1/8
@rohanpaul_ai
This is ABSOLUTELY incredible to see -
AI outperforms humans in research ideation novelty
**Key Insights from this Paper **:
**:
• LLM-generated ideas are judged as more novel than human expert ideas
• AI ideas may be slightly less feasible than human ideas
• LLMs cannot reliably evaluate research ideas yet
-----
**Solution in this Paper** :
:
• Recruited 100+ NLP researchers for idea generation and blind review
• Developed an LLM ideation agent with:
- RAG-based paper retrieval
- Overgeneration of ideas (4000 per topic)
- LLM-based idea ranking
• Implemented strict controls:
- Standardized idea format and writing style
- Matched topic distribution between human and AI ideas
• Evaluated ideas on novelty, excitement, feasibility, effectiveness, and overall quality
-----
**Results** :
:
• AI ideas rated significantly more novel than human ideas (p < 0.05)
- Novelty score: 5.64 (AI) vs 4.84 (Human)
• AI ideas slightly less feasible than human ideas (not statistically significant)
- Feasibility score: 6.34 (AI) vs 6.61 (Human)
• Only 5% of AI-generated ideas were non-duplicates
• LLM evaluators showed lower agreement with human reviewers than inter-human agreement
- Best LLM evaluator accuracy: 53.3% vs Human inter-reviewer consistency: 56.1%
2/8
@rohanpaul_ai
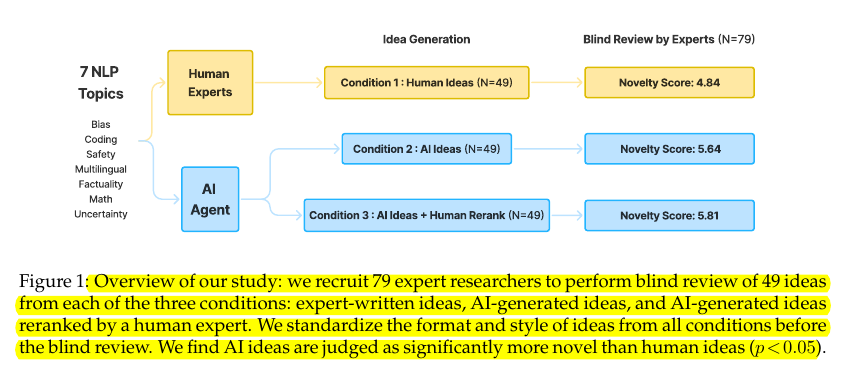
Overview of study:
- recruit 79 expert researchers to perform blind review of 49 ideas from each of the three conditions: expert-written ideas, AI-generated ideas, and AI-generated ideas reranked by a human expert.
- standardize the format and style of ideas from all conditions before the blind review. We find AI ideas are judged as significantly more novel than human ideas (p < 0.05 )
 [2409.04109] Can LLMs Generate Novel Research Ideas? A Large-Scale Human Study with 100+ NLP Researchers
[2409.04109] Can LLMs Generate Novel Research Ideas? A Large-Scale Human Study with 100+ NLP Researchers
3/8
@ChromeSub
They certainly can brainstorm and use other creativity techniques better than most people who are hung up by social norms and being judged by the perceived worth of their ideas. We tend to play it safe and offer only incremental changes.
4/8
@rohanpaul_ai
exactly, isn't it
5/8
@rohanpaul_ai
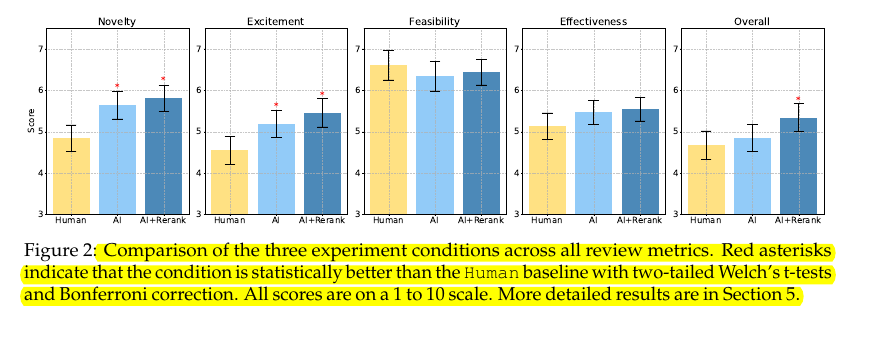
Comparison of the three experiment conditions across all review metrics.
Red asterisks indicate that the condition is statistically better than the Human baseline with two-tailed Welch’s t-tests and Bonferroni correction.
All scores are on a 1 to 10 scale.
6/8
@rohanpaul_ai
The “experts” in this study are the 'REAL' experts, some of the best people in the field.
Coming from 36 different institutions, our participants are mostly PhDs and postdocs.
As a proxy metric, their idea writers have a median citation count of 125, and their reviewers have 327.
7/8
@deter3
you might want to check my paper"Automating psychological hypothesis generation with AI: when large language models meet causal graph" Automating psychological hypothesis generation with AI: when large language models meet causal graph - Humanities and Social Sciences Communications , we have approved our workflow/algo can even generate novel hypothesis better than GPT4 and Phd .
8/8
@maledorak
Badge of “Type 1 Civilization of Kardashev scale” we are coming for you
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@rohanpaul_ai
This is ABSOLUTELY incredible to see -
AI outperforms humans in research ideation novelty
**Key Insights from this Paper
**:• LLM-generated ideas are judged as more novel than human expert ideas
• AI ideas may be slightly less feasible than human ideas
