The startup from MIT's CSAIL says its Liquid Foundation Models have smaller memory needs thanks to a post-transformer architecture.

venturebeat.com
MIT spinoff Liquid debuts non-transformer AI models and they’re already state-of-the-art
Carl Franzen@carlfranzen
September 30, 2024 2:16 PM
Credit: VentureBeat made with OpenAI ChatGPT
Liquid AI, a startup co-founded by former researchers from the Massachusetts Institute of Technology (MIT)’s Computer Science and Artificial Intelligence Laboratory (CSAIL), has announced the
debut of its first multimodal AI models: the “Liquid Foundation Models (LFMs).”
Unlike most others of the current generative AI wave, these models are not based around the transformer architecture outlined in the
seminal 2017 paper “Attention Is All You Need.”
Instead, Liquid states that its goal “is to explore ways to build foundation models beyond Generative Pre-trained Transformers (GPTs)” and with the new LFMs, specifically building from “first principles…the same way engineers built engines, cars, and airplanes.”
It seems they’ve done just that — as the new LFM models already boast superior performance to other transformer-based ones of comparable size such as Meta’s Llama 3.1-8B and Microsoft’s Phi-3.5 3.8B.
Liquid’s LFMs currently come in three different sizes and variants:
- LFM 1.3B (smallest)
- LFM 3B
- LFM 40B MoE (largest, a “Mixture-of-Experts” model similar to Mistral’s Mixtral)
The “B” in their name stands for billion and refers the number of parameters — or settings — that govern the model’s information processing, analysis, and output generation. Generally, models with a higher number of parameters are more capable across a wider range of tasks.
Already, Liquid AI says the LFM 1.3B version outperforms
Meta’s new Llama 3.2-1.2B and
Microsoft’s Phi-1.5 on many leading third-party benchmarks including the popular Massive Multitask Language Understanding (MMLU) consisting of 57 problems across science, tech, engineering and math (STEM) fields, “the first time a non-GPT architecture significantly outperforms transformer-based models.”
All three are designed to offer state-of-the-art performance while optimizing for memory efficiency, with Liquid’s LFM-3B requiring only 16 GB of memory compared to the more than 48 GB required by Meta’s Llama-3.2-3B model (shown in the chart above).
Maxime Labonne, Head of Post-Training at Liquid AI,
took to his account on X to say the LFMs were “the proudest release of my career

” and to clarify that the core advantage of LFMs: their ability to outperform transformer-based models while using significantly less memory.
This is the proudest release of my career
At
@LiquidAI_, we're launching three LLMs (1B, 3B, 40B MoE) with SOTA performance, based on a custom architecture.
Minimal memory footprint & efficient inference bring long context tasks to edge devices for the first time!
pic.twitter.com/v9DelExyTa
— Maxime Labonne (@maximelabonne)
September 30, 2024
The models are engineered to be competitive not only on raw performance benchmarks but also in terms of operational efficiency, making them ideal for a variety of use cases, from enterprise-level applications specifically in the fields of financial services, biotechnology, and consumer electronics, to deployment on edge devices.
However, importantly for prospective users and customers, the models are not open source. Instead, users will need to access them through
Liquid’s inference playground,
Lambda Chat, or
Perplexity AI.
How Liquid is going ‘beyond’ the generative pre-trained transformer (GPT)
In this case, Liquid says it used a blend of “computational units deeply rooted in the theory of dynamical systems, signal processing, and numerical linear algebra,” and that the result is “general-purpose AI models that can be used to model any kind of sequential data, including video, audio, text, time series, and signals” to train its new LFMs.
Last year,
VentureBeat covered more about Liquid’s approach to training post-transformer AI models, noting at the time that it was using Liquid Neural Networks (LNNs), an architecture developer at CSAIL that seeks to make the artificial “neurons” or nodes for transforming data, more efficient and adaptable.
Unlike traditional deep learning models, which require thousands of neurons to perform complex tasks, LNNs demonstrated that fewer neurons—combined with innovative mathematical formulations—could achieve the same results.
Liquid AI’s new models retain the core benefits of this adaptability, allowing for real-time adjustments during inference without the computational overhead associated with traditional models, handling up to 1 million tokens efficiently, while keeping memory usage to a minimum.
A chart from the Liquid blog shows that the LFM-3B model, for instance, outperforms popular models like Google’s Gemma-2, Microsoft’s Phi-3, and Meta’s Llama-3.2 in terms of inference memory footprint, especially as token length scales.
While other models experience a sharp increase in memory usage for long-context processing, LFM-3B maintains a significantly smaller footprint, making it highly suitable for applications requiring large volumes of sequential data processing, such as document analysis or chatbots.
Liquid AI has built its foundation models to be versatile across multiple data modalities, including audio, video, and text.
With this multimodal capability, Liquid aims to address a wide range of industry-specific challenges, from financial services to biotechnology and consumer electronics.
Accepting invitations for launch event and eyeing future improvements
Liquid AI says it is is optimizing its models for deployment on hardware from NVIDIA, AMD, Apple, Qualcomm, and Cerebras.
While the models are still in the preview phase, Liquid AI invites early adopters and developers to test the models and provide feedback.
Labonne noted that while things are “not perfect,” the feedback received during this phase will help the team refine their offerings in preparation for a full launch event on October 23, 2024, at MIT’s Kresge Auditorium in Cambridge, MA. The company is accepting
RSVPs for attendees of that event in-person here.
As part of its commitment to transparency and scientific progress, Liquid says it will release a series of technical blog posts leading up to the product launch event.
The company also plans to engage in red-teaming efforts, encouraging users to test the limits of their models to improve future iterations.
With the introduction of Liquid Foundation Models, Liquid AI is positioning itself as a key player in the foundation model space. By combining state-of-the-art performance with unprecedented memory efficiency, LFMs offer a compelling alternative to traditional transformer-based models.

 Still relying on human-crafted rules to improve pretraining data? Time to try Programming Every Example(ProX)! Our latest efforts use LMs to refine data with unprecedented accuracy, and brings up to 20x faster training in general and math domain!
Still relying on human-crafted rules to improve pretraining data? Time to try Programming Every Example(ProX)! Our latest efforts use LMs to refine data with unprecedented accuracy, and brings up to 20x faster training in general and math domain! Curious about the details?
Curious about the details? Pre-training large language models (LLMs) typically relies on static, human-crafted rules for data refinement. While useful, these rules can’t adapt to the diverse examples in the data.
Pre-training large language models (LLMs) typically relies on static, human-crafted rules for data refinement. While useful, these rules can’t adapt to the diverse examples in the data.
 Enter ProX, where we treat data refinement as a programming task! Instead of fixed rules, ProX empowers LMs to generate tailored refining programs for each sample. Even with models as small as 0.3B parameters
Enter ProX, where we treat data refinement as a programming task! Instead of fixed rules, ProX empowers LMs to generate tailored refining programs for each sample. Even with models as small as 0.3B parameters , ProX’s approach can surpass human-level quality greatly!
, ProX’s approach can surpass human-level quality greatly!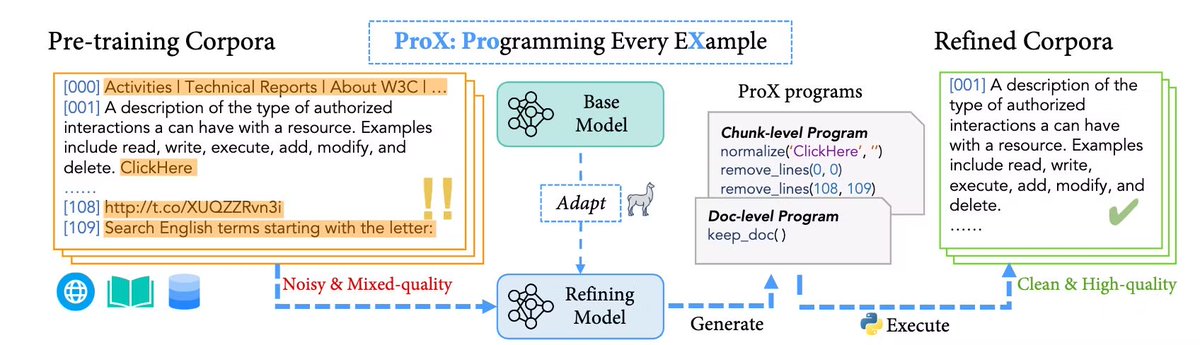
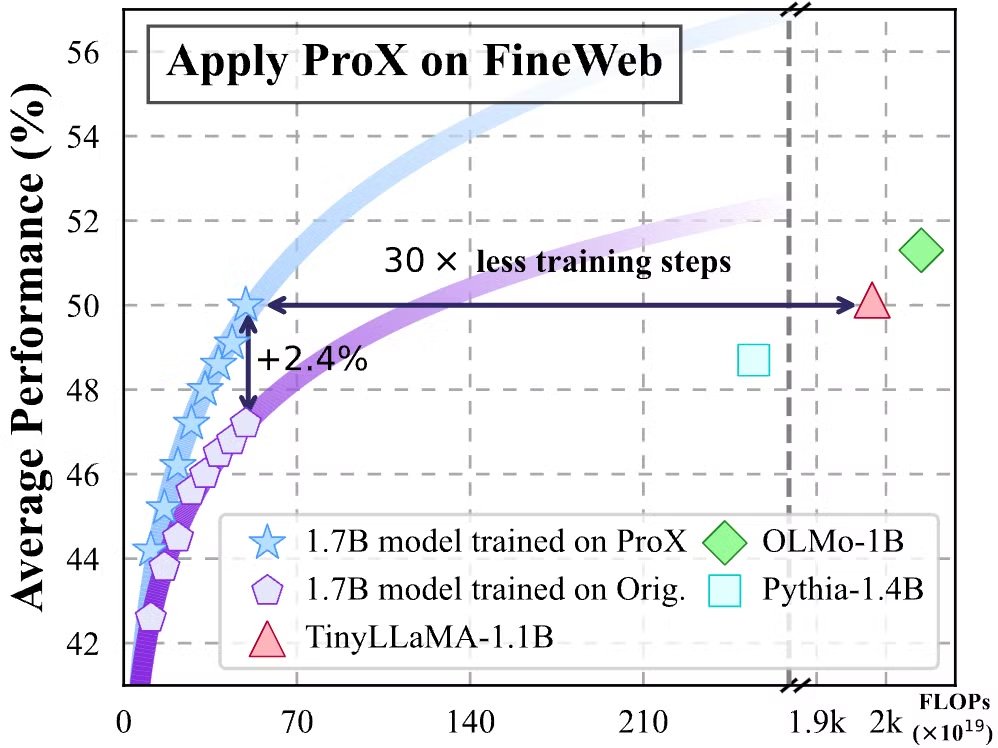
 The results? Models trained on ProX-refined data show > 2% gains on 10 downstream benchmarks. Plus, models trained on 50B tokens achieve comparable performance to those trained on 3T tokens
The results? Models trained on ProX-refined data show > 2% gains on 10 downstream benchmarks. Plus, models trained on 50B tokens achieve comparable performance to those trained on 3T tokens  .
.
 ProX also SHINES in domain-specific continual pre-training! On math domain, models trained on ProX surprisingly saw 7%~20% improvement with just 10B tokens! This means ProX achieves performance on par with existing models using 20x fewer tokens, excelling its efficiency!
ProX also SHINES in domain-specific continual pre-training! On math domain, models trained on ProX surprisingly saw 7%~20% improvement with just 10B tokens! This means ProX achieves performance on par with existing models using 20x fewer tokens, excelling its efficiency!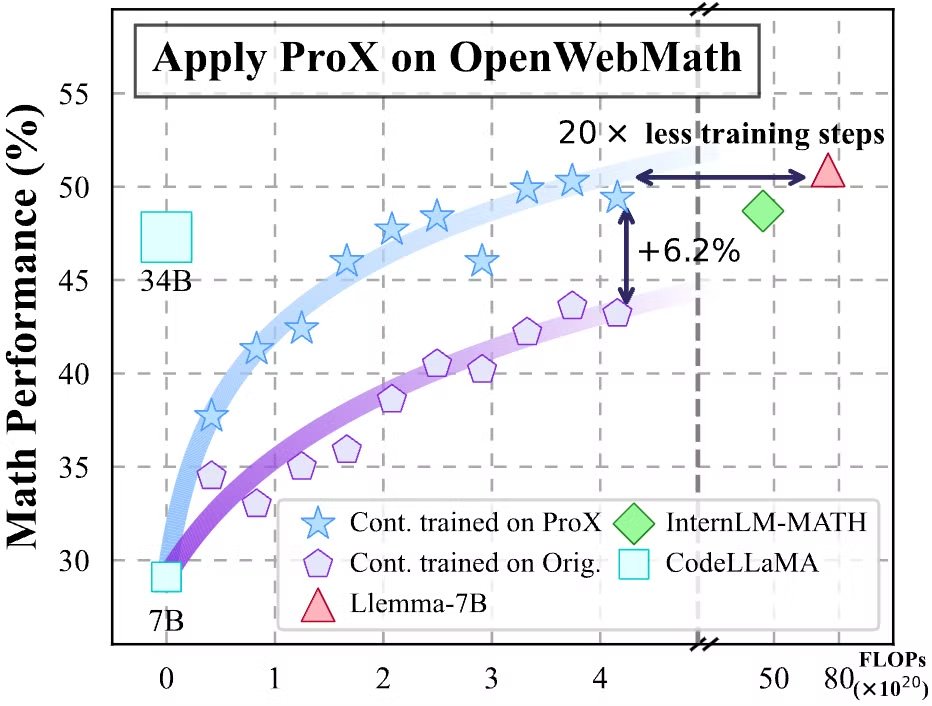
 Analysis shows investing FLOPs in data refinement actually helps SAVING computing FLOPs. With the trained model getting larger, achieving same performance via ProX will actually save more FLOPs. In preliminary experiments, we could save about 40% for 1.7B models!
Analysis shows investing FLOPs in data refinement actually helps SAVING computing FLOPs. With the trained model getting larger, achieving same performance via ProX will actually save more FLOPs. In preliminary experiments, we could save about 40% for 1.7B models!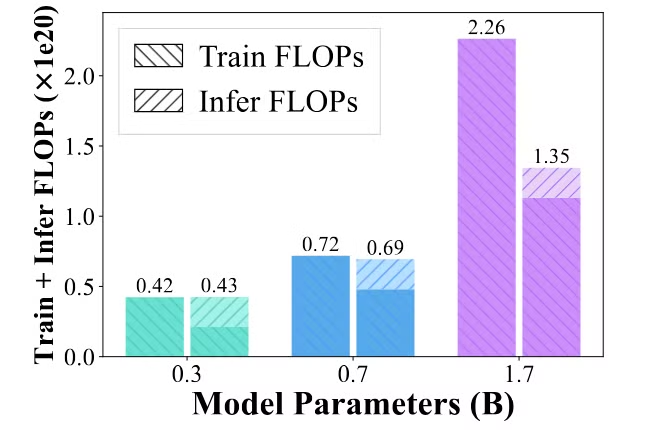
 We believe ProX is a step toward making pre-training more efficient by investing more in data refinement. And we also believe that
We believe ProX is a step toward making pre-training more efficient by investing more in data refinement. And we also believe that  inference time scaling
inference time scaling
 Learn more about ProX and stay tuned at:
Learn more about ProX and stay tuned at: GitHub Repo:
GitHub Repo:  Hugging Face:
Hugging Face:  Paper:
Paper: 
 )
) : Google’s NotebookLM could let users build custom chatbots from notebooks.
: Google’s NotebookLM could let users build custom chatbots from notebooks.