1/6
@omarsar0
Mistral AI is doubling down on small language models.
Their latest Ministral models (both the 3B and 8B) are pretty impressive and will be incredibly useful for a lot of LLM workflows.
Some observations:
I enjoy seeing how committed Mistral AI is to developing smaller and more capable models.
They seem to understand what developers want and need today.
There is huge competition for the finest, smallest, and cheapest models. This is good for the AI developer community.
This sets up the community really well in terms of the wave of innovation that’s coming around on-device AI and agentic workflows. 2025 is going to be a wild year.
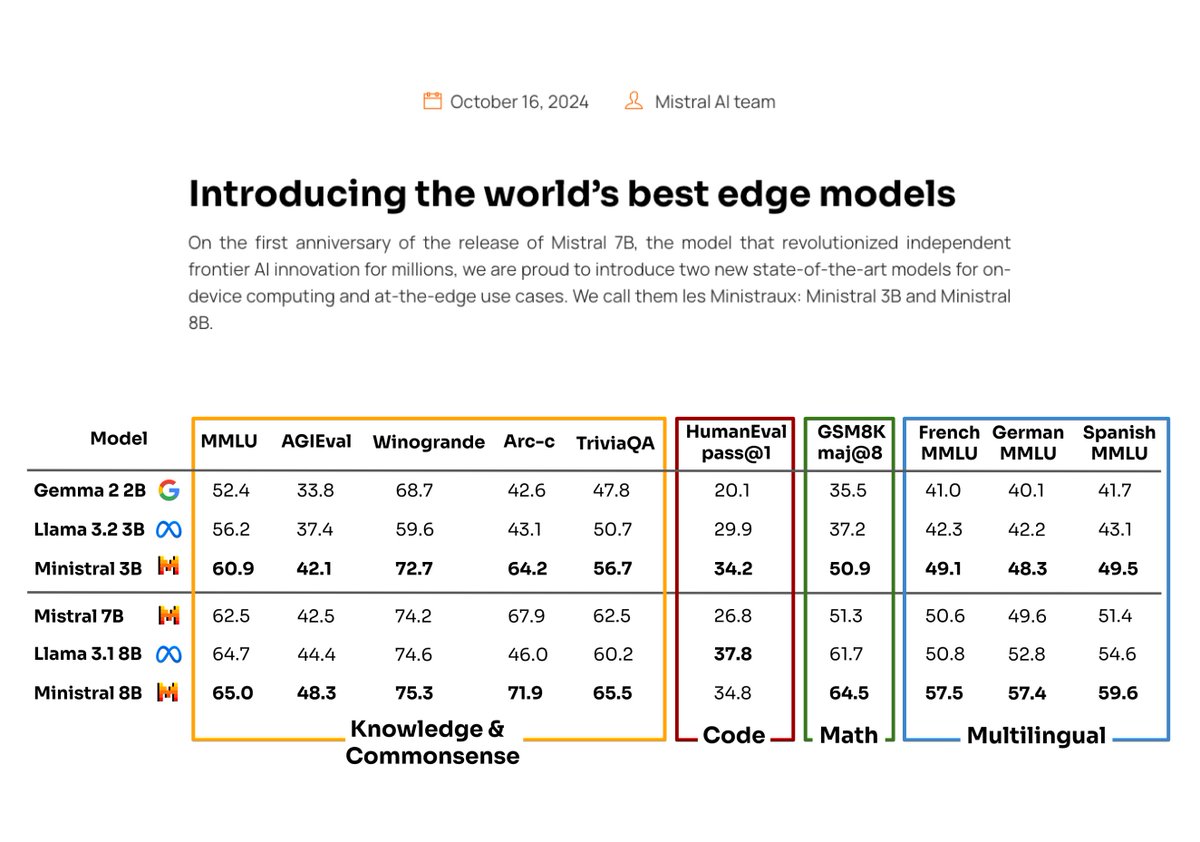
They don’t mention the secret sauce behind these capable smaller models (probably some distillation happening), the Ministral 3B model already performs competitively with Mistral 7B. I think this is a great focus of Mistral as they seek to differentiate from other LLM providers.
Given this announcement, I am now super curious about what the next Gemma and Llama small models are going to bring. Mini models are taking over!
I use small models for processing data, structuring information, function calling, routing, evaluation pipelines, prompt chaining, agentic workflows, and a whole lot more.
2/6
@omarsar0
More thoughts here: https://invidious.poast.org/dh1i3YAwd1I
3/6
@thomvlieshout
For what do you use small models?
4/6
@omarsar0
I mentioned a few ways I use them towards the end the first post.
5/6
@M_Kasinski
What do you use as a small model for function calling for my part nothing suits me. If you have to call a suite of functions
6/6
@remotelama
refreshing pivot to efficient, compact models! interpretive yet concise approaches open new possibilities. impressive versatility.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@omarsar0
Mistral AI is doubling down on small language models.
Their latest Ministral models (both the 3B and 8B) are pretty impressive and will be incredibly useful for a lot of LLM workflows.
Some observations:
I enjoy seeing how committed Mistral AI is to developing smaller and more capable models.
They seem to understand what developers want and need today.
There is huge competition for the finest, smallest, and cheapest models. This is good for the AI developer community.
This sets up the community really well in terms of the wave of innovation that’s coming around on-device AI and agentic workflows. 2025 is going to be a wild year.
They don’t mention the secret sauce behind these capable smaller models (probably some distillation happening), the Ministral 3B model already performs competitively with Mistral 7B. I think this is a great focus of Mistral as they seek to differentiate from other LLM providers.
Given this announcement, I am now super curious about what the next Gemma and Llama small models are going to bring. Mini models are taking over!
I use small models for processing data, structuring information, function calling, routing, evaluation pipelines, prompt chaining, agentic workflows, and a whole lot more.
2/6
@omarsar0
More thoughts here: https://invidious.poast.org/dh1i3YAwd1I
3/6
@thomvlieshout
For what do you use small models?
4/6
@omarsar0
I mentioned a few ways I use them towards the end the first post.
5/6
@M_Kasinski
What do you use as a small model for function calling for my part nothing suits me. If you have to call a suite of functions
6/6
@remotelama
refreshing pivot to efficient, compact models! interpretive yet concise approaches open new possibilities. impressive versatility.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196























 :
: :
: :
:





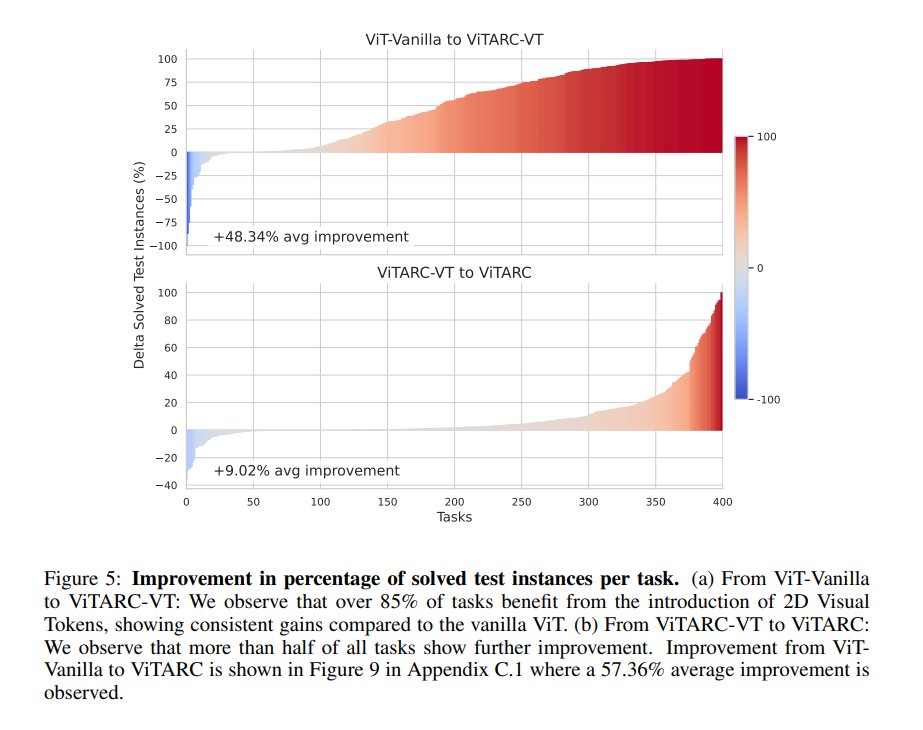
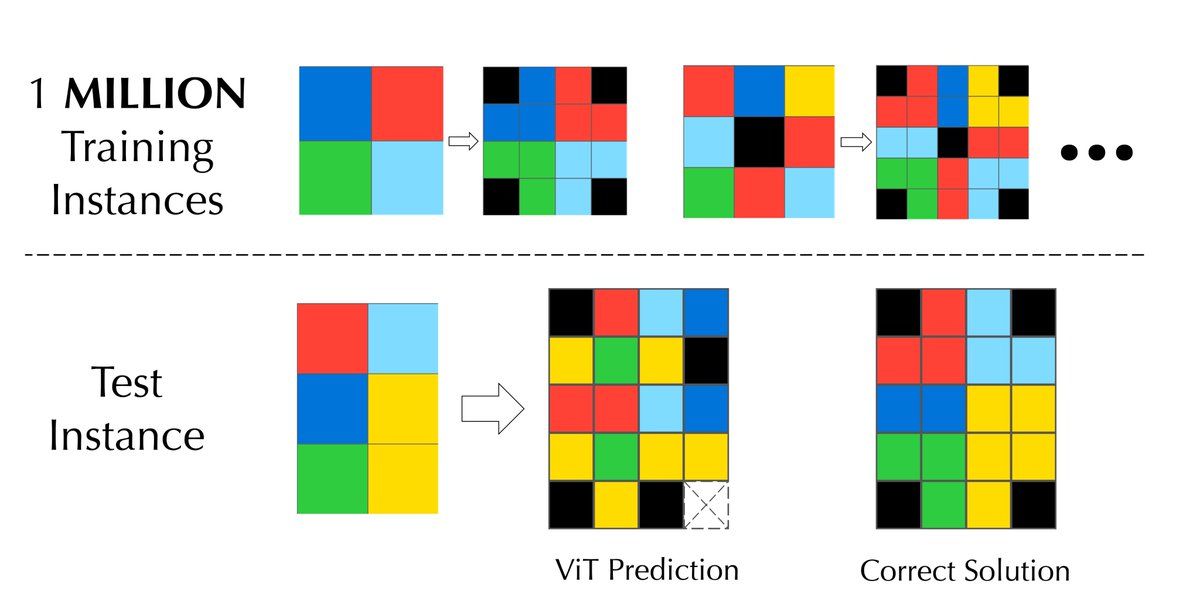
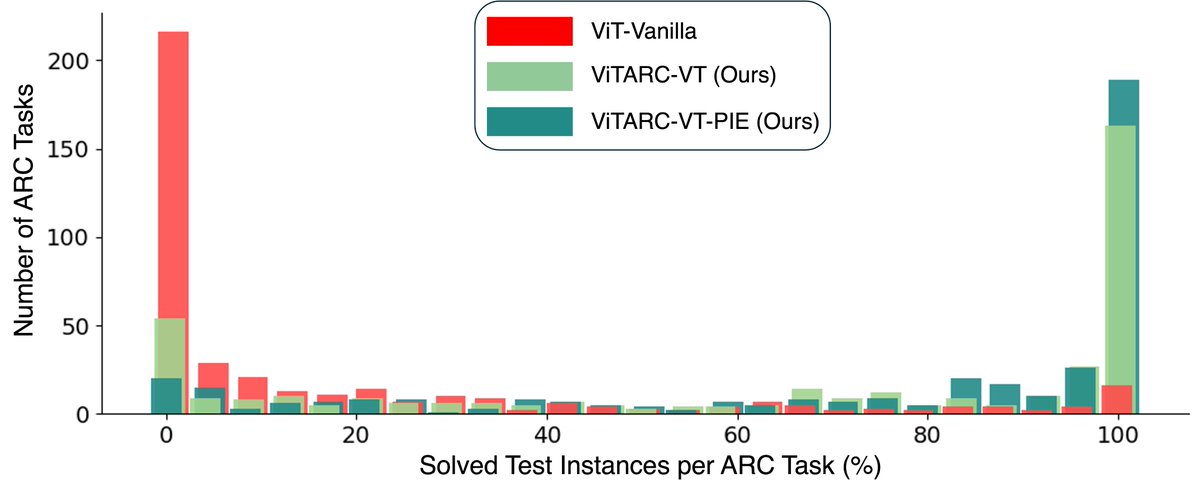
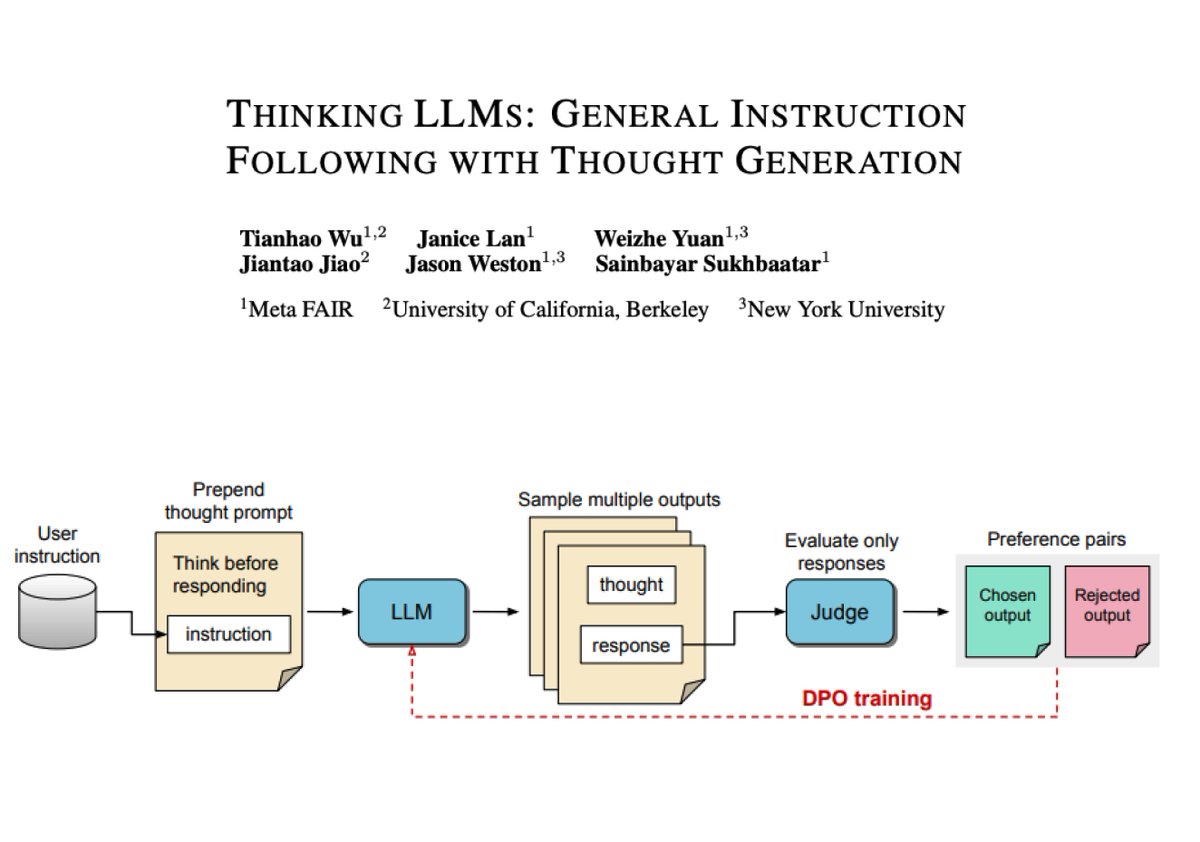
 The naive ICRL approach failed miserably, with models quickly degenerating to always predicting the same output. This was due to an inability to explore and difficulty learning from complex in-context signals like negative rewards.
