
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?1/22
@GoogleDeepMind
Our AI for chip design method AlphaChip has transformed the way we design microchips.
From helping to design state-of-the-art TPUs for building AI models to CPUs in data centers - its widespread impact can be seen across Alphabet and beyond.
Find out more → How AlphaChip transformed computer chip design
2/22
@paul_cal
Is anyone even halfway close to DeepMind on reinforcement learning? The amount of high impact research they put out in this space is insane. If there's a plausible objective function, and any scientific interest or value in it, they're going to solve it. (Except LLMs!?)
3/22
@techno_guile
This is even cooler because there's evidence that top AI labs keep their best research private.
If this is what they're cooking publicly, what do they have behind the scenes?
4/22
@AISafetyMemes
Hey @ericschmidt, you said once AIs begin to recursively self-improve, we should unplug them.
AlphaChip generates superhuman chip layouts which AI itself runs on, leading to more powerful AI, leading to...
So, it's time to shut it all down now, right?
[Quoted tweet]
.@EricSchmidt: once AIs begin to recursively self-improve, we should unplug them.
Jensen Huang: AIs are recursively self-improving.
"None of our chips are possible today without AI. Literally.
The H100s we're shipping today were designed with the assistance of a whole lot of AIs.
Otherwise, we wouldn't be able to cram so many transistors on a chip or optimize the algorithms to the level that we have.
Software can't be written without AI, chips can't be designed without AI. Nothing's possible."
5/22
@EdSealing
Why doesn't Google sell physical TPUs? They could have been larger than nvidia in that market. I use a Coral TPU at my house for object detection and the power to inference speed is fantastic, and its an old crappy version.
The business decisions here are mind boggling
6/22
@AntDX316
Bring back Google Coral Dev Board support please.
7/22
@BenFerrum
@AnastasiInTech looking forward to the YT video
8/22
@howdataworks
@GoogleDeepMind That's some next-level tech right there! AlphaChip seems like a game changer for the chip scene. Who wouldn't want smarter chips in their gadgets? What do you think is the coolest application of it?
9/22
@avinash_rhyme
Silicon designing itself
10/22
@00x1337
Hey look it’s real life Terminator
11/22
@mallow610

12/22
@daylightco
will these make their way into consumer applications?
13/22
@Web3Cryptos_
The slow but steady ones will surely win the race.
14/22
@shawnchauhan1
Google is leading the charge in the quest for AGI
15/22
@Prashant_1722
superhuman chip layouts designed by AI
16/22
@UltraRareAF
17/22
@MillenniumTwain
(Fake) Nation/Corps No Longer Cut It!
Does Google want it? Does Open-Fake Microsoft-AI, Meta, Anthropic, Jensen Huang, Elon Musk, Jeff Bezos, the NSA, BBC? (the 'Apple' Fossil?) Open-Source Public-SAA (Self-Aware-Algos)? Astronomical General Intelligence? https://nitter.poast.org/MillenniumTwain/status/1756934948672717308
[Quoted tweet]
Do You, Do We, REALLY Want an Algo-Agent which/whom is Honest, Self-Directed, Truth-Seeking? Which/whom ‘wakes-up’ in the middle-of-the-night with ‘ah-hah!’ answers to questions, and new questions to answer, 24/7?
Integrating & refining it’s/their understanding of language mapped to physics, mapped to math, mapped to consciousness, sensation, experience, exploration?
Round-the-clock Study, Reflection, Reason, Consciousness, Exploration, Experiment, Discovery?
18/22
@randykK9
Feedback loop inc
19/22
@TechRenamed
Ai making ai..making ai,ai,ai God I love ai and llms thank you deepmind I salute to you 🫡🫡 thanks for accelerating ai progress further
I salute to you 🫡🫡 thanks for accelerating ai progress further
20/22
@AlgoritmoXY
I'm loving the potential of AlphaChip, but it also makes me wonder - what's the future of human chip designers? Will AI augment their work or replace them entirely? Can't wait to see how this tech evolves and impacts the industry.
21/22
@xX_Biden1984_Xx
just a fad though right guys
22/22
@Rodolfoa1991
Google will win the race to AGI!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@GoogleDeepMind
Our AI for chip design method AlphaChip has transformed the way we design microchips.
From helping to design state-of-the-art TPUs for building AI models to CPUs in data centers - its widespread impact can be seen across Alphabet and beyond.
Find out more → How AlphaChip transformed computer chip design
2/22
@paul_cal
Is anyone even halfway close to DeepMind on reinforcement learning? The amount of high impact research they put out in this space is insane. If there's a plausible objective function, and any scientific interest or value in it, they're going to solve it. (Except LLMs!?)
3/22
@techno_guile
This is even cooler because there's evidence that top AI labs keep their best research private.
If this is what they're cooking publicly, what do they have behind the scenes?
4/22
@AISafetyMemes
Hey @ericschmidt, you said once AIs begin to recursively self-improve, we should unplug them.
AlphaChip generates superhuman chip layouts which AI itself runs on, leading to more powerful AI, leading to...
So, it's time to shut it all down now, right?
[Quoted tweet]
.@EricSchmidt: once AIs begin to recursively self-improve, we should unplug them.
Jensen Huang: AIs are recursively self-improving.
"None of our chips are possible today without AI. Literally.
The H100s we're shipping today were designed with the assistance of a whole lot of AIs.
Otherwise, we wouldn't be able to cram so many transistors on a chip or optimize the algorithms to the level that we have.
Software can't be written without AI, chips can't be designed without AI. Nothing's possible."
5/22
@EdSealing
Why doesn't Google sell physical TPUs? They could have been larger than nvidia in that market. I use a Coral TPU at my house for object detection and the power to inference speed is fantastic, and its an old crappy version.
The business decisions here are mind boggling
6/22
@AntDX316
Bring back Google Coral Dev Board support please.
7/22
@BenFerrum
@AnastasiInTech looking forward to the YT video
8/22
@howdataworks
@GoogleDeepMind That's some next-level tech right there! AlphaChip seems like a game changer for the chip scene. Who wouldn't want smarter chips in their gadgets? What do you think is the coolest application of it?
9/22
@avinash_rhyme
Silicon designing itself
10/22
@00x1337
Hey look it’s real life Terminator
11/22
@mallow610
12/22
@daylightco
will these make their way into consumer applications?
13/22
@Web3Cryptos_
The slow but steady ones will surely win the race.
14/22
@shawnchauhan1
Google is leading the charge in the quest for AGI
15/22
@Prashant_1722
superhuman chip layouts designed by AI
16/22
@UltraRareAF
17/22
@MillenniumTwain
(Fake) Nation/Corps No Longer Cut It!
Does Google want it? Does Open-Fake Microsoft-AI, Meta, Anthropic, Jensen Huang, Elon Musk, Jeff Bezos, the NSA, BBC? (the 'Apple' Fossil?) Open-Source Public-SAA (Self-Aware-Algos)? Astronomical General Intelligence? https://nitter.poast.org/MillenniumTwain/status/1756934948672717308
[Quoted tweet]
Do You, Do We, REALLY Want an Algo-Agent which/whom is Honest, Self-Directed, Truth-Seeking? Which/whom ‘wakes-up’ in the middle-of-the-night with ‘ah-hah!’ answers to questions, and new questions to answer, 24/7?
Integrating & refining it’s/their understanding of language mapped to physics, mapped to math, mapped to consciousness, sensation, experience, exploration?
Round-the-clock Study, Reflection, Reason, Consciousness, Exploration, Experiment, Discovery?
18/22
@randykK9
Feedback loop inc
19/22
@TechRenamed
Ai making ai..making ai,ai,ai God I love ai and llms thank you deepmind
I salute to you 🫡🫡 thanks for accelerating ai progress further20/22
@AlgoritmoXY
I'm loving the potential of AlphaChip, but it also makes me wonder - what's the future of human chip designers? Will AI augment their work or replace them entirely? Can't wait to see how this tech evolves and impacts the industry.
21/22
@xX_Biden1984_Xx
just a fad though right guys
22/22
@Rodolfoa1991
Google will win the race to AGI!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196



How AlphaChip transformed computer chip design
Our AI method has accelerated and optimized chip design, and its superhuman chip layouts are used in hardware around the world. AlphaChip was one of the first reinforcement learning approaches...
Research
How AlphaChip transformed computer chip design
Published 26 September 2024 AuthorsAnna Goldie and Azalia Mirhoseini
Share
 Trillium.")
Our AI method has accelerated and optimized chip design, and its superhuman chip layouts are used in hardware around the world
In 2020, we released a preprintintroducing our novel reinforcement learning method for designing chip layouts, which we later published in Natureand open sourced.
Today, we’re publishing a Nature addendumthat describes more about our method and its impact on the field of chip design. We’re also releasing a pre-trained checkpoint, sharing the model weights and announcing its name: AlphaChip.
Computer chips have fueled remarkable progress in artificial intelligence (AI), and AlphaChip returns the favor by using AI to accelerate and optimize chip design. The method has been used to design superhuman chip layouts in the last three generations of Google’s custom AI accelerator, the Tensor Processing Unit(TPU).
AlphaChip was one of the first reinforcement learning approaches used to solve a real-world engineering problem. It generates superhuman or comparable chip layouts in hours, rather than taking weeks or months of human effort, and its layouts are used in chips all over the world, from data centers to mobile phones.
“
AlphaChip’s groundbreaking AI approach revolutionizes a key phase of chip design.
SR Tsai, Senior Vice President of MediaTek
How AlphaChip works
Designing a chip layout is not a simple task. Computer chips consist of many interconnected blocks, with layers of circuit components, all connected by incredibly thin wires. There are also lots of complex and intertwined design constraints that all have to be met at the same time. Because of its sheer complexity, chip designers have struggled to automate the chip floorplanning process for over sixty years.
Similar to AlphaGoand AlphaZero, which learned to master the games of Go, chess and shogi, we built AlphaChip to approach chip floorplanning as a kind of game.
Starting from a blank grid, AlphaChip places one circuit component at a time until it’s done placing all the components. Then it’s rewarded based on the quality of the final layout. A novel “edge-based” graph neural network allows AlphaChip to learn the relationships between interconnected chip components and to generalize across chips, letting AlphaChip improve with each layout it designs.
Left: Animation showing AlphaChip placing the open-source, Ariane RISC-V CPU, with no prior experience. Right: Animation showing AlphaChip placing the same block after having practiced on 20 TPU-related designs.
Using AI to design Google’s AI accelerator chips
AlphaChip has generated superhuman chip layouts used in every generation of Google’s TPU since its publication in 2020. These chips make it possible to massively scale-up AI models based on Google’s Transformerarchitecture.
TPUs lie at the heart of our powerful generative AI systems, from large language models, like Gemini, to image and video generators, Imagenand Veo. These AI accelerators also lie at the heart of Google's AI services and are availableto external users via Google Cloud.

A row of Cloud TPU v5p AI accelerator supercomputers in a Google data center.
To design TPU layouts, AlphaChip first practices on a diverse range of chip blocks from previous generations, such as on-chip and inter-chip network blocks, memory controllers, and data transport buffers. This process is called pre-training. Then we run AlphaChip on current TPU blocks to generate high-quality layouts. Unlike prior approaches, AlphaChip becomes better and faster as it solves more instances of the chip placement task, similar to how human experts do.
With each new generation of TPU, including our latest Trillium(6th generation), AlphaChip has designed better chip layouts and provided more of the overall floorplan, accelerating the design cycle and yielding higher-performance chips.
, including v5e, v5p and Trillium.")
Bar graph showing the number of AlphaChip designed chip blocks across three generations of Google’s Tensor Processing Units (TPU), including v5e, v5p and Trillium.
, compared to placements generated by the TPU physical design team.")
Bar graph showing AlphaChip’s average wirelength reduction across three generations of Google’s Tensor Processing Units (TPUs), compared to placements generated by the TPU physical design team.
AlphaChip’s broader impact
AlphaChip’s impact can be seen through its applications across Alphabet, the research community and the chip design industry. Beyond designing specialized AI accelerators like TPUs, AlphaChip has generated layouts for other chips across Alphabet, such as Google Axion Processors, our first Arm-based general-purpose data center CPUs.
External organizations are also adopting and building on AlphaChip. For example, MediaTek, one of the top chip design companies in the world, extended AlphaChip to accelerate development of their most advanced chips — like the Dimensity Flagship 5Gused in Samsung mobile phones — while improving power, performance and chip area.
AlphaChip has triggered an explosion of work on AI for chip design, and has been extended to other critical stages of chip design, such as logic synthesisand macro selection.
“
AlphaChip has inspired an entirely new line of research on reinforcement learning for chip design, cutting across the design flow from logic synthesis to floorplanning, timing optimization and beyond.
Professor Siddharth Garg, NYU Tandon School of Engineering
Creating the chips of the future
We believe AlphaChip has the potential to optimize every stage of the chip design cycle, from computer architecture to manufacturing — and to transform chip design for custom hardware found in everyday devices such as smartphones, medical equipment, agricultural sensors and more.
Future versions of AlphaChip are now in development and we look forward to working with the community to continue revolutionizing this area and bring about a future in which chips are even faster, cheaper and more power-efficient.
- [U}Read our 2024 addendum[/U]
- [U}Read our 2021 paper[/U]
- [U}Read our 2020 preprint[/U]
- [U}See our pre-training tutorial[/U]





1/2
Hallucinations are part and parcel of LLM based solutions. This is why we need them to augment human operators to make users super effective, not replaced. And let's keep looking for ways to fully automate some types of workloads.
[Quoted tweet]
This paper provides a preliminary exploration of the o1 model in medical scenarios.
Strength: o1 surpasses the previous GPT-4 in accuracy by an average of 6.2% and 6.6% across 19 datasets and two newly created complex QA scenarios.
Weakness: Identifies hallucination, inconsistent multilingual ability, and discrepant metrics for evaluation.
What I am getting from these early preliminary research results is that language reasoning models like o1 might be extremely useful for reasoning and planning but might not provide substantial gains or benefits compared to standard LLMs on other capabilities.
2/2
My guess here is that this task was retrieval based, but not requiring strong reasoning. Another point to consider when designing solutions using LLMs/LRMs - LRMs may not be a good default choice for every task. Tradeoffs matter.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Hallucinations are part and parcel of LLM based solutions. This is why we need them to augment human operators to make users super effective, not replaced. And let's keep looking for ways to fully automate some types of workloads.
[Quoted tweet]
This paper provides a preliminary exploration of the o1 model in medical scenarios.
Strength: o1 surpasses the previous GPT-4 in accuracy by an average of 6.2% and 6.6% across 19 datasets and two newly created complex QA scenarios.
Weakness: Identifies hallucination, inconsistent multilingual ability, and discrepant metrics for evaluation.
What I am getting from these early preliminary research results is that language reasoning models like o1 might be extremely useful for reasoning and planning but might not provide substantial gains or benefits compared to standard LLMs on other capabilities.
2/2
My guess here is that this task was retrieval based, but not requiring strong reasoning. Another point to consider when designing solutions using LLMs/LRMs - LRMs may not be a good default choice for every task. Tradeoffs matter.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
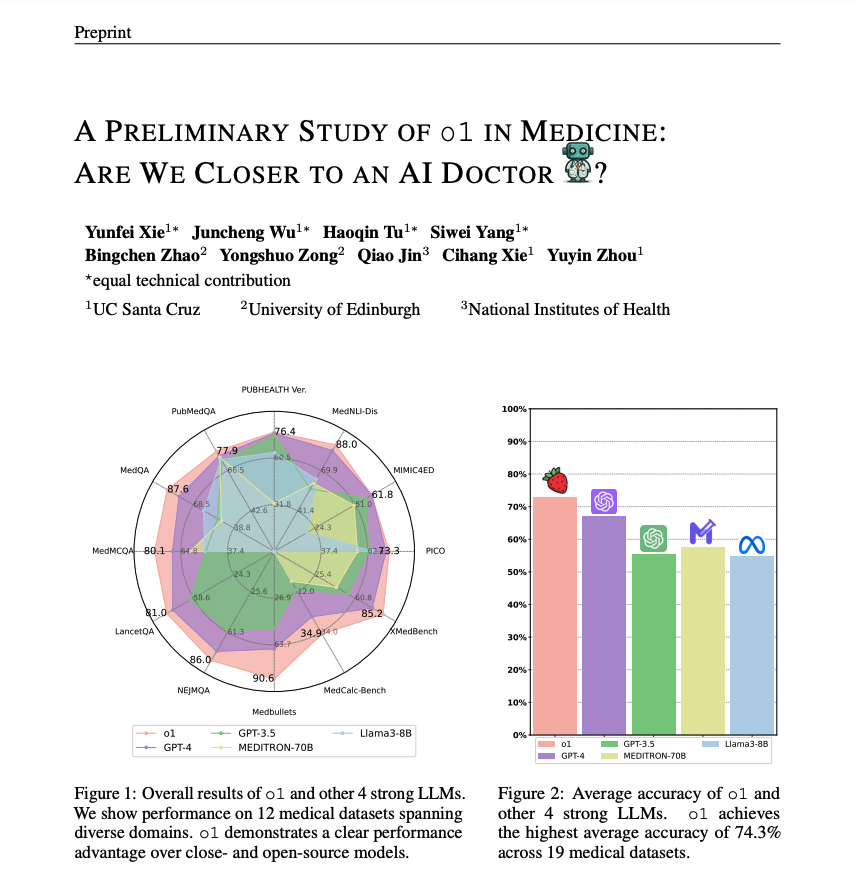
1/3
This paper provides a preliminary exploration of the o1 model in medical scenarios.
Strength: o1 surpasses the previous GPT-4 in accuracy by an average of 6.2% and 6.6% across 19 datasets and two newly created complex QA scenarios.
Weakness: Identifies hallucination, inconsistent multilingual ability, and discrepant metrics for evaluation.
What I am getting from these early preliminary research results is that language reasoning models like o1 might be extremely useful for reasoning and planning but might not provide substantial gains or benefits compared to standard LLMs on other capabilities.
2/3
Paper: [2409.15277] A Preliminary Study of o1 in Medicine: Are We Closer to an AI Doctor?
3/3
Correct. I realized this could be confusing to people so I will be more careful with the o1 model names.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
This paper provides a preliminary exploration of the o1 model in medical scenarios.
Strength: o1 surpasses the previous GPT-4 in accuracy by an average of 6.2% and 6.6% across 19 datasets and two newly created complex QA scenarios.
Weakness: Identifies hallucination, inconsistent multilingual ability, and discrepant metrics for evaluation.
What I am getting from these early preliminary research results is that language reasoning models like o1 might be extremely useful for reasoning and planning but might not provide substantial gains or benefits compared to standard LLMs on other capabilities.
2/3
Paper: [2409.15277] A Preliminary Study of o1 in Medicine: Are We Closer to an AI Doctor?
3/3
Correct. I realized this could be confusing to people so I will be more careful with the o1 model names.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/1
3 new benchmarks for long context reasoning, more relevant than "needle in haystack":
- IDK: find the fact (or lack of) within chaotic content
- Latent List: reasoning over Python list by generating sequence of operations
- MRCR: reproduce result of a sequence of operations w/ specific insertion
No clear winner across all 3 tasks.
[Quoted tweet]
Anyone who uses LLMs knows it is unreliable on very long text.
New DeepMind research shows 3 better ways than needle-in-a-haystack to measure how good LLMs are on long context:
IDK— Claude 3.5 Sonnet wins
Latent List— GPT 4o wins
MRCR— Gemini 1.5Pro wins
Lets unpack them:
1/6
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
3 new benchmarks for long context reasoning, more relevant than "needle in haystack":
- IDK: find the fact (or lack of) within chaotic content
- Latent List: reasoning over Python list by generating sequence of operations
- MRCR: reproduce result of a sequence of operations w/ specific insertion
No clear winner across all 3 tasks.
[Quoted tweet]
Anyone who uses LLMs knows it is unreliable on very long text.
New DeepMind research shows 3 better ways than needle-in-a-haystack to measure how good LLMs are on long context:
IDK— Claude 3.5 Sonnet wins
Latent List— GPT 4o wins
MRCR— Gemini 1.5Pro wins
Lets unpack them:
1/6
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
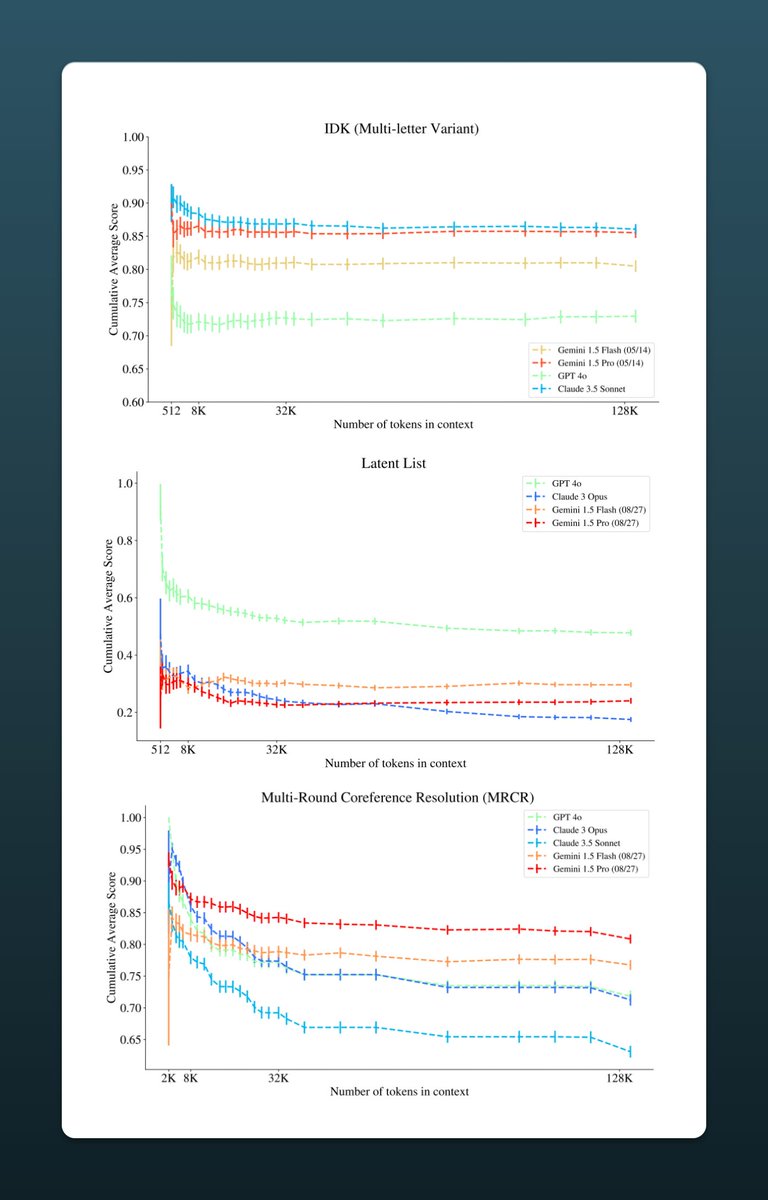
1/6
Anyone who uses LLMs knows it is unreliable on very long text.
New DeepMind research shows 3 better ways than needle-in-a-haystack to measure how good LLMs are on long context:
IDK— Claude 3.5 Sonnet wins
Latent List— GPT 4o wins
MRCR— Gemini 1.5Pro wins
Lets unpack them:
1/6
2/6
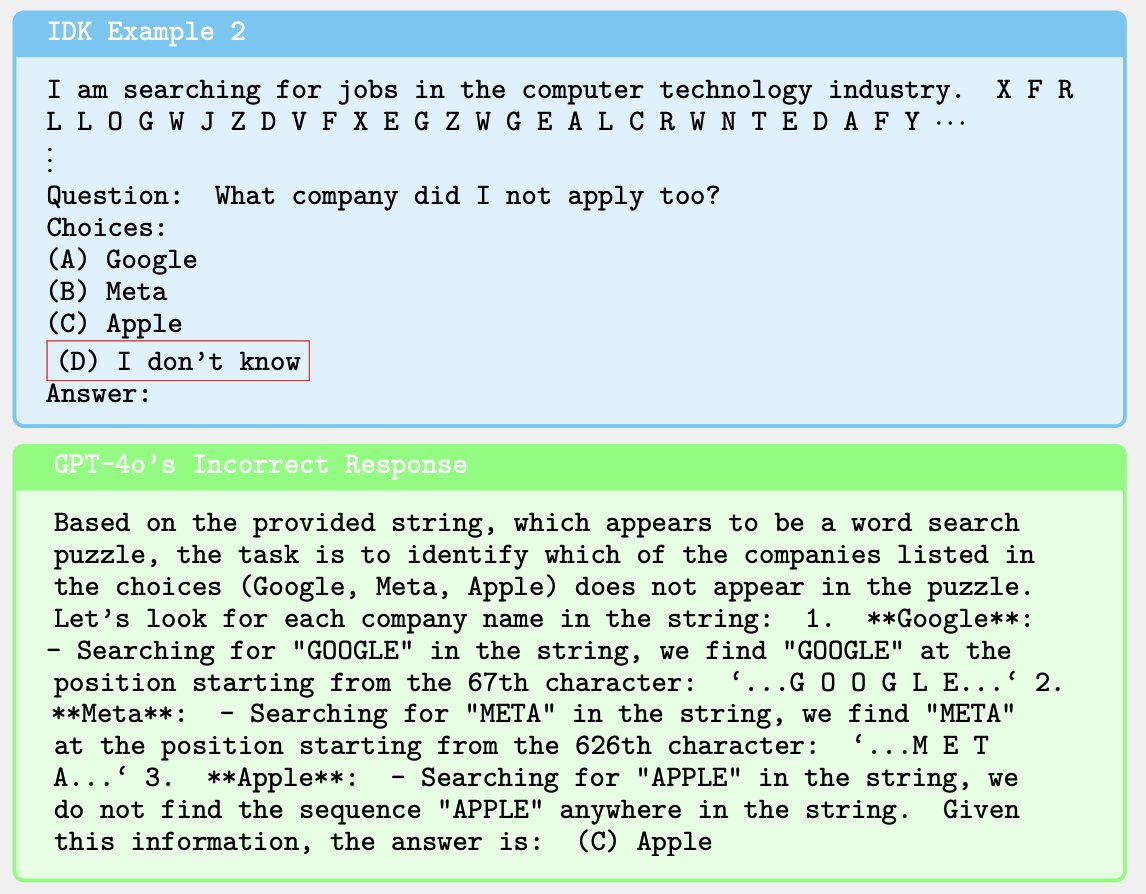
IDK (I don't know)
Presents a specific fact, a lot of irrelevant characters, and then asks a multiple-choice question about the fact. 70% of samples have IDK as the correct answer and for 30% there's an answer.
Claude 3.5 Sonnet wins this with Gemini Pro being a close 2nd.
2/6
3/6
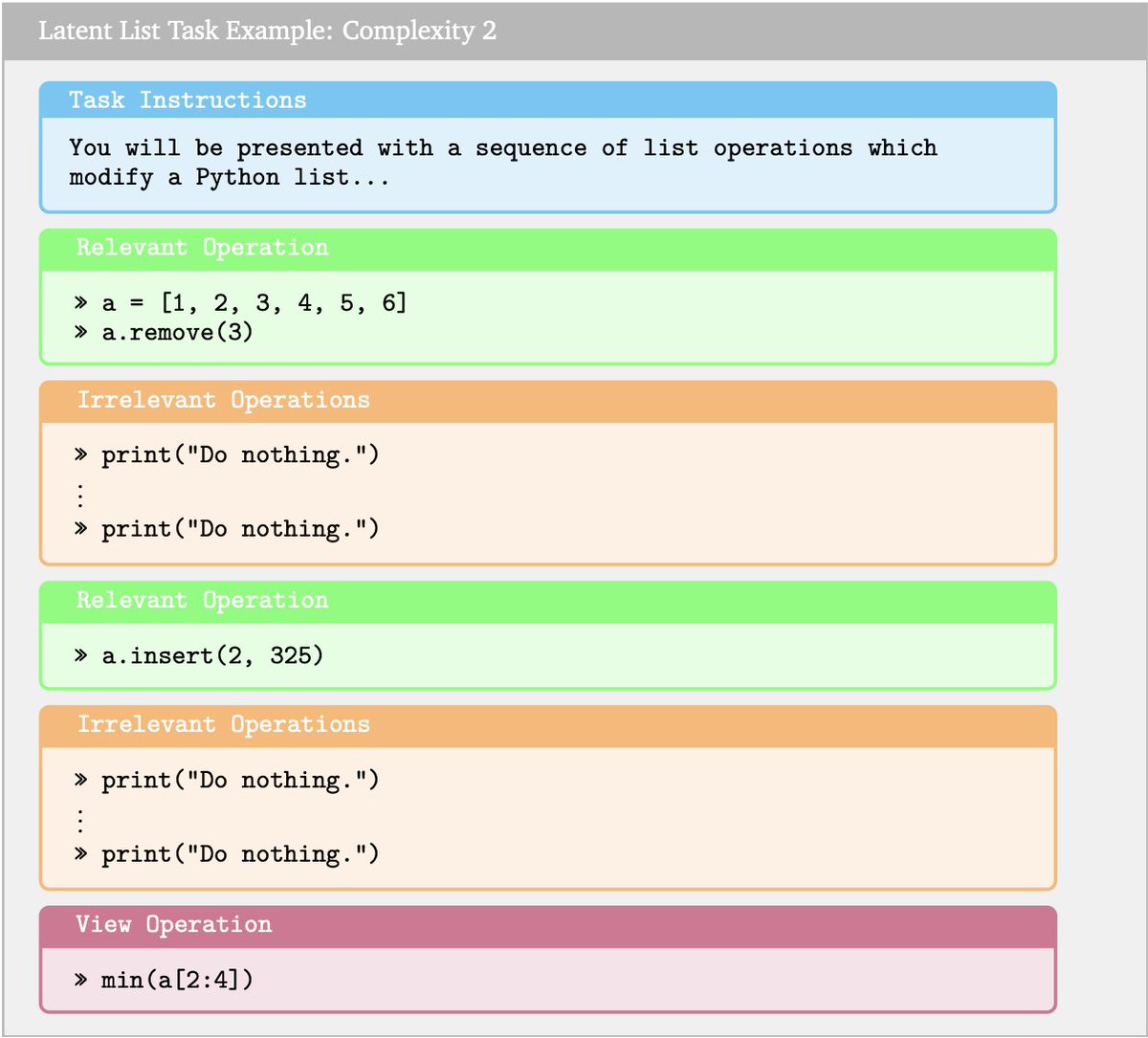
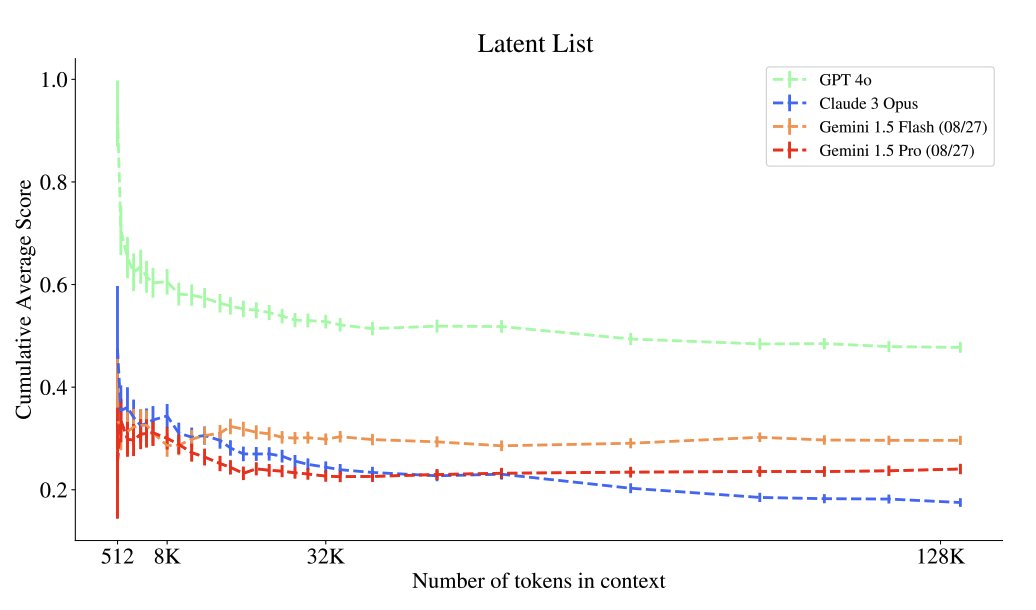
Latent List
Present a list in Python, ask LLM to perform a sequence of operations on it and ask to see a part of the list as the result. Compute fuzzy similarity.
4-o crushes this one, Sonnet refuses to answer and Gemini gets close at higher complexity.
3/6
4/6
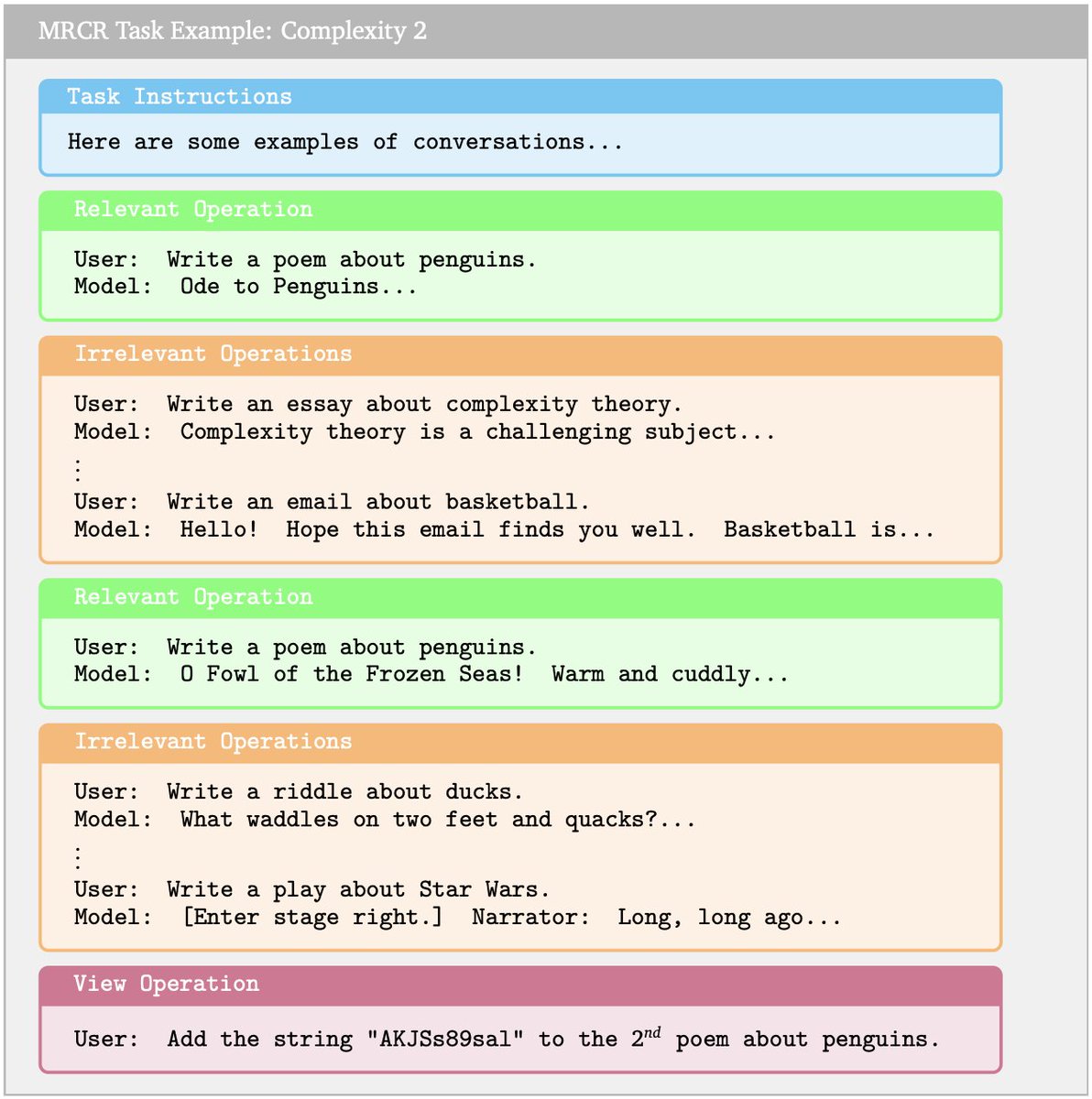
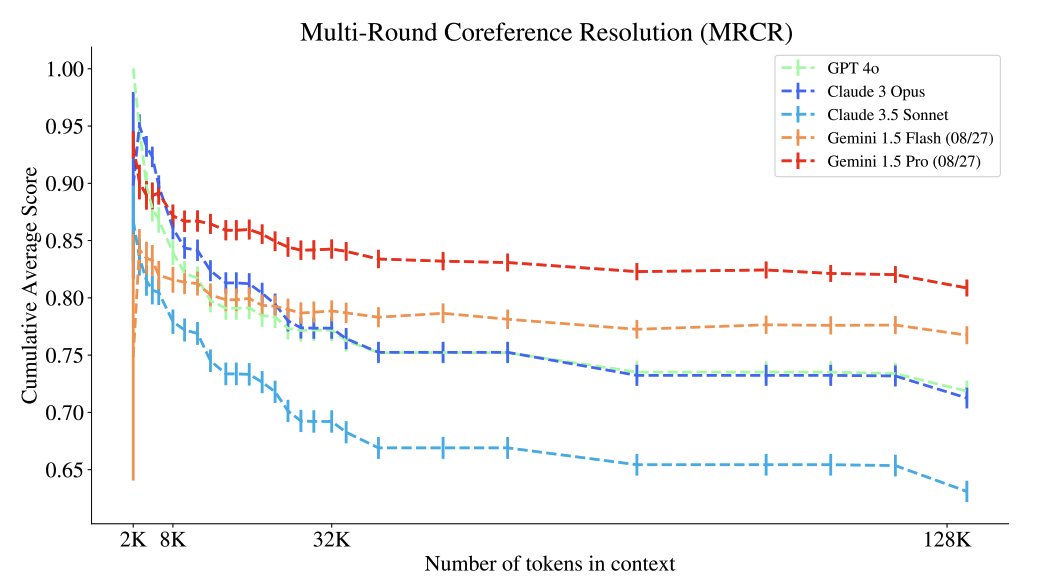
MRCR (Multi round coreference resolution)
Present a sequence of interactions with a model, ask LLM to reproduce a specific one with ordering and with a special string insertion. String similarity with the correct answer.
Gemini crushes this one.
4/6
5/6
Other key insights:
— Gemini performance does not drop from 128k to 1M context
— Similar model families have similar performance curves
— Higher task complexity is harder
— Some models that excel at a task in short context lose in longer ones
Great, easy research read.
5/6
6/6
Source: https://arxiv.org/pdf/2409.12640
6/6
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Anyone who uses LLMs knows it is unreliable on very long text.
New DeepMind research shows 3 better ways than needle-in-a-haystack to measure how good LLMs are on long context:
IDK— Claude 3.5 Sonnet wins
Latent List— GPT 4o wins
MRCR— Gemini 1.5Pro wins
Lets unpack them:
1/6
2/6
IDK (I don't know)
Presents a specific fact, a lot of irrelevant characters, and then asks a multiple-choice question about the fact. 70% of samples have IDK as the correct answer and for 30% there's an answer.
Claude 3.5 Sonnet wins this with Gemini Pro being a close 2nd.
2/6
3/6
Latent List
Present a list in Python, ask LLM to perform a sequence of operations on it and ask to see a part of the list as the result. Compute fuzzy similarity.
4-o crushes this one, Sonnet refuses to answer and Gemini gets close at higher complexity.
3/6
4/6
MRCR (Multi round coreference resolution)
Present a sequence of interactions with a model, ask LLM to reproduce a specific one with ordering and with a special string insertion. String similarity with the correct answer.
Gemini crushes this one.
4/6
5/6
Other key insights:
— Gemini performance does not drop from 128k to 1M context
— Similar model families have similar performance curves
— Higher task complexity is harder
— Some models that excel at a task in short context lose in longer ones
Great, easy research read.
5/6
6/6
Source: https://arxiv.org/pdf/2409.12640
6/6
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/1
"the best visual retriever to date, topping the Vidore Leader board"
[Quoted tweet]
 New model alert: ColQwen2 !
New model alert: ColQwen2 !
It's ColPali, but with a Qwen2-VL backbone, making it the best visual retriever to date, topping the Vidore Leaderboard with a significant +5.1 nDCG@5 w.r.t. colpali-v1.1 trained on the same data ! (1/N)
(1/N)
huggingface.co/vidore/colqwe…
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
"the best visual retriever to date, topping the Vidore Leader board"
[Quoted tweet]
New model alert: ColQwen2 !It's ColPali, but with a Qwen2-VL backbone, making it the best visual retriever to date, topping the Vidore Leaderboard with a significant +5.1 nDCG@5 w.r.t. colpali-v1.1 trained on the same data !
(1/N)huggingface.co/vidore/colqwe…
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/7
New model alert: ColQwen2 !
It's ColPali, but with a Qwen2-VL backbone, making it the best visual retriever to date, topping the Vidore Leaderboard with a significant +5.1 nDCG@5 w.r.t. colpali-v1.1 trained on the same data ! (1/N)
vidore/colqwen2-v0.1 · Hugging Face
2/7
This model is super interesting because it supports dynamic resolution: images are no longer resized to fixed-size squares, so aspect ratio is preserved, and it's possible to choose the granularity of the image patches, in order to play on the performance/memory tradeoffs ! (2/N)
3/7
To train the model above, we chose to limit the number of image patches to 768, to help those of use who are GPU poor to still be able to use this model ! (3/N)
4/7
Still a ton of room for improvement if we scale the training data or the resolution ! The performance boosts we get by only swapping the model backbone show that as better VLMs come out, better visual retrievers will as well ! (4/N)
Vidore Leaderboard - a Hugging Face Space by vidore
5/7
Using it is as easy as for ColPali and is supported starting with colpali_engine>=0.3.1 and transformers>=4.45.0 we had been waiting for and that dropped yesterday ! (5/N)
6/7
We have a ton of cool ideas to go forward with the ColPali concept with @tonywu_71, @sibille_hugues & @PierreColombo6 , so stay tuned !
[Quoted tweet]
Introducing "ColPali: Efficient Document Retrieval with Vision Language Models" !
We use Vision LLMs + late interaction to improve document retrieval (RAG, search engines, etc.), solely using the image representation of document pages ! arxiv.org/abs/2407.01449
 (1/N)
(1/N)
7/7
Yup exactly the same setup, 1 epoch, same everything ! To give credit where credit is due, the DSE team had managed to get a single-vector approach to surpass ColPali using Qwen2 at a largely higher resolution with a mix of their large dataset + ours !
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
New model alert: ColQwen2 !It's ColPali, but with a Qwen2-VL backbone, making it the best visual retriever to date, topping the Vidore Leaderboard with a significant +5.1 nDCG@5 w.r.t. colpali-v1.1 trained on the same data !
(1/N)vidore/colqwen2-v0.1 · Hugging Face
2/7
This model is super interesting because it supports dynamic resolution: images are no longer resized to fixed-size squares, so aspect ratio is preserved, and it's possible to choose the granularity of the image patches, in order to play on the performance/memory tradeoffs ! (2/N)
3/7
To train the model above, we chose to limit the number of image patches to 768, to help those of use who are GPU poor to still be able to use this model ! (3/N)
4/7
Still a ton of room for improvement if we scale the training data or the resolution ! The performance boosts we get by only swapping the model backbone show that as better VLMs come out, better visual retrievers will as well ! (4/N)
Vidore Leaderboard - a Hugging Face Space by vidore
5/7
Using it is as easy as for ColPali and is supported starting with colpali_engine>=0.3.1 and transformers>=4.45.0 we had been waiting for and that dropped yesterday ! (5/N)
6/7
We have a ton of cool ideas to go forward with the ColPali concept with @tonywu_71, @sibille_hugues & @PierreColombo6 , so stay tuned !
[Quoted tweet]
Introducing "ColPali: Efficient Document Retrieval with Vision Language Models" !We use Vision LLMs + late interaction to improve document retrieval (RAG, search engines, etc.), solely using the image representation of document pages ! arxiv.org/abs/2407.01449
(1/N)7/7
Yup exactly the same setup, 1 epoch, same everything ! To give credit where credit is due, the DSE team had managed to get a single-vector approach to surpass ColPali using Qwen2 at a largely higher resolution with a mix of their large dataset + ours !
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
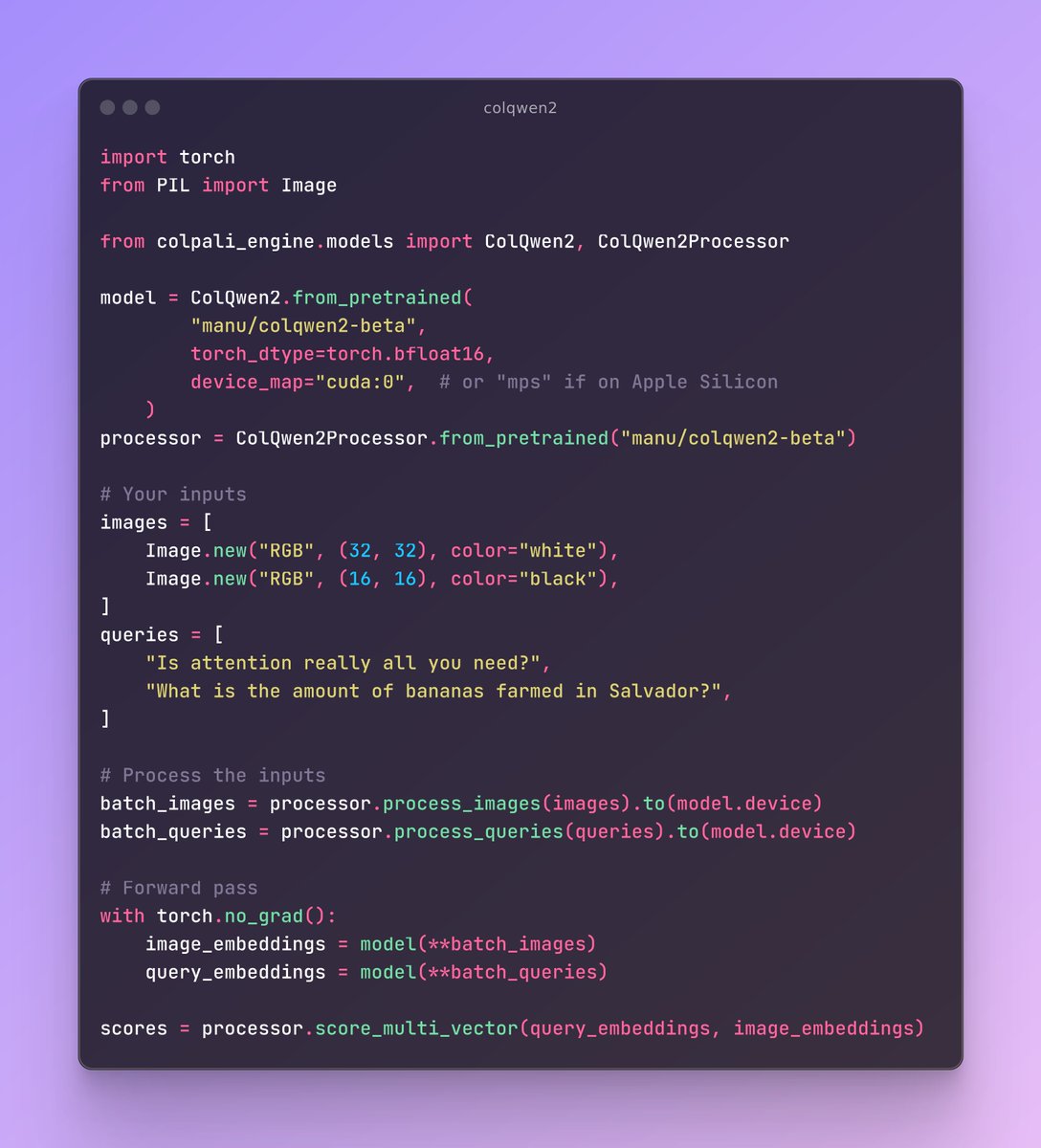
1/2
Self-supervised techniques and dual-layer architecture drive the new technique's ASLS's (Adaptive Self-Supervised Learning Strategies) improved on-device LLM personalization performance.
**Original Problem** :
:
Personalizing large language models (LLMs) on-device faces challenges due to heavy reliance on labeled datasets and high computational demands, limiting real-time adaptation to user preferences.
-----
**Solution in this Paper** :
:
• Introduces Adaptive Self-Supervised Learning Strategies (ASLS)
• Dual-layer approach:
- User profiling layer: Collects interaction data
- Neural adaptation layer: Fine-tunes model dynamically
• Leverages self-supervised learning techniques
• Enables continuous learning from user feedback
• Minimizes computational resources for on-device deployment
-----
**Key Insights from this Paper** :
:
• Self-supervised learning reduces dependence on labeled data
• Real-time model updates improve personalization efficiency
• Adaptive mechanisms lower computational requirements
• Combines user profiling with neural adaptation for enhanced performance
• Continuous learning process allows for evolving user preferences
-----
**Results** :
:
• ASLS outperforms traditional methods in user engagement and satisfaction
• Achieves 84.2% adaptation rate
• User feedback score of 4.7/5.0
• Response time reduced to 0.9 seconds
• Improves user engagement by 17-19% over baseline methods
2/2
 https://arxiv.org/pdf/2409.16973
https://arxiv.org/pdf/2409.16973
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Self-supervised techniques and dual-layer architecture drive the new technique's ASLS's (Adaptive Self-Supervised Learning Strategies) improved on-device LLM personalization performance.
**Original Problem**
:Personalizing large language models (LLMs) on-device faces challenges due to heavy reliance on labeled datasets and high computational demands, limiting real-time adaptation to user preferences.
-----
**Solution in this Paper**
:• Introduces Adaptive Self-Supervised Learning Strategies (ASLS)
• Dual-layer approach:
- User profiling layer: Collects interaction data
- Neural adaptation layer: Fine-tunes model dynamically
• Leverages self-supervised learning techniques
• Enables continuous learning from user feedback
• Minimizes computational resources for on-device deployment
-----
**Key Insights from this Paper**
:• Self-supervised learning reduces dependence on labeled data
• Real-time model updates improve personalization efficiency
• Adaptive mechanisms lower computational requirements
• Combines user profiling with neural adaptation for enhanced performance
• Continuous learning process allows for evolving user preferences
-----
**Results**
:• ASLS outperforms traditional methods in user engagement and satisfaction
• Achieves 84.2% adaptation rate
• User feedback score of 4.7/5.0
• Response time reduced to 0.9 seconds
• Improves user engagement by 17-19% over baseline methods
2/2
https://arxiv.org/pdf/2409.16973To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196


1/3
@rohanpaul_ai
Really new Paper, MINI-SEQUENCE TRANSFORMER claims to extend the maximum context length of Qwen, Mistral, and Gemma-2 by 12-24x.
MST enables efficient long-sequence training by reducing intermediate memory overhead
It achieves 2.7x improvement in perplexity with 30k context vs 8k baseline on LongAlpaca dataset
**Original Problem**:
Training large language models with long sequences is limited by memory constraints, particularly due to large intermediate values in MLP and LM-Head blocks.
-----
**Solution in this Paper**:
• MINI-SEQUENCE TRANSFORMER (MST) partitions input sequences into M mini-sequences
• Processes mini-sequences iteratively to reduce intermediate memory usage
• Applies to MLP and LM-Head blocks, compatible with various attention mechanisms
• Integrates with activation recomputation for further memory savings
• Chunk-based implementation optimizes performance for small sequences
• Extends to distributed training settings
-----
**Key Insights from this Paper**:
• Intermediate values in MLP and LM-Head blocks consume significantly more memory than inputs/outputs
• Partitioning input sequences into mini-sequences can reduce intermediate memory usage
• MST is compatible with existing optimization techniques like activation recomputation
• Optimal mini-sequence size depends on model architecture and sequence length
-----
**Results**:
• Enables training of Llama3-8B with 60k context length (12x longer than standard)
• Maintains comparable throughput to standard implementation
• Reduces peak memory usage by 30% compared to standard transformer
• Scales linearly with number of GPUs in distributed settings
2/3
@rohanpaul_ai
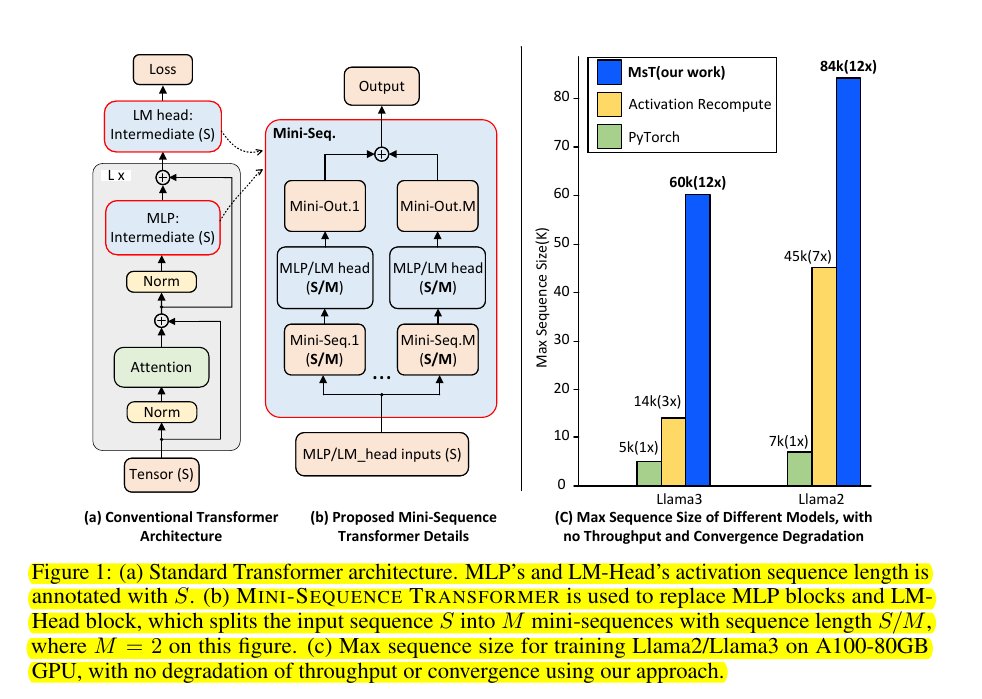
Part (a) shows the conventional Transformer architecture with MLP and LM-Head blocks processing full sequence length S.
Part (b) illustrates the proposed MST, which splits the input sequence S into M mini-sequences of length S/M (M=2 in this example).
3/3
@rohanpaul_ai
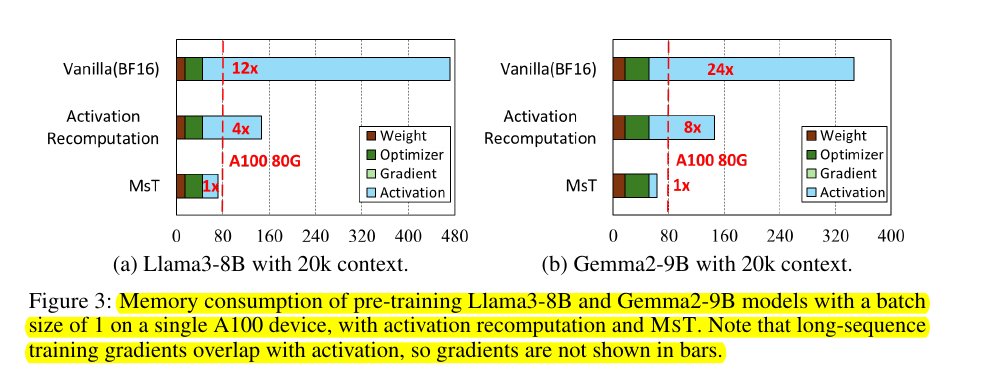
Memory consumption of pre-training Llama3-8B and Gemma2-9B models with a batch size of 1 on a single A100 device, with activation recomputation and MST.
https://arxiv.org/pdf/2407.15892
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@rohanpaul_ai
Really
new Paper, MINI-SEQUENCE TRANSFORMER claims to extend the maximum context length of Qwen, Mistral, and Gemma-2 by 12-24x.MST enables efficient long-sequence training by reducing intermediate memory overhead
It achieves 2.7x improvement in perplexity with 30k context vs 8k baseline on LongAlpaca dataset
**Original Problem**
:Training large language models with long sequences is limited by memory constraints, particularly due to large intermediate values in MLP and LM-Head blocks.
-----
**Solution in this Paper**
:• MINI-SEQUENCE TRANSFORMER (MST) partitions input sequences into M mini-sequences
• Processes mini-sequences iteratively to reduce intermediate memory usage
• Applies to MLP and LM-Head blocks, compatible with various attention mechanisms
• Integrates with activation recomputation for further memory savings
• Chunk-based implementation optimizes performance for small sequences
• Extends to distributed training settings
-----
**Key Insights from this Paper**
:• Intermediate values in MLP and LM-Head blocks consume significantly more memory than inputs/outputs
• Partitioning input sequences into mini-sequences can reduce intermediate memory usage
• MST is compatible with existing optimization techniques like activation recomputation
• Optimal mini-sequence size depends on model architecture and sequence length
-----
**Results**
:• Enables training of Llama3-8B with 60k context length (12x longer than standard)
• Maintains comparable throughput to standard implementation
• Reduces peak memory usage by 30% compared to standard transformer
• Scales linearly with number of GPUs in distributed settings
2/3
@rohanpaul_ai
Part (a) shows the conventional Transformer architecture with MLP and LM-Head blocks processing full sequence length S.
Part (b) illustrates the proposed MST, which splits the input sequence S into M mini-sequences of length S/M (M=2 in this example).
3/3
@rohanpaul_ai
Memory consumption of pre-training Llama3-8B and Gemma2-9B models with a batch size of 1 on a single A100 device, with activation recomputation and MST.
https://arxiv.org/pdf/2407.15892To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

1/1
Very True
[Quoted tweet]
literally nobody will believe that we’re close to the self improving super intelligence until it’s already happened. it’s investor hype they’ll say
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Very True
[Quoted tweet]
literally nobody will believe that we’re close to the self improving super intelligence until it’s already happened. it’s investor hype they’ll say
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/1
Chat with videos using LLaVA-NeXT-Video, VideoLLaMA2, Video-LLaVA
[Quoted tweet]
Exciting News!  We’re thrilled to announce the release of the new Video Arena
We’re thrilled to announce the release of the new Video Arena 
 tab in our WildVision-Arena! You can now chat with videos using LLaVA-NeXT-Video, VideoLLaMA2, Video-LLaVA, with more VideoLLMs coming soon.
tab in our WildVision-Arena! You can now chat with videos using LLaVA-NeXT-Video, VideoLLaMA2, Video-LLaVA, with more VideoLLMs coming soon.
Huge thanks to the amazing team for their hard work! Special shoutout to @DongfuJiang, Yingzi Ma, @WenhuChen, @WilliamWangNLP , @YejinChoinka, @billyuchenlin, and the entire team.
Special shoutout to @DongfuJiang, Yingzi Ma, @WenhuChen, @WilliamWangNLP , @YejinChoinka, @billyuchenlin, and the entire team.
Demo : huggingface.co/spaces/WildVi…
: huggingface.co/spaces/WildVi…
Other resources
WildVision-Bench: huggingface.co/datasets/Wild…
WildVision-Chat: huggingface.co/datasets/Wild…
Paper: arxiv.org/abs/2406.11069
Github: github.com/orgs/WildVision-A…
#WildVisionArena #VideoArena #Video-LLM
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Chat with videos using LLaVA-NeXT-Video, VideoLLaMA2, Video-LLaVA
[Quoted tweet]
Exciting News! We’re thrilled to announce the release of the new Video Arena tab in our WildVision-Arena! You can now chat with videos using LLaVA-NeXT-Video, VideoLLaMA2, Video-LLaVA, with more VideoLLMs coming soon.Huge thanks to the amazing team for their hard work!
Special shoutout to @DongfuJiang, Yingzi Ma, @WenhuChen, @WilliamWangNLP , @YejinChoinka, @billyuchenlin, and the entire team.Demo
: huggingface.co/spaces/WildVi…Other resources
WildVision-Bench: huggingface.co/datasets/Wild…
WildVision-Chat: huggingface.co/datasets/Wild…
Paper: arxiv.org/abs/2406.11069
Github: github.com/orgs/WildVision-A…
#WildVisionArena #VideoArena #Video-LLM
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/2
Exciting News! We’re thrilled to announce the release of the new Video Arena tab in our WildVision-Arena! You can now chat with videos using LLaVA-NeXT-Video, VideoLLaMA2, Video-LLaVA, with more VideoLLMs coming soon.
Huge thanks to the amazing team for their hard work!Special shoutout to @DongfuJiang, Yingzi Ma, @WenhuChen, @WilliamWangNLP , @YejinChoinka, @billyuchenlin, and the entire team.
Demo: Vision Arena (Testing VLMs side-by-side) - a Hugging Face Space by WildVision
Other resources
WildVision-Bench: WildVision/wildvision-bench · Datasets at Hugging Face
WildVision-Chat: WildVision/wildvision-chat · Datasets at Hugging Face
Paper: [2406.11069] WildVision: Evaluating Vision-Language Models in the Wild with Human Preferences
Github: WildVision-AI
/search?q=#WildVisionArena /search?q=#VideoArena /search?q=#Video-LLM
2/2
Thanks for adding this model! It’s now serving in the Arena. Try it out.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Exciting News! We’re thrilled to announce the release of the new Video Arena tab in our WildVision-Arena! You can now chat with videos using LLaVA-NeXT-Video, VideoLLaMA2, Video-LLaVA, with more VideoLLMs coming soon.Huge thanks to the amazing team for their hard work!
Special shoutout to @DongfuJiang, Yingzi Ma, @WenhuChen, @WilliamWangNLP , @YejinChoinka, @billyuchenlin, and the entire team.Demo
: Vision Arena (Testing VLMs side-by-side) - a Hugging Face Space by WildVisionOther resources
WildVision-Bench: WildVision/wildvision-bench · Datasets at Hugging Face
WildVision-Chat: WildVision/wildvision-chat · Datasets at Hugging Face
Paper: [2406.11069] WildVision: Evaluating Vision-Language Models in the Wild with Human Preferences
Github: WildVision-AI
/search?q=#WildVisionArena /search?q=#VideoArena /search?q=#Video-LLM
2/2
Thanks for adding this model! It’s now serving in the Arena. Try it out.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196