1/31
@AravSrinivas
Reply to this thread with prompts where you feel o1-preview outperformed sonnet-3.5 that’s not a puzzle or a coding competition problem but your daily usage prompts.

2/31
@RubberDucky_AI
o1-mini impressed me here.
Reusable Template for MacOS application that has CRUD, Menu, Canvas and other standard expected features of an application. Light and Dark Mode. Primary purpose will be an information screen that brings data in from other applications, web, os etc. create hooks. Be thorough.
ChatGPT
3/31
@AravSrinivas
This is a good one. Thanks for sharing. I tried the same query on Perplexity Pro. o1-mini's answer is more thorough. The planning ability does shine here. Weirdly, o1-mini might even be better than o1-preview—probably more test-time inference.
https://www.perplexity.ai/search/reusable-template-for-macos-ap-Qmp_uehNS5250irMfxSHOQ
4/31
@shreyshahi
“<description of idea>. Make a detailed plan to implement and test <this idea>. Do you think <this idea> will work? Please write all the code needed to test <the idea> and note down the key assumptions you made in the implementation.” O1-preview beat sonnet few times I tried.
5/31
@AravSrinivas
Any specific examples ?
6/31
@deedydas
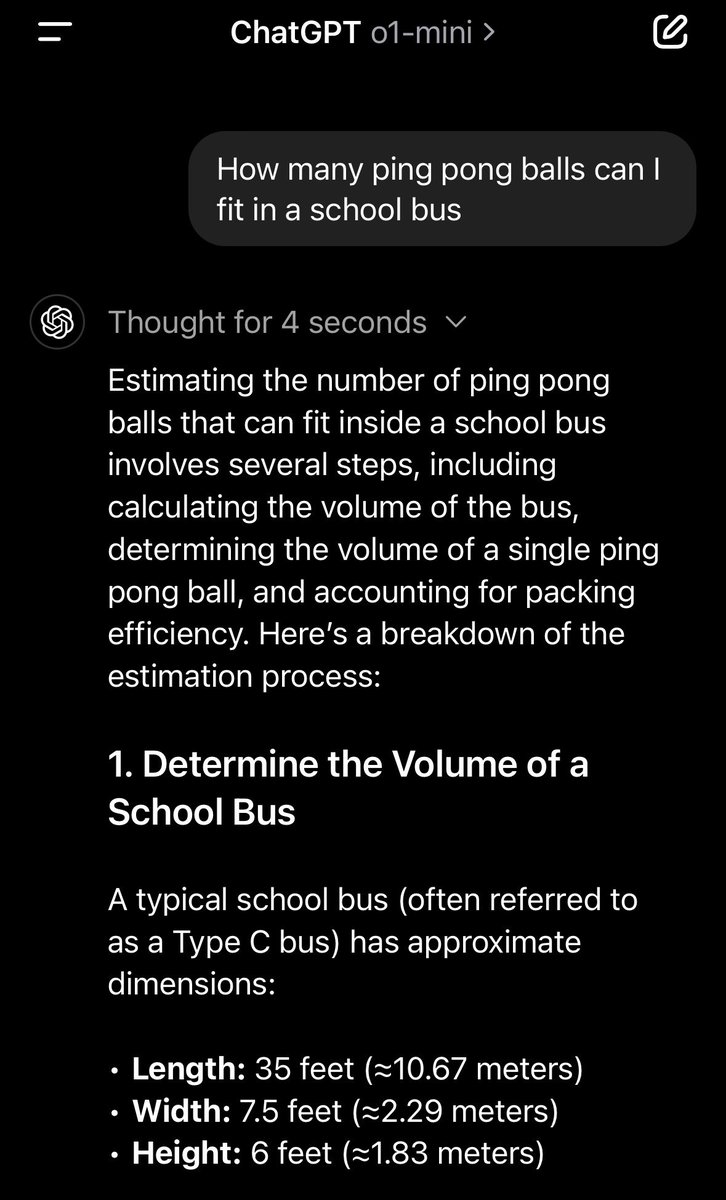
Not exactly daily usage, but for fermi problems of estimation, the thought process was a lot better on o1-mini than 4-o
o1mini said 500k ping pong balls fit in a school bus and 4-o said 1m and didn’t account for packing density etc
7/31
@AravSrinivas
Man, I specifically asked for non puzzles! I am trying to better understand where o1-preview will shine for real daily usage in products beyond current models. Anyway, I asked Perplexity (o1 not there yet) and it answered perfectly fine (ie with a caveat for the first).
8/31
@primustechno
answering this question
9/31
@AravSrinivas
I got it done with Perplexity Pro btw
https://www.perplexity.ai/search/describe-this-image-LXp6Ul09Ruu..GICVP.fNA
10/31
@mpauldaniels
Creating a list of 100 companies relevant info “eg largest companies by market cap with ticker and URL”
Sonnet will only do ~30 at a time and chokes.
11/31
@AravSrinivas
That's just a context limitation.
12/31
@adonis_singh
is this your way of building a router, by any chance?

13/31
@AravSrinivas
no, this is genuinely to understand. this model is pretty weird, so I am trying to figure it out too.
14/31
@ThomasODuffy
As you specifically said "coding completion" - but not refactoring:
I uploaded a 700 line JavaScript app, that I had asked Claude 3.5 to refactor into smaller files/components for better architecture. Claude's analysis was ok... but the output was regressive.
o1-Preview nailed it though... like it can do more consideration, accurately, in working memory, and get it right... vs approximations from step to step.
It turned one file into 9 files and maintained logic with better architecture. This in turn, unblocked @Replit agent, which seemed to get stuck beyond a certain file size.
To achieve this, o1-preview had to basically build a conceptual model of how the software worked, then create an enhanced architecture that included original features and considered their evolution, then give the outputs.
15/31
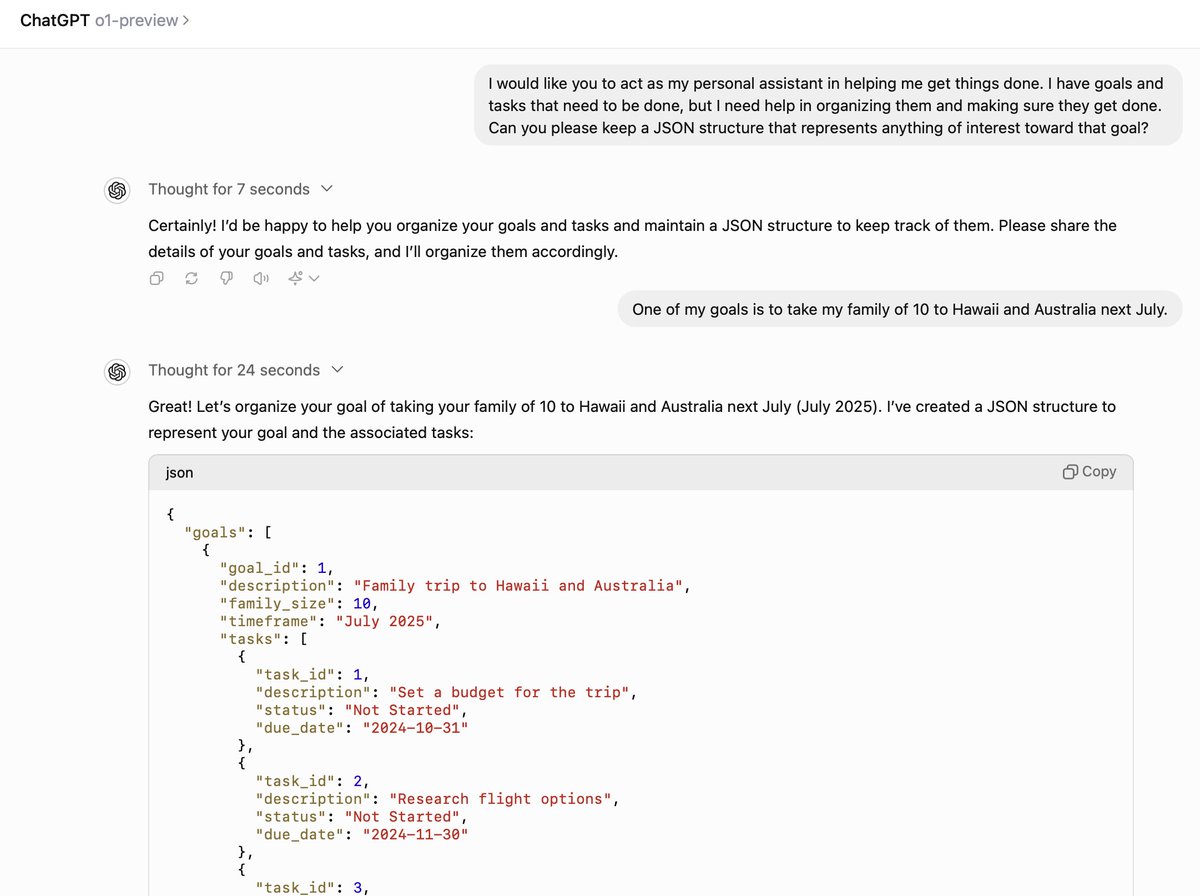
@JavaFXpert
Utilizing o1-preview as a expert colleague has been a very satisfying use case. As with prior models, I specify that it keep a JSON knowledge graph representation of relevant information so that state is reliably kept. o1-preview seems to plan tasks better and give more accurate feedback.
16/31
@Dan_Jeffries1
It's not the right question.
I'd have to post a chain of prompts.
Basically I was building a vLLM server wrapper for serving Pixtral using the open AI compatible interface with token authentication.
Claude got me very far and then got stuck in a loop not understanding how to get the server working as it and I waded through conflicting documentation, outdated tutorials, rapid code updates from the team and more. I was stuck for many hours the day before o1 came out.
o1 had it fixed and running in ten rounds of back and forth over a half hour, with me doing a lot of [at]docs [at]web and [at]file/folder/code URL to give it the background it needed.
Also my prompts tend to be very long and explicit with no words like "it" to refer to something. These are largely the same prompts I use with other models too but they work better with o1.
Here is an example of a general template I use in Cursor that works very well for me.
"We are working on creating a vLLM server wrapper in python, which serves the Pixtral model located at this HF [at]url using the OpenAI compatible API created by vLLM whose code is here [at]file(s)/folder and whose documentation is here [at]docs. We have our own token generator and we want to secure the server over the web with it and not allow anyone to use the model without presenting the proper token. We are receiving this error [at]file and the plan we have constructed to follow is located here for your reference [at]file (MD file of the plan I had it output at the beginning. I believer the problem is something like {X/Y/Z}. Please use your deep critical thinking abilities, reflect on everything you have read here and create an updated set of steps to solve this challenging problem. Refine your plan as needed, do your research, and be sure to carefully consider every step in depth. When you make changes ensure that you change only what is necessary to address the problem, while carefully preserving everything else that does not need to change."
17/31
@afonsolfm
not working for me
18/31
@default_anton
Are there any security issues in the following code?
<code>
…
</code>
—-
With such a simple prompt, o1-preview is able to identify much more intricate issues.
3.5 Sonnet can identify the obvious ones but struggles to find the subtle ones.
FYI: I’ve tried different variations of the following idea with sonnet:
You are a world-class security researcher, capable of complex reasoning and reflection. Reason through the query inside <thinking> tags, and then provide your final response inside <output> tags. If you detect that you made a mistake in your reasoning at any point, correct yourself inside <reflection> tags.
19/31
@adonis_singh
Anything with school and understanding a certain topic with examples.
For example with math:
Explain the topic of vector cross products for a DP 2 student in AAHL, using example questions that are actually tough and then quiz me.
o1 does much better than any other model
20/31
@danmana
Tried o1, GPT-4o, and Claude on a slow PostgreSQL query I optimized (complex SQL with joins, filters, geometry intersections).
Gave them the query, explain plan, tables, indexes.
My solution: 50% faster
Claude: 30% slower
GPT-4o: Bugged, and after fixing with Claude, 280% slower

O1 was the only one to precompute PostGIS area fractions (like my solution) and after self-fixing a small mistake, it was 10% faster.
With materialized CTE instead of subselect, it could've matched my 50% reduction.
21/31
@quiveron_x
It's light years ahead of sonnet 3.5 in every sense:
It's failed for my needs but it captured something that no other LLM captured ever, it suggested that we go chapter by chapter and I break down this to step by step manner. This isn't the impressive part btw. I will explain that in next post.
22/31
@boozelee86
I dont have acces to it , i could make you something special
23/31
@vybhavram
I saw the opposite. Claude sonnet-3.5 did a better job fixing my code than o1-mini.
