Anthropic builds RAG directly into Claude models with new Citations API
New feature allows Claude to reference source documents and reduce hallucinations.
Anthropic builds RAG directly into Claude models with new Citations API
New feature allows Claude to reference source documents and reduce hallucinations.
Benj Edwards – Jan 24, 2025 4:05 PM |
38

Credit: Kirillm via Getty Images
On Thursday, Anthropic announced Citations, a new API feature that helps Claude models avoid confabulations (also called hallucinations) by linking their responses directly to source documents. The feature lets developers add documents to Claude's context window, enabling the model to automatically cite specific passages it uses to generate answers.
"When Citations is enabled, the API processes user-provided source documents (PDF documents and plaintext files) by chunking them into sentences," Anthropic says. "These chunked sentences, along with user-provided context, are then passed to the model with the user's query."
The company describes several potential uses for Citations, including summarizing case files with source-linked key points, answering questions across financial documents with traced references, and powering support systems that cite specific product documentation.
In its own internal testing, the company says that the feature improved recall accuracy by up to 15 percent compared to custom citation implementations created by users within prompts. While a 15 percent improvement in accurate recall doesn't sound like much, the new feature still attracted interest from AI researchers like Simon Willison because of its fundamental integration of Retrieval Augmented Generation (RAG) techniques. In a detailed post on his blog, Willison explained why citation features are important.
"The core of the Retrieval Augmented Generation (RAG) pattern is to take a user's question, retrieve portions of documents that might be relevant to that question and then answer the question by including those text fragments in the context provided to the LLM," he writes. "This usually works well, but there is still a risk that the model may answer based on other information from its training data (sometimes OK) or hallucinate entirely incorrect details (definitely bad)."
Willison notes that while citing sources helps verify accuracy, building a system that does it well "can be quite tricky," but Citations appears to be a step in the right direction by building RAG capability directly into the model.
Apparently, that capability is not a new thing. Anthropic's Alex Albert wrote on X, "Under the hood, Claude is trained to cite sources. With Citations, we are exposing this ability to devs. To use Citations, users can pass a new "citations: {enabled:true}" parameter on any document type they send through the API."
Early adopter reports promising results
The company released Citations for Claude 3.5 Sonnet and Claude 3.5 Haiku models through both the Anthropic API and Google Cloud's Vertex AI platform, but it's apparently already getting some use in the field.
Anthropic says that Thomson Reuters, which uses Claude to power its CoCounsel legal AI reference platform, is looking forward to using Citations in a way that helps "minimize hallucination risk but also strengthens trust in AI-generated content."
Additionally, financial technology company Endex told Anthropic that Citations reduced their source confabulations from 10 percent to zero while increasing references per response by 20 percent, according to CEO Tarun Amasa.
Despite these claims, relying on any LLM to accurately relay reference information is still a risk until the technology is more deeply studied and proven in the field.
Anthropic will charge users its standard token-based pricing, though quoted text in responses won't count toward output token costs. Sourcing a 100-page document as a reference would cost approximately $0.30 with Claude 3.5 Sonnet or $0.08 with Claude 3.5 Haiku, according to Anthropic's standard API pricing.


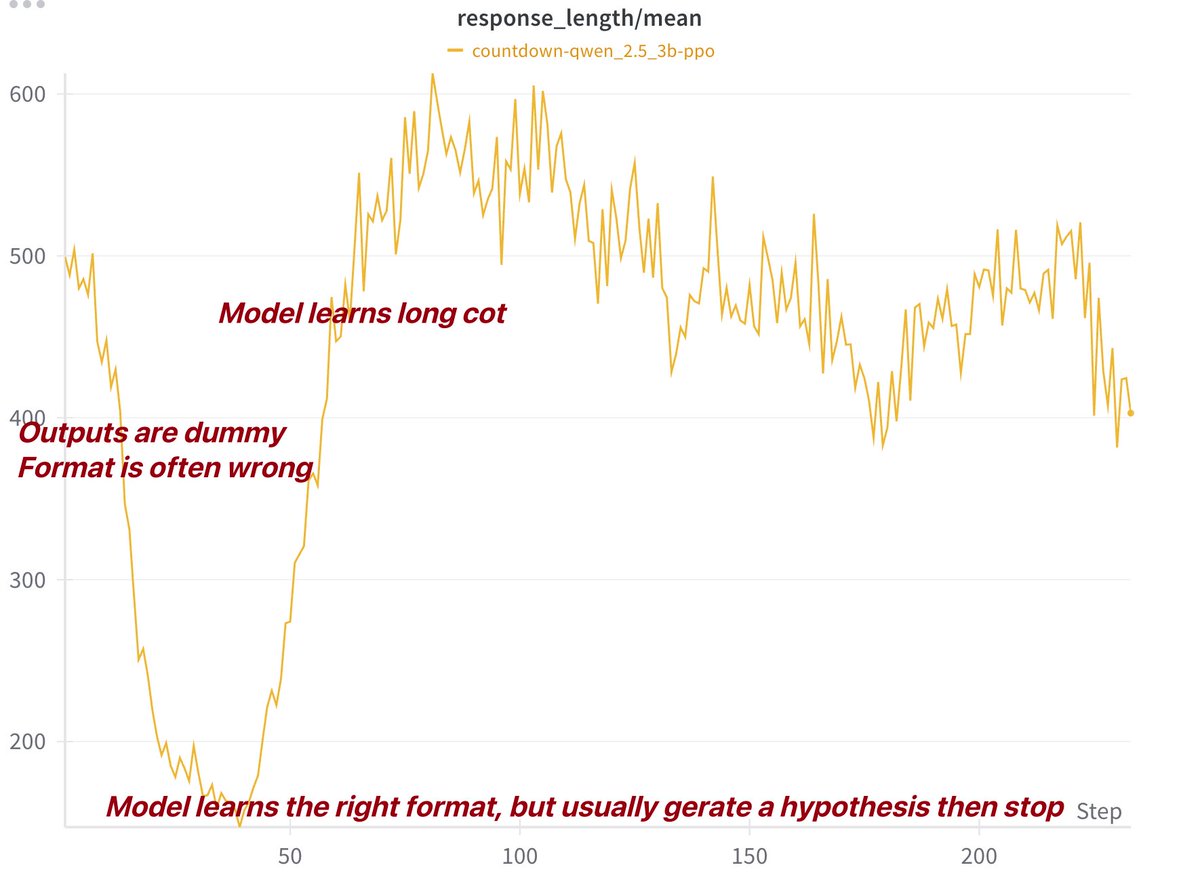
 who wouldn't want a system that generates proveably save long horizon task execution programs. Therefore the AI system needs to generate the symbolic abstraction by itself at Inference Time. Not only use symbolic abstractions, but even come up with helpful symbolic abstractions. Therefore the amount of symbolic abstractions should grow with inference time asymptotically. To a manageable size. Best thing: it's human readable. And one can create 100% accurate synthetic Data with it. Which means valuable signal to noise.
who wouldn't want a system that generates proveably save long horizon task execution programs. Therefore the AI system needs to generate the symbolic abstraction by itself at Inference Time. Not only use symbolic abstractions, but even come up with helpful symbolic abstractions. Therefore the amount of symbolic abstractions should grow with inference time asymptotically. To a manageable size. Best thing: it's human readable. And one can create 100% accurate synthetic Data with it. Which means valuable signal to noise.










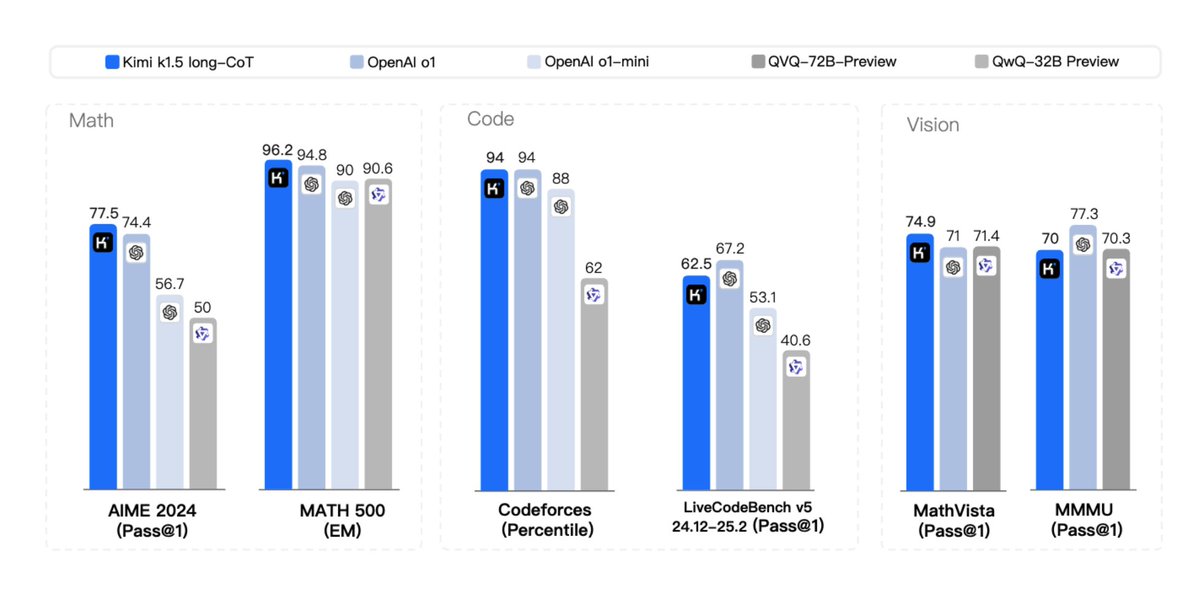
 Introducing Kimi k1.5 --- an o1-level multi-modal model
Introducing Kimi k1.5 --- an o1-level multi-modal model AIME,
AIME,  LiveCodeBench by a large margin (up to +550%)
LiveCodeBench by a large margin (up to +550%) MathVista,
MathVista, 


 🫡
🫡 @huggingface still has a few To available I guess.
@huggingface still has a few To available I guess.

 What can Kimi k1.5 do?
What can Kimi k1.5 do? Image to Code: Convert images into structured code and insights
Image to Code: Convert images into structured code and insights
 Available now on
Available now on 








 AIME,
AIME, 

 Now supporting a 1 MILLION TOKEN CONTEXT LENGTH
Now supporting a 1 MILLION TOKEN CONTEXT LENGTH  Open Models: Meet Qwen2.5-7B-Instruct-1M & Qwen2.5-14B-Instruct-1M —our first-ever models handling 1M-token contexts!
Open Models: Meet Qwen2.5-7B-Instruct-1M & Qwen2.5-14B-Instruct-1M —our first-ever models handling 1M-token contexts! 
 Lightning-Fast Inference Framework: We’ve fully open-sourced our inference framework based on vLLM , integrated with sparse attention methods. Experience 3x to 7x faster processing for 1M-token inputs!
Lightning-Fast Inference Framework: We’ve fully open-sourced our inference framework based on vLLM , integrated with sparse attention methods. Experience 3x to 7x faster processing for 1M-token inputs! 
 Tech Deep Dive: Check out our detailed Technical Report for all the juicy details behind the Qwen2.5-1M series!
Tech Deep Dive: Check out our detailed Technical Report for all the juicy details behind the Qwen2.5-1M series! 
 Technical Report:
Technical Report:  Blog:
Blog:  Play with Qwen2.5-Turbo supporting 1M tokens in Qwen Chat (
Play with Qwen2.5-Turbo supporting 1M tokens in Qwen Chat (


















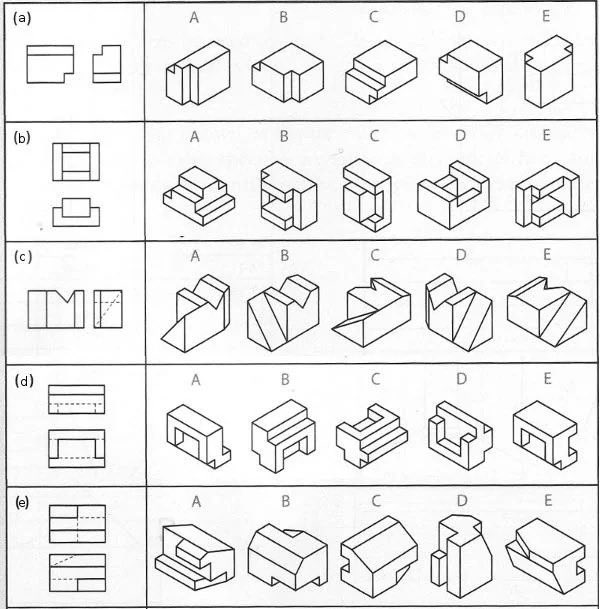
 @ssfd____ for
@ssfd____ for  unroll
unroll
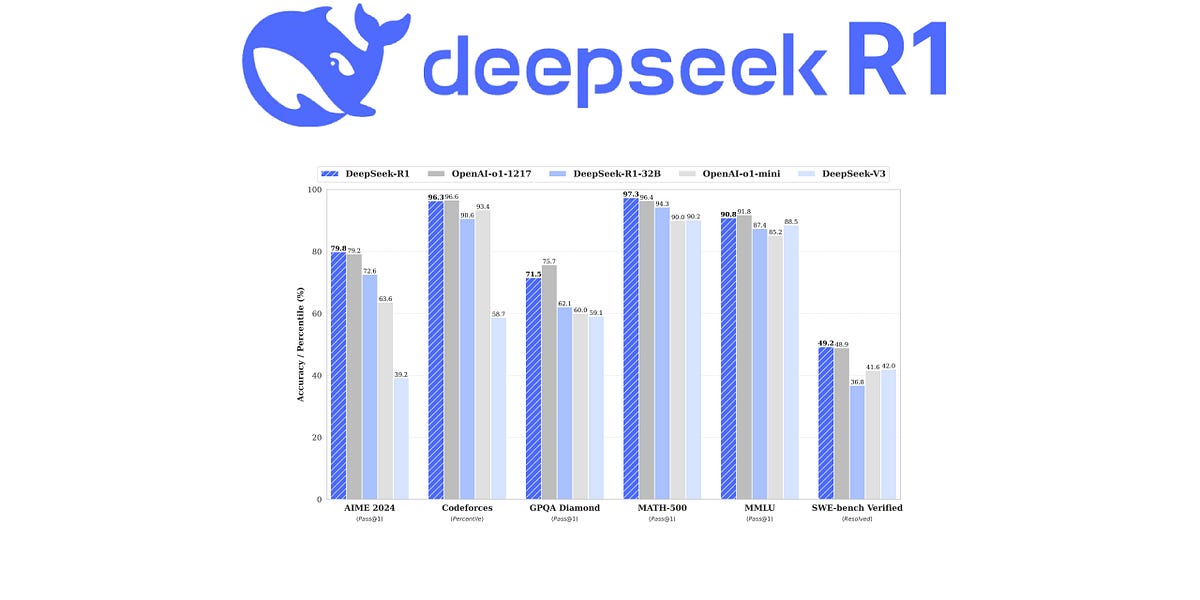



 Finally had a chance to dig into DeepSeek’s r1…
Finally had a chance to dig into DeepSeek’s r1… 



 While Everyone Panics About China Taking Over AI, Here’s the Real Reason It Won’t Happen
While Everyone Panics About China Taking Over AI, Here’s the Real Reason It Won’t Happen  is cookin'
is cookin'








 Meanwhile, at /search?q=#PublicAI, we're just trying to make sure everyone gets a slice of the data pie!
Meanwhile, at /search?q=#PublicAI, we're just trying to make sure everyone gets a slice of the data pie!