
1/11
@gordic_aleksa
How does OpenAI's o1 exactly work? Here is a list of papers & summaries on LLM reasoning that I've recently read.
I'll split them into 2 categories:
1) prompt-based - enforce step by step reasoning & self-correcting flow purely using prompts
2) learning-based - bake in the above into the policy model's weights (or into a verifier - usually a PRM; process reward model)
--- Prompt-based
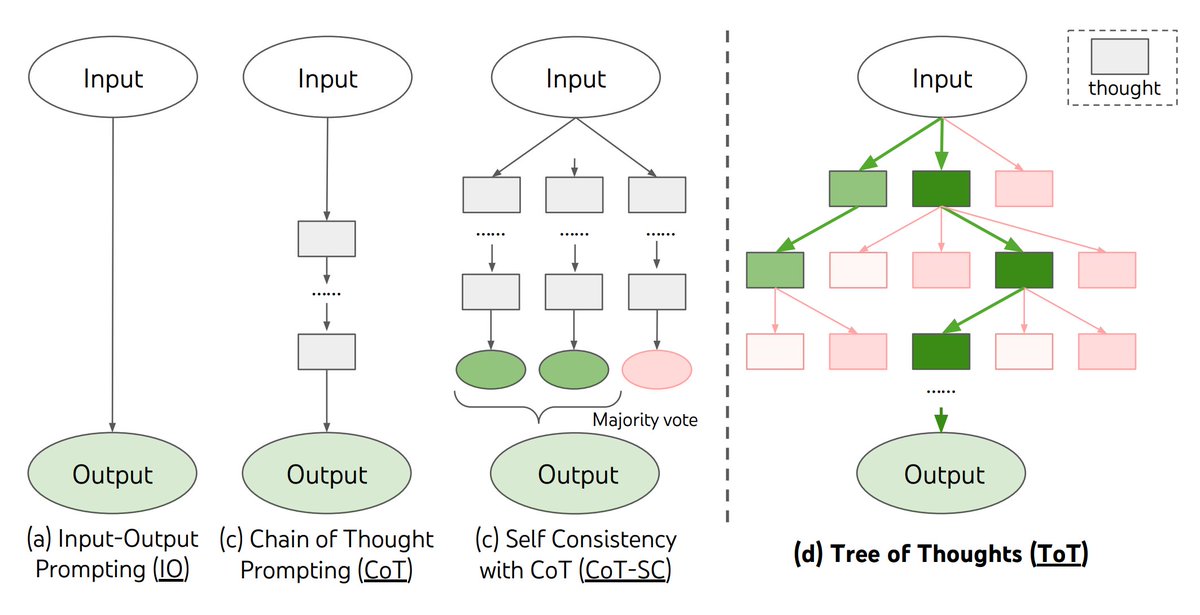
0) CoT et al: https://arxiv.org/pdf/2201.11903
Ground zero (plus I'm a C guy :P iykyk). It started with Chain-of-Thought paper. This class of methods boils down to asking the LLM nicely to reveal its internal thoughts (e.g. "Let's think step by step"; more generally telling the model to disclose the intermediate computation steps in someway).
A simple variation on CoT would be "CoT self-consistency" -> i.e. sample multiple CoT traces in parallel and use majority voting to find the "right" answer.
1) ToT (tree of thought): https://arxiv.org/pdf/2305.10601
Further complexifies the above (in CS terms we go from linear list -> tree): build up an m-ary tree of intermediate thoughts (thoughts = intermediate steps of CoT); at each thought/node:
a) run the “propose next thoughts” prompt (or just sample completions m times)
b) evaluate those thoughts (either independently or jointly)
c) keep the top m
cons: very expensive & slow
pro: works with off-the-shelf LLMs
2) Self-Reflection: https://arxiv.org/pdf/2405.06682
If incorrect response pass the self-reflection feedback back to an LLM before attempting to re-answer again;
As an input self-reflection gets a gold answer and is prompted to explain how it would now solve the problem. The results are redacted before passing back the feedback to avoid leaking the solution.
Even re-answering given only a binary feedback (“your previous answer was incorrect”) is significantly stronger than the baseline (no feedback, just sample a response once).
3) Self-Contrast: https://arxiv.org/pdf/2401.02009
a) create multiple solutions by evaluating diverse prompts derived from the original question (yields diverse perspectives on how to solve the problem
b) pairwise contrast the solutions
c) generate a todo checklist in order to revise the generations from a)
4) Think Before You Speak: https://arxiv.org/pdf/2311.07445
Introduces the CSIM method: 5 prompts that make the model better at dialogue applications.
5 prompts they use to help improve the communication skills are "empathy", "topic transition", "proactively asking questions", "concept guidance", "summarizing often".
Their LLM has 2 roles: thinking and speaking. The thinking role, or the “inner monologue” is occasionally triggered by the 5 prompts and is not displayed to the user but is instead used as the input for the user-facing speaking role.
I think these 5 bullet points nicely captures the main modes of prompt-based methods i've observed -> lmk if I missed an important one!
--- learning-based -> coming up in the follow-up post
2/11
@gordic_aleksa
One more here (I guess I should have classified this bucket as not a learning-based instead of prompt-based...anyhow ):
):
Chain-of-Thought Reasoning w/o prompting: https://arxiv.org/pdf/2402.10200
Introduces CoT-decoding method showing that pre-trained LMs can reason w/o excplicit CoT prompting.
The idea is simple: sample top-k paths and compute the average difference between the probability of the 1st and 2nd most likely token along the answer’s token sequence. Take the path that maximizes this metric - that is likely the CoT path.
Has a good argument against the CoT self-consistency method: most of the solutions they sample are incorrect, only using their heuristic they pick the implicit CoT traces.
3/11
@Ki_Seki_here
There are more options here.
[Quoted tweet]
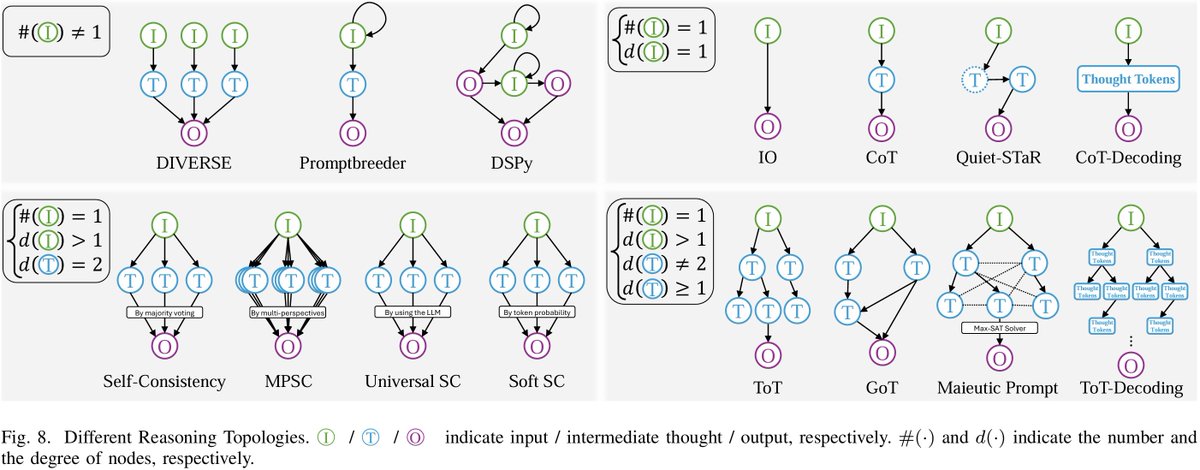
Here, I'd like to share one line: reasoning topologically. @OpenAI o1 uses one such technique, Quiet-STaR. Beyond this, there are other related techniques: optimizing the input , introducing more topological relationships, applying inference in decoding phase...
