1/3
@rohanpaul_ai
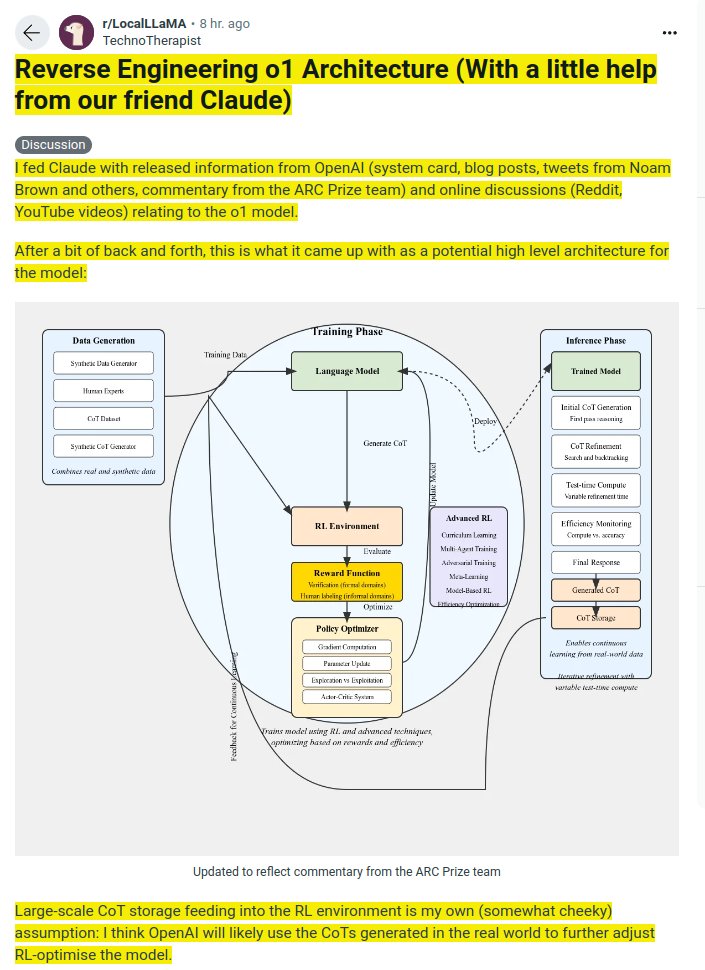
Reverse Engineering o1 OpenAI Architecture with Claude
2/3
@NorbertEnders
The reverse engineered o1 OpenAI Architecture simplified and explained in a more narrative style, using layman’s terms.
I used Claude Sonnet 3.5 for that.
Keep in mind: it’s just an educated guess
3/3
@NorbertEnders
Longer version:
Imagine a brilliant but inexperienced chef named Alex. Alex's goal is to become a master chef who can create amazing dishes on the spot, adapting to any ingredient or cuisine challenge. This is like our language model aiming to provide intelligent, reasoned responses to any query.
Alex's journey begins with intense preparation:
First, Alex gathers recipes. Some are from famous cookbooks, others from family traditions, and many are creative variations Alex invents. This is like our model's Data Generation phase, collecting a mix of real and synthetic data to learn from.
Next comes Alex's training. It's not just about memorizing recipes, but understanding the principles of cooking. Alex practices in a special kitchen (our Training Phase) where:
1. Basic cooking techniques are mastered (Language Model training).
2. Alex plays cooking games, getting points for tasty dishes and helpful feedback when things go wrong (Reinforcement Learning).
3. Sometimes, the kitchen throws curveballs - like changing ingredients mid-recipe or having multiple chefs compete (Advanced RL techniques).
This training isn't a one-time thing. Alex keeps learning, always aiming to improve.
Now, here's where the real magic happens - when Alex faces actual cooking challenges (our Inference Phase):
1. A customer orders a dish. Alex quickly thinks of a recipe (Initial CoT Generation).
2. While cooking, Alex tastes the dish and adjusts seasonings (CoT Refinement).
3. For simple dishes, Alex works quickly. For complex ones, more time is taken to perfect it (Test-time Compute).
4. Alex always keeps an eye on the clock, balancing perfection with serving time (Efficiency Monitoring).
5. Finally, the dish is served (Final Response).
6. Alex remembers this experience for future reference (CoT Storage).
The key here is Alex's ability to reason and adapt on the spot. It's not about rigidly following recipes, but understanding cooking principles deeply enough to create new dishes or solve unexpected problems.
What makes Alex special is the constant improvement. After each shift, Alex reviews the day's challenges, learning from successes and mistakes (feedback loop). Over time, Alex becomes more efficient, creative, and adaptable.
In our language model, this inference process is where the real value lies. It's the ability to take a query (like a cooking order), reason through it (like Alex combining cooking knowledge to create a dish), and produce a thoughtful, tailored response (serving the perfect dish).
The rest of the system - the data collection, the intense training - are all in service of this moment of creation. They're crucial, but they're the behind-the-scenes work. The real magic, the part that amazes the 'customers' (users), happens in this inference stage.
Just as a master chef can delight diners with unique, perfectly crafted dishes for any request, our advanced language model aims to provide insightful, reasoned responses to any query, always learning and improving with each interaction.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@rohanpaul_ai
Reverse Engineering o1 OpenAI Architecture with Claude
2/3
@NorbertEnders
The reverse engineered o1 OpenAI Architecture simplified and explained in a more narrative style, using layman’s terms.
I used Claude Sonnet 3.5 for that.
Keep in mind: it’s just an educated guess
3/3
@NorbertEnders
Longer version:
Imagine a brilliant but inexperienced chef named Alex. Alex's goal is to become a master chef who can create amazing dishes on the spot, adapting to any ingredient or cuisine challenge. This is like our language model aiming to provide intelligent, reasoned responses to any query.
Alex's journey begins with intense preparation:
First, Alex gathers recipes. Some are from famous cookbooks, others from family traditions, and many are creative variations Alex invents. This is like our model's Data Generation phase, collecting a mix of real and synthetic data to learn from.
Next comes Alex's training. It's not just about memorizing recipes, but understanding the principles of cooking. Alex practices in a special kitchen (our Training Phase) where:
1. Basic cooking techniques are mastered (Language Model training).
2. Alex plays cooking games, getting points for tasty dishes and helpful feedback when things go wrong (Reinforcement Learning).
3. Sometimes, the kitchen throws curveballs - like changing ingredients mid-recipe or having multiple chefs compete (Advanced RL techniques).
This training isn't a one-time thing. Alex keeps learning, always aiming to improve.
Now, here's where the real magic happens - when Alex faces actual cooking challenges (our Inference Phase):
1. A customer orders a dish. Alex quickly thinks of a recipe (Initial CoT Generation).
2. While cooking, Alex tastes the dish and adjusts seasonings (CoT Refinement).
3. For simple dishes, Alex works quickly. For complex ones, more time is taken to perfect it (Test-time Compute).
4. Alex always keeps an eye on the clock, balancing perfection with serving time (Efficiency Monitoring).
5. Finally, the dish is served (Final Response).
6. Alex remembers this experience for future reference (CoT Storage).
The key here is Alex's ability to reason and adapt on the spot. It's not about rigidly following recipes, but understanding cooking principles deeply enough to create new dishes or solve unexpected problems.
What makes Alex special is the constant improvement. After each shift, Alex reviews the day's challenges, learning from successes and mistakes (feedback loop). Over time, Alex becomes more efficient, creative, and adaptable.
In our language model, this inference process is where the real value lies. It's the ability to take a query (like a cooking order), reason through it (like Alex combining cooking knowledge to create a dish), and produce a thoughtful, tailored response (serving the perfect dish).
The rest of the system - the data collection, the intense training - are all in service of this moment of creation. They're crucial, but they're the behind-the-scenes work. The real magic, the part that amazes the 'customers' (users), happens in this inference stage.
Just as a master chef can delight diners with unique, perfectly crafted dishes for any request, our advanced language model aims to provide insightful, reasoned responses to any query, always learning and improving with each interaction.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196