
1/11
@ZyphraAI
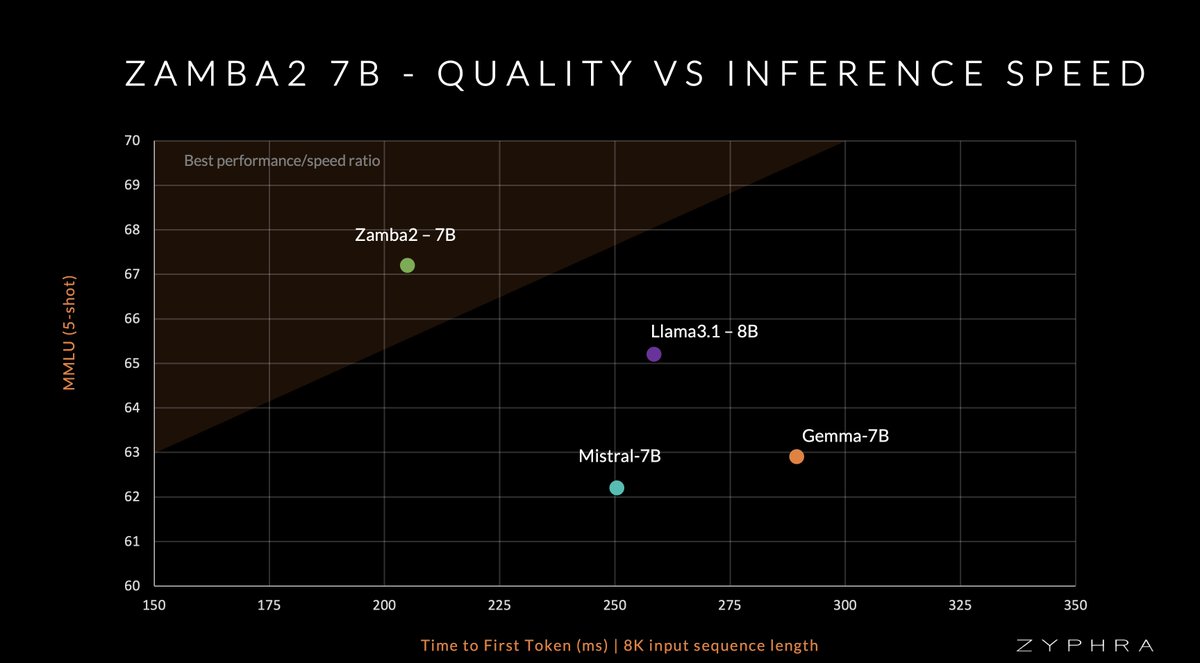
Today, in collaboration with @NvidiaAI, we bring you Zamba2-7B – a hybrid-SSM model that outperforms Mistral, Gemma, Llama3 & other leading models in both quality and speed.
Zamba2-7B is the leading model for ≤8B weight class.
 See more in the thread below
See more in the thread below
2/11
@ZyphraAI
