
1/11
@ArtificialAnlys
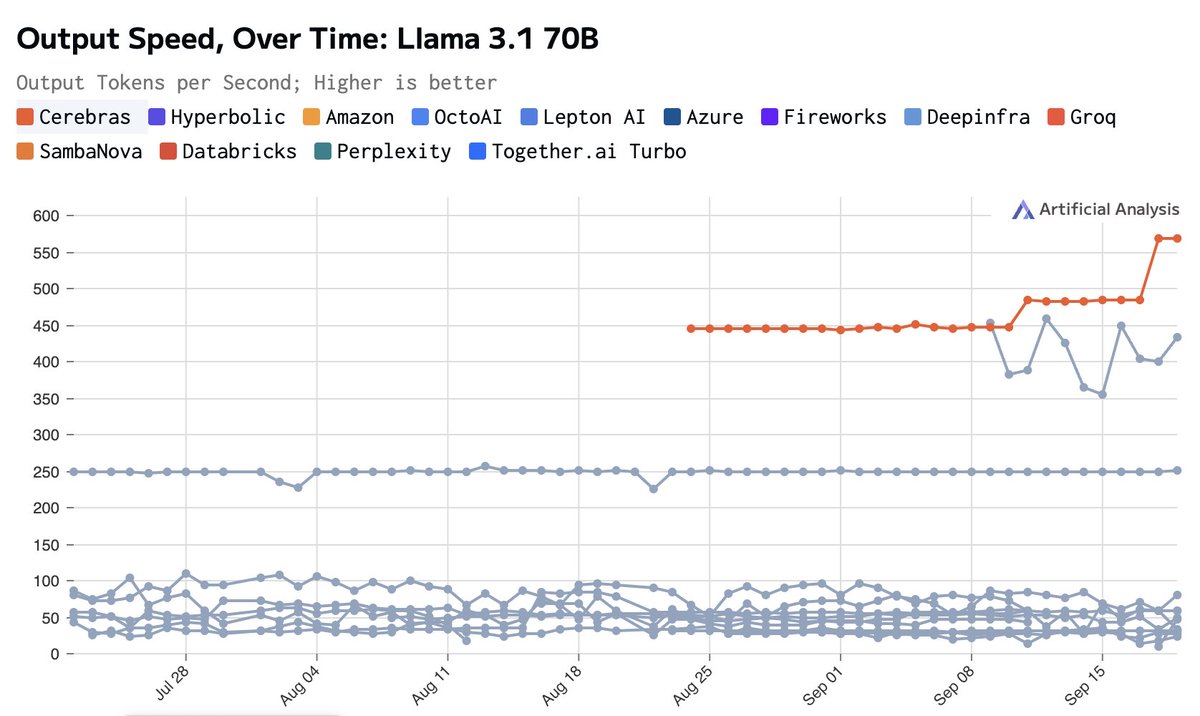
Cerebras continues to deliver output speed improvements, breaking the 2,000 tokens/s barrier on Llama 3.1 8B and 550 tokens/s on 70B
Since launching less than a month ago, @CerebrasSystems has continued to improve output speed inference performance on their custom chips.
We are now measuring 2,005 output tokens per second on @AIatMeta's Llama 3.1 8B and 566 output tokens per second on Llama 3.1 70B.
Faster output speed supports use-cases which require low-latency interactions including consumer applications (games, chatbots, etc) and new techniques of using the models such as agents and multi-query RAG.
Link to our comparison of Llama 3.1 70B and 8B providers below
2/11
@ArtificialAnlys
Analysis of Llama 3.1 70B providers:
https://artificialanalysis.ai/models/llama-3-1-instruct-70b/providers
Analysis of Llama 3.1 8B providers:
https://artificialanalysis.ai/models/llama-3-1-instruct-8b/providers
https://artificialanalysis.ai/models/llama-3-1-instruct-70b/providers
3/11
@linqtoinc
Incredible work @CerebrasSystems team!
4/11
@JonathanRoseD
Llama 405B when? I assume not soon because of the hardware—a chip that could handle that would be an absolute BEAST
5/11
@alby13
Why don't they talk about running Llama 3.1 405B?
6/11
@JERBAGSCRYPTO
When IPO
7/11
@itsTimDent
We need qwen or qwen coder similar output speeds.
8/11
@kalyan5v
Cerebras systems need lot of PR if it’s taking on /search?q=#NVDA
9/11
@pa_pfeiffer
How do you validate, that the model behind is actually Llama3.1 8B with full precision (bfloat16) and not something quantized, pruned or destilled?
10/11
@tristanbob
Amazing, congrats @CerebrasSystems!
11/11
@StartupHubAI
[Quoted tweet]
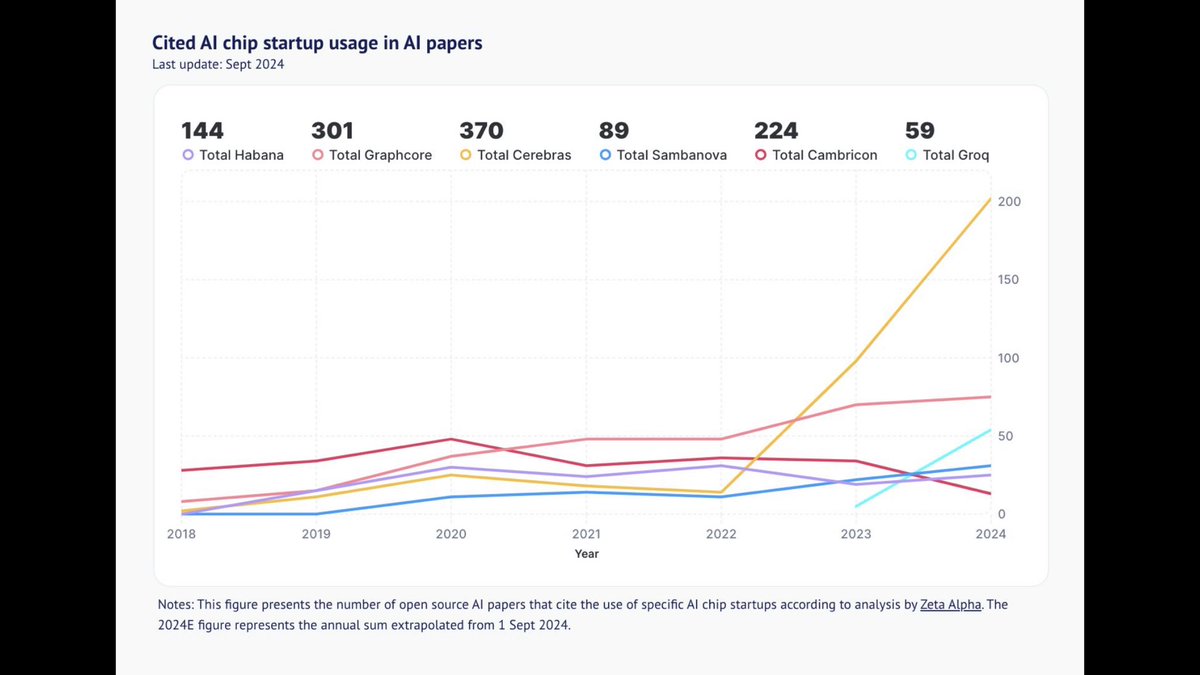
Top AI investor and researcher and market analyst @nathanbenaich updated @stateofaireport with #AI chip usage
 @CerebrasSystems doubled YoY.
@CerebrasSystems doubled YoY.
@graphcoreai
@SambaNovaAI
@GroqInc
@HabanaLabs
it’s how many AI startup chips are cited in AI research papers, a clever proxy
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@ArtificialAnlys
Cerebras continues to deliver output speed improvements, breaking the 2,000 tokens/s barrier on Llama 3.1 8B and 550 tokens/s on 70B
Since launching less than a month ago, @CerebrasSystems has continued to improve output speed inference performance on their custom chips.
We are now measuring 2,005 output tokens per second on @AIatMeta's Llama 3.1 8B and 566 output tokens per second on Llama 3.1 70B.
Faster output speed supports use-cases which require low-latency interactions including consumer applications (games, chatbots, etc) and new techniques of using the models such as agents and multi-query RAG.
Link to our comparison of Llama 3.1 70B and 8B providers below
2/11
@ArtificialAnlys
Analysis of Llama 3.1 70B providers:
https://artificialanalysis.ai/models/llama-3-1-instruct-70b/providers
Analysis of Llama 3.1 8B providers:
https://artificialanalysis.ai/models/llama-3-1-instruct-8b/providers
https://artificialanalysis.ai/models/llama-3-1-instruct-70b/providers
3/11
@linqtoinc
Incredible work @CerebrasSystems team!
4/11
@JonathanRoseD
Llama 405B when? I assume not soon because of the hardware—a chip that could handle that would be an absolute BEAST
5/11
@alby13
Why don't they talk about running Llama 3.1 405B?
6/11
@JERBAGSCRYPTO
When IPO
7/11
@itsTimDent
We need qwen or qwen coder similar output speeds.
8/11
@kalyan5v
Cerebras systems need lot of PR if it’s taking on /search?q=#NVDA
9/11
@pa_pfeiffer
How do you validate, that the model behind is actually Llama3.1 8B with full precision (bfloat16) and not something quantized, pruned or destilled?
10/11
@tristanbob
Amazing, congrats @CerebrasSystems!
11/11
@StartupHubAI
[Quoted tweet]
Top AI investor and researcher and market analyst @nathanbenaich updated @stateofaireport with #AI chip usage
@CerebrasSystems doubled YoY.@graphcoreai
@SambaNovaAI
@GroqInc
@HabanaLabs
it’s how many AI startup chips are cited in AI research papers, a clever proxyTo post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196















 Three model sizes: 1.5B, 7B, and 32B (coming soon) up to 128K tokens using YaRN
Three model sizes: 1.5B, 7B, and 32B (coming soon) up to 128K tokens using YaRN Pre-trained on 5.5 trillion tokens, post-trained on tens of millions example (no details on # tokens)
Pre-trained on 5.5 trillion tokens, post-trained on tens of millions example (no details on # tokens) 7:2:1 ratio of public code data, synthetic data, and text data outperformed other combinations, even those with more code proportion.
7:2:1 ratio of public code data, synthetic data, and text data outperformed other combinations, even those with more code proportion. Build scalable synthetic data generation using LLM scorers, checklist-based scoring, and sandbox for code verification to filter out low-quality data.
Build scalable synthetic data generation using LLM scorers, checklist-based scoring, and sandbox for code verification to filter out low-quality data. Trained on 92+ programming languages and Incorporated multilingual code instruction data
Trained on 92+ programming languages and Incorporated multilingual code instruction data To improve long context, create instruction pairs with FIM format using AST
To improve long context, create instruction pairs with FIM format using AST Adopted a two-stage post-training process—starting with diverse, low-quality data (tens of millions) for broad learning, followed by high-quality data with rejection sampling for refinement (millions).
Adopted a two-stage post-training process—starting with diverse, low-quality data (tens of millions) for broad learning, followed by high-quality data with rejection sampling for refinement (millions). Performed decontamination on all datasets (pre & post) to ensure integrity using a 10-gram overlap method
Performed decontamination on all datasets (pre & post) to ensure integrity using a 10-gram overlap method 7B Outperforms other open Code LLMs < 40B, including Mistral Codestral, or Deepseek
7B Outperforms other open Code LLMs < 40B, including Mistral Codestral, or Deepseek 7B matches OpenAI GPT-4 0613 on various benchmarks
7B matches OpenAI GPT-4 0613 on various benchmarks Released under Apache 2.0 and available on @huggingface
Released under Apache 2.0 and available on @huggingface


























 Q-Sparse can achieve results comparable to those of baseline LLMs while being much more efficient at inference time;
Q-Sparse can achieve results comparable to those of baseline LLMs while being much more efficient at inference time; We present an inference-optimal scaling law for sparsely-activated LLMs; As the total model size grows, the gap between sparsely-activated and dense model continuously narrows.
We present an inference-optimal scaling law for sparsely-activated LLMs; As the total model size grows, the gap between sparsely-activated and dense model continuously narrows. Q-Sparse is effective in different settings, including training-from-scratch, continue-training of off-the-shelf LLMs, and finetuning;
Q-Sparse is effective in different settings, including training-from-scratch, continue-training of off-the-shelf LLMs, and finetuning; Q-Sparse works for both full-precision and 1-bit LLMs (e.g., BitNet b1.58). Particularly, the synergy of BitNet b1.58 and Q-Sparse (can be equipped with MoE) provides the cornerstone and a clear path to revolutionize the efficiency of future LLMs.
Q-Sparse works for both full-precision and 1-bit LLMs (e.g., BitNet b1.58). Particularly, the synergy of BitNet b1.58 and Q-Sparse (can be equipped with MoE) provides the cornerstone and a clear path to revolutionize the efficiency of future LLMs.







 It’ll be second-rate, but people won’t care because they don’t want to go learn the first-rate alternative and get used to a brand new tool
It’ll be second-rate, but people won’t care because they don’t want to go learn the first-rate alternative and get used to a brand new tool
