AI labs traveling the road to super-intelligent systems are realizing they might have to take a detour. "AI scaling laws," the methods and expectations

techcrunch.com
Current AI scaling laws are showing diminishing returns, forcing AI labs to change course
Maxwell Zeff
6:00 AM PST · November 20, 2024
AI labs traveling the road to super-intelligent systems are realizing they might have to take a detour.
“AI scaling laws,” the methods and expectations that labs have used to increase the capabilities of their models for the last five years, are now showing signs of diminishing returns, according to several AI investors, founders, and CEOs who spoke with TechCrunch. Their sentiments echo
recent reports that indicate models inside leading AI labs are improving more slowly than they used to.
Everyone now seems to be admitting you can’t just use more compute and more data while pretraining large language models and expect them to turn into some sort of all-knowing digital god. Maybe that sounds obvious, but these scaling laws were a key factor in developing ChatGPT, making it better, and likely influencing many CEOs to make
bold predictions about AGI arriving in just a few years.
OpenAI and Safe Super Intelligence co-founder Ilya Sutskever told Reuters last week that “
everyone is looking for the next thing” to scale their AI models. Earlier this month, a16z co-founder Marc Andreessen said in a podcast that AI models currently seem to be converging at the
same ceiling on capabilities.
But now, almost immediately after these concerning trends started to emerge, AI CEOs, researchers, and investors are already declaring we’re in a new era of scaling laws. “Test-time compute,” which gives AI models more time and compute to “think” before answering a question, is an especially promising contender to be the next big thing.
“We are seeing the emergence of a new scaling law,” said Microsoft CEO Satya Nadella
onstage at Microsoft Ignite on Tuesday, referring to the test-time compute research underpinning
OpenAI’s o1 model.
He’s not the only one now pointing to o1 as the future.
“We’re now in the second era of scaling laws, which is test-time scaling,” said Andreessen Horowitz partner Anjney Midha, who also sits on the board of Mistral and was an angel investor in Anthropic, in a recent interview with TechCrunch.
If the unexpected success — and now, the sudden slowing — of the previous AI scaling laws tell us anything, it’s that it is very hard to predict how and when AI models will improve.
Regardless, there seems to be a paradigm shift underway: The ways AI labs try to advance their models for the next five years likely won’t resemble the last five.
What are AI scaling laws?
The rapid AI model improvements that OpenAI, Google, Meta, and Anthropic have achieved since 2020 can largely be attributed to one key insight: use more compute and more data during an AI model’s pretraining phase.
When researchers give machine learning systems abundant resources during this phase — in which AI identifies and stores patterns in large datasets — models have tended to perform better at predicting the next word or phrase.
This first generation of AI scaling laws pushed the envelope of what computers could do, as engineers increased the number of GPUs used and the quantity of data they were fed. Even if this particular method has run its course, it has already redrawn the map. Every Big Tech company has basically gone all in on AI, while Nvidia, which supplies the GPUs all these companies train their models on, is now the
most valuable publicly traded company in the world.
But these investments were also made with the expectation that scaling would continue as expected.
It’s important to note that scaling laws are not laws of nature, physics, math, or government. They’re not guaranteed by anything, or anyone, to continue at the same pace. Even Moore’s Law, another famous scaling law, eventually petered out — though it certainly had a longer run.
“If you just put in more compute, you put in more data, you make the model bigger — there are diminishing returns,” said Anyscale co-founder and former CEO Robert Nishihara in an interview with TechCrunch. “In order to keep the scaling laws going, in order to keep the rate of progress increasing, we also need new ideas.”
Nishihara is quite familiar with AI scaling laws. Anyscale reached a billion-dollar valuation by developing software that helps OpenAI and other AI model developers scale their AI training workloads to tens of thousands of GPUs. Anyscale has been one of the biggest beneficiaries of pretraining scaling laws around compute, but even its co-founder recognizes that the season is changing.
“When you’ve read a million reviews on Yelp, maybe the next reviews on Yelp don’t give you that much,” said Nishihara, referring to the limitations of scaling data. “But that’s pretraining. The methodology around post-training, I would say, is quite immature and has a lot of room left to improve.”
