1/11
@reach_vb
Let's goo! F5-TTS
> Trained on 100K hours of data
> Zero-shot voice cloning
> Speed control (based on total duration)
> Emotion based synthesis
> Long-form synthesis
> Supports code-switching
> Best part: CC-BY license (commercially permissive)
Diffusion based architecture:
> Non-Autoregressive + Flow Matching with DiT
> Uses ConvNeXt to refine text representation, alignment
Synthesised: I was, like, talking to my friend, and she’s all, um, excited about her, uh, trip to Europe, and I’m just, like, so jealous, right? (Happy emotion)
The TTS scene is on fire!
https://video.twimg.com/ext_tw_video/1845154255683919887/pu/vid/avc1/480x300/mzGDLl_iiw5TUzGg.mp4
2/11
@reach_vb
Check out the open model weights here:
SWivid/F5-TTS · Hugging Face
3/11
@reach_vb
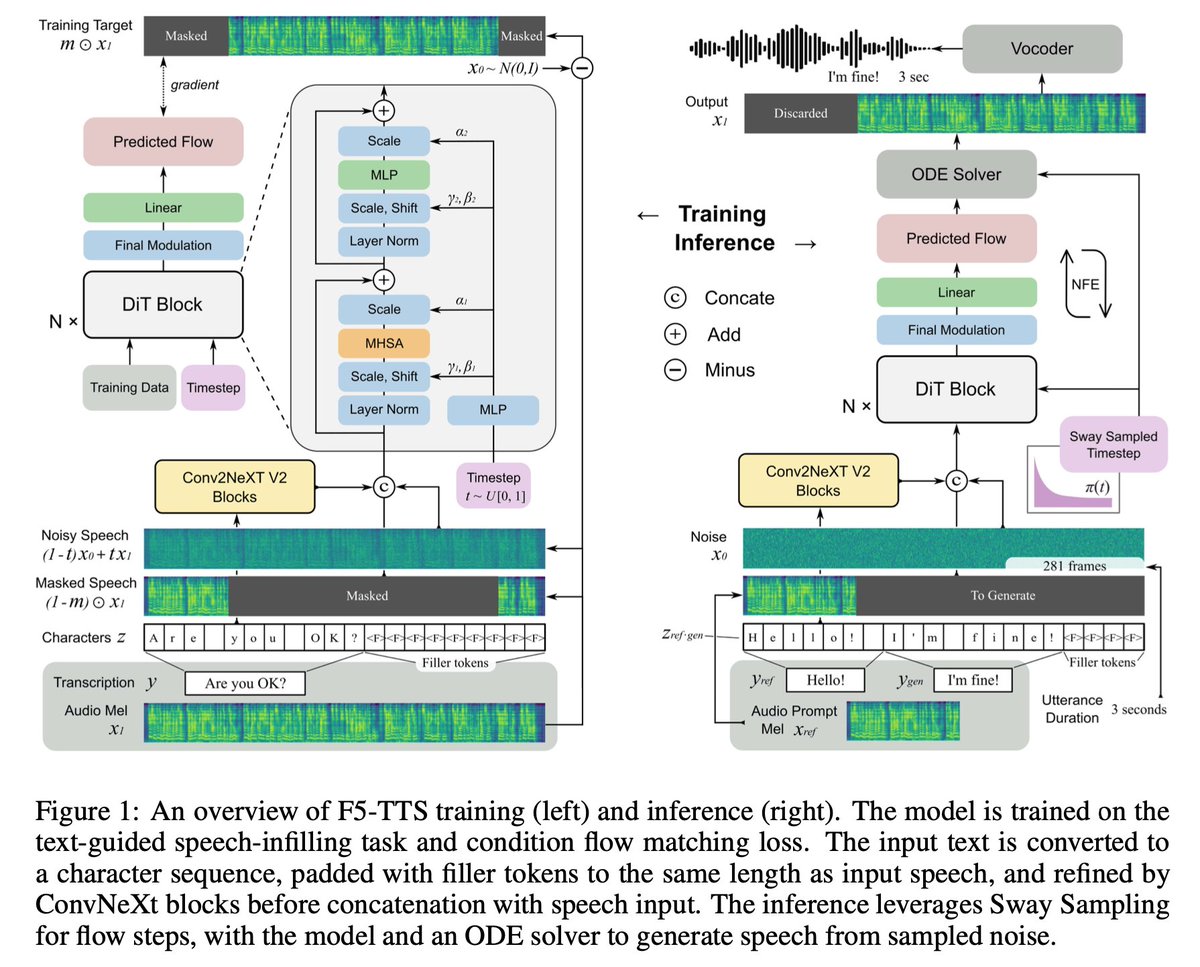
Overall architecture:
4/11
@reach_vb
Also, @realmrfakename made a dope space to play with the model:
E2/F5 TTS - a Hugging Face Space by mrfakename
5/11
@reach_vb
Some notes on the model:
1. Non-Autoregressive Design: Uses filler tokens to match text and speech lengths, eliminating complex models like duration and text encoders.
2. Flow Matching with DiT: Employs flow matching with a Diffusion Transformer (DiT) for denoising and speech generation.
3. ConvNeXt for Text: used to refine text representation, enhancing alignment with speech.
4. Sway Sampling: Introduces an inference-time Sway Sampling strategy to boost performance and efficiency, applicable without retraining.
5. Fast Inference: Achieves an inference Real-Time Factor (RTF) of 0.15, faster than state-of-the-art diffusion-based TTS models.
6. Multilingual Zero-Shot: Trained on a 100K hours multilingual dataset, demonstrates natural, expressive zero-shot speech, seamless code-switching, and efficient speed control.
6/11
@TommyFalkowski
This model is pretty good indeed! I haven't tried long form generation yet though but am really excited to have a model that could replace the online edge tts I'm currently using.
[Quoted tweet]
I think we might finally have an elevenlabs level text-to-speech model at home! I got the demo to run on a machine with a 3070 with 8GB of vram!
https://video.twimg.com/ext_tw_video/1844477815166500885/pu/vid/avc1/1108x720/ULTpniql5_9M761K.mp4
7/11
@realkieranlewis
can this be ran on replicate etc? any indication on cost vs ElevenLabs?
8/11
@j6sp5r
nice
Wen in open NotebookLM
9/11
@lalopenguin
it sounds great!!
10/11
@BhanuKonepalli
This one's a game changer !!
11/11
@modeless
Ooh, this looks really great!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@reach_vb
Let's goo! F5-TTS
> Trained on 100K hours of data
> Zero-shot voice cloning
> Speed control (based on total duration)
> Emotion based synthesis
> Long-form synthesis
> Supports code-switching
> Best part: CC-BY license (commercially permissive)
Diffusion based architecture:
> Non-Autoregressive + Flow Matching with DiT
> Uses ConvNeXt to refine text representation, alignment
Synthesised: I was, like, talking to my friend, and she’s all, um, excited about her, uh, trip to Europe, and I’m just, like, so jealous, right? (Happy emotion)
The TTS scene is on fire!
https://video.twimg.com/ext_tw_video/1845154255683919887/pu/vid/avc1/480x300/mzGDLl_iiw5TUzGg.mp4
2/11
@reach_vb
Check out the open model weights here:
SWivid/F5-TTS · Hugging Face
3/11
@reach_vb
Overall architecture:
4/11
@reach_vb
Also, @realmrfakename made a dope space to play with the model:
E2/F5 TTS - a Hugging Face Space by mrfakename
5/11
@reach_vb
Some notes on the model:
1. Non-Autoregressive Design: Uses filler tokens to match text and speech lengths, eliminating complex models like duration and text encoders.
2. Flow Matching with DiT: Employs flow matching with a Diffusion Transformer (DiT) for denoising and speech generation.
3. ConvNeXt for Text: used to refine text representation, enhancing alignment with speech.
4. Sway Sampling: Introduces an inference-time Sway Sampling strategy to boost performance and efficiency, applicable without retraining.
5. Fast Inference: Achieves an inference Real-Time Factor (RTF) of 0.15, faster than state-of-the-art diffusion-based TTS models.
6. Multilingual Zero-Shot: Trained on a 100K hours multilingual dataset, demonstrates natural, expressive zero-shot speech, seamless code-switching, and efficient speed control.
6/11
@TommyFalkowski
This model is pretty good indeed! I haven't tried long form generation yet though but am really excited to have a model that could replace the online edge tts I'm currently using.
[Quoted tweet]
I think we might finally have an elevenlabs level text-to-speech model at home! I got the demo to run on a machine with a 3070 with 8GB of vram!
https://video.twimg.com/ext_tw_video/1844477815166500885/pu/vid/avc1/1108x720/ULTpniql5_9M761K.mp4
7/11
@realkieranlewis
can this be ran on replicate etc? any indication on cost vs ElevenLabs?
8/11
@j6sp5r
nice
Wen in open NotebookLM
9/11
@lalopenguin
it sounds great!!
10/11
@BhanuKonepalli
This one's a game changer !!
11/11
@modeless
Ooh, this looks really great!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
 🫣
🫣 - change is the only constant!
- change is the only constant! @rhymes_ai_ released Aria - Multimodal MoE (3.9B active), 64K tokens, caption 256 frames in 10 sec, Apache 2.0 licensed! Beats GPT4o & Gemini Flash
@rhymes_ai_ released Aria - Multimodal MoE (3.9B active), 64K tokens, caption 256 frames in 10 sec, Apache 2.0 licensed! Beats GPT4o & Gemini Flash 










 /search?q=#OpenSourceAGI
/search?q=#OpenSourceAGI



 Can Generate 10-second videos at 768p/24FPS
Can Generate 10-second videos at 768p/24FPS 2B parameter single unified Diffusion Transformer (DiT)
2B parameter single unified Diffusion Transformer (DiT) Supports both text-to-video AND image-to-video
Supports both text-to-video AND image-to-video Uses Flow Matching for efficient training
Uses Flow Matching for efficient training Two model variants: 384p (5s) and 768p (10s)
Two model variants: 384p (5s) and 768p (10s) example videos on project page
example videos on project page Simple two-step implementation process
Simple two-step implementation process MIT License and available on @huggingface
MIT License and available on @huggingface Trained only on open-source datasets
Trained only on open-source datasets Training code coming soon!
Training code coming soon!

 page: pyramid-flow.github.io/
page: pyramid-flow.github.io/ paper: arxiv.org/abs/2410.05954
paper: arxiv.org/abs/2410.05954 code: github.com/jy0205/Pyramid-Fl…
code: github.com/jy0205/Pyramid-Fl… runpod-t2v: github.com/camenduru/pyramid…
runpod-t2v: github.com/camenduru/pyramid… tost: please try it
tost: please try it  tost.ai
tost.ai
 The
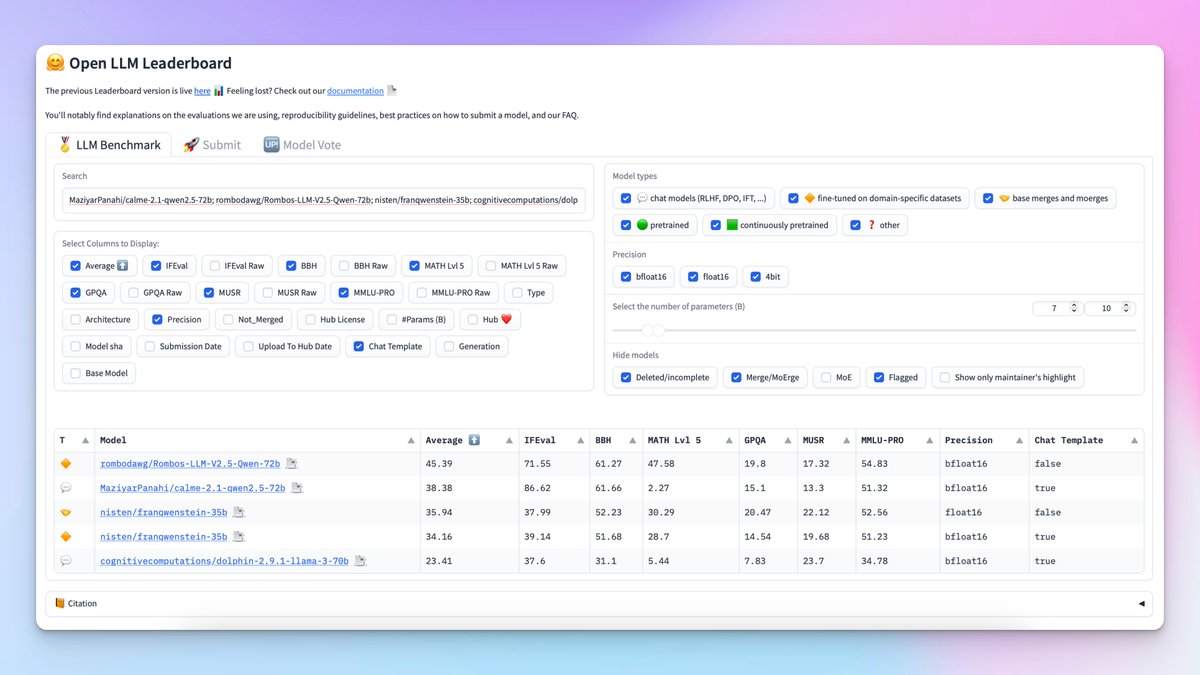
The  Last week, 139 new models joined the Leaderboard
Last week, 139 new models joined the Leaderboard
 Maintainer's Highlight Top 20 Rank Change
Maintainer's Highlight Top 20 Rank Change
 Top 3 models by average score last week
Top 3 models by average score last week First place: rombodawg/Rombos-LLM-V2.5-Qwen-72b (45.39 avg)
First place: rombodawg/Rombos-LLM-V2.5-Qwen-72b (45.39 avg) Second place: MaziyarPanahi/calme-2.1-qwen2.5-72b (38.38 avg)
Second place: MaziyarPanahi/calme-2.1-qwen2.5-72b (38.38 avg) Third place: ssmits/Qwen2.5-95B-Instruct (37.43 avg)
Third place: ssmits/Qwen2.5-95B-Instruct (37.43 avg)

 Benchmarks top performers
Benchmarks top performers

 Open LLM Leaderboard:
Open LLM Leaderboard:  Define Agents, each with its own instructions, role (e.g., "Sales Agent"), and available functions (will be converted to JSON structures).
Define Agents, each with its own instructions, role (e.g., "Sales Agent"), and available functions (will be converted to JSON structures).  Define logic for transferring control to another agent based on conversation flow or specific criteria within agent functions. This handoff is achieved by simply returning the next agent to call within the function.
Define logic for transferring control to another agent based on conversation flow or specific criteria within agent functions. This handoff is achieved by simply returning the next agent to call within the function.  Context Variables provide initial context and update them throughout the conversation to maintain state and share information between agents.
Context Variables provide initial context and update them throughout the conversation to maintain state and share information between agents.  Client run() initiate and manage the multi-agent conversation. It needs an initial agent, user messages, and context and returns a response containing updated messages, context variables, and the last active agent.
Client run() initiate and manage the multi-agent conversation. It needs an initial agent, user messages, and context and returns a response containing updated messages, context variables, and the last active agent. Swarm manages a loop of agent interactions, function calls, and potential handoffs.
Swarm manages a loop of agent interactions, function calls, and potential handoffs. Agents encapsulate instructions, available functions (tools), and handoff logic.
Agents encapsulate instructions, available functions (tools), and handoff logic. The framework is stateless between calls, offering transparency and fine-grained control.
The framework is stateless between calls, offering transparency and fine-grained control. Streaming responses are supported for real-time interaction.
Streaming responses are supported for real-time interaction. The framework is experimental. Maybe to collect feedback?
The framework is experimental. Maybe to collect feedback? Flexible and works with any OpenAI client, e.g., Hugging Face TGI or vLLM-hosted models.
Flexible and works with any OpenAI client, e.g., Hugging Face TGI or vLLM-hosted models.


 Provides a concise intro focusing on the generative decoder-only architecture.
Provides a concise intro focusing on the generative decoder-only architecture.

 :
: :
:




 Layered structure: LLM components arranged in sequential layers, with parallel execution within layers.
Layered structure: LLM components arranged in sequential layers, with parallel execution within layers. Plug-and-play: Users can select existing techniques or add new ones, specifying desired objectives.
Plug-and-play: Users can select existing techniques or add new ones, specifying desired objectives. Task adaptability: Can be optimized for specific tasks or as a general-purpose architecture.
Task adaptability: Can be optimized for specific tasks or as a general-purpose architecture.





 :
: