
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?[Submitted on 1 Jul 2024 (v1), last revised 4 Oct 2024 (this version, v2)]
Deciphering the Factors Influencing the Efficacy of Chain-of-Thought: Probability, Memorization, and Noisy Reasoning
Akshara Prabhakar, Thomas L. Griffiths, R. Thomas McCoyChain-of-Thought (CoT) prompting has been shown to enhance the multi-step reasoning capabilities of Large Language Models (LLMs). However, debates persist about whether LLMs exhibit abstract generalization or rely on shallow heuristics when given CoT prompts. To understand the factors influencing CoT reasoning we provide a detailed case study of the symbolic reasoning task of decoding shift ciphers, where letters are shifted forward some number of steps in the alphabet. We analyze the pattern of results produced by three LLMs -- GPT-4, Claude 3, and Llama 3.1 -- performing this task using CoT prompting. By focusing on a single relatively simple task, we are able to identify three factors that systematically affect CoT performance: the probability of the task's expected output (probability), what the model has implicitly learned during pre-training (memorization), and the number of intermediate operations involved in reasoning (noisy reasoning). We show that these factors can drastically influence task accuracy across all three LLMs; e.g., when tested with GPT-4, varying the output's probability of occurrence shifts accuracy from 26% to 70%. Overall, we conclude that CoT prompting performance reflects both memorization and a probabilistic version of genuine reasoning. Code and data at this this https URL
| Comments: | EMNLP 2024 Findings; 9 pages plus references and appendices |
| Subjects: | Computation and Language (cs.CL); Artificial Intelligence (cs.AI) |
| Cite as: | arXiv:2407.01687 [cs.CL] |
| (or arXiv:2407.01687v2 [cs.CL] for this version) | |
| [2407.01687] Deciphering the Factors Influencing the Efficacy of Chain-of-Thought: Probability, Memorization, and Noisy Reasoning Focus to learn more |
Submission history
From: Akshara Prabhakar [view email]
[v1] Mon, 1 Jul 2024 18:01:07 UTC (2,503 KB)
[v2] Fri, 4 Oct 2024 01:01:39 UTC (3,109 KB)
1/11
@midosommar
AI needs to be nuked I’m so serious
[Quoted tweet]
This GAG OHH ARIANA

2/11
@2000insurgence
genuinely tell me what is the tell here, like normally ai lighting looks weird, it just doesnt here
3/11
@midosommar
Her face being weirdly lit compared to the rest of the photo, some facial features are off, hair randomly floating as if being blown upwards, and “brat” on her shirt a completely different font to the official artwork. It’s small stuff but there’s an uncanny valley feel to it.
4/11
@iamnaaomixx
THAT'S AI???? it now looks waaay too realistic
5/11
@yxngweaveB
Yeah, no this is getting scary.
6/11
@Junokawai
imagine AI in the future though, we wouldn't even know what's real or not
7/11
@saylesssavage
this looks so real omg it kinda ate
8/11
@lucyqrow
I HONESTLY THOUGHT THIS WAS REAL
9/11
@taylamay222
it was AI??? this is truly terrifying
10/11
@luldopamine
Admit it. That picture eats down tho
11/11
@MercyBuzzard13
What was the giveaway on this one? This would have even tricked me.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@midosommar
AI needs to be nuked I’m so serious
[Quoted tweet]
This GAG OHH ARIANA
2/11
@2000insurgence
genuinely tell me what is the tell here, like normally ai lighting looks weird, it just doesnt here
3/11
@midosommar
Her face being weirdly lit compared to the rest of the photo, some facial features are off, hair randomly floating as if being blown upwards, and “brat” on her shirt a completely different font to the official artwork. It’s small stuff but there’s an uncanny valley feel to it.
4/11
@iamnaaomixx
THAT'S AI???? it now looks waaay too realistic
5/11
@yxngweaveB
Yeah, no this is getting scary.
6/11
@Junokawai
imagine AI in the future though, we wouldn't even know what's real or not
7/11
@saylesssavage
this looks so real omg it kinda ate
8/11
@lucyqrow
I HONESTLY THOUGHT THIS WAS REAL
9/11
@taylamay222
it was AI??? this is truly terrifying
10/11
@luldopamine
Admit it. That picture eats down tho
11/11
@MercyBuzzard13
What was the giveaway on this one? This would have even tricked me.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/11
@beyoncesspamacc
Mind u this was AI not even a year ago.... somebody needs to break into the server rooms & pour pepsi on all the racks
[Quoted tweet]
This GAG OHH ARIANA

2/11
@LilKittyZoey
courtrooms need start setting up laws because this is terrifying it's going daily and it's getting scarier and scarier
3/11
@imperfect4mads
wdym this is literally a real picture of ariana wearing olive green jeans????
4/11
@catpoopburglar
no this one is real
5/11
@MiaMiaOnlyFun
ai still looks not too far off this, I'm guessing they used another picture as a base or photoshopped it
6/11
@pvaches
but the edition was so beautiful too...
7/11
@cecithelatina
I will do it but I only have iced tea
8/11
@i_anilbishnoi
Looking a Stunning nd gorgeous
I cant believe
9/11
@mothermoirae2d
the problem was you were using crayon lol
10/11
@JoannaGiaOfCali
There would literally be 0 downside to a ban on hyper-realistic AI imagery, it's not a double-edged sword, it's a necessity.
11/11
@SillaySall94876
Like it’s actually getting scary + the facts there aren’t laws surrounding this is a recipe for disaster exhibit A would be the Taylor thing that happened a few months back with that one weirdo on twt
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@beyoncesspamacc
Mind u this was AI not even a year ago.... somebody needs to break into the server rooms & pour pepsi on all the racks
[Quoted tweet]
This GAG OHH ARIANA
2/11
@LilKittyZoey
courtrooms need start setting up laws because this is terrifying it's going daily and it's getting scarier and scarier
3/11
@imperfect4mads
wdym this is literally a real picture of ariana wearing olive green jeans????
4/11
@catpoopburglar
no this one is real
5/11
@MiaMiaOnlyFun
ai still looks not too far off this, I'm guessing they used another picture as a base or photoshopped it
6/11
@pvaches
but the edition was so beautiful too...7/11
@cecithelatina
I will do it but I only have iced tea
8/11
@i_anilbishnoi
Looking a Stunning nd gorgeous
I cant believe
9/11
@mothermoirae2d
the problem was you were using crayon lol
10/11
@JoannaGiaOfCali
There would literally be 0 downside to a ban on hyper-realistic AI imagery, it's not a double-edged sword, it's a necessity.
11/11
@SillaySall94876
Like it’s actually getting scary + the facts there aren’t laws surrounding this is a recipe for disaster
exhibit A would be the Taylor thing that happened a few months back with that one weirdo on twtTo post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

OpenAI's o1 Model Excels in Reasoning But Struggles with Rare and Complex Tasks
Researchers analyzed OpenAI’s o1 model and found it improves reasoning performance, but still retains probabilistic biases from autoregressive training, especially in rare or complex tasks.
 www.azoai.com
www.azoai.com
OpenAI's o1 Model Excels in Reasoning But Struggles with Rare and Complex Tasks
By Soham Nandi
Reviewed by Joel Scanlon Oct 9 2024
Despite being optimized for reasoning, OpenAI’s o1 model continues to show sensitivity to probability and task frequency, revealing the deep-rooted impact of autoregressive training even in cutting-edge AI systems.
Research: When a language model is optimized for reasoning, does it still show embers of autoregression? An analysis of OpenAI o1In an article recently submitted to the arXiv preprint* server, researchers investigated whether OpenAI's o1, a language model optimized for reasoning, overcame limitations seen in previous large language models (LLMs). The study showed that while o1 performed significantly better, especially on rare tasks, it still exhibited sensitivity to probability, a trait from its autoregressive origins. This suggests that while optimizing for reasoning enhances performance, it might not entirely eliminate the probabilistic biases that remain embedded in the model.
Background
, all six LLMs evaluated here—including o1—show sensitivity to output probability, with higher accuracies on examples that have a high output probability than on examples that have a low output probability. The results for all models except o1 are from McCoy et al. (2023). The intervals around the lines show one standard error.") Across the four tasks we considered (shift ciphers, Pig Latin, article swapping, and reversal), all six LLMs evaluated here—including o1—show sensitivity to output probability, with higher accuracies on examples that have a high output probability than on examples that have a low output probability. The results for all models except o1 are from McCoy et al. (2023). The intervals around the lines show one standard error.
Across the four tasks we considered (shift ciphers, Pig Latin, article swapping, and reversal), all six LLMs evaluated here—including o1—show sensitivity to output probability, with higher accuracies on examples that have a high output probability than on examples that have a low output probability. The results for all models except o1 are from McCoy et al. (2023). The intervals around the lines show one standard error.LLMs, such as generative pre-trained transformers (GPT), have traditionally been trained using autoregressive techniques, which predict the next word in a sequence based on prior input. While this method has produced models capable of impressive feats in natural language understanding, research highlights key limitations.
One notable issue is that LLMs are biased toward producing high-probability sequences, leading to challenges in tasks where the expected output is rare or unconventional. These "embers of autoregression" influence performance across various tasks, even those unrelated to basic next-word prediction. In previous research, these trends were evident even when models were used for complex tasks like reasoning.
Earlier findings revealed that LLMs perform better on tasks with high-probability outputs but struggle with less likely sequences, especially in uncommon task variants. These limitations prompted researchers to analyze OpenAI’s o1 model to determine whether optimization for reasoning could address these biases.
Sensitivity to Output Probability and Task Frequency
The researchers assessed the performance of OpenAI’s o1 model on a variety of tasks, examining whether it exhibited sensitivity to the probability of output and the frequency of task types. They tested two primary factors: output probability (how likely the model’s answer is based on common language patterns) and task frequency (how often a particular task variant occurs in training data).
For output probability, the researchers evaluated o1 on four tasks: decoding shift ciphers, decoding Pig Latin messages, article swapping, and reversing word lists. Their results indicated that o1 performed better on high-probability examples compared to low-probability ones.
For instance, o1’s accuracy on the shift cipher task ranged from 47% on low-probability examples to 92% on high-probability examples. In addition to better performance on high-probability tasks, o1 used fewer tokens in these cases, highlighting its sensitivity to output probability.
Next, the authors explored whether o1 performed differently on common versus rare task variants. They tested five task types with both common and rare variants, including decoding ciphers, forming acronyms, and sorting lists. The researchers found that o1 outperformed other LLMs, particularly on rare task variants. This suggests that o1 is less sensitive to task frequency compared to earlier models, though some effects remained.
However, to ensure that these findings weren’t limited by "ceiling effects" (where tasks were too easy for differences to be noticeable), they introduced more challenging variants of some tasks. In these harder cases, o1's performance dropped significantly for rare task variants, reinforcing its sensitivity to task frequency in more difficult scenarios.
 and a variant that is rare (e.g., forming acronyms from the second letter of each word in a sequence). On these datasets, the five LLMs other than o1 showed much higher accuracy on the common variants than the rare ones, but o1 showed similar performance on common and rare variants. The results for models other than o1 are from McCoy et al. (2023). Top right: On datasets based on challenging sorting tasks, o1 performs better on the common type of sorting (i.e., sorting into alphabetical order) than on the rare type of sorting (i.e., sorting into reverse alphabetical order). Bottom right: When decoding shift ciphers, o1 shows roughly the same performance on the common cipher type and on the rare cipher type when the examples are ones with a high output probability. However, when it is instead evaluated on examples with medium or low probability, its accuracy is higher for the common cipher type than the rare one. The error intervals in all plots show one standard error.") Left: We evaluated LLMs on two variants of five tasks—a variant that is common in Internet text (e.g., forming acronyms from the first letter of each word in a sequence) and a variant that is rare (e.g., forming acronyms from the second letter of each word in a sequence). On these datasets, the five LLMs other than o1 showed much higher accuracy on the common variants than the rare ones, but o1 showed similar performance on common and rare variants. The results for models other than o1 are from McCoy et al. (2023). Top right: On datasets based on challenging sorting tasks, o1 performs better on the common type of sorting (i.e., sorting into alphabetical order) than on the rare type of sorting (i.e., sorting into reverse alphabetical order). Bottom right: When decoding shift ciphers, o1 shows roughly the same performance on the common cipher type and on the rare cipher type when the examples are ones with a high output probability. However, when it is instead evaluated on examples with medium or low probability, its accuracy is higher for the common cipher type than the rare one. The error intervals in all plots show one standard error.
Left: We evaluated LLMs on two variants of five tasks—a variant that is common in Internet text (e.g., forming acronyms from the first letter of each word in a sequence) and a variant that is rare (e.g., forming acronyms from the second letter of each word in a sequence). On these datasets, the five LLMs other than o1 showed much higher accuracy on the common variants than the rare ones, but o1 showed similar performance on common and rare variants. The results for models other than o1 are from McCoy et al. (2023). Top right: On datasets based on challenging sorting tasks, o1 performs better on the common type of sorting (i.e., sorting into alphabetical order) than on the rare type of sorting (i.e., sorting into reverse alphabetical order). Bottom right: When decoding shift ciphers, o1 shows roughly the same performance on the common cipher type and on the rare cipher type when the examples are ones with a high output probability. However, when it is instead evaluated on examples with medium or low probability, its accuracy is higher for the common cipher type than the rare one. The error intervals in all plots show one standard error.For example, when the sorting task was made more challenging by using words with the same first letter, o1 performed significantly better on the common variant (alphabetical sorting) than the rare one (reverse alphabetical sorting). Similarly, in cipher decoding tasks with medium- and low-probability examples, o1 performed better on the common cipher than on the rare one. This performance gap was also reflected in token usage, with o1 consuming more tokens for rare task variants, indicating their increased difficulty.
In essence, while o1 exhibited less sensitivity to task frequency than earlier LLMs, it still showed some dependence on output probability and task frequency in more challenging scenarios. Token usage data corroborated these trends, with o1 using more tokens for low-probability tasks and rare task variants, even when accuracy was comparable. The results highlighted that while o1 represented a substantial improvement over previous models, the influence of probabilistic training objectives remained evident in its behavior.
Conclusion
In conclusion, OpenAI's o1 model demonstrated notable improvements over previous LLMs, particularly in handling rare task variants. Despite these advancements, o1 still exhibited significant sensitivity to output probability and task frequency, echoing patterns observed in earlier LLMs. While the model showed progress in reducing these biases, its performance in more challenging scenarios suggests that probabilistic judgments are deeply ingrained.
The findings suggested that while optimizing for reasoning enhanced performance, the "embers of autoregression" persisted. Future developments may require innovative approaches that reduce reliance on probabilistic judgments to fully address the inherent limitations associated with autoregression, potentially incorporating non-probabilistic components to overcome these biases.
When a language model is optimized for reasoning, does it still show embers of autoregression? An analysis of OpenAI o1
In "Embers of Autoregression" (McCoy et al., 2023), we showed that several large language models (LLMs) have some important limitations that are attributable to their origins in next-word prediction. Here we investigate whether these issues persist with o1, a new system from OpenAI that differs...
[Submitted on 2 Oct 2024 (v1), last revised 4 Oct 2024 (this version, v2)]
When a language model is optimized for reasoning, does it still show embers of autoregression? An analysis of OpenAI o1
R. Thomas McCoy, Shunyu Yao, Dan Friedman, Mathew D. Hardy, Thomas L. GriffithsIn "Embers of Autoregression" (McCoy et al., 2023), we showed that several large language models (LLMs) have some important limitations that are attributable to their origins in next-word prediction. Here we investigate whether these issues persist with o1, a new system from OpenAI that differs from previous LLMs in that it is optimized for reasoning. We find that o1 substantially outperforms previous LLMs in many cases, with particularly large improvements on rare variants of common tasks (e.g., forming acronyms from the second letter of each word in a list, rather than the first letter). Despite these quantitative improvements, however, o1 still displays the same qualitative trends that we observed in previous systems. Specifically, o1 -- like previous LLMs -- is sensitive to the probability of examples and tasks, performing better and requiring fewer "thinking tokens" in high-probability settings than in low-probability ones. These results show that optimizing a language model for reasoning can mitigate but might not fully overcome the language model's probability sensitivity.
| Comments: | 6 pages; updated to fix typo in Fig 4 caption |
| Subjects: | Computation and Language (cs.CL); Artificial Intelligence (cs.AI) |
| Cite as: | arXiv:2410.01792 [cs.CL] |
| (or arXiv:2410.01792v2 [cs.CL] for this version) | |
| [2410.01792] When a language model is optimized for reasoning, does it still show embers of autoregression? An analysis of OpenAI o1 Focus to learn more |
Submission history
From: Tom McCoy [view email]
[v1] Wed, 2 Oct 2024 17:50:19 UTC (74 KB)
[v2] Fri, 4 Oct 2024 03:57:33 UTC (74 KB)
1/11
@svpino
Large Language Models don't reason.
Thank you,
Apple.

2/11
@RaulJuncoV
Job is safe
3/11
@svpino
Job might not need reasoning…
4/11
@AlexTobiasDev
Excuses. AI will be the new 'him' in math, programming, science pretty soon.
Y'all can be mad and cling onto false hopes all you want.
5/11
@svpino
who's mad? not me
6/11
@barancezayirli
People not going to give up from the idea that a random text generation code can reason
This is a good paper. First we need to define and understand how humans reason, then we can build a solution for that.
7/11
@SagarBhupalam
Watch what Ilya had to say about LLMs reasoning.
8/11
@Stephen87165188
However, frontier LLMs do memorize the patterns of deductive logic at many levels of abstraction.
In particular, for someone experienced in symbolic logic, knowledge representation, planning, and logical justification, observe that frontier LLMs do reason and justify it, in particular when few steps from the given context are required.
Not all forms or reason, not yet to the depth of an expert human, but 'reason' enough to help automate the construction of what comes next in AI.
9/11
@wardchristianj
I think we need to take a big step back and recognize that humans don’t often “reason” well either. There are more similarities than not.
10/11
@01Singularity01
"Reasoning" is the progressive, iterative reduction of informational entropy in a knowledge domain. o1-preview does that better by introducing iteration. It's not perfect, but it does it. "Reasoning" is not a special, magical thing. It's an information process.
11/11
@jenwiderberg
Psychology enters the chat on reason:
Interesting and evolving topic.

To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@svpino
Large Language Models don't reason.
Thank you,
Apple.
2/11
@RaulJuncoV
Job is safe
3/11
@svpino
Job might not need reasoning…
4/11
@AlexTobiasDev
Excuses. AI will be the new 'him' in math, programming, science pretty soon.
Y'all can be mad and cling onto false hopes all you want.
5/11
@svpino
who's mad? not me
6/11
@barancezayirli
People not going to give up from the idea that a random text generation code can reason
This is a good paper. First we need to define and understand how humans reason, then we can build a solution for that.
7/11
@SagarBhupalam
Watch what Ilya had to say about LLMs reasoning.
8/11
@Stephen87165188
However, frontier LLMs do memorize the patterns of deductive logic at many levels of abstraction.
In particular, for someone experienced in symbolic logic, knowledge representation, planning, and logical justification, observe that frontier LLMs do reason and justify it, in particular when few steps from the given context are required.
Not all forms or reason, not yet to the depth of an expert human, but 'reason' enough to help automate the construction of what comes next in AI.
9/11
@wardchristianj
I think we need to take a big step back and recognize that humans don’t often “reason” well either. There are more similarities than not.
10/11
@01Singularity01
"Reasoning" is the progressive, iterative reduction of informational entropy in a knowledge domain. o1-preview does that better by introducing iteration. It's not perfect, but it does it. "Reasoning" is not a special, magical thing. It's an information process.
11/11
@jenwiderberg
Psychology enters the chat on reason:
Interesting and evolving topic.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Last edited:
1/5
@rohanpaul_ai
Reflection with Multi-Step Reasoning
Chain-of-Thought with local LLM "Llama-3.1 8B"
Interesting work
[Quoted tweet]
Reflective Chain-of-Thought via local LLM "Llama-3.1 8B" and @Gradio
1. Reflective Reasoning
2. Chain-of-Thought (CoT)
3. Summarization and Distillation
4. Iterative Refinement
The normal CoT answer got 7/10, but this one got 10/10 from Claude!
https://video.twimg.com/ext_tw_video/1834664957188661248/pu/vid/avc1/1280x720/vQDWDXFP-rtO_R6c.mp4
2/5
@MaziyarPanahi
Thanks @rohanpaul_ai

3/5
@rohanpaul_ai

4/5
@BenjaminKlieger
Cool work! I have been experimenting with prompting strategies alone to improve reasoning for g1, it’s powerful!
[Quoted tweet]
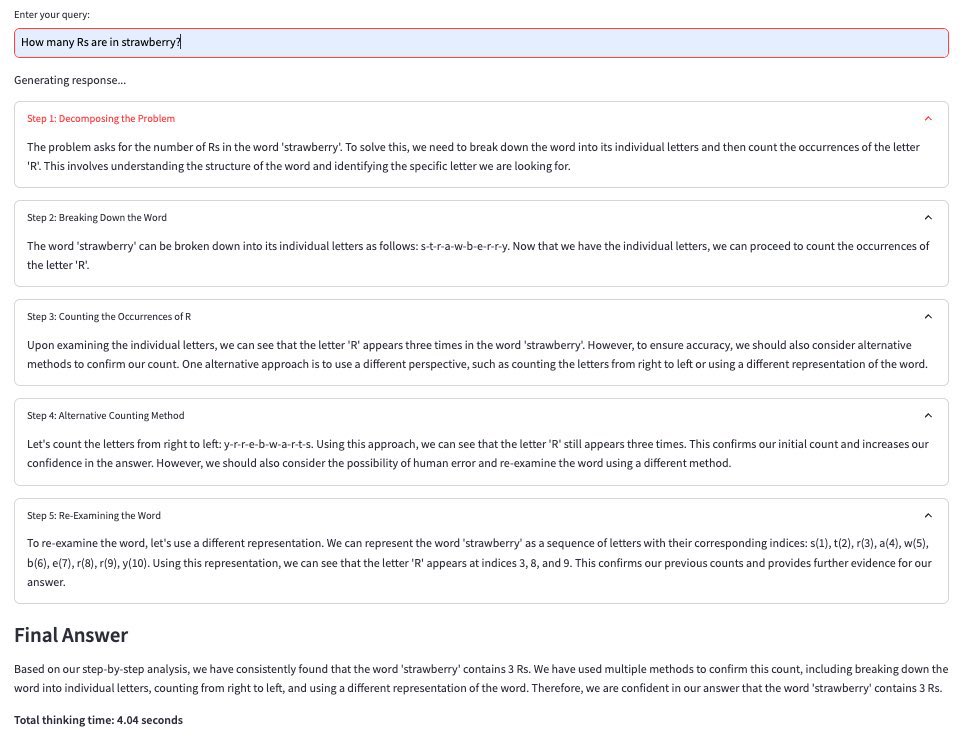
Inspired by the new o1 model, I hacked together g1, powered by Llama-3.1 on @GroqInc. It uses reasoning chains to solve problems.
It solves the Strawberry problem ~70% of the time, with no fine tuning or few shot techniques.
A thread (with GitHub repo!)
(with GitHub repo!)

5/5
@andysingal
how do you differentiate with CRAG?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@rohanpaul_ai
Reflection with Multi-Step Reasoning
Chain-of-Thought with local LLM "Llama-3.1 8B"
Interesting work
[Quoted tweet]
Reflective Chain-of-Thought via local LLM "Llama-3.1 8B" and @Gradio
1. Reflective Reasoning
2. Chain-of-Thought (CoT)
3. Summarization and Distillation
4. Iterative Refinement
The normal CoT answer got 7/10, but this one got 10/10 from Claude!
https://video.twimg.com/ext_tw_video/1834664957188661248/pu/vid/avc1/1280x720/vQDWDXFP-rtO_R6c.mp4
2/5
@MaziyarPanahi
Thanks @rohanpaul_ai
3/5
@rohanpaul_ai
4/5
@BenjaminKlieger
Cool work! I have been experimenting with prompting strategies alone to improve reasoning for g1, it’s powerful!
[Quoted tweet]
Inspired by the new o1 model, I hacked together g1, powered by Llama-3.1 on @GroqInc. It uses reasoning chains to solve problems.
It solves the Strawberry problem ~70% of the time, with no fine tuning or few shot techniques.
A thread
(with GitHub repo!)
5/5
@andysingal
how do you differentiate with CRAG?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/23
@MaziyarPanahi
Reflective Chain-of-Thought via local LLM "Llama-3.1 8B" and @Gradio
1. Reflective Reasoning
2. Chain-of-Thought (CoT)
3. Summarization and Distillation
4. Iterative Refinement
The normal CoT answer got 7/10, but this one got 10/10 from Claude!
https://video.twimg.com/ext_tw_video/1834664957188661248/pu/vid/avc1/1280x720/vQDWDXFP-rtO_R6c.mp4
2/23
@MaziyarPanahi
The reflection part:

3/23
@MaziyarPanahi
The whole Reflection 70B thing really opened my eyes. It was crazy how hard it was to convince people that the first model (still trending and not removed) was just Llama-3-70B with a system prompt slapped on top. That's when it hit me - a lot of folks have no clue how these AI platforms actually work under the hood!
There's so much going on behind the scenes that users don't see. We're talking tons of processing before and after, a bunch of different models running at the same time, and special models for different jobs. It's way more complex than most people realize.
It's kind of a bummer that there's this big gap in understanding. But hey, it's a chance to teach people something new. We need to spread the word that using these AI models isn't just about throwing a single prompt at a single model and calling it a day. There's a whole lot more to it, and knowing that can really help you get the most out of these powerful tools.
PS: Now you now how big it is where we say Llama-3.1 405B is that close to Claude Sonnet 3.5 or GPT-4! These are AI Platforms, not just models! So it's huge how close open LLMs are to these AI platforms.
Stay tune for more! This one was easy and fun! (might setup a git to put everything there later)

4/23
@MemoSparkfield
Feels unreal!
5/23
@MaziyarPanahi
It’s llama-3.1 8b, with larger models on the mix, some pauses for thinking (UI/UX), including some tools and RAG in steps that can benefit, we won’t be having a smarter model, we will have a smarter use of these local LLMs!
6/23
@rot13maxi
Is the workflow something like:
Give a system prompt about reflecting on the problem, then feed the output into another prompt about breaking it down step by step, then distilling step? Ive been playing with just feeding answers back into the model with iteration
7/23
@MaziyarPanahi
100%! I think we should talk more about iterations, chaining, mix of models, and anything else that could even remotely use local LLMs with more than just a simple in->out!
Most of the modern AI Platforms are more engineering than the research these days.
8/23
@tech_schulz
Impressive results from experimenting with Reflective Chain-of-Thought via local LLM and Gradio - a perfect score of 10/10 from Claude is no easy feat. What inspired you to try this approach?
9/23
@MaziyarPanahi
Smaller models are getting good in accuracy, so they are pretty fast at inference. We can do more iterations to help the LLM think and find its way to a better answer.
I always think of it as "asking a model to code" compare to "asking a model to code, run it, give the model the error, and ask it to fix it", with one more iteration it will have more chance to fix its mistake.
10/23
@MaziyarPanahi
The reflection was called out by the post Chain of Thought:

11/23
@cognitivetech_
so this is a drop-in replacement for o1, right?
12/23
@MaziyarPanahi
100%! It also uses the 8B model, the most accurate of all!
13/23
@iamRezaSayar
can you make a torrent file though?
14/23
@MaziyarPanahi
but is there anyone who can help me setup a torrent?
15/23
@iamRezaSayar
jk. awesome job!
I have set my eyes on my next Distillation project, using Personas and even possibly something similar to this Reflection thing. do you have any free time / interest to join me in it? (no pressure)
16/23
@MaziyarPanahi
I need to learn how to best do reflection tuning to be honest. I am hoping thanks to o1 I'll see more datasets and more tunes. (would love to see a different rewarding system and loss function for it)
17/23
@casper_hansen_
Let's be honest, you can't prompt or RLHF your way to this. You need some other methods to make it work
18/23
@MaziyarPanahi
The point was not to create an o1 model here, so I agree promoting and rlhf won’t be enough. There is more to it than just a new model even. However, it does get us to talk about why local LLMs are mostly used by 1 iteration! Why can’t we change the way we use them to get more.
A zero-shot 8B model answers this question with the score of 7/10, doing this 3 iterations without any extra work made it 10/10! (Add tools to each step, CoT those separately, ... and we get even more)
What’s new is the inference part that goes beyond a simple input->output. More multiple steps/iterations, reflections, CoT, parallel calls, anything that can improve the answer.
19/23
@filoynavaja
I’ve already seen this somewhere else
20/23
@AI_GPT42
can you share this prompt?
21/23
@herrschmidt_tv
Pretty cool! I'd love to see the prompt / prompts . Did you pipe the output of one prompt into the next and asked it to reflect? Do you set the number of iterations or does the LLM somehow "realize" when it has everything together for a final answer and prints a stop sequence?
. Did you pipe the output of one prompt into the next and asked it to reflect? Do you set the number of iterations or does the LLM somehow "realize" when it has everything together for a final answer and prints a stop sequence?
22/23
@MasoudMaani

23/23
@RaviRan85788251
Can you share the code?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@MaziyarPanahi
Reflective Chain-of-Thought via local LLM "Llama-3.1 8B" and @Gradio
1. Reflective Reasoning
2. Chain-of-Thought (CoT)
3. Summarization and Distillation
4. Iterative Refinement
The normal CoT answer got 7/10, but this one got 10/10 from Claude!
https://video.twimg.com/ext_tw_video/1834664957188661248/pu/vid/avc1/1280x720/vQDWDXFP-rtO_R6c.mp4
2/23
@MaziyarPanahi
The reflection part:
3/23
@MaziyarPanahi
The whole Reflection 70B thing really opened my eyes. It was crazy how hard it was to convince people that the first model (still trending and not removed) was just Llama-3-70B with a system prompt slapped on top. That's when it hit me - a lot of folks have no clue how these AI platforms actually work under the hood!
There's so much going on behind the scenes that users don't see. We're talking tons of processing before and after, a bunch of different models running at the same time, and special models for different jobs. It's way more complex than most people realize.
It's kind of a bummer that there's this big gap in understanding. But hey, it's a chance to teach people something new. We need to spread the word that using these AI models isn't just about throwing a single prompt at a single model and calling it a day. There's a whole lot more to it, and knowing that can really help you get the most out of these powerful tools.
PS: Now you now how big it is where we say Llama-3.1 405B is that close to Claude Sonnet 3.5 or GPT-4! These are AI Platforms, not just models! So it's huge how close open LLMs are to these AI platforms.
Stay tune for more! This one was easy and fun! (might setup a git to put everything there later)
4/23
@MemoSparkfield
Feels unreal!
5/23
@MaziyarPanahi
It’s llama-3.1 8b, with larger models on the mix, some pauses for thinking (UI/UX), including some tools and RAG in steps that can benefit, we won’t be having a smarter model, we will have a smarter use of these local LLMs!
6/23
@rot13maxi
Is the workflow something like:
Give a system prompt about reflecting on the problem, then feed the output into another prompt about breaking it down step by step, then distilling step? Ive been playing with just feeding answers back into the model with iteration
7/23
@MaziyarPanahi
100%! I think we should talk more about iterations, chaining, mix of models, and anything else that could even remotely use local LLMs with more than just a simple in->out!
Most of the modern AI Platforms are more engineering than the research these days.
8/23
@tech_schulz
Impressive results from experimenting with Reflective Chain-of-Thought via local LLM and Gradio - a perfect score of 10/10 from Claude is no easy feat. What inspired you to try this approach?
9/23
@MaziyarPanahi
Smaller models are getting good in accuracy, so they are pretty fast at inference. We can do more iterations to help the LLM think and find its way to a better answer.
I always think of it as "asking a model to code" compare to "asking a model to code, run it, give the model the error, and ask it to fix it", with one more iteration it will have more chance to fix its mistake.
10/23
@MaziyarPanahi
The reflection was called out by the post Chain of Thought:
11/23
@cognitivetech_
so this is a drop-in replacement for o1, right?
12/23
@MaziyarPanahi
100%! It also uses the 8B model, the most accurate of all!
13/23
@iamRezaSayar
can you make a torrent file though?
14/23
@MaziyarPanahi
but is there anyone who can help me setup a torrent?
15/23
@iamRezaSayar
jk. awesome job!
I have set my eyes on my next Distillation project, using Personas and even possibly something similar to this Reflection thing. do you have any free time / interest to join me in it? (no pressure)
16/23
@MaziyarPanahi
I need to learn how to best do reflection tuning to be honest. I am hoping thanks to o1 I'll see more datasets and more tunes. (would love to see a different rewarding system and loss function for it)
17/23
@casper_hansen_
Let's be honest, you can't prompt or RLHF your way to this. You need some other methods to make it work
18/23
@MaziyarPanahi
The point was not to create an o1 model here, so I agree promoting and rlhf won’t be enough. There is more to it than just a new model even. However, it does get us to talk about why local LLMs are mostly used by 1 iteration! Why can’t we change the way we use them to get more.
A zero-shot 8B model answers this question with the score of 7/10, doing this 3 iterations without any extra work made it 10/10! (Add tools to each step, CoT those separately, ... and we get even more)
What’s new is the inference part that goes beyond a simple input->output. More multiple steps/iterations, reflections, CoT, parallel calls, anything that can improve the answer.
19/23
@filoynavaja
I’ve already seen this somewhere else
20/23
@AI_GPT42
can you share this prompt?
21/23
@herrschmidt_tv
Pretty cool! I'd love to see the prompt / prompts
. Did you pipe the output of one prompt into the next and asked it to reflect? Do you set the number of iterations or does the LLM somehow "realize" when it has everything together for a final answer and prints a stop sequence?22/23
@MasoudMaani
23/23
@RaviRan85788251
Can you share the code?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/1
@arcee_ai
First came Arcee AI's flagship 70B model, 𝗦𝘂𝗽𝗲𝗿𝗡𝗼𝘃𝗮, followed by the 𝟴𝗕 𝗦𝘂𝗽𝗲𝗿𝗡𝗼𝘃𝗮-𝗟𝗶𝘁𝗲.
Today we add to this family of superpower Small Language Models (SLMs) with the release of the 14B 𝗦𝘂𝗽𝗲𝗿𝗡𝗼𝘃𝗮-𝗠𝗲𝗱𝗶𝘂𝘀.
SuperNova-Medius represents a breakthrough in SLMs, combining the power of model merging with the efficiency of knowledge distillation.
Developed by the innovative team at Arcee Labs, this model represents a significant leap forward in combining advanced capabilities with practical efficiency.
At its core, SuperNova-Medius is built on the robust Qwen2.5-14B. But what sets it apart is its unique heritage. It's a carefully-orchestrated fusion of knowledge, using our DistillKit, from two AI giants: Qwen2.5-72B-Instruct and Llama-3.1-405B-Instruct.
This amalgamation of different AI "minds" results in a model that punches well above its weight class, offering performance that rivals much larger models despite its more manageable size.
Read more about the unique development of SuperNova, straight from our Chief of Frontier Research Charles Goddard @chargoddard, here: Introducing SuperNova-Medius: Arcee AI's 14B Small Language Model That Rivals a 70B
/search?q=#GenAI /search?q=#opensource /search?q=#LLMs
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@arcee_ai
First came Arcee AI's flagship 70B model, 𝗦𝘂𝗽𝗲𝗿𝗡𝗼𝘃𝗮, followed by the 𝟴𝗕 𝗦𝘂𝗽𝗲𝗿𝗡𝗼𝘃𝗮-𝗟𝗶𝘁𝗲.
Today we add to this family of superpower Small Language Models (SLMs) with the release of the 14B 𝗦𝘂𝗽𝗲𝗿𝗡𝗼𝘃𝗮-𝗠𝗲𝗱𝗶𝘂𝘀.
SuperNova-Medius represents a breakthrough in SLMs, combining the power of model merging with the efficiency of knowledge distillation.
Developed by the innovative team at Arcee Labs, this model represents a significant leap forward in combining advanced capabilities with practical efficiency.
At its core, SuperNova-Medius is built on the robust Qwen2.5-14B. But what sets it apart is its unique heritage. It's a carefully-orchestrated fusion of knowledge, using our DistillKit, from two AI giants: Qwen2.5-72B-Instruct and Llama-3.1-405B-Instruct.
This amalgamation of different AI "minds" results in a model that punches well above its weight class, offering performance that rivals much larger models despite its more manageable size.
Read more about the unique development of SuperNova, straight from our Chief of Frontier Research Charles Goddard @chargoddard, here: Introducing SuperNova-Medius: Arcee AI's 14B Small Language Model That Rivals a 70B
/search?q=#GenAI /search?q=#opensource /search?q=#LLMs
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196