
1/11
@genmoai
Introducing Mochi 1 preview. A new SOTA in open-source video generation. Apache 2.0.
magnet:?xt=urn:btih:441da1af7a16bcaa4f556964f8028d7113d21cbb&dn=weights&tr=udp://tracker.opentrackr.org:1337/announce
https://video.twimg.com/ext_tw_video/1848745801926795264/pu/vid/avc1/1920x1080/zCXCFAyOnvznHUAf.mp4
2/11
@genmoai
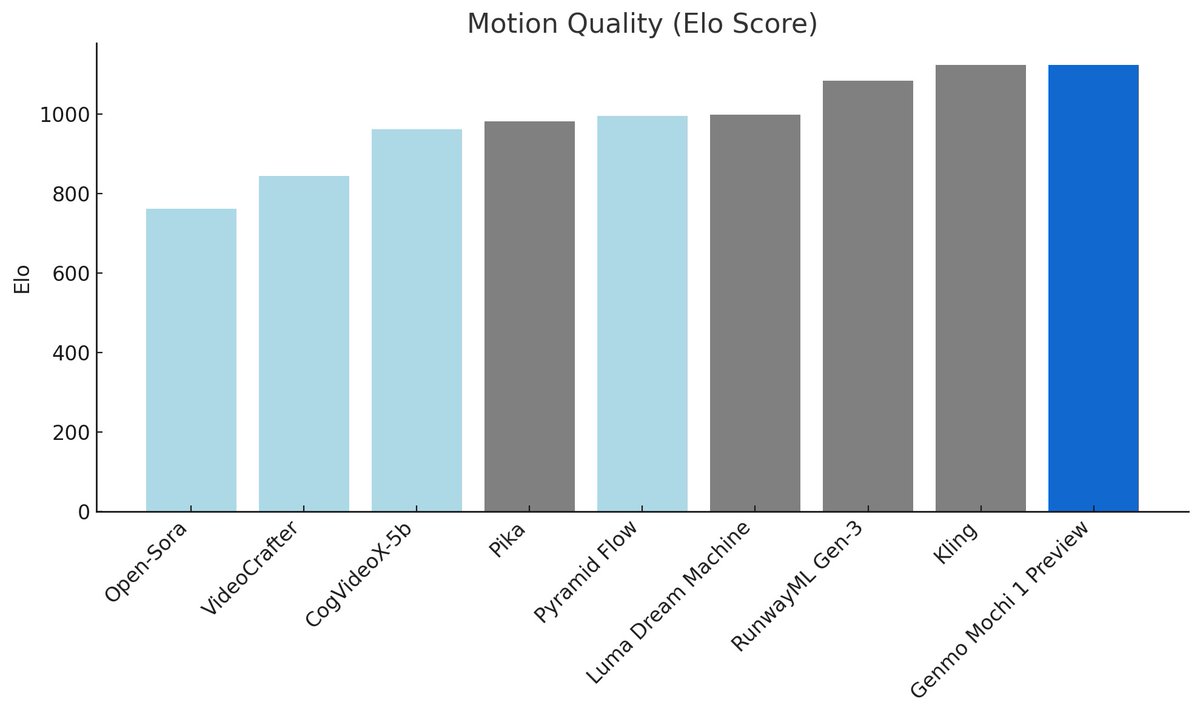
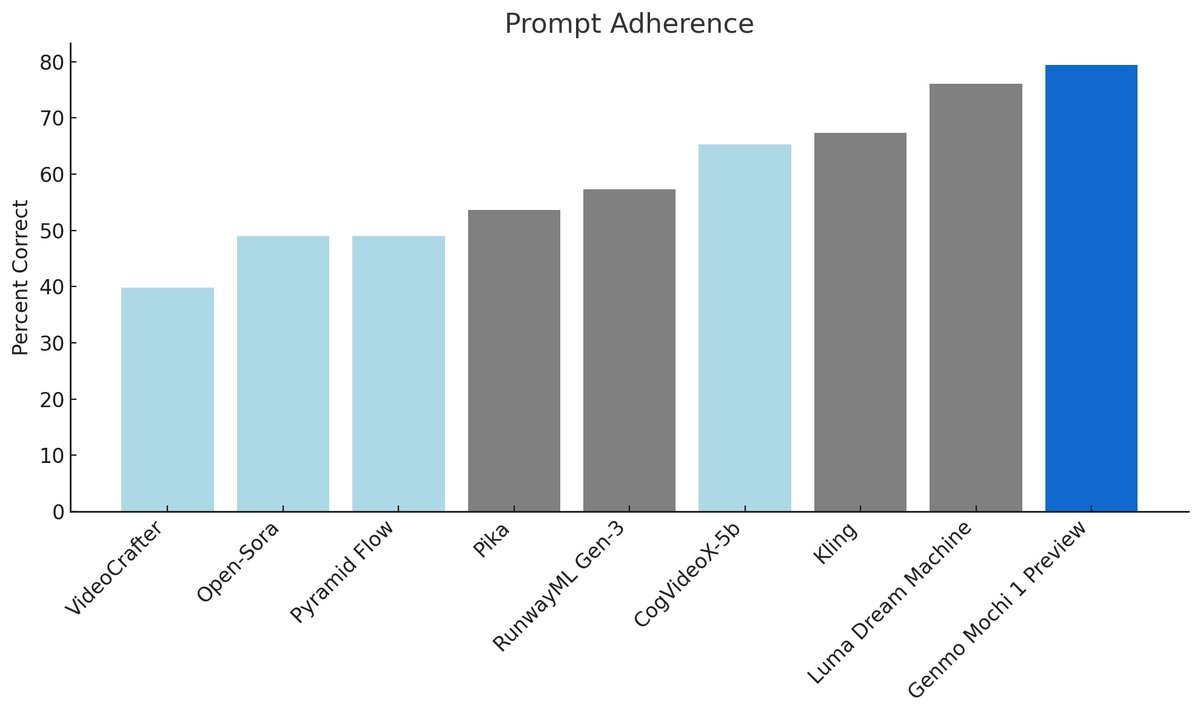
Mochi 1 has superior motion quality, prompt adherence and exceptional rendering of humans that begins to cross the uncanny valley.
Today, we are open-sourcing our base 480p model with an HD version coming soon.
3/11
@genmoai
We're excited to see what you create with Mochi 1. We're also excited to announce our $28.4M Series A from @NEA, @TheHouseVC, @GoldHouseCo, @WndrCoLLC, @parasnis, @amasad, @pirroh and more.
Use Mochi 1 via our playground at our homepage or download the weights freely.
4/11
@jahvascript
can I get a will smith eating spaghetti video?
5/11
@genmoai
6/11
@GozukaraFurkan
Does it have image to video and video to video?
7/11
@genmoai
Good question! Our new model, Mochi, is entirely text to video. On Genmo. The best open video generation models. , if you use the older model (Replay v.0.2), you're able to do image to video as well as text to video.
8/11
@iamhitarth
Keep getting this error message even though I've created an account and signed in
9/11
@genmoai
Hey there, thanks for escalating this! We're taking a closer look right now to see why this is happening I appreciate your patience and understanding!
I appreciate your patience and understanding!
10/11
@sairahul1
Where can I try it
11/11
@genmoai
You can find everything you'll need to try Mochi at Genmo. The best open video generation models. 🫶 Happy generating!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@genmoai
Introducing Mochi 1 preview. A new SOTA in open-source video generation. Apache 2.0.
magnet:?xt=urn:btih:441da1af7a16bcaa4f556964f8028d7113d21cbb&dn=weights&tr=udp://tracker.opentrackr.org:1337/announce
https://video.twimg.com/ext_tw_video/1848745801926795264/pu/vid/avc1/1920x1080/zCXCFAyOnvznHUAf.mp4
2/11
@genmoai
Mochi 1 has superior motion quality, prompt adherence and exceptional rendering of humans that begins to cross the uncanny valley.
Today, we are open-sourcing our base 480p model with an HD version coming soon.
3/11
@genmoai
We're excited to see what you create with Mochi 1. We're also excited to announce our $28.4M Series A from @NEA, @TheHouseVC, @GoldHouseCo, @WndrCoLLC, @parasnis, @amasad, @pirroh and more.
Use Mochi 1 via our playground at our homepage or download the weights freely.
4/11
@jahvascript
can I get a will smith eating spaghetti video?
5/11
@genmoai
6/11
@GozukaraFurkan
Does it have image to video and video to video?
7/11
@genmoai
Good question! Our new model, Mochi, is entirely text to video. On Genmo. The best open video generation models. , if you use the older model (Replay v.0.2), you're able to do image to video as well as text to video.
8/11
@iamhitarth
Keep getting this error message even though I've created an account and signed in
9/11
@genmoai
Hey there, thanks for escalating this! We're taking a closer look right now to see why this is happening
I appreciate your patience and understanding!10/11
@sairahul1
Where can I try it
11/11
@genmoai
You can find everything you'll need to try Mochi at Genmo. The best open video generation models. 🫶 Happy generating!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/3
@AIWarper
My Mochi 1 test thread. Will post some video examples below if you are interested.
Inference done with FAL
https://video.twimg.com/ext_tw_video/1848834063462993920/pu/vid/avc1/848x480/5De8HKQoKL4cYf6I.mp4
https://video-t-1.twimg.com/ext_tw_...016/pu/vid/avc1/848x480/JJWbnMjCeriVR86A.mp4?
2/3
@AIWarper
A floating being composed of pure, radiant energy, its form shifting between physical and immaterial states. The Lumiscribe’s eyes glow with ancient knowledge, and its translucent wings pulse with golden light. It hovers above the Skyvault, a vast floating city on its homeworld, Zephyra, a world of constant storms and lightning-filled skies. Giant skyborne creatures soar above the city, their bodies crackling with electricity. Below, the landscape is a mix of jagged mountains and stormy seas, illuminated by constant flashes of lightning. The Lumiscribe uses its energy to inscribe symbols of power into the air, controlling the flow of the storms that define their world.
https://video.twimg.com/ext_tw_video/1848835515191332868/pu/vid/avc1/848x480/HjfJWN7l2MzSNEcz.mp4
3/3
@DataPlusEngine
Holy shyt it's so good
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@AIWarper
My Mochi 1 test thread. Will post some video examples below if you are interested.
Inference done with FAL
https://video.twimg.com/ext_tw_video/1848834063462993920/pu/vid/avc1/848x480/5De8HKQoKL4cYf6I.mp4
https://video-t-1.twimg.com/ext_tw_...016/pu/vid/avc1/848x480/JJWbnMjCeriVR86A.mp4?
2/3
@AIWarper
A floating being composed of pure, radiant energy, its form shifting between physical and immaterial states. The Lumiscribe’s eyes glow with ancient knowledge, and its translucent wings pulse with golden light. It hovers above the Skyvault, a vast floating city on its homeworld, Zephyra, a world of constant storms and lightning-filled skies. Giant skyborne creatures soar above the city, their bodies crackling with electricity. Below, the landscape is a mix of jagged mountains and stormy seas, illuminated by constant flashes of lightning. The Lumiscribe uses its energy to inscribe symbols of power into the air, controlling the flow of the storms that define their world.
https://video.twimg.com/ext_tw_video/1848835515191332868/pu/vid/avc1/848x480/HjfJWN7l2MzSNEcz.mp4
3/3
@DataPlusEngine
Holy shyt it's so good
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/1
引用
Mochi 1 represents a significant advancement in open-source video generation, featuring a 10 billion parameter diffusion model built on our novel Asymmetric Diffusion Transformer architecture.
The model requires at least 4 H100 GPUs to run.
genmo/mochi-1-preview · Hugging Face
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
引用
Mochi 1 represents a significant advancement in open-source video generation, featuring a 10 billion parameter diffusion model built on our novel Asymmetric Diffusion Transformer architecture.
The model requires at least 4 H100 GPUs to run.
genmo/mochi-1-preview · Hugging Face
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/10
@_akhaliq
Mochi 1 preview
A new SOTA in open-source video generation. Apache 2.0
https://video.twimg.com/ext_tw_video/1848763058291642370/pu/vid/avc1/1280x720/QFGsHnbVyszo5Xgz.mp4
2/10
@_akhaliq
model: genmo/mochi-1-preview · Hugging Face
3/10
@Prashant_1722
Sora has become extremely non moat by now
4/10
@LearnedVector
Ima need more h100s
5/10
@thebuttredettes
Getting only errors on the preview page.
6/10
@noonescente
What is a SOTA?
7/10
@m3ftah
It requires 4 H100 to run!
8/10
@ED84VG
It’s crazy how fast ai video has come.
Does anyone know if it got better because Sora showed it was possible, or would they have gotten this good even if they never showed us?
9/10
@JonathanKorstad

10/10
@_EyesofTruth_
OpenAi getting mogged
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@_akhaliq
Mochi 1 preview
A new SOTA in open-source video generation. Apache 2.0
https://video.twimg.com/ext_tw_video/1848763058291642370/pu/vid/avc1/1280x720/QFGsHnbVyszo5Xgz.mp4
2/10
@_akhaliq
model: genmo/mochi-1-preview · Hugging Face
3/10
@Prashant_1722
Sora has become extremely non moat by now
4/10
@LearnedVector
Ima need more h100s
5/10
@thebuttredettes
Getting only errors on the preview page.
6/10
@noonescente
What is a SOTA?
7/10
@m3ftah
It requires 4 H100 to run!
8/10
@ED84VG
It’s crazy how fast ai video has come.
Does anyone know if it got better because Sora showed it was possible, or would they have gotten this good even if they never showed us?
9/10
@JonathanKorstad
10/10
@_EyesofTruth_
OpenAi getting mogged
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Last edited:

 @TheReal_Ingrid_ for
@TheReal_Ingrid_ for  unroll
unroll






 used to work on sd 1.5 with animate diff
used to work on sd 1.5 with animate diff















 thinks about it:
thinks about it:
 This paper introduces EfficientViT-SAM, a highly efficient and fast model for image segmentation. It innovates on the Segment Anything Model (SAM) framework by incorporating EfficientViT, a more streamlined image encoder, enhancing the model's speed without sacrificing accuracy. EfficientViT-SAM shows a significant processing rate improvement over SAM-ViTH, achieving a 48.9 times faster rate on the A100 GPU.
This paper introduces EfficientViT-SAM, a highly efficient and fast model for image segmentation. It innovates on the Segment Anything Model (SAM) framework by incorporating EfficientViT, a more streamlined image encoder, enhancing the model's speed without sacrificing accuracy. EfficientViT-SAM shows a significant processing rate improvement over SAM-ViTH, achieving a 48.9 times faster rate on the A100 GPU.
 Model on @Huggingface with MIT license:
Model on @Huggingface with MIT license: 
 Extremely easy to launch: Clone the repo, install from requirements, and launch the app `python app_py`
Extremely easy to launch: Clone the repo, install from requirements, and launch the app `python app_py` 

 A dataset of 5000 samples to test cognitive reasoning capabilities of MLLMs.
A dataset of 5000 samples to test cognitive reasoning capabilities of MLLMs. The best scores achieved on POLYMATH are ∼ 41%, ∼ 36%, and ∼ 27%, obtained by Claude-3.5 Sonnet, GPT-4o and Gemini-1.5 Pro respectively while human baseline was at ~66%.
The best scores achieved on POLYMATH are ∼ 41%, ∼ 36%, and ∼ 27%, obtained by Claude-3.5 Sonnet, GPT-4o and Gemini-1.5 Pro respectively while human baseline was at ~66%. An improvement of 4% is observed when image descriptions are passed instead of actual images, indicating reliance on text over image even in multimodal reasoning.
An improvement of 4% is observed when image descriptions are passed instead of actual images, indicating reliance on text over image even in multimodal reasoning. Open AI o1 models get competitive scores with human baseline on text only samples, highlighting room for improvement!
Open AI o1 models get competitive scores with human baseline on text only samples, highlighting room for improvement!









 Upload your pic
Upload your pic  , add the dress, and see how it looks on you instantly!
, add the dress, and see how it looks on you instantly! 






 Experience the thrill of trying on any fashionable outfit and using @Kling_ai to turn your images into dynamic videos. Don't miss out!
Experience the thrill of trying on any fashionable outfit and using @Kling_ai to turn your images into dynamic videos. Don't miss out! 
