

Mistral unveils new AI models and chat features | TechCrunch
French AI startup Mistral has released a slew of updates to its product portfolio as it looks to remain competitive in the cutthroat AI space.
 techcrunch.com
techcrunch.com
Mistral unveils new AI models and chat features
Kyle Wiggers8:03 AM PST · November 18, 2024
French AI startup Mistral has released a slew of updates to its product portfolio as it looks to stay competitive in the cutthroat AI space.
Mistral’s Le Chat chatbot platform can now search the web — with citations in line, a la OpenAI’s ChatGPT. It’s also gained a “canvas” tool along the lines of ChatGPT Canvas, allowing users to modify, transform, or edit content, like webpage mockups and data visualizations, leveraging Mistral’s AI models.
“You can use [the canvas feature] to create documents, presentations, code, mockups… the list goes on,” Mistral writes in a blog post. “You’re able to modify its contents in place without regenerating responses, version your drafts, and preview your designs.”
In addition to all this, Le Chat can now process large PDF documents and images for analysis and summarization, including files containing graphs and equations. As of today, the platform incorporates Black Forest Labs‘ Flux Pro model for image generation. And Le Chat can now host shareable automated workflows for tasks like scanning expense reports and invoice processing; Mistal calls these AI “agents.”
Some of Le Chat’s new capabilities, all of which will remain free while in beta, are made possible by Mistral’s new models.
One, Pixtral Large, can process both text and images — it’s the second in Mistral’s Pixtral family of models. Weighing in at 124 billion parameters, Pixtral Large matches or bests leading models including Anthropic’s Claude 3.5 Sonnet, Google’s Gemini 1.5 Pro, and OpenAI’s GPT-4o on certain multimodal benchmarks. (Parameters roughly correspond to a model’s problem-solving skills, and models with more parameters generally perform better than those with fewer parameters.)
“Particularly, Pixtral Large is able to understand documents, charts, and natural images,” Mistral wrote in a second blog post. “The model demonstrates frontier-level image understanding.”
Mistral also today unveiled a new version of Mistral Large, its flagship line of text-only models. Called Mistral Large 24.11, the new model brings “notable improvements” in long context understanding, Mistral says, making it well-suited for use cases like document analysis and task automation.
Both Pixtral Large and Mistral Large 24.11 can be used outside of Le Chat under two licenses: a more restrictive license for research and an enterprise license for development and commercialization. Mistral Large 24.11 is already in Mistral’s API and on AI platform Hugging Face, and will soon be available through cloud platforms including Google Cloud and Microsoft Azure, Mistral says.
Paris-based Mistral, which recently raised $640 million in venture capital, continues to gradually expand its AI offerings. Over the past few months, the company has launched a free service for developers to test its models, an SDK to let customers fine-tune those models, and new models, including a generative model for code called Codestral.
Co-founded by alumni from Meta and DeepMind, Mistral’s stated mission is to create highly competitive models and services around those models — and ideally make money in the process. While the “making money” bit is proving to be challenging (as it is for most generative AI startups), Mistral reportedly began to generate revenue this summer.
“At Mistral, our approach to AI is different — we’re not chasing artificial general intelligence at all costs; our mission is to instead place frontier AI in your hands, so you get to decide what to do with advanced AI capabilities,” the company wrote in one of its blogs today. “This approach has allowed us to be quite frugal with our capital, while consistently delivering frontier capabilities at affordable price points.”

.%20Building%20on%20this%20momentum%2C%20Marco-o1%20not%20only%20focuses%20on%20disciplines%20with%20standard%20answers%2C%20such%20as%20mathematics%2C%20physics%2C%20and%20coding%20--%20which%20are%20well-suited%20for%20reinforcement%20learning%20(RL)%20--%20but%20also%20places%20greater%20emphasis%20on%20open-ended%20resolutions.%20We%20aim%20to%20address%20the%20question%3A%20Can%20the%20o1%20model%20effectively%20generalize%20to%20broader%20domains%20where%20clear%20standards%20are%20absent%20and%20rewards%20are%20challenging%20to%20quantify%3F%20Marco-o1%20is%20powered%20by%20Chain-of-Thought%20(CoT)%20fine-tuning%2C%20Monte%20Carlo%20Tree%20Search%20(MCTS)%2C%20reflection%20mechanisms%2C%20and%20innovative%20reasoning%20strategies%20--%20optimized%20for%20complex%20real-world%20problem-solving%20tasks.)
 MarcoPolo Team
MarcoPolo Team 




 Marco-o1 not only focuses on disciplines with standard answers, such as mathematics, physics, and coding—which are well-suited for reinforcement learning (RL)—but also places greater emphasis on open-ended resolutions. We aim to address the question: "Can the o1 model effectively generalize to broader domains where clear standards are absent and rewards are challenging to quantify?"
Marco-o1 not only focuses on disciplines with standard answers, such as mathematics, physics, and coding—which are well-suited for reinforcement learning (RL)—but also places greater emphasis on open-ended resolutions. We aim to address the question: "Can the o1 model effectively generalize to broader domains where clear standards are absent and rewards are challenging to quantify?" Limitations: We would like to emphasize that this research work is inspired by OpenAI's o1 (from which the name is also derived). This work aims to explore potential approaches to shed light on the currently unclear technical roadmap for large reasoning models. Besides, our focus is on open-ended questions, and we have observed interesting phenomena in multilingual applications. However, we must acknowledge that the current model primarily exhibits o1-like reasoning characteristics and its performance still fall short of a fully realized "o1" model. This is not a one-time effort, and we remain committed to continuous optimization and ongoing improvement.
Limitations: We would like to emphasize that this research work is inspired by OpenAI's o1 (from which the name is also derived). This work aims to explore potential approaches to shed light on the currently unclear technical roadmap for large reasoning models. Besides, our focus is on open-ended questions, and we have observed interesting phenomena in multilingual applications. However, we must acknowledge that the current model primarily exhibits o1-like reasoning characteristics and its performance still fall short of a fully realized "o1" model. This is not a one-time effort, and we remain committed to continuous optimization and ongoing improvement.
 Fine-Tuning with CoT Data: We develop Marco-o1-CoT by performing full-parameter fine-tuning on the base model using open-source CoT dataset combined with our self-developed synthetic data.
Fine-Tuning with CoT Data: We develop Marco-o1-CoT by performing full-parameter fine-tuning on the base model using open-source CoT dataset combined with our self-developed synthetic data. Marco-o1 leverages advanced techniques like CoT fine-tuning, MCTS, and Reasoning Action Strategies to enhance its reasoning power. As shown in Figure 2, by fine-tuning Qwen2-7B-Instruct with a combination of the filtered Open-O1 CoT dataset, Marco-o1 CoT dataset, and Marco-o1 Instruction dataset, Marco-o1 improved its handling of complex tasks. MCTS allows exploration of multiple reasoning paths using confidence scores derived from softmax-applied log probabilities of the top-k alternative tokens, guiding the model to optimal solutions. Moreover, our reasoning action strategy involves varying the granularity of actions within steps and mini-steps to optimize search efficiency and accuracy.
Marco-o1 leverages advanced techniques like CoT fine-tuning, MCTS, and Reasoning Action Strategies to enhance its reasoning power. As shown in Figure 2, by fine-tuning Qwen2-7B-Instruct with a combination of the filtered Open-O1 CoT dataset, Marco-o1 CoT dataset, and Marco-o1 Instruction dataset, Marco-o1 improved its handling of complex tasks. MCTS allows exploration of multiple reasoning paths using confidence scores derived from softmax-applied log probabilities of the top-k alternative tokens, guiding the model to optimal solutions. Moreover, our reasoning action strategy involves varying the granularity of actions within steps and mini-steps to optimize search efficiency and accuracy.
 on Figure 6: correct answer on the right should be 2 legos remaining, not 11!
on Figure 6: correct answer on the right should be 2 legos remaining, not 11!
 In contrast, here is the output from o1-preview:
In contrast, here is the output from o1-preview:


 :
: :
: :
: :
:
 The role of reflection mechanism in improving model performance
The role of reflection mechanism in improving model performance
 Marco-o1 introduces varying granularity in Monte Carlo Tree Search (MCTS) actions:
Marco-o1 introduces varying granularity in Monte Carlo Tree Search (MCTS) actions:

 New AI Model Gemini Experimental 1114 Debuts On Google AI Studio
New AI Model Gemini Experimental 1114 Debuts On Google AI Studio
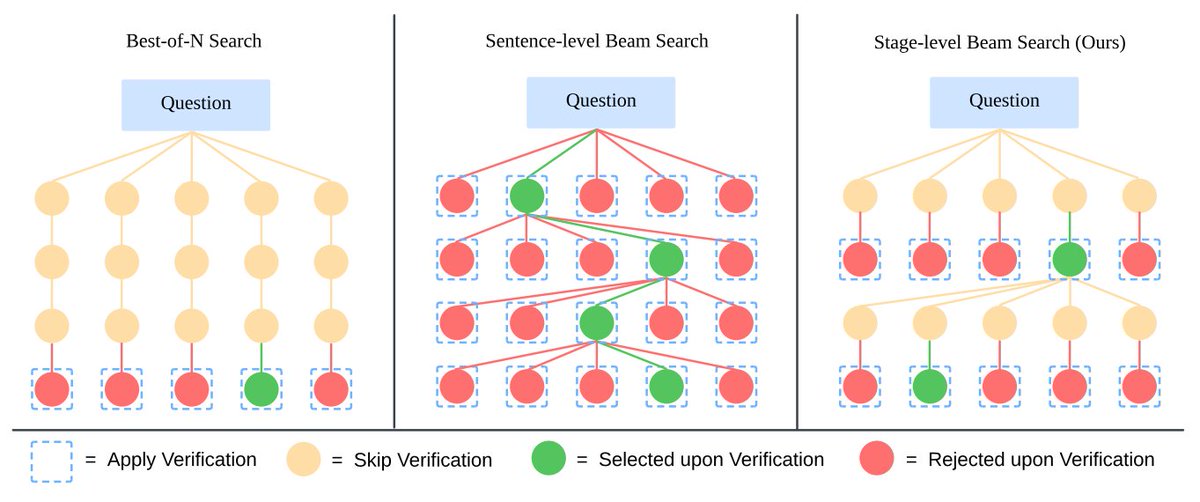
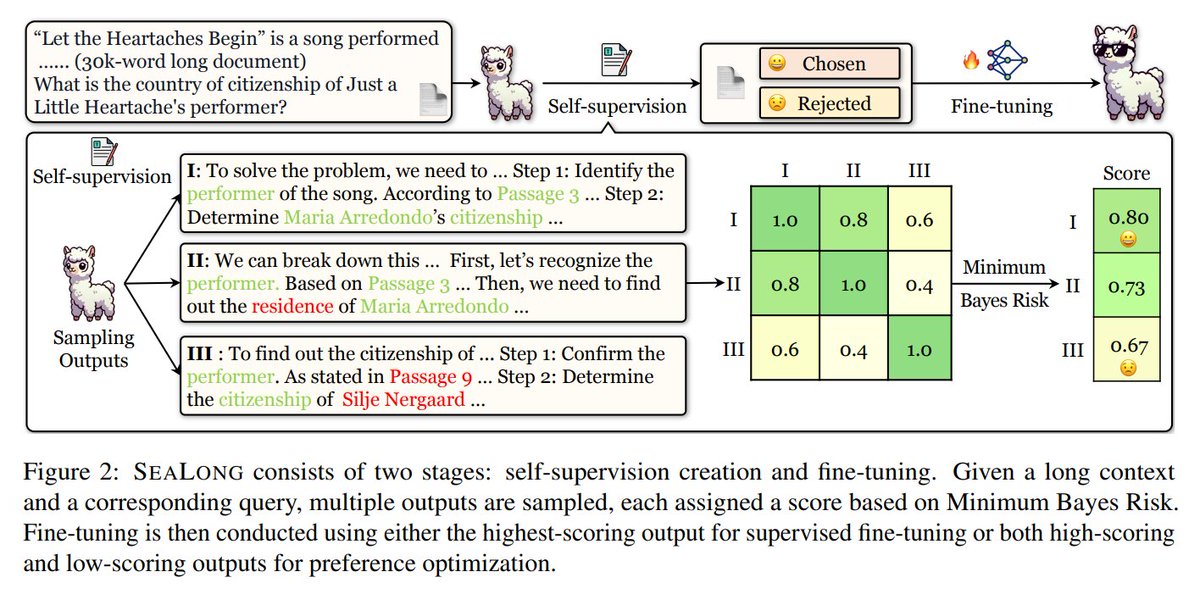
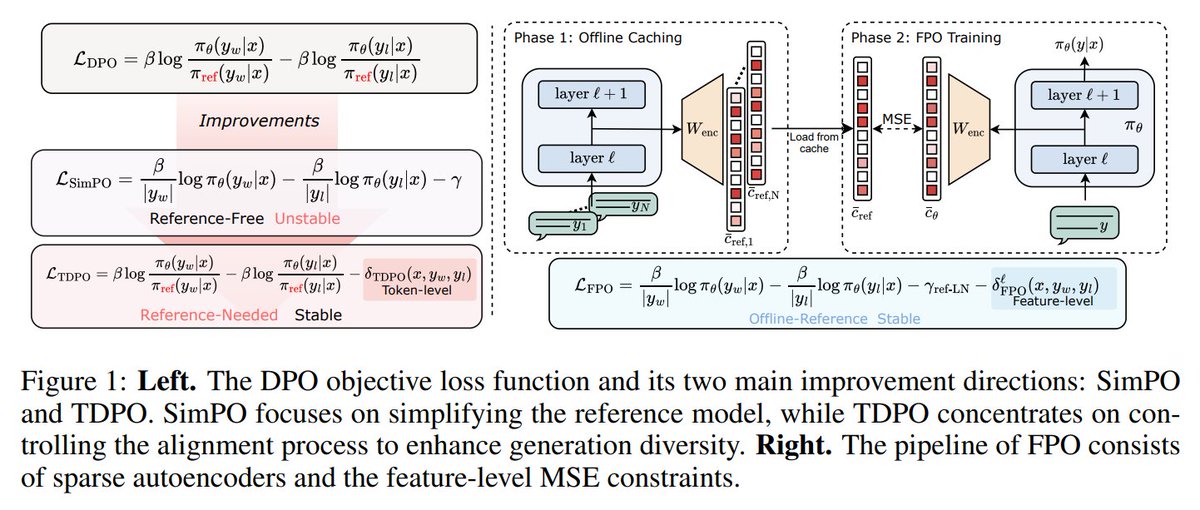
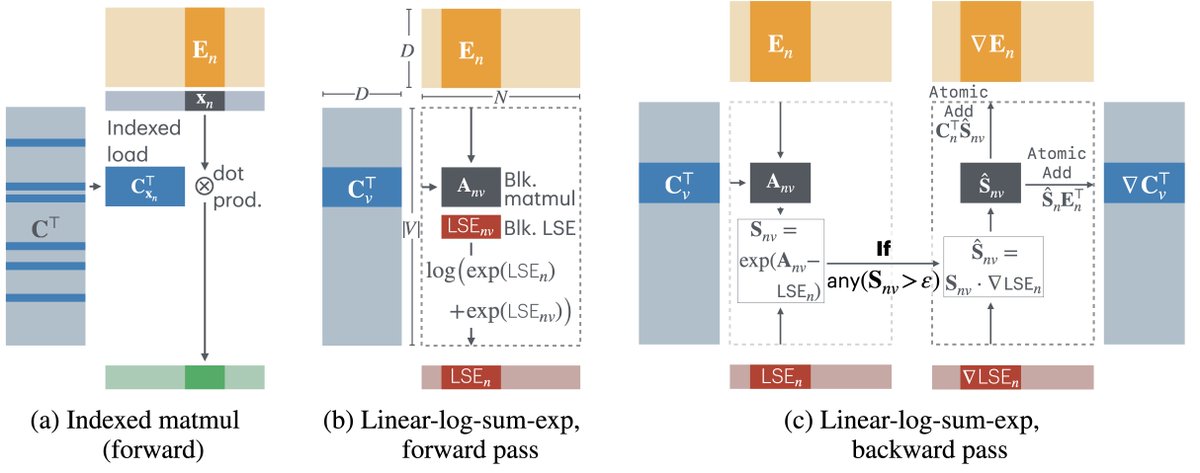
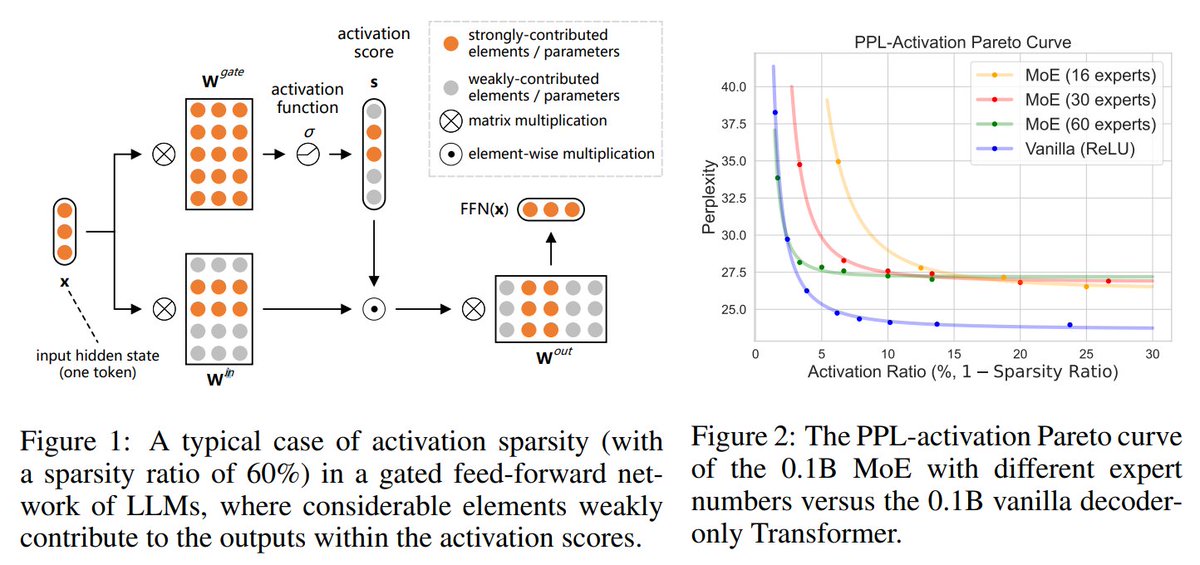
 #76: Rethinking Scaling Laws (when plateau is actually a fork)
#76: Rethinking Scaling Laws (when plateau is actually a fork)







 NVIDIA just unveiled Fugatto, a groundbreaking 2.5B parameter audio AI model that can generate and transform any combination of music, voices, and sounds using text prompts and audio inputs
NVIDIA just unveiled Fugatto, a groundbreaking 2.5B parameter audio AI model that can generate and transform any combination of music, voices, and sounds using text prompts and audio inputs Architecture
Architecture Real-world Applications
Real-world Applications



