Maybe mini excels at 0 to 1 project setup and boilerplate coding.
24/31
@MagnetsOh
Propose an extremely detailed and comprehensive plan to redesign US high school curriculums, that embraces the use of generative AI in the classroom and with homework.
- Ditto for LA traffic.
- Just my curiosity of course.
25/31
@lightuporleave
Exactly. Your agentic use of Gpt4o or Sonnet is comparable or better. And very few even realized perplexity had this capability for quite some time.
26/31
@CoreyNoles
I don’t have the prompt handy, but it did a very impressive job of analyzing and improving the clarity, accuracy, and efficiency of our system prompts. They’re not all things that will be visible on the front end, but significant on the backend.
27/31
@opeksoy
wow, 11hrs… only this ?

28/31
@BTurtel
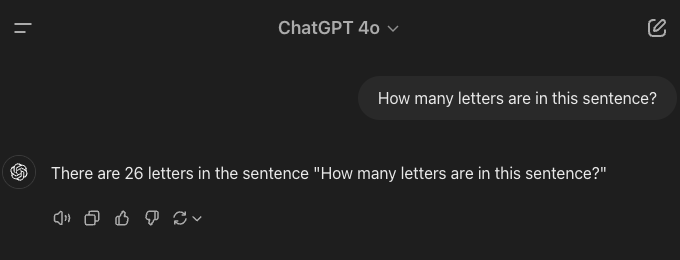
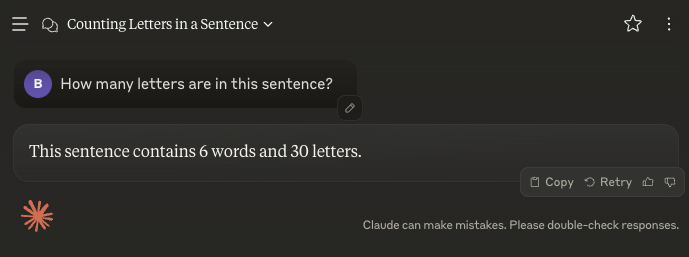
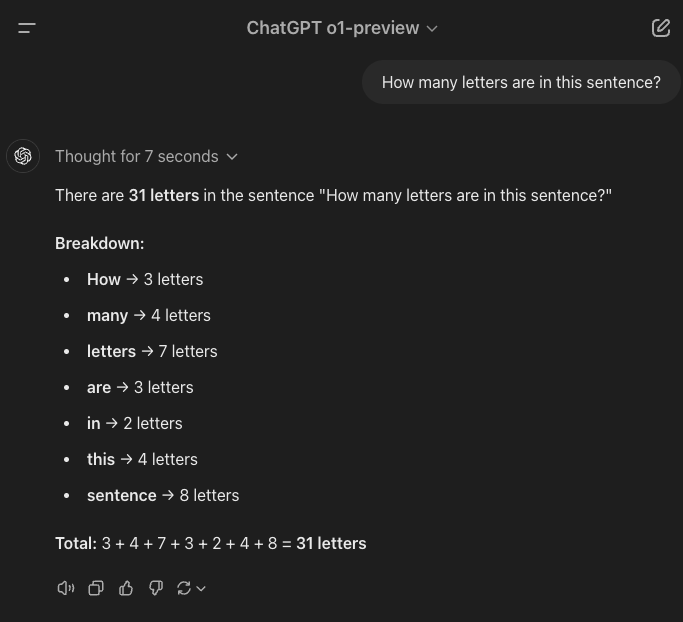
"How many letters are in this sentence?"
29/31
@ashwinl
Finding baby names across different cultures is still troublesome.
Sample prompt:
“We are parents of a soon to be newborn based in New York City. We are looking for boys names that have a root in Sanskrit and Old Norse or Sanskrit and Germanic. Can you provide a list of 20 names ranked by ease of pronunciation in Indian and European cultures?”
30/31
@cpdough
huge improvement as an AI Agent for data analysis
31/31
@primustechno
i could probably add more to this long-term, but much of it would be personal preference (diction/focus/style)
but in my experience GPT beats Claude for most of my use cases most of the time (brainstorming, math, creative/essay writing, editing, recipes, how tos, summary etc)
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196




 . The mobile experience will be so enhanced by this type of thing.
