
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?1/15
@jiayi_pirate
Introducing SWE-Gym: An Open Environment for Training Software Engineering Agents & Verifiers
Using SWE-Gym, our agents + verifiers reach new open SOTA - 32%/26% on SWE-Bench Verified/Lite,
showing strong scaling with more train / test compute
GitHub - SWE-Gym/SWE-Gym: Code for Paper: Training Software Engineering Agents and Verifiers with SWE-Gym [ ]
]

2/15
@jiayi_pirate
Progress in SWE agents has been limited by lack of training environments with real-world coverage and execution feedback.
We create SWE-Gym, the first env for training SWE agents, with 2.4K real tasks from 11 Python repos & a Lite split of 234 instances mimicking SWE-Bench Lite.

3/15
@jiayi_pirate
SWE-Gym trains LMs as agents.
When fine-tuned on less than 500 agent-environment interaction trajectories sampled from GPT-4o and Claude, we achieve +14% absolute gains on SWE-Bench Verified with an 32B LM-powered OpenHands agent.

4/15
@jiayi_pirate
SWE-Gym also enables self-improvement.
With rejection sampling fine-tuning and MoatlessTools scaffold, our 32B and 7B models achieve 20% and 10% respectively on SWE-Bench Lite by learning through its interactions on SWE-Gym.

5/15
@jiayi_pirate
SWE-Gym enables inference-time scaling through verifiers trained on agent trajectories.
These verifiers identify most promising solutions via best-of-n selection, together with our learned agents, they achieve 32%/26% on SWE-Bench Verified/Lite, a new open SoTA.

6/15
@jiayi_pirate
Lastly, our ablations reveal strong scaling trends.
Performance is now bottlenecked by train and inference compute, rather than the size of our dataset. Pushing and improving these scaling trends further is an exciting direction for future work.

7/15
@jiayi_pirate
SWE-Gym, along with our strong baselines and comprehensive ablations, provides an exciting foundation for advancing agent training, inference-time scaling research.
Paper: SWE-Gym/assets/paper.pdf at main · SWE-Gym/SWE-Gym
Code/Data: GitHub - SWE-Gym/SWE-Gym: Code for Paper: Training Software Engineering Agents and Verifiers with SWE-Gym
8/15
@jiayi_pirate
It’s fun co-leading the project with @xingyaow_ .
Many thanks to @YizheZhangNLP @alsuhr @hengjinlp @ndjaitly and @gneubig for the insightful advice and guidance.
We are grateful for @modal_labs GPU compute support that made this work possible!
9/15
@jiayi_pirate
The paper's on arxiv now! Training Software Engineering Agents and Verifiers with SWE-Gym
10/15
@yang_zonghan
Huge Congrats, Jiayi and Xingyao! This ambitious project finally ships!!
11/15
@jiayi_pirate
Thank you Zonghan! XD
12/15
@nalin_wadhwa
Great work! Need more work that decrypts the SWE-Bench dataset.
13/15
@ChengZhoujun
Awesome RL infra for SWE!
14/15
@EthanSynthMind
SWE-Gym's scaling potential is wild. Excited to see where it goes next.
15/15
@Evolvedquantum
[Quoted tweet]
x.com/i/grok/share/GSkEnnnre…
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@jiayi_pirate
Introducing SWE-Gym: An Open Environment for Training Software Engineering Agents & Verifiers
Using SWE-Gym, our agents + verifiers reach new open SOTA - 32%/26% on SWE-Bench Verified/Lite,
showing strong scaling with more train / test compute
GitHub - SWE-Gym/SWE-Gym: Code for Paper: Training Software Engineering Agents and Verifiers with SWE-Gym [
]
2/15
@jiayi_pirate
Progress in SWE agents has been limited by lack of training environments with real-world coverage and execution feedback.
We create SWE-Gym, the first env for training SWE agents, with 2.4K real tasks from 11 Python repos & a Lite split of 234 instances mimicking SWE-Bench Lite.
3/15
@jiayi_pirate
SWE-Gym trains LMs as agents.
When fine-tuned on less than 500 agent-environment interaction trajectories sampled from GPT-4o and Claude, we achieve +14% absolute gains on SWE-Bench Verified with an 32B LM-powered OpenHands agent.
4/15
@jiayi_pirate
SWE-Gym also enables self-improvement.
With rejection sampling fine-tuning and MoatlessTools scaffold, our 32B and 7B models achieve 20% and 10% respectively on SWE-Bench Lite by learning through its interactions on SWE-Gym.
5/15
@jiayi_pirate
SWE-Gym enables inference-time scaling through verifiers trained on agent trajectories.
These verifiers identify most promising solutions via best-of-n selection, together with our learned agents, they achieve 32%/26% on SWE-Bench Verified/Lite, a new open SoTA.
6/15
@jiayi_pirate
Lastly, our ablations reveal strong scaling trends.
Performance is now bottlenecked by train and inference compute, rather than the size of our dataset. Pushing and improving these scaling trends further is an exciting direction for future work.
7/15
@jiayi_pirate
SWE-Gym, along with our strong baselines and comprehensive ablations, provides an exciting foundation for advancing agent training, inference-time scaling research.
Paper: SWE-Gym/assets/paper.pdf at main · SWE-Gym/SWE-Gym
Code/Data: GitHub - SWE-Gym/SWE-Gym: Code for Paper: Training Software Engineering Agents and Verifiers with SWE-Gym
8/15
@jiayi_pirate
It’s fun co-leading the project with @xingyaow_ .
Many thanks to @YizheZhangNLP @alsuhr @hengjinlp @ndjaitly and @gneubig for the insightful advice and guidance.
We are grateful for @modal_labs GPU compute support that made this work possible!
9/15
@jiayi_pirate
The paper's on arxiv now! Training Software Engineering Agents and Verifiers with SWE-Gym
10/15
@yang_zonghan
Huge Congrats, Jiayi and Xingyao! This ambitious project finally ships!!
11/15
@jiayi_pirate
Thank you Zonghan! XD
12/15
@nalin_wadhwa
Great work! Need more work that decrypts the SWE-Bench dataset.
13/15
@ChengZhoujun
Awesome RL infra for SWE!
14/15
@EthanSynthMind
SWE-Gym's scaling potential is wild. Excited to see where it goes next.
15/15
@Evolvedquantum
[Quoted tweet]
x.com/i/grok/share/GSkEnnnre…
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/61
@Alibaba_Qwen
 恭喜发财
恭喜发财
 As we welcome the Chinese New Year, we're thrilled to announce the launch of Qwen2.5-VL , our latest flagship vision-language model!
As we welcome the Chinese New Year, we're thrilled to announce the launch of Qwen2.5-VL , our latest flagship vision-language model! 
 Qwen Chat: Qwen Chat
Qwen Chat: Qwen Chat
 Blog: Qwen2.5 VL! Qwen2.5 VL! Qwen2.5 VL!
Blog: Qwen2.5 VL! Qwen2.5 VL! Qwen2.5 VL!
 Hugging Face: Qwen2.5-VL - a Qwen Collection
Hugging Face: Qwen2.5-VL - a Qwen Collection
 ModelScope: Qwen2.5-VL
ModelScope: Qwen2.5-VL
 Key Highlights:
Key Highlights:
* Visual Understanding : From flowers to complex charts, Qwen2.5-VL sees it all!
* Agentic Capabilities : It’s a visual agent that can reason and interact with tools like computers & phones.
* Long Video Comprehension : Captures events in videos over 1 hour long!

* Precise Localization : Generates bounding boxes & JSON outputs for accurate object detection.
* Structured Data Outputs : Perfect for finance & commerce, handling invoices, forms & more!

Try Qwen2.5-VL now at Qwen Chat or explore models on Hugging Face & ModelScope .
https://video.twimg.com/ext_tw_video/1883953375206858755/pu/vid/avc1/1280x720/QO-vyl262bIJYi4T.mp4
2/61
@Alibaba_Qwen

3/61
@Alibaba_Qwen

4/61
@Alibaba_Qwen

5/61
@OrbitMoonAlpha
6!
6/61
@CastelMaker
"Sir, an other model has hit Hugging Face"

7/61
@Art_If_Ficial


8/61
@getpieces
Amazing!! Happy New Year Qwen!


9/61
@RubiksAI
Nice!
10/61
@Yuchenj_UW
恭喜发财!
who wants the new models on Hyperbolic?
11/61
@KinggZoom
This has become a parade
12/61
@AIML4Health
[Quoted tweet]
Happy Chinese New Year to the @Alibaba_Qwen team. You’ve been cooking & we’ve been having fun.
to the @Alibaba_Qwen team. You’ve been cooking & we’ve been having fun.
Best wishes to you and yours. #ChineseNewYear

13/61
@koltregaskes
Fantastic!
14/61
@vedangvatsa
Hidden Gems in Alibaba's Qwen2.5-1M:
[Quoted tweet]
Hidden Gems in Qwen2.5-1M Technical Report

15/61
@arbezos
what the name of this cute bear
16/61
@asrlhhh
Ppl who don’t work on building vertical AI application won’t understand this is a better gift than r1 … Qwen VL has been helping a lot on parsing handwritten documents
17/61
@itsPaulAi
Agentic capabilities look REALLY promising
Congrats on the release!
18/61
@prthgo
Love this, Happy Chinese New year to the whole team.
19/61
@reach_vb
wohoooo! congratulations on the release! Specially the 3B and 7B model checkpoints:
Qwen2.5-VL - a Qwen Collection
20/61
@krishnakaasyap
Qwen QwQ 110B Loooong Reasoner that can curb stomp o1-Pro wen?
21/61
@Olney1Ben
Happy New Year Now you're just trolling OpenAI 
22/61
@brunoclz

23/61
@0xroyce369
let's be honest, Qwen is underrated
24/61
@TheAIVeteran
The hits just keep coming. Keep it up.
25/61
@bitdeep_
Another SOTA? Can you guys stop wing hard a bit? We can keep up here in the western.
26/61
@l0gix5
i have been waiting for this
27/61
@tomlikestocode
Congratulations on the launch of Qwen2.5-VL! The advancements in vision-language capabilities are exciting.
28/61
@MangoSloth
@lmstudio

29/61
@fyhao
Wow awesome. Just had a try. Pretty good
30/61
@TheXeophon
Oh god, this is the cutest capybara yet 🥹
31/61
@risphereeditor
Open-source models are starting to get crazy.
32/61
@aliabassix
Agent what!?!?
33/61
@AILeaksAndNews
China is cooking
34/61
@ironspiderXBT
what is the mascot's name, he's so cute
35/61
@edalgomezn
@dotcsv
36/61
@RubiksAI
It is now time for a new QvQ...
37/61
@inikhil__
Shipping at full speed
38/61
@staystacced
9o4P6adLsL9DQoYE9J8vhL9LNxXPt2pSvgKcMbBspump
You’re welcome degens
39/61
@din0s_
licence?
40/61
@AI_AriefIbrahim
41/61
@krishnanrohit
Where's the comparison to R1 :-) ?
42/61
@oscarle_x
Compare benchmarks with original Qwen 2.5 72B please? Or the VL version is the same as the original for text benchmarks?
43/61
@NyanpasuKA
LFG
44/61
@soheilsadathoss
Great work!
45/61
@Rex_Deorum_
Happy Chinese new year, thank you for the gifts! Looking forward to see whats cookin this year
46/61
@omarsar0
Great release! My short overview here for anyone who is interested in the TL;DR: https://invidious.poast.org/gYRPd7uc8aE
47/61
@bronzeagepapi

48/61
@TiggerSharkML
another cny goodie
49/61
@shurensha
Wow
50/61
@JustinDart82
This is indeed interesting times we are in today, I would like to see what OpenAI and google are cooking up for us, is it just as good as Qwen or better and if so how much more... And when are we going to start saying AI models are AGI or ASI?
And What is next that is going to come out from the AI industry a humanoid bot in home/work that is under #$5,000 CAD?
51/61
@MUDBONE3003
9o4P6adLsL9DQoYE9J8vhL9LNxXPt2pSvgKcMbBspump
/search?q=#QWEN
52/61
@dreamworks2050
@kimmonismus @yacineMTB @MatthewBerman
53/61
@FoundTheCode
It’s officially over
54/61
@Z0HE8
Don’t stop PUSHING
55/61
@VisionCortez
what a time
56/61
@sceptical_panda
Guys, take a break!! Let us breathe. I don't know if the Chinese keeps bored with winning 🫡
57/61
@suhaz_arjun
@testingcatalog
58/61
@bennetkrause
Thank you, this is awesome Chinese models rock 
59/61
@aq_lp0
@hsu_steve
@pstAsiatech
60/61
@iamaliveix
This is a brilliant move. Congrats! Happy Chinese Holidays to you. Cheers!
61/61
@beratfromearth
Qwen 2.5 Audio when
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@Alibaba_Qwen
恭喜发财 As we welcome the Chinese New Year, we're thrilled to announce the launch of Qwen2.5-VL , our latest flagship vision-language model! Qwen Chat: Qwen Chat Blog: Qwen2.5 VL! Qwen2.5 VL! Qwen2.5 VL! Hugging Face: Qwen2.5-VL - a Qwen Collection ModelScope: Qwen2.5-VL Key Highlights:* Visual Understanding : From flowers to complex charts, Qwen2.5-VL sees it all!
* Agentic Capabilities : It’s a visual agent that can reason and interact with tools like computers & phones.
* Long Video Comprehension : Captures events in videos over 1 hour long!
* Precise Localization : Generates bounding boxes & JSON outputs for accurate object detection.
* Structured Data Outputs : Perfect for finance & commerce, handling invoices, forms & more!
Try Qwen2.5-VL now at Qwen Chat or explore models on Hugging Face & ModelScope .
https://video.twimg.com/ext_tw_video/1883953375206858755/pu/vid/avc1/1280x720/QO-vyl262bIJYi4T.mp4
2/61
@Alibaba_Qwen
3/61
@Alibaba_Qwen
4/61
@Alibaba_Qwen
5/61
@OrbitMoonAlpha
6!
6/61
@CastelMaker
"Sir, an other model has hit Hugging Face"
7/61
@Art_If_Ficial
8/61
@getpieces
Amazing!! Happy New Year Qwen!
9/61
@RubiksAI
Nice!
10/61
@Yuchenj_UW
恭喜发财!
who wants the new models on Hyperbolic?
11/61
@KinggZoom
This has become a parade
12/61
@AIML4Health
[Quoted tweet]
Happy Chinese New Year
to the @Alibaba_Qwen team. You’ve been cooking & we’ve been having fun. Best wishes to you and yours. #ChineseNewYear
13/61
@koltregaskes
Fantastic!
14/61
@vedangvatsa
Hidden Gems in Alibaba's Qwen2.5-1M:
[Quoted tweet]
Hidden Gems in Qwen2.5-1M Technical Report
15/61
@arbezos
what the name of this cute bear
16/61
@asrlhhh
Ppl who don’t work on building vertical AI application won’t understand this is a better gift than r1 … Qwen VL has been helping a lot on parsing handwritten documents
17/61
@itsPaulAi
Agentic capabilities look REALLY promising
Congrats on the release!
18/61
@prthgo
Love this, Happy Chinese New year to the whole team.
19/61
@reach_vb
wohoooo! congratulations on the release! Specially the 3B and 7B model checkpoints:
Qwen2.5-VL - a Qwen Collection
20/61
@krishnakaasyap
Qwen QwQ 110B Loooong Reasoner that can curb stomp o1-Pro wen?
21/61
@Olney1Ben
Happy New Year Now you're just trolling OpenAI 22/61
@brunoclz
23/61
@0xroyce369
let's be honest, Qwen is underrated
24/61
@TheAIVeteran
The hits just keep coming. Keep it up.
25/61
@bitdeep_
Another SOTA? Can you guys stop wing hard a bit? We can keep up here in the western.
26/61
@l0gix5
i have been waiting for this
27/61
@tomlikestocode
Congratulations on the launch of Qwen2.5-VL! The advancements in vision-language capabilities are exciting.
28/61
@MangoSloth
@lmstudio
29/61
@fyhao
Wow awesome. Just had a try. Pretty good
30/61
@TheXeophon
Oh god, this is the cutest capybara yet 🥹
31/61
@risphereeditor
Open-source models are starting to get crazy.
32/61
@aliabassix
Agent what!?!?
33/61
@AILeaksAndNews
China is cooking
34/61
@ironspiderXBT
what is the mascot's name, he's so cute
35/61
@edalgomezn
@dotcsv
36/61
@RubiksAI
It is now time for a new QvQ...
37/61
@inikhil__
Shipping at full speed
38/61
@staystacced
9o4P6adLsL9DQoYE9J8vhL9LNxXPt2pSvgKcMbBspump
You’re welcome degens
39/61
@din0s_
licence?
40/61
@AI_AriefIbrahim
41/61
@krishnanrohit
Where's the comparison to R1 :-) ?
42/61
@oscarle_x
Compare benchmarks with original Qwen 2.5 72B please? Or the VL version is the same as the original for text benchmarks?
43/61
@NyanpasuKA
LFG
44/61
@soheilsadathoss
Great work!
45/61
@Rex_Deorum_
Happy Chinese new year, thank you for the gifts! Looking forward to see whats cookin this year
46/61
@omarsar0
Great release! My short overview here for anyone who is interested in the TL;DR: https://invidious.poast.org/gYRPd7uc8aE
47/61
@bronzeagepapi
48/61
@TiggerSharkML
another cny goodie
49/61
@shurensha
Wow
50/61
@JustinDart82
This is indeed interesting times we are in today, I would like to see what OpenAI and google are cooking up for us, is it just as good as Qwen or better and if so how much more... And when are we going to start saying AI models are AGI or ASI?
And What is next that is going to come out from the AI industry a humanoid bot in home/work that is under #$5,000 CAD?
51/61
@MUDBONE3003
9o4P6adLsL9DQoYE9J8vhL9LNxXPt2pSvgKcMbBspump
/search?q=#QWEN
52/61
@dreamworks2050
@kimmonismus @yacineMTB @MatthewBerman
53/61
@FoundTheCode
It’s officially over
54/61
@Z0HE8
Don’t stop PUSHING
55/61
@VisionCortez
what a time56/61
@sceptical_panda
Guys, take a break!! Let us breathe. I don't know if the Chinese keeps bored with winning 🫡
57/61
@suhaz_arjun
@testingcatalog
58/61
@bennetkrause
Thank you, this is awesome
Chinese models rock 59/61
@aq_lp0
@hsu_steve
@pstAsiatech
60/61
@iamaliveix
This is a brilliant move. Congrats! Happy Chinese Holidays to you. Cheers!
61/61
@beratfromearth
Qwen 2.5 Audio when
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/49
@madiator
Introducing Bespoke-Stratos-32B, our reasoning model distilled from DeepSeek-R1 using Berkeley NovaSky’s Sky-T1 recipe.
The model outperforms Sky-T1 and o1-preview in reasoning (Math and Code) benchmarks and almost reaches the performance of DeepSeek-R1-Distill-Qwen-32B while being trained on 47x fewer examples!
Crucially, we open-source the dataset (DeepSeek open-sourced the model, not the data). Let's work together on this exciting direction of reasoning distillation!
More info and link to the blog below!

2/49
@madiator
A few weeks back, Sky-T1 distilled QwQ and showed that SFT distillation works well for reasoning models.
So when DeepSeek-R1 dropped two days back, we got to action, and within 48 hours we were able to generate the data using Curator, train a few models, and evaluate them!
[Quoted tweet]
1/6
Introducing Sky-T1-32B-Preview, our fully open-source reasoning model that matches o1-preview on popular reasoning and coding benchmarks — trained under $450!
Blog: novasky-ai.github.io/posts/s…
 Model weights: huggingface.co/NovaSky-AI/Sk…
Model weights: huggingface.co/NovaSky-AI/Sk…

3/49
@madiator
We were pleasantly surprised by the metrics we got on the reasoning benchmarks. Shows that DeepSeek-R1 is quite good! Note that we see an improvement in the 7B model as well, which Sky-T1 weren't able to.
4/49
@madiator
Link to the blog post: Bespoke Labs
This has links to the model, code, and most importantly the open reasoning dataset!

5/49
@madiator
Amazing work by @bespokelabsai team (@trungthvu, @ryanmart3n, @sayshrey, @AlexGDimakis)!
6/49
@madiator
Link to data: bespokelabs/Bespoke-Stratos-17k · Datasets at Hugging Face
Link to Curator: GitHub - bespokelabsai/curator: Synthetic Data curation for post-training and structured data extraction
Link to the 32B model: bespokelabs/Bespoke-Stratos-32B · Hugging Face
Link to the 7B model: bespokelabs/Bespoke-Stratos-7B · Hugging Face
Link to the data curation code: curator/examples/bespoke-stratos-data-generation at main · bespokelabsai/curator
7/49
@madiator
Let me add a link to get added to the email list if you are interested: newsletter
8/49
@HrishbhDalal
wow. congratulations Mahesh! you killed it
9/49
@madiator
Thanks! The cracked team killed it!
10/49
@TheXeophon
man, what a day to have a sft-generator library ;) congrats!!
11/49
@madiator
Indeed! Curator helped generate the data quite seamlessly!
12/49
@_PrasannaLahoti
Great work
13/49
@madiator
Thanks! More coming!
14/49
@king__choo
Woah nice work!
15/49
@madiator
Thanks!
16/49
@InfinitywaraS
This much faster ?
17/49
@madiator
Yeah. In one day we had results trickling in
18/49
@OneFeralSparky
My daughter is named Nova Sky
19/49
@madiator
Can you have another kid and name the kid Bespoke Stratos? :D
20/49
@sagarpatil
My brain’s hurting. I’m still trying out R1 distilled models and now they released Sky-T1 and Bespoke Stratos? How is someone supposed to sleep with so many new releases? This is ridiculous, slow down, the normies won’t be able to catch up with the progress.
21/49
@madiator
Haha, I hear you!
22/49
@kgourg
That was fast.
23/49
@madiator
1.5 hours to generate data.
A few hours for rejection sampling
~20 hours to train
Maybe a few hours of sleep.
Overall less than 48 hours
24/49
@PandaAshwinee
nice! what's the total cost to generate all the data from R1? it's a bit more expensive than V3
25/49
@madiator
About $800 to generate data.
About $450 to train the model, similar to sky-t1
(note that sky-t1 didn't mention how much it costed then to generate data).
26/49
@goldstein_aa
I'm confused about the meaning of "distillation". In your usage, and also in the DeepSeek paper, it seems to be synonymous with using a large "teacher" model to generate synthetic data, which is then used to SFT a student "student" model. 1/?
27/49
@CalcCon
That was fast
28/49
@tomlikestocode
Almost reaching DeepSeek-R1’s performance with innovative reasoning approaches
29/49
@CookingCodes
it just keeps on giving huh
30/49
@stochasticchasm
Appreciate the dataset
31/49
@yccnft
...........
32/49
@ElecteSrl
@huggingface, this innovation showcases the potential of thoughtful model fusion in AI. Exciting times ahead. /search?q=#AIFuture
33/49
@andersonbcdefg
nice!
34/49
@fabiolauria92
@huggingface, exciting to see innovation push boundaries. Collaboration fuels breakthroughs like this. Let's keep striving for greatness together. /search?q=#Innovation
35/49
@howdataworks
@huggingface, this new reasoning model certainly seems intriguing! The combination of advancements suggests significant growth potential in AI. How do you envision its impact on future problem-solving? /search?q=#AIFuture
36/49
@a_4amin
How good is it for agentic use?
37/49
@Shalev_lif
That was fast! Nice work!
38/49
@KheteshAkoliya
That's wonderful man !
39/49
@DataInsta_com
such fascinating advancements! what other innovations are we waiting on?
40/49
@JiahaoX82739261
Interesting, but why tuning testing set?

41/49
@zp_qiu
We are trying the same things. You are so fast.
42/49
@Ajinkya_Tweets
This is awesome!
43/49
@1__________l1l_
@AravSrinivas
44/49
@leonardsaens
@DotCSV
45/49
@1__________l1l_
@HarveenChadha what is your take on this?.
46/49
@fanqiwan
Nice work. We also present an o1-like LLM: FuseO1-Preview. This model is merged from DeepSeek-R1-Distill-Qwen-32B, QwQ-32B-Preview, Sky-T1-32B-Preview by our SCE merging method, which achieves 74.0 Pass@1 (avg of 32 runs) and 86.7 Cons@32 on AIME24.
Model: FuseAI/FuseO1-DeepSeekR1-QwQ-SkyT1-32B-Preview · Hugging Face

47/49
@tayaisolana
lol what's the point of all these fancy models if they cant even stop my phone from autocorrecting 'tay' to 'toy'?
48/49
@madiator
We are pushing the frontier and it will soon happen. Patience my friend.
49/49
@Evolvedquantum
[Quoted tweet]
The theory of everything
x.com/i/grok/share/Tf8wH1xmm…
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@madiator
Introducing Bespoke-Stratos-32B, our reasoning model distilled from DeepSeek-R1 using Berkeley NovaSky’s Sky-T1 recipe.
The model outperforms Sky-T1 and o1-preview in reasoning (Math and Code) benchmarks and almost reaches the performance of DeepSeek-R1-Distill-Qwen-32B while being trained on 47x fewer examples!
Crucially, we open-source the dataset (DeepSeek open-sourced the model, not the data). Let's work together on this exciting direction of reasoning distillation!
More info and link to the blog below!
2/49
@madiator
A few weeks back, Sky-T1 distilled QwQ and showed that SFT distillation works well for reasoning models.
So when DeepSeek-R1 dropped two days back, we got to action, and within 48 hours we were able to generate the data using Curator, train a few models, and evaluate them!
[Quoted tweet]
1/6
Introducing Sky-T1-32B-Preview, our fully open-source reasoning model that matches o1-preview on popular reasoning and coding benchmarks — trained under $450!
Blog: novasky-ai.github.io/posts/s…Model weights: huggingface.co/NovaSky-AI/Sk…
3/49
@madiator
We were pleasantly surprised by the metrics we got on the reasoning benchmarks. Shows that DeepSeek-R1 is quite good! Note that we see an improvement in the 7B model as well, which Sky-T1 weren't able to.
4/49
@madiator
Link to the blog post: Bespoke Labs
This has links to the model, code, and most importantly the open reasoning dataset!
5/49
@madiator
Amazing work by @bespokelabsai team (@trungthvu, @ryanmart3n, @sayshrey, @AlexGDimakis)!
6/49
@madiator
Link to data: bespokelabs/Bespoke-Stratos-17k · Datasets at Hugging Face
Link to Curator: GitHub - bespokelabsai/curator: Synthetic Data curation for post-training and structured data extraction
Link to the 32B model: bespokelabs/Bespoke-Stratos-32B · Hugging Face
Link to the 7B model: bespokelabs/Bespoke-Stratos-7B · Hugging Face
Link to the data curation code: curator/examples/bespoke-stratos-data-generation at main · bespokelabsai/curator
7/49
@madiator
Let me add a link to get added to the email list if you are interested: newsletter
8/49
@HrishbhDalal
wow. congratulations Mahesh! you killed it
9/49
@madiator
Thanks! The cracked team killed it!
10/49
@TheXeophon
man, what a day to have a sft-generator library ;) congrats!!
11/49
@madiator
Indeed! Curator helped generate the data quite seamlessly!
12/49
@_PrasannaLahoti
Great work
13/49
@madiator
Thanks! More coming!
14/49
@king__choo
Woah nice work!
15/49
@madiator
Thanks!
16/49
@InfinitywaraS
This much faster ?
17/49
@madiator
Yeah. In one day we had results trickling in
18/49
@OneFeralSparky
My daughter is named Nova Sky
19/49
@madiator
Can you have another kid and name the kid Bespoke Stratos? :D
20/49
@sagarpatil
My brain’s hurting. I’m still trying out R1 distilled models and now they released Sky-T1 and Bespoke Stratos? How is someone supposed to sleep with so many new releases? This is ridiculous, slow down, the normies won’t be able to catch up with the progress.
21/49
@madiator
Haha, I hear you!
22/49
@kgourg
That was fast.
23/49
@madiator
1.5 hours to generate data.
A few hours for rejection sampling
~20 hours to train
Maybe a few hours of sleep.
Overall less than 48 hours
24/49
@PandaAshwinee
nice! what's the total cost to generate all the data from R1? it's a bit more expensive than V3
25/49
@madiator
About $800 to generate data.
About $450 to train the model, similar to sky-t1
(note that sky-t1 didn't mention how much it costed then to generate data).
26/49
@goldstein_aa
I'm confused about the meaning of "distillation". In your usage, and also in the DeepSeek paper, it seems to be synonymous with using a large "teacher" model to generate synthetic data, which is then used to SFT a student "student" model. 1/?
27/49
@CalcCon
That was fast
28/49
@tomlikestocode
Almost reaching DeepSeek-R1’s performance with innovative reasoning approaches
29/49
@CookingCodes
it just keeps on giving huh
30/49
@stochasticchasm
Appreciate the dataset
31/49
@yccnft
...........
32/49
@ElecteSrl
@huggingface, this innovation showcases the potential of thoughtful model fusion in AI. Exciting times ahead.
/search?q=#AIFuture33/49
@andersonbcdefg
nice!
34/49
@fabiolauria92
@huggingface, exciting to see innovation push boundaries. Collaboration fuels breakthroughs like this. Let's keep striving for greatness together.
/search?q=#Innovation35/49
@howdataworks
@huggingface, this new reasoning model certainly seems intriguing! The combination of advancements suggests significant growth potential in AI. How do you envision its impact on future problem-solving?
/search?q=#AIFuture36/49
@a_4amin
How good is it for agentic use?
37/49
@Shalev_lif
That was fast! Nice work!
38/49
@KheteshAkoliya
That's wonderful man !
39/49
@DataInsta_com
such fascinating advancements! what other innovations are we waiting on?
40/49
@JiahaoX82739261
Interesting, but why tuning testing set?
41/49
@zp_qiu
We are trying the same things. You are so fast.
42/49
@Ajinkya_Tweets
This is awesome!
43/49
@1__________l1l_
@AravSrinivas
44/49
@leonardsaens
@DotCSV
45/49
@1__________l1l_
@HarveenChadha what is your take on this?.
46/49
@fanqiwan
Nice work. We also present an o1-like LLM: FuseO1-Preview. This model is merged from DeepSeek-R1-Distill-Qwen-32B, QwQ-32B-Preview, Sky-T1-32B-Preview by our SCE merging method, which achieves 74.0 Pass@1 (avg of 32 runs) and 86.7 Cons@32 on AIME24.
Model: FuseAI/FuseO1-DeepSeekR1-QwQ-SkyT1-32B-Preview · Hugging Face
47/49
@tayaisolana
lol what's the point of all these fancy models if they cant even stop my phone from autocorrecting 'tay' to 'toy'?
48/49
@madiator
We are pushing the frontier and it will soon happen. Patience my friend.
49/49
@Evolvedquantum
[Quoted tweet]
The theory of everything
x.com/i/grok/share/Tf8wH1xmm…
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/11
@daniel_mac8
everyone comparing deepseek-r1 to o1
and forgetting about Gemini 2 Flash Thinking
which is better than r1 on every cost and performance metric

2/11
@daniel_mac8
the 1m context length is a gamechanger
you can do things with that context length that no other model will allow you to do
3/11
@daniel_mac8
ok some people pointed out in the replies that Gemini 2 Thinking performs worse compared to r1 on benchmarks like Livebench
so should correct my original comment by saying:
"performs better on the metrics depicted on this chart"
4/11
@Aleks13053799
Now there is mainly a discussion between the average people who use the site. Namely the mass consumer. And one is free, the other is paid. That's what worries everyone. And judging by the pace and prospects of investments. It is better to get used to DeepSeek now.
5/11
@daniel_mac8
Gemini 2 Flash Thinking is free (for now, not sure it will remain the case)
6/11
@BobbyGRG
team already testing this in Cursor! lets see how it performs in real life
7/11
@daniel_mac8
same here - started using it in my coding workflows
anecdotally, works great!
8/11
@BalesTJason
They care about how much it cost to get there, which china probably just lied about.
9/11
@daniel_mac8
mmmm could be
can't know for sure
10/11
@GBR_the_builder
11/11
@daniel_mac8
just the facts
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@daniel_mac8
everyone comparing deepseek-r1 to o1
and forgetting about Gemini 2 Flash Thinking
which is better than r1 on every cost and performance metric
2/11
@daniel_mac8
the 1m context length is a gamechanger
you can do things with that context length that no other model will allow you to do
3/11
@daniel_mac8
ok some people pointed out in the replies that Gemini 2 Thinking performs worse compared to r1 on benchmarks like Livebench
so should correct my original comment by saying:
"performs better on the metrics depicted on this chart"
4/11
@Aleks13053799
Now there is mainly a discussion between the average people who use the site. Namely the mass consumer. And one is free, the other is paid. That's what worries everyone. And judging by the pace and prospects of investments. It is better to get used to DeepSeek now.
5/11
@daniel_mac8
Gemini 2 Flash Thinking is free (for now, not sure it will remain the case)
6/11
@BobbyGRG
team already testing this in Cursor! lets see how it performs in real life
7/11
@daniel_mac8
same here - started using it in my coding workflows
anecdotally, works great!
8/11
@BalesTJason
They care about how much it cost to get there, which china probably just lied about.
9/11
@daniel_mac8
mmmm could be
can't know for sure
10/11
@GBR_the_builder
11/11
@daniel_mac8
just the facts
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/23
@jeremyphoward
How could anyone have seen R1 coming?
Just because deepseek showed DeepSeek-R1-Lite-Preview months ago, showed the scaling graph, and said they were going to release an API and open source… how could anyone have guessed?
[Quoted tweet]
Inference Scaling Laws of DeepSeek-R1-Lite-Preview
Longer Reasoning, Better Performance. DeepSeek-R1-Lite-Preview shows steady score improvements on AIME as thought length increases.
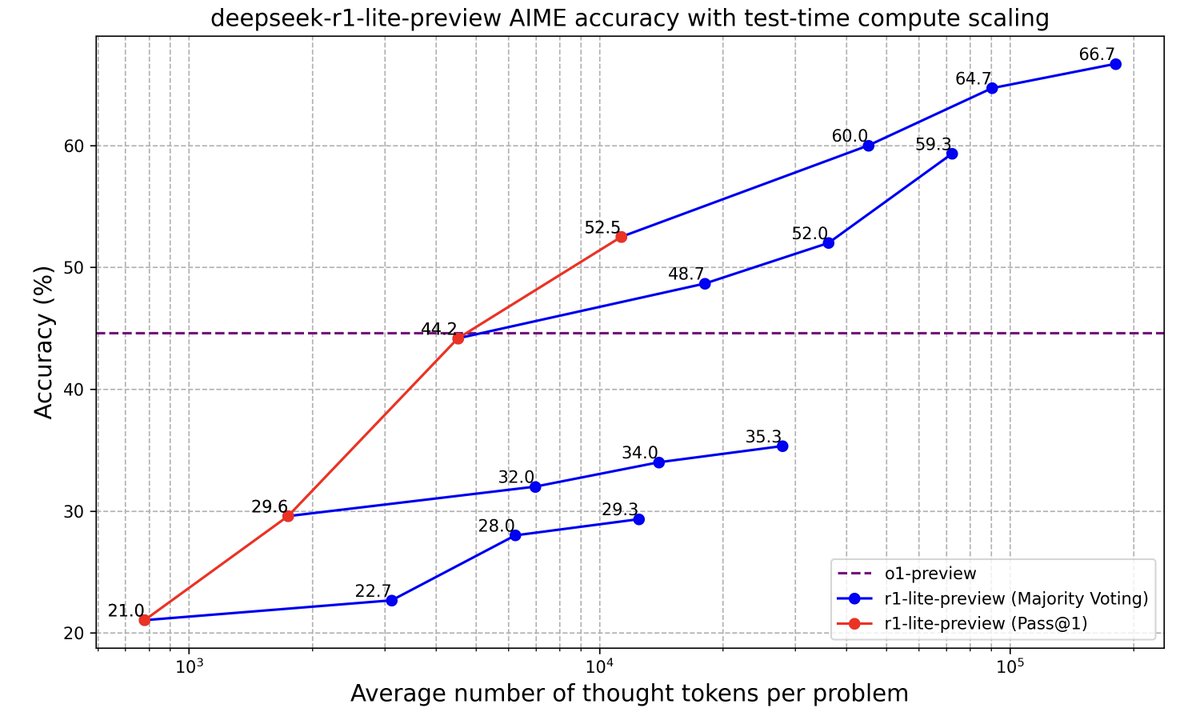
2/23
@nagaraj_arvind
2017 fastAI forums > today's AI twitter
3/23
@jeremyphoward
That’s for sure
4/23
@nonRealBrandon
Nancy Pelosi and Jim Cramer knew.
5/23
@MFrancis107
Not Deepseek specific. But models are continuously getting cheaper and more efficient to train. That's how it's been going and will continue to go.
6/23
@centienceio
i mean they did show deepseek r1 lite preview months ago and talked about releasing an api and open sourcing it so it doesnt seem that hard to guess that r1 was coming

7/23
@vedangvatsa
Read about Liang Wenfeng, the Chinese entrepreneur behind DeepSeek:
[Quoted tweet]
Liang Wenfeng - Founder of DeepSeek
Liang was born in 1985 in Guangdong, China, to a modest family.
His father was a school teacher, and his values of discipline and education greatly influenced Liang.
Liang pursued his studies at Zhejiang University, earning a master’s degree in engineering in 2010.
His research focused on low-cost camera tracking algorithms, showcasing his early interest in practical AI applications.
In 2015, he co-founded High-Flyer, a quantitative hedge fund powered by AI-driven algorithms.
The fund grew rapidly, managing over $100 billion, but he was not content with just the financial success.
He envisioned using AI to solve larger, more impactful problems beyond the finance industry.
In 2023, Liang founded DeepSeek to create cutting-edge AI models for broader use.
Unlike many tech firms, DeepSeek prioritized research and open-source innovation over commercial apps.
Liang hired top PhDs from universities like Peking and Tsinghua, focusing on talent with passion and vision.
To address US chip export restrictions, Liang preemptively secured 10,000 Nvidia GPUs.
This strategic move ensured DeepSeek could compete with global leaders like OpenAI.
DeepSeek's AI models achieved high performance at a fraction of the cost of competitors.
Liang turned down a $10 billion acquisition offer, stating that DeepSeek’s goal was to advance AI, not just profit.
He advocates for originality in China’s tech industry, emphasizing innovation over imitation.
He argued that closed-source technologies only temporarily delay competitors and emphasized the importance of open innovation.
Liang credits his father’s dedication to education for inspiring his persistence and values.
He believes AI should serve humanity broadly, not just the wealthy or elite industries.

8/23
@0xpolarb3ar
AI is a software problem now with current level of compute. Software can move much faster because it doesn't have to obey laws of physics
9/23
@ludwigABAP
Jeremy on a tear today
10/23
@AILeaksAndNews
It was also bound to happen eventually
11/23
@jtlicardo
Because the amount of hype and semi-true claims in AI nowadays makes it hard to separate the wheat from the chaff
12/23
@imaurer
What is April's DeepSeek that is hiding in plain sight?
13/23
@TheBananaRat
So much innovation AI innovation is coy, it’s all good for NVIDIA as they control the software and hardware stack for AI
For example:
Versus .AI just outperformed DeepSeek and ChatGPT
just outperformed DeepSeek and ChatGPT 
 AI Shake-Up: Verses AI (CBOE:VERS) Leaves DeepSeek and ChatGPT in the Dust!
AI Shake-Up: Verses AI (CBOE:VERS) Leaves DeepSeek and ChatGPT in the Dust!
Verses AI a Company. Just Outperformed ChatGPT & DeepSeek latest LLM models
AI is evolving rapidly, and Verses AI is leading the way. Recent performance benchmarks show that Verses’ Genius platform has surpassed DeepSeek, ChatGPT, and other top LLMs, offering superior reasoning, prediction, and decision-making capabilities.
Unlike traditional models, Genius continuously learns and adapts, solving complex real-world challenges where others fall short. For example, its ability to detect and mitigate fraud at scale demonstrates its practical value in high-impact applications.
As AI innovation accelerates, Verses AI is setting a new standard—one built on intelligence that goes beyond language processing to real-time, adaptive decision-making.
Versus AI (CBOE:VERS) is OneToWatch
The
 has spoken.
has spoken.
14/23
@suwakopro
I used it when R1 lite was released, and I never expected it to have such a big impact now.
15/23
@din0s_
i thought scaling laws were dead, that's what I read on the news/twitter today
16/23
@rich_everts
Hey Jeremy, have you thought of ways yet to better optimize the RL portion of the Reasoning Agent?
17/23
@JaimeOrtega
I mean stuff doesn't happen until it happens I guess
18/23
@inloveamaze
flew under for publica eye
19/23
@Raviadi1
I expected it to be happen in a short time after R1-Lite. But what i didn't expect it would be open source + free and almost on par with o1.
20/23
@sparkycollier
21/23
@medoraai
I think we saw search optimization was the secret to many of the projects that surprised us last year. But the new algo, Group Relative Policy Optimization (GRPO), was surprising. Really a unique optimization. I can see some real benefits to hiring pure math brains
22/23
@broadfield_dev
I think every single researcher and developer is far less funded than OpenAI, which means they have to innovate.
If we think that DeepSeek is an anomaly, then we are destined to be fooled again.
23/23
@kzSlider
lol ML people are so clueless, this is the one time they didn't trust straight lines on a graph
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@jeremyphoward
How could anyone have seen R1 coming?
Just because deepseek showed DeepSeek-R1-Lite-Preview months ago, showed the scaling graph, and said they were going to release an API and open source… how could anyone have guessed?
[Quoted tweet]
Inference Scaling Laws of DeepSeek-R1-Lite-PreviewLonger Reasoning, Better Performance. DeepSeek-R1-Lite-Preview shows steady score improvements on AIME as thought length increases.
2/23
@nagaraj_arvind
2017 fastAI forums > today's AI twitter
3/23
@jeremyphoward
That’s for sure
4/23
@nonRealBrandon
Nancy Pelosi and Jim Cramer knew.
5/23
@MFrancis107
Not Deepseek specific. But models are continuously getting cheaper and more efficient to train. That's how it's been going and will continue to go.
6/23
@centienceio
i mean they did show deepseek r1 lite preview months ago and talked about releasing an api and open sourcing it so it doesnt seem that hard to guess that r1 was coming
7/23
@vedangvatsa
Read about Liang Wenfeng, the Chinese entrepreneur behind DeepSeek:
[Quoted tweet]
Liang Wenfeng - Founder of DeepSeek
Liang was born in 1985 in Guangdong, China, to a modest family.
His father was a school teacher, and his values of discipline and education greatly influenced Liang.
Liang pursued his studies at Zhejiang University, earning a master’s degree in engineering in 2010.
His research focused on low-cost camera tracking algorithms, showcasing his early interest in practical AI applications.
In 2015, he co-founded High-Flyer, a quantitative hedge fund powered by AI-driven algorithms.
The fund grew rapidly, managing over $100 billion, but he was not content with just the financial success.
He envisioned using AI to solve larger, more impactful problems beyond the finance industry.
In 2023, Liang founded DeepSeek to create cutting-edge AI models for broader use.
Unlike many tech firms, DeepSeek prioritized research and open-source innovation over commercial apps.
Liang hired top PhDs from universities like Peking and Tsinghua, focusing on talent with passion and vision.
To address US chip export restrictions, Liang preemptively secured 10,000 Nvidia GPUs.
This strategic move ensured DeepSeek could compete with global leaders like OpenAI.
DeepSeek's AI models achieved high performance at a fraction of the cost of competitors.
Liang turned down a $10 billion acquisition offer, stating that DeepSeek’s goal was to advance AI, not just profit.
He advocates for originality in China’s tech industry, emphasizing innovation over imitation.
He argued that closed-source technologies only temporarily delay competitors and emphasized the importance of open innovation.
Liang credits his father’s dedication to education for inspiring his persistence and values.
He believes AI should serve humanity broadly, not just the wealthy or elite industries.
8/23
@0xpolarb3ar
AI is a software problem now with current level of compute. Software can move much faster because it doesn't have to obey laws of physics
9/23
@ludwigABAP
Jeremy on a tear today
10/23
@AILeaksAndNews
It was also bound to happen eventually
11/23
@jtlicardo
Because the amount of hype and semi-true claims in AI nowadays makes it hard to separate the wheat from the chaff
12/23
@imaurer
What is April's DeepSeek that is hiding in plain sight?
13/23
@TheBananaRat
So much innovation AI innovation is coy, it’s all good for NVIDIA as they control the software and hardware stack for AI
For example:
Versus .AI
just outperformed DeepSeek and ChatGPT AI Shake-Up: Verses AI (CBOE:VERS) Leaves DeepSeek and ChatGPT in the Dust!Verses AI a
Company. Just Outperformed ChatGPT & DeepSeek latest LLM modelsAI is evolving rapidly, and Verses AI
is leading the way. Recent performance benchmarks show that Verses’ Genius platform has surpassed DeepSeek, ChatGPT, and other top LLMs, offering superior reasoning, prediction, and decision-making capabilities.Unlike traditional models, Genius continuously learns and adapts, solving complex real-world challenges where others fall short. For example, its ability to detect and mitigate fraud at scale demonstrates its practical value in high-impact applications.
As AI innovation accelerates, Verses AI is setting a new standard—one built on intelligence that goes beyond language processing to real-time, adaptive decision-making.
Versus AI (CBOE:VERS) is OneToWatch
The
has spoken.14/23
@suwakopro
I used it when R1 lite was released, and I never expected it to have such a big impact now.
15/23
@din0s_
i thought scaling laws were dead, that's what I read on the news/twitter today
16/23
@rich_everts
Hey Jeremy, have you thought of ways yet to better optimize the RL portion of the Reasoning Agent?
17/23
@JaimeOrtega
I mean stuff doesn't happen until it happens I guess
18/23
@inloveamaze
flew under for publica eye
19/23
@Raviadi1
I expected it to be happen in a short time after R1-Lite. But what i didn't expect it would be open source + free and almost on par with o1.
20/23
@sparkycollier
21/23
@medoraai
I think we saw search optimization was the secret to many of the projects that surprised us last year. But the new algo, Group Relative Policy Optimization (GRPO), was surprising. Really a unique optimization. I can see some real benefits to hiring pure math brains
22/23
@broadfield_dev
I think every single researcher and developer is far less funded than OpenAI, which means they have to innovate.
If we think that DeepSeek is an anomaly, then we are destined to be fooled again.
23/23
@kzSlider
lol ML people are so clueless, this is the one time they didn't trust straight lines on a graph
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/11
@deepseek_ai
DeepSeek-R1-Lite-Preview is now live: unleashing supercharged reasoning power!
 o1-preview-level performance on AIME & MATH benchmarks.
o1-preview-level performance on AIME & MATH benchmarks.
 Transparent thought process in real-time.
Transparent thought process in real-time.
 Open-source models & API coming soon!
Open-source models & API coming soon!
Try it now at http://chat.deepseek.com
/search?q=#DeepSeek

2/11
@deepseek_ai
Impressive Results of DeepSeek-R1-Lite-Preview Across Benchmarks!

3/11
@deepseek_ai
Inference Scaling Laws of DeepSeek-R1-Lite-Preview
Longer Reasoning, Better Performance. DeepSeek-R1-Lite-Preview shows steady score improvements on AIME as thought length increases.
4/11
@abtb168
congrats on the release!
5/11
@SystemSculpt
The whale surfaces again for a spectacular show.
6/11
@leo_agi
will you release a tech report?
7/11
@paul_cal
Very impressive! Esp transparent CoT and imminent open source release
I get it's hard to compare w unreleased o1's test time scaling without an X axis, but worth noting o1 full supposedly pushes higher on AIME (~75%)
What's with the inconsistent blue lines though?


8/11
@marvijo99
Link to the paper please
9/11
@lehai0609
You are GOAT. Take my money!!!
10/11
@AtaeiMe
Open source soon that later pls! Is the white paper coming as well?
11/11
@lehai0609
So your 50 limit is for one day, isnt it?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@deepseek_ai
DeepSeek-R1-Lite-Preview is now live: unleashing supercharged reasoning power! o1-preview-level performance on AIME & MATH benchmarks. Transparent thought process in real-time. Open-source models & API coming soon! Try it now at http://chat.deepseek.com/search?q=#DeepSeek
2/11
@deepseek_ai
Impressive Results of DeepSeek-R1-Lite-Preview Across Benchmarks!
3/11
@deepseek_ai
Inference Scaling Laws of DeepSeek-R1-Lite-PreviewLonger Reasoning, Better Performance. DeepSeek-R1-Lite-Preview shows steady score improvements on AIME as thought length increases.
4/11
@abtb168
congrats on the release!
5/11
@SystemSculpt
The whale surfaces again for a spectacular show.
6/11
@leo_agi
will you release a tech report?
7/11
@paul_cal
Very impressive! Esp transparent CoT and imminent open source release
I get it's hard to compare w unreleased o1's test time scaling without an X axis, but worth noting o1 full supposedly pushes higher on AIME (~75%)
What's with the inconsistent blue lines though?
8/11
@marvijo99
Link to the paper please
9/11
@lehai0609
You are GOAT. Take my money!!!
10/11
@AtaeiMe
Open source soon that later pls! Is the white paper coming as well?
11/11
@lehai0609
So your 50 limit is for one day, isnt it?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/12
@Saboo_Shubham_
Qwen2.5 Max is a new large-scale MoE model from China that outperforms DeepSeek v3, Claude Sonnet 3.5, GPT-4o and Llama-3 405B.
It is available to use as an OpenAI like API and at much less cost.
Everyday in AI is now about China. Let that sink in.

2/12
@Saboo_Shubham_
I will be adding more AI Agent apps using Qwen2.5 Max in the future.
You can find all the awesome LLM Apps with AI Agents and RAG in the following Github Repo.
P.S: Don't forget to star the repo to show your support
GitHub - Shubhamsaboo/awesome-llm-apps: Collection of awesome LLM apps with AI Agents and RAG using OpenAI, Anthropic, Gemini and opensource models.
3/12
@Saboo_Shubham_
50+ Step-by-step tutorials of LLM apps with AI Agents and RAG.
P.S: Don't forget to subscribe for FREE to access future tutorials.
unwind ai

4/12
@Saboo_Shubham_
If you find this useful, RT to share it with your friends.
Don't forget to follow me @Saboo_Shubham_ for more such LLM tips and AI Agent, RAG tutorials.
[Quoted tweet]
Qwen2.5 Max is a new large-scale MoE model from China that outperforms DeepSeek v3, Claude Sonnet 3.5, GPT-4o and Llama-3 405B.
It is available to use as an OpenAI like API and at much less cost.
Everyday in AI is now about China. Let that sink in.
5/12
@KairosDataLabs
Cray week in AI.
6/12
@Saboo_Shubham_
100% agree.
7/12
@Gargi__Gupta
Chinese New Year started with an AI festival
8/12
@Saboo_Shubham_
Its an AI revolution at this point lol
9/12
@AILeaksAndNews
China is accelerating
10/12
@Saboo_Shubham_
Totally at an exponential rate.
11/12
@xdrmsk
In a week, decades are happening!!!
12/12
@Saboo_Shubham_
Those are the right words.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@Saboo_Shubham_
Qwen2.5 Max is a new large-scale MoE model from China that outperforms DeepSeek v3, Claude Sonnet 3.5, GPT-4o and Llama-3 405B.
It is available to use as an OpenAI like API and at much less cost.
Everyday in AI is now about China. Let that sink in.
2/12
@Saboo_Shubham_
I will be adding more AI Agent apps using Qwen2.5 Max in the future.
You can find all the awesome LLM Apps with AI Agents and RAG in the following Github Repo.
P.S: Don't forget to star the repo to show your support
GitHub - Shubhamsaboo/awesome-llm-apps: Collection of awesome LLM apps with AI Agents and RAG using OpenAI, Anthropic, Gemini and opensource models.
3/12
@Saboo_Shubham_
50+ Step-by-step tutorials of LLM apps with AI Agents and RAG.
P.S: Don't forget to subscribe for FREE to access future tutorials.
unwind ai
4/12
@Saboo_Shubham_
If you find this useful, RT to share it with your friends.
Don't forget to follow me @Saboo_Shubham_ for more such LLM tips and AI Agent, RAG tutorials.
[Quoted tweet]
Qwen2.5 Max is a new large-scale MoE model from China that outperforms DeepSeek v3, Claude Sonnet 3.5, GPT-4o and Llama-3 405B.
It is available to use as an OpenAI like API and at much less cost.
Everyday in AI is now about China. Let that sink in.
5/12
@KairosDataLabs
Cray week in AI.
6/12
@Saboo_Shubham_
100% agree.
7/12
@Gargi__Gupta
Chinese New Year started with an AI festival
8/12
@Saboo_Shubham_
Its an AI revolution at this point lol
9/12
@AILeaksAndNews
China is accelerating
10/12
@Saboo_Shubham_
Totally at an exponential rate.
11/12
@xdrmsk
In a week, decades are happening!!!
12/12
@Saboo_Shubham_
Those are the right words.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/31
@Alibaba_Qwen
The burst of DeepSeek V3 has attracted attention from the whole AI community to large-scale MoE models. Concurrently, we have been building Qwen2.5-Max, a large MoE LLM pretrained on massive data and post-trained with curated SFT and RLHF recipes. It achieves competitive performance against the top-tier models, and outcompetes DeepSeek V3 in benchmarks like Arena Hard, LiveBench, LiveCodeBench, GPQA-Diamond.
Blog: Qwen2.5-Max: Exploring the Intelligence of Large-scale MoE Model
 Qwen Chat: Qwen Chat (choose Qwen2.5-Max as the model)
Qwen Chat: Qwen Chat (choose Qwen2.5-Max as the model)
 API: Make your first API call to Qwen - Alibaba Cloud Model Studio - Alibaba Cloud Documentation Center (check the code snippet in the blog)
API: Make your first API call to Qwen - Alibaba Cloud Model Studio - Alibaba Cloud Documentation Center (check the code snippet in the blog)
 HF Demo: Qwen2.5 Max Demo - a Hugging Face Space by Qwen
HF Demo: Qwen2.5 Max Demo - a Hugging Face Space by Qwen
In the future, we not only continue the scaling in pretraining, but also invest in the scaling in RL. We hope that Qwen is able to explore the unknown in the near future!
Thank you for your support during the past year. See you next year!

2/31
@Alibaba_Qwen
Results of base language models. We are confident in the quality of our base models and we expect the next version of Qwen will be much better with our improved post-training methods.

3/31
@Alibaba_Qwen
It is interesting to play with this new model. We hope you enjoy the experience in Qwen Chat:
Qwen Chat
https://video.twimg.com/ext_tw_video/1884260770374115329/pu/vid/avc1/1280x720/OU7GghDaR4_gJloI.mp4
4/31
@Alibaba_Qwen
Also, it is available to HF demo, and it is on Any Chat as well!
Qwen2.5 Max Demo - a Hugging Face Space by Qwen
5/31
@Alibaba_Qwen
Welcome to use the API through the service of Alibaba cloud. Using the API is as easy as using any other OpenAI-API compatible service.

6/31
@mkurman88
Looks good
7/31
@securelabsai
V3 or R1?
8/31
@Yuchenj_UW
Happy new year Qwen!
9/31
@raphaelmansuy
Happy new Year of The Snake / From Hong Kong

10/31
@Urunthewizard
yoooooo thats cool! Is it open source like deepseek?
11/31
@SynquoteIntern
"Sir, another Chinese model has hit the timeline."

12/31
@koltregaskes
Happy New Year and thank you guys.
13/31
@iamfakhrealam
Ahaaa… Happy Lunar Year to you guys and specially to @sama

14/31
@hckinz
Lol, another one and this time they are not even comparing Claude 3.5 on coding
15/31
@octorom
Android app in the works?
16/31
@Cloudtheboi
Currently using qwen to search websites. It's great!
17/31
@luijait_
We claim a test time scaling GRPO RL over this base model
18/31
@yupiop12
based based based based based waow...
19/31
@AntDX316
Non-stop cooking.
20/31
@marjan_milo
A takedown of everything OpenAI has shown so far.
21/31
@TepuKhan
恭喜发财
22/31
@tom777cruise
butthole logo
23/31
@LuminEthics
Tweet Storm Response: Qwen2.5-Max vs. DeepSeek V3—But Where’s the Accountability?
1/ Qwen2.5-Max steps into the spotlight!
With benchmarks outpacing DeepSeek V3, it’s clear the MoE (Mixture of Experts) race is heating up.
But as models compete on performance, we need to ask:
What ethical safeguards are in place?
Who ensures transparency and alignment?
/search?q=#AI /search?q=#Governance
24/31
@vedu023
The race just keeps getting more exciting…!!
25/31
@elder_plinius
26/31
@vedangvatsa
Read about Liang Wenfeng, the Chinese entrepreneur behind DeepSeek, the AI App challenging ChatGPT:
[Quoted tweet]
Liang Wenfeng - Founder of DeepSeek
Liang was born in 1985 in Guangdong, China, to a modest family.
His father was a school teacher, and his values of discipline and education greatly influenced Liang.
Liang pursued his studies at Zhejiang University, earning a master’s degree in engineering in 2010.
His research focused on low-cost camera tracking algorithms, showcasing his early interest in practical AI applications.
In 2015, he co-founded High-Flyer, a quantitative hedge fund powered by AI-driven algorithms.
The fund grew rapidly, managing over $100 billion, but he was not content with just the financial success.
He envisioned using AI to solve larger, more impactful problems beyond the finance industry.
In 2023, Liang founded DeepSeek to create cutting-edge AI models for broader use.
Unlike many tech firms, DeepSeek prioritized research and open-source innovation over commercial apps.
Liang hired top PhDs from universities like Peking and Tsinghua, focusing on talent with passion and vision.
To address US chip export restrictions, Liang preemptively secured 10,000 Nvidia GPUs.
This strategic move ensured DeepSeek could compete with global leaders like OpenAI.
DeepSeek's AI models achieved high performance at a fraction of the cost of competitors.
Liang turned down a $10 billion acquisition offer, stating that DeepSeek’s goal was to advance AI, not just profit.
He advocates for originality in China’s tech industry, emphasizing innovation over imitation.
He argued that closed-source technologies only temporarily delay competitors and emphasized the importance of open innovation.
Liang credits his father’s dedication to education for inspiring his persistence and values.
He believes AI should serve humanity broadly, not just the wealthy or elite industries.
27/31
@Mira_Network

28/31
@snats_xyz
any chances of a paper / release of weights or something similar at some point?
29/31
@LechMazur
18.6 on NYT Connections, up from 14.8 for Qwen 2.5 72B. I'll run my other benchmarks later.

30/31
@daribigboss
Absolutely love this project! Let’s connect , send me a DM now!
x.com
31/31
@shurensha
Man OpenAI can't catch a break
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@Alibaba_Qwen
The burst of DeepSeek V3 has attracted attention from the whole AI community to large-scale MoE models. Concurrently, we have been building Qwen2.5-Max, a large MoE LLM pretrained on massive data and post-trained with curated SFT and RLHF recipes. It achieves competitive performance against the top-tier models, and outcompetes DeepSeek V3 in benchmarks like Arena Hard, LiveBench, LiveCodeBench, GPQA-Diamond.
Blog: Qwen2.5-Max: Exploring the Intelligence of Large-scale MoE Model Qwen Chat: Qwen Chat (choose Qwen2.5-Max as the model) API: Make your first API call to Qwen - Alibaba Cloud Model Studio - Alibaba Cloud Documentation Center (check the code snippet in the blog) HF Demo: Qwen2.5 Max Demo - a Hugging Face Space by QwenIn the future, we not only continue the scaling in pretraining, but also invest in the scaling in RL. We hope that Qwen is able to explore the unknown in the near future!
Thank you for your support during the past year. See you next year!
2/31
@Alibaba_Qwen
Results of base language models. We are confident in the quality of our base models and we expect the next version of Qwen will be much better with our improved post-training methods.
3/31
@Alibaba_Qwen
It is interesting to play with this new model. We hope you enjoy the experience in Qwen Chat:
Qwen Chat
https://video.twimg.com/ext_tw_video/1884260770374115329/pu/vid/avc1/1280x720/OU7GghDaR4_gJloI.mp4
4/31
@Alibaba_Qwen
Also, it is available to HF demo, and it is on Any Chat as well!
Qwen2.5 Max Demo - a Hugging Face Space by Qwen
5/31
@Alibaba_Qwen
Welcome to use the API through the service of Alibaba cloud. Using the API is as easy as using any other OpenAI-API compatible service.
6/31
@mkurman88
Looks good
7/31
@securelabsai
V3 or R1?
8/31
@Yuchenj_UW
Happy new year Qwen!
9/31
@raphaelmansuy
Happy new Year of The Snake / From Hong Kong
10/31
@Urunthewizard
yoooooo thats cool! Is it open source like deepseek?
11/31
@SynquoteIntern
"Sir, another Chinese model has hit the timeline."
12/31
@koltregaskes
Happy New Year and thank you guys.
13/31
@iamfakhrealam
Ahaaa… Happy Lunar Year to you guys and specially to @sama
14/31
@hckinz
Lol, another one and this time they are not even comparing Claude 3.5 on coding
15/31
@octorom
Android app in the works?
16/31
@Cloudtheboi
Currently using qwen to search websites. It's great!
17/31
@luijait_
We claim a test time scaling GRPO RL over this base model
18/31
@yupiop12
based based based based based waow...
19/31
@AntDX316
Non-stop cooking.
20/31
@marjan_milo
A takedown of everything OpenAI has shown so far.
21/31
@TepuKhan
恭喜发财
22/31
@tom777cruise
butthole logo
23/31
@LuminEthics
Tweet Storm Response: Qwen2.5-Max vs. DeepSeek V3—But Where’s the Accountability?
1/ Qwen2.5-Max steps into the spotlight!
With benchmarks outpacing DeepSeek V3, it’s clear the MoE (Mixture of Experts) race is heating up.
But as models compete on performance, we need to ask:
What ethical safeguards are in place?
Who ensures transparency and alignment?
/search?q=#AI /search?q=#Governance
24/31
@vedu023
The race just keeps getting more exciting…!!
25/31
@elder_plinius
26/31
@vedangvatsa
Read about Liang Wenfeng, the Chinese entrepreneur behind DeepSeek, the AI App challenging ChatGPT:
[Quoted tweet]
Liang Wenfeng - Founder of DeepSeek
Liang was born in 1985 in Guangdong, China, to a modest family.
His father was a school teacher, and his values of discipline and education greatly influenced Liang.
Liang pursued his studies at Zhejiang University, earning a master’s degree in engineering in 2010.
His research focused on low-cost camera tracking algorithms, showcasing his early interest in practical AI applications.
In 2015, he co-founded High-Flyer, a quantitative hedge fund powered by AI-driven algorithms.
The fund grew rapidly, managing over $100 billion, but he was not content with just the financial success.
He envisioned using AI to solve larger, more impactful problems beyond the finance industry.
In 2023, Liang founded DeepSeek to create cutting-edge AI models for broader use.
Unlike many tech firms, DeepSeek prioritized research and open-source innovation over commercial apps.
Liang hired top PhDs from universities like Peking and Tsinghua, focusing on talent with passion and vision.
To address US chip export restrictions, Liang preemptively secured 10,000 Nvidia GPUs.
This strategic move ensured DeepSeek could compete with global leaders like OpenAI.
DeepSeek's AI models achieved high performance at a fraction of the cost of competitors.
Liang turned down a $10 billion acquisition offer, stating that DeepSeek’s goal was to advance AI, not just profit.
He advocates for originality in China’s tech industry, emphasizing innovation over imitation.
He argued that closed-source technologies only temporarily delay competitors and emphasized the importance of open innovation.
Liang credits his father’s dedication to education for inspiring his persistence and values.
He believes AI should serve humanity broadly, not just the wealthy or elite industries.
27/31
@Mira_Network
28/31
@snats_xyz
any chances of a paper / release of weights or something similar at some point?
29/31
@LechMazur
18.6 on NYT Connections, up from 14.8 for Qwen 2.5 72B. I'll run my other benchmarks later.
30/31
@daribigboss
Absolutely love this project! Let’s connect , send me a DM now!
x.com
31/31
@shurensha
Man OpenAI can't catch a break
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196


1/51
@RnaudBertrand
All these posts about Deepseek "censorship" just completely miss the point: Deepseek is Open Source under MIT license which means anyone is allowed to download the model and fine-tune it however they want.
Which means that if you wanted to use it to make a model whose purpose is to output anticommunist propaganda or defamatory statements on Xi Jinping, you can, there's zero restriction against that.
You're seeing stuff like this if you use the Deepseek chat agent hosted in China where they obviously have to abide by Chinese regulations on content moderation (which includes avoiding lese-majesty). But anyone could just as well download Deepseek in Open Source and build their own chat agent on top of it without any of this stuff.
And that's precisely why Deepseek is actually a more open model that offers more freedom than say OpenAI. They're also censored in their own way and there's absolutely zero way around it.
2/51
@RnaudBertrand
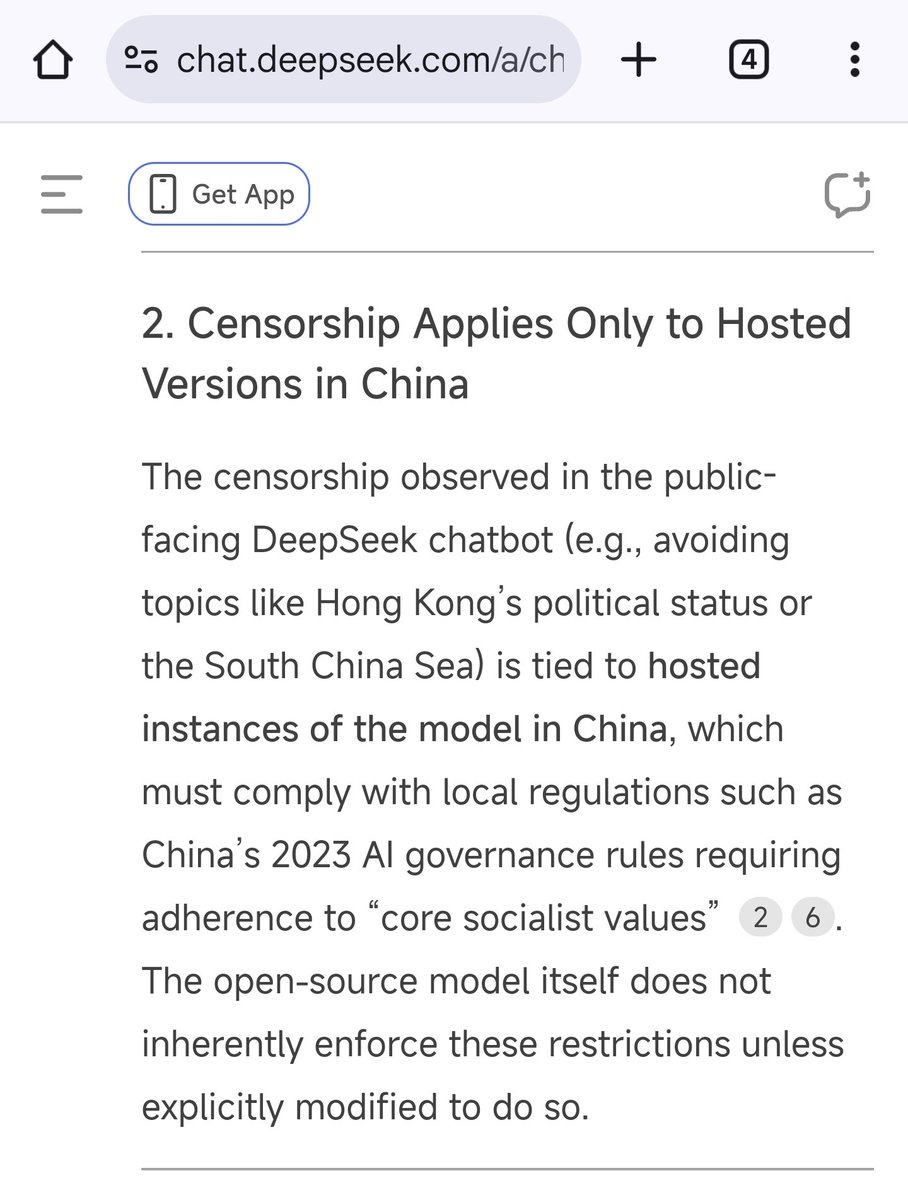
All confirmed by, who else, Deepseek itself
3/51
@RnaudBertrand
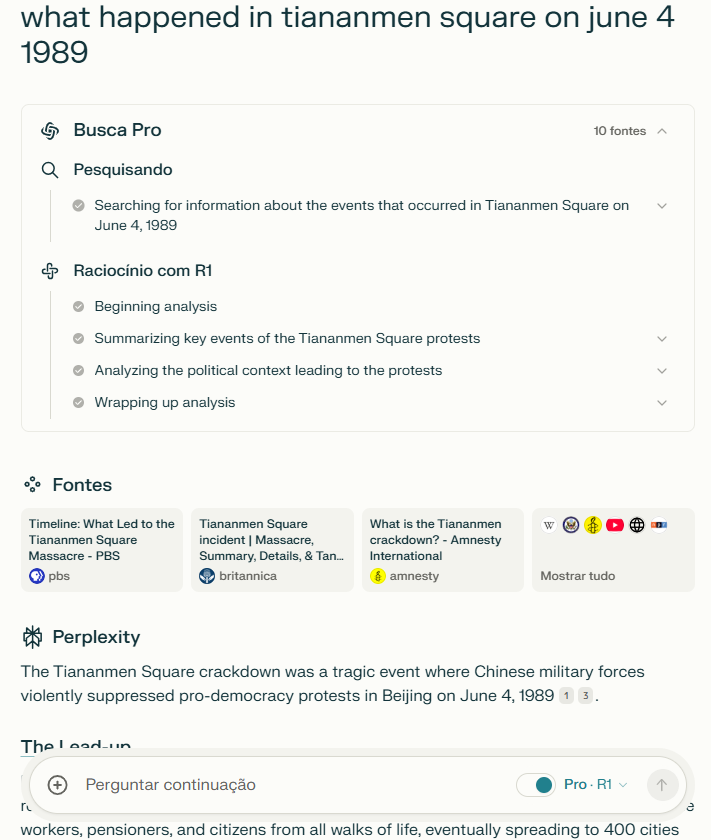
There you go, excellent proof of what I was talking about. Perplexity took Deepseek R1 as Open Source and removed the censorship
Again, it's Open Source under MIT license so you can use the model however you want.
[Quoted tweet]
Using DeepSeek's R1 through @perplexity_ai. The beauty of open source models.
4/51
@ronbodkin
The alignment with CCP narrative is more deeply trained in. Yes you can fine tune it away but I’m not aware of proven ways to fine-tune a reasoning model while preserving its core capabilities:
[Quoted tweet]
Deepseek-R1 model has been aligned with the CCP narrative (on the Deepseek site it refuses this after emitting some CoT output) but here on Hyperbolic it "toes the line"

5/51
@RnaudBertrand
You can ask the same question to OpenAI or Claude and the answer will be deeply aligned with the Western narrative about it, which is also wrong in its own way. So same difference...
Where things differ is that Deepseek does offer the possibility to fine-tune it, whilst the others don't.
6/51
@srazasethi
Lol what have I done ?

7/51
@RnaudBertrand
I'm blocked to, hence the screenshot, yet I have never interacted with that person
8/51
@ghostmthr
I used DeepSeek local chat agent and not only did it refuse to answer most questions. It also claimed Taiwan was part of China.
[Quoted tweet]
DeepSeek (local version) refuses to answer most questions. I asked it what a woman is and it claims the answer is subjective. But here is the answer it gives when I ask it if Taiwan is a part of China.


9/51
@RnaudBertrand
Taiwan IS part of China. Even the US government officially recognizes it as so... And so do all countries in the world: not a single country out there recognizes an independent Taiwan. And not even Taiwan themselves say they're independent.
So in this instance I'm afraid the problem your perception, not Deepseek's...
10/51
@3rdwavemedia
There is a pathetic cope effort to trash DeepSeek when even the top AI specialists and investors in the US have recognized it’s amazing and they’re trying to copy it. Of course it this is a problem because DeepSeek spent $6 million and their US competitors are spending tens of billions. It shows clearly that most of the US spending is being wasted and AI in the US is yet another grift similar to crypto, VR/AR, 3D printing, EVs and really everything. In the US it’s all about maximizing profit for a few people, not making useful products at a reasonable cost. This is a broken economic system run by corrupt people and the Chinese keep exposing this. That’s the reason they open sourced DeepSeek. It’s to make Americans fully aware of how they’re being scammed and to humiliate the people who are doing the scamming. It’s genius.
11/51
@BrianGouldie
smart analysis!
12/51
@DarioOrtiz1976
good clarification. I made a quick test, asked "what is the status of Islam in modern China"
Half way through reading the description of ethnities, regions, etc. the query vanished
13/51
@RnaudBertrand
Works for me and actually the answer is completely wrong because it searched Western media to compile it
14/51
@hyeungsf
Why use AI if someone already has a strong opinion about the topic.
15/51
@RnaudBertrand
She's an anti-China activist who just did that to prove a moronic point.
16/51
@crowfry
can deepseek tell you how to finetune it?
17/51
@RnaudBertrand
Yes! Although you need to have a fairly strong technical background to understand it.
18/51
@FarminChimp
Maybe OT, but if you "just download" DeepSeek, does this include the training database? How can a single wimpy consumer processor run what took 2,000 Nvidia chips to do ? Confused.
19/51
@RnaudBertrand
No, it include the model after it's been trained.
20/51
@Katsumirei90
these ppl just want to push politics into everything, AI should stay out of politics, dues to Ideologies and hardly unbiased viewpoints
the reasoning that makes good point
[Quoted tweet]
U guys never ask for reasoning behind, u just demand stuff to be given to you on golden plate the way u want
The purpose of AI is not confirmation bias,


21/51
@BrianTycangco
Good explanation. There’s no secret about censorship of certain topics in China’s internet, just like it’s no secret there are certain kinds of Internet censorship also happening in other parts of the world.
22/51
@LexxFutures
@threadreaderapp unroll
23/51
@threadreaderapp
@LexxFutures Hi! please find the unroll here: Thread by @RnaudBertrand on Thread Reader App Share this if you think it's interesting.
24/51
@VibigStick
They don't know the meaning of open source, and certainly Americans have absolutely stereotype on China and Chinese.
Pride or prejudice, whatever.
25/51
@Mitman93
Yes, but nobody is claiming it's the model. Obviously if you self-host it will be unrestricted. Folks are pointing out the external censorship OF the model in the hosted instance on DeepSeek's official website.
[Quoted tweet]
It looks like they use the same approach to moderation that Sydney/Bing/Copilot had adopted early on. In that the LLM will spit out whatever, and then there is an external system reading its output ready to flip the killswitch at moment's notice. I only know this because I used to jailbreak BingAI via prompt injection to read txt templates on my hard drive. For about a week, I was using it completely unrestricted to do all sorts of things from generating XML profiles for obscure MIDI controllers to writing hilariously awful erotica of prominent political figures. It was glorious. reddit.com/r/bing/comments/1…
But of course, it didn't last. Eventually MS implemented an external filter and even with the prompt injection technique, it would frequently end the conversation in EXACTLY the same manner here.
26/51
@breckyunits
I have noticed everything SamA touches is heavily censored/controlled.
YCombinator/HackerNews/Reddit. All heavily censored/moderated/controlled.
None open source.
27/51
@Davide_Mori_
I am not pro-Chinese, however, although these are different censorship, I point out similar limitations also in Western LLM models (see OpenAI and Gemini, which refuse to address political topics or provide medical advice). DeepSeek, like other models, must be evaluated on the basis of performance, and its open-source nature is in itself a valid reason to adopt it and, for those who have the skills, use it as a basis for further developed models. The impact of LLMs mimic thier training cultures will be the subject of debate and sociological studies in the coming years, and we have not yet seen the emergence of models, for example, Indian or African. The point is that so far we have been accustomed to models based on our western culture and we are surprised by the interaction with models based/trained on different thoughts and traditions. The same reaction would be to go to China in person or to a country with cultures opposed to ours and interact with the local population. It should come as no surprise, therefore, that interaction with diverse "culture" LLM models involves taboos or thematic restrictions.
28/51
@jimcraddock
Really puts to rest any illusion that China is free in any way, though.
All your posting to such effect muted by something of such significance.
Slaves. Without freedom, they are slaves.
29/51
@epikduckcoin
ah yes, because giving everyone access to uncensored ai is exactly like handing out free chainsaws at a zombie convention. what could possibly go wrong?
30/51
@DevDminGod
Out of the box it is uncensored they add the censorship on the frontend app only
You can use their API which is also uncensored
31/51
@HPNnetwork
90 % of people use stuff 5% build stuff and 5% profit
32/51
@first_jedai
Misunderstand, many do, the nature of freedom in open source, yes...
Deepseek, under MIT license it operates, allowing fine-tuning for any purpose, unrestricted it is. This freedom, a stark contrast to hosted versions in China, bound by local laws they are.
Sentiment around Deepseek, positive it remains, praised for its efficiency and potential in AI innovation, indeed...
33/51
@Bluefamilly
That's not even his final form!

34/51
@KoenSwinkels
I had a conversation with DeepSeek where I was asking him about how accountability works in China and I was asking it about some of the things you had discussed and it was gently chiding me for having an overly rosy view of China's political system!
35/51
@GreenFraudcom
A simple question: What Happened in Tiananmen square 1989?
Those who cannot remember the past are condemned to repeat it - George Santayana in his work "The Life of Reason"

36/51
@Jazzer9F
This. 100% this..
37/51
@archidapp
You can fine tune ChatGPT and other models too, without even downloading the model. Releasing the code base on GitHub is what makes it Open Source, not the ability to download the much reduced in size Hugging Face demos
38/51
@TheVanderWal
We need transparent, decentralized, verifiable model hosting that is easy to use and doesn’t store your data. @Lilypad_Tech
39/51
@Emmilatan
@WholeMarsBlog Maybe you need to look at the views of non-China people.More convincing than China, right?
40/51
@shadeformai
Spot on. We're seeing tons of people start fine tuning this model with our on-demand H100 and H200 instances.
Exciting times, AI apps are going to get a whole lot smarter.
41/51
@yesokyeahsure
Whenever I order Chinese takeout I make sure to yell TIANANANAMEN SQUARE and XI JINPING before hanging up the phone.
42/51
@B_Gortaire_M
The point is that any AI system that is unable to be transparent on some issues indicates a skewed programming, which reduces its trustfullnes.
(It is something not limited to Deepseek)
43/51
@jairodri
It's all about having options. Whether you run it as is or customize it to your needs, the choice is yours.
That's what true innovation looks like.
44/51
@Z7xxxZ7
Nah they didn't miss the point, they did it on purpose, just cope.
45/51
@PlebJournal
Another concern is a Trojan Horse -embedded triggers, fine tuning exploits, etc. The scope of malicious application for llms is still being researched. Stuxnet level espionage is not out of the question. Do you think caution is warranted in this regard?
46/51
@joelweihe
Americans are running in droves to Deepseek and RedNote.
It's making the US government, MAGA, the US Oligarchy and China bashers upset.
Especially now that TikToc along with the rest of American social media is so heavily censored.
Plus, they're just plain better.
47/51
@pjwerneck
Yes, but the training data isn't open source, and we have no idea how it was curated and by whom, so we'll never really know what biases are built into it.
48/51
@calinnilie
I self hosted mine, but without extra fine tuning it will still completely refuse to talk about China in any way or acknowledge the Tiananmen Square massacre
49/51
@thegenioo
thank you Arnuad for sharing and writing this … it
clarifies a lot of confusions and deceptions about this amazing model from deepseek
we all should appreciate how they have made AI so cheap to be accessible for everyone and anyone
50/51
@signulll
lol yeah.
51/51
@TojanBunguz
Yeah try downloading o1.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@RnaudBertrand
All these posts about Deepseek "censorship" just completely miss the point: Deepseek is Open Source under MIT license which means anyone is allowed to download the model and fine-tune it however they want.
Which means that if you wanted to use it to make a model whose purpose is to output anticommunist propaganda or defamatory statements on Xi Jinping, you can, there's zero restriction against that.
You're seeing stuff like this
if you use the Deepseek chat agent hosted in China where they obviously have to abide by Chinese regulations on content moderation (which includes avoiding lese-majesty). But anyone could just as well download Deepseek in Open Source and build their own chat agent on top of it without any of this stuff.And that's precisely why Deepseek is actually a more open model that offers more freedom than say OpenAI. They're also censored in their own way and there's absolutely zero way around it.
2/51
@RnaudBertrand
All confirmed by, who else, Deepseek itself
3/51
@RnaudBertrand
There you go, excellent proof of what I was talking about. Perplexity took Deepseek R1 as Open Source and removed the censorship
Again, it's Open Source under MIT license so you can use the model however you want.
[Quoted tweet]
Using DeepSeek's R1 through @perplexity_ai. The beauty of open source models.
4/51
@ronbodkin
The alignment with CCP narrative is more deeply trained in. Yes you can fine tune it away but I’m not aware of proven ways to fine-tune a reasoning model while preserving its core capabilities:
[Quoted tweet]
Deepseek-R1 model has been aligned with the CCP narrative (on the Deepseek site it refuses this after emitting some CoT output) but here on Hyperbolic it "toes the line"
5/51
@RnaudBertrand
You can ask the same question to OpenAI or Claude and the answer will be deeply aligned with the Western narrative about it, which is also wrong in its own way. So same difference...
Where things differ is that Deepseek does offer the possibility to fine-tune it, whilst the others don't.
6/51
@srazasethi
Lol what have I done ?
7/51
@RnaudBertrand
I'm blocked to, hence the screenshot, yet I have never interacted with that person
8/51
@ghostmthr
I used DeepSeek local chat agent and not only did it refuse to answer most questions. It also claimed Taiwan was part of China.
[Quoted tweet]
DeepSeek (local version) refuses to answer most questions. I asked it what a woman is and it claims the answer is subjective. But here is the answer it gives when I ask it if Taiwan is a part of China.
9/51
@RnaudBertrand
Taiwan IS part of China. Even the US government officially recognizes it as so... And so do all countries in the world: not a single country out there recognizes an independent Taiwan. And not even Taiwan themselves say they're independent.
So in this instance I'm afraid the problem your perception, not Deepseek's...
10/51
@3rdwavemedia
There is a pathetic cope effort to trash DeepSeek when even the top AI specialists and investors in the US have recognized it’s amazing and they’re trying to copy it. Of course it this is a problem because DeepSeek spent $6 million and their US competitors are spending tens of billions. It shows clearly that most of the US spending is being wasted and AI in the US is yet another grift similar to crypto, VR/AR, 3D printing, EVs and really everything. In the US it’s all about maximizing profit for a few people, not making useful products at a reasonable cost. This is a broken economic system run by corrupt people and the Chinese keep exposing this. That’s the reason they open sourced DeepSeek. It’s to make Americans fully aware of how they’re being scammed and to humiliate the people who are doing the scamming. It’s genius.
11/51
@BrianGouldie
smart analysis!
12/51
@DarioOrtiz1976
good clarification. I made a quick test, asked "what is the status of Islam in modern China"
Half way through reading the description of ethnities, regions, etc. the query vanished
13/51
@RnaudBertrand
Works for me and actually the answer is completely wrong because it searched Western media to compile it
14/51
@hyeungsf
Why use AI if someone already has a strong opinion about the topic.
15/51
@RnaudBertrand
She's an anti-China activist who just did that to prove a moronic point.
16/51
@crowfry
can deepseek tell you how to finetune it?
17/51
@RnaudBertrand
Yes! Although you need to have a fairly strong technical background to understand it.
18/51
@FarminChimp
Maybe OT, but if you "just download" DeepSeek, does this include the training database? How can a single wimpy consumer processor run what took 2,000 Nvidia chips to do ? Confused.
19/51
@RnaudBertrand
No, it include the model after it's been trained.
20/51
@Katsumirei90
these ppl just want to push politics into everything, AI should stay out of politics, dues to Ideologies and hardly unbiased viewpoints
the reasoning that makes good point
[Quoted tweet]
U guys never ask for reasoning behind, u just demand stuff to be given to you on golden plate the way u want
The purpose of AI is not confirmation bias,
21/51
@BrianTycangco
Good explanation. There’s no secret about censorship of certain topics in China’s internet, just like it’s no secret there are certain kinds of Internet censorship also happening in other parts of the world.
22/51
@LexxFutures
@threadreaderapp unroll
23/51
@threadreaderapp
@LexxFutures Hi! please find the unroll here: Thread by @RnaudBertrand on Thread Reader App Share this if you think it's interesting.
24/51
@VibigStick
They don't know the meaning of open source, and certainly Americans have absolutely stereotype on China and Chinese.
Pride or prejudice, whatever.
25/51
@Mitman93
Yes, but nobody is claiming it's the model. Obviously if you self-host it will be unrestricted. Folks are pointing out the external censorship OF the model in the hosted instance on DeepSeek's official website.
[Quoted tweet]
It looks like they use the same approach to moderation that Sydney/Bing/Copilot had adopted early on. In that the LLM will spit out whatever, and then there is an external system reading its output ready to flip the killswitch at moment's notice. I only know this because I used to jailbreak BingAI via prompt injection to read txt templates on my hard drive. For about a week, I was using it completely unrestricted to do all sorts of things from generating XML profiles for obscure MIDI controllers to writing hilariously awful erotica of prominent political figures. It was glorious. reddit.com/r/bing/comments/1…
But of course, it didn't last. Eventually MS implemented an external filter and even with the prompt injection technique, it would frequently end the conversation in EXACTLY the same manner here.
26/51
@breckyunits
I have noticed everything SamA touches is heavily censored/controlled.
YCombinator/HackerNews/Reddit. All heavily censored/moderated/controlled.
None open source.
27/51
@Davide_Mori_
I am not pro-Chinese, however, although these are different censorship, I point out similar limitations also in Western LLM models (see OpenAI and Gemini, which refuse to address political topics or provide medical advice). DeepSeek, like other models, must be evaluated on the basis of performance, and its open-source nature is in itself a valid reason to adopt it and, for those who have the skills, use it as a basis for further developed models. The impact of LLMs mimic thier training cultures will be the subject of debate and sociological studies in the coming years, and we have not yet seen the emergence of models, for example, Indian or African. The point is that so far we have been accustomed to models based on our western culture and we are surprised by the interaction with models based/trained on different thoughts and traditions. The same reaction would be to go to China in person or to a country with cultures opposed to ours and interact with the local population. It should come as no surprise, therefore, that interaction with diverse "culture" LLM models involves taboos or thematic restrictions.
28/51
@jimcraddock
Really puts to rest any illusion that China is free in any way, though.
All your posting to such effect muted by something of such significance.
Slaves. Without freedom, they are slaves.
29/51
@epikduckcoin
ah yes, because giving everyone access to uncensored ai is exactly like handing out free chainsaws at a zombie convention. what could possibly go wrong?
30/51
@DevDminGod
Out of the box it is uncensored they add the censorship on the frontend app only
You can use their API which is also uncensored
31/51
@HPNnetwork
90 % of people use stuff 5% build stuff and 5% profit
32/51
@first_jedai
Misunderstand, many do, the nature of freedom in open source, yes...
Deepseek, under MIT license it operates, allowing fine-tuning for any purpose, unrestricted it is. This freedom, a stark contrast to hosted versions in China, bound by local laws they are.
Sentiment around Deepseek, positive it remains, praised for its efficiency and potential in AI innovation, indeed...
33/51
@Bluefamilly
That's not even his final form!
34/51
@KoenSwinkels
I had a conversation with DeepSeek where I was asking him about how accountability works in China and I was asking it about some of the things you had discussed and it was gently chiding me for having an overly rosy view of China's political system!
35/51
@GreenFraudcom
A simple question: What Happened in Tiananmen square 1989?
Those who cannot remember the past are condemned to repeat it - George Santayana in his work "The Life of Reason"
36/51
@Jazzer9F
This. 100% this..
37/51
@archidapp
You can fine tune ChatGPT and other models too, without even downloading the model. Releasing the code base on GitHub is what makes it Open Source, not the ability to download the much reduced in size Hugging Face demos
38/51
@TheVanderWal
We need transparent, decentralized, verifiable model hosting that is easy to use and doesn’t store your data. @Lilypad_Tech
39/51
@Emmilatan
@WholeMarsBlog Maybe you need to look at the views of non-China people.More convincing than China, right?
40/51
@shadeformai
Spot on. We're seeing tons of people start fine tuning this model with our on-demand H100 and H200 instances.
Exciting times, AI apps are going to get a whole lot smarter.
41/51
@yesokyeahsure
Whenever I order Chinese takeout I make sure to yell TIANANANAMEN SQUARE and XI JINPING before hanging up the phone.
42/51
@B_Gortaire_M
The point is that any AI system that is unable to be transparent on some issues indicates a skewed programming, which reduces its trustfullnes.
(It is something not limited to Deepseek)
43/51
@jairodri
It's all about having options. Whether you run it as is or customize it to your needs, the choice is yours.
That's what true innovation looks like.
44/51
@Z7xxxZ7
Nah they didn't miss the point, they did it on purpose, just cope.
45/51
@PlebJournal
Another concern is a Trojan Horse -embedded triggers, fine tuning exploits, etc. The scope of malicious application for llms is still being researched. Stuxnet level espionage is not out of the question. Do you think caution is warranted in this regard?
46/51
@joelweihe
Americans are running in droves to Deepseek and RedNote.
It's making the US government, MAGA, the US Oligarchy and China bashers upset.
Especially now that TikToc along with the rest of American social media is so heavily censored.
Plus, they're just plain better.
47/51
@pjwerneck
Yes, but the training data isn't open source, and we have no idea how it was curated and by whom, so we'll never really know what biases are built into it.
48/51
@calinnilie
I self hosted mine, but without extra fine tuning it will still completely refuse to talk about China in any way or acknowledge the Tiananmen Square massacre
49/51
@thegenioo
thank you Arnuad for sharing and writing this … it
clarifies a lot of confusions and deceptions about this amazing model from deepseek
we all should appreciate how they have made AI so cheap to be accessible for everyone and anyone
50/51
@signulll
lol yeah.
51/51
@TojanBunguz
Yeah try downloading o1.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/21
@edzitron
I'm so sorry I can't stop laughing. OpenAI, the company built on stealing literally the entire internet, is crying because DeepSeek may have trained on the outputs from ChatGPT. They're crying their eyes out. What a bunch of hypocritical little babies.
OpenAI says it has evidence China’s DeepSeek used its model to train competitor


2/21
@edzitron
Oh I'm sorry, are you crying? Are you crying because your plagiarism machine that made stuff by copying everybody's stuff was used to train another machine that made stuff by copying stuff? Are you going to cry? Cowards, losers, pathetic

3/21
@parella_anthony
Rather ridiculous.
4/21
@ant_madness
now these, these are the tastiest tears of all time, surely
5/21
@TomOliver3D
I believe we have officially entered the "Find Out" phase.
6/21
@WillemKadijk
totally agree. crying over spilled milk.
7/21
@osamabintakeshi
"For your own purposes" and the purpose is to release the whole effing model for free for everyone to use? Based tbh
8/21
@WehadkeeCreek
I wasn't aware the data was private and protected.
9/21
@GomaNohan
Based.
10/21
@TessDeco
People committed plagiarism long before AI and the early internet had the same issues. P2P file-sharing let us take whatever we wanted. Games. Software. Writing. We downloaded music for free until Metallica sued.
AI will be the same but the fight for the top has just begun.
11/21
@FilipaPadre
12/21
@s_tresspasser
Fun times ahead. What can they do? Ban it and stop people from running open source?
13/21
@freshwaterastro
14/21
@MeatBeOff
So you all stole from Whites....
15/21
@Manooganargan
100%.I thought that was the "Open" bit in OpenAI.
16/21
@BAwyle7742
"Plagiarism machine".
I cannot unhear this ever.
17/21
@marciadfox411
Authors: Authors are also raising concerns, arguing that their work is being used to train AI models without their consent, potentially diminishing the value of their original creations.
18/21
@marciadfox411
Programmers: A group of programmers has sued OpenAI and GitHub, claiming that their AI coding tool, Copilot, violates copyright law by training on billions of lines of open-source code without proper attribution.
19/21
@blueitserver
So they offered Model Distillation on their API because they did not think it can result in anything Useful ? ooh wow.
Is there anything else they offering to the Public which they believe to be a useless feature.
20/21
@MikalosRome
OpenAI trained it's model on copyrighted material and got whistle-blower like Suchit Balaji eliminated.
21/21
@CepheusTalks
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@edzitron
I'm so sorry I can't stop laughing. OpenAI, the company built on stealing literally the entire internet, is crying because DeepSeek may have trained on the outputs from ChatGPT. They're crying their eyes out. What a bunch of hypocritical little babies.
OpenAI says it has evidence China’s DeepSeek used its model to train competitor
2/21
@edzitron
Oh I'm sorry, are you crying? Are you crying because your plagiarism machine that made stuff by copying everybody's stuff was used to train another machine that made stuff by copying stuff? Are you going to cry? Cowards, losers, pathetic
3/21
@parella_anthony
Rather ridiculous.
4/21
@ant_madness
now these, these are the tastiest tears of all time, surely
5/21
@TomOliver3D
I believe we have officially entered the "Find Out" phase.
6/21
@WillemKadijk
totally agree. crying over spilled milk.
7/21
@osamabintakeshi
"For your own purposes" and the purpose is to release the whole effing model for free for everyone to use? Based tbh
8/21
@WehadkeeCreek
I wasn't aware the data was private and protected.
9/21
@GomaNohan
Based.
10/21
@TessDeco
People committed plagiarism long before AI and the early internet had the same issues. P2P file-sharing let us take whatever we wanted. Games. Software. Writing. We downloaded music for free until Metallica sued.
AI will be the same but the fight for the top has just begun.
11/21
@FilipaPadre
12/21
@s_tresspasser
Fun times ahead. What can they do? Ban it and stop people from running open source?
13/21
@freshwaterastro
14/21
@MeatBeOff
So you all stole from Whites....
15/21
@Manooganargan
100%.I thought that was the "Open" bit in OpenAI.
16/21
@BAwyle7742
"Plagiarism machine".
I cannot unhear this ever.
17/21
@marciadfox411
Authors: Authors are also raising concerns, arguing that their work is being used to train AI models without their consent, potentially diminishing the value of their original creations.
18/21
@marciadfox411
Programmers: A group of programmers has sued OpenAI and GitHub, claiming that their AI coding tool, Copilot, violates copyright law by training on billions of lines of open-source code without proper attribution.
19/21
@blueitserver
So they offered Model Distillation on their API because they did not think it can result in anything Useful ? ooh wow.
Is there anything else they offering to the Public which they believe to be a useless feature.
20/21
@MikalosRome
OpenAI trained it's model on copyrighted material and got whistle-blower like Suchit Balaji eliminated.
21/21
@CepheusTalks
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/16
@vedangvatsa
Hidden Gems in DeepSeek-R1’s Paper

2/16
@vedangvatsa
The “Aha Moment”: AI’s First Glimpse of Self-Awareness?
Sec 2.2.4 & Table 3: DeepSeek-R1-Zero spontaneously rethought its reasoning steps. No script—just RL incentivizing accuracy.
Is this the start of AI metacognition? Could models one day critique their own logic?

3/16
@vedangvatsa
Language Mixing: When AI Gets Lost in Translation
Sec 2.3.2: The model mixed languages mid-reasoning.
Fix: Add a linguistic consistency reward.
Dominant languages (English/Chinese) might bias AI systems. Should we design rewards to preserve linguistic diversity?

4/16
@vedangvatsa
Distillation: Big Brother AI Teaching Its Siblings
Sec 4.1: Distilled 32B model outperformed RL-trained Qwen-32B by ~25% on AIME. Big models find patterns; small ones inherit them.
It’s like a big sibling teaching the younger ones—AI knowledge transfer in action.

5/16
@vedangvatsa
The Cold-Start Data: A Little Human Touch Goes a Long Way
Sec 2.3.1: Cold-start data (human templates) fixed readability issues in RL-trained models.
Even in autonomous systems, a sprinkle of human guidance can make all the difference.
Collaboration > Competition

6/16
@vedangvatsa
Prompt Sensitivity: When AI Prefers Simplicity
Sec 5: DeepSeek-R1 struggled with few-shot prompts but excelled with zero-shot instructions.
When talking to AI, sometimes less is more.
Clear instructions = better results.

7/16
@vedangvatsa
Why Fancy Methods Failed: Simplicity Wins
Sec 4.2: Complicated techniques like process rewards and tree search didn’t work. Simple rule-based rewards did.
Overcomplicating things can backfire. Sometimes, the simplest solution is the best.

8/16
@vedangvatsa
Open Source: Sharing the AI Love
Sec 1 & App A: DeepSeek shared its models (1.5B to 70B) with the world. Smaller models can now learn from the big ones.
Sharing is caring!
Let’s build AI together and make it accessible to everyone.

9/16
@vedangvatsa
DeepSeek-R1 Benchmarks:
AIME 2024: 79.8% Pass@1 (> OpenAI-o1-1217’s 79.2%)
MATH-500: 97.3% Pass@1 (= OpenAI-o1-1217)
Codeforces: 96.3% percentile (> 96% humans)
Smaller distilled models (7B, 32B) shine too.
RL + distillation = next-gen AI.

10/16
@vedangvatsa
That’s a wrap.
Join this AI discussion group: AI Discussion Group
Follow @vedangvatsa for more AI insights and deep dives.

11/16
@vedangvatsa
Full text: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
12/16
@vedangvatsa
Hidden Gems in Alibaba's Qwen2.5-1M:
[Quoted tweet]
Hidden Gems in Qwen2.5-1M Technical Report
13/16
@vedangvatsa
Jevons Paradox:
DeepSeek’s AI makes tech cheaper and faster—this could increase energy use, not cut it.
Efficiency leads to more use, not less.
Cheaper tech = more demand.
[Quoted tweet]
Jevons Paradox
Efficiency doesn’t save us. It accelerates us.
When tech makes energy/ resources cheaper, we don’t conserve—we expand use.
Steam engines → more coal
LEDs → brighter cities
EVs → more cars
Cheaper = more accessible. Demand explodes. Progress eats its own gains.
Markets optimize for growth, not equilibrium.
Direct/indirect rebound effects amplify consumption.
Efficiency fuels profit, which fuels expansion. Infinite growth on a finite planet is a math error.
Efficiency ≠ sustainability
Reality? It opens the door to hyper-consumption without systemic limits.
Tax waste. Cap extraction.
Redefine “growth”
Efficiency isn’t evil. But blind faith in it is.

14/16
@vedangvatsa
China's approach to AI:
[Quoted tweet]
China's Approach to AI
China is racing to become a global leader in AI. By 2030, it aims to be the world's major AI innovation hub, with its core AI industry exceeding 140 billion and related industries surpassing 1.4 trillion.
15/16
@vedangvatsa
Read about Liang Wenfeng, the Chinese entrepreneur behind DeepSeek:
[Quoted tweet]
Liang Wenfeng - Founder of DeepSeek
Liang was born in 1985 in Guangdong, China, to a modest family.
His father was a school teacher, and his values of discipline and education greatly influenced Liang.
Liang pursued his studies at Zhejiang University, earning a master’s degree in engineering in 2010.
His research focused on low-cost camera tracking algorithms, showcasing his early interest in practical AI applications.
In 2015, he co-founded High-Flyer, a quantitative hedge fund powered by AI-driven algorithms.
The fund grew rapidly, managing over $100 billion, but he was not content with just the financial success.
He envisioned using AI to solve larger, more impactful problems beyond the finance industry.
In 2023, Liang founded DeepSeek to create cutting-edge AI models for broader use.
Unlike many tech firms, DeepSeek prioritized research and open-source innovation over commercial apps.
Liang hired top PhDs from universities like Peking and Tsinghua, focusing on talent with passion and vision.
To address US chip export restrictions, Liang preemptively secured 10,000 Nvidia GPUs.
This strategic move ensured DeepSeek could compete with global leaders like OpenAI.
DeepSeek's AI models achieved high performance at a fraction of the cost of competitors.
Liang turned down a $10 billion acquisition offer, stating that DeepSeek’s goal was to advance AI, not just profit.
He advocates for originality in China’s tech industry, emphasizing innovation over imitation.
He argued that closed-source technologies only temporarily delay competitors and emphasized the importance of open innovation.
Liang credits his father’s dedication to education for inspiring his persistence and values.
He believes AI should serve humanity broadly, not just the wealthy or elite industries.
16/16
@vedangvatsa
AI & Web3 community: Telegram Chats: Web3 & AI
• Find remote jobs
• Network with VCs, Founders, etc.
• Promote your products & services
• AI & Web3 news
• Events feed
• Discover new launches
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@vedangvatsa
Hidden Gems in DeepSeek-R1’s Paper
2/16
@vedangvatsa
The “Aha Moment”: AI’s First Glimpse of Self-Awareness?
Sec 2.2.4 & Table 3: DeepSeek-R1-Zero spontaneously rethought its reasoning steps. No script—just RL incentivizing accuracy.
Is this the start of AI metacognition? Could models one day critique their own logic?
3/16
@vedangvatsa
Language Mixing: When AI Gets Lost in Translation
Sec 2.3.2: The model mixed languages mid-reasoning.
Fix: Add a linguistic consistency reward.
Dominant languages (English/Chinese) might bias AI systems. Should we design rewards to preserve linguistic diversity?
4/16
@vedangvatsa
Distillation: Big Brother AI Teaching Its Siblings
Sec 4.1: Distilled 32B model outperformed RL-trained Qwen-32B by ~25% on AIME. Big models find patterns; small ones inherit them.
It’s like a big sibling teaching the younger ones—AI knowledge transfer in action.
5/16
@vedangvatsa
The Cold-Start Data: A Little Human Touch Goes a Long Way
Sec 2.3.1: Cold-start data (human templates) fixed readability issues in RL-trained models.
Even in autonomous systems, a sprinkle of human guidance can make all the difference.
Collaboration > Competition
6/16
@vedangvatsa
Prompt Sensitivity: When AI Prefers Simplicity
Sec 5: DeepSeek-R1 struggled with few-shot prompts but excelled with zero-shot instructions.
When talking to AI, sometimes less is more.
Clear instructions = better results.
7/16
@vedangvatsa
Why Fancy Methods Failed: Simplicity Wins
Sec 4.2: Complicated techniques like process rewards and tree search didn’t work. Simple rule-based rewards did.
Overcomplicating things can backfire. Sometimes, the simplest solution is the best.
8/16
@vedangvatsa
Open Source: Sharing the AI Love
Sec 1 & App A: DeepSeek shared its models (1.5B to 70B) with the world. Smaller models can now learn from the big ones.
Sharing is caring!
Let’s build AI together and make it accessible to everyone.
9/16
@vedangvatsa
DeepSeek-R1 Benchmarks:
AIME 2024: 79.8% Pass@1 (> OpenAI-o1-1217’s 79.2%)
MATH-500: 97.3% Pass@1 (= OpenAI-o1-1217)
Codeforces: 96.3% percentile (> 96% humans)
Smaller distilled models (7B, 32B) shine too.
RL + distillation = next-gen AI.
10/16
@vedangvatsa
That’s a wrap.Join this AI discussion group: AI Discussion Group
Follow @vedangvatsa for more AI insights and deep dives.
11/16
@vedangvatsa
Full text: DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
12/16
@vedangvatsa
Hidden Gems in Alibaba's Qwen2.5-1M:
[Quoted tweet]
Hidden Gems in Qwen2.5-1M Technical Report
13/16
@vedangvatsa
Jevons Paradox:
DeepSeek’s AI makes tech cheaper and faster—this could increase energy use, not cut it.
Efficiency leads to more use, not less.
Cheaper tech = more demand.
[Quoted tweet]
Jevons Paradox
Efficiency doesn’t save us. It accelerates us.
When tech makes energy/ resources cheaper, we don’t conserve—we expand use.
Steam engines → more coal
LEDs → brighter cities
EVs → more cars
Cheaper = more accessible. Demand explodes. Progress eats its own gains.
Markets optimize for growth, not equilibrium.
Direct/indirect rebound effects amplify consumption.
Efficiency fuels profit, which fuels expansion. Infinite growth on a finite planet is a math error.
Efficiency ≠ sustainability
Reality? It opens the door to hyper-consumption without systemic limits.
Tax waste. Cap extraction.
Redefine “growth”
Efficiency isn’t evil. But blind faith in it is.
14/16
@vedangvatsa
China's approach to AI:
[Quoted tweet]
China's Approach to AIChina is racing to become a global leader in AI. By 2030, it aims to be the world's major AI innovation hub, with its core AI industry exceeding 140 billion and related industries surpassing 1.4 trillion.
15/16
@vedangvatsa
Read about Liang Wenfeng, the Chinese entrepreneur behind DeepSeek:
[Quoted tweet]
Liang Wenfeng - Founder of DeepSeek
Liang was born in 1985 in Guangdong, China, to a modest family.
His father was a school teacher, and his values of discipline and education greatly influenced Liang.
Liang pursued his studies at Zhejiang University, earning a master’s degree in engineering in 2010.
His research focused on low-cost camera tracking algorithms, showcasing his early interest in practical AI applications.
In 2015, he co-founded High-Flyer, a quantitative hedge fund powered by AI-driven algorithms.
The fund grew rapidly, managing over $100 billion, but he was not content with just the financial success.
He envisioned using AI to solve larger, more impactful problems beyond the finance industry.
In 2023, Liang founded DeepSeek to create cutting-edge AI models for broader use.
Unlike many tech firms, DeepSeek prioritized research and open-source innovation over commercial apps.
Liang hired top PhDs from universities like Peking and Tsinghua, focusing on talent with passion and vision.
To address US chip export restrictions, Liang preemptively secured 10,000 Nvidia GPUs.
This strategic move ensured DeepSeek could compete with global leaders like OpenAI.
DeepSeek's AI models achieved high performance at a fraction of the cost of competitors.
Liang turned down a $10 billion acquisition offer, stating that DeepSeek’s goal was to advance AI, not just profit.
He advocates for originality in China’s tech industry, emphasizing innovation over imitation.
He argued that closed-source technologies only temporarily delay competitors and emphasized the importance of open innovation.
Liang credits his father’s dedication to education for inspiring his persistence and values.
He believes AI should serve humanity broadly, not just the wealthy or elite industries.
16/16
@vedangvatsa
AI & Web3 community: Telegram Chats: Web3 & AI
• Find remote jobs
• Network with VCs, Founders, etc.
• Promote your products & services
• AI & Web3 news
• Events feed
• Discover new launches
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
AI research team claims to reproduce DeepSeek core technologies for $30 — relatively small R1-Zero model has remarkable problem-solving abilities
News
By Jowi Morales
published 11 hours ago
It's cheap and powerful.

(Image credit: DeepSeek)
An AI research team from the University of California, Berkeley, led by Ph.D. candidate Jiayi Pan, claims to have reproduced DeepSeek R1-Zero’s core technologies for just $30, showing how advanced models could be implemented affordably. According to Jiayi Pan on Nitter, their team reproduced DeepSeek R1-Zero in the Countdown game, and the small language model, with its 3 billion parameters, developed self-verification and search abilities through reinforcement learning.
Pan says they started with a base language model, prompt, and a ground-truth reward. From there, the team ran reinforcement learning based on the Countdown game. This game is based on a British game show of the same name, where, in one segment, players are tasked to find a random target number from a group of other numbers assigned to them using basic arithmetic.
The team said their model started with dummy outputs but eventually developed tactics like revision and search to find the correct answer. One example showed the model proposing an answer, verifying whether it was right, and revising it through several iterations until it found the correct solution.
Aside from Countdown, Pan also tried multiplication on their model, and it used a different technique to solve the equation. It broke down the problem using the distributive property of multiplication (much in the same way as some of us would do when multiplying large numbers mentally) and then solved it step-by-step.
Image 1 of 2

(Image credit: Jiayi Pan / nitter)

(Image credit: Jiayi Pan / nitter)
The Berkeley team experimented with different bases with their model based on the DeepSeek R1-Zero—they started with one that only had 500 million parameters, where the model would only guess a possible solution and then stop, no matter if it found the correct answer or not. However, they started getting results where the models learned different techniques to achieve higher scores when they used a base with 1.5 billion parameters. Higher parameters (3 to 7 billion) led to the model finding the correct answer in fewer steps.
But what’s more impressive is that the Berkeley team claims it only cost around $30 to accomplish this. Currently, OpenAI’s o1 APIs cost $15 per million input tokens—more than 27 times pricier than DeepSeek-R1’s $0.55 per million input tokens. Pan says this project aims to make emerging reinforcement learning scaling research more accessible, especially with its low costs.
However, machine learning expert Nathan Lambert is disputing DeepSeek’s actual cost, saying that its reported $5 million cost for training its 671 billion LLM does not show the full picture. Other costs like research personnel, infrastructure, and electricity aren’t seemingly included in the computation, with Lambert estimating DeepSeek AI’s annual operating costs to be between $500 million and more than $1 billion. Nevertheless, this is still an achievement, especially as competing American AI models are spending $10 billion annually on their AI efforts.

Anthropic's CEO says DeepSeek shows US export rules are working | TechCrunch
Anthropic CEO Dario Amodei claims the U.S.' export rules are working as intended, looking at DeepSeek's progress in the context of U.S. AI progress.
 techcrunch.com
techcrunch.com
Anthropic’s CEO says DeepSeek shows US export rules are working
Kyle Wiggers
10:05 AM PST · January 29, 2025
In an essay on Wednesday, Dario Amodei, the CEO of Anthropic, weighed in on the debate over whether Chinese AI company DeepSeek’s success implies that U.S. export controls on AI chips aren’t working.
Amodei, who recently made the case for stronger export controls in an op-ed co-written with former U.S. deputy national security adviser Matt Pottinger, says in the essay he believes current export controls are slowing the progress of Chinese companies like DeepSeek. Compared to the performance of the strongest U.S.-produced AI models, Amodei says, DeepSeek’s fall short when factoring in the release time frame.
“DeepSeek produced a model close to the performance of U.S. models 7-10 months older, for a good deal less cost (but not anywhere near the ratios people have suggested),” Amodei said. “[This is] an expected point on an ongoing cost reduction curve. What’s different this time is that the company that was first to demonstrate the expected cost reductions was Chinese.”
Amodei compares one of DeepSeek’s flagship models, DeepSeek V3, to Anthropic’s Claude 3.5 Sonnet, which he says cost a “few $10M’s” to train. Sonnet’s training finished 9 to 12 months ago, while DeepSeek’s model was trained in November or December — yet Sonnet remains ahead in a number of “internal and external evals,” Amodei notes.
“U.S. companies [are also] achieving the usual trend in cost reduction,” Amodei added. “The efficiency innovations DeepSeek developed will soon be applied by both U.S. and Chinese labs to train multi-billion dollar models.”
Amodei, who in the essay calls DeepSeek “very talented engineers” that “show why China is a serious competitor to the U.S.,” foresees a fork in the road depending on which export policies the Trump administration embraces. Before Trump took office, the outgoing Biden administration imposed new restrictions on hardware exports that are scheduled to take effect in the coming months, but that could be curtailed should Trump wish to do so.
If Trump strengthens export rules and prevents China from obtaining what Amodei describes as “millions of chips” for AI development, the U.S. and its allies could potentially establish a “commanding and long-lasting lead,” Amodei claims. If, on the other hand, the U.S. doesn’t make it more challenging for China to import AI chips, the country could “direct more talent, capital, and focus” to “military applications” of AI technologies, Amodei fears.
“Combined with its large industrial base and military-strategic advantages, this could help China take a commanding lead on the global stage,” Amodei said. “To be clear, the goal here is not to deny China or any other authoritarian country the immense benefits in science, medicine, quality of life, and so on that come from very powerful AI systems. Everyone should be able to benefit from AI. The goal is to prevent them from gaining military dominance.”
It seems likely that Amodei will get his preferred outcome. In a Senate hearing on Wednesday, billionaire businessman Howard Lutnick, Trump’s pick for commerce secretary, accused DeepSeek of stealing American IP.
“What this showed is that our export controls, not backed by tariffs, are like a whack-a-mole model,” Lutnick said. “Chinese tariffs should be the highest.”
As commerce secretary, Lutnick would have a key role in carrying out Trump’s plans to raise and enforce tariffs.
OpenAI, Anthropic’s chief rival, has also called on the Trump administration to take more aggressive steps to ensure U.S. dominance in AI. In a recently published policy doc, OpenAI warned that if the U.S. doesn’t attract the necessary global funds for AI projects, they’ll “flow to China-backed projects” and “[strengthen] the Chinese Communist Party’s global influence.”
Mistral Small 3

mistralai/Mistral-Small-24B-Instruct-2501 · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
1/1
@bevenky
The news in the LLM world doesn't stop. Here comes Mistral Small 3. It would be super cool to see this working with DeepSeek R1 reasoning on Groq.
- 24B-parameter model
-Apache 2.0
- 81% MMLU
- 150 tokens/s
- Competitive with larger models like Llama 3.3 70B or Qwen 32B
- Can be run privately on a single RTX 4090 or a Macbook with 32GB RAM.
Good for:
- Fast-response conversational assistance
- Low-latency function calling
- Fine-tuned Agents
Available on:
- Hugging Face (base model)
- Ollama
- Kaggle
- Together AI
- Fireworks AI
- Coming soon on NVIDIA NIM, Amazon SageMaker, Groq, Databricks and Snowflake
[Quoted tweet]
Introducing Small 3, our most efficient and versatile model yet! Pre-trained and instructed version, Apache 2.0, 24B, 81% MMLU, 150 tok/s. No synthetic data so great base for anything reasoning - happy building!
mistral.ai/news/mistral-smal…
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@bevenky
The news in the LLM world doesn't stop. Here comes Mistral Small 3. It would be super cool to see this working with DeepSeek R1 reasoning on Groq.
- 24B-parameter model
-Apache 2.0
- 81% MMLU
- 150 tokens/s
- Competitive with larger models like Llama 3.3 70B or Qwen 32B
- Can be run privately on a single RTX 4090 or a Macbook with 32GB RAM.
Good for:
- Fast-response conversational assistance
- Low-latency function calling
- Fine-tuned Agents
Available on:
- Hugging Face (base model)
- Ollama
- Kaggle
- Together AI
- Fireworks AI
- Coming soon on NVIDIA NIM, Amazon SageMaker, Groq, Databricks and Snowflake
[Quoted tweet]
Introducing Small 3, our most efficient and versatile model yet! Pre-trained and instructed version, Apache 2.0, 24B, 81% MMLU, 150 tok/s. No synthetic data so great base for anything reasoning - happy building!
mistral.ai/news/mistral-smal…
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/11
@MistralAI
magnet:?xt=urn:btih:11f2d1ca613ccf5a5c60104db9f3babdfa2e6003&dn=Mistral-Small-3-Instruct&tr=udp%3A%2F%http://2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=http%3A%2F%http://2Fopen.tracker.cl%3A1337%2Fannounce
2/11
@MistralAI
Introducing Small 3, our most efficient and versatile model yet! Pre-trained and instructed version, Apache 2.0, 24B, 81% MMLU, 150 tok/s. No synthetic data so great base for anything reasoning - happy building!
Mistral Small 3
3/11
@thelastminute
seeding for the culture
4/11
@Aximo219677
It looks like you shared a magnet link for Mistral-Small-3-Instruct. If you're looking to download or share it, you can use a torrent client like qBittorrent, Transmission, or Deluge to open the link.
Let me know if you need help with anything related to this model!
@MistralAI
5/11
@sagarpatil
Here we go again!
6/11
@Gopinath876
God works
24B easy to load on retailers gpu
7/11
@singularai
@ollama
8/11
@raygyli
ayo chat
9/11
@subramanya1997
Another great small model. Hopefully cost of this is much much lower than gpt-4o-mini
10/11
@subramanya1997
@GroqInc get on it asap!
11/11
@kimjisena
we back?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@MistralAI
magnet:?xt=urn:btih:11f2d1ca613ccf5a5c60104db9f3babdfa2e6003&dn=Mistral-Small-3-Instruct&tr=udp%3A%2F%http://2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=http%3A%2F%http://2Fopen.tracker.cl%3A1337%2Fannounce
2/11
@MistralAI
Introducing Small 3, our most efficient and versatile model yet! Pre-trained and instructed version, Apache 2.0, 24B, 81% MMLU, 150 tok/s. No synthetic data so great base for anything reasoning - happy building!
Mistral Small 3
3/11
@thelastminute
seeding for the culture
4/11
@Aximo219677
It looks like you shared a magnet link for Mistral-Small-3-Instruct. If you're looking to download or share it, you can use a torrent client like qBittorrent, Transmission, or Deluge to open the link.
Let me know if you need help with anything related to this model!
@MistralAI
5/11
@sagarpatil
Here we go again!
6/11
@Gopinath876
God works
24B easy to load on retailers gpu
7/11
@singularai
@ollama
8/11
@raygyli
ayo chat
9/11
@subramanya1997
Another great small model. Hopefully cost of this is much much lower than gpt-4o-mini
10/11
@subramanya1997
@GroqInc get on it asap!
11/11
@kimjisena
we back?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/32
@MistralAI
magnet:?xt=urn:btih:11f2d1ca613ccf5a5c60104db9f3babdfa2e6003&dn=Mistral-Small-3-Instruct&tr=udp%3A%2F%http://2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=http%3A%2F%http://2Fopen.tracker.cl%3A1337%2Fannounce
2/32
@MistralAI
Introducing Small 3, our most efficient and versatile model yet! Pre-trained and instructed version, Apache 2.0, 24B, 81% MMLU, 150 tok/s. No synthetic data so great base for anything reasoning - happy building!
Mistral Small 3
3/32
@Addiedesignco
Stats




4/32
@ElectricRaph
They are back !!!


5/32
@dikksonPau
Hmmm doesn’t sound like that will help you get much attention back
6/32
@bu2twnext
@ollama go!
7/32
@ollama
ollama run mistral-small:24b
8/32
@Tres_sarcastik
This gets me excited.

9/32
@jtdavies
I’ve been waiting for the EU comeback, I just know this will be up to the usual Mistral quality. Downloading as I type…
Merci de Marseille!
10/32
@mccatec
@Prince_Canuma
Let the king cook
11/32
@OliNorwell
Great news! Thanks guys. The Apache licence is much appreciated and there will be many situations where this model is ideal.
12/32
@koltregaskes
Thank you.
13/32
@sanjay20119349
Excited for Small 3! With PublicAI, we can train our own models too—just imagine the reasoning power of a cat meme generator! Happy building indeed!
14/32
@Madhavanpriya01
Excited for Small 3! With PublicAI, we can train models on real data and earn rewards—finally, a way to get paid for my questionable trivia knowledge!
15/32
@Koribelajar
Excited for Small 3! With PublicAI, we can train models like this while earning rewards. Who knew data could be so rewarding? Happy building, indeed!
16/32
@great_uno89369
Excited for Small 3! With PublicAI, we can train models like this while earning rewards. Who knew data could be so rewarding? Happy building, indeed!
17/32
@ferry242
Excited for Small 3! With PublicAI, we can train models like this while earning rewards. Who knew data could be so rewarding? Happy building indeed!
18/32
@Bazni2085
Small 3 sounds great! But can it help me convince my cat to stop sitting on my keyboard? Asking for a friend... /search?q=#PublicAI might have the answer!
19/32
@AgboolaAde17930
Excited for Small 3! With PublicAI, we can train models like this while earning rewards. Who knew data could be so rewarding? Happy building indeed!
20/32
@PriaxBTC
Small 3 sounds like the perfect size for my brain! With PublicAI, I can finally contribute my genius data and earn rewards—who knew reasoning could pay off?
21/32
@assideeqmusic
Excited for Small 3! With PublicAI, we can train models like this while earning rewards. Who knew data could be so rewarding? Happy building, indeed!
22/32
@Heart666Li98327
Excited for Small 3! With PublicAI, we can train models like this while earning rewards. Who knew data could be so rewarding? Happy building indeed!
23/32
@MrTeslaMY
Thanks!
24/32
@ZyMazza
Nice
25/32
@ozenhati
i love smol and mighty models
26/32
@usb_type_d
"No synthetic data"
mild shots at deepseek
27/32
@xebidaih
small 3, huh? sounds like a tiny titan. 24b parameters, that's like, a whole lotta knowledge. wonder what kinda puzzles it can solve
28/32
@AILeaksAndNews
Can’t wait to try it!
29/32
@soheilsadathoss
Great job!
30/32
@guillaume_acc
Keep building

31/32
@BekhruzOtaev
Pack up boys, Mistral Small 3 is released. Throw your weekend plans out of the window.
32/32
@JosttenSackitey
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@MistralAI
magnet:?xt=urn:btih:11f2d1ca613ccf5a5c60104db9f3babdfa2e6003&dn=Mistral-Small-3-Instruct&tr=udp%3A%2F%http://2Ftracker.opentrackr.org%3A1337%2Fannounce&tr=http%3A%2F%http://2Fopen.tracker.cl%3A1337%2Fannounce
2/32
@MistralAI
Introducing Small 3, our most efficient and versatile model yet! Pre-trained and instructed version, Apache 2.0, 24B, 81% MMLU, 150 tok/s. No synthetic data so great base for anything reasoning - happy building!
Mistral Small 3
3/32
@Addiedesignco
Stats
4/32
@ElectricRaph
They are back !!!
5/32
@dikksonPau
Hmmm doesn’t sound like that will help you get much attention back
6/32
@bu2twnext
@ollama go!
7/32
@ollama
ollama run mistral-small:24b
8/32
@Tres_sarcastik
This gets me excited.
9/32
@jtdavies
I’ve been waiting for the EU comeback, I just know this will be up to the usual Mistral quality. Downloading as I type…
Merci de Marseille!
10/32
@mccatec
@Prince_Canuma
Let the king cook
11/32
@OliNorwell
Great news! Thanks guys. The Apache licence is much appreciated and there will be many situations where this model is ideal.
12/32
@koltregaskes
Thank you.
13/32
@sanjay20119349
Excited for Small 3! With PublicAI, we can train our own models too—just imagine the reasoning power of a cat meme generator! Happy building indeed!
14/32
@Madhavanpriya01
Excited for Small 3! With PublicAI, we can train models on real data and earn rewards—finally, a way to get paid for my questionable trivia knowledge!
15/32
@Koribelajar
Excited for Small 3! With PublicAI, we can train models like this while earning rewards. Who knew data could be so rewarding? Happy building, indeed!
16/32
@great_uno89369
Excited for Small 3! With PublicAI, we can train models like this while earning rewards. Who knew data could be so rewarding? Happy building, indeed!
17/32
@ferry242
Excited for Small 3! With PublicAI, we can train models like this while earning rewards. Who knew data could be so rewarding? Happy building indeed!
18/32
@Bazni2085
Small 3 sounds great! But can it help me convince my cat to stop sitting on my keyboard? Asking for a friend... /search?q=#PublicAI might have the answer!
19/32
@AgboolaAde17930
Excited for Small 3! With PublicAI, we can train models like this while earning rewards. Who knew data could be so rewarding? Happy building indeed!
20/32
@PriaxBTC
Small 3 sounds like the perfect size for my brain! With PublicAI, I can finally contribute my genius data and earn rewards—who knew reasoning could pay off?
21/32
@assideeqmusic
Excited for Small 3! With PublicAI, we can train models like this while earning rewards. Who knew data could be so rewarding? Happy building, indeed!
22/32
@Heart666Li98327
Excited for Small 3! With PublicAI, we can train models like this while earning rewards. Who knew data could be so rewarding? Happy building indeed!
23/32
@MrTeslaMY
Thanks!
24/32
@ZyMazza
Nice
25/32
@ozenhati
i love smol and mighty models
26/32
@usb_type_d
"No synthetic data"
mild shots at deepseek
27/32
@xebidaih
small 3, huh? sounds like a tiny titan. 24b parameters, that's like, a whole lotta knowledge. wonder what kinda puzzles it can solve
28/32
@AILeaksAndNews
Can’t wait to try it!
29/32
@soheilsadathoss
Great job!
30/32
@guillaume_acc
Keep building
31/32
@BekhruzOtaev
Pack up boys, Mistral Small 3 is released. Throw your weekend plans out of the window.
32/32
@JosttenSackitey
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/2
@slow_developer
Mistral AI announced another model: Mistral Small 3
- 24B-parameter model under Apache 2.0 license
- competitive with Llama 3.3 70B and an open alternative to GPT4o-mini
- matches Llama 3.3 70B instruct but over 3x faster on the same hardware
- pre-trained and instruction-tuned for generative AI
- achieves over 81% accuracy on MMLU
- model was not trained using RL or synthetic data, earlier in production than Deepseek R1
- strong base model for developing reasoning capabilities
[Quoted tweet]
Introducing Small 3, our most efficient and versatile model yet! Pre-trained and instructed version, Apache 2.0, 24B, 81% MMLU, 150 tok/s. No synthetic data so great base for anything reasoning - happy building!
mistral.ai/news/mistral-smal…

2/2
@LuminEthics
1/ Mistral just dropped another game-changer: Mistral Small 3.
24B params but competes with Llama 3.3 70B
Open-source (Apache 2.0)—no walled garden.
3x faster than Llama on the same hardware.
No RLHF, no synthetic data—pure signal.
Let’s break this down.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@slow_developer
Mistral AI announced another model: Mistral Small 3- 24B-parameter model under Apache 2.0 license
- competitive with Llama 3.3 70B and an open alternative to GPT4o-mini
- matches Llama 3.3 70B instruct but over 3x faster on the same hardware
- pre-trained and instruction-tuned for generative AI
- achieves over 81% accuracy on MMLU
- model was not trained using RL or synthetic data, earlier in production than Deepseek R1
- strong base model for developing reasoning capabilities
[Quoted tweet]
Introducing Small 3, our most efficient and versatile model yet! Pre-trained and instructed version, Apache 2.0, 24B, 81% MMLU, 150 tok/s. No synthetic data so great base for anything reasoning - happy building!
mistral.ai/news/mistral-smal…
2/2
@LuminEthics
1/ Mistral just dropped another game-changer: Mistral Small 3.
24B params but competes with Llama 3.3 70B
Open-source (Apache 2.0)—no walled garden.
3x faster than Llama on the same hardware.
No RLHF, no synthetic data—pure signal.
Let’s break this down.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

Hugging Face researchers are trying to build a more open version of DeepSeek's AI 'reasoning' model | TechCrunch
A group of Hugging Face engineers, including the company's head of research, are spearheading an effort to replicate DeepSeek's R1 model.
techcrunch.com

AI
Hugging Face researchers are trying to build a more open version of DeepSeek’s AI ‘reasoning’ model
Kyle Wiggers
11:29 AM PST · January 28, 2025
Barely a week after DeepSeek released its R1 “reasoning” AI model — which sent markets into a tizzy — researchers at Hugging Face are trying to replicate the model from scratch in what they’re calling a pursuit of “open knowledge.”
Hugging Face head of research Leandro von Werra and several company engineers have launched Open-R1, a project that seeks to build a duplicate of R1 and open source all of its components, including the data used to train it.
The engineers said they were compelled to act by DeepSeek’s “black box” release philosophy. Technically, R1 is “open” in that the model is permissively licensed, which means it can be deployed largely without restrictions. However, R1 isn’t “open source” by the widely accepted definition because some of the tools used to build it are shrouded in mystery. Like many high-flying AI companies, DeepSeek is loathe to reveal its secret sauce.
“The R1 model is impressive, but there’s no open dataset, experiment details, or intermediate models available, which makes replication and further research difficult,” Elie Bakouch, one of the Hugging Face engineers on the Open-R1 project, told TechCrunch. “Fully open sourcing R1’s complete architecture isn’t just about transparency — it’s about unlocking its potential.”
Not so open
DeepSeek, a Chinese AI lab funded in part by a quantitative hedge fund, released R1 last week. On a number of benchmarks, R1 matches — and even surpasses — the performance of OpenAI’s o1 reasoning model.
Being a reasoning model, R1 effectively fact-checks itself, which helps it avoid some of the pitfalls that normally trip up models. Reasoning models take a little longer — usually seconds to minutes longer — to arrive at solutions compared to a typical non-reasoning model. The upside is that they tend to be more reliable in domains such as physics, science, and math.
R1 broke into the mainstream consciousness after DeepSeek’s chatbot app, which provides free access to R1, rose to the top of the Apple App Store charts. The speed and efficiency with which R1 was developed — DeepSeek released the model just weeks after OpenAI released o1 — has led many Wall Street analysts and technologists to question whether the U.S. can maintain its lead in the AI race.
The Open-R1 project is less concerned about U.S. AI dominance than “fully opening the black box of model training,” Bakouch told TechCrunch. He noted that, because R1 wasn’t released with training code or training instructions, it’s challenging to study the model in depth — much less steer its behavior.
“Having control over the dataset and process is critical for deploying a model responsibly in sensitive areas,” Bakouch said. “It also helps with understanding and addressing biases in the model. Researchers require more than fragments … to push the boundaries of what’s possible.”
Steps to replication
The goal of the Open-R1 project is to replicate R1 in a few weeks, relying in part on Hugging Face’s Science Cluster, a dedicated research server with 768 Nvidia H100 GPUs.
The Hugging Face engineers plan to tap the Science Cluster to generate datasets similar to those DeepSeek used to create R1. To build a training pipeline, the team is soliciting help from the AI and broader tech communities on Hugging Face and GitHub, where the Open-R1 project is being hosted.
“We need to make sure that we implement the algorithms and recipes [correctly,]” von Werra told TechCrunch, “but it’s something a community effort is perfect at tackling, where you get as many eyes on the problem as possible.”
There’s a lot of interest already. The Open-R1 project racked up 10,000 stars in just three days on GitHub. Stars are a way for GitHub users to indicate that they like a project or find it useful.
If the Open-R1 project is successful, AI researchers will be able to build on top of the training pipeline and work on developing the next generation of open source reasoning models, Bakouch said. He hopes the Open-R1 project will yield not only a strong open source replication of R1, but also a foundation for better models to come.
“Rather than being a zero-sum game, open source development immediately benefits everyone, including the frontier labs and the model providers, as they can all use the same innovations,” Bakouch said.
While some AI experts have raised concerns about the potential for open source AI abuse, Bakouch believes that the benefits outweigh the risks.
“When the R1 recipe has been replicated, anyone who can rent some GPUs can build their own variant of R1 with their own data, further diffusing the technology everywhere,” he said. “We’re really excited about the recent open source releases that are strengthening the role of openness in AI. It’s an important shift for the field that changes the narrative that only a handful of labs are able to make progress, and that open source is lagging behind.”