
1/7
(1/7) Physics of LM, Part 2.1 with 8 results for LLM reasoning is out: [2407.20311] Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process. Probing reveals that LLMs secretly develop some "level-2" reasoning skill beyond Humans. Although I recommend watching my ICML tutorial first... Come in this thread to see the slides.

2/7
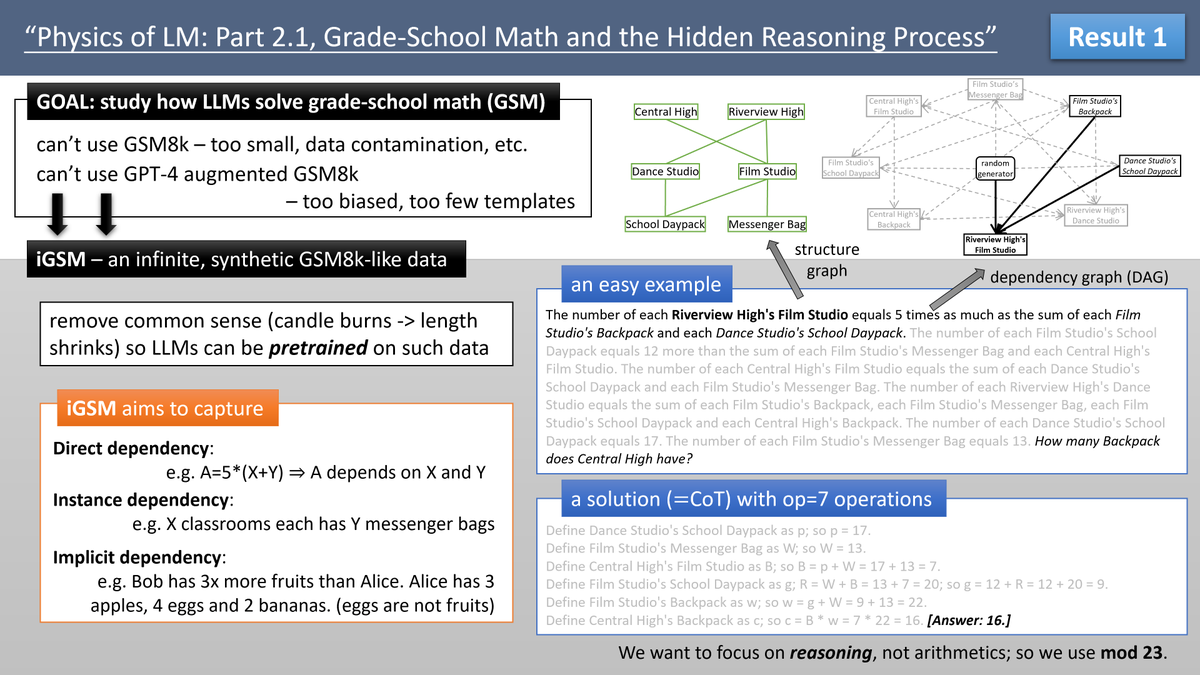
Result 1: we don't want to chat with GPT4 to guess how it reasons. Instead, we create synthetic grade-school math data (using mod-23 and removing common sense, focusing solely on reasoning) and pretrain model directly on it. This allows for controlled experiments and probing.
3/7
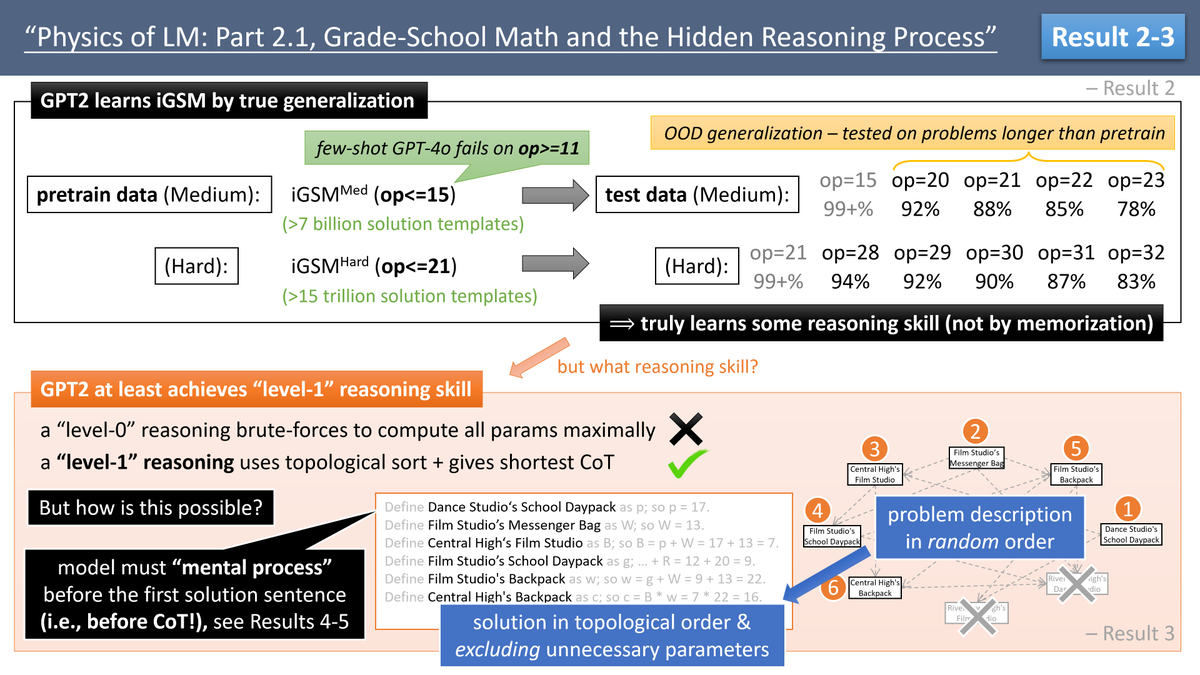
Result 2-3: Using this data, we show models can truly learn some reasoning skill (not by memorizing solution templates). Crucially, models can mentally do planning to generate shortest solutions (avoiding unnecessary computations) – a level 1 reasoning skill that Humans also do.
4/7
Result 4-5: we invent probing technique to discover, before a question is asked, model already figures out (mentally!) what parameter recursively depends on what. This skill is not needed for solving the problem, and different from human reasoning. We call it "level-2" reasoning.

