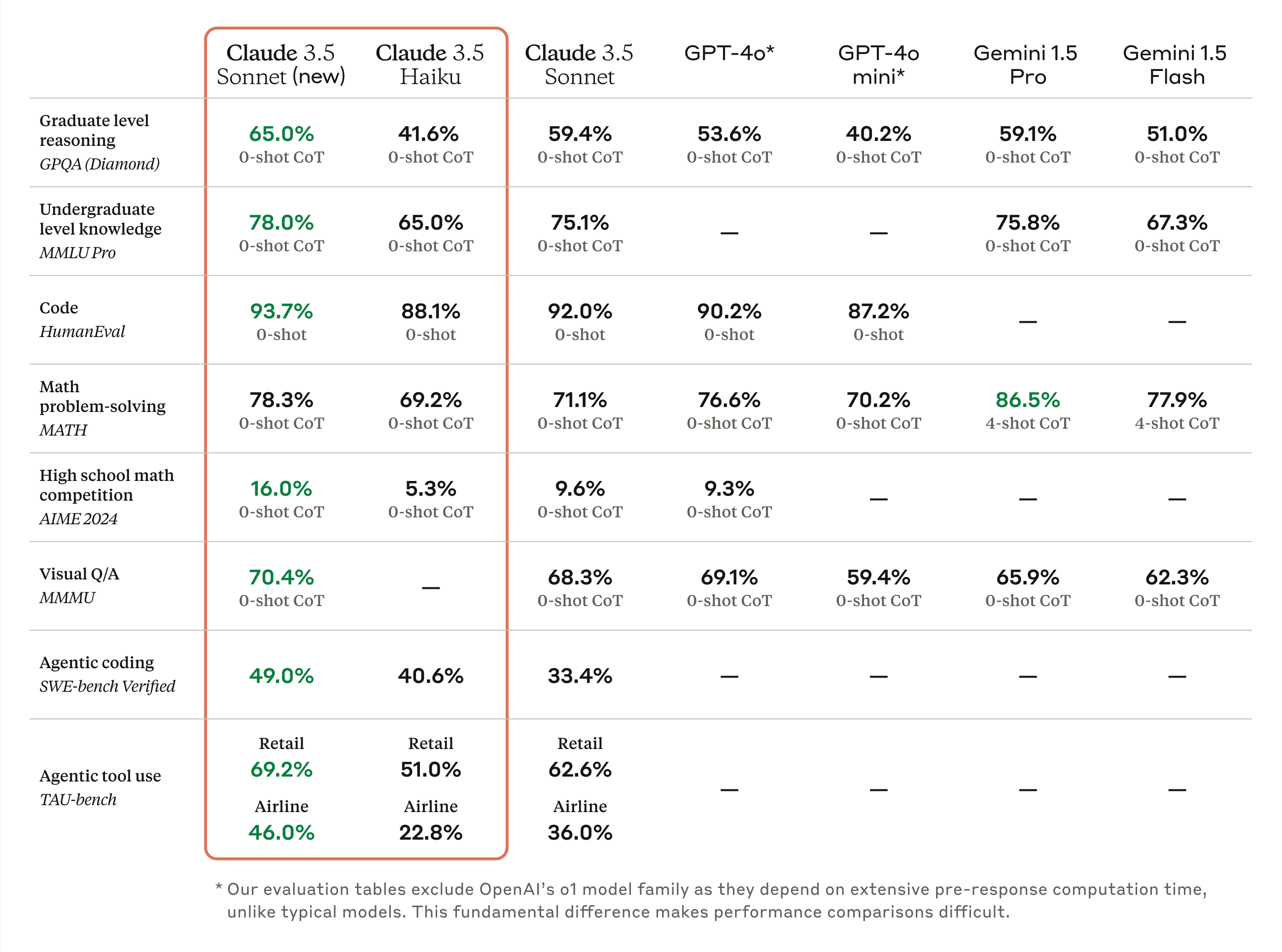
Claude 3.5 Sonnet: Industry-leading software engineering skills
The updated Claude 3.5 Sonnet shows wide-ranging improvements on industry benchmarks, with particularly strong gains in agentic coding and tool use tasks. On coding, it improves performance on SWE-bench Verified from 33.4% to 49.0%, scoring higher than all publicly available models—including reasoning models like OpenAI o1-preview and specialized systems designed for agentic coding. It also improves performance on TAU-bench, an agentic tool use task, from 62.6% to 69.2% in the retail domain, and from 36.0% to 46.0% in the more challenging airline domain. The new Claude 3.5 Sonnet offers these advancements at the same price and speed as its predecessor.
Early customer feedback suggests the upgraded Claude 3.5 Sonnet represents a significant leap for AI-powered coding. GitLab, which tested the model for DevSecOps tasks, found it delivered stronger reasoning (up to 10% across use cases) with no added latency, making it an ideal choice to power multi-step software development processes. Cognition uses the new Claude 3.5 Sonnet for autonomous AI evaluations, and experienced substantial improvements in coding, planning, and problem-solving compared to the previous version. The Browser Company, in using the model for automating web-based workflows, noted Claude 3.5 Sonnet outperformed every model they’ve tested before.
As part of our continued effort to partner with external experts, joint pre-deployment testing of the new Claude 3.5 Sonnet model was conducted by the US AI Safety Institute (US AISI) and the UK Safety Institute (UK AISI).
We also evaluated the upgraded Claude 3.5 Sonnet for catastrophic risks and found that the ASL-2 Standard, as outlined in our Responsible Scaling Policy, remains appropriate for this model.
Claude 3.5 Haiku: State-of-the-art meets affordability and speed
Claude 3.5 Haiku is the next generation of our fastest model. For the same cost and similar speed to Claude 3 Haiku, Claude 3.5 Haiku improves across every skill set and surpasses even Claude 3 Opus, the largest model in our previous generation, on many intelligence benchmarks. Claude 3.5 Haiku is particularly strong on coding tasks. For example, it scores 40.6% on SWE-bench Verified, outperforming many agents using publicly available state-of-the-art models—including the original Claude 3.5 Sonnet and GPT-4o.
With low latency, improved instruction following, and more accurate tool use, Claude 3.5 Haiku is well suited for user-facing products, specialized sub-agent tasks, and generating personalized experiences from huge volumes of data—like purchase history, pricing, or inventory records.
Claude 3.5 Haiku will be made available later this month across our first-party API, Amazon Bedrock, and Google Cloud’s Vertex AI—initially as a text-only model and with image input to follow.
Teaching Claude to navigate computers, responsibly
With computer use, we're trying something fundamentally new. Instead of making specific tools to help Claude complete individual tasks, we're teaching it general computer skills—allowing it to use a wide range of standard tools and software programs designed for people. Developers can use this nascent capability to automate repetitive processes, build and test software, and conduct open-ended tasks like research.
To make these general skills possible, we've built an API that allows Claude to perceive and interact with computer interfaces. Developers can integrate this API to enable Claude to translate instructions (e.g., “use data from my computer and online to fill out this form”) into computer commands (e.g. check a spreadsheet; move the cursor to open a web browser; navigate to the relevant web pages; fill out a form with the data from those pages; and so on). On OSWorld, which evaluates AI models' ability to use computers like people do, Claude 3.5 Sonnet scored 14.9% in the screenshot-only category—notably better than the next-best AI system's score of 7.8%. When afforded more steps to complete the task, Claude scored 22.0%.
While we expect this capability to improve rapidly in the coming months, Claude's current ability to use computers is imperfect. Some actions that people perform effortlessly—scrolling, dragging, zooming—currently present challenges for Claude and we encourage developers to begin exploration with low-risk tasks. Because computer use may provide a new vector for more familiar threats such as spam, misinformation, or fraud, we're taking a proactive approach to promote its safe deployment. We've developed new classifiers that can identify when computer use is being used and whether harm is occurring. You can read more about the research process behind this new skill, along with further discussion of safety measures, in our post on developing computer use.
Looking ahead
Learning from the initial deployments of this technology, which is still in its earliest stages, will help us better understand both the potential and the implications of increasingly capable AI systems.
We’re excited for you to explore our new models and the public beta of computer use—and welcome you to share your feedback with us. We believe these developments will open up new possibilities for how you work with Claude, and we look forward to seeing what you'll create.

 I appreciate your patience and understanding!
I appreciate your patience and understanding!

 @TheReal_Ingrid_ for
@TheReal_Ingrid_ for  unroll
unroll






 used to work on sd 1.5 with animate diff
used to work on sd 1.5 with animate diff














 can't wait to see what you generate
can't wait to see what you generate



 :Ichigo: Mixed-Modal Early-Fusion Realtime Voice Assistant
:Ichigo: Mixed-Modal Early-Fusion Realtime Voice Assistant :
:




