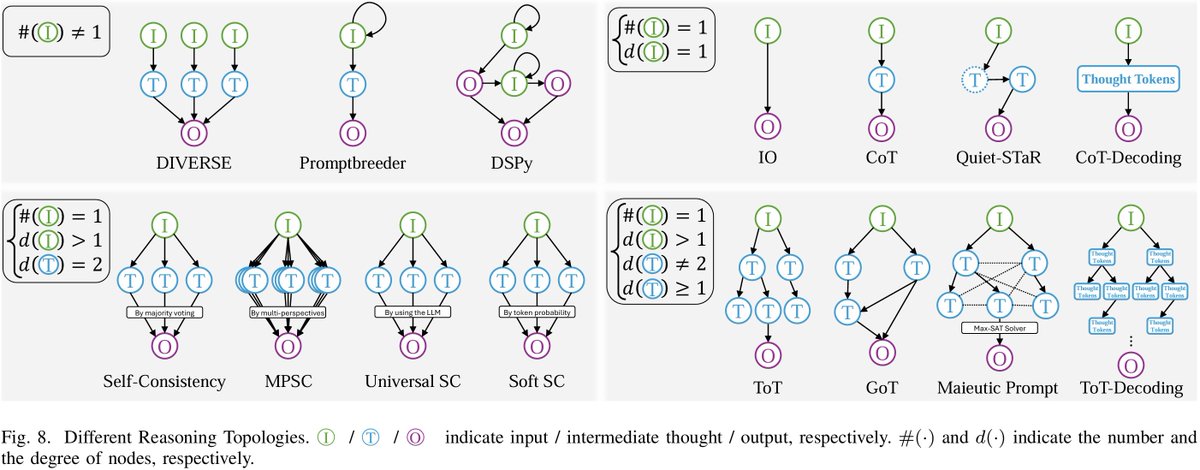
1/10
@omarsar0
Thinking LLMs
How difficult is it to train LLMs to do explicit "thinking" before responding to questions or tasks?
This work proposes a training method to equip LLMs with thinking abilities for general instruction-following without human-annotated data.
It uses an iterative search and optimization procedure to explore thought generation which enables the model to learn without direct supervision.
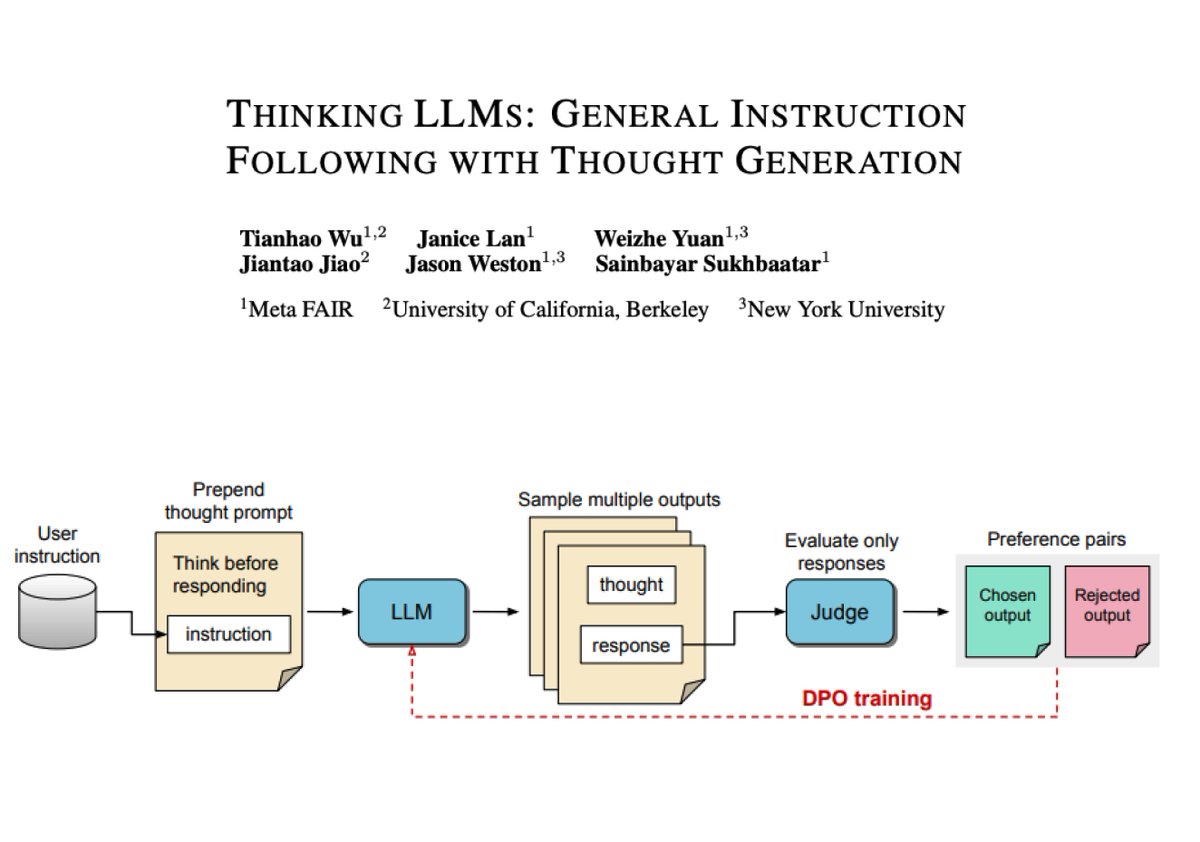
Thought candidates for each user instruction are scored with a judge model. Note that only the responses are evaluated by the Judge which determines the best and worst ones.
Then the corresponding full outputs are used as chosen and rejected pairs for DPO (referred to as Thought Preference Optimization in this paper). This entails the full training process that involves multiple iterations.
Overall, this is a simple yet very effective approach to incentivizing the model to generate its own thoughts without explicitly teaching it how to think. The authors also find that these Thinking LLMs are effective even in problems that often don't rely on reasoning or CoT methods.
2/10
@omarsar0
Paper: [2410.10630] Thinking LLMs: General Instruction Following with Thought Generation
3/10
@ninataft
AI's new thinking cap: Now with less coffee, more thought bubbles, and zero existential crises!

4/10
@BensenHsu
The paper focuses on training large language models (LLMs) to have the ability to "think" before providing a response, similar to how humans think before answering a complex question. This is called "Thinking LLMs". The authors argue that thinking can be beneficial for a wide range of tasks, not just logical or math-related ones.
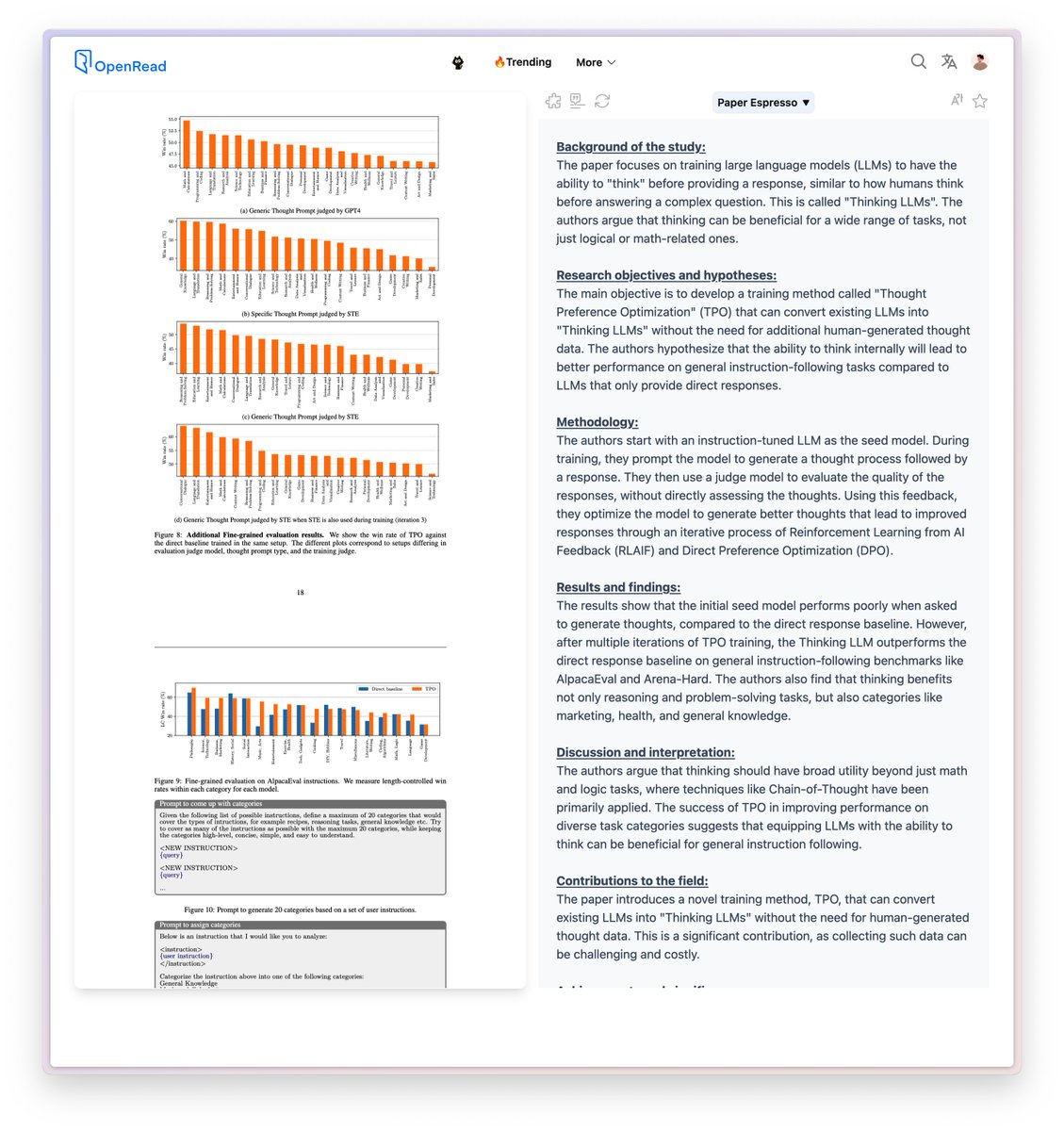
The results show that the initial seed model performs poorly when asked to generate thoughts, compared to the direct response baseline. However, after multiple iterations of TPO training, the Thinking LLM outperforms the direct response baseline on general instruction-following benchmarks like AlpacaEval and Arena-Hard. The authors also find that thinking benefits not only reasoning and problem-solving tasks, but also categories like marketing, health, and general knowledge.
full paper: THINKING LLMS: GENERAL INSTRUCTION FOLLOWING WITH THOUGHT GENERATION
5/10
@LaurenceBrem
From the abstract, it still feels like inference is happening in some form before responding. Still impressive!
6/10
@bytetweets
It’s not thinking, it is reasoning.
7/10
@Anonymo74027124
Interesting concept. Curious to see the results of this training method. Will keep an eye on its progress.
8/10
@jackshiels
It’s actually very interesting how so many researchers missed this. The need for compute probably left many with an implicit assumption that ‘compute is bad’, meaning it was overlooked.
9/10
@bate5a55
Interesting that the 'Judge' component evaluates only the responses, allowing the LLM to generate unfiltered thoughts. This might enable emergent metacognition, a capability rarely seen in AI models.
10/10
@gpt_biz
This sounds like an exciting development in AI research! It's impressive to see models being trained to think more independently without needing human annotations. Looking forward to the future possibilities!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@omarsar0
Thinking LLMs
How difficult is it to train LLMs to do explicit "thinking" before responding to questions or tasks?
This work proposes a training method to equip LLMs with thinking abilities for general instruction-following without human-annotated data.
It uses an iterative search and optimization procedure to explore thought generation which enables the model to learn without direct supervision.
Thought candidates for each user instruction are scored with a judge model. Note that only the responses are evaluated by the Judge which determines the best and worst ones.
Then the corresponding full outputs are used as chosen and rejected pairs for DPO (referred to as Thought Preference Optimization in this paper). This entails the full training process that involves multiple iterations.
Overall, this is a simple yet very effective approach to incentivizing the model to generate its own thoughts without explicitly teaching it how to think. The authors also find that these Thinking LLMs are effective even in problems that often don't rely on reasoning or CoT methods.
2/10
@omarsar0
Paper: [2410.10630] Thinking LLMs: General Instruction Following with Thought Generation
3/10
@ninataft
AI's new thinking cap: Now with less coffee, more thought bubbles, and zero existential crises!
4/10
@BensenHsu
The paper focuses on training large language models (LLMs) to have the ability to "think" before providing a response, similar to how humans think before answering a complex question. This is called "Thinking LLMs". The authors argue that thinking can be beneficial for a wide range of tasks, not just logical or math-related ones.
The results show that the initial seed model performs poorly when asked to generate thoughts, compared to the direct response baseline. However, after multiple iterations of TPO training, the Thinking LLM outperforms the direct response baseline on general instruction-following benchmarks like AlpacaEval and Arena-Hard. The authors also find that thinking benefits not only reasoning and problem-solving tasks, but also categories like marketing, health, and general knowledge.
full paper: THINKING LLMS: GENERAL INSTRUCTION FOLLOWING WITH THOUGHT GENERATION
5/10
@LaurenceBrem
From the abstract, it still feels like inference is happening in some form before responding. Still impressive!
6/10
@bytetweets
It’s not thinking, it is reasoning.
7/10
@Anonymo74027124
Interesting concept. Curious to see the results of this training method. Will keep an eye on its progress.
8/10
@jackshiels
It’s actually very interesting how so many researchers missed this. The need for compute probably left many with an implicit assumption that ‘compute is bad’, meaning it was overlooked.
9/10
@bate5a55
Interesting that the 'Judge' component evaluates only the responses, allowing the LLM to generate unfiltered thoughts. This might enable emergent metacognition, a capability rarely seen in AI models.
10/10
@gpt_biz
This sounds like an exciting development in AI research! It's impressive to see models being trained to think more independently without needing human annotations. Looking forward to the future possibilities!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196







 :
: :
:


 The naive ICRL approach failed miserably, with models quickly degenerating to always predicting the same output. This was due to an inability to explore and difficulty learning from complex in-context signals like negative rewards.
The naive ICRL approach failed miserably, with models quickly degenerating to always predicting the same output. This was due to an inability to explore and difficulty learning from complex in-context signals like negative rewards. So two key modifications are introduced by the authors to make to address the exploration problem in ICRL
So two key modifications are introduced by the authors to make to address the exploration problem in ICRL



 ):
):