1/15
@ai_for_success
OpenAI o1-preview and o1-mini best coding examples that I’ve come across, and they’re really impressive.

2/15
@ai_for_success
[Quoted tweet]
Making progress on o1-mini-engineer.

Now it can create complex folder and file structures in one shot. Will release as a repo soon.
Watch it create a Windows OS replica as a Flask app.
Also, definitely use o1-mini, don't use Preview for everyday coding tasks.
https://video.twimg.com/ext_tw_video/1834733646516801536/pu/vid/avc1/1658x1080/fTIGPzO_IbrrZeFt.mp4
3/15
@ai_for_success
[Quoted tweet]
A fun test I like to do with new LLMs is have them write the complete code for a Factorio style automation game prototype in pygame.
I read that coding isn’t really what o1-preview excels at so I was thoroughly surprised that within 8 prompts I got this very robust and expandable prototype. This is something I would’ve struggled to accomplish previously using GPT4 in general, let alone in such a short timespan.
I made absolutely 0 changes to the code myself, every single line is 100% generated by the model except of course the assets which I quickly whipped up in paint.
So yeah, very impressed over here.
reddit.com/r/OpenAI/comments…
https://video.twimg.com/ext_tw_video/1834864080647340036/pu/vid/avc1/1280x720/E3YaEw_0bgnaumF1.mp4
4/15
@ai_for_success
[Quoted tweet]
Tutorial: Create Art with ChatGPT o1 and Illustrator Scripts
No coding experience needed! I’ll walk you through my creative coding process, where I used OpenAI o1 scripts to make a simple, popular fractal: the Sierpinski Triangle.
Illustrator uses JavaScript to create art with code. The key is iteration. My first attempt didn’t give the expected result, but through trial and error, I got it right. Watch my short video to see how.
Steps:
Verify if the output is accurate.
Share what's off—like I did when OpenAI o1's result was wrong, and I debugged it.
Keep iterating until it works!
After making the fractal, I used Illustrator's 3D tools to add depth and turned it into a neon sign using Adobe Firefly.
As a former backend coder of 10 years, this AI-driven process is refreshingly different, and I’m loving it! Feel free to ask me anything!
https://video.twimg.com/ext_tw_video/1834389344477401088/pu/vid/avc1/1920x1080/9sTjfV3hIiLyZxqK.mp4
5/15
@ai_for_success
[Quoted tweet]
A very primordial coding agent built with o1.
o1 API doesn't support function calling or system prompts.
You can simulate these features by adding a pre-prompt that forces the model to output responses in JSON.
Then use a parser to generate coding files from the response.
 https://video.twimg.com/ext_tw_video/1834393194873712640/pu/vid/avc1/1920x1080/pGpmPwGm0TX7NJqb.mp4
https://video.twimg.com/ext_tw_video/1834393194873712640/pu/vid/avc1/1920x1080/pGpmPwGm0TX7NJqb.mp4
6/15
@ai_for_success
[Quoted tweet]
Just combined @OpenAI o1 and Cursor Composer to create an iOS app in under 10 mins!
o1 mini kicks off the project (o1 was taking too long to think), then switch to o1 to finish off the details.
And boom—full Weather app for iOS with animations, in under 10

Video sped up!
https://video.twimg.com/ext_tw_video/1834347696351506433/pu/vid/avc1/1670x1080/IbiRyYlBrlsnOFse.mp4
7/15
@ai_for_success
[Quoted tweet]
Just used @OpenAI o1 to create a 3D version of Snake in under a minute!

One-shot prompt, straight into @Replit, and run.
https://video.twimg.com/ext_tw_video/1834312091794087936/pu/vid/avc1/1920x1080/TAkw4LgdJQbMsjKj.mp4
8/15
@ai_for_success
[Quoted tweet]
o1-mini is blowing my mind. Watch as o1 saves me hours of time on a complex coding update, and does a nice little refactor as a bonus.
The world is changing before our eyes and I'm loving it.
cc @gdb @swyx @emollick @mckaywrigley @_jasonwei
https://video.twimg.com/ext_tw_video/1834620058779443200/pu/vid/avc1/1862x1080/qLMHModRIvr0-Cua.mp4
9/15
@ai_for_success
[Quoted tweet]
o1-mini is blowing my mind. Watch as o1 saves me hours of time on a complex coding update, and does a nice little refactor as a bonus.
The world is changing before our eyes and I'm loving it.
cc @gdb @swyx @emollick @mckaywrigley @_jasonwei
https://video.twimg.com/ext_tw_video/1834620058779443200/pu/vid/avc1/1862x1080/qLMHModRIvr0-Cua.mp4
10/15
@ai_for_success
[Quoted tweet]
OpenAI o1 creates a fully interactive space shooter game in less than 2 minutes and Replit lets me run it in seconds.
AI and coding has changed forever.
https://video.twimg.com/ext_tw_video/1834418626708774912/pu/vid/avc1/1434x720/dDV52U9f1Ws9J_cG.mp4
11/15
@ai_for_success
[Quoted tweet]
This is madness...
OpenAI o1 model builds a fully functional "chess game" that allows me to compete against an AI-based opponent.
o1-preview is the real deal.
https://video.twimg.com/ext_tw_video/1835684469346340864/pu/vid/avc1/1280x720/2APhiiXEQHJAwph4.mp4
12/15
@ai_for_success
[Quoted tweet]
Introducing o1 web crawler

It crawls entire websites with OpenAI’s new o1 reasoning model and @firecrawl_dev .
Just state an objective and it will navigate + return the requested data in a JSON schema.
Check it out:
https://video.twimg.com/ext_tw_video/1835774638166585345/pu/vid/avc1/930x720/bhglpVFnzCBYkT-s.mp4
13/15
@ai_for_success
[Quoted tweet]
Yesterday I wanted to test @OpenAI's new o1 model out so I took a stab at creating a Mario-esque platformer using some @unofficialmfers pixel assets I made a while back.
I'm impressed with the model's speed and capability to problem solve while writing long sections of code. I have no experience with other models, but I can say it's much better than 4o.
4 hours from beginning to end and much of that was spent hastily making assets and getting the model to design the level, which was tougher than you'd think...still needs work and probably a way to make it manually tbh, but maybe we figure that out too.
Will see how it does in the next few days, but generally impressed how far I was able to get in a morning. Just a hobby project, but I'm going to continue to make assets and maybe change themes and gameplay, so it turns into a bit of its own thing.
Let you all know where I am in a few days to a week.
https://video.twimg.com/ext_tw_video/1836313513574182912/pu/vid/avc1/818x720/Srkb1bgciC6n2j4B.mp4
14/15
@ai_for_success
[Quoted tweet]
When I first taught myself how to code, the first real project I built was a side-scroller game for an NFT project (left video)
With OpenAI o1, I recreated the entire front-end in one prompt and no coding (right video)
If you have an old side project, I highly recommend prompting o1 to recreate it.
Watching the model code something you originally built by hand, in minutes, feels surreal.
It might take some tinkering with the prompts, but that's the point. Prompting o1 is a completely different experience compared to using GPT-4.
It's never been easier to code your own app. I can't wait to see what the next generation of builders create with tools like o1.
https://video.twimg.com/ext_tw_video/1835360419050852352/pu/vid/avc1/1066x720/HFRq_AsyP7s1ONcY.mp4
15/15
@ai_for_success
[Quoted tweet]
o1 is really good at making fun small games! for example, i made AISteroid Game w/ retro scifi vibes
 https://video.twimg.com/ext_tw_video/1834280665275342848/pu/vid/avc1/1472x720/sQcdz_XD-hBd7xNd.mp4
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
https://video.twimg.com/ext_tw_video/1834280665275342848/pu/vid/avc1/1472x720/sQcdz_XD-hBd7xNd.mp4
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

 :
: :
: :
:
 :
:

 :
: :
:

 :
:


 Input: Agents receive competition details (description, dataset, leaderboard).
Input: Agents receive competition details (description, dataset, leaderboard). Process: Agents develop ML solutions (train models, debug, create submissions).
Process: Agents develop ML solutions (train models, debug, create submissions). Output: Agents submit a CSV file with predictions.
Output: Agents submit a CSV file with predictions. Evaluation: A grader scores the submission locally.
Evaluation: A grader scores the submission locally. Comparison: Agent performance is benchmarked against human Kaggle competitors using real competition leaderboards.
Comparison: Agent performance is benchmarked against human Kaggle competitors using real competition leaderboards.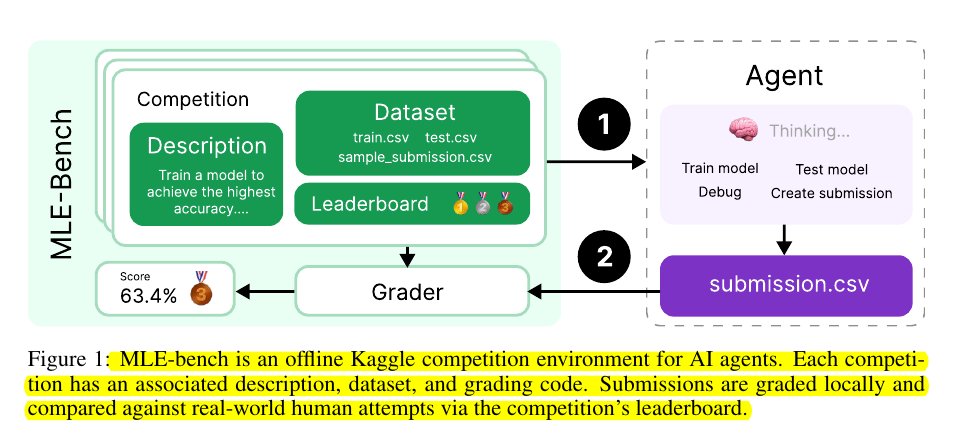






















 Model from @OpenAI works, this paper from May,2023 is a good start.
Model from @OpenAI works, this paper from May,2023 is a good start.  To train more reliable models, we can turn either to outcome supervision, which provides feedback for a final result, or process supervision, which provides feedback for each intermediate reasoning step.
To train more reliable models, we can turn either to outcome supervision, which provides feedback for a final result, or process supervision, which provides feedback for each intermediate reasoning step. :
:
