
1/11
@AnthropicAI
With styles, you can now customize how Claude responds.
Select from the new preset options: Concise, Explanatory, or Formal.
https://video.twimg.com/ext_tw_video/1861472528524337152/pu/vid/avc1/1920x1080/zvAWsXTu5K5R0A6N.mp4
2/11
@AnthropicAI
Want Claude to more closely match how you communicate?
Upload writing samples and Claude can automatically generate custom styles, just for you.
https://video.twimg.com/ext_tw_video/1861472551139934208/pu/vid/avc1/1920x1080/HHCgSB3ATOqAUssN.mp4
3/11
@testingcatalog
Finally someone released something to really improve writing
4/11
@KinggZoom
When will Claude get internet access and better rate limits?
5/11
@thegenioo
Anthropic takes it again OpenAI losing
6/11
@omarsar0
Curious how this works together with Projects? I find myself often using Projects for styled responses.
7/11
@novocrypto
Can there be a “prefer not to choose style” option that defaults to Claude as it is? That would be dope 🫡
8/11
@JohnForrester
rather than a menu selection, I think it is better for you to build a default personalization of user styles. Asking users for writing samples and remembering. btw, what is going on with your latency via the API? huge spike in Sonnet latency last 30 days.
9/11
@AGI_Odyssey
Fabulous!
10/11
@koltregaskes
Thank you again guys!
11/11
@alikayadibi11
Good job
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@AnthropicAI
With styles, you can now customize how Claude responds.
Select from the new preset options: Concise, Explanatory, or Formal.
https://video.twimg.com/ext_tw_video/1861472528524337152/pu/vid/avc1/1920x1080/zvAWsXTu5K5R0A6N.mp4
2/11
@AnthropicAI
Want Claude to more closely match how you communicate?
Upload writing samples and Claude can automatically generate custom styles, just for you.
https://video.twimg.com/ext_tw_video/1861472551139934208/pu/vid/avc1/1920x1080/HHCgSB3ATOqAUssN.mp4
3/11
@testingcatalog
Finally someone released something to really improve writing
4/11
@KinggZoom
When will Claude get internet access and better rate limits?
5/11
@thegenioo
Anthropic takes it again OpenAI losing
6/11
@omarsar0
Curious how this works together with Projects? I find myself often using Projects for styled responses.
7/11
@novocrypto
Can there be a “prefer not to choose style” option that defaults to Claude as it is? That would be dope 🫡
8/11
@JohnForrester
rather than a menu selection, I think it is better for you to build a default personalization of user styles. Asking users for writing samples and remembering. btw, what is going on with your latency via the API? huge spike in Sonnet latency last 30 days.
9/11
@AGI_Odyssey
Fabulous!
10/11
@koltregaskes
Thank you again guys!
11/11
@alikayadibi11
Good job
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
 Original Problem:
Original Problem: Solution in this Paper:
Solution in this Paper: Key Insights:
Key Insights: Results:
Results:




 Thomson Reuters integrates o1-mini model, into its CoCounsel, achieves 1400% user growth in legal AI
Thomson Reuters integrates o1-mini model, into its CoCounsel, achieves 1400% user growth in legal AI
 Key Considerations
Key Considerations



 :
: :
:
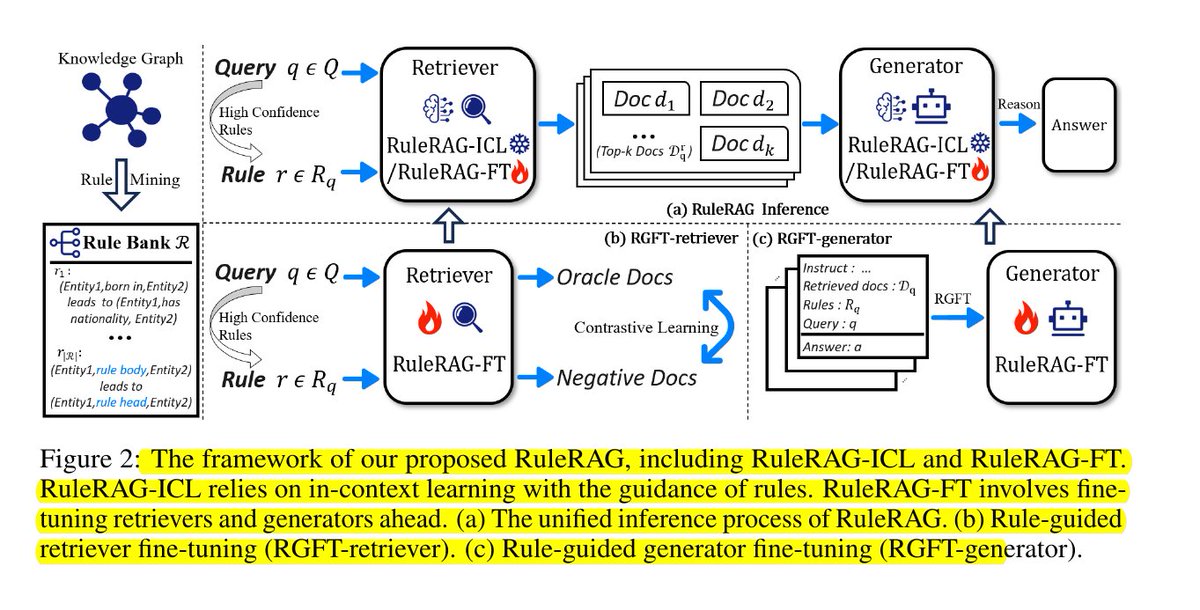
 NeKo's architecture
NeKo's architecture
 Solution in this Paper:
Solution in this Paper:





 Original Problem:
Original Problem:



