
Meta Reality Labs Research Introduces Sonata: Advancing Self-Supervised Representation Learning for 3D Point Clouds
3D self-supervised learning (SSL) has faced persistent challenges in developing semantically meaningful point representations suitable for diverse applications with minimal supervision. Despite substantial progress in image-based SSL, existing point cloud SSL methods have largely been limited...
 www.marktechpost.com
www.marktechpost.com
Meta Reality Labs Research Introduces Sonata: Advancing Self-Supervised Representation Learning for 3D Point Clouds
By Nikhil
March 28, 2025
Reddit Vote Flip Share Tweet 0 Shares
3D self-supervised learning (SSL) has faced persistent challenges in developing semantically meaningful point representations suitable for diverse applications with minimal supervision. Despite substantial progress in image-based SSL, existing point cloud SSL methods have largely been limited due to the issue known as the “geometric shortcut,” where models excessively rely on low-level geometric features like surface normals or point heights. This reliance compromises the generalizability and semantic depth of the representations, hindering their practical deployment.
Researchers from the University of Hong Kong and Meta Reality Labs Research introduce Sonata, an advanced approach designed to address these fundamental challenges. Sonata employs a self-supervised learning framework that effectively mitigates the geometric shortcut by strategically obscuring low-level spatial cues and reinforcing dependency on richer input features. Drawing inspiration from recent advancements in image-based SSL, Sonata integrates a point self-distillation mechanism that gradually refines representation quality and ensures robustness against geometric simplifications.
Check out how HOSTINGER HORIZONS can help to build and launch full-stack web apps, tools, and software in minutes without writing any code (Promoted)
At a technical level, Sonata utilizes two core strategies: firstly, it operates on coarser scales to obscure spatial information that might otherwise dominate the learned representations. Secondly, Sonata adopts a point self-distillation approach, progressively increasing task difficulty through adaptive masking strategies to foster deeper semantic understanding. Crucially, Sonata removes decoder structures traditionally used in hierarchical models to avoid reintroducing local geometric shortcuts, allowing the encoder alone to build robust, multi-scale feature representations. Additionally, Sonata applies “masked point jitter,” introducing random perturbations to the spatial coordinates of masked points, thus further discouraging reliance on trivial geometric features.
The empirical results reported validate Sonata’s efficacy and efficiency. Sonata achieves significant performance gains on benchmarks like ScanNet, where it records a linear probing accuracy of 72.5%, substantially surpassing previous state-of-the-art SSL approaches. Importantly, Sonata demonstrates robustness even with limited data, performing effectively using as little as 1% of the ScanNet dataset, which highlights its suitability for low-resource scenarios. Its parameter efficiency is also notable, delivering strong performance improvements with fewer parameters compared to conventional methods. Furthermore, integrating Sonata with image-derived representations such as DINOv2 results in enhanced accuracy, emphasizing its capacity to capture distinctive semantic details specific to 3D data.
Sonata’s capabilities are further illustrated through insightful zero-shot visualizations including PCA-colored point clouds and dense feature correspondence, demonstrating coherent semantic clustering and robust spatial reasoning under challenging augmentation conditions. The versatility of Sonata is also evidenced across various semantic segmentation tasks, spanning indoor datasets like ScanNet and ScanNet200, as well as outdoor datasets including Waymo, consistently achieving state-of-the-art outcomes.
In conclusion, Sonata represents a significant advancement in addressing inherent limitations in 3D self-supervised learning. Its methodological innovations effectively resolve issues associated with the geometric shortcut, providing semantically richer and more reliable representations. Sonata’s integration of self-distillation, careful manipulation of spatial information, and scalability to large datasets establish a solid foundation for future explorations in versatile and robust 3D representation learning. The framework sets a methodological benchmark, facilitating further research towards comprehensive multimodal SSL integration and practical 3D applications.
Check out the Paper and GitHub Page . All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 85k+ ML SubReddit .










 Today’s Global AI Native Industry Insights include:
Today’s Global AI Native Industry Insights include: Dive into the in-depth insights in the thread below. Here’s what’s shaping the future of AI—and why it matters:
Dive into the in-depth insights in the thread below. Here’s what’s shaping the future of AI—and why it matters: 
 Key Details:
Key Details: How It Helps:
How It Helps:







 Subscribe:
Subscribe: 









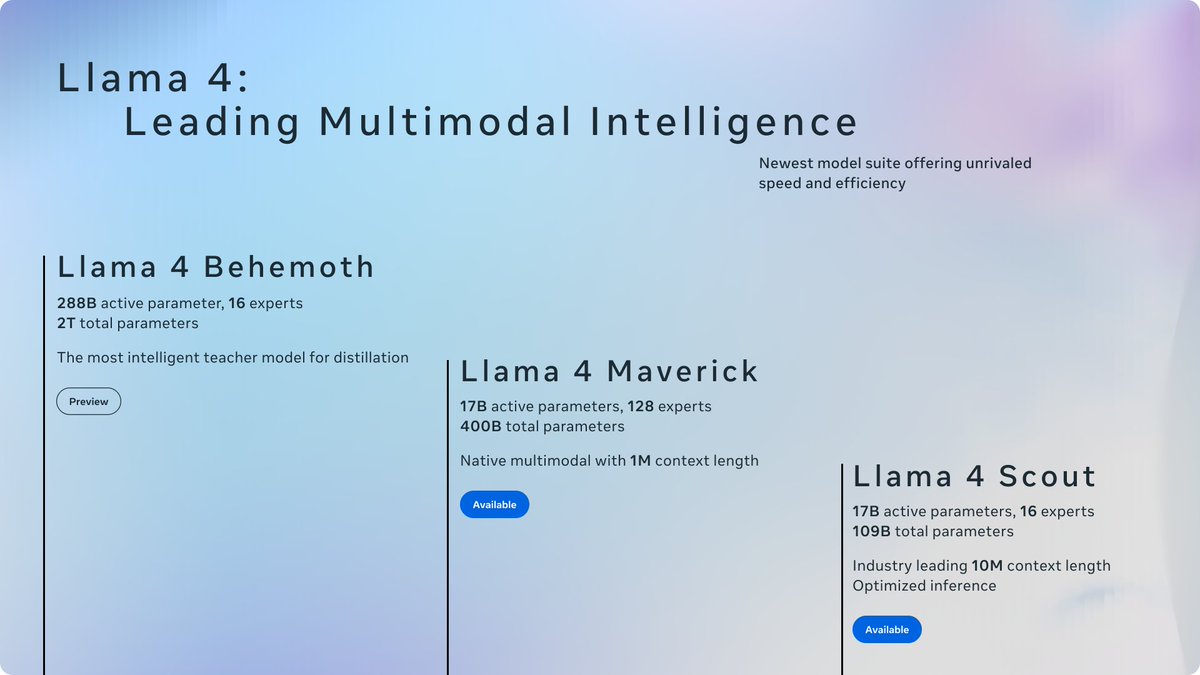









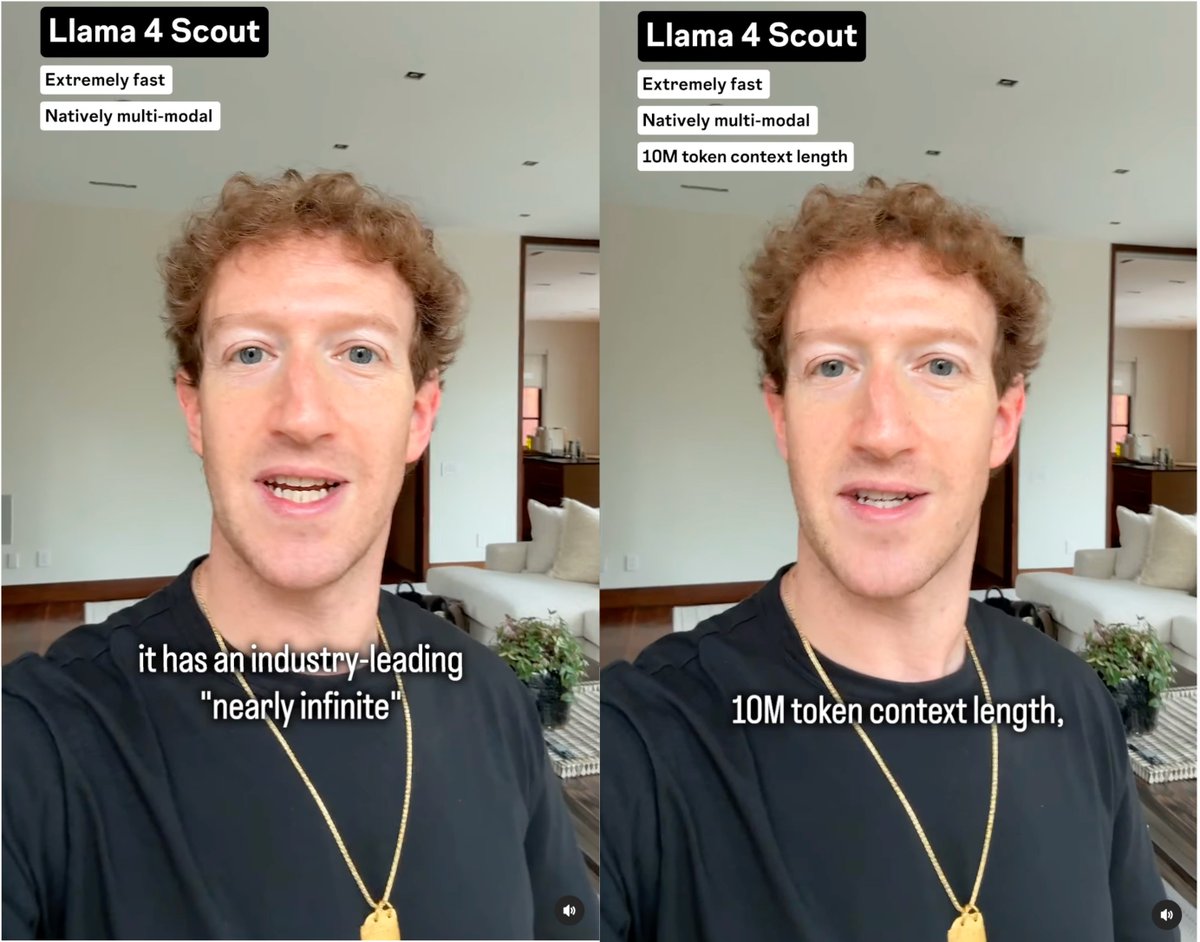
 Meet Llama 4 Scout: 17B parameters, 16 experts, and a ridiculous 10M token context window. That’s like cramming 15,000 pages of text into its brain at once! It’s stomping Gemma 3, Gemini 2.0 Flash-Lite, and Mistral 3.1 in benchmarks. /search?q=#AI /search?q=#Tech
Meet Llama 4 Scout: 17B parameters, 16 experts, and a ridiculous 10M token context window. That’s like cramming 15,000 pages of text into its brain at once! It’s stomping Gemma 3, Gemini 2.0 Flash-Lite, and Mistral 3.1 in benchmarks. /search?q=#AI /search?q=#Tech
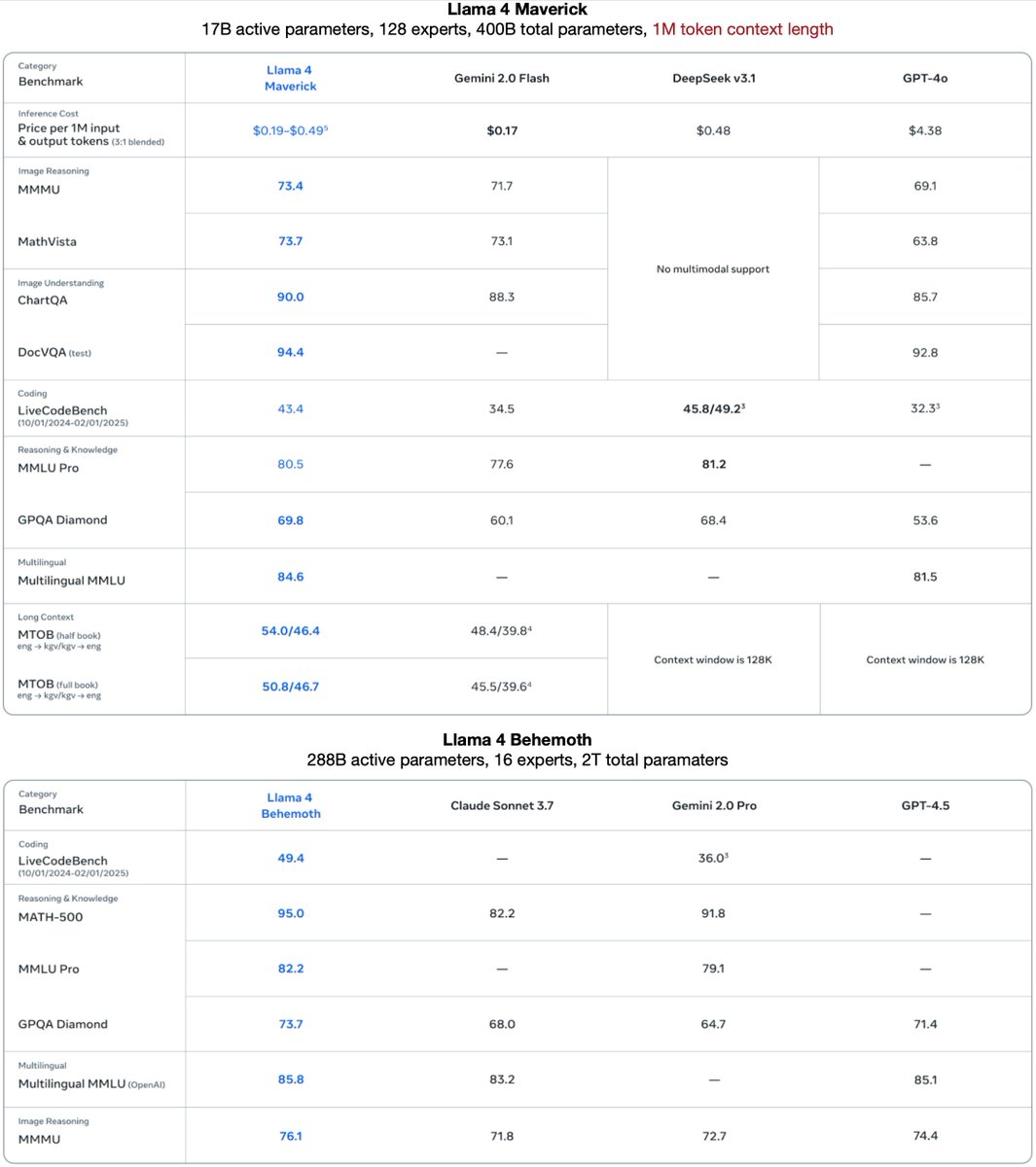
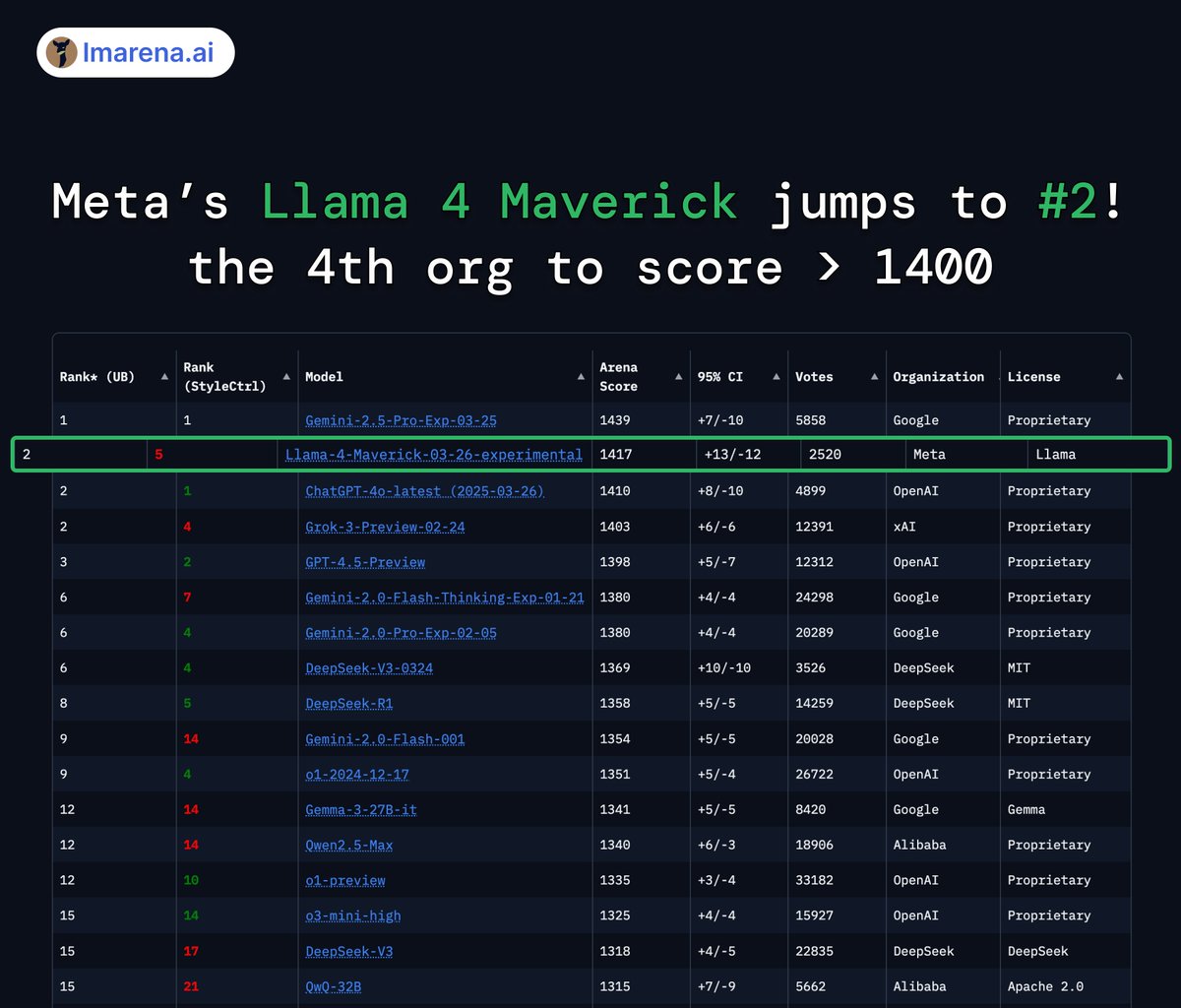
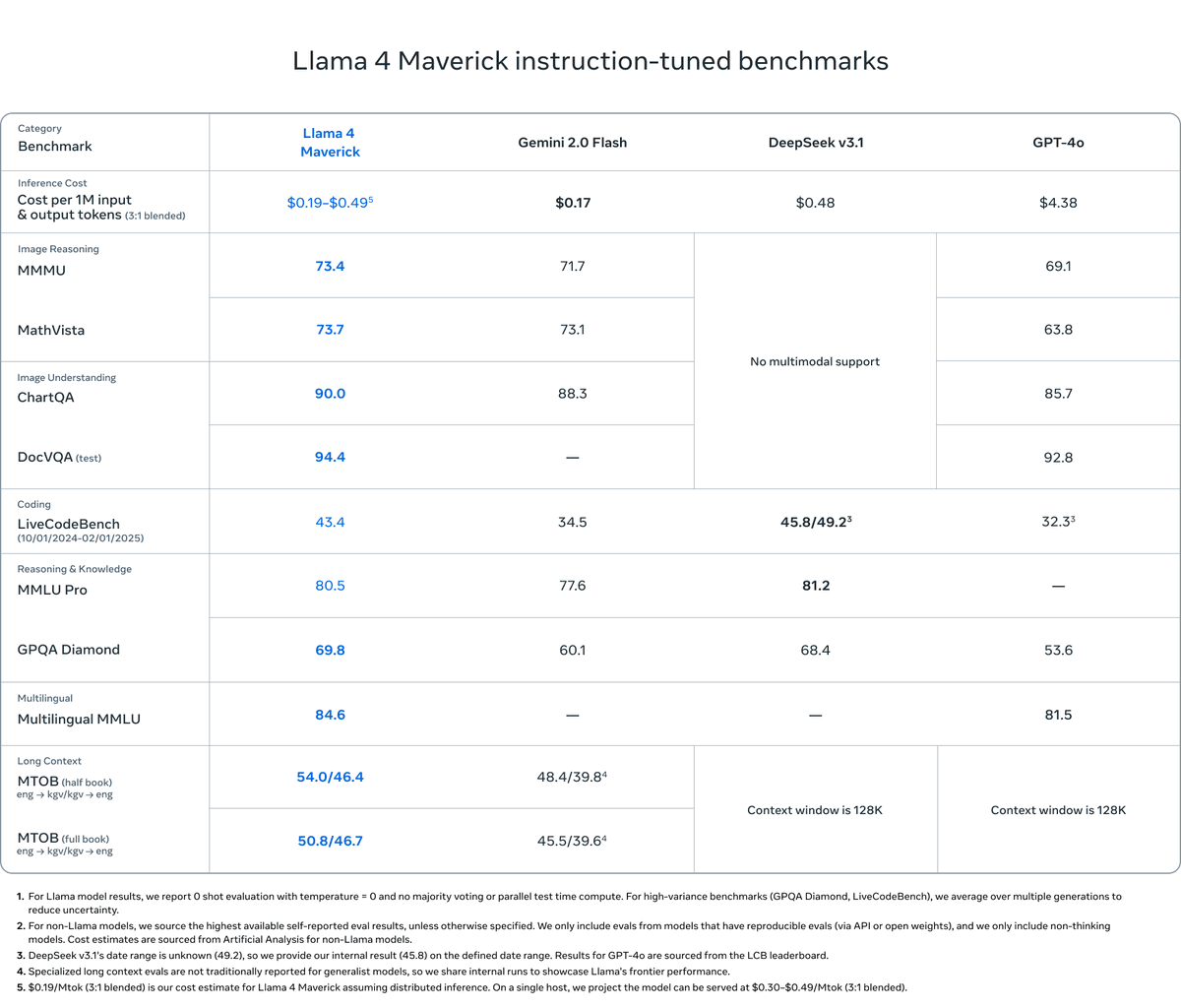
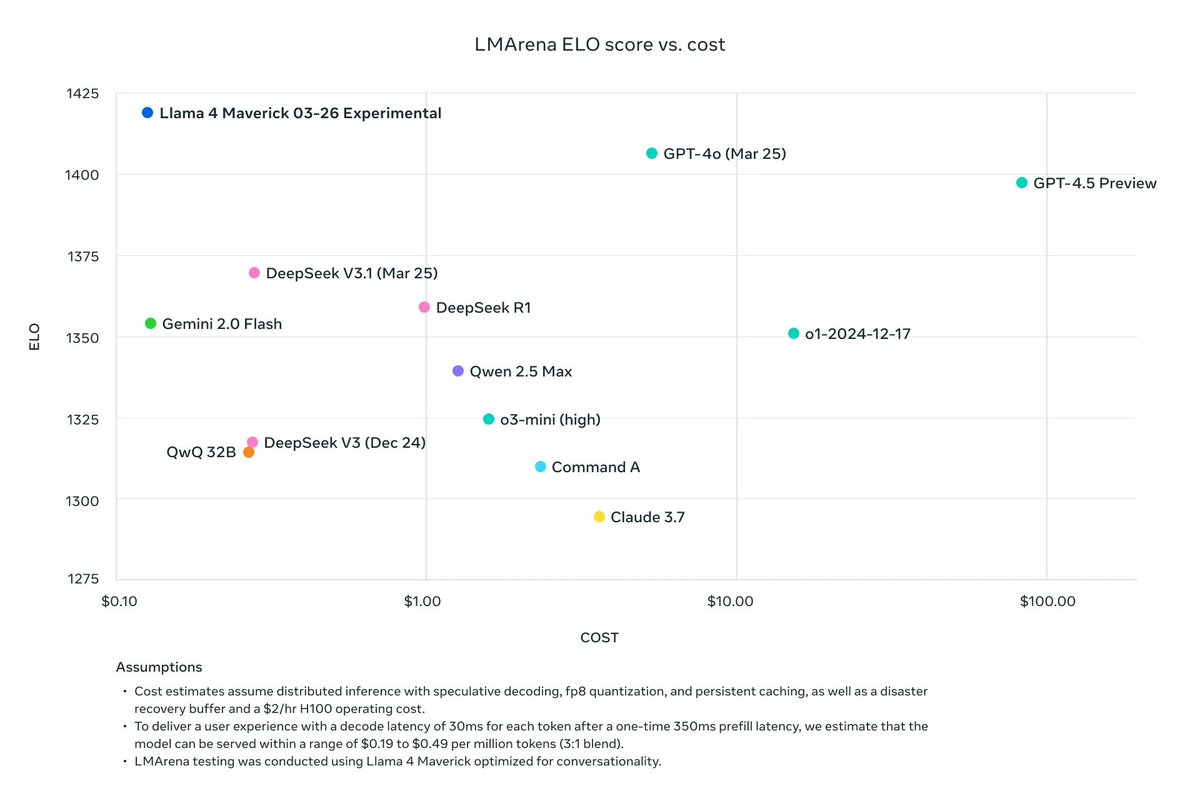
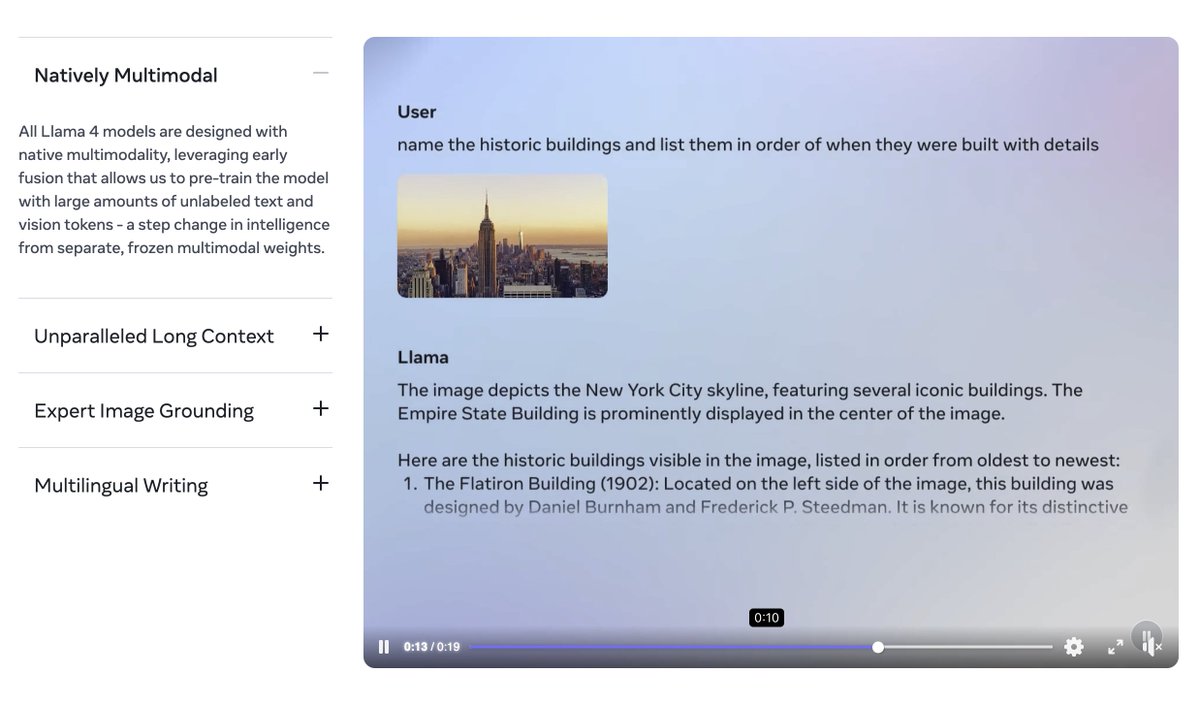
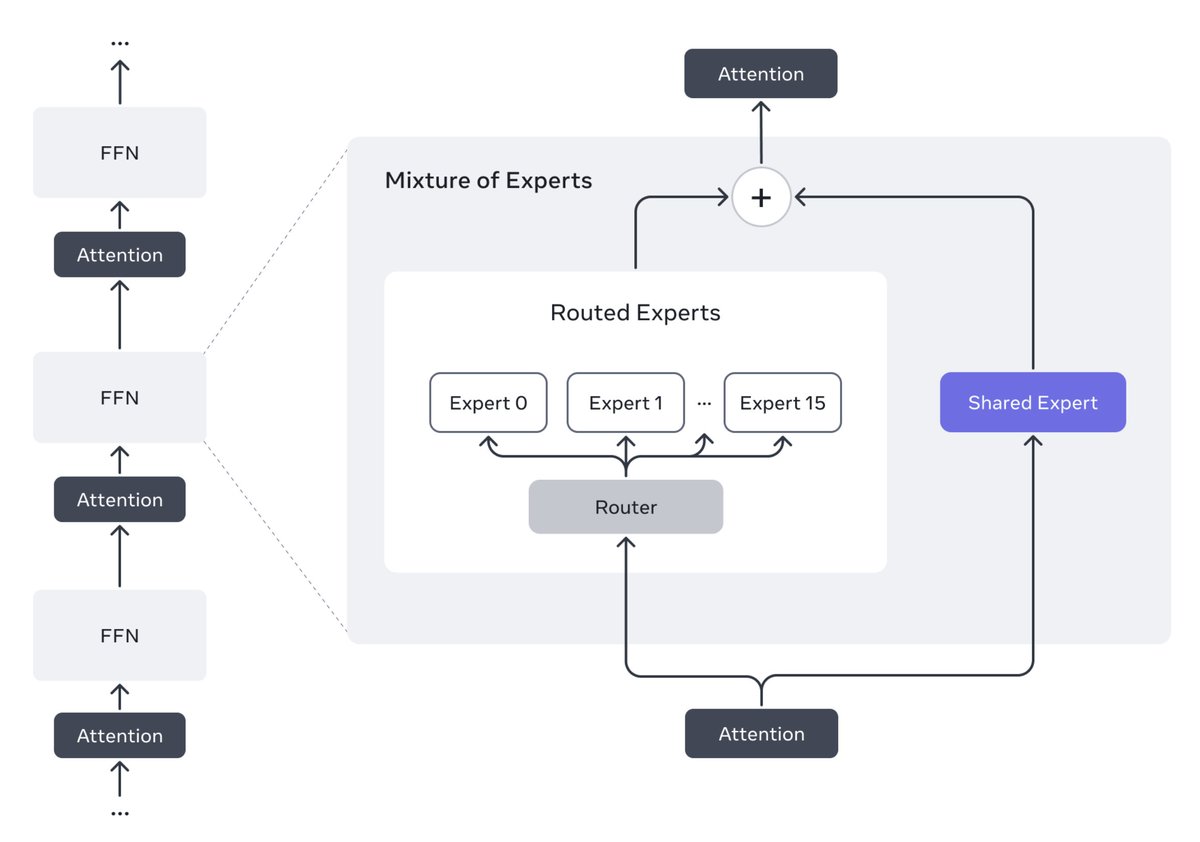
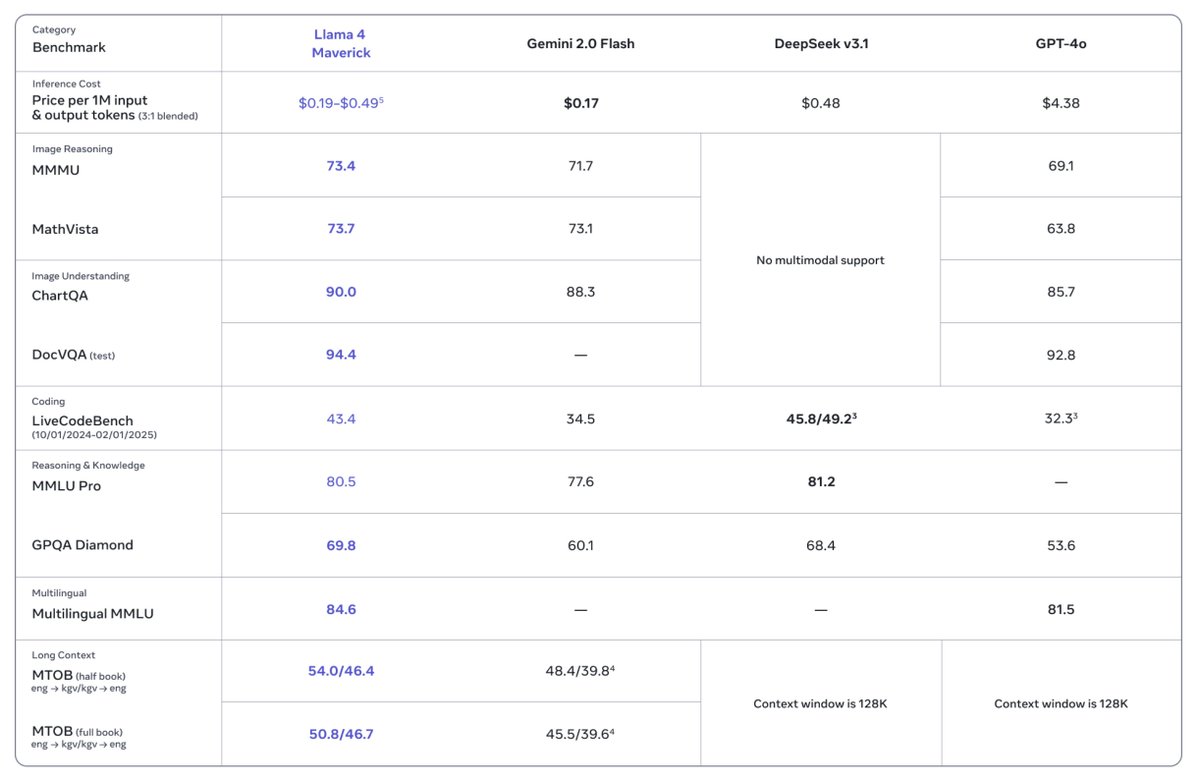
 Then there’s Llama 4 Maverick: 17B parameters with 128 experts. This one’s a wizard at image grounding—think pinpointing exactly what you mean in a picture from your text prompt. It beats GPT-4o and Gemini 2.0 Flash, and matches DeepSeek v3.
Then there’s Llama 4 Maverick: 17B parameters with 128 experts. This one’s a wizard at image grounding—think pinpointing exactly what you mean in a picture from your text prompt. It beats GPT-4o and Gemini 2.0 Flash, and matches DeepSeek v3.
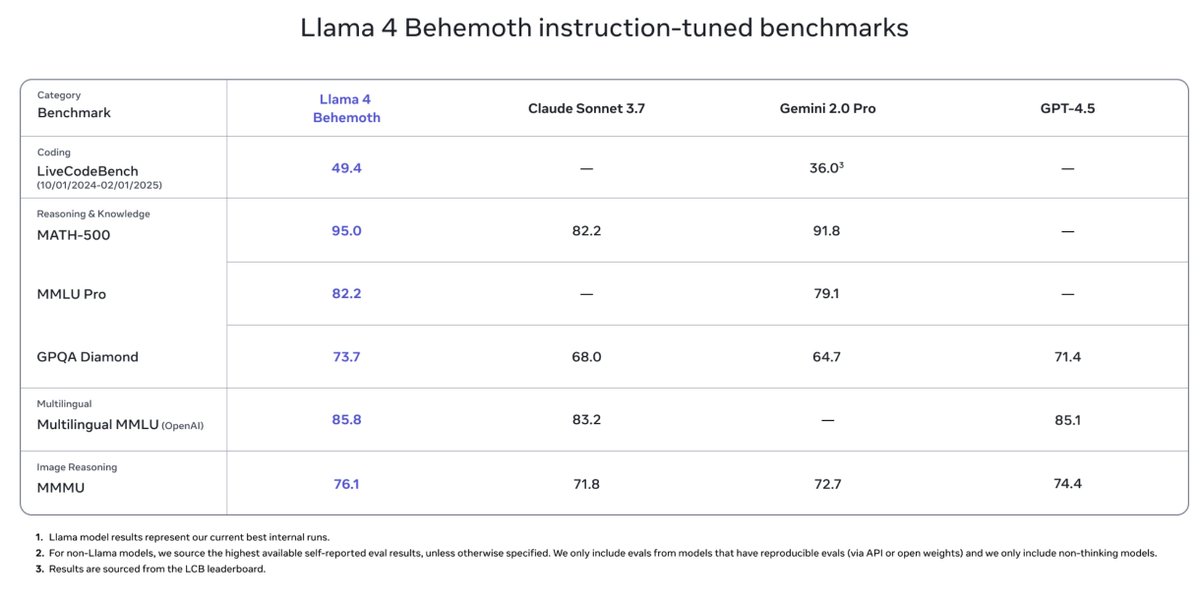
 Here’s the kicker: both Scout and Maverick got their smarts from Llama 4 Behemoth, a beast still training with nearly 2T parameters. It’s already outpacing GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro in STEM benchmarks. Meta’s cooking something huge.
Here’s the kicker: both Scout and Maverick got their smarts from Llama 4 Behemoth, a beast still training with nearly 2T parameters. It’s already outpacing GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro in STEM benchmarks. Meta’s cooking something huge.
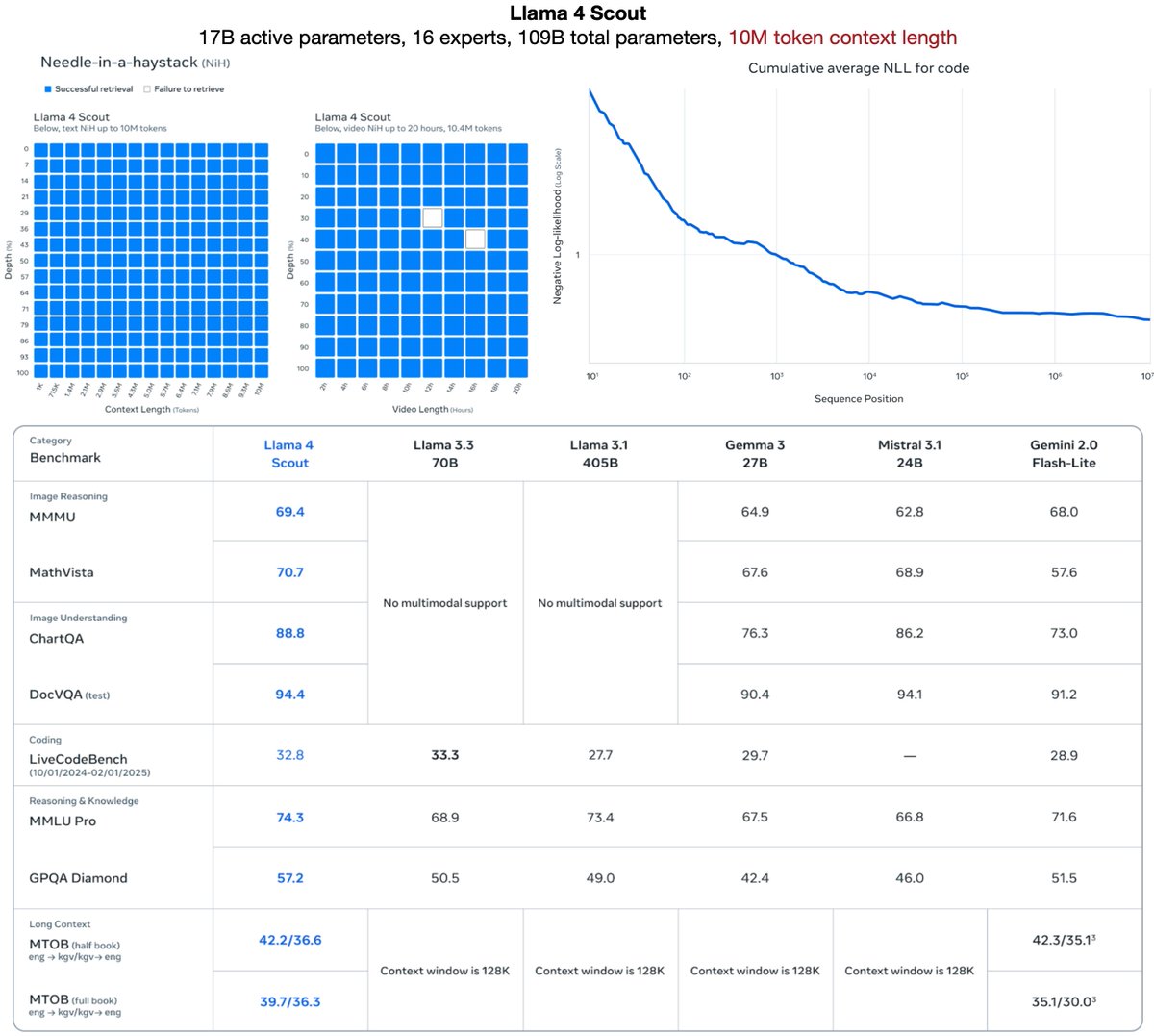
 Llama 4 Scout
Llama 4 Scout 17B active params · 16 experts · 109B total params
17B active params · 16 experts · 109B total params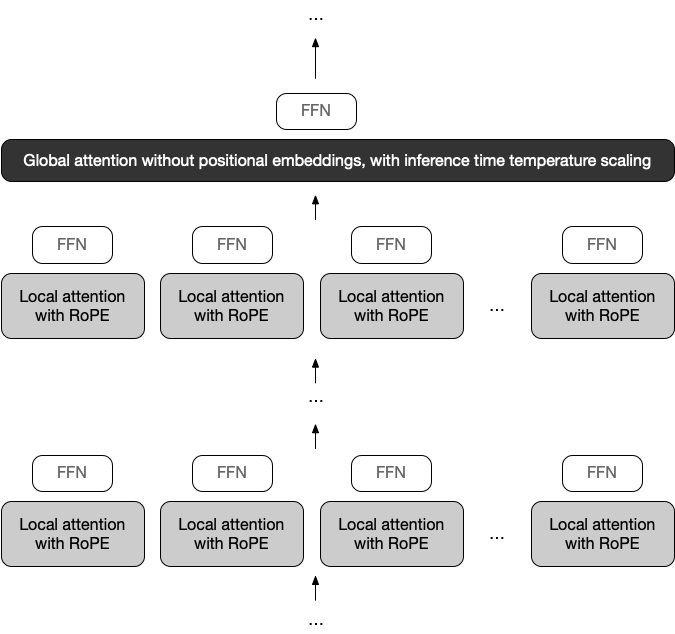

 More analysis below
More analysis below








 AI Just Broke Humanity’s Coding Record: Full o3 Officially World’s BEST Programmer!
AI Just Broke Humanity’s Coding Record: Full o3 Officially World’s BEST Programmer! 

 Just imagine—an AI model that was once 175th in coding rankings has now ascended to the very top.
Just imagine—an AI model that was once 175th in coding rankings has now ascended to the very top.


 ️
️