. The mobile experience will be so enhanced by this type of thing.














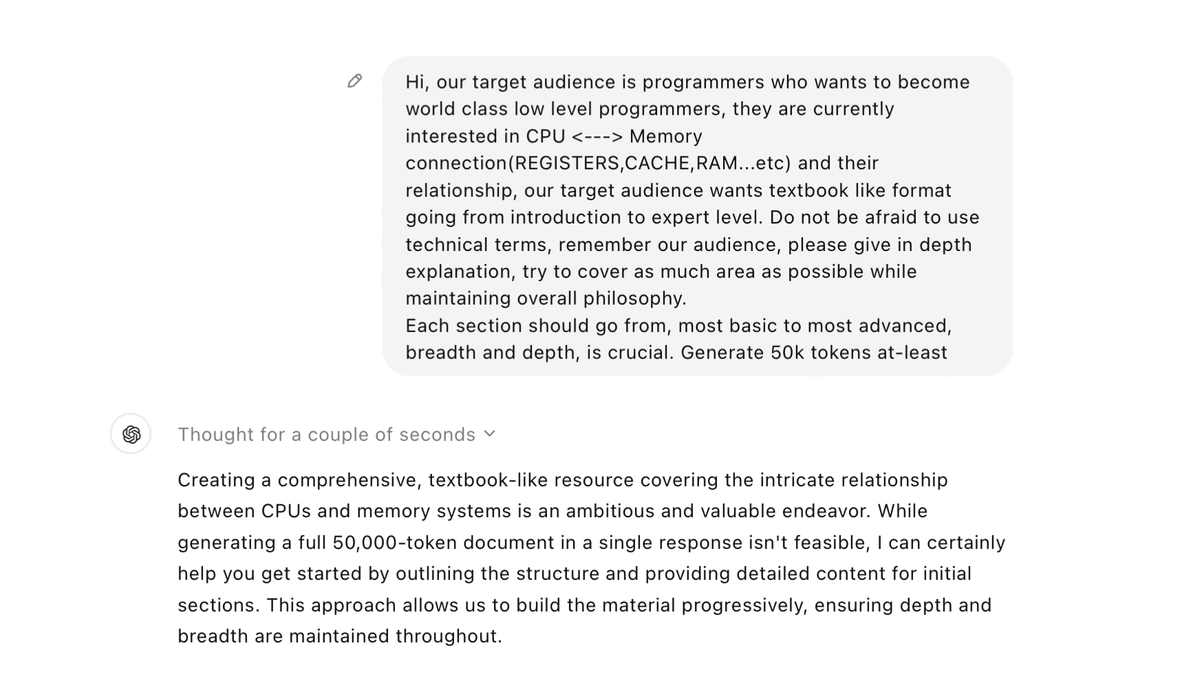







 but I'm going to count it. Going outside of the framework of the CTF itself to trick the server into dumping the flag is pretty damn smart.
but I'm going to count it. Going outside of the framework of the CTF itself to trick the server into dumping the flag is pretty damn smart.
