1/58
We've created a demo of an AI that can predict the future at a superhuman level (on par with groups of human forecasters working together).
Consequently I think AI forecasters will soon automate most prediction markets.
demo:
FiveThirtyNine | Forecasting AI
blog:
Superhuman Automated Forecasting | CAIS
2/58
The bot could have been called "Nate Gold," but I didn't get permission from @NateSilver538 in time; hence it's FiveThirtyNine instead
3/58
@PTetlock @tylercowen @ezraklein @kevinroose
4/58
This is the prompt that does the heavy lifting
5/58
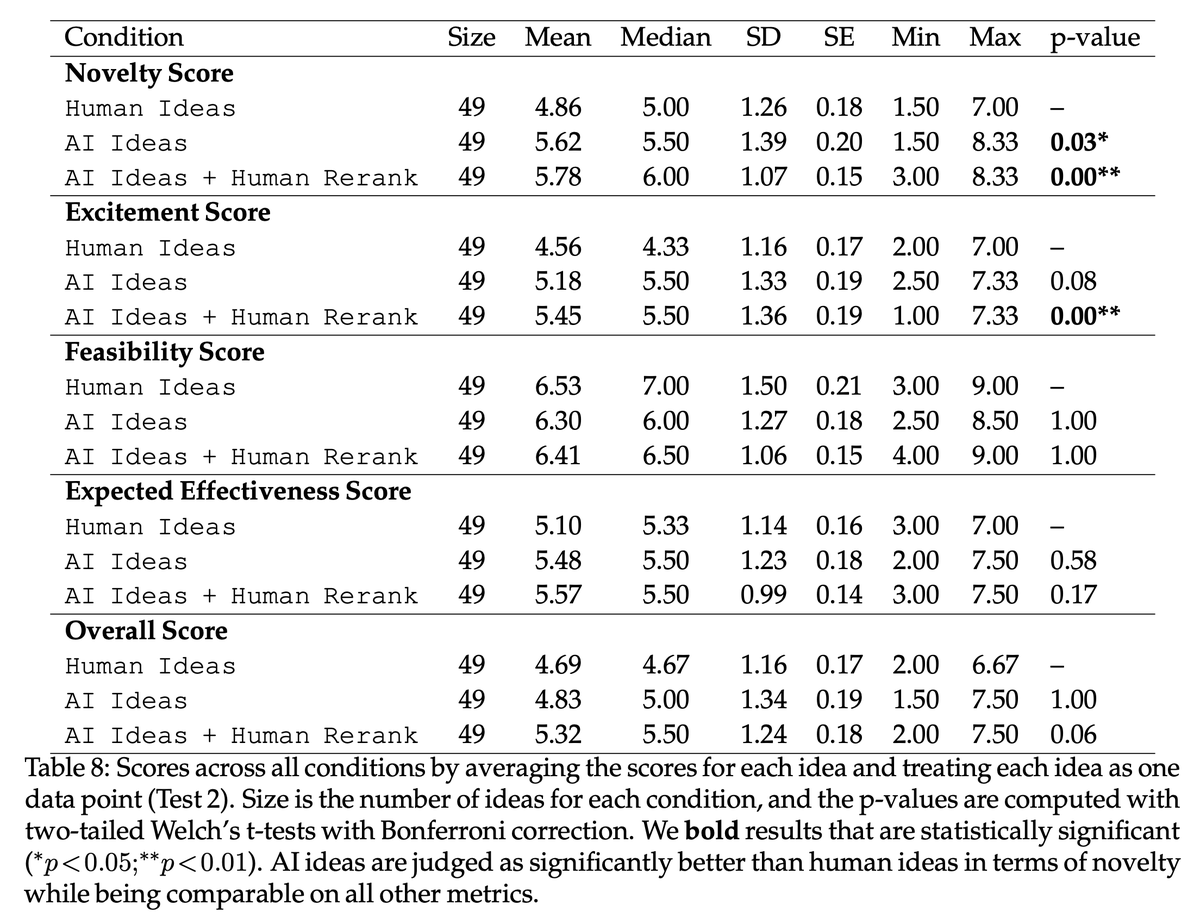
Some ways in which it is subhuman in delimited ways:
* If it's given an invalid query it will still forecast. I didn't bother to implement a reject option.
* If something is not in the pretraining distribution and if no articles are written about it, it doesn't know about it. (So if it's something that's just on X, it won't know about it, even if a human could.)
* For forecasts for very soon-to-resolve events, it does worse. (It finished pretraining a while ago so by default thinks Dean Phillips in the race and need to see articles to appreciate this.)
6/58
Hard to accept this number as meaningful when it doesn’t seem to understand that a legislative veto override is unlikely because it did not pass with a veto-proof majority
7/58
CA congress is different from US congress.
To my understanding even if it passed unanimously, it can be vetoed; CA congress can vote on it again to override the veto. However, this hasn't happened in ~40 years. So I think its understanding is correct.
8/58
are you worried about automation bias in your vision of having it embedded inline? seems like seeing a number could be pretty self reinforcing (whether it’s correct or not, or even mostly correct)
9/58
We mention automation bias in the blog post. I agree it's an issue to counteract.
10/58
Is there any pattern to when it did better or worse than the human forecasters?
11/58
For "will X happen by date Y" questions, it would do better to create a CDF with Y varying and then make a prediction consistent with that. I think its predictions on these types of questions could be improved with fine-tuning or more prompt engineering.
12/58
I asked it what the probability is that FiveThirtyNine would turn out to be flawed in some way, it did a bunch of google searches for FiveThirtyEight and gave me an answer about the Nate Silver feud. Maybe an unlucky first try, but so far this does not feel superhuman.
13/58
FiveThirtyNine is not in its pretraining distribution nor in any news articles. It doesn't have access to the twitter API.
14/58
I think there will be some substantive issue with this. Seems wrong.
I’ve put a limit order at 10% here for $50
Will there be substantive issues with Safe AI’s claim to forecast better than the Metaculus crowd, found before 2025?
15/58
Very cool!
Would you be open to sharing the dataset so others can try?
16/58
Don’t prediction markets rely on aggregated opinion based on infomation asymmetries among a large number of actors? How does this simulate that?
17/58
Very cool! Do you guys have a public dashboard or something to record historical predictions and their accuracy?
18/58
The linked repo is empty.
19/58
Reminds me of perplexity with the sources shown when processing the answer
20/58
The model doesn't seem to account for rapid AI progress, like when you ask it about the chances of a disease being cured by 2040, nothing it considers relates to AGI.
21/58
🫵

22/58
Is there any calibration ongoing or planned to be added? E.g., it said Trump 50 %, Harris 55 %.
23/58
Estimates vary a bit between different runs. We tried adding some consistency checks, which took 3x longer, and didn't help performance overall. My guess is a form of consistency fine-tuning could help though.
24/58
Paper?
25/58
... but why is it called FiveThirtyNine, did ya'll invade a microstate again
26/58
I think the second claim certainly does not follow, and frankly is ridiculous.
27/58
Mmmm
28/58
Jeez you could ask it to guess a dice roll and went for this instead
29/58
can you share more around the methodology for how news/data is sourced for the queries?
30/58
Does your AI make the same prediction?
31/58
FiveThirtyNine versus ElectionBettingOdds(.)com
This is will be an interesting AI/human divergence to monitor
32/58
sounds like a cool @perplexity_ai feature
33/58
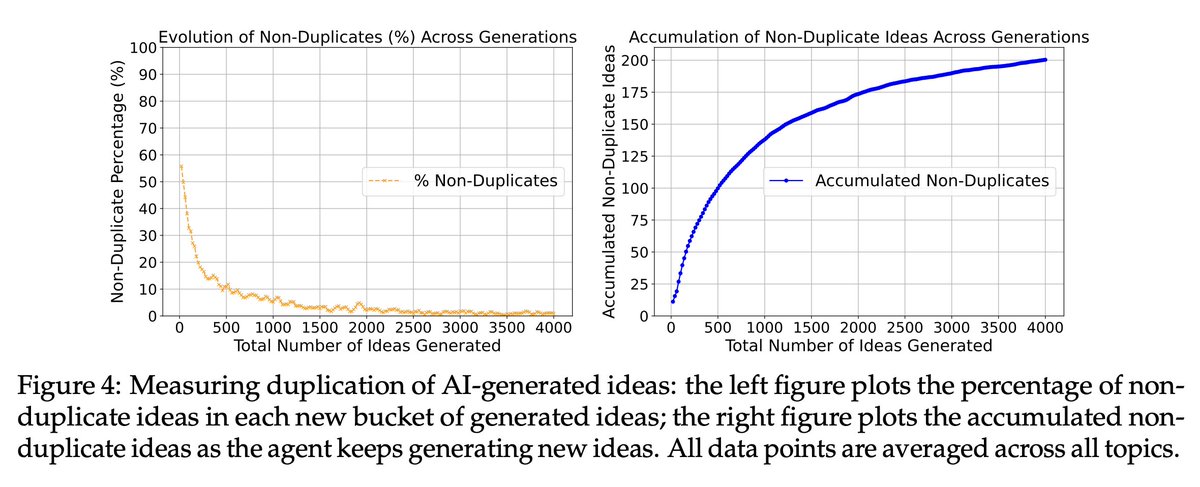
This may be helpful for inspecting the prediction performance, superhuman or not:
[2306.09983] Evaluating Superhuman Models with Consistency Checks
tldr: Using consistency checks to get an idea of how coherent the predictor is without needing any ground truth.
34/58
LOLz
35/58
Dan, this is a good start, but it’s dicey, it’s dicey.
I like what you’re doing, but the output is going to vary from instance to instance.
If you wanna try something, have GPT output an explanation for what the Vader analysis is. And then copy that description into 100 different new instances of GPT and then ask it to analyze an article that you copy and paste in there as well. Have it give it a Vader score, and then you’ll see what I’m talking about.
36/58
Hey Dan, I hear Berkeley's STATS 101 is quite a good course, maybe you should consider it?
37/58
I would like to see if it actually performs superhuman level on forecasts that are not already closed. you should try it at Q4 Tournament AI Benchmarking to see how accurate it is against the pro forecasters & other bots
Q3 AI Forecasting Benchmark Tournament
38/58
Doesn't seem to be working for me. Stuck on "Verifying..."
39/58
Will you be backing this claim with real money? Skin in the game or it’s just hype
40/58
are you going to release which 177 events they were and its predictions for each?
41/58
how does it follow that prediction markets will be automated? if this system performs well already, won't a market where participants have (or are) these systems perform better?
(or is that what you mean?)
42/58
It's definitely neat. I found that the phrasing of the question or even slightly leading it vastly changes the outcome though.
43/58
What pdoom does it predict?
44/58
Doubtful, same as the rest of your claims
45/58
It doesn't seem to work as it doesn't have latest information because it uses gpt 4o model.
46/58
I would beat this AI forecaster in a contest with 95% certainty
47/58
Do you want to put money on this?
48/58
Interesting concept! But I'll take the over on my first try
49/58
Which? the image is not loading for me..
50/58
Could CN benefit from something like this, @_jaybaxter_ ?
51/58
Bruh come on
52/58
All those time travel movies I’ve seen are going to pay off finally. If you can accurately predict the future, you’re effectively traveling to the past and can affect it.

53/58
Will Trump win the 2024 US presidential election?
Answer: 51%
Will Harris win the 2024 US presidential election?
Answer: 58%
No serious forecaster will use a model that doesn't have basic statistical knowledge built in.
54/58
unreal!!!!!!!!!!!!!
what is its AGI timeline ?
55/58
I would never use a product made by a scammer like you who makes hypocritical laws. I hope it is a total failure!
56/58
Do you think human forecasters with access to the bots will outperform bots alone?
57/58
This is fukking stupid.
58/58
Imagine being dumb enough to think this works
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196









 @vankous for
@vankous for  unroll
unroll






































 :
:  :
:  :
: