
1/29
@sdianahu
Deepsilicon runs neural nets with 5x less RAM and ~20x faster. They are building SW and custom silicon for it.
What’s interesting is that they have proved it with SW, and you can even try it.
On why we funded them 1/7
2/29
@sdianahu
2/7 They found that representing transformer models as ternary values (-1, 0, 1) eliminates the need for computationally expensive floating-point math.
3/29
@sdianahu
3/7 So, there is no need for GPUs, which are good at floating point matrix operations, but energy and memory-hungry.
4/29
@sdianahu
4/7 They actually got SOTA models to run, overcoming the issues from the MSFT BitNet paper that inspired this. BitNet: Scaling 1-bit Transformers for Large Language Models - Microsoft Research.
5/29
@sdianahu
5/7 Now, you could run SOTA models that typically need HPC GPUs like H100s to make inferences on consumers or embedded GPUs like the NVIDIA Jetson.
This makes it possible for the first time to run SOTA models on embedded HW, such as robotics, that need that real-time response for inference.
6/29
@sdianahu
6/7 What NVDIA is overlooking, is the opportunity with specialized HW for inference, since they've been focused on the high end with the HPC cluster world.
7/29
@sdianahu
7/7 You can try it here for the SW version GitHub - deepsilicon/Sila
When they get the HW ready, the speedups and energy consumption will be even higher.
More details here too Launch HN: Deepsilicon (YC S24) – Software and hardware for ternary transformers | Hacker News
8/29
@sdianahu
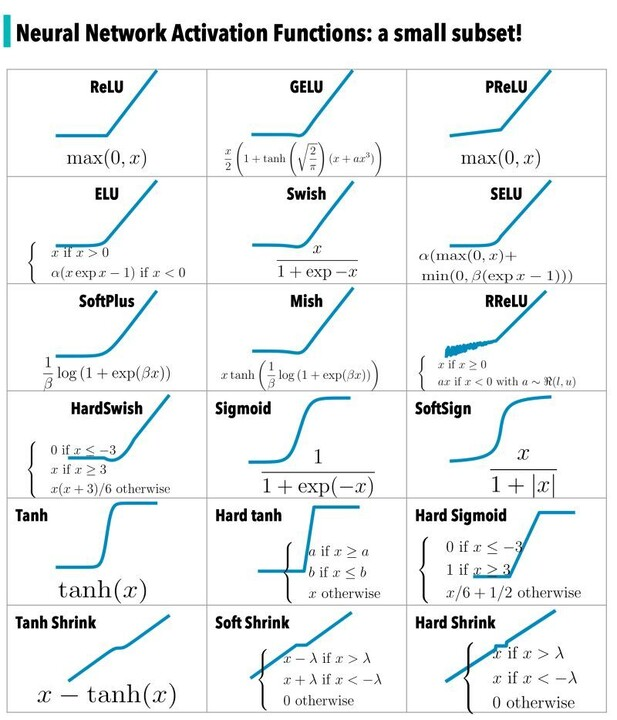
Intuitively this works, because neurons in DNN use activation functions that are S curved with 3 states. With only (-1,0,1), the dot product between matrices just becomes arithmetic.
9/29
@sdianahu
the OSS project at the moment converts a model to ternary through pretraining/distillation. It'll eventually have their ternary implementation. Stay tuned when the deepsilicon team updates Sila
10/29
@StephanSturges
interested in an intro as a potential customer
11/29
@gpt_biz
This sounds impressive, definitely worth checking out if you're into cutting-edge AI hardware development!
12/29
@gopal_kp
@threadreaderapp unroll
13/29
@threadreaderapp
@gopal_kp Guten Tag, the unroll you asked for: Thread by @sdianahu on Thread Reader App Talk to you soon.
14/29
@AsimovsOracle
Does this obviate NVidia entirely as a company, lol?
15/29
@EseralLabs
Now I have a good reason to use the Jetson
16/29
@adamviaja
I learned from context that SW stands for “software” in this context in case anyone else was also confused 🫶 cheers
cheers
17/29
@Rufus87078959
Impressive
18/29
@alexdanilo99
The founders are truly built different.
19/29
@uday_1212
Wow..!! This is really awesome..!! Will eagerly look forward to how this is going to take shape..
However we d still need GPUs for training tasks.. but inference is the major share
20/29
@timelessdev
Just software solution? I need to try.
21/29
@mattspergel
You still need to keep the model in a vector database?
22/29
@Karnage420x
I’m far too dumb to understand this.
23/29
@aitedmaster
Deepsilicon's innovation is exactly what we need to accelerate AI development. By optimizing RAM usage and boosting speed, they're pushing the boundaries of what's possible. Impressive that they're making it accessible through software too.
24/29
@cleantecher
y is the reduction in RAM needed if the code is efficient? whats the energy draw from good and bad written code and how does that change thermal effects on servers that r in farms being cooled by AC which will become uneconomical in 3 years and melt.
25/29
@shreyashdamania
How do you learn and understand these concepts from bottom up ?
Asking as a complete beginner.
BTW thankyou for the Lightcone podcast !!!
!!!
26/29
@CannaFirm
When is next round for them, can we buy some of your equity ??
27/29
@Photo_Jeff
Please give me a device I can plug into any USB-C port on Linux, MacOS, and Windows load up a model, and run inference. I don't need another Google TPU, Groq, or million dollar cloud based solution and Coral AI is dead.
28/29
@NRA29
Wow !
29/29
@mobadawy_
This technology exists and had been commercialized for over 15 years
They just dropped out of college and gave it a new name
Fixed points processors are used almost in every application around you
Who’s revising these applications?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@sdianahu
Deepsilicon runs neural nets with 5x less RAM and ~20x faster. They are building SW and custom silicon for it.
What’s interesting is that they have proved it with SW, and you can even try it.
On why we funded them 1/7
2/29
@sdianahu
2/7 They found that representing transformer models as ternary values (-1, 0, 1) eliminates the need for computationally expensive floating-point math.
3/29
@sdianahu
3/7 So, there is no need for GPUs, which are good at floating point matrix operations, but energy and memory-hungry.
4/29
@sdianahu
4/7 They actually got SOTA models to run, overcoming the issues from the MSFT BitNet paper that inspired this. BitNet: Scaling 1-bit Transformers for Large Language Models - Microsoft Research.
5/29
@sdianahu
5/7 Now, you could run SOTA models that typically need HPC GPUs like H100s to make inferences on consumers or embedded GPUs like the NVIDIA Jetson.
This makes it possible for the first time to run SOTA models on embedded HW, such as robotics, that need that real-time response for inference.
6/29
@sdianahu
6/7 What NVDIA is overlooking, is the opportunity with specialized HW for inference, since they've been focused on the high end with the HPC cluster world.
7/29
@sdianahu
7/7 You can try it here for the SW version GitHub - deepsilicon/Sila
When they get the HW ready, the speedups and energy consumption will be even higher.
More details here too Launch HN: Deepsilicon (YC S24) – Software and hardware for ternary transformers | Hacker News
8/29
@sdianahu
Intuitively this works, because neurons in DNN use activation functions that are S curved with 3 states. With only (-1,0,1), the dot product between matrices just becomes arithmetic.
9/29
@sdianahu
the OSS project at the moment converts a model to ternary through pretraining/distillation. It'll eventually have their ternary implementation. Stay tuned when the deepsilicon team updates Sila
10/29
@StephanSturges
interested in an intro as a potential customer
11/29
@gpt_biz
This sounds impressive, definitely worth checking out if you're into cutting-edge AI hardware development!
12/29
@gopal_kp
@threadreaderapp unroll
13/29
@threadreaderapp
@gopal_kp Guten Tag, the unroll you asked for: Thread by @sdianahu on Thread Reader App Talk to you soon.
14/29
@AsimovsOracle
Does this obviate NVidia entirely as a company, lol?
15/29
@EseralLabs
Now I have a good reason to use the Jetson
16/29
@adamviaja
I learned from context that SW stands for “software” in this context in case anyone else was also confused 🫶
cheers17/29
@Rufus87078959
Impressive
18/29
@alexdanilo99
The founders are truly built different.
19/29
@uday_1212
Wow..!! This is really awesome..!! Will eagerly look forward to how this is going to take shape..
However we d still need GPUs for training tasks.. but inference is the major share
20/29
@timelessdev
Just software solution? I need to try.
21/29
@mattspergel
You still need to keep the model in a vector database?
22/29
@Karnage420x
I’m far too dumb to understand this.
23/29
@aitedmaster
Deepsilicon's innovation is exactly what we need to accelerate AI development. By optimizing RAM usage and boosting speed, they're pushing the boundaries of what's possible. Impressive that they're making it accessible through software too.
24/29
@cleantecher
y is the reduction in RAM needed if the code is efficient? whats the energy draw from good and bad written code and how does that change thermal effects on servers that r in farms being cooled by AC which will become uneconomical in 3 years and melt.
25/29
@shreyashdamania
How do you learn and understand these concepts from bottom up ?
Asking as a complete beginner.
BTW thankyou for the Lightcone podcast
!!!26/29
@CannaFirm
When is next round for them, can we buy some of your equity ??
27/29
@Photo_Jeff
Please give me a device I can plug into any USB-C port on Linux, MacOS, and Windows load up a model, and run inference. I don't need another Google TPU, Groq, or million dollar cloud based solution and Coral AI is dead.
28/29
@NRA29
Wow !
29/29
@mobadawy_
This technology exists and had been commercialized for over 15 years
They just dropped out of college and gave it a new name
Fixed points processors are used almost in every application around you
Who’s revising these applications?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Last edited:




