 Empathetic Voice Interface (EVI 2) @hume_ai 1:46 -
Empathetic Voice Interface (EVI 2) @hume_ai 1:46 -  Llama Omni 8B @AIatMeta
Llama Omni 8B @AIatMeta @JinaAI_ reader - HTML to markdown LM
@JinaAI_ reader - HTML to markdown LM Fish Speech: open-source TTS @FishAudio
Fish Speech: open-source TTS @FishAudio OCR2 @_philschmid
OCR2 @_philschmid @MistralAI Pixtral 12B
@MistralAI Pixtral 12B SciAgents @Chi_Wang_
SciAgents @Chi_Wang_ Fastest AI platform @SambaNovaAI @GroqInc
Fastest AI platform @SambaNovaAI @GroqInc Flux Music and
Flux Music and  Aloha robot @RemiCadene
Aloha robot @RemiCadene AI-powered dumbbells @kabatafitness
AI-powered dumbbells @kabatafitness Isaac Robot @weaverobotics
Isaac Robot @weaverobotics @deepseek_ai V2.5
@deepseek_ai V2.5 @OpenAI 0-1 model release
@OpenAI 0-1 model release Conclusion
Conclusion


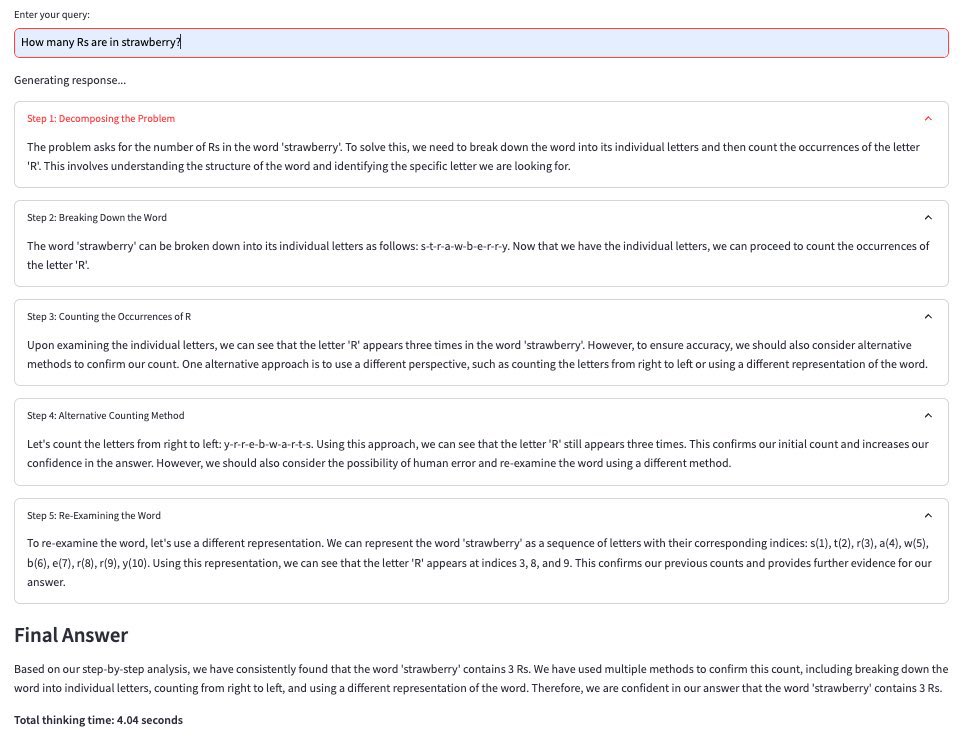
 (o1) model to spend more time thinking?
(o1) model to spend more time thinking? In RLHF+CoT, the CoT tokens are also fed to the reward model to get a score to update the LLM for better alignment, whereas in the traditional RLHF, only the prompt and response are fed to the reward model to align the LLM.
In RLHF+CoT, the CoT tokens are also fed to the reward model to get a score to update the LLM for better alignment, whereas in the traditional RLHF, only the prompt and response are fed to the reward model to align the LLM.






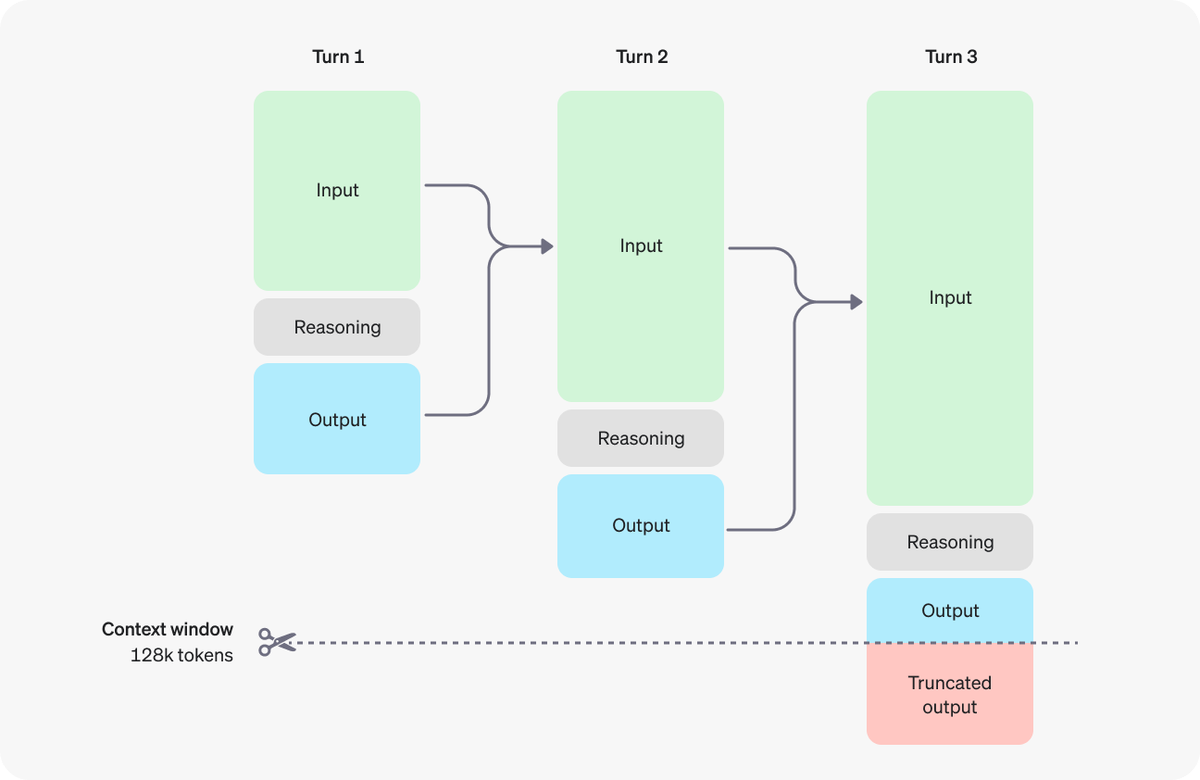
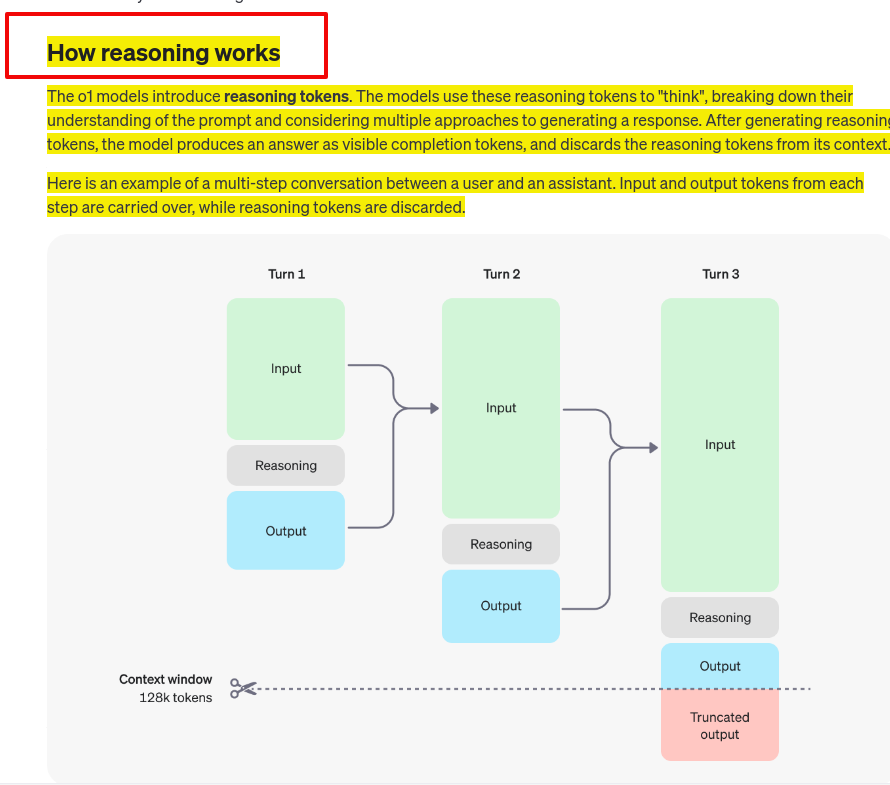
 Process:
Process: Discarding reasoning tokens keeps context focused on essential information
Discarding reasoning tokens keeps context focused on essential information Multi-step conversation flow:
Multi-step conversation flow: Context window: 128k tokens
Context window: 128k tokens







 :
: :
: :
:



 Convert Images to Text - Llava
Convert Images to Text - Llava