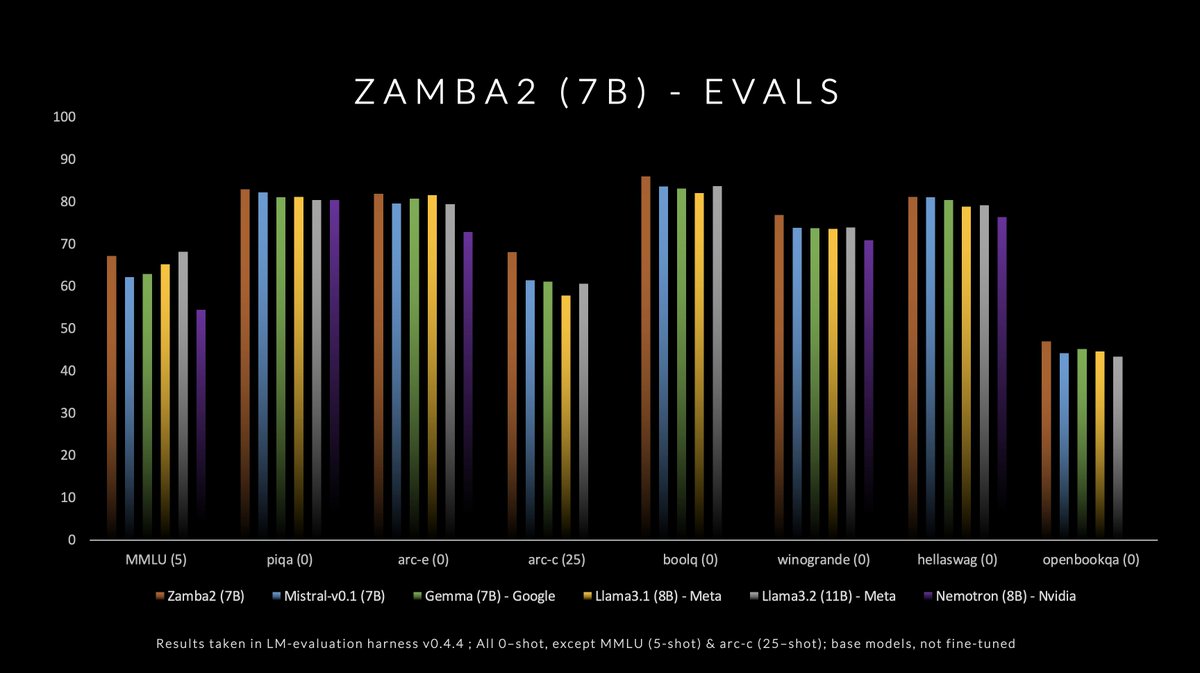
Beyond just MMLU, we perform strongly across all standard benchmarks, beating competing models in the ≤8B bracket. Zamba2 is released with open-weights under a permissive Apache 2.0 License. We’re excited to see what the open source community will build with this model.
3/11
@ZyphraAI
Read more (blog): Zyphra
