1/6
@rohanpaul_ai
First Open code LLM to reveal entire training pipeline and reproducible datasets
 Original Problem:
Original Problem:
Code LLMs lack transparency in training data and protocols, limiting research community's ability to establish strong baselines and gain deeper insights.
-----
 Solution in this Paper:
Solution in this Paper:
→ Introduces OpenCoder, a fully transparent code LLM with complete training data, processing pipeline, and protocols
→ Implements sophisticated data processing pipeline called RefineCode with 960B tokens across 607 programming languages
→ Uses aggressive file-level deduplication and language-specific filtering rules
→ Employs two-stage instruction tuning with annealing phase using high-quality synthetic data
-----
 Key Insights:
Key Insights:
→ File-level deduplication outperforms repository-level approach for maintaining data diversity
→ GitHub star-based filtering can reduce data diversity and affect distribution
→ High-quality data in annealing phase is more crucial than quantity
→ Two-stage instruction tuning improves both theoretical and practical coding tasks
-----
 Results:
Results:
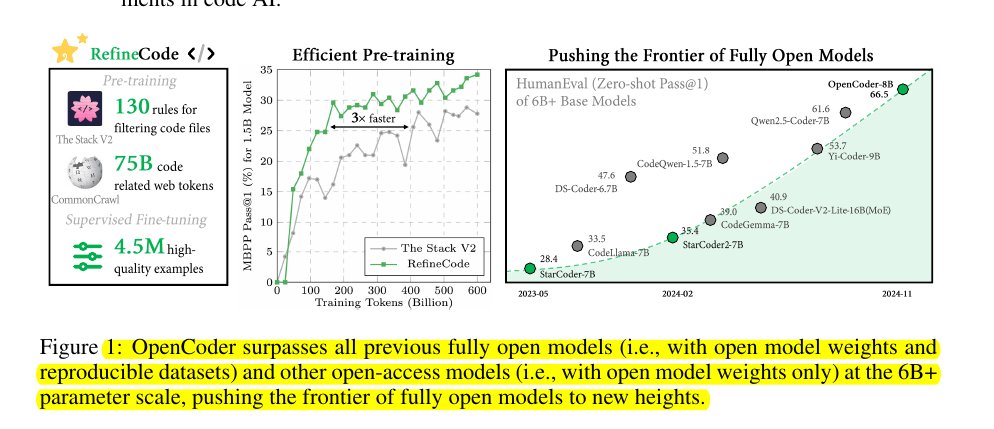
→ OpenCoder-8B achieves 83.5% pass@1 on HumanEval benchmark
→ Surpasses all previous fully open models at 6B+ parameter scale
→ Demonstrates superior training efficiency compared to The Stack v2

2/6
@rohanpaul_ai
Paper Title: "OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models"
Generated below podcast on this paper with Google's Illuminate.
https://video.twimg.com/ext_tw_video/1861161457960001538/pu/vid/avc1/1080x1080/mc7X5OmyGwoCxj21.mp4
3/6
@rohanpaul_ai
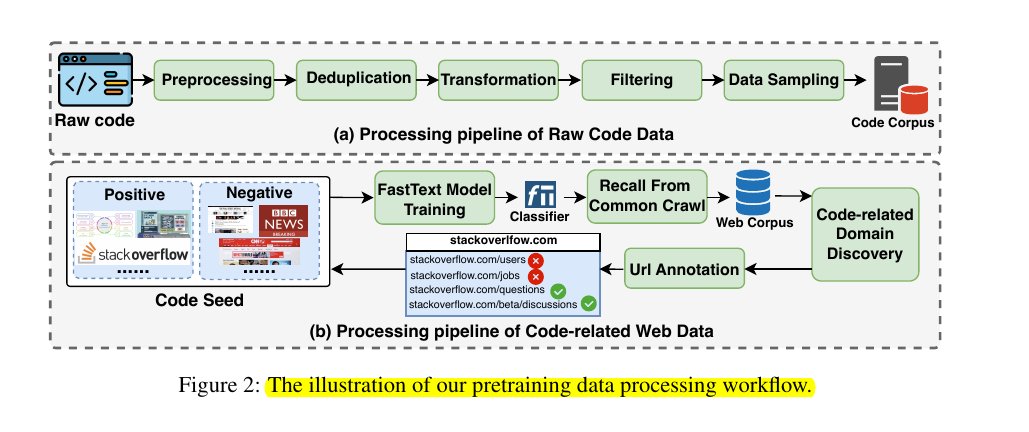
The illustration of our pretraining data processing workflow.
4/6
@rohanpaul_ai
 OpenCoder surpasses all previous fully open models and other open-access models at the 6B+ parameter scale. The 8B version achieves 83.5% pass@1 on HumanEval benchmark, making it competitive with leading proprietary models.
OpenCoder surpasses all previous fully open models and other open-access models at the 6B+ parameter scale. The 8B version achieves 83.5% pass@1 on HumanEval benchmark, making it competitive with leading proprietary models.
5/6
@rohanpaul_ai
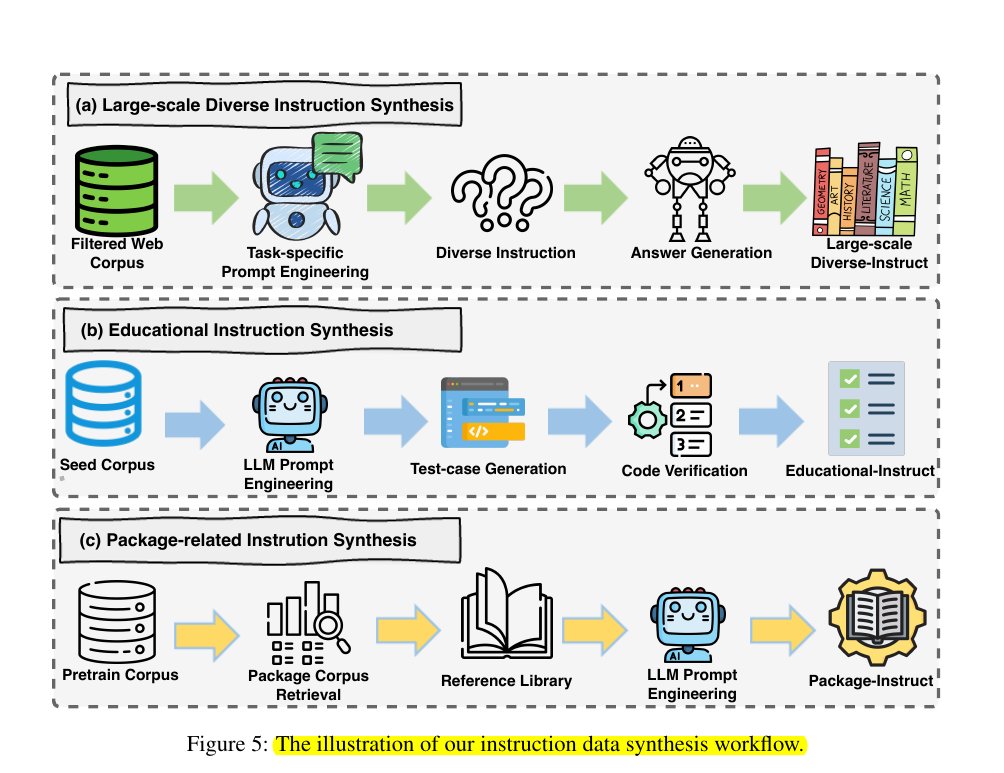
Their instruction data synthesis workflow
6/6
@rohanpaul_ai
[2411.04905] OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@rohanpaul_ai
First Open code LLM to reveal entire training pipeline and reproducible datasets
Original Problem:Code LLMs lack transparency in training data and protocols, limiting research community's ability to establish strong baselines and gain deeper insights.
-----
Solution in this Paper:→ Introduces OpenCoder, a fully transparent code LLM with complete training data, processing pipeline, and protocols
→ Implements sophisticated data processing pipeline called RefineCode with 960B tokens across 607 programming languages
→ Uses aggressive file-level deduplication and language-specific filtering rules
→ Employs two-stage instruction tuning with annealing phase using high-quality synthetic data
-----
Key Insights:→ File-level deduplication outperforms repository-level approach for maintaining data diversity
→ GitHub star-based filtering can reduce data diversity and affect distribution
→ High-quality data in annealing phase is more crucial than quantity
→ Two-stage instruction tuning improves both theoretical and practical coding tasks
-----
Results:→ OpenCoder-8B achieves 83.5% pass@1 on HumanEval benchmark
→ Surpasses all previous fully open models at 6B+ parameter scale
→ Demonstrates superior training efficiency compared to The Stack v2
2/6
@rohanpaul_ai
Paper Title: "OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models"
Generated below podcast on this paper with Google's Illuminate.
https://video.twimg.com/ext_tw_video/1861161457960001538/pu/vid/avc1/1080x1080/mc7X5OmyGwoCxj21.mp4
3/6
@rohanpaul_ai
The illustration of our pretraining data processing workflow.
4/6
@rohanpaul_ai
OpenCoder surpasses all previous fully open models and other open-access models at the 6B+ parameter scale. The 8B version achieves 83.5% pass@1 on HumanEval benchmark, making it competitive with leading proprietary models.
5/6
@rohanpaul_ai
Their instruction data synthesis workflow
6/6
@rohanpaul_ai
[2411.04905] OpenCoder: The Open Cookbook for Top-Tier Code Large Language Models
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
 Original Problem:
Original Problem: Solution in this Paper:
Solution in this Paper:


 The Knights and Knaves benchmark generates logical puzzles where some characters always tell truth (knights) and others always lie (knaves).
The Knights and Knaves benchmark generates logical puzzles where some characters always tell truth (knights) and others always lie (knaves).











 We're releasing a preview of QwQ /kwju:/ — an open model designed to advance AI reasoning capabilities.
We're releasing a preview of QwQ /kwju:/ — an open model designed to advance AI reasoning capabilities.



 . The model doesn’t directly apply a simple counting method it goes letter by letter, analyzing each position as if it doesn’t trust itself to handle the word holistically. After reaching the correct count of 3, it goes back and double-checks every position of “r.”
. The model doesn’t directly apply a simple counting method it goes letter by letter, analyzing each position as if it doesn’t trust itself to handle the word holistically. After reaching the correct count of 3, it goes back and double-checks every position of “r.”



 , I’ll show you how to set up and use Qwq, including downloading the model and integrating it into VSCode.
, I’ll show you how to set up and use Qwq, including downloading the model and integrating it into VSCode.


 Qwen/QwQ-32B-Preview (full precision)
Qwen/QwQ-32B-Preview (full precision)



 the reasoning is too much fun
the reasoning is too much fun




 an experimental 32B model by the Qwen team that is competitive with o1-mini and o1-preview in some cases.
an experimental 32B model by the Qwen team that is competitive with o1-mini and o1-preview in some cases. 




 oh llama
oh llama