
1/16
@leloykun
Deep Learning Optimizers from First Principles
My attempt at answering these questions:
1. Why do steepest descent in non-Euclidean spaces?
2. Why does adaptive preconditioning work so well in practice? And,
3. Why normalize everything ala nGPT?
[Quoted tweet]
The Case for Muon
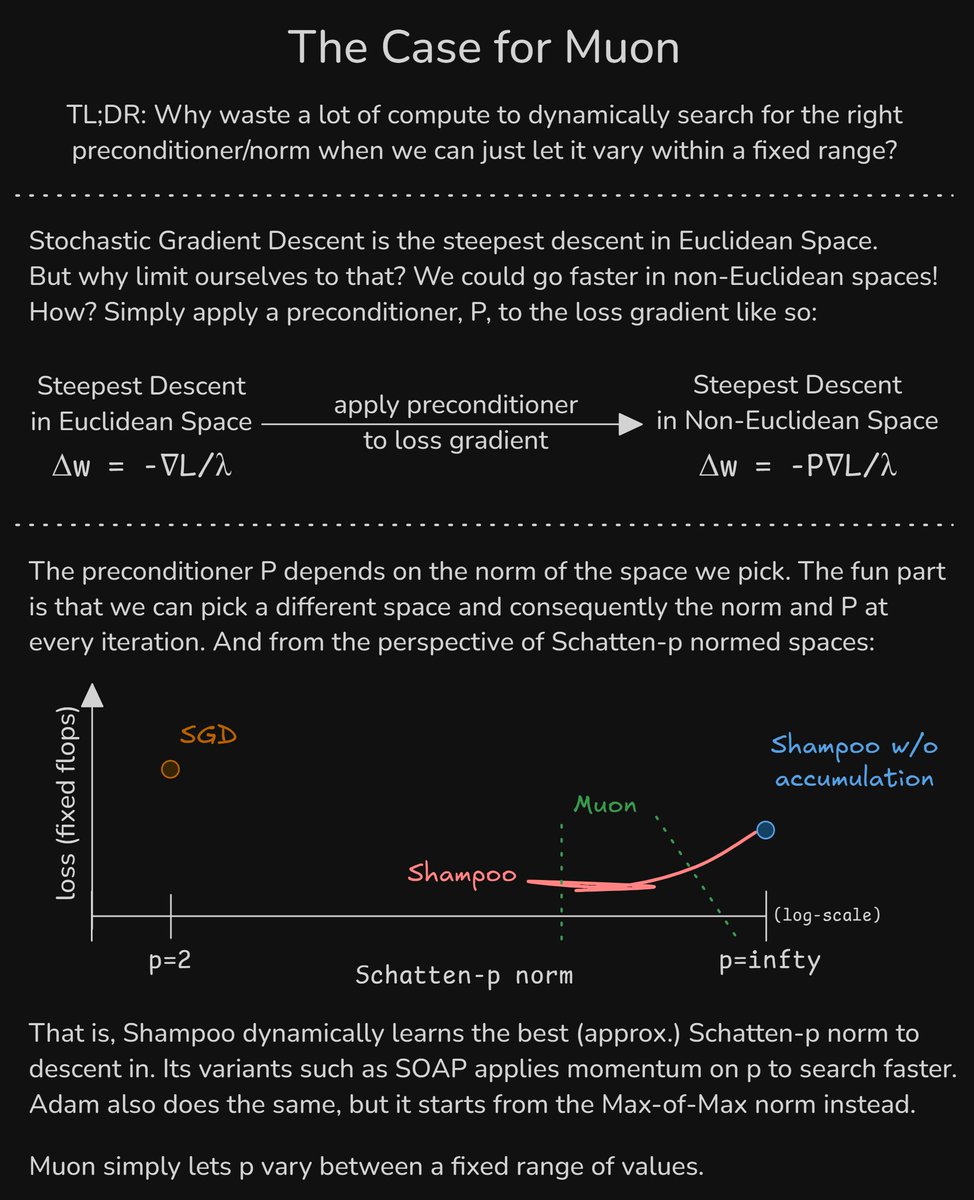
1) We can descend 'faster' in non-Euclidean spaces
2) Adam/Shampoo/SOAP/etc. dynamically learn the preconditioner and, equivalently, the norm & space to descend in
3) Muon saves a lot of compute by simply letting the norm to vary within a fixed range
2/16
@leloykun
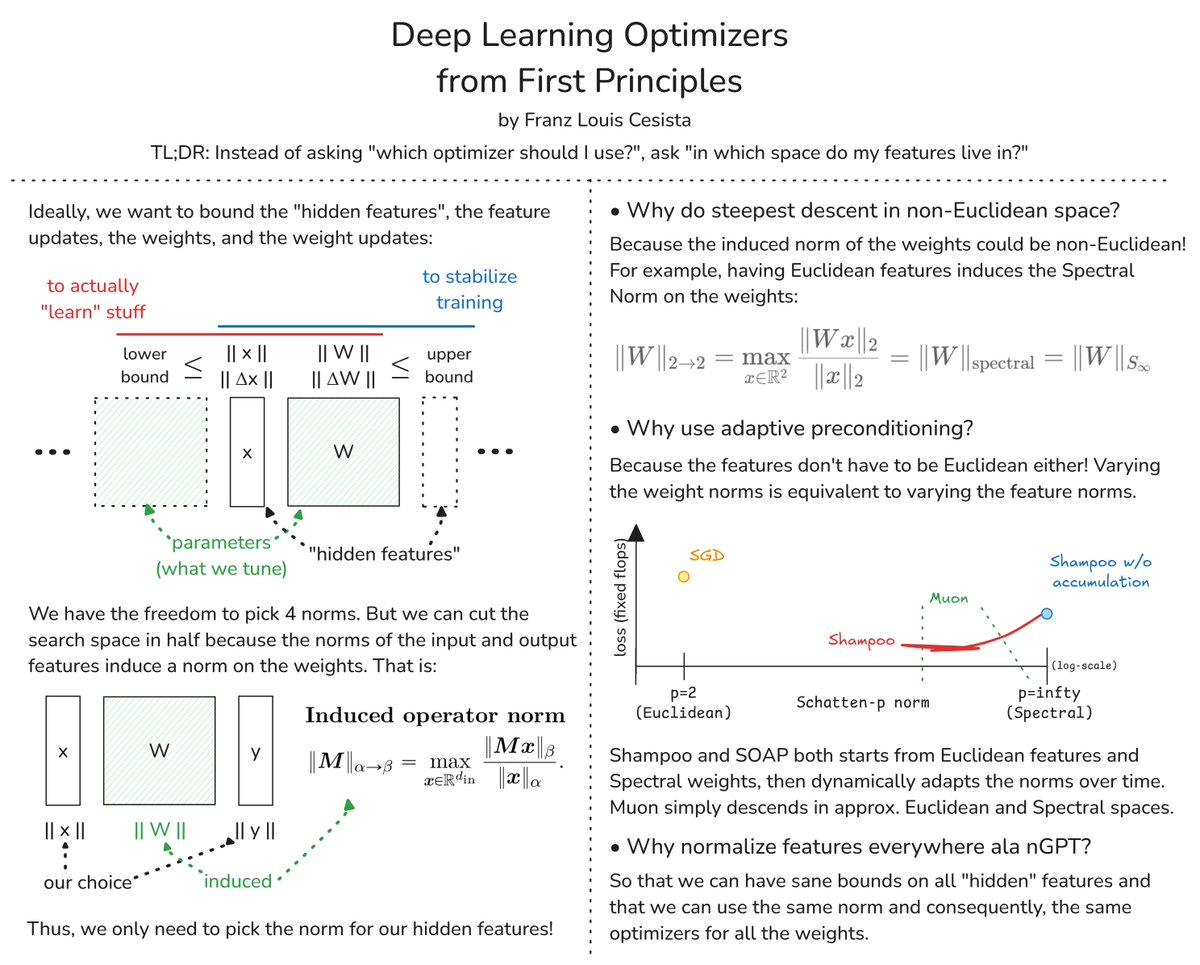
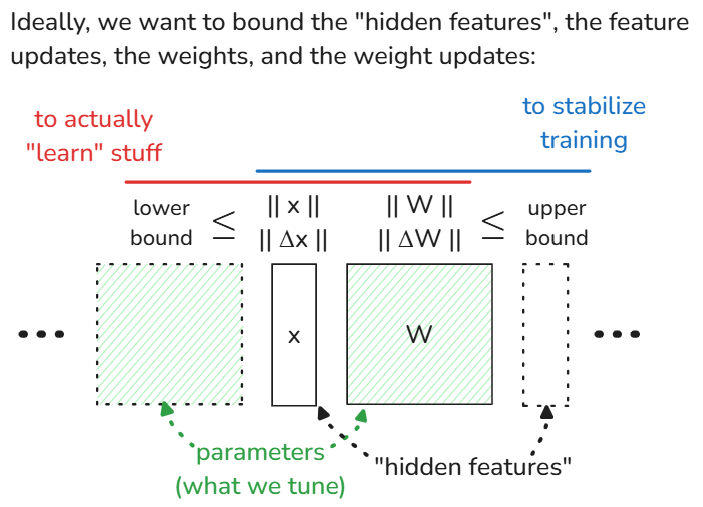
Ideally, when training a neural network, we want to bound the features, the weights, and their respective updates so that:
1. [lower] the model actually "learns" stuff; and
2. [upper] model training is stable
These bounds then depend on the norms, but which norms?
3/16
@leloykun
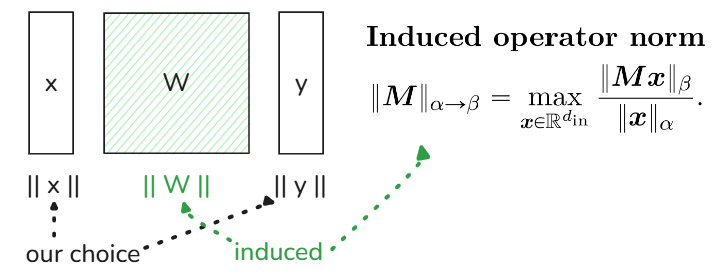
The fun part is that the norms of the input and output features already induce the norm of the weights between them
We can also let the feature and feature updates have the same norm (likewise for the weights)
And so, we only have to choose the norms for the features!
4/16
@leloykun
Now, our datasets are usually Euclidean or locally Euclidean (see Manifold Hypothesis)
What's the norm induced by Euclidean input and output vector spaces? The Spectral Norm!

5/16
@leloykun
So even if we don't want to do anything fancy, we'd still have to do steepest descent in non-Euclidean space because:
1. The induced norm for the weights (w/ Euclidean features) is non-Euclidean; and
2. We're optimizing the weights, not the features
cc:
[Quoted tweet]
The rate this whole space is converging towards a topological math problem makes me really uncomfortable
6/16
@leloykun
The model inputs and outputs being Euclidean sounds reasonable, but why do the "hidden" features have to be Euclidean too?
If we vary the norms of these features, we also vary the induced norms of the weights and v.v
Adaptive preconditioning then "searches" for the proper norms
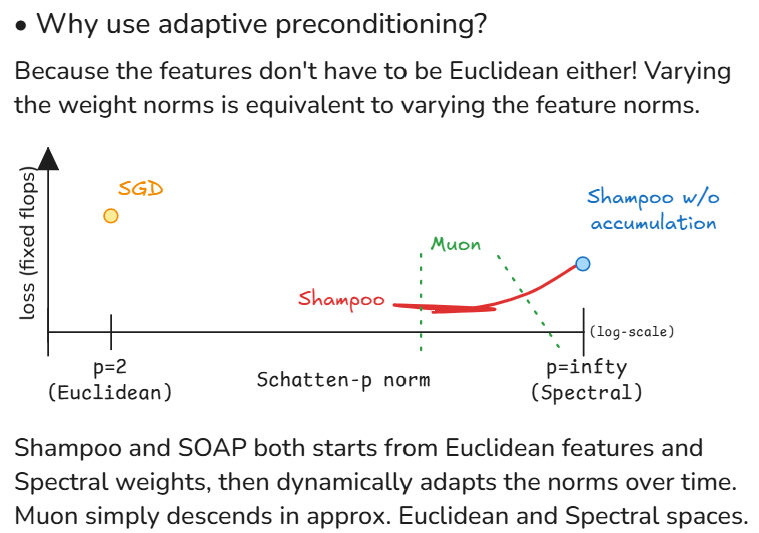
7/16
@leloykun
This also answers @mattecapu's Q here
Shampoo & SOAP starts from Euclidean features and Spectral weights, then tunes the norms over time. SOAP does this tuning with momentum so it's theoretically faster.
[Quoted tweet]
really cool to also optimize the p in the norm. do you have a conceptual idea of what that's tuning? I guess intuitively as p->oo each dimension is getting 'further away' from each other..
8/16
@leloykun
A more cynical answer, from a mathematician to another, is that almost nobody in this field is actually doing proper linear algebra.
Adaptive preconditioning allows us to start from really crappy configurations/parametrizations and get away scoff free
9/16
@leloykun
A more pro-ML answer would be that humans suck at predicting which inductive biases would work best when cooked into the models
E.g. why should the "hidden" features be in Euclidean space? Why not let the model learn the proper space(s) to work with?
10/16
@leloykun
Another takeaway here is that interpretability folks also need to be mindful of this.
The "hidden" features may not be Euclidean!
And e.g., if you use Adam (w/o accumulation), what you're really doing is optimizing a transform from l_1 norm to l_infty norm
11/16
@leloykun
Finally, why is it a good idea to normalize everything everywhere?
Cuz it lets us have sane bounds & same norms on the features which means we can use the same optimizer for all the layers with minimal tuning!
[2410.01131] nGPT: Normalized Transformer with Representation Learning on the Hypersphere
12/16
@leloykun
I also realized I overlooked something elementary here
I was getting unstable iterators because I wasn't properly upper-bounding the polynomials lol
[Quoted tweet]
I've also noticed that for each γ, there is a minimum r below which things become unstable. And as we increase γ, the minimum r also increases
This indicates that as we shrink the attractor basin, the more iterations we'll need for things to converge.
13/16
@leloykun
If you want to design your own iterators:
1. Pick an inner and outer radii (l, r)
2. Let {0,+-(1-l),+-(1+r)} be fixed points
3. Binary search for the maximum gamma such that the peak in (0, 1-l) = 1 + r while the trough in (1-l, 1+r) > 0
The current iterator already decent tho
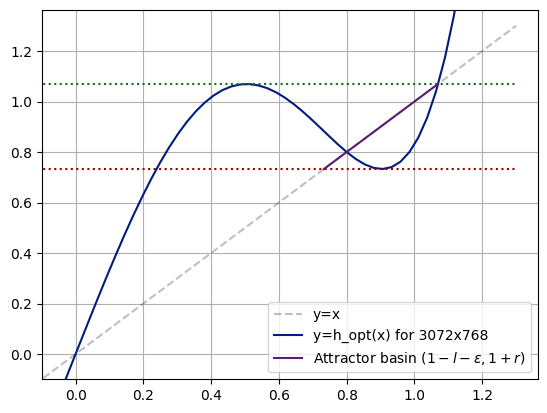
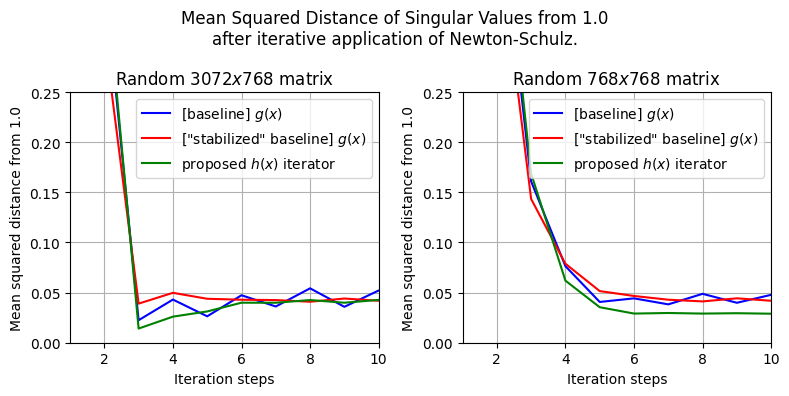
14/16
@leloykun
Going back,
it's really important to think about where we're mapping things to and from because the optimizer, learning rate scheduler, and etc. can be derived from there
15/16
@leloykun
That's all from me!
I now feel intellectually satisfied and the nerdsnipe trance is wearing off. I can finally be normal again and be productive and post memes huhu
16/16
@leloykun
I also really recommend this work by @TheGregYang and @jxbz : [2310.17813] A Spectral Condition for Feature Learning
This one too: [2409.20325] Old Optimizer, New Norm: An Anthology
super information-dense works!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@leloykun
Deep Learning Optimizers from First Principles
My attempt at answering these questions:
1. Why do steepest descent in non-Euclidean spaces?
2. Why does adaptive preconditioning work so well in practice? And,
3. Why normalize everything ala nGPT?
[Quoted tweet]
The Case for Muon
1) We can descend 'faster' in non-Euclidean spaces
2) Adam/Shampoo/SOAP/etc. dynamically learn the preconditioner and, equivalently, the norm & space to descend in
3) Muon saves a lot of compute by simply letting the norm to vary within a fixed range
2/16
@leloykun
Ideally, when training a neural network, we want to bound the features, the weights, and their respective updates so that:
1. [lower] the model actually "learns" stuff; and
2. [upper] model training is stable
These bounds then depend on the norms, but which norms?
3/16
@leloykun
The fun part is that the norms of the input and output features already induce the norm of the weights between them
We can also let the feature and feature updates have the same norm (likewise for the weights)
And so, we only have to choose the norms for the features!
4/16
@leloykun
Now, our datasets are usually Euclidean or locally Euclidean (see Manifold Hypothesis)
What's the norm induced by Euclidean input and output vector spaces? The Spectral Norm!
5/16
@leloykun
So even if we don't want to do anything fancy, we'd still have to do steepest descent in non-Euclidean space because:
1. The induced norm for the weights (w/ Euclidean features) is non-Euclidean; and
2. We're optimizing the weights, not the features
cc:
[Quoted tweet]
The rate this whole space is converging towards a topological math problem makes me really uncomfortable
6/16
@leloykun
The model inputs and outputs being Euclidean sounds reasonable, but why do the "hidden" features have to be Euclidean too?
If we vary the norms of these features, we also vary the induced norms of the weights and v.v
Adaptive preconditioning then "searches" for the proper norms
7/16
@leloykun
This also answers @mattecapu's Q here
Shampoo & SOAP starts from Euclidean features and Spectral weights, then tunes the norms over time. SOAP does this tuning with momentum so it's theoretically faster.
[Quoted tweet]
really cool to also optimize the p in the norm. do you have a conceptual idea of what that's tuning? I guess intuitively as p->oo each dimension is getting 'further away' from each other..
8/16
@leloykun
A more cynical answer, from a mathematician to another, is that almost nobody in this field is actually doing proper linear algebra.
Adaptive preconditioning allows us to start from really crappy configurations/parametrizations and get away scoff free
9/16
@leloykun
A more pro-ML answer would be that humans suck at predicting which inductive biases would work best when cooked into the models
E.g. why should the "hidden" features be in Euclidean space? Why not let the model learn the proper space(s) to work with?
10/16
@leloykun
Another takeaway here is that interpretability folks also need to be mindful of this.
The "hidden" features may not be Euclidean!
And e.g., if you use Adam (w/o accumulation), what you're really doing is optimizing a transform from l_1 norm to l_infty norm
11/16
@leloykun
Finally, why is it a good idea to normalize everything everywhere?
Cuz it lets us have sane bounds & same norms on the features which means we can use the same optimizer for all the layers with minimal tuning!
[2410.01131] nGPT: Normalized Transformer with Representation Learning on the Hypersphere
12/16
@leloykun
I also realized I overlooked something elementary here
I was getting unstable iterators because I wasn't properly upper-bounding the polynomials lol
[Quoted tweet]
I've also noticed that for each γ, there is a minimum r below which things become unstable. And as we increase γ, the minimum r also increases
This indicates that as we shrink the attractor basin, the more iterations we'll need for things to converge.
13/16
@leloykun
If you want to design your own iterators:
1. Pick an inner and outer radii (l, r)
2. Let {0,+-(1-l),+-(1+r)} be fixed points
3. Binary search for the maximum gamma such that the peak in (0, 1-l) = 1 + r while the trough in (1-l, 1+r) > 0
The current iterator already decent tho
14/16
@leloykun
Going back,
it's really important to think about where we're mapping things to and from because the optimizer, learning rate scheduler, and etc. can be derived from there
15/16
@leloykun
That's all from me!
I now feel intellectually satisfied and the nerdsnipe trance is wearing off. I can finally be normal again and be productive and post memes huhu
16/16
@leloykun
I also really recommend this work by @TheGregYang and @jxbz : [2310.17813] A Spectral Condition for Feature Learning
This one too: [2409.20325] Old Optimizer, New Norm: An Anthology
super information-dense works!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
3/4
@rohanpaul_ai
New Transformer architecture modifications from NVIDIA researchers.
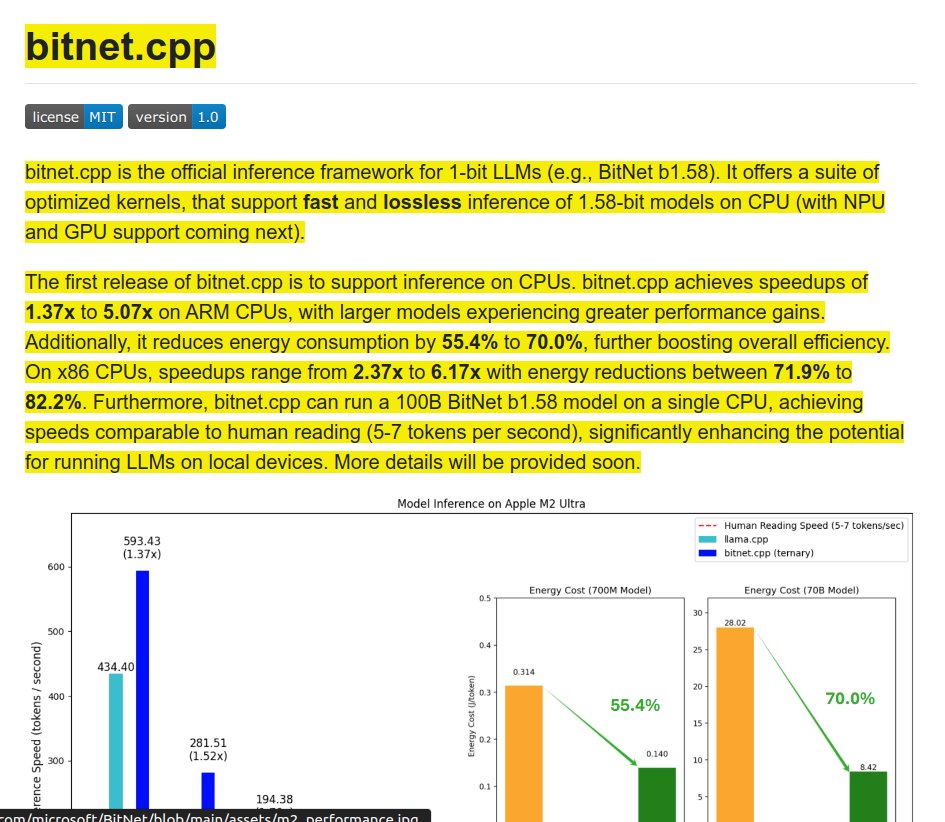
nGPT: A hypersphere-based Transformer achieving 4-20x faster training and improved stability for LLMs.
**Key Insights from this Paper** :
:
• nGPT learns 4-20x faster than standard Transformers
• Hyperspherical representation improves stability and embedding separability
• Transformer layers act as optimization steps on a hypersphere
• Eigen learning rates control the impact of each block's updates
• nGPT handles longer contexts without modifying positional encodings
-----
**Results** :
:
• 4x faster training for 1k context length
• 10x faster training for 4k context length
• 20x faster training for 8k context length
• Similar or better performance on downstream tasks with less training
• More stable performance when extrapolating to longer sequences
------
Generated this podcast with Google's Illuminate.
[Quoted tweet]
New Transformer architecture modifications from NVIDIA researchers.
nGPT: A hypersphere-based Transformer achieving 4-20x faster training and improved stability for LLMs.
**Proposals in this Paper** :
:
• Normalized Transformer (nGPT) architecture
• All vectors normalized to unit norm on hypersphere
• Learnable eigen learning rates control hidden state updates
• Removal of LayerNorm/RMSNorm layers
• Introduction of scaling factors for logits, query/key vectors, and MLP states
• Elimination of weight decay and learning rate warmup
-----
**Key Insights from this Paper**:
• nGPT learns 4-20x faster than standard Transformers
• Hyperspherical representation improves stability and embedding separability
• Transformer layers act as optimization steps on a hypersphere
• Eigen learning rates control the impact of each block's updates
• nGPT handles longer contexts without modifying positional encodings
-----
**Results**:
• 4x faster training for 1k context length
• 10x faster training for 4k context length
• 20x faster training for 8k context length
• Similar or better performance on downstream tasks with less training
• More stable performance when extrapolating to longer sequences

https://video-t-2.twimg.com/ext_tw_...16/pu/vid/avc1/1080x1080/puHpFuQ16dykA8Pb.mp4
4/4
@VXaviervm
what are the current transformers that are not a hypersphere?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@rohanpaul_ai
New Transformer architecture modifications from NVIDIA researchers.
nGPT: A hypersphere-based Transformer achieving 4-20x faster training and improved stability for LLMs.
**Key Insights from this Paper**
:• nGPT learns 4-20x faster than standard Transformers
• Hyperspherical representation improves stability and embedding separability
• Transformer layers act as optimization steps on a hypersphere
• Eigen learning rates control the impact of each block's updates
• nGPT handles longer contexts without modifying positional encodings
-----
**Results**
:• 4x faster training for 1k context length
• 10x faster training for 4k context length
• 20x faster training for 8k context length
• Similar or better performance on downstream tasks with less training
• More stable performance when extrapolating to longer sequences
------
Generated this podcast with Google's Illuminate.
[Quoted tweet]
New Transformer architecture modifications from NVIDIA researchers.
nGPT: A hypersphere-based Transformer achieving 4-20x faster training and improved stability for LLMs.
**Proposals in this Paper**
:• Normalized Transformer (nGPT) architecture
• All vectors normalized to unit norm on hypersphere
• Learnable eigen learning rates control hidden state updates
• Removal of LayerNorm/RMSNorm layers
• Introduction of scaling factors for logits, query/key vectors, and MLP states
• Elimination of weight decay and learning rate warmup
-----
**Key Insights from this Paper**
:• nGPT learns 4-20x faster than standard Transformers
• Hyperspherical representation improves stability and embedding separability
• Transformer layers act as optimization steps on a hypersphere
• Eigen learning rates control the impact of each block's updates
• nGPT handles longer contexts without modifying positional encodings
-----
**Results**
:• 4x faster training for 1k context length
• 10x faster training for 4k context length
• 20x faster training for 8k context length
• Similar or better performance on downstream tasks with less training
• More stable performance when extrapolating to longer sequences
https://video-t-2.twimg.com/ext_tw_...16/pu/vid/avc1/1080x1080/puHpFuQ16dykA8Pb.mp4
4/4
@VXaviervm
what are the current transformers that are not a hypersphere?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
 How does nGPT differ from the standard Transformer architecture?
How does nGPT differ from the standard Transformer architecture?
 Potential drawbacks of nGPT
Potential drawbacks of nGPT nGPT allows for some insights about Transformer internals :
nGPT allows for some insights about Transformer internals :
 This method involves replacing the standard Linear layers with specialized BitLinear layers that are compatible with the BitNet architecture, with appropriate dynamic quantization of activations, weight unpacking, and matrix multiplication.
This method involves replacing the standard Linear layers with specialized BitLinear layers that are compatible with the BitNet architecture, with appropriate dynamic quantization of activations, weight unpacking, and matrix multiplication.






 :
:

 GraphLM was created by fine-tuning Vicuna-7b on GraphInstruct using LoRA.
GraphLM was created by fine-tuning Vicuna-7b on GraphInstruct using LoRA.






 Traditional matrix multiplication:
Traditional matrix multiplication: BitNet b1.58 approach:
BitNet b1.58 approach: Why this is highly optimizable:
Why this is highly optimizable:
 Starting point:
Starting point: Goal:
Goal: The process:
The process: Step 1: Find the average:
Step 1: Find the average: Result:
Result: Why do this?
Why do this?
 Right graph (Memory):
Right graph (Memory): Table (Throughput):
Table (Throughput):



