1/12
@minchoi
HeyGen just dropped Avatar 3.0 with Unlimited Looks.
Now anyone can clone themselves with AI and unlock multiple poses, outfits, and camera angles.
Here's how:
https://video.twimg.com/ext_tw_video/1843391162154909696/pu/vid/avc1/1280x720/vjOC27CxtaYlcsNT.mp4
2/12
@minchoi
1/ Create your Avatar
- Go to HeyGen
- Click on Avatars then Create Avatar
- Follow the given step by step instructions
It's very important to follow the instructions on making a good video of yourself
https://video.twimg.com/ext_tw_video/1843391974348369920/pu/vid/avc1/1402x720/u1ApPmZvnF9nKIKv.mp4
3/12
@minchoi
2/ Create your Video
- Click Create Video
- Click Avatar Video
- Choose video orientation
- Select your Avatar (you can add more Scenes for different Looks)
- Add/Generate your script
- Then Click Submit
https://video.twimg.com/ext_tw_video/1843392144632889344/pu/vid/avc1/1402x720/xFXBfdxUpFtB66hu.mp4
4/12
@minchoi
3/ Wait for your Video to be generated
- Depending on the length of your video, it will take several minutes to process
- And you are done
https://video.twimg.com/ext_tw_video/1843392877172281344/pu/vid/avc1/1402x720/knyVqqheSTn9iaVk.mp4
5/12
@minchoi
Official video from @HeyGen_Official & @joshua_xu_
Unlock Unlimited looks, unlimited creativity at HeyGen - AI Video Generator
https://video.twimg.com/ext_tw_video/1841433281515892737/pu/vid/avc1/1920x1080/mzMZa8aPOgAp1Pm9.mp4
6/12
@minchoi
If you enjoyed this thread,
Follow me @minchoi and please Bookmark, Like, Comment & Repost the first Post below to share with your friends:
[Quoted tweet]
HeyGen just dropped Avatar 3.0 with Unlimited Looks.
Now anyone can clone themselves with AI and unlock multiple poses, outfits, and camera angles.
Here's how:
https://video.twimg.com/ext_tw_video/1843391162154909696/pu/vid/avc1/1280x720/vjOC27CxtaYlcsNT.mp4
7/12
@KanikaBK
Woah, awesome
8/12
@minchoi
Awesome indeed
9/12
@adolfoasorlin
This is amazing dude

10/12
@minchoi
Lip syncing on HeyGen is another level
11/12
@mhdfaran
With all these unlimited looks and poses, I bet social media influencers are already gearing up to flood our feeds with even more content.
12/12
@minchoi
Genuine human content will become more important than ever
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@minchoi
HeyGen just dropped Avatar 3.0 with Unlimited Looks.
Now anyone can clone themselves with AI and unlock multiple poses, outfits, and camera angles.
Here's how:
https://video.twimg.com/ext_tw_video/1843391162154909696/pu/vid/avc1/1280x720/vjOC27CxtaYlcsNT.mp4
2/12
@minchoi
1/ Create your Avatar
- Go to HeyGen
- Click on Avatars then Create Avatar
- Follow the given step by step instructions
It's very important to follow the instructions on making a good video of yourself
https://video.twimg.com/ext_tw_video/1843391974348369920/pu/vid/avc1/1402x720/u1ApPmZvnF9nKIKv.mp4
3/12
@minchoi
2/ Create your Video
- Click Create Video
- Click Avatar Video
- Choose video orientation
- Select your Avatar (you can add more Scenes for different Looks)
- Add/Generate your script
- Then Click Submit
https://video.twimg.com/ext_tw_video/1843392144632889344/pu/vid/avc1/1402x720/xFXBfdxUpFtB66hu.mp4
4/12
@minchoi
3/ Wait for your Video to be generated
- Depending on the length of your video, it will take several minutes to process
- And you are done
https://video.twimg.com/ext_tw_video/1843392877172281344/pu/vid/avc1/1402x720/knyVqqheSTn9iaVk.mp4
5/12
@minchoi
Official video from @HeyGen_Official & @joshua_xu_
Unlock Unlimited looks, unlimited creativity at HeyGen - AI Video Generator
https://video.twimg.com/ext_tw_video/1841433281515892737/pu/vid/avc1/1920x1080/mzMZa8aPOgAp1Pm9.mp4
6/12
@minchoi
If you enjoyed this thread,
Follow me @minchoi and please Bookmark, Like, Comment & Repost the first Post below to share with your friends:
[Quoted tweet]
HeyGen just dropped Avatar 3.0 with Unlimited Looks.
Now anyone can clone themselves with AI and unlock multiple poses, outfits, and camera angles.
Here's how:
https://video.twimg.com/ext_tw_video/1843391162154909696/pu/vid/avc1/1280x720/vjOC27CxtaYlcsNT.mp4
7/12
@KanikaBK
Woah, awesome
8/12
@minchoi
Awesome indeed
9/12
@adolfoasorlin
This is amazing dude
10/12
@minchoi
Lip syncing on HeyGen is another level
11/12
@mhdfaran
With all these unlimited looks and poses, I bet social media influencers are already gearing up to flood our feeds with even more content.
12/12
@minchoi
Genuine human content will become more important than ever
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

Create Realistic AI Video Avatars in Minutes | HeyGen
Produce lifelike AI video avatars 4 times faster with 60% higher performance. Choose from 1,000+ avatar styles for training, marketing, and global outreach.

 :
: :
: :
:
 How does nGPT differ from the standard Transformer architecture?
How does nGPT differ from the standard Transformer architecture?
 Potential drawbacks of nGPT
Potential drawbacks of nGPT nGPT allows for some insights about Transformer internals :
nGPT allows for some insights about Transformer internals :
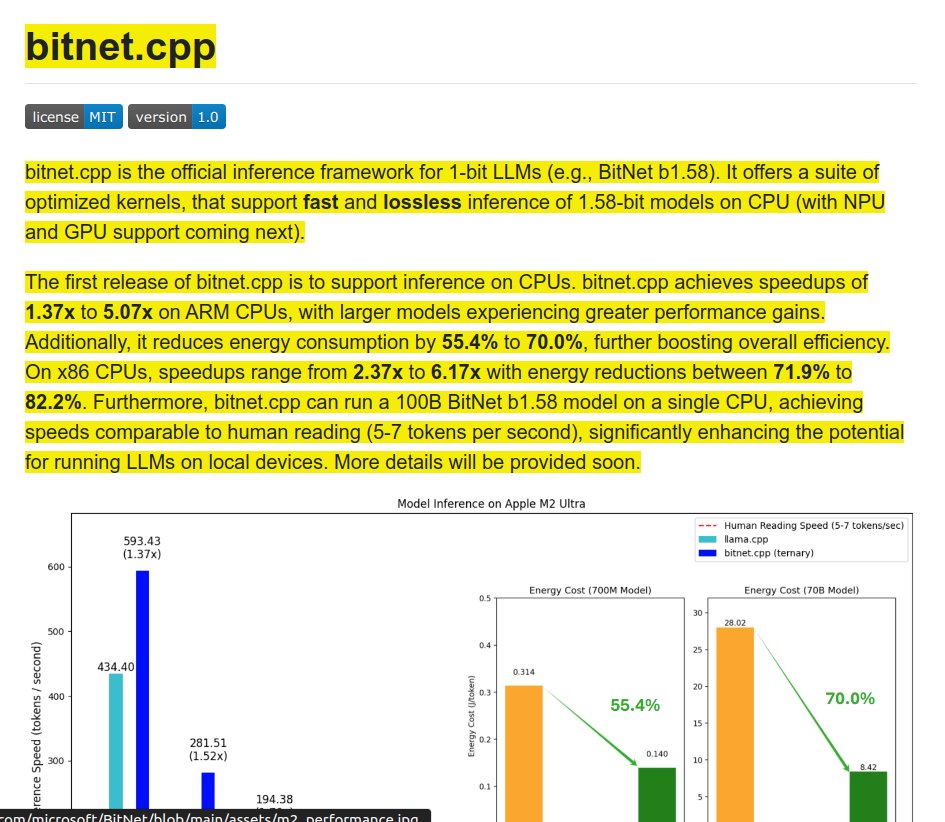
 This method involves replacing the standard Linear layers with specialized BitLinear layers that are compatible with the BitNet architecture, with appropriate dynamic quantization of activations, weight unpacking, and matrix multiplication.
This method involves replacing the standard Linear layers with specialized BitLinear layers that are compatible with the BitNet architecture, with appropriate dynamic quantization of activations, weight unpacking, and matrix multiplication.






 :
:


 Traditional matrix multiplication:
Traditional matrix multiplication: BitNet b1.58 approach:
BitNet b1.58 approach: Why this is highly optimizable:
Why this is highly optimizable:
 Starting point:
Starting point: Goal:
Goal: The process:
The process: Step 1: Find the average:
Step 1: Find the average: Result:
Result: Why do this?
Why do this?
 Right graph (Memory):
Right graph (Memory): Table (Throughput):
Table (Throughput):



 I'll try my best.
I'll try my best.