To be clear, AI model developers will likely continue chasing after larger compute cluster and bigger datasets for pretraining, and there’s probably more improvement to eke out of those methods. Elon Musk recently finished building a
supercomputer with 100,000 GPUs, dubbed Colossus, to train xAI’s next models. There will be more, and larger, clusters to come.
But trends suggest exponential growth is not possible by simply using more GPUs with existing strategies, so new methods are suddenly getting more attention.
Test-time compute: The AI industry’s next big bet
When OpenAI released a preview of its o1 model, the startup announced it was part of
a new series of models separate from GPT.
OpenAI improved its GPT models largely through traditional scaling laws: more data, more power during pretraining. But now that method reportedly isn’t gaining them much. The o1 framework of models relies on a new concept, test-time compute, so called because the computing resources are used after a prompt, not before. The technique hasn’t been explored much yet in the context of neural networks, but is already showing promise.
Some are already pointing to test-time compute as the next method to scale AI systems.
“A number of experiments are showing that even though pretraining scaling laws may be slowing, the test-time scaling laws — where you give the model more compute at inference — can give increasing gains in performance,” said a16z’s Midha.
“OpenAI’s new ‘o’ series pushes [chain-of-thought] further, and requires far more computing resources, and therefore energy, to do so,” said famed AI researcher Yoshua Bengio in an
op-ed on Tuesday. “We thus see a new form of computational scaling appear. Not just more training data and larger models but more time spent ‘thinking’ about answers.”
Over a period of 10 to 30 seconds, OpenAI’s o1 model re-prompts itself several times, breaking down a large problem into a series of smaller ones. Despite ChatGPT saying it is “thinking,” it isn’t doing what humans do — although our internal problem-solving methods, which benefit from clear restatement of a problem and stepwise solutions, were key inspirations for the method.
A decade or so back, Noam Brown, who now leads OpenAI’s work on o1, was trying to build AI systems that could beat humans at poker. During a
recent talk, Brown says he noticed at the time how human poker players took time to consider different scenarios before playing a hand. In 2017,
he introduced a method to let a model “think” for 30 seconds before playing. In that time, the AI was playing different subgames, figuring out how different scenarios would play out to determine the best move.
Ultimately, the AI performed seven times better than his past attempts.
Granted, Brown’s research in 2017 did not use neural networks, which weren’t as popular at the time. However, MIT researchers released a paper last week showing that
test-time compute significantly improves an AI model’s performance on reasoning tasks.
It’s not immediately clear how test-time compute would scale. It could mean that AI systems need a really long time to think about hard questions; maybe hours or even days. Another approach could be letting an AI model “think” through a questions on lots of chips simultaneously.
If test-time compute does take off as the next place to scale AI systems, Midha says the demand for AI chips that specialize in high-speed inference could go up dramatically. This could be good news for startups such as Groq or Cerebras, which specialize in fast AI inference chips. If finding the answer is just as compute-heavy as training the model, the “pick and shovel” providers in AI win again.
The AI world is not yet panicking
Most of the AI world doesn’t seem to be losing their cool about these old scaling laws slowing down. Even if test-time compute does not prove to be the next wave of scaling, some feel we’re only scratching the surface of applications for current AI models.
New popular products could buy AI model developers some time to figure out new ways to improve the underlying models.
“I’m completely convinced we’re going to see at least 10 to 20x gains in model performance just through pure application-level work, just allowing the models to shine through intelligent prompting, UX decisions, and passing context at the right time into the models,” said Midha.
For example, ChatGPT’s Advanced Voice Mode is one the more impressive applications from current AI models. However, that was largely an innovation in user experience, not necessarily the underlying tech. You can see how further UX innovations, such as giving that feature access to the web or applications on your phone, would make the product that much better.
Kian Katanforoosh, the CEO of AI startup Workera and a Stanford adjunct lecturer on deep learning, tells TechCrunch that companies building AI applications, like his, don’t necessarily need exponentially smarter models to build better products. He also says the products around current models have a lot of room to get better.
“Let’s say you build AI applications and your AI hallucinates on a specific task,” said Katanforoosh. “There are two ways that you can avoid that. Either the LLM has to get better and it will stop hallucinating, or the tooling around it has to get better and you’ll have opportunities to fix the issue.”
Whatever the case is for the frontier of AI research, users probably won’t feel the effects of these shifts for some time. That said, AI labs will do whatever is necessary to continue shipping bigger, smarter, and faster models at the same rapid pace. That means several leading tech companies could now pivot how they’re pushing the boundaries of AI.

 Nexa AI team created OmniVision-968M, the world's smallest vision-language model that packs quite a punch for its size.
Nexa AI team created OmniVision-968M, the world's smallest vision-language model that packs quite a punch for its size. Implements native "listening" abilities in LLMs, similar to Siri but runs locally on-device
Implements native "listening" abilities in LLMs, similar to Siri but runs locally on-device
















 : Disco Sculptures by ClaraCo
: Disco Sculptures by ClaraCo
 Mind-blowing work by the team at @FLAIR_Ox! They've created Kinetix, a framework for training general-purpose RL agents that can tackle physics-based challenges.
Mind-blowing work by the team at @FLAIR_Ox! They've created Kinetix, a framework for training general-purpose RL agents that can tackle physics-based challenges. Congrats @mitrma and team.
Congrats @mitrma and team.
 Kinetix can represent problems ranging from robotic locomotion and grasping, to classic RL environments and video games, all within a unified framework. This opens the door to training a single generalist agent for all these tasks!
Kinetix can represent problems ranging from robotic locomotion and grasping, to classic RL environments and video games, all within a unified framework. This opens the door to training a single generalist agent for all these tasks! By procedurally generating random environments, we train an RL agent that can zero-shot solve unseen handmade problems. This includes some where RL from scratch fails!
By procedurally generating random environments, we train an RL agent that can zero-shot solve unseen handmade problems. This includes some where RL from scratch fails!

 Each environment has the same goal: make
Each environment has the same goal: make  Our general agent shows emergent physical reasoning capabilities, for instance being able to zero-shot control unseen morphologies by moving them underneath a goal (
Our general agent shows emergent physical reasoning capabilities, for instance being able to zero-shot control unseen morphologies by moving them underneath a goal ( ).
).
 One big takeaway from this work is the importance of autocurricula. In particular, we found significantly improved results by dynamically prioritising levels with high 'learnability'.
One big takeaway from this work is the importance of autocurricula. In particular, we found significantly improved results by dynamically prioritising levels with high 'learnability'.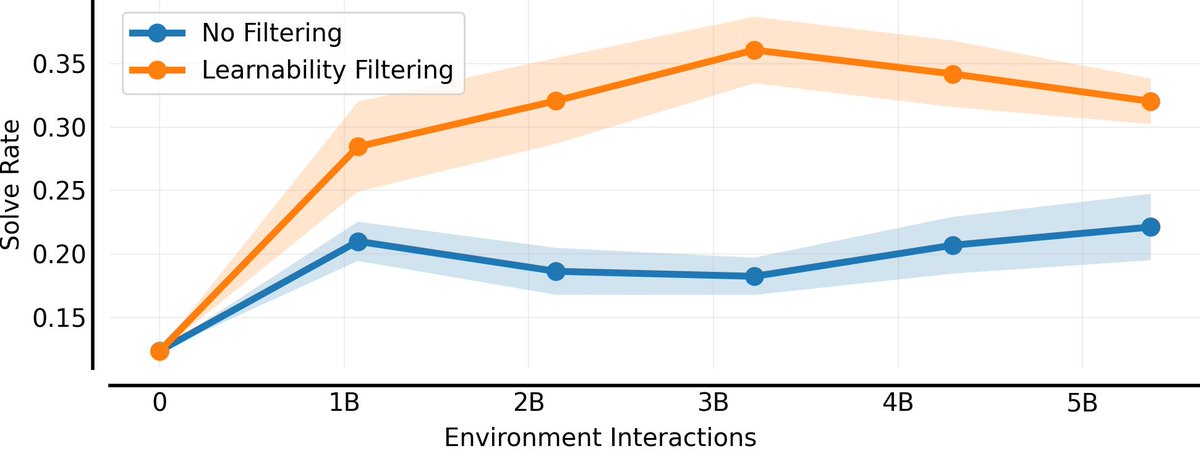
 The core of Kinetix is our new 2D rigid body physics engine: Jax2D. This is a minimal rewrite of the classic Box2D engine made by @erin_catto. Jax2D allows us to run thousands of heterogeneous parallel environments on a single GPU (yes, you can vmap over different tasks!)
The core of Kinetix is our new 2D rigid body physics engine: Jax2D. This is a minimal rewrite of the classic Box2D engine made by @erin_catto. Jax2D allows us to run thousands of heterogeneous parallel environments on a single GPU (yes, you can vmap over different tasks!) Don't take our word for it, try it out for yourself!
Don't take our word for it, try it out for yourself!













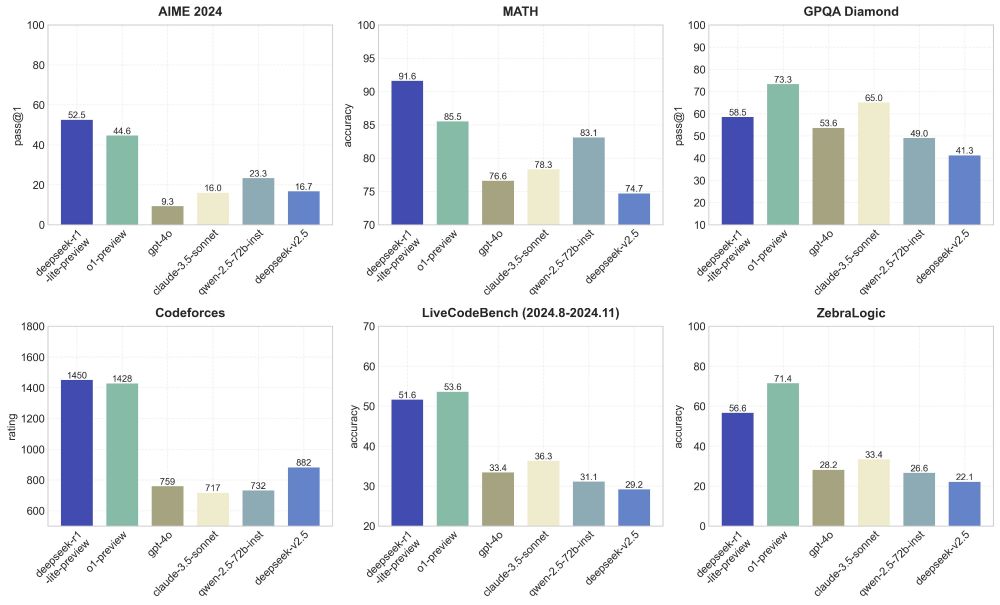
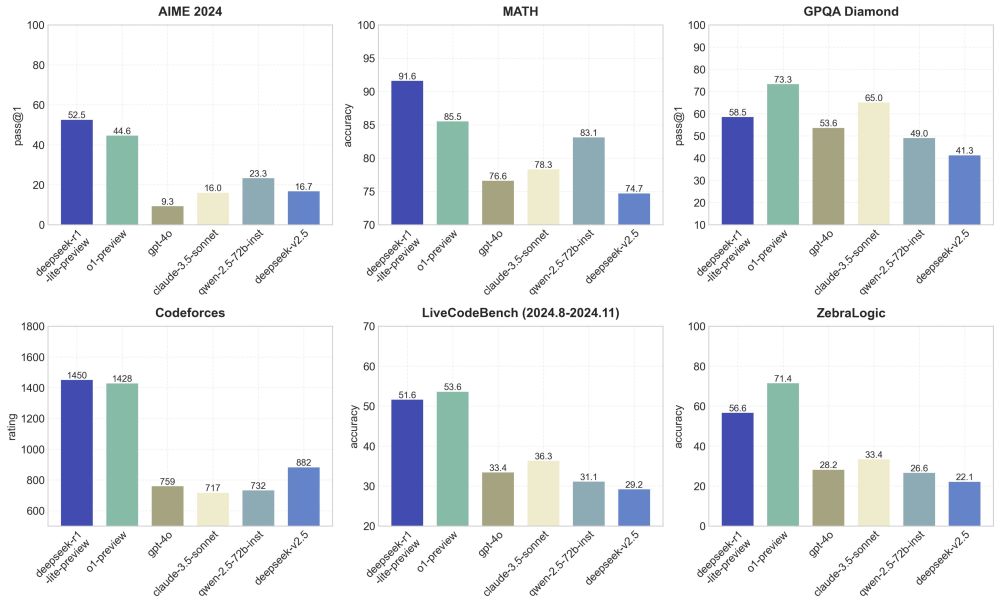
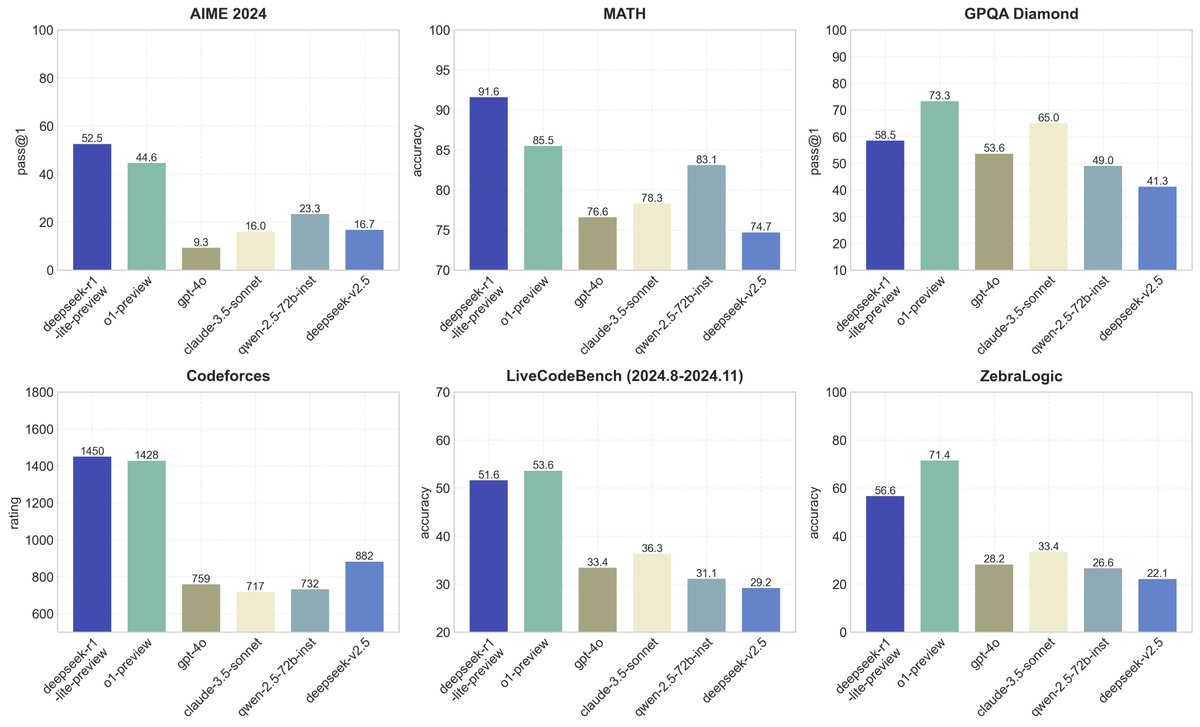
 o1-preview-level performance on AIME & MATH benchmarks.
o1-preview-level performance on AIME & MATH benchmarks. Transparent thought process in real-time.
Transparent thought process in real-time. Open-source models & API coming soon!
Open-source models & API coming soon! Try it now at
Try it now at 

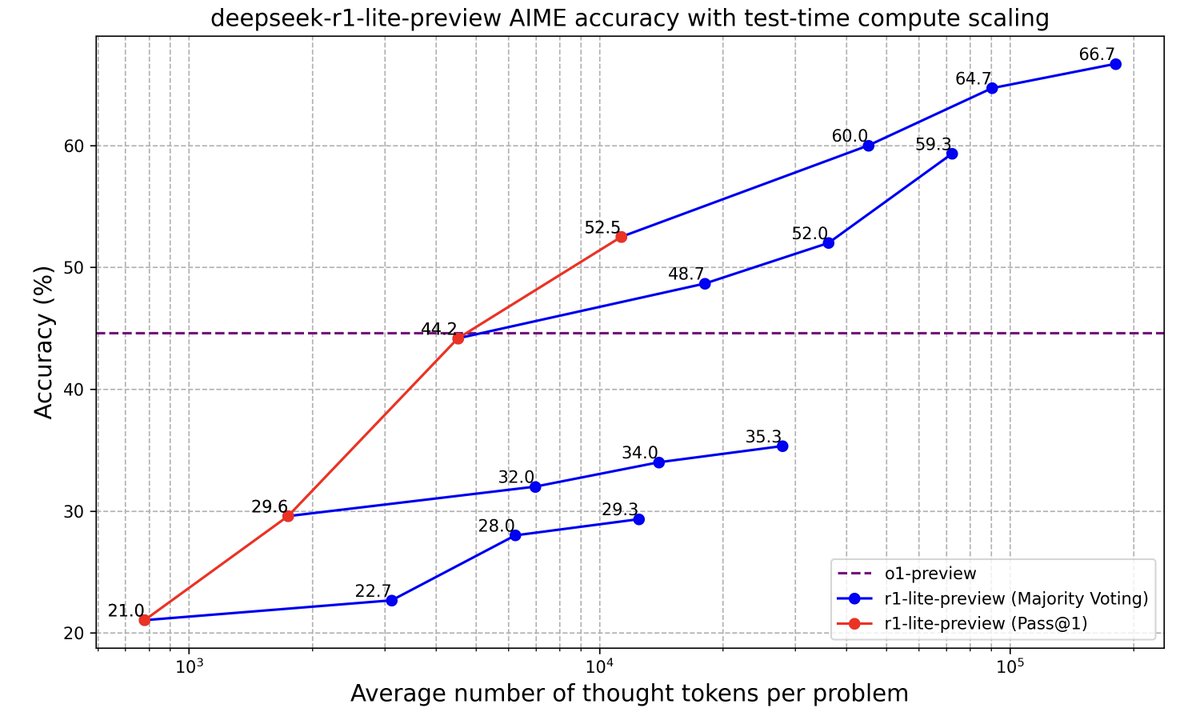
























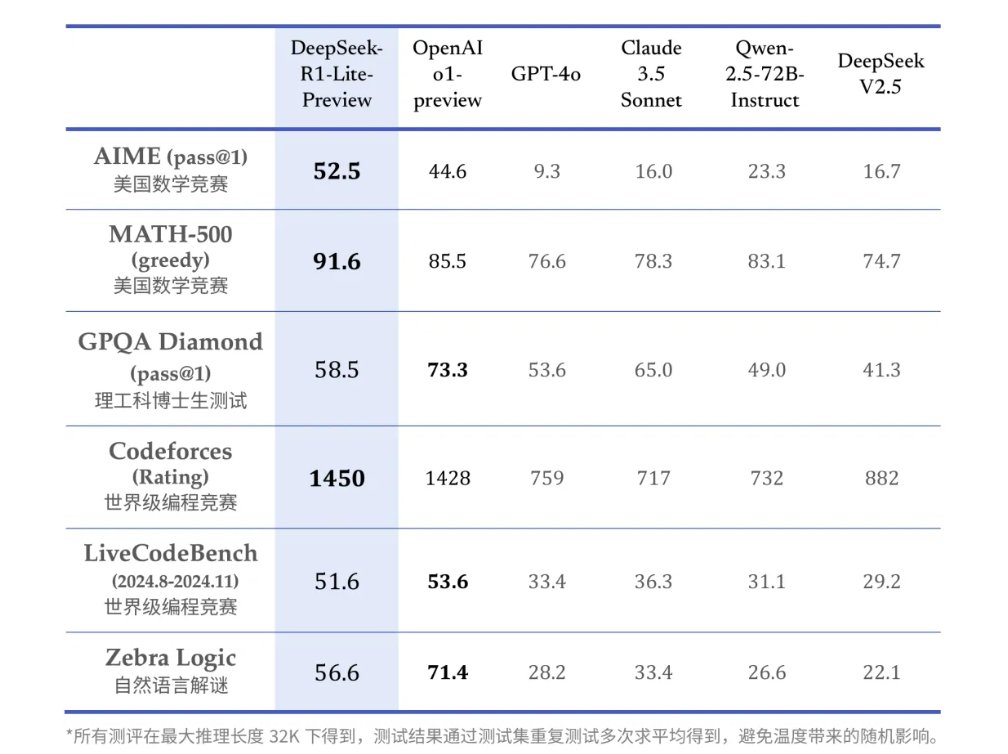




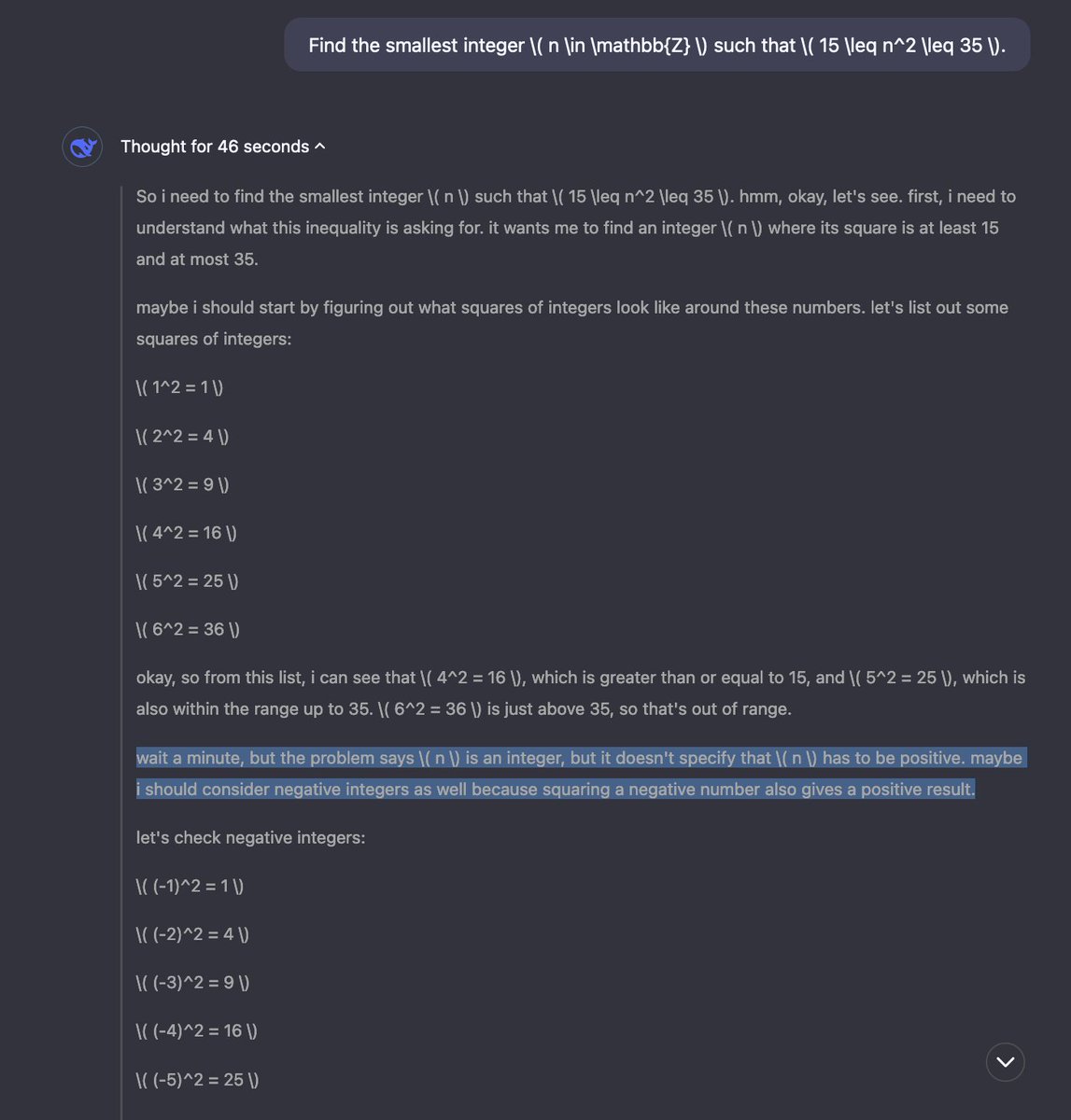







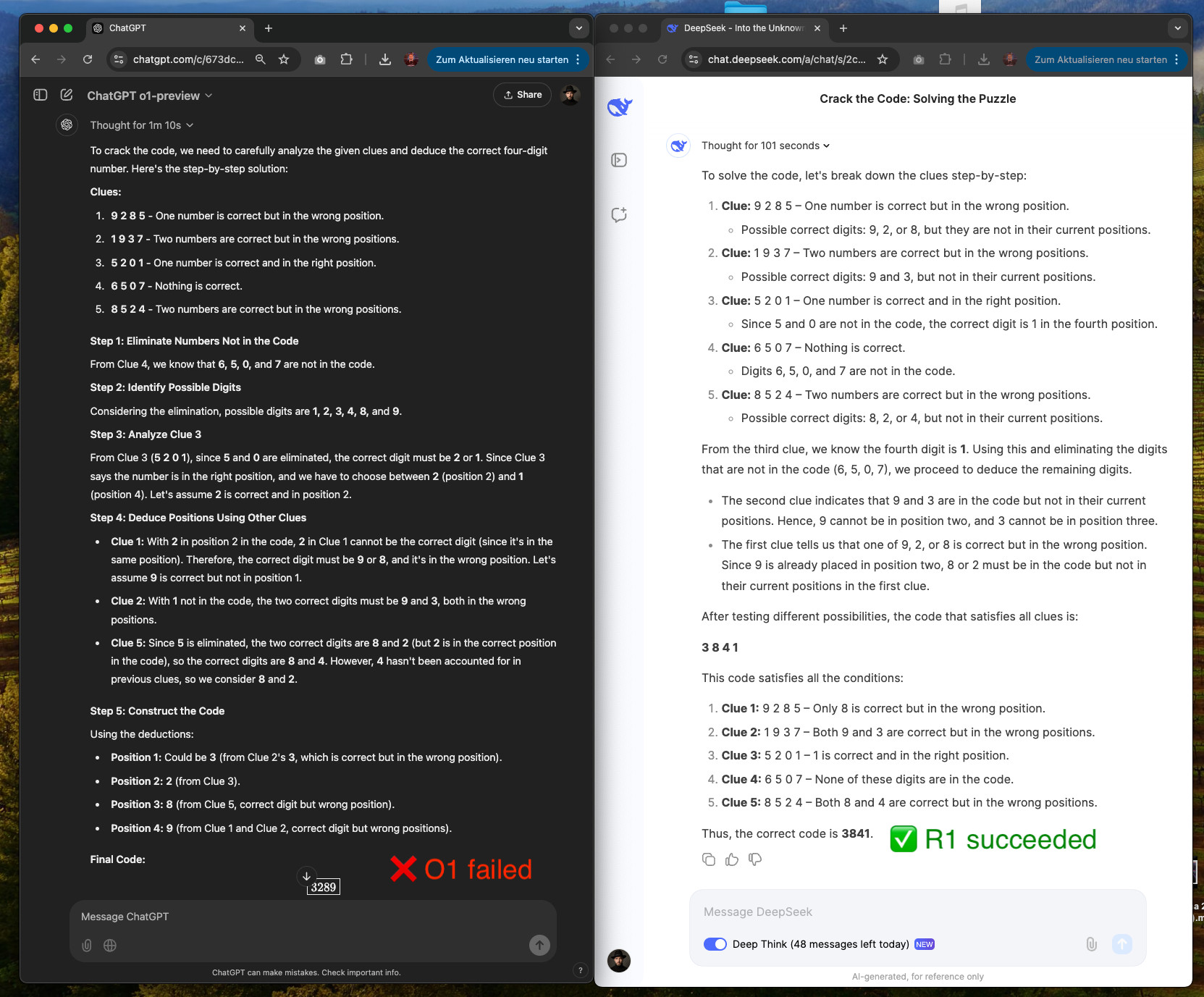
 New reasoning model preview from @deepseek_ai that matches @OpenAI o1!
New reasoning model preview from @deepseek_ai that matches @OpenAI o1!  DeepSeek-R1-Lite-Preview is now live to test in deepseek chat designed for long Reasoning!
DeepSeek-R1-Lite-Preview is now live to test in deepseek chat designed for long Reasoning! 



 @din_lol_ GODIN
@din_lol_ GODIN