The naive ICRL approach failed miserably, with models quickly degenerating to always predicting the same output. This was due to an inability to explore and difficulty learning from complex in-context signals like negative rewards.




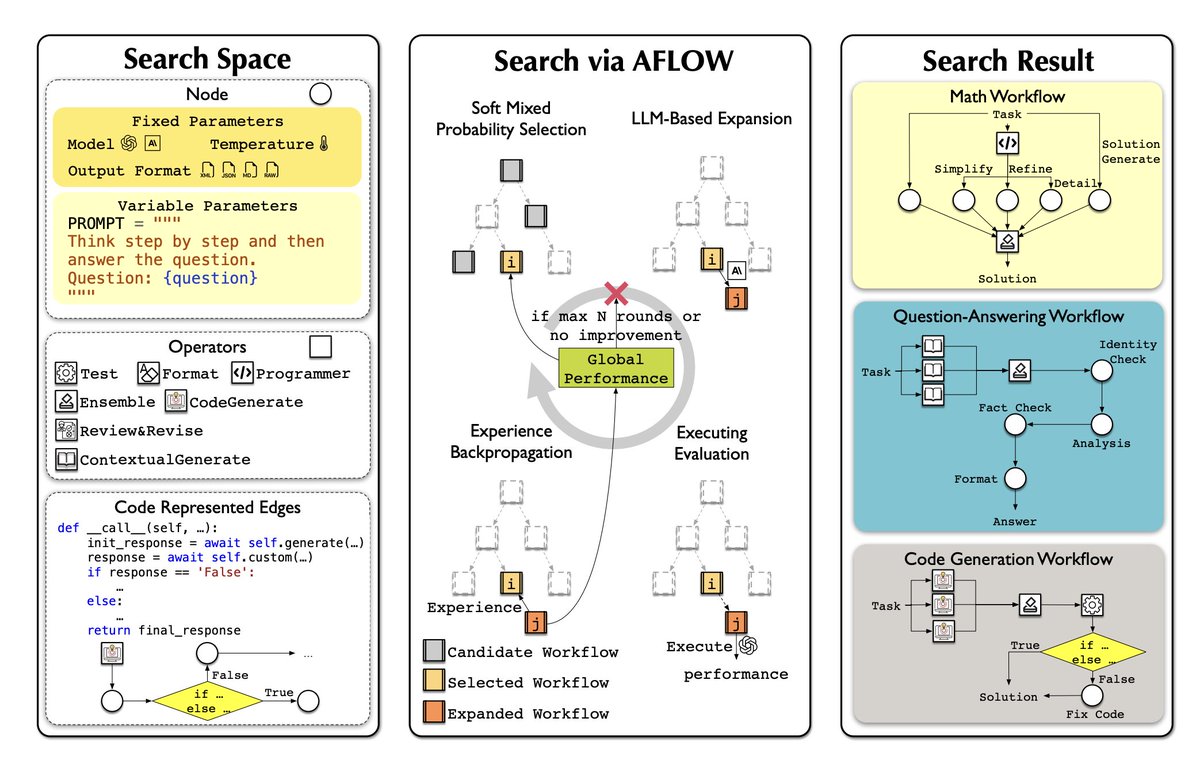
 We are thrilled to introduce AFlow: Automating Agentic Workflow Generation
We are thrilled to introduce AFlow: Automating Agentic Workflow Generation Paper: arxiv.org/abs/2410.10762
Paper: arxiv.org/abs/2410.10762 Code will be available at github.com/geekan/MetaGPT/
Code will be available at github.com/geekan/MetaGPT/