10/11
4/11
@bate5a55
Fascinating breakdown! Interestingly, OpenAI's o1 reportedly employs a dynamic Tree of Thoughts during inference, allowing it to adaptively optimize reasoning paths in real-time—almost like crafting its own cognitive map on the fly.
5/11
@sabeerawa05
Superb!
6/11
@CoolMFcat
Youtube video when
7/11
@Mikuk84
Thanks so much for the paper list!
8/11
@marinac_dev
What about swarm they released recently?
IMO I think o1 is swarm principle just on steroids.
9/11
@attention_gan
Does that mean it is not actually thinking but trying to use a combination of steps seen in the data
10/11
@joao_monoirelia
.
11/11
@MarkoVelich
Nice overview. Recently I did a talk on this topic. Put a bunch of reference throughout: Intuition Behind Reasoning in LLMs
My view on all these post-training/prompting techniques is that it is basically a filtering of the pre-train corpus. Ways to squeeze out good traces from the model.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@gordic_aleksa
How does OpenAI's o1 exactly work? Here is a list of papers & summaries on LLM reasoning that I've recently read.
I'll split them into 2 categories:
1) prompt-based - enforce step by step reasoning & self-correcting flow purely using prompts
2) learning-based - bake in the above into the policy model's weights (or into a verifier - usually a PRM; process reward model)
--- Prompt-based
0) CoT et al: https://arxiv.org/pdf/2201.11903
Ground zero (plus I'm a C guy :P iykyk). It started with Chain-of-Thought paper. This class of methods boils down to asking the LLM nicely to reveal its internal thoughts (e.g. "Let's think step by step"; more generally telling the model to disclose the intermediate computation steps in someway).
A simple variation on CoT would be "CoT self-consistency" -> i.e. sample multiple CoT traces in parallel and use majority voting to find the "right" answer.
1) ToT (tree of thought): https://arxiv.org/pdf/2305.10601
Further complexifies the above (in CS terms we go from linear list -> tree): build up an m-ary tree of intermediate thoughts (thoughts = intermediate steps of CoT); at each thought/node:
a) run the “propose next thoughts” prompt (or just sample completions m times)
b) evaluate those thoughts (either independently or jointly)
c) keep the top m
cons: very expensive & slow
pro: works with off-the-shelf LLMs
2) Self-Reflection: https://arxiv.org/pdf/2405.06682
If incorrect response pass the self-reflection feedback back to an LLM before attempting to re-answer again;
As an input self-reflection gets a gold answer and is prompted to explain how it would now solve the problem. The results are redacted before passing back the feedback to avoid leaking the solution.
Even re-answering given only a binary feedback (“your previous answer was incorrect”) is significantly stronger than the baseline (no feedback, just sample a response once).
3) Self-Contrast: https://arxiv.org/pdf/2401.02009
a) create multiple solutions by evaluating diverse prompts derived from the original question (yields diverse perspectives on how to solve the problem
b) pairwise contrast the solutions
c) generate a todo checklist in order to revise the generations from a)
4) Think Before You Speak: https://arxiv.org/pdf/2311.07445
Introduces the CSIM method: 5 prompts that make the model better at dialogue applications.
5 prompts they use to help improve the communication skills are "empathy", "topic transition", "proactively asking questions", "concept guidance", "summarizing often".
Their LLM has 2 roles: thinking and speaking. The thinking role, or the “inner monologue” is occasionally triggered by the 5 prompts and is not displayed to the user but is instead used as the input for the user-facing speaking role.
I think these 5 bullet points nicely captures the main modes of prompt-based methods i've observed -> lmk if I missed an important one!
--- learning-based -> coming up in the follow-up post
2/11
@gordic_aleksa
One more here (I guess I should have classified this bucket as not a learning-based instead of prompt-based...anyhow
):Chain-of-Thought Reasoning w/o prompting: https://arxiv.org/pdf/2402.10200
Introduces CoT-decoding method showing that pre-trained LMs can reason w/o excplicit CoT prompting.
The idea is simple: sample top-k paths and compute the average difference between the probability of the 1st and 2nd most likely token along the answer’s token sequence. Take the path that maximizes this metric - that is likely the CoT path.
Has a good argument against the CoT self-consistency method: most of the solutions they sample are incorrect, only using their heuristic they pick the implicit CoT traces.
3/11
@Ki_Seki_here
There are more options here.
[Quoted tweet]
Here, I'd like to share one line: reasoning topologically. @OpenAI o1 uses one such technique, Quiet-STaR. Beyond this, there are other related techniques: optimizing the input , introducing more topological relationships, applying inference in decoding phase...
10/11
4/11
@bate5a55
Fascinating breakdown! Interestingly, OpenAI's o1 reportedly employs a dynamic Tree of Thoughts during inference, allowing it to adaptively optimize reasoning paths in real-time—almost like crafting its own cognitive map on the fly.
5/11
@sabeerawa05
Superb!
6/11
@CoolMFcat
Youtube video when
7/11
@Mikuk84
Thanks so much for the paper list!
8/11
@marinac_dev
What about swarm they released recently?
IMO I think o1 is swarm principle just on steroids.
9/11
@attention_gan
Does that mean it is not actually thinking but trying to use a combination of steps seen in the data
10/11
@joao_monoirelia
.
11/11
@MarkoVelich
Nice overview. Recently I did a talk on this topic. Put a bunch of reference throughout: Intuition Behind Reasoning in LLMs
My view on all these post-training/prompting techniques is that it is basically a filtering of the pre-train corpus. Ways to squeeze out good traces from the model.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/9
@gordic_aleksa
How does OpenAI's o1 exactly work? Part 2. Here is a list of papers & summaries on LLM reasoning that I've recently read. All learning-based.
0) STaR: Self-Taught Reasoner https://arxiv.org/pdf/2203.14465
Ground Zero. Instead of always having to CoT prompt, bake that into the default model behavior. Given a dataset of (question, answer) pairs, manually curate a few CoT traces and use them as fewshot examples to generate (rationale, answer) tuples, given a question, for the rest of the dataset ("bootstrap reasoning"). SFT on (question, rationale, answer) triples. Do multiple iterations of this i.e. collect data retrain and keep sampling from that new policy (in practice I've observed people use ~3 iterations). Con: can only learn from correct triples.
1) V-STaR: https://arxiv.org/pdf/2402.06457
A variation on STaR. Collect both correct/incorrect samples. Incorrect ones can be used to train a verifier LLM via DPO. During inference additionally use the verifier to rank the generations.
---
[Recommended reading for 2) below]
Let’s Verify Step by Step: https://arxiv.org/pdf/2305.20050
They train a Process Supervision Reward Model PRM and show its advantage over Outcome Supervision RM - ORM (i.e. don't just pass a whole generation and ask for how good it is, pass in individual CoT elements instead; finer resolution).
Data collection: Humans were employed to annotate each line of step-by-step solutions (math problems) - expensive!! They've been given a curated list of samples that were automatically selected as “convincing wrong-answer” solutions - a form of hard sample mining.
---
2) Improve Mathematical Reasoning in LMs: https://arxiv.org/pdf/2406.06592
Proposes OmegaPRM - a process RM trained on data collected using MCTS (AlphaGo vibes? yes, paper comes from DeepMind). As a policy for collecting PRM data they used a SFT-ed Gemini Pro (instruct samples distilled from Gemini Ultra). Gemini Pro combined with OmegaPRM-weighted majority voting yielded nice improvements on math benchmarks. Suitable only when there is a golden answer, doesn’t work for open-ended tasks.
3) Learn Beyond The Answer: https://arxiv.org/pdf/2406.12050
Instead of increasing the number of samples in SFT dataset (STaR-like) they augment/extend the samples by appending a reflection to the existing (q,a) tuple. Reflection = alternative reasoning and follow-ups like analogy & abstraction). Complementary to STaR.
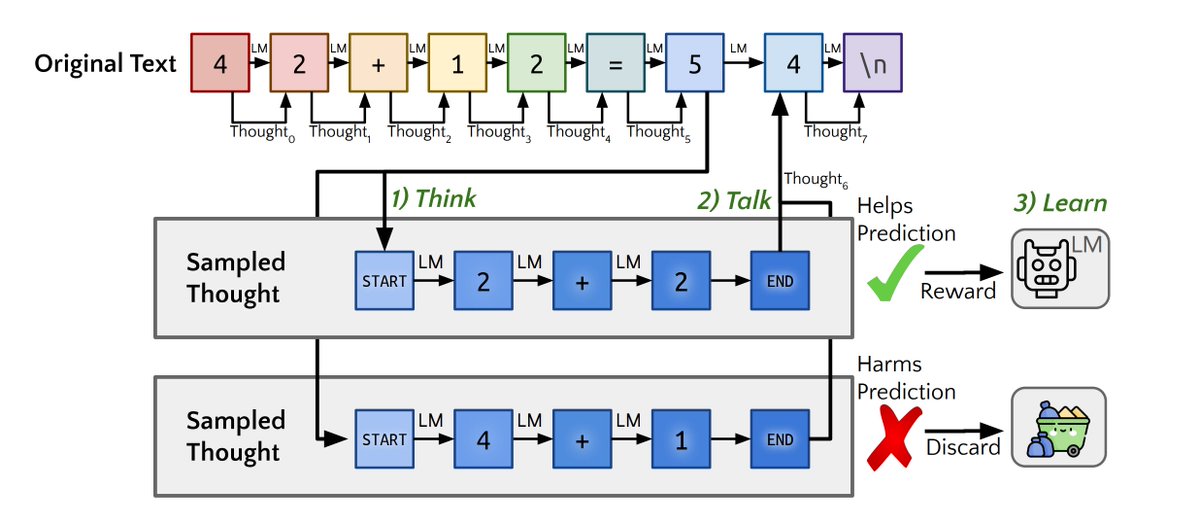
4) Quiet-STaR: https://arxiv.org/pdf/2403.09629
Uses RL (reinforce method) and picks rationales, which branch off of a thought, that increase the likelihood of the correct answer and subsequently trains on them. Adds new start/end of thinking tokens, and an MLP for mixing the rationale stream with the default stream. Interesting ideas, I feel that due to its complexity it won't survive Bitter Lesson's filter.
5) Scaling LLM Test-Time Compute: https://arxiv.org/pdf/2408.03314
They first estimate the difficulty of a user query placing it into one out of 5 difficulty bins (i think they need 2048 samples for this!). Then depending on the query’s difficulty they deploy various techniques to estimate the optimal results.
They experimented with 2 categories of methods: search requires a PRM verifier) & revisions (afaik they only did intra-comparisons, i.e. they didn’t compare search vs revision).
For search they experimented with best-of-N-weighted, beam, and lookahead.
For easier Qs best-of-N is the best method, later it’s beam (lookahead never pays off). For revision they first do SFT on samples that consist out of 0-4 incorrect intermediate steps followed by the correct solution (to teach it to self-correct). Subsequently they test applying it sequentially vs in parallel. There exists an “optimal” ratio of sequential-to-parallel depending on the difficulty bin.
6) Agent Q: https://arxiv.org/pdf/2408.07199
Really the main idea is to use MCTS to do test-time search (according to the perf they get not according to paper authors).
The second core idea is to leverage successful & unsuccessful trajectories collected using a “guided MCTS” (guided by an LLM judge) to improve the base policy via DPO, this gives them the “Agent Q”. Agent Q + test-time MCTS yields the best results.
Note: they operate in a very specific environment - web and focus on a narrow task: booking a table.
7) Training LMs to Self-Correct via RL: https://arxiv.org/pdf/2409.12917
They introduce SCoRe, a multi-turn (multi=2) RL method. They show that STaR methods fail to improve in a multi-turn setup (due to behavior collapse as measured by the edit distance histogram; i.e. STaR models are reluctant to deviate significantly from their 1st solution).
Training proceeds in 2 stages:
1) train the base model to produce high reward responses at the 2nd attempt while forcing the model not to change its 1st attempt (via KL div)
2) jointly maximize reward of both attempts; in order to prevent a collapse to a non-self-correcting behavior they do reward shaping by adding an additional penalty that rewards the model if it achieves higher reward on the 2nd attempt and heavily penalizes the transitions from correct->incorrect.
---
That's a wrap for now, so how does o1 work?
No idea, but likely involves above ideas + a shyt ton of compute & scale (data, params).
Let me know if I missed an important paper that's not an obvious interpolation of the above ideas (unless it's seminal despite that?).
2/9
@gordic_aleksa
thanks @_philschmid for aggregating the list LLM Reasoning Papers - a philschmid Collection
3/9
@JUQ_AI
Are you impressed with o1?
4/9
@barrettlattimer
Thanks for making this list! Another is
Sparse Rewards Can Self-Train Dialogue Agents: https://arxiv.org/pdf/2409.04617
Introduces JOSH, an algorithm that uses sparse rewards to extract the ideal behavior of a model in multi turn dialogue and improves quality for small & frontier models
5/9
@neurosp1ke
I would be very interested in creating a “must-read-essentials” short-list of the GitHub - open-thought/system-2-research: System 2 Reasoning Link Collection list. I will take your list as a first candidate.
6/9
@axel_pond
top quality content, king
7/9
@synthical_ai
Dark mode for this paper for those who read at night STaR: Bootstrapping Reasoning With Reasoning
STaR: Bootstrapping Reasoning With Reasoning
8/9
@MapaloChansa1
Interesting
9/9
@eatnow240008
[2310.04363] Amortizing intractable inference in large language models
Perhaps this?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@gordic_aleksa
How does OpenAI's o1 exactly work? Part 2. Here is a list of papers & summaries on LLM reasoning that I've recently read. All learning-based.
0) STaR: Self-Taught Reasoner https://arxiv.org/pdf/2203.14465
Ground Zero. Instead of always having to CoT prompt, bake that into the default model behavior. Given a dataset of (question, answer) pairs, manually curate a few CoT traces and use them as fewshot examples to generate (rationale, answer) tuples, given a question, for the rest of the dataset ("bootstrap reasoning"). SFT on (question, rationale, answer) triples. Do multiple iterations of this i.e. collect data retrain and keep sampling from that new policy (in practice I've observed people use ~3 iterations). Con: can only learn from correct triples.
1) V-STaR: https://arxiv.org/pdf/2402.06457
A variation on STaR. Collect both correct/incorrect samples. Incorrect ones can be used to train a verifier LLM via DPO. During inference additionally use the verifier to rank the generations.
---
[Recommended reading for 2) below]
Let’s Verify Step by Step: https://arxiv.org/pdf/2305.20050
They train a Process Supervision Reward Model PRM and show its advantage over Outcome Supervision RM - ORM (i.e. don't just pass a whole generation and ask for how good it is, pass in individual CoT elements instead; finer resolution).
Data collection: Humans were employed to annotate each line of step-by-step solutions (math problems) - expensive!! They've been given a curated list of samples that were automatically selected as “convincing wrong-answer” solutions - a form of hard sample mining.
---
2) Improve Mathematical Reasoning in LMs: https://arxiv.org/pdf/2406.06592
Proposes OmegaPRM - a process RM trained on data collected using MCTS (AlphaGo vibes? yes, paper comes from DeepMind). As a policy for collecting PRM data they used a SFT-ed Gemini Pro (instruct samples distilled from Gemini Ultra). Gemini Pro combined with OmegaPRM-weighted majority voting yielded nice improvements on math benchmarks. Suitable only when there is a golden answer, doesn’t work for open-ended tasks.
3) Learn Beyond The Answer: https://arxiv.org/pdf/2406.12050
Instead of increasing the number of samples in SFT dataset (STaR-like) they augment/extend the samples by appending a reflection to the existing (q,a) tuple. Reflection = alternative reasoning and follow-ups like analogy & abstraction). Complementary to STaR.
4) Quiet-STaR: https://arxiv.org/pdf/2403.09629
Uses RL (reinforce method) and picks rationales, which branch off of a thought, that increase the likelihood of the correct answer and subsequently trains on them. Adds new start/end of thinking tokens, and an MLP for mixing the rationale stream with the default stream. Interesting ideas, I feel that due to its complexity it won't survive Bitter Lesson's filter.
5) Scaling LLM Test-Time Compute: https://arxiv.org/pdf/2408.03314
They first estimate the difficulty of a user query placing it into one out of 5 difficulty bins (i think they need 2048 samples for this!). Then depending on the query’s difficulty they deploy various techniques to estimate the optimal results.
They experimented with 2 categories of methods: search requires a PRM verifier) & revisions (afaik they only did intra-comparisons, i.e. they didn’t compare search vs revision).
For search they experimented with best-of-N-weighted, beam, and lookahead.
For easier Qs best-of-N is the best method, later it’s beam (lookahead never pays off). For revision they first do SFT on samples that consist out of 0-4 incorrect intermediate steps followed by the correct solution (to teach it to self-correct). Subsequently they test applying it sequentially vs in parallel. There exists an “optimal” ratio of sequential-to-parallel depending on the difficulty bin.
6) Agent Q: https://arxiv.org/pdf/2408.07199
Really the main idea is to use MCTS to do test-time search (according to the perf they get not according to paper authors).
The second core idea is to leverage successful & unsuccessful trajectories collected using a “guided MCTS” (guided by an LLM judge) to improve the base policy via DPO, this gives them the “Agent Q”. Agent Q + test-time MCTS yields the best results.
Note: they operate in a very specific environment - web and focus on a narrow task: booking a table.
7) Training LMs to Self-Correct via RL: https://arxiv.org/pdf/2409.12917
They introduce SCoRe, a multi-turn (multi=2) RL method. They show that STaR methods fail to improve in a multi-turn setup (due to behavior collapse as measured by the edit distance histogram; i.e. STaR models are reluctant to deviate significantly from their 1st solution).
Training proceeds in 2 stages:
1) train the base model to produce high reward responses at the 2nd attempt while forcing the model not to change its 1st attempt (via KL div)
2) jointly maximize reward of both attempts; in order to prevent a collapse to a non-self-correcting behavior they do reward shaping by adding an additional penalty that rewards the model if it achieves higher reward on the 2nd attempt and heavily penalizes the transitions from correct->incorrect.
---
That's a wrap for now, so how does o1 work?
No idea, but likely involves above ideas + a shyt ton of compute & scale (data, params).
Let me know if I missed an important paper that's not an obvious interpolation of the above ideas (unless it's seminal despite that?
).
2/9
@gordic_aleksa
thanks @_philschmid for aggregating the list LLM Reasoning Papers - a philschmid Collection
3/9
@JUQ_AI
Are you impressed with o1?
4/9
@barrettlattimer
Thanks for making this list! Another is
Sparse Rewards Can Self-Train Dialogue Agents: https://arxiv.org/pdf/2409.04617
Introduces JOSH, an algorithm that uses sparse rewards to extract the ideal behavior of a model in multi turn dialogue and improves quality for small & frontier models
5/9
@neurosp1ke
I would be very interested in creating a “must-read-essentials” short-list of the GitHub - open-thought/system-2-research: System 2 Reasoning Link Collection list. I will take your list as a first candidate.
6/9
@axel_pond
top quality content, king
7/9
@synthical_ai
Dark mode for this paper for those who read at night
STaR: Bootstrapping Reasoning With Reasoning8/9
@MapaloChansa1
Interesting
9/9
@eatnow240008
[2310.04363] Amortizing intractable inference in large language models
Perhaps this?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196



































