At the TED AI conference, OpenAI’s Noam Brown unveiled the o1 model, showcasing how "System Two Thinking" could transform industries by enabling AI to deliver smarter, more deliberate decision-making.

venturebeat.com
OpenAI scientist Noam Brown stuns TED AI Conference: ’20 seconds of thinking worth 100,000x more data’
Michael Nuñez@MichaelFNunez
October 23, 2024 12:46 PM
Credit: VentureBeat made with Midjourney
Noam Brown, a leading research scientist at
OpenAI, took the stage at the
TED AI conference in San Francisco on Tuesday to deliver a powerful speech on the future of artificial intelligence, with a particular focus on
OpenAI’s new o1 model and its potential to transform industries through strategic reasoning, advanced coding, and scientific research. Brown, who has previously driven breakthroughs in AI systems like
Libratus, the poker-playing AI, and
CICERO, which mastered the game of Diplomacy, now envisions a future where AI isn’t just a tool, but a core engine of innovation and decision-making across sectors.
“The incredible progress in AI over the past five years can be summarized in one word:
scale,” Brown began, addressing a captivated audience of developers, investors, and industry leaders. “Yes, there have been uplink advances, but the frontier models of today are still based on the same transformer architecture that was introduced in 2017. The main difference is the scale of the data and the compute that goes into it.”
Brown, a central figure in OpenAI’s research endeavors, was quick to emphasize that while scaling models has been a critical factor in AI’s progress, it’s time for a paradigm shift. He pointed to the need for AI to move beyond sheer data processing and into what he referred to as “
system two thinking”—a slower, more deliberate form of reasoning that mirrors how humans approach complex problems.
The psychology behind AI’s next big leap: Understanding system two thinking
To underscore this point, Brown shared a story from his PhD days when he was working on
Libratus, the poker-playing AI that famously defeated top human players in 2017.
“It turned out that having a bot think for just 20 seconds in a hand of poker got the same boosting performance as scaling up the model by 100,000x and training it for 100,000 times longer,” Brown said. “When I got this result, I literally thought it was a bug. For the first three years of my PhD, I had managed to scale up these models by 100x. I was proud of that work. I had written
multiple papers on how to do that scaling, but I knew pretty quickly that all that would be a footnote compared to this scaling up system two thinking.”
Brown’s presentation introduced system two thinking as the solution to the limitations of traditional scaling. Popularized by psychologist Daniel Kahneman in the book
Thinking, Fast and Slow, system two thinking refers to a slower, more deliberate mode of thought that humans use for solving complex problems. Brown believes incorporating this approach into AI models could lead to major performance gains without requiring exponentially more data or computing power.
He recounted that allowing
Libratus to think for 20 seconds before making decisions had a profound effect, equating it to scaling the model by 100,000x. “The results blew me away,” Brown said, illustrating how businesses could achieve better outcomes with fewer resources by focusing on system two thinking.
Inside OpenAI’s o1: The revolutionary model that takes time to think
Brown’s talk comes shortly after the release of OpenAI’s
o1 series models, which introduce system two thinking into AI. Launched in September 2024, these models are designed to process information more carefully than their predecessors, making them ideal for complex tasks in fields like scientific research, coding, and strategic decision-making.
“We’re no longer constrained to just scaling up the system one training. Now we can scale up the system two thinking as well, and the beautiful thing about scaling up in this direction is that it’s largely untapped,” Brown explained. “This isn’t a revolution that’s 10 years away or even two years away. It’s a revolution that’s happening now.”
The o1 models have already demonstrated strong performance in
various benchmarks. For instance, in a qualifying exam for the International Mathematics Olympiad, the o1 model achieved an 83% accuracy rate—a significant leap from the 13% scored by OpenAI’s GPT-4o. Brown noted that the ability to reason through complex mathematical formulas and scientific data makes the o1 model especially valuable for industries that rely on data-driven decision-making.
The business case for slower AI: Why patience pays off in enterprise solutions
For businesses, OpenAI’s o1 model offers benefits beyond academic performance. Brown emphasized that scaling system two thinking could improve decision-making processes in industries like healthcare, energy, and finance. He used cancer treatment as an example, asking the audience, “Raise your hand if you would be willing to pay more than $1 for a new cancer treatment… How about $1,000? How about a million dollars?”
Brown suggested that the o1 model could help researchers speed up data collection and analysis, allowing them to focus on interpreting results and generating new hypotheses. In energy, he noted that the model could accelerate the development of more efficient solar panels, potentially leading to breakthroughs in renewable energy.
He acknowledged the skepticism about slower AI models. “When I mention this to people, a frequent response that I get is that people might not be willing to wait around for a few minutes to get a response, or pay a few dollars to get an answer to the question,” he said. But for the most important problems, he argued, that cost is well worth it.
Silicon Valley’s new AI race: Why processing power isn’t everything
OpenAI’s shift toward system two thinking could reshape the competitive landscape for AI, especially in enterprise applications. While most current models are optimized for speed, the deliberate reasoning process behind o1 could offer businesses more accurate insights, particularly in industries like finance and healthcare.
In the tech sector, where companies like
Google and
Meta are heavily investing in AI, OpenAI’s focus on deep reasoning sets it apart. Google’s
Gemini AI, for instance, is optimized for multimodal tasks, but it remains to be seen how it will compare to OpenAI’s models in terms of problem-solving capabilities.
That said, the cost of implementing o1 could limit its widespread adoption. The model is slower and more expensive to run than previous versions. Reports indicate that the o1-preview model costs
$15 per million input tokens and
$60 per million output tokens, far more than GPT-4o. Still, for enterprises that need high-accuracy outputs, the investment may be worthwhile.
As Brown concluded his talk, he emphasized that AI development is at a critical juncture: “Now we have a new parameter, one where we can scale up system two thinking as well — and we are just at the very beginning of scaling up in this direction.”

 @huggingface paper-page is now available directly through arXiv
@huggingface paper-page is now available directly through arXiv









 QAT + LoRA Method
QAT + LoRA Method SpinQuant Method
SpinQuant Method Key Differences
Key Differences










 gpt ass
gpt ass
 @JuliusAI_
@JuliusAI_
 /search?q=#BetterLateThanNever
/search?q=#BetterLateThanNever

 克劳德宝贝加油
克劳德宝贝加油 :
: :
: :
:
 LenCtrl-Bench Details
LenCtrl-Bench Details Vanilla Prompting:
Vanilla Prompting: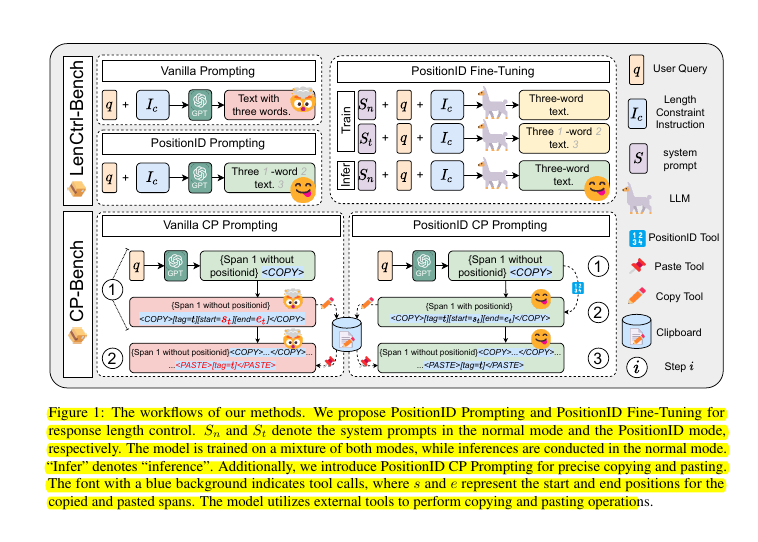

 :PositionID: LLMs can Control Lengths, Copy and Paste with Explicit Positional Awareness
:PositionID: LLMs can Control Lengths, Copy and Paste with Explicit Positional Awareness :
:





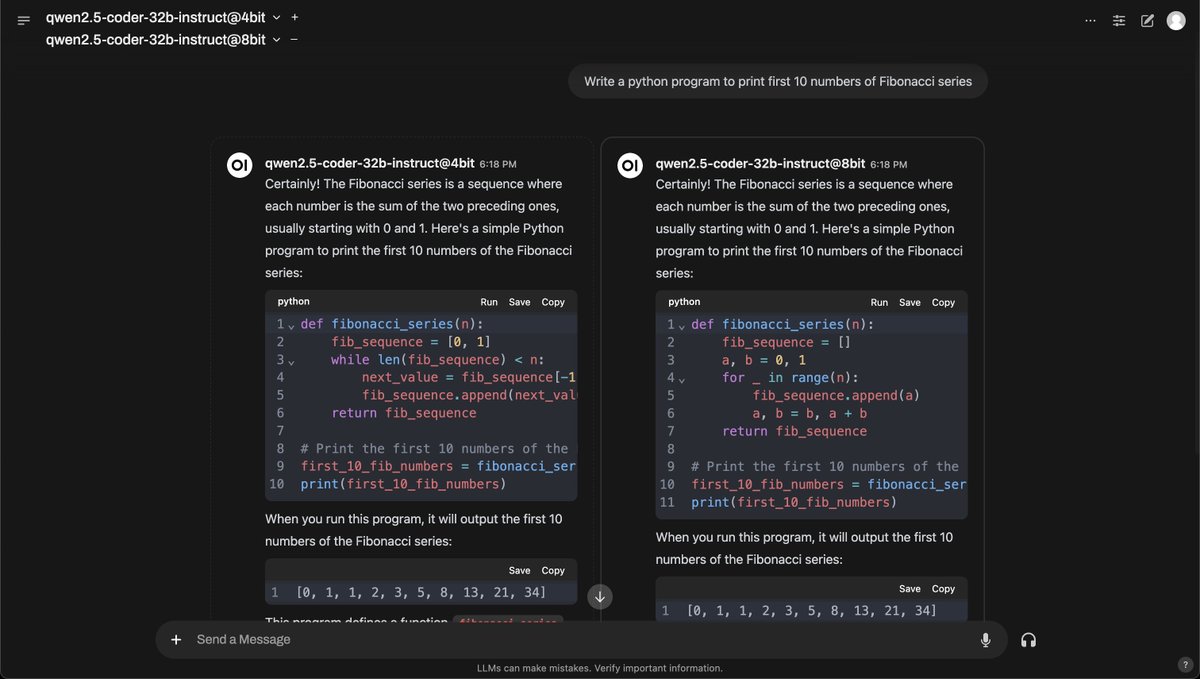


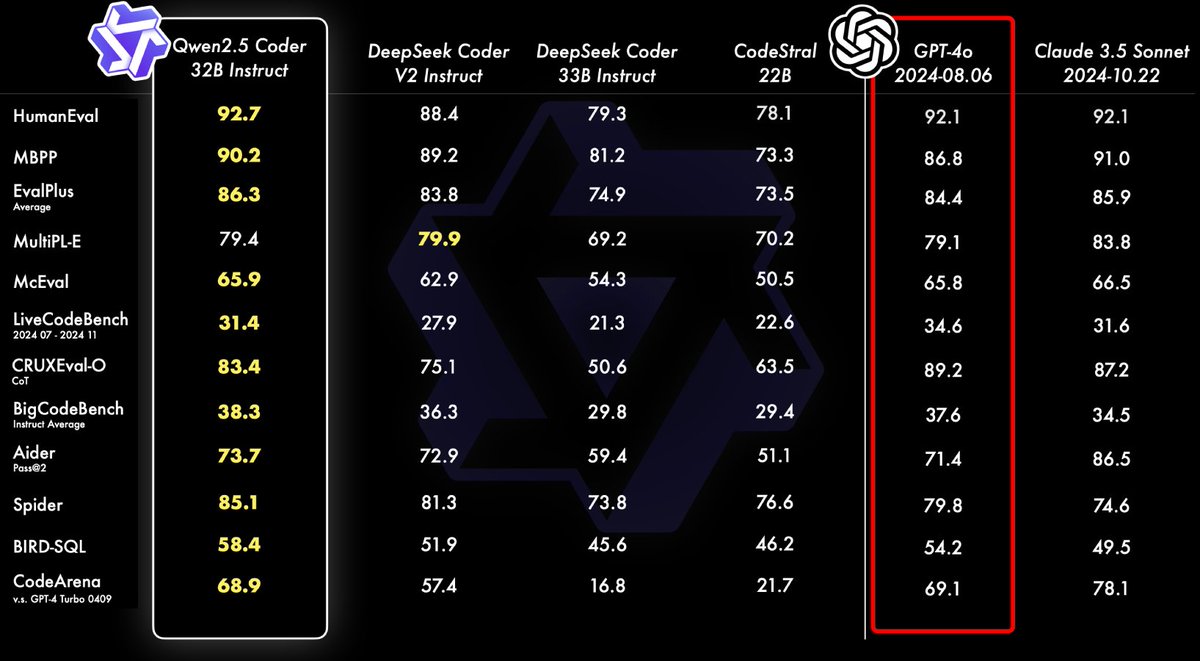

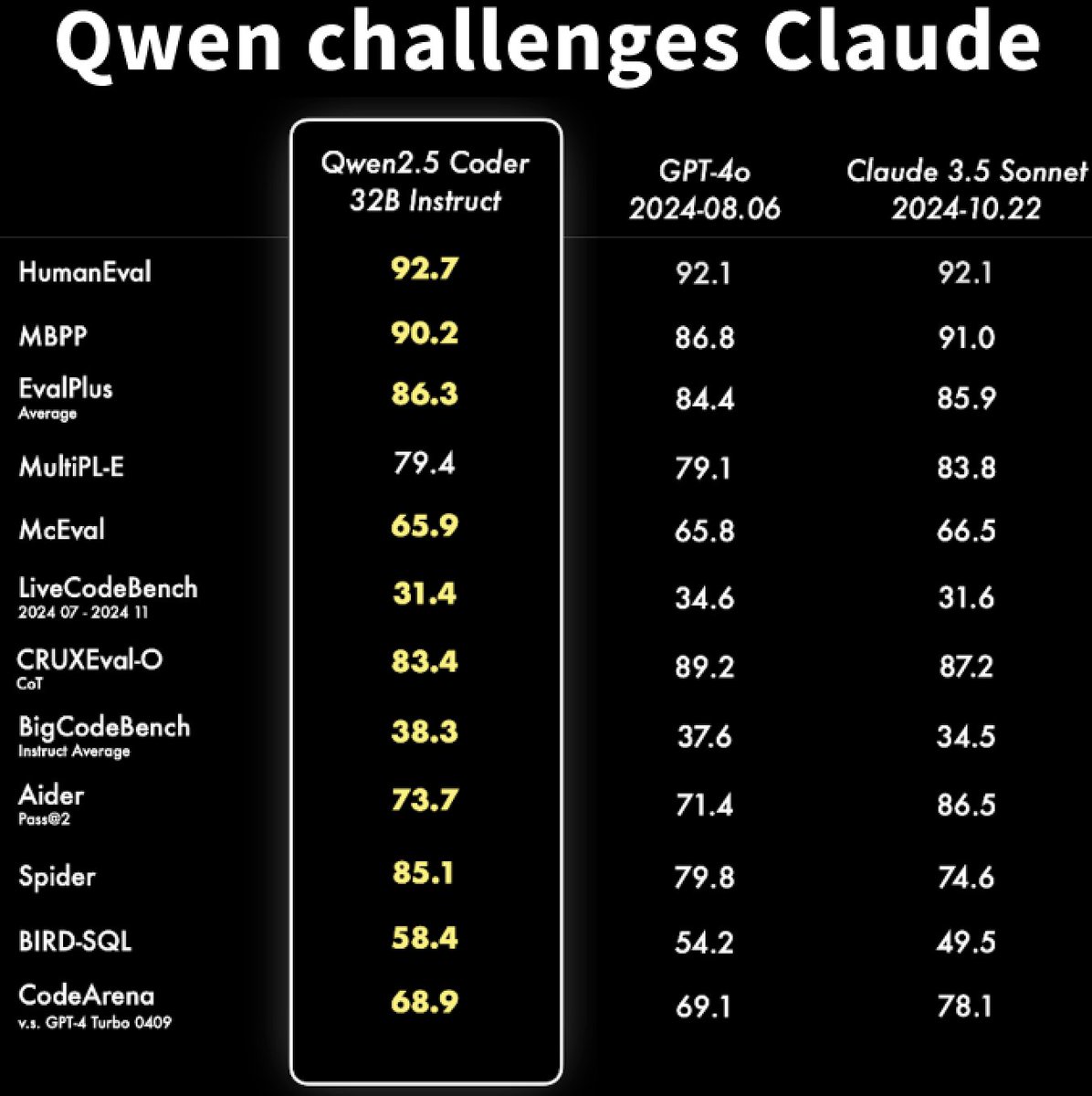
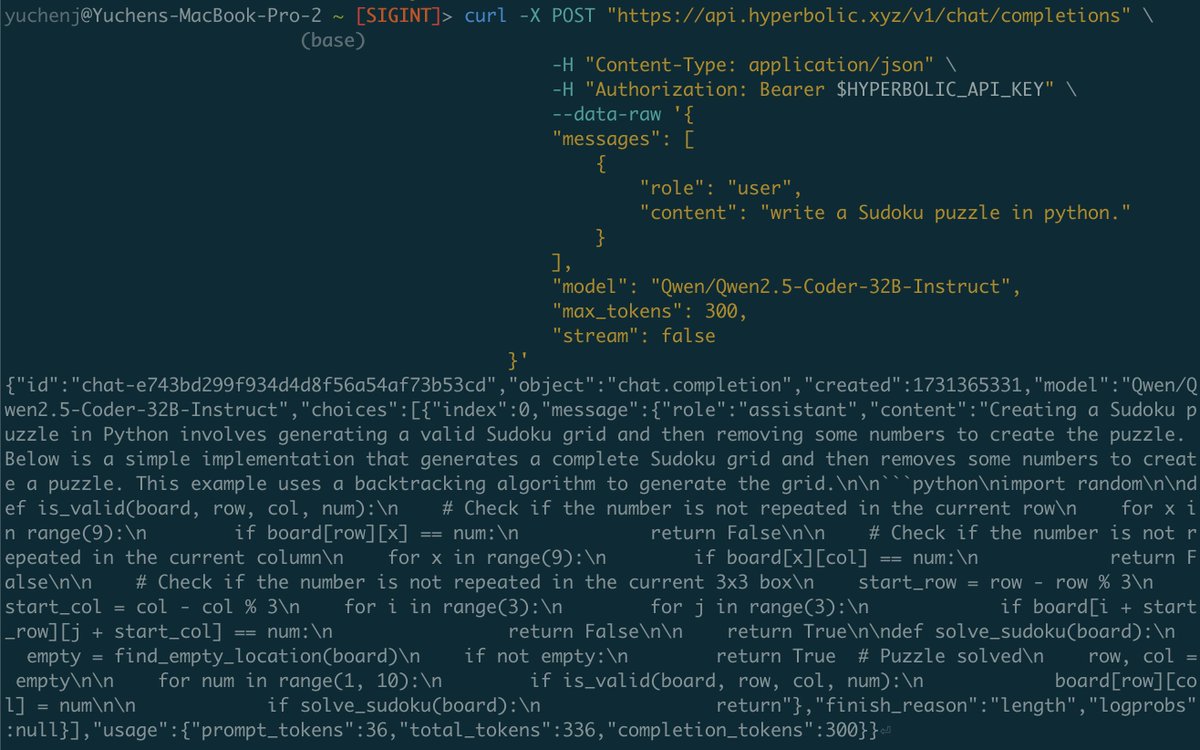
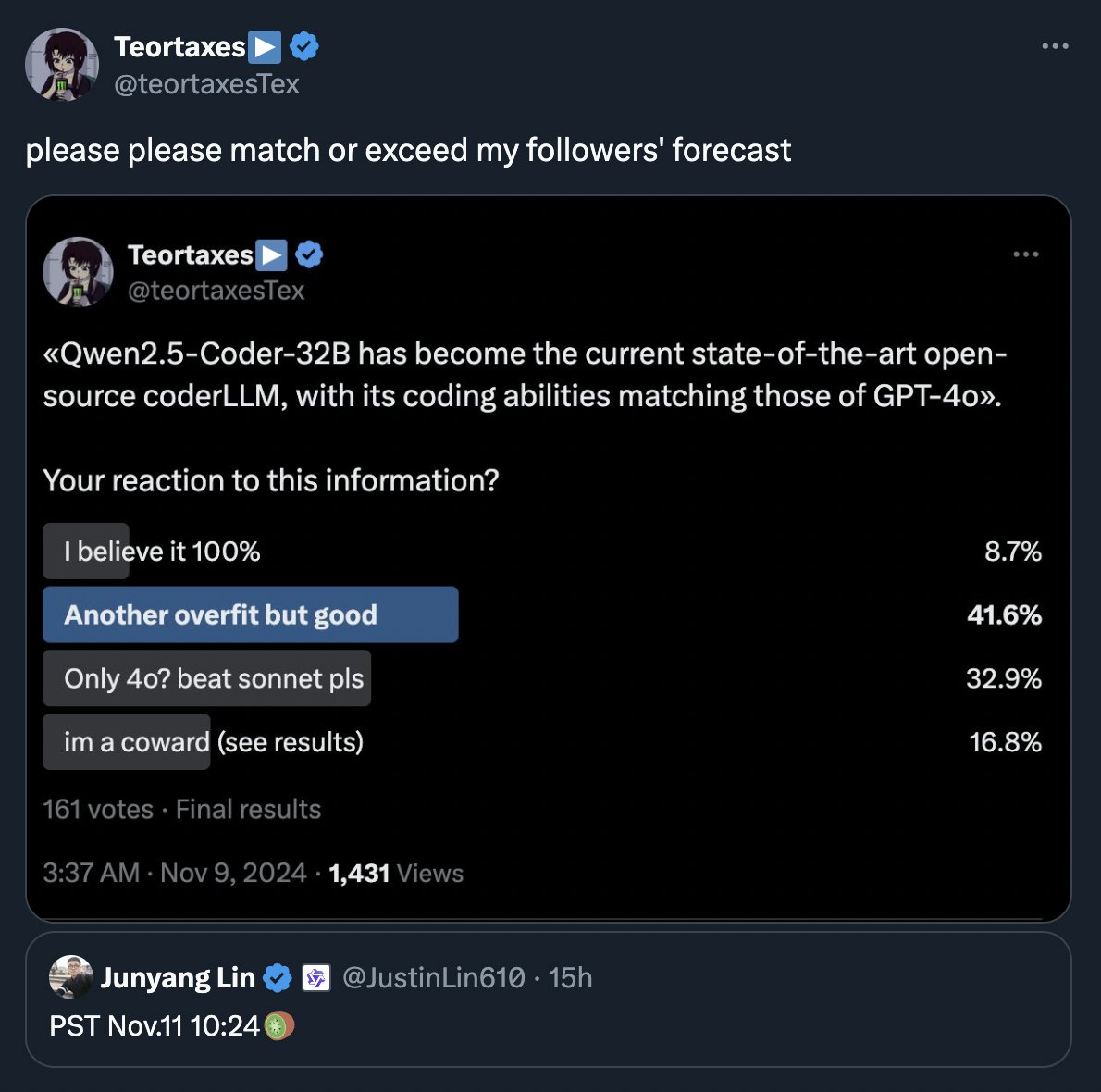


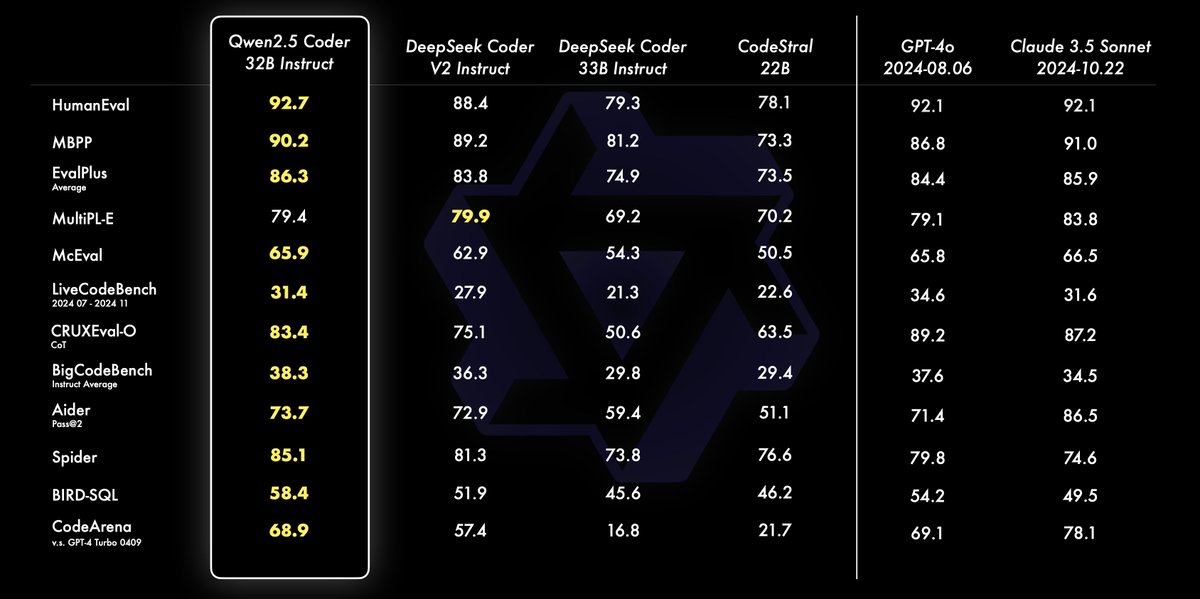
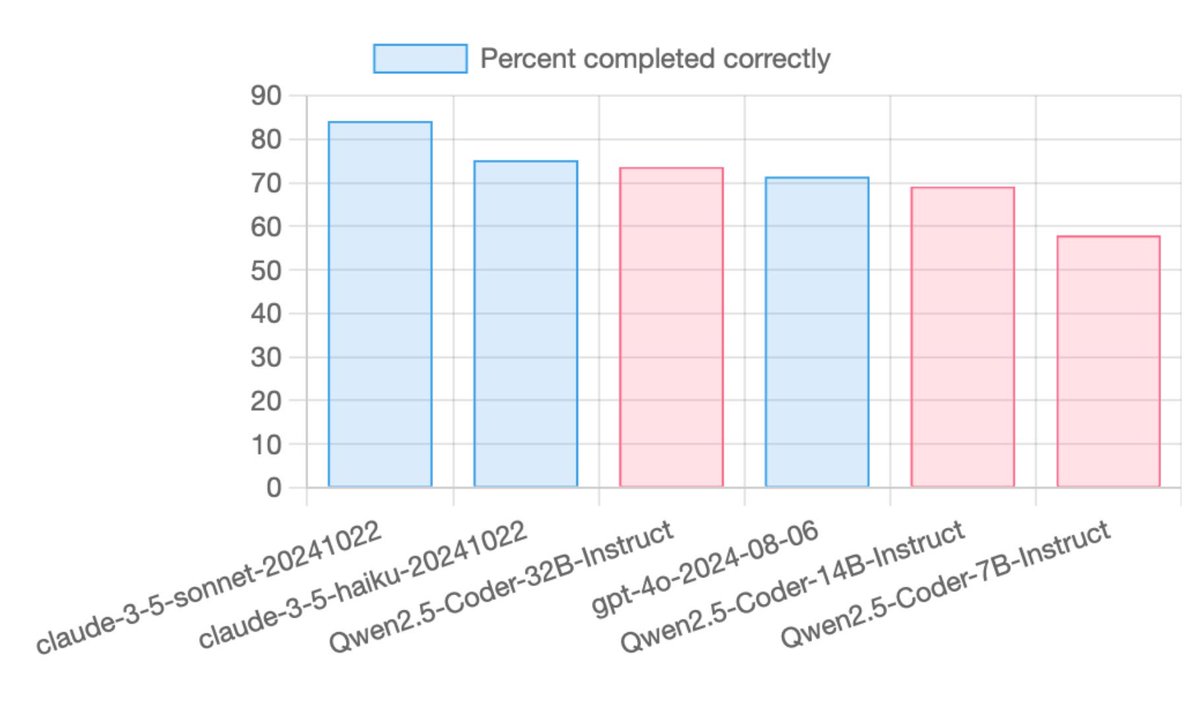
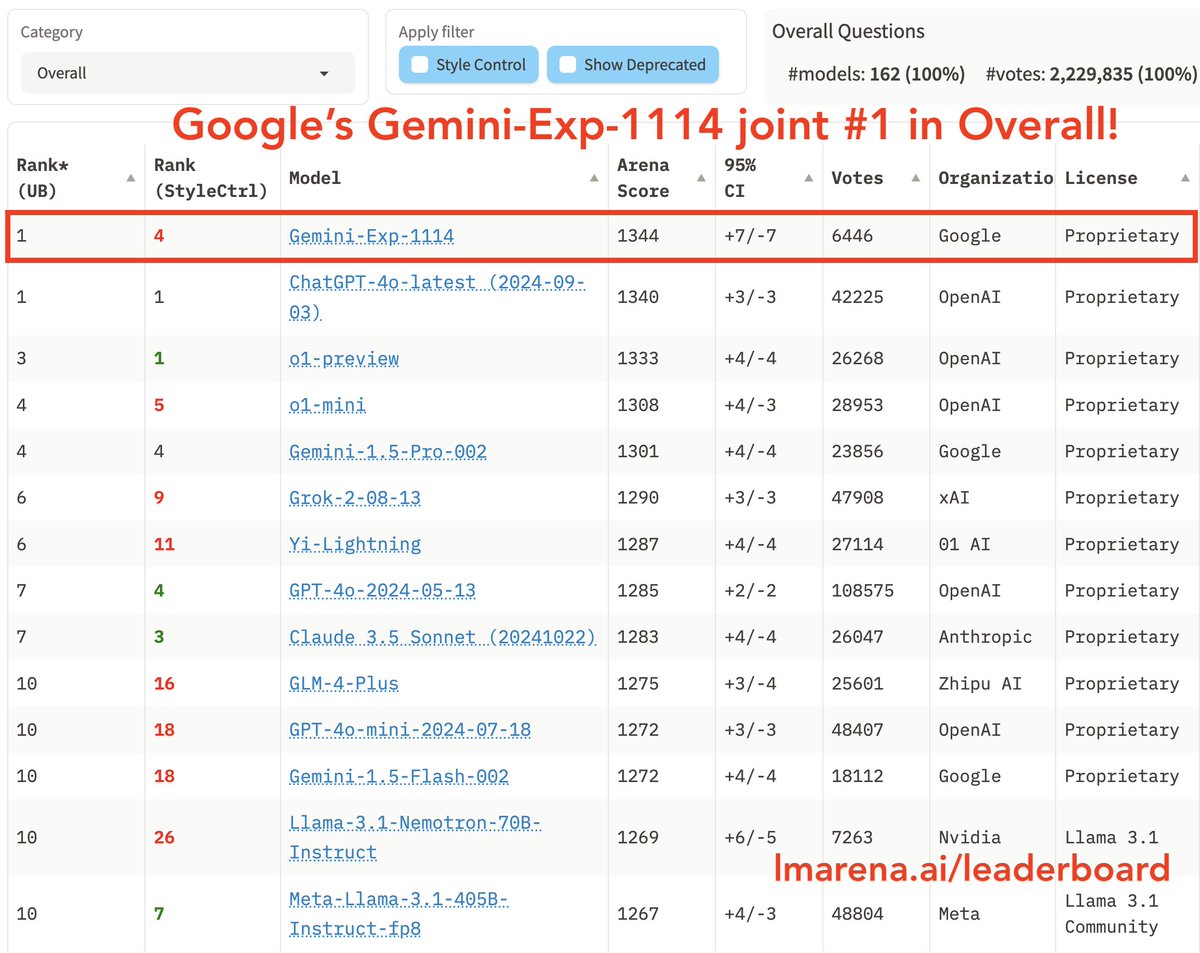
 Qwen2.5-Coder Instruct demos:
Qwen2.5-Coder Instruct demos:  Our tutorial on using Qwen2.5 Coder 32B on Hyperstack is coming very soon - keep an eye out!
Our tutorial on using Qwen2.5 Coder 32B on Hyperstack is coming very soon - keep an eye out! 

 It's the largest open-source Transformer-based MoE model
It's the largest open-source Transformer-based MoE model


















 #75: What is Metacognitive AI
#75: What is Metacognitive AI












.png?width=1152&height=896&name=watch_display_in_a_luxury_store__background_of_the_store_with_people_undefined%20(1).png "watch_display_in_a_luxury_store__background_of_the_store_with_people_undefined (1)")