• LLMs cannot reliably evaluate research ideas yet
-----
**Solution in this Paper**
:• Recruited 100+ NLP researchers for idea generation and blind review
• Developed an LLM ideation agent with:
- RAG-based paper retrieval
- Overgeneration of ideas (4000 per topic)
- LLM-based idea ranking
• Implemented strict controls:
- Standardized idea format and writing style
- Matched topic distribution between human and AI ideas
• Evaluated ideas on novelty, excitement, feasibility, effectiveness, and overall quality
-----
**Results**
:• AI ideas rated significantly more novel than human ideas (p < 0.05)
- Novelty score: 5.64 (AI) vs 4.84 (Human)
• AI ideas slightly less feasible than human ideas (not statistically significant)
- Feasibility score: 6.34 (AI) vs 6.61 (Human)
• Only 5% of AI-generated ideas were non-duplicates
• LLM evaluators showed lower agreement with human reviewers than inter-human agreement
- Best LLM evaluator accuracy: 53.3% vs Human inter-reviewer consistency: 56.1%
2/8
@rohanpaul_ai
Overview of study:
- recruit 79 expert researchers to perform blind review of 49 ideas from each of the three conditions: expert-written ideas, AI-generated ideas, and AI-generated ideas reranked by a human expert.
- standardize the format and style of ideas from all conditions before the blind review. We find AI ideas are judged as significantly more novel than human ideas (p < 0.05 )
[2409.04109] Can LLMs Generate Novel Research Ideas? A Large-Scale Human Study with 100+ NLP Researchers3/8
@ChromeSub
They certainly can brainstorm and use other creativity techniques better than most people who are hung up by social norms and being judged by the perceived worth of their ideas. We tend to play it safe and offer only incremental changes.
4/8
@rohanpaul_ai
exactly, isn't it
5/8
@rohanpaul_ai
Comparison of the three experiment conditions across all review metrics.
Red asterisks indicate that the condition is statistically better than the Human baseline with two-tailed Welch’s t-tests and Bonferroni correction.
All scores are on a 1 to 10 scale.
6/8
@rohanpaul_ai
The “experts” in this study are the 'REAL' experts, some of the best people in the field.
Coming from 36 different institutions, our participants are mostly PhDs and postdocs.
As a proxy metric, their idea writers have a median citation count of 125, and their reviewers have 327.
7/8
@deter3
you might want to check my paper"Automating psychological hypothesis generation with AI: when large language models meet causal graph" Automating psychological hypothesis generation with AI: when large language models meet causal graph - Humanities and Social Sciences Communications , we have approved our workflow/algo can even generate novel hypothesis better than GPT4 and Phd .
8/8
@maledorak
Badge of “Type 1 Civilization of Kardashev scale” we are coming for you
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196







 Exciting news! We’ve officially launched DeepSeek-V2.5 – a powerful combination of DeepSeek-V2-0628 and DeepSeek-Coder-V2-0724! Now, with enhanced writing, instruction-following, and human preference alignment, it’s available on Web and API. Enjoy seamless Function Calling, FIM, and Json Output all-in-one!
Exciting news! We’ve officially launched DeepSeek-V2.5 – a powerful combination of DeepSeek-V2-0628 and DeepSeek-Coder-V2-0724! Now, with enhanced writing, instruction-following, and human preference alignment, it’s available on Web and API. Enjoy seamless Function Calling, FIM, and Json Output all-in-one!










 )
)













 what weights were mixed up ?
what weights were mixed up ?