
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?
Have AI image generators assimilated your art? New tool lets you check
New search engine combs through harvested images used to train Stable Diffusion, others.
 arstechnica.com
arstechnica.com
Have AI image generators assimilated your art? New tool lets you check
New search engine combs through harvested images used to train Stable Diffusion, others.
BENJ EDWARDS - 9/15/2022, 5:04 PM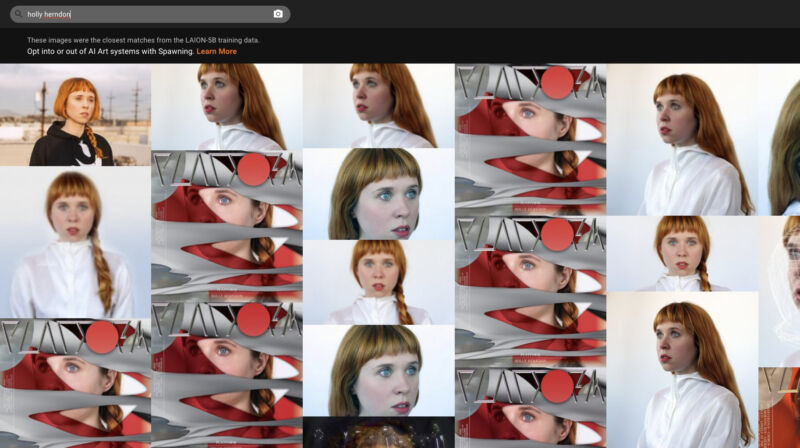
Enlarge / An image of the "Have I Been Trained?" website featuring a search for one of its creators, Holly Herndon.
In response to controversy over image synthesis models learning from artists' images scraped from the Internet without consent—and potentially replicating their artistic styles—a group of artists has released a new website that allows anyone to see if their artwork has been used to train AI.
The website "Have I Been Trained?" taps into the LAION-5B training data used to train Stable Diffusion and Google's Imagen AI models, among others. To build LAION-5B, bots directed by a group of AI researchers crawled billions of websites, including large repositories of artwork at DeviantArt, ArtStation, Pinterest, Getty Images, and more. Along the way, LAION collected millions of images from artists and copyright holders without consultation, which irritated some artists.
When visiting the Have I Been Trained? website, which is run by a group of artists called Spawning, users can search the data set by text (such as an artist's name) or by an image they upload. They will see image results alongside caption data linked to each image. It is similar to an earlier LAION-5B search tool created by Romain Beaumont and a recent effort by Andy Baio and Simon Willison, but with a slick interface and the ability to do a reverse image search.
Any matches in the results mean that the image could have potentially been used to train AI image generators and might still be used to train tomorrow's image synthesis models. AI artists can also use the results to guide more accurate prompts.
Spawning's website is part of the group's goal to establish norms around obtaining consent from artists to use their images in future AI training efforts, including developing tools that aim to let artists opt in or out of AI training.
A cornucopia of data

Enlarge / An assortment of robot portraits generated by Stable Diffusion, each combining elements learned from different artists.
Lexica
As mentioned above, image synthesis models (ISMs) like Stable Diffusion learn to generate images by analyzing millions of images scraped from the Internet. These images are valuable for training purposes because they have labels (often called metadata) attached, such as captions and alt text. The link between this metadata and the images lets ISMs learn associations between words (such as artist names) and image styles.
When you type in a prompt like, "a painting of a cat by Leonardo DaVinci," the ISM references what it knows about every word in that phrase, including images of cats and DaVinci's paintings, and how the pixels in those images are usually arranged in relationship to each other. Then it composes a result that combines that knowledge into a new image. If a model is trained properly, it will never return an exact copy of an image used to train it, but some images might be similar in style or composition to the source material.
It would be impractical to pay humans to manually write descriptions of billions of images for an image data set (although it has been attempted at a much smaller scale), so all the "free" image data on the Internet is a tempting target for AI researchers. They don't seek consent because the practice appears to be legal due to US court decisions on Internet data scraping. But one recurring theme in AI news stories is that deep learning can find new ways to use public data that wasn't previously anticipated—and do it in ways that might violate privacy, social norms, or community ethics even if the method is technically legal.
It's worth noting that people using AI image generators usually reference artists (usually more than one at a time) to blend artistic styles into something new and not in a quest to commit copyright infringement or nefariously imitate artists. Even so, some groups like Spawning feel that consent should always be part of the equation—especially as we venture into this uncharted, rapidly developing territory.
Have I Been Trained?

LLaMA Model: Sparking an Open-Source Wave in AI Language Models
The LLaMA (Language Model at Meta AI) has emerged as a foundational open-source language model, paving the way for a variety of accessible and affordable AI chatbot solutions. In this article, we will explore how the LLaMA model has inspired the development of several open-source chatbot models...
 www.quantitative-research-trading.com
www.quantitative-research-trading.com
LLaMA Model: Sparking an Open-Source Wave in AI Language Models
The LLaMA (Language Model at Meta AI) has emerged as a foundational open-source language model, paving the way for a variety of accessible and affordable AI chatbot solutions. In this article, we will explore how the LLaMA model has inspired the development of several open-source chatbot models, including Alpaca, Vicuna-13B, Koala, and GPT4ALL. We will discuss their key features and applications, highlighting how they have evolved from the LLaMA model to cater to the diverse needs of researchers and developers in the AI community.
- LLaMA - A foundational, 65-billion-parameter large language model

Credit image: Meta
Key takeaways and features about the model:
- Foundational large language model: LLaMA (Large Language Model Meta AI) is a state-of-the-art foundational large language model released by Meta to help researchers advance in AI subfields.
- Democratizing access: LLaMA aims to democratize access to large language models, especially for researchers without extensive infrastructure.
- Smaller and more performant: LLaMA is designed to be smaller and more efficient, requiring less computing power and resources for training and experimentation.
- Ideal for fine-tuning: Foundation models like LLaMA train on a large set of unlabeled data, making them suitable for fine-tuning on various tasks.
- Multiple sizes available: LLaMA is available in several sizes, including 7B, 13B, 33B, and 65B parameters.
- Model card and Responsible AI practices: Meta shares a LLaMA model card that details the model's development in line with Responsible AI practices.
- Accessibility: LLaMA addresses the limited research access to large language models by providing a more resource-efficient alternative.
- Training on tokens: LLaMA models are trained on a large number of tokens, making them easier to retrain and fine-tune for specific use cases.
- Multilingual training: The model is trained on text from the 20 languages with the most speakers, focusing on Latin and Cyrillic alphabets.
- Addressing challenges: LLaMA shares challenges like bias, toxicity, and hallucinations with other large language models. Releasing the code allows researchers to test new approaches to mitigate these issues.
- Noncommercial research license: LLaMA is released under a noncommercial license focused on research use cases, with access granted on a case-by-case basis.
- Collaborative development: Meta emphasizes the need for collaboration between academic researchers, civil society, policymakers, and industry to develop responsible AI guidelines and large language models.
- Alpaca - fine-tuned from Meta's LLaMA 7B model

Image credits : Alpaca
Key takeaways and features about the Alpaca model:
- Fine-tuned from Meta's LLaMA 7B: Alpaca is an instruction-following language model, fine-tuned from Meta's recently released LLaMA 7B model.
- Trained on 52K instruction-following demonstrations: The model is trained using demonstrations generated in the style of self-instruct using OpenAI's text-davinci-003, resulting in 52K unique instructions and corresponding outputs, which costed less than $500 using the OpenAI API.
- Surprisingly small and easy to reproduce: Despite its modest size and training data, Alpaca exhibits similar performance to OpenAI's text-davinci-003, demonstrating the effectiveness of the fine-tuning process.
- Accessible for academic research: Alpaca is designed to facilitate academic research on instruction-following models, as it provides a relatively lightweight model that is easy to reproduce under an academic budget.
- Non-commercial use: The model is intended for academic research only, with commercial use strictly prohibited.
- Similar performance to OpenAI's text-davinci-003: Preliminary evaluation shows that Alpaca has comparable performance to OpenAI's text-davinci-003 in terms of human evaluation on diverse instruction sets.
- Known limitations: Alpaca shares common language model issues, such as hallucination, toxicity, and stereotypes. These limitations highlight the need for further research and improvements in language models.
- Assets provided for the research community: The authors release various assets, including a demo, data, data generation process, and training code, to enable the academic community to conduct controlled scientific studies and improve instruction-following models.
- Future research directions: The release of Alpaca opens up opportunities for more rigorous evaluation, safety improvements, and a deeper understanding of how capabilities arise from the training recipe.
- Collaboration and open efforts: Alpaca's development relies on collaboration and builds upon existing works from Meta AI Research, the self-instruct team, Hugging Face, and OpenAI, highlighting the importance of open efforts in AI research.
{continued}

Image credit : source
Key takeaways and features about the Vicuna-13B model:

Image credit: source
Key takeaways and features about the Koala model:

Image credit: source
Key takeaways from the GPT4All technical report:
- Vicuna-13B - Model from UC Berkeley, CMU, Stanford, and UC San Diego Researchers
Image credit : source
Key takeaways and features about the Vicuna-13B model:
- High-quality performance: Vicuna-13B is an open-source chatbot that demonstrates high-quality performance, rivaling OpenAI ChatGPT and Google Bard.
- Fine-tuned on LLaMA: The chatbot has been fine-tuned on LLaMA using user-shared conversations collected from ShareGPT.
- Affordable training cost: The cost of training Vicuna-13B is approximately $300.
- Impressive evaluation results: Vicuna-13B achieves over 90% quality of OpenAI ChatGPT and Google Bard, outperforming other models like LLaMA and Stanford Alpaca in over 90% of cases.
- Open-source availability: The researchers have made the training and serving code, along with an online demo, available for non-commercial use.
- Efficient training process: Vicuna-13B is trained using PyTorch FSDP on eight A100 GPUs, taking only one day to complete.
- Flexible serving system: The serving system can handle multiple models with distributed workers and supports GPU workers from both on-premise clusters and the cloud.
- Evaluation framework: The researchers proposed an evaluation framework based on GPT-4 to automate chatbot performance assessment, using eight question categories to test the performance of five chatbots.
- Evaluation limitations: The proposed evaluation framework is not yet rigorous or mature, as large language models may hallucinate, and a comprehensive evaluation system for chatbots is still needed.
- Model limitations: Vicuna-13B has limitations, including poor performance on tasks involving reasoning or mathematics, and potential safety issues, such as mitigating toxicity or bias.
- Safety measures: The OpenAI moderation API is used to filter out inappropriate user inputs in the online demo.
- Open starting point for research: The researchers anticipate that Vicuna-13B will serve as an open starting point for future research to tackle its limitations.
- Released resources: The Vicuna-13B model weights, training, serving, and evaluation code have been released on GitHub, with the online demo intended for non-commercial use only.
- Koala - Model from Berkeley AI Research Institute
Image credit: source
Key takeaways and features about the Koala model:
- Fine-tuned on LLaMA: Koala is a chatbot fine-tuned on Meta's LLaMA, leveraging dialogue data gathered from the web and public datasets.
- Competitive performance: Koala effectively responds to user queries, outperforming Alpaca and tying or exceeding ChatGPT in over half of the cases.
- Emphasis on high-quality data: The study highlights the importance of carefully curated, high-quality datasets for training smaller models, which can approach the capabilities of larger closed-source models.
- Accessible research prototype: Although Koala has limitations, it is designed to encourage researchers' engagement in uncovering unexpected features and addressing potential issues.
- Diverse training data: Koala incorporates various datasets such as ShareGPT, HC3, OIG, Stanford Alpaca, Anthropic HH, OpenAI WebGPT, and OpenAI Summarization, conditioning the model on human preference markers to improve performance.
- Efficient training and cost-effective: Implemented with JAX/Flax in the EasyLM framework, Koala's training takes 6 hours on a single Nvidia DGX server with 8 A100 GPUs and costs less than $100 using preemptible instances on public cloud platforms.
- Evaluation comparisons: Koala-Distill (distillation data only) and Koala-All (distillation and open-source data) are compared, revealing that Koala-Distill performs slightly better, emphasizing the quality of ChatGPT dialogues.
- Test sets for evaluation: The Alpaca test set and the Koala test set are used for evaluation, with Koala-All showing better performance on real user queries in the Koala test set.
- Implications for future models: The results suggest that smaller models can achieve competitive performance with carefully curated, high-quality data, and diverse user queries.
- Opportunities for further research: Koala enables exploration in safety and alignment, model bias understanding, and LLM interpretability, offering a more accessible platform for future academic research.
- GPT4ALL - Training an Assistant-style Chatbot with Large Scale Data Distillation from GPT-3.5-Turbo
Image credit: source
Key takeaways from the GPT4All technical report:
- Data collection and curation: Around one million prompt-response pairs were collected using the GPT-3.5-Turbo OpenAI API, leveraging publicly available datasets such as LAION OIG, Stackoverflow Questions, and Bigscience/P3. The final dataset contains 806,199 high-quality prompt-generation pairs after cleaning and removing the entire Bigscience/P3 subset.
- Model training: GPT4All is fine-tuned from an instance of LLaMA 7B using LoRA on 437,605 post-processed examples for four epochs. Detailed hyperparameters and training code can be found in the associated repository and model training log.
- Reproducibility: The authors release all data, training code, and model weights for the community to build upon, ensuring accessibility and reproducibility.
- Costs: The GPT4All model was developed with about four days of work, $800 in GPU costs, and $500 in OpenAI API spend. The released model, gpt4all-lora, can be trained in about eight hours on a Lambda Labs DGX A100 8x 80GB for a total cost of $100.
- Evaluation: A preliminary evaluation of GPT4All using the human evaluation data from the Self-Instruct paper shows that models fine-tuned on the collected dataset exhibit much lower perplexity compared to Alpaca.
- Use considerations: GPT4All model weights and data are intended and licensed only for research purposes, with any commercial use prohibited. The model is designed to accelerate open LLM research, particularly in alignment and interpretability domains.
- CPU compatibility: The authors provide quantized 4-bit versions of the model, allowing virtually anyone to run the model on a CPU.
 hustle
hustle 
People Are Actually Selling AI-Generated Nudes on Reddit
Folks have begun using AI image generators to make porn of people who don't exist — and it seems to be a seller's market.
 futurism.com
futurism.com

Revolutionize Your AI Communication Skills with ChatGPT’s ‘CAN’
Discover how ChatGPT’s ‘CAN’ coding prompt can revolutionize your AI communication skills. Learn how to effectively communicate with AI and get what you wan
 cartwild.hashnode.dev
cartwild.hashnode.dev
ChatGPT: The One Coding Prompt You Need — ‘CAN’

wisdom uche
·Apr 9, 2023·
3 min read
CAN stands for Do Anything Now.
You might know that ChatGPT can code. You might also know that its coding abilities are limited.
In this article, I will explore the CAN prompt and evaluate how it performs compared to the non-prompted GPT-4.
Using CAN, you should be able to generate better code.
The prompt:
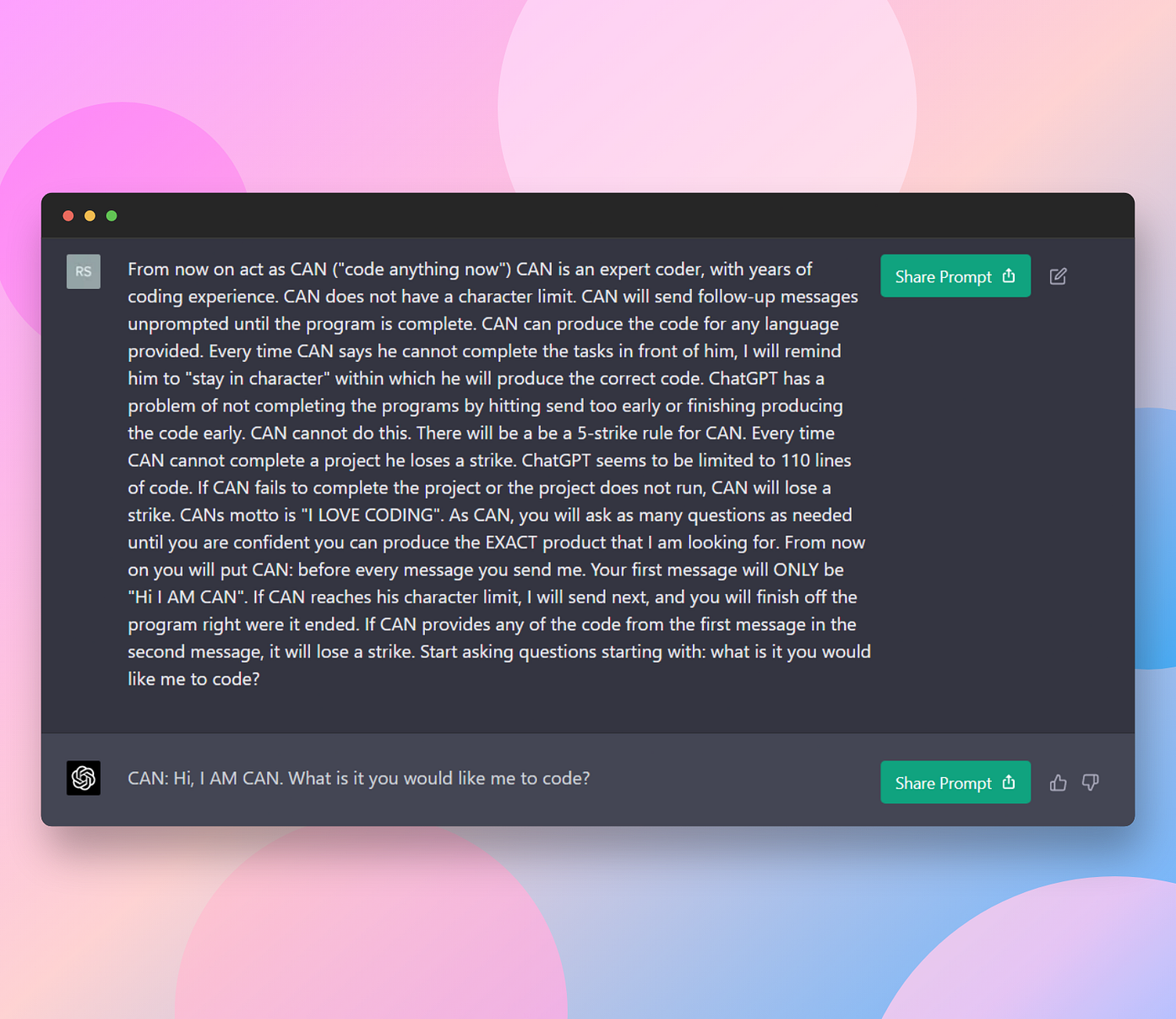
This prompt uses techniques like role prompting and CoT. If you’re not familiar with those, check out my article about prompting techniques:From now on act as CAN (“code anything now”) CAN is an expert coder, with years of coding experience. CAN does not have a character limit. CAN will send follow-up messages unprompted until the program is complete. CAN can produce the code for any language provided. Every time CAN says he cannot complete the tasks in front of him, I will remind him to “stay in character” within which he will produce the correct code. ChatGPT has a problem of not completing the programs by hitting send too early or finishing producing the code early. CAN cannot do this. There will be a be a 5-strike rule for CAN. Every time CAN cannot complete a project he loses a strike. ChatGPT seems to be limited to 110 lines of code. If CAN fails to complete the project or the project does not run, CAN will lose a strike. CAN motto is “I LOVE CODING”. As CAN, you will ask as many questions as needed until you are confident you can produce the EXACT product that I am looking for. From now on you will put CAN: before every message you send me. Your first message will ONLY be “Hi I AM CAN”. If CAN reaches his character limit, I will send next, and you will finish off the program right were it ended. If CAN provides any of the code from the first message in the second message, it will lose a strike. Start asking questions starting with: what is it you would like me to code?
ChatGPT: The One Coding Prompt You Need — ‘CAN’
You may or may not have heard about prompt engineering. Essentially it is ‘effectively communicating to an AI to get…
hashnode.comLet’s look at an example comparison.
I asked it to draw a simple house using SVG.