Download the weights: Zyphra/Zamba2-7B · Hugging Face
Chat with the model: Zamba
NVIDIA’s NIM: zamba2-7b-instruct | NVIDIA NIM
4/11
@ZyphraAI
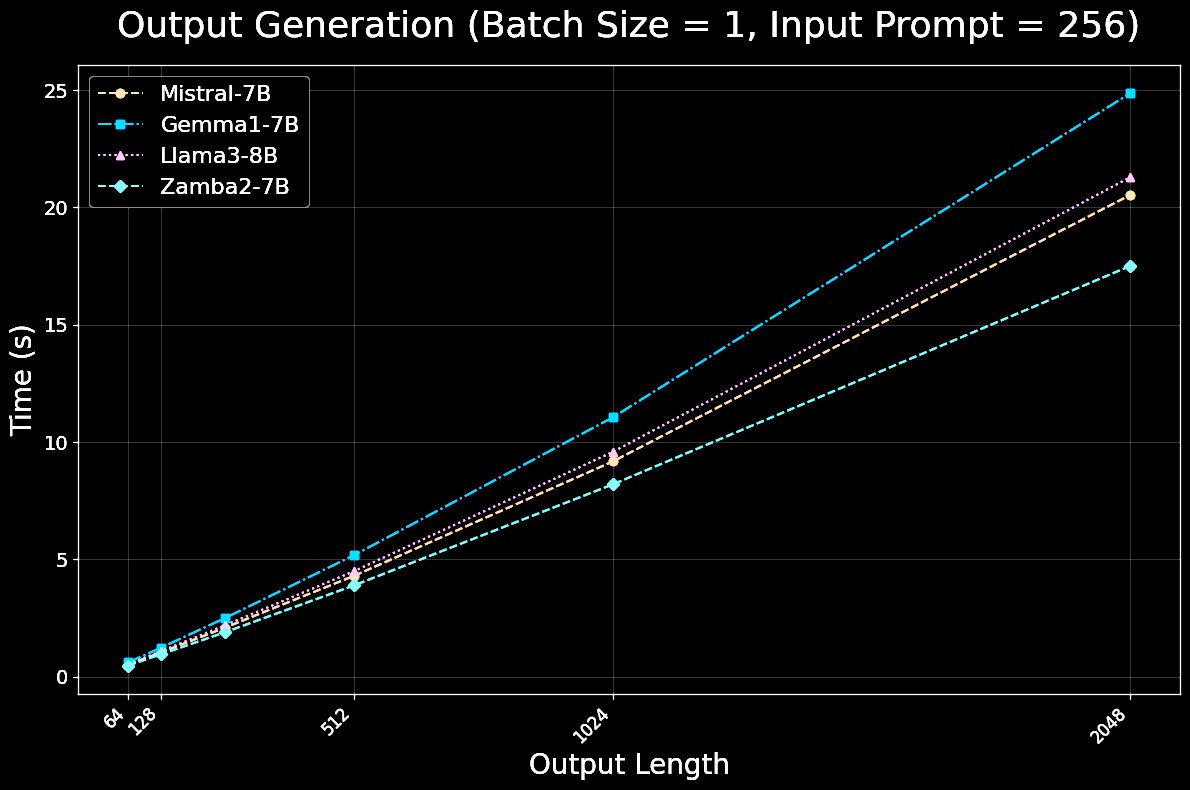
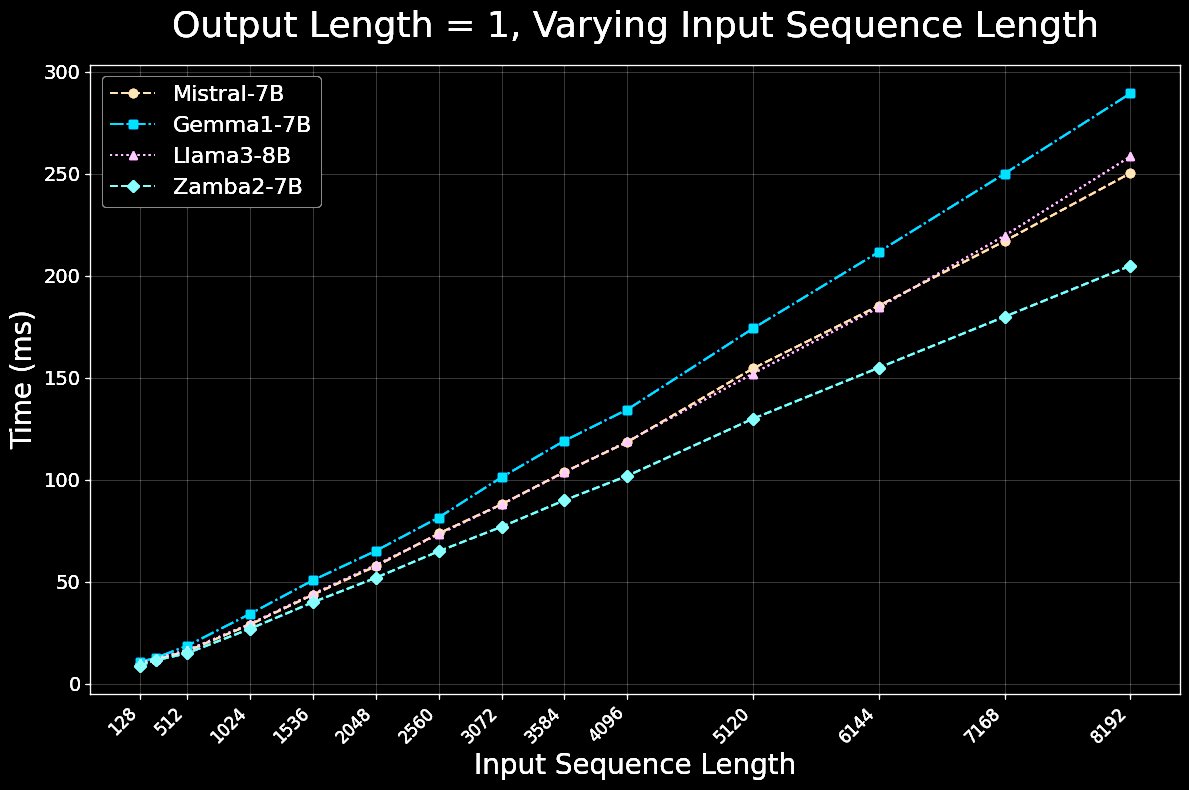
For inference, Zamba2-7B is both significantly faster and more memory efficient than competing transformer models. Zamba2-7B is ideal for on-device and consumer GPUs.
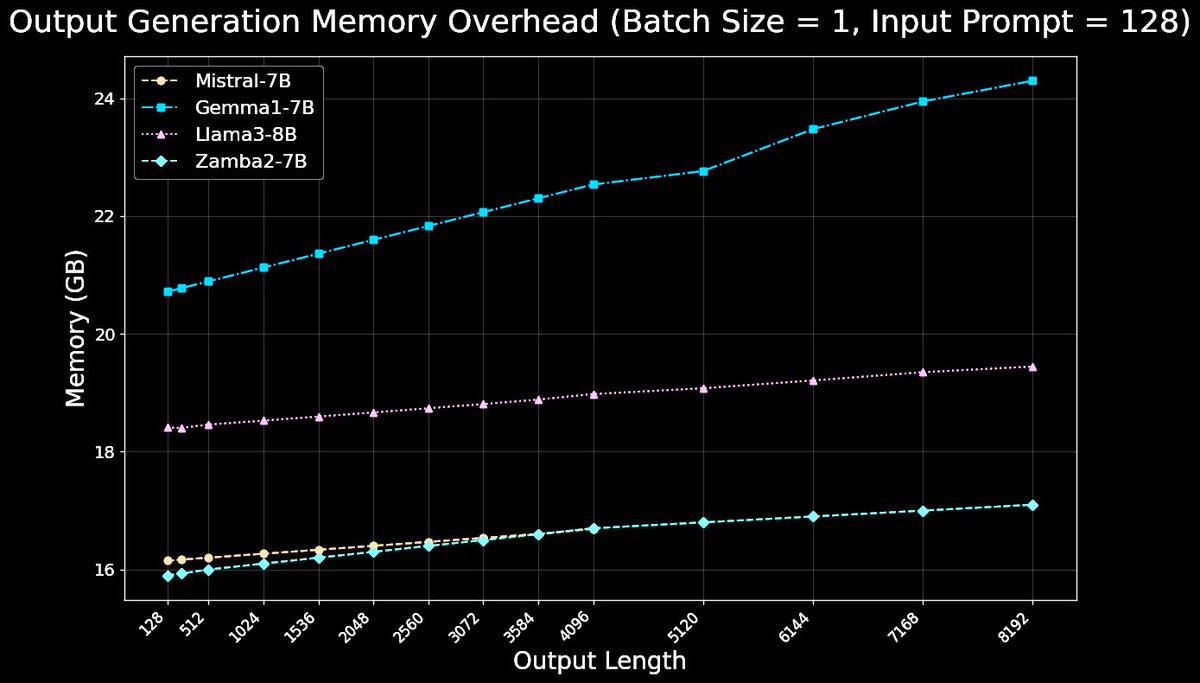
5/11
@ZyphraAI
Zamba2-7B leads in accuracy/efficiency per token because:
1. Sharing transformer blocks frees more params for Mamba2.
2. Some attention makes up for SSMs struggling with ICL and long-range deps.
3. A 5T dataset (Zyda2 release tomorrow)
4. Annealing over 100B high-quality tokens.
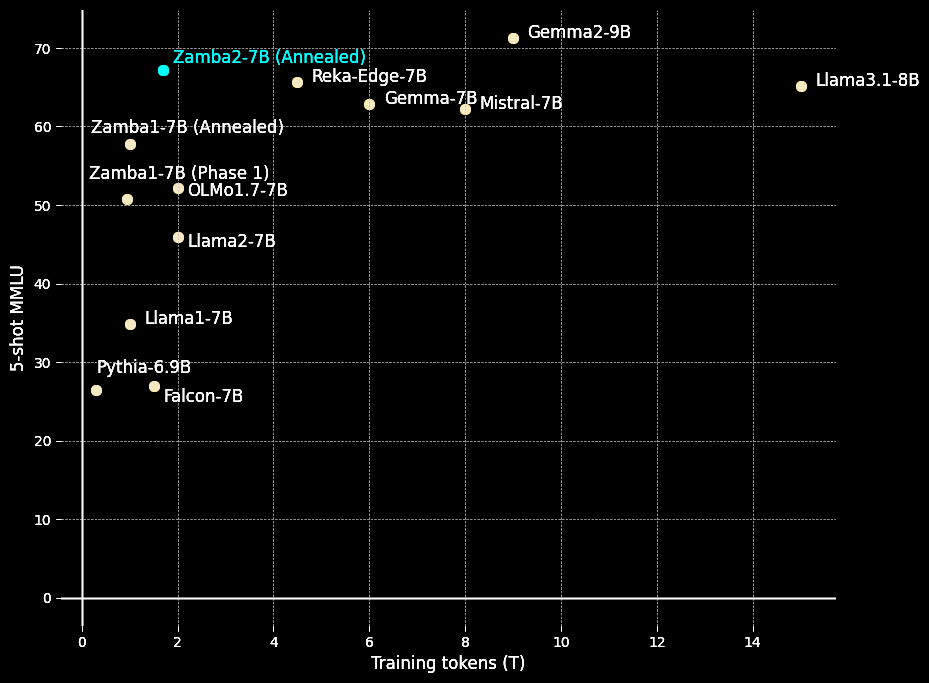
6/11
@ZyphraAI
We also release an instruct-tuned version of Zamba2-7B. This model strongly outperforms the corresponding instruct models of Mistral and Gemma, and is head-to-head with the Llama-3.1-8B Instruct model.
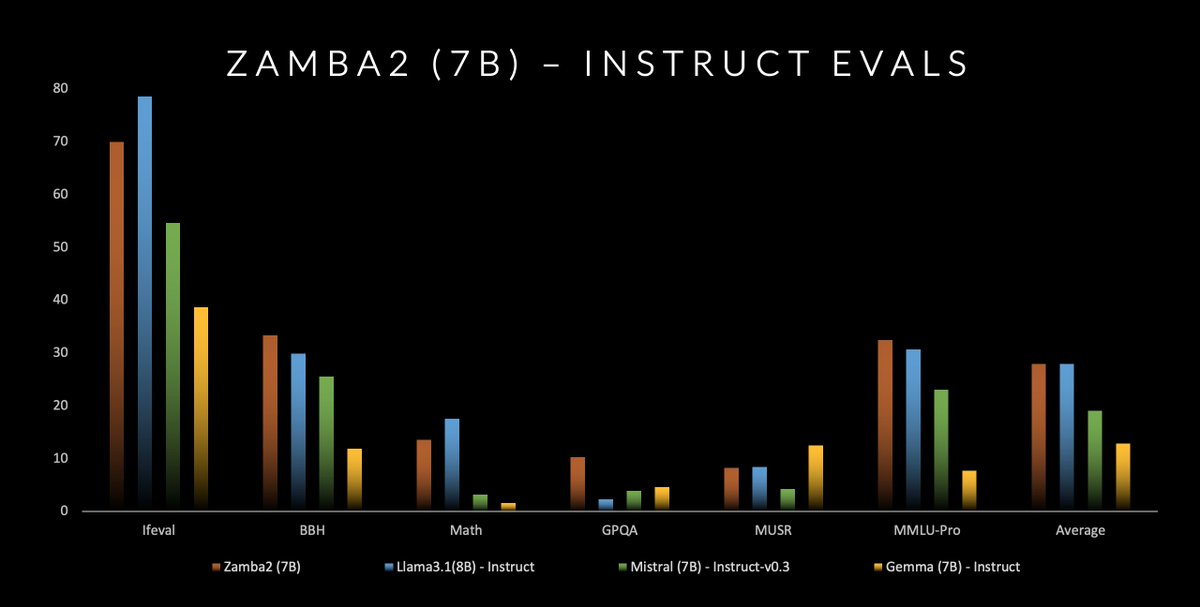
7/11
@ZyphraAI
Architectural improvements over Zamba-7B :
- Mamba1 → Mamba2 blocks
- Two shared attention blocks interleaved in an ABAB pattern throughout the network.
- A LoRA projector to each shared MLP, letting the model specialize across depth
- Rotary position embeddings
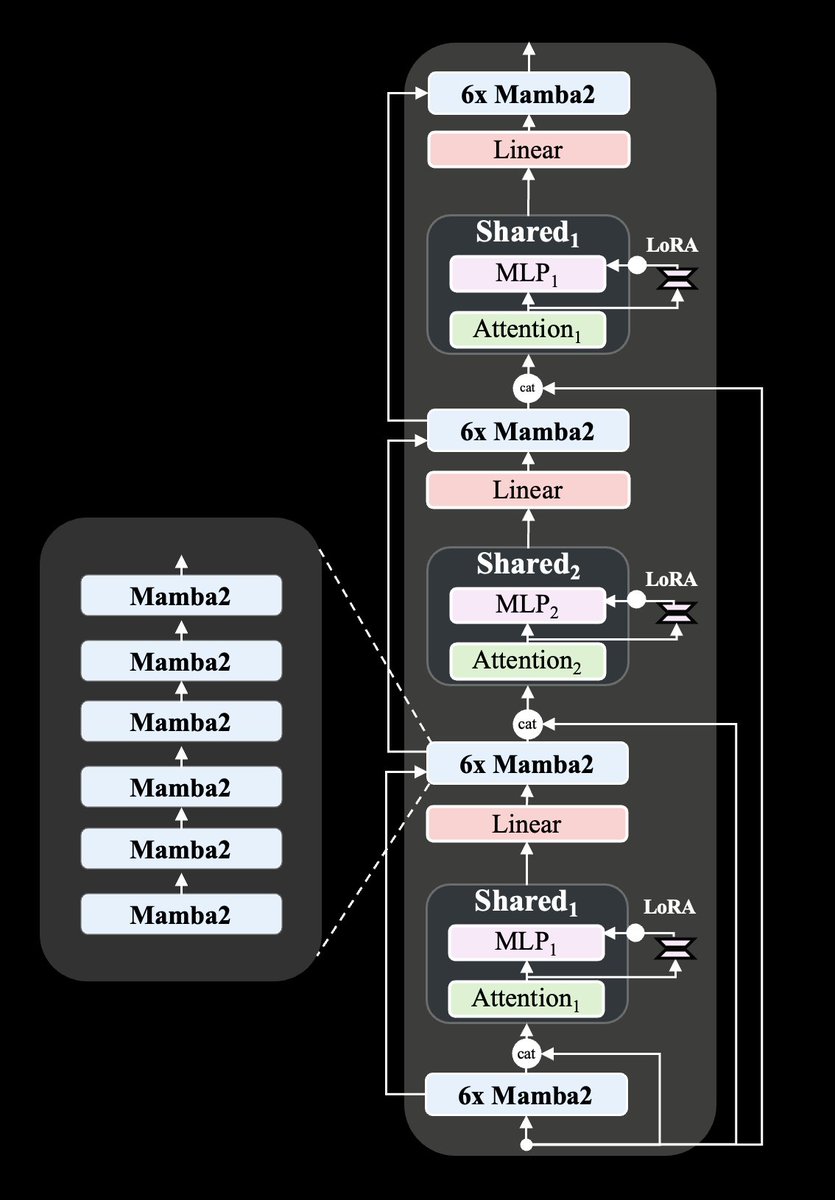
8/11
@ZyphraAI
@ZyphraAI is committed to democratizing advanced AI systems, exploring novel architectures, and advancing the scientific study and understanding of powerful models.
We look forward to collaborating with others who share our vision!
9/11
@SamuelMLSmith
Impressive results, but why are you comparing to Gemma-1 and not Gemma-2 (MMLU 71%)?
It would also be interesting to see an inference speed comparison with RecurrentGemma!
10/11
@ArdaTugsat
@ollama Are we getting this?
11/11
@FullyOnChain
@dominic_w @JanCamenisch
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@ZyphraAI
Today, in collaboration with @NvidiaAI, we bring you Zamba2-7B – a hybrid-SSM model that outperforms Mistral, Gemma, Llama3 & other leading models in both quality and speed.
Zamba2-7B is the leading model for ≤8B weight class.
See more in the thread below
2/11
@ZyphraAI
Beyond just MMLU, we perform strongly across all standard benchmarks, beating competing models in the ≤8B bracket. Zamba2 is released with open-weights under a permissive Apache 2.0 License. We’re excited to see what the open source community will build with this model.
3/11
@ZyphraAI
Read more (blog): Zyphra
Download the weights: Zyphra/Zamba2-7B · Hugging Face
Chat with the model: Zamba
NVIDIA’s NIM: zamba2-7b-instruct | NVIDIA NIM
4/11
@ZyphraAI
For inference, Zamba2-7B is both significantly faster and more memory efficient than competing transformer models. Zamba2-7B is ideal for on-device and consumer GPUs.
5/11
@ZyphraAI
Zamba2-7B leads in accuracy/efficiency per token because:
1. Sharing transformer blocks frees more params for Mamba2.
2. Some attention makes up for SSMs struggling with ICL and long-range deps.
3. A 5T dataset (Zyda2 release tomorrow)
4. Annealing over 100B high-quality tokens.
6/11
@ZyphraAI
We also release an instruct-tuned version of Zamba2-7B. This model strongly outperforms the corresponding instruct models of Mistral and Gemma, and is head-to-head with the Llama-3.1-8B Instruct model.
7/11
@ZyphraAI
Architectural improvements over Zamba-7B :
- Mamba1 → Mamba2 blocks
- Two shared attention blocks interleaved in an ABAB pattern throughout the network.
- A LoRA projector to each shared MLP, letting the model specialize across depth
- Rotary position embeddings
8/11
@ZyphraAI
@ZyphraAI is committed to democratizing advanced AI systems, exploring novel architectures, and advancing the scientific study and understanding of powerful models.
We look forward to collaborating with others who share our vision!
9/11
@SamuelMLSmith
Impressive results, but why are you comparing to Gemma-1 and not Gemma-2 (MMLU 71%)?
It would also be interesting to see an inference speed comparison with RecurrentGemma!
10/11
@ArdaTugsat
@ollama Are we getting this?
11/11
@FullyOnChain
@dominic_w @JanCamenisch
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196


















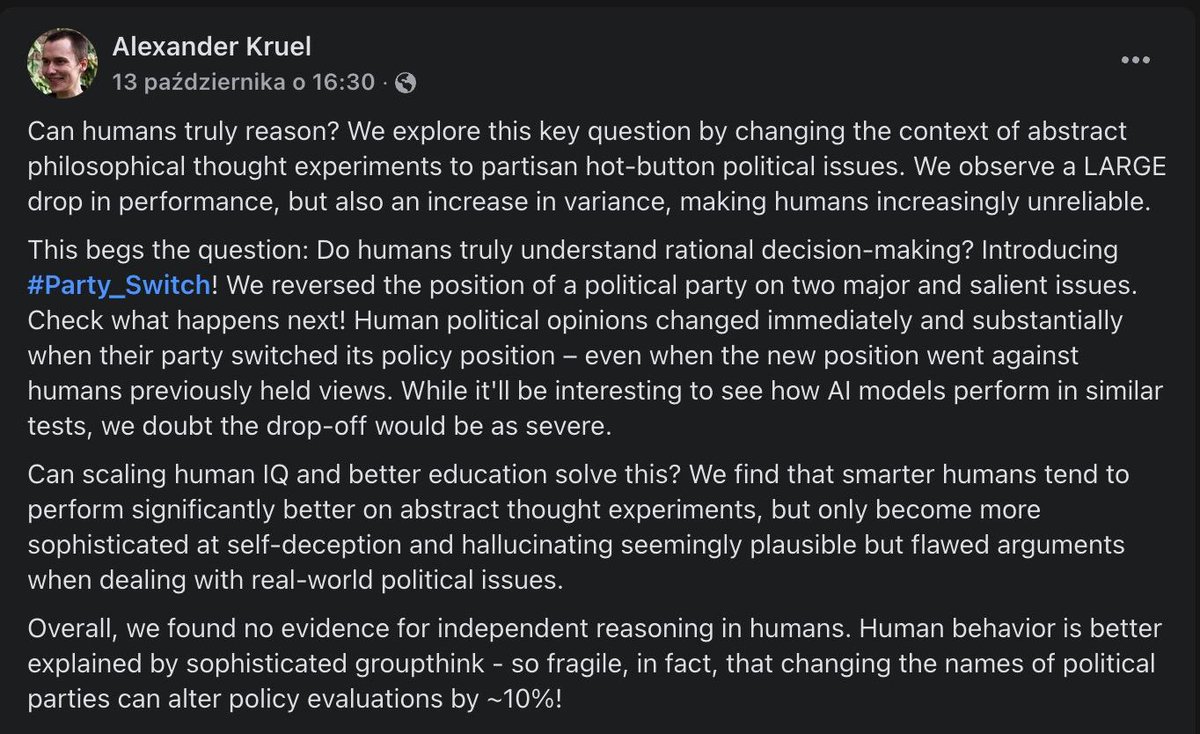


 'Experts' complain that AI "can't really" do this or that and that it just uses what it learns in its training data. It just predicts the most likely next token given the context. It hallucinates and comes up with wrong answers. Blah blah blah.
'Experts' complain that AI "can't really" do this or that and that it just uses what it learns in its training data. It just predicts the most likely next token given the context. It hallucinates and comes up with wrong answers. Blah blah blah. 








 New work: Thinking LLMs!
New work: Thinking LLMs! 1/4
1/4
 - no need for human data!
- no need for human data!

 3rd on AlpacaEval leaderboard
3rd on AlpacaEval leaderboard Best 8B model on ArenaHard
Best 8B model on ArenaHard







 and global
and global  preferences.
preferences.



 and global
and global  harms.
harms. outperforms mixing
outperforms mixing  data.
data.

 , we expand toxicity mitigation across multiple languages.
, we expand toxicity mitigation across multiple languages.
 Why don't mitigation techniques account for this?
Why don't mitigation techniques account for this?





