1/13
@cocktailpeanut
Omnigen: One Model to Rule Them All
One universal model to take care of every image generation task WITHOUT add-ons like controlnet, ip-adapter, etc. Prompt is all you need.
They finally dropped the code and a gradio app, and now you can run it on your computer with 1 click.
[Quoted tweet]
OmniGen
Unified Image Generation
discuss: huggingface.co/papers/2409.1…
In this work, we introduce OmniGen, a new diffusion model for unified image generation. Unlike popular diffusion models (e.g., Stable Diffusion), OmniGen no longer requires additional modules such as ControlNet or IP-Adapter to process diverse control conditions. OmniGenis characterized by the following features: 1) Unification: OmniGen not only demonstrates text-to-image generation capabilities but also inherently supports other downstream tasks, such as image editing, subject-driven generation, and visual-conditional generation. Additionally, OmniGen can handle classical computer vision tasks by transforming them into image generation tasks, such as edge detection and human pose recognition. 2) Simplicity: The architecture of OmniGen is highly simplified, eliminating the need for additional text encoders. Moreover, it is more user-friendly compared to existing diffusion models, enabling complex tasks to be accomplished through instructions without the need for extra preprocessing steps (e.g., human pose estimation), thereby significantly simplifying the workflow of image generation. 3) Knowledge Transfer: Through learning in a unified format, OmniGen effectively transfers knowledge across different tasks, manages unseen tasks and domains, and exhibits novel capabilities. We also explore the model's reasoning capabilities and potential applications of chain-of-thought mechanism. This work represents the first attempt at a general-purpose image generation model, and there remain several unresolved issues.


2/13
@cocktailpeanut
Available for 1 click launch on
Pinokio
3/13
@cocktailpeanut
Omnigen Project Page
GitHub - VectorSpaceLab/OmniGen
4/13
@cocktailpeanut
The localized gradio app was adopted from the huggingface space here
https://huggingface.co/spaces/shytao/OmniGen
5/13
@cocktailpeanut
It runs on ALL platforms (Mac, NVIDIA, etc.) but the real question is how fast it will be.
FYI it uses a lot of resources and not the fastest thing you would run.
On NVIDIA 4090, it took 1 minute 10 second to generate this 1024x576 image.
6/13
@cocktailpeanut
And on a Mac M1 Max 64G....around 40 minutes to generate an 1024x576 image.
If you're planning to try this on a Mac, I recommend closing EVERY app you're running and only keep this running, as the more memory you have the faster it will be.
7/13
@cocktailpeanut
Here are some example things you can do, it's really powerful and versatile.
If you read through the prompts, it can **potentially** replace all kinds of things like IPAdapter, ControlNet, and even things like SAM.
8/13
@cocktailpeanut
You can use multiple images as input, and even OpenPose as input (WITHOUT a controlnet addon!), and background removal, and so on and so on.
It has its own markup language, kind of like a mix between an LLM and an image model.
9/13
@cocktailpeanut
IMO this is the future. I don't think people in the future will be sitting there trying to combine A111 extensions and so on. Just ask AI something and you get it.
Plus, the more inter-disciplinary knowledge (LLM + Image + maybe even Video) an AI has, the smarter it will be.
10/13
@cocktailpeanut
But lets not get ahead of ourselves, first we def need a lighter version of this (omnigen-turbo?)
If I can generate one image in 10 second on my 4090 for example, I will be much more motivated to experiment more.
11/13
@cocktailpeanut
Also I appreciate how powerful the prompt markup is, but I think maybe we can improve it.
The markup feels too machine-like. If there's a way to express all this in natural language which gets transformed into the markup, that would ideal. Maybe an additional LLM layer?
12/13
@cocktailpeanut
Since this is an edge tech that takes relatively long time to run, if you play with this, please do share your results so others can learn more. I will add the shared results on the pinokio newsfeed here
Pinokio
13/13
@cocktailpeanut
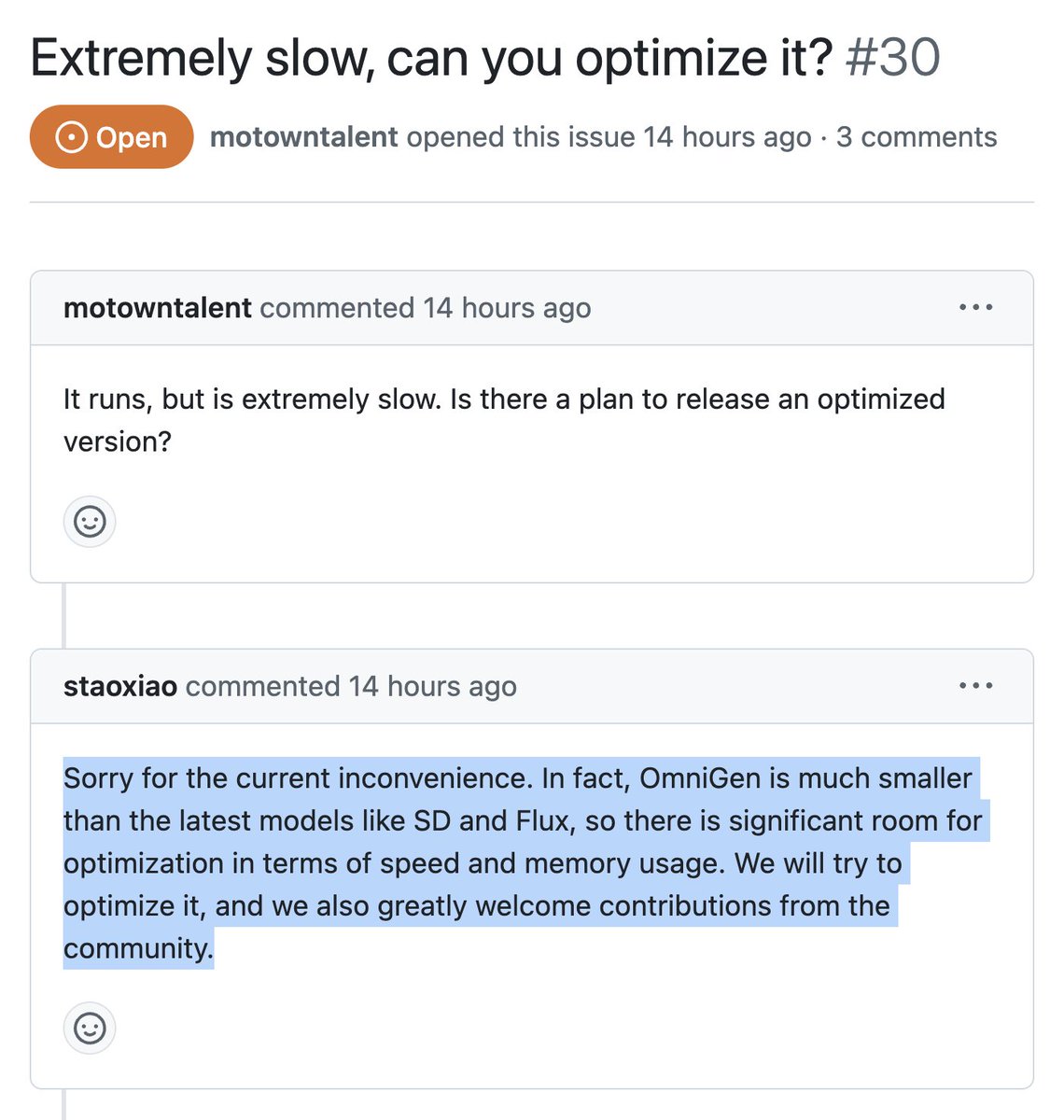
Looks like Omnigen is actually NOT supposed to be this slow. In fact it's supposed to be even faster than Flux or SD, they said they're gonna work on it, so we should all go ask them to do it ASAP
[Quoted tweet]
"In fact, OmniGen is much smaller than the latest models like SD and Flux, so there is significant room for optimization"
Wait what?
Good news is, if we all go and ask them enough, they will appreciate all the interest and expedite it probably. Lesgo!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196


 Extremely easy to launch: Clone the repo, install from requirements, and launch the app `python app_py`
Extremely easy to launch: Clone the repo, install from requirements, and launch the app `python app_py` 
 Repo for Computer_Use_OOTB: GitHub - showlab/computer_use_ootb: An out-of-the-box (OOTB) version of Anthropic Claude Computer Use
Repo for Computer_Use_OOTB: GitHub - showlab/computer_use_ootb: An out-of-the-box (OOTB) version of Anthropic Claude Computer Use Excited to release our study on visual comprehension and abstract reasoning skills via #PolyMATH. We provide both quantitative and qualitative evaluations of #GPT4o, #Claude 3.5 Sonnet, #Gemini 1.5 pro, #OpenAI o1 models & 13 other models.
Excited to release our study on visual comprehension and abstract reasoning skills via #PolyMATH. We provide both quantitative and qualitative evaluations of #GPT4o, #Claude 3.5 Sonnet, #Gemini 1.5 pro, #OpenAI o1 models & 13 other models.
 Full paper: arxiv.org/abs/2410.14702
Full paper: arxiv.org/abs/2410.14702 @huggingface Dataset:
@huggingface Dataset:  Key Insights:
Key Insights: A dataset of 5000 samples to test cognitive reasoning capabilities of MLLMs.
A dataset of 5000 samples to test cognitive reasoning capabilities of MLLMs. The best scores achieved on POLYMATH are ∼ 41%, ∼ 36%, and ∼ 27%, obtained by Claude-3.5 Sonnet, GPT-4o and Gemini-1.5 Pro respectively while human baseline was at ~66%.
The best scores achieved on POLYMATH are ∼ 41%, ∼ 36%, and ∼ 27%, obtained by Claude-3.5 Sonnet, GPT-4o and Gemini-1.5 Pro respectively while human baseline was at ~66%. An improvement of 4% is observed when image descriptions are passed instead of actual images, indicating reliance on text over image even in multimodal reasoning.
An improvement of 4% is observed when image descriptions are passed instead of actual images, indicating reliance on text over image even in multimodal reasoning. Open AI o1 models get competitive scores with human baseline on text only samples, highlighting room for improvement!
Open AI o1 models get competitive scores with human baseline on text only samples, highlighting room for improvement!









 Upload your pic
Upload your pic  , add the dress, and see how it looks on you instantly!
, add the dress, and see how it looks on you instantly! 







 Contact us if you made a great AI tool to be featured:
Contact us if you made a great AI tool to be featured:  Experience the thrill of trying on any fashionable outfit and using @Kling_ai to turn your images into dynamic videos. Don't miss out!
Experience the thrill of trying on any fashionable outfit and using @Kling_ai to turn your images into dynamic videos. Don't miss out! 





 HUGE
HUGE 

 And it will be used according to individual's level of knowledge and understanding.
And it will be used according to individual's level of knowledge and understanding.
 and what better way to start than with a beginners guide to @huggingface spaces!
and what better way to start than with a beginners guide to @huggingface spaces!












 QAT + LoRA Method
QAT + LoRA Method SpinQuant Method
SpinQuant Method Key Differences
Key Differences








 gpt ass
gpt ass
 @JuliusAI_
@JuliusAI_
 /search?q=#BetterLateThanNever
/search?q=#BetterLateThanNever