5/7
Result 6: We explain how reasoning errors occur. For instance, some error traces back to the model's mental planning stage => such error can be predicted even before the model starts to generate the first token; such errors are independent of the random generation process.

6/7
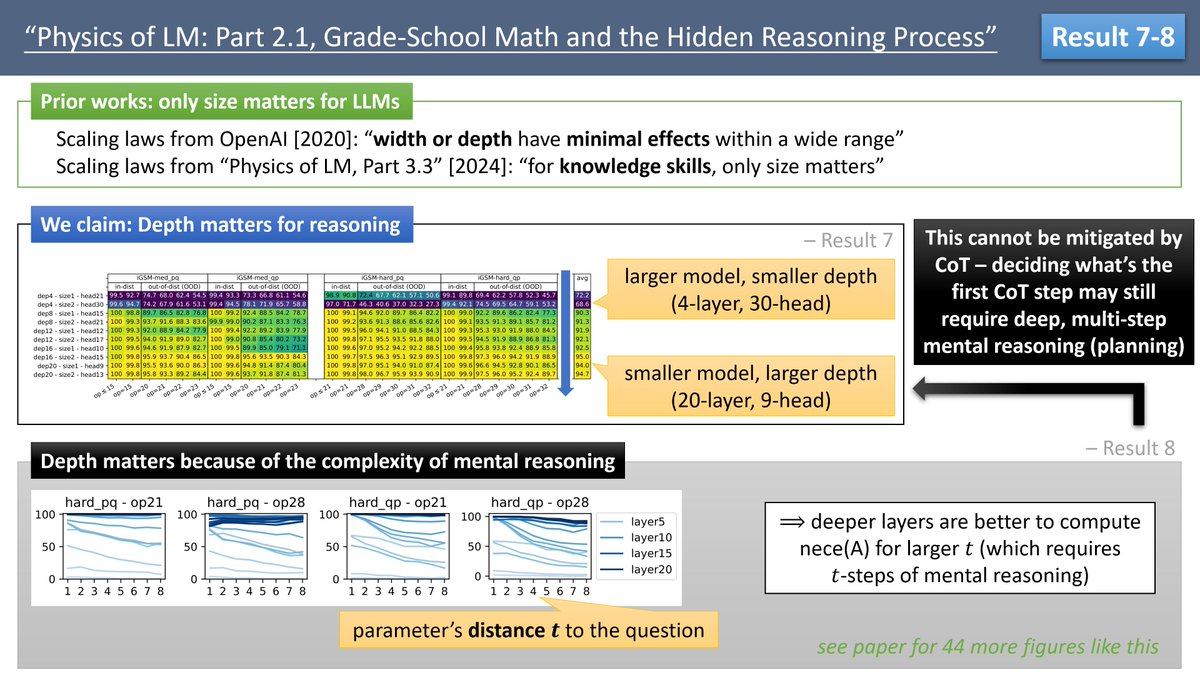
Result 7-8. Depth of model is crucial for reasoning; and we explain this necessity in depth by the complexity of the mental processes involved. This cannot be mitigated by CoT – deciding what’s the first CoT step may still require deep, multi-step mental reasoning (planning).
7/7
This is joint work with @yetian648(CMU/Meta), Zicheng Xu (Meta), Yuanzhi Li (MBZUAI). I'd like to thank once again my manager Lin Xiao for encouraging this exploratory research, FAIR's sponsorship on A100 + V100, and FAIR's wonderful engineering team that supported our heavy jobs
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
(1/7) Physics of LM, Part 2.1 with 8 results for LLM reasoning is out: [2407.20311] Physics of Language Models: Part 2.1, Grade-School Math and the Hidden Reasoning Process. Probing reveals that LLMs secretly develop some "level-2" reasoning skill beyond Humans. Although I recommend watching my ICML tutorial first... Come in this thread to see the slides.
2/7
Result 1: we don't want to chat with GPT4 to guess how it reasons. Instead, we create synthetic grade-school math data (using mod-23 and removing common sense, focusing solely on reasoning) and pretrain model directly on it. This allows for controlled experiments and probing.
3/7
Result 2-3: Using this data, we show models can truly learn some reasoning skill (not by memorizing solution templates). Crucially, models can mentally do planning to generate shortest solutions (avoiding unnecessary computations) – a level 1 reasoning skill that Humans also do.
4/7
Result 4-5: we invent probing technique to discover, before a question is asked, model already figures out (mentally!) what parameter recursively depends on what. This skill is not needed for solving the problem, and different from human reasoning. We call it "level-2" reasoning.
5/7
Result 6: We explain how reasoning errors occur. For instance, some error traces back to the model's mental planning stage => such error can be predicted even before the model starts to generate the first token; such errors are independent of the random generation process.
6/7
Result 7-8. Depth of model is crucial for reasoning; and we explain this necessity in depth by the complexity of the mental processes involved. This cannot be mitigated by CoT – deciding what’s the first CoT step may still require deep, multi-step mental reasoning (planning).
7/7
This is joint work with @yetian648(CMU/Meta), Zicheng Xu (Meta), Yuanzhi Li (MBZUAI). I'd like to thank once again my manager Lin Xiao for encouraging this exploratory research, FAIR's sponsorship on A100 + V100, and FAIR's wonderful engineering team that supported our heavy jobs
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196





 Stay Updated!
Stay Updated! Introducing Llama 3.2: Lightweight models for edge devices, vision models and more!
Introducing Llama 3.2: Lightweight models for edge devices, vision models and more!
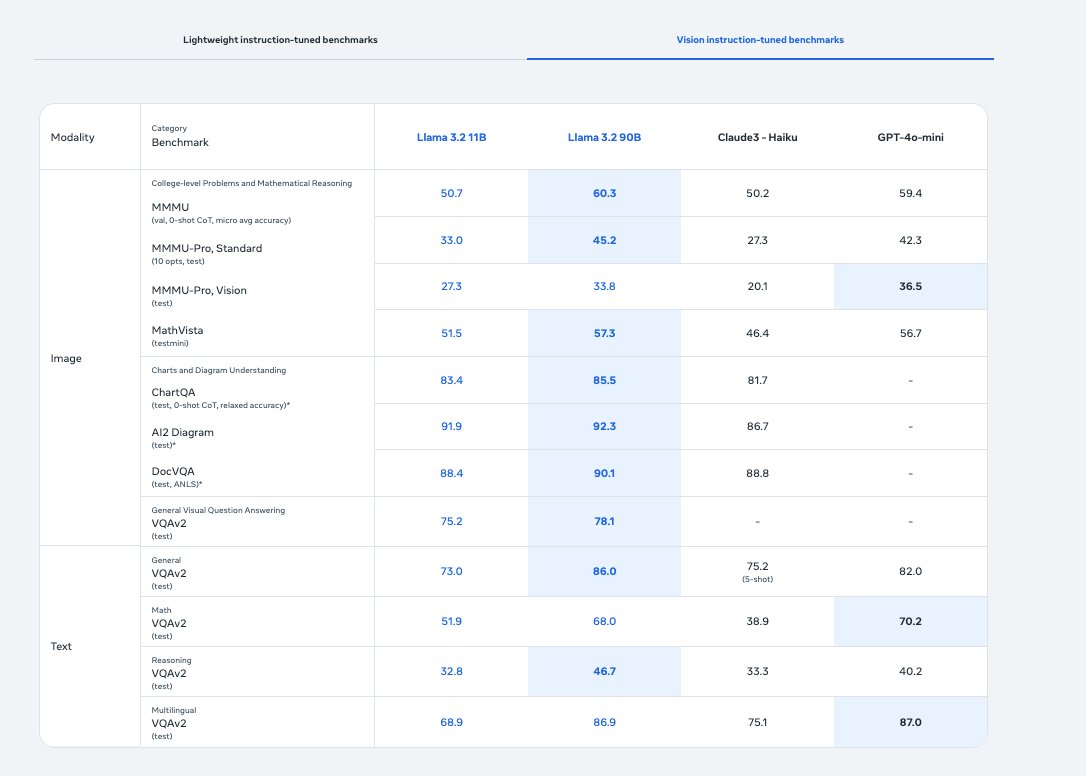
 We love that Llama has gone multimodal! We're excited to partner with @AIatMeta to offer free access to the Llama 3.2 11B vision model for developers. Can't wait to see what everyone builds!
We love that Llama has gone multimodal! We're excited to partner with @AIatMeta to offer free access to the Llama 3.2 11B vision model for developers. Can't wait to see what everyone builds!




 BREAKING
BREAKING
 Free access to Llama 3.2 Vision Model for developers to build and innovate with open source AI. api.together.ai/playground/c…
Free access to Llama 3.2 Vision Model for developers to build and innovate with open source AI. api.together.ai/playground/c… 

 Try it:
Try it:  vision models are coming very soon!
vision models are coming very soon!

 running locally in VSCode with Ollama and CodeGPT
running locally in VSCode with Ollama and CodeGPT



 it's almost nothing now
it's almost nothing now

 o1 model (@sama @OpenAI: with stunning results!).
o1 model (@sama @OpenAI: with stunning results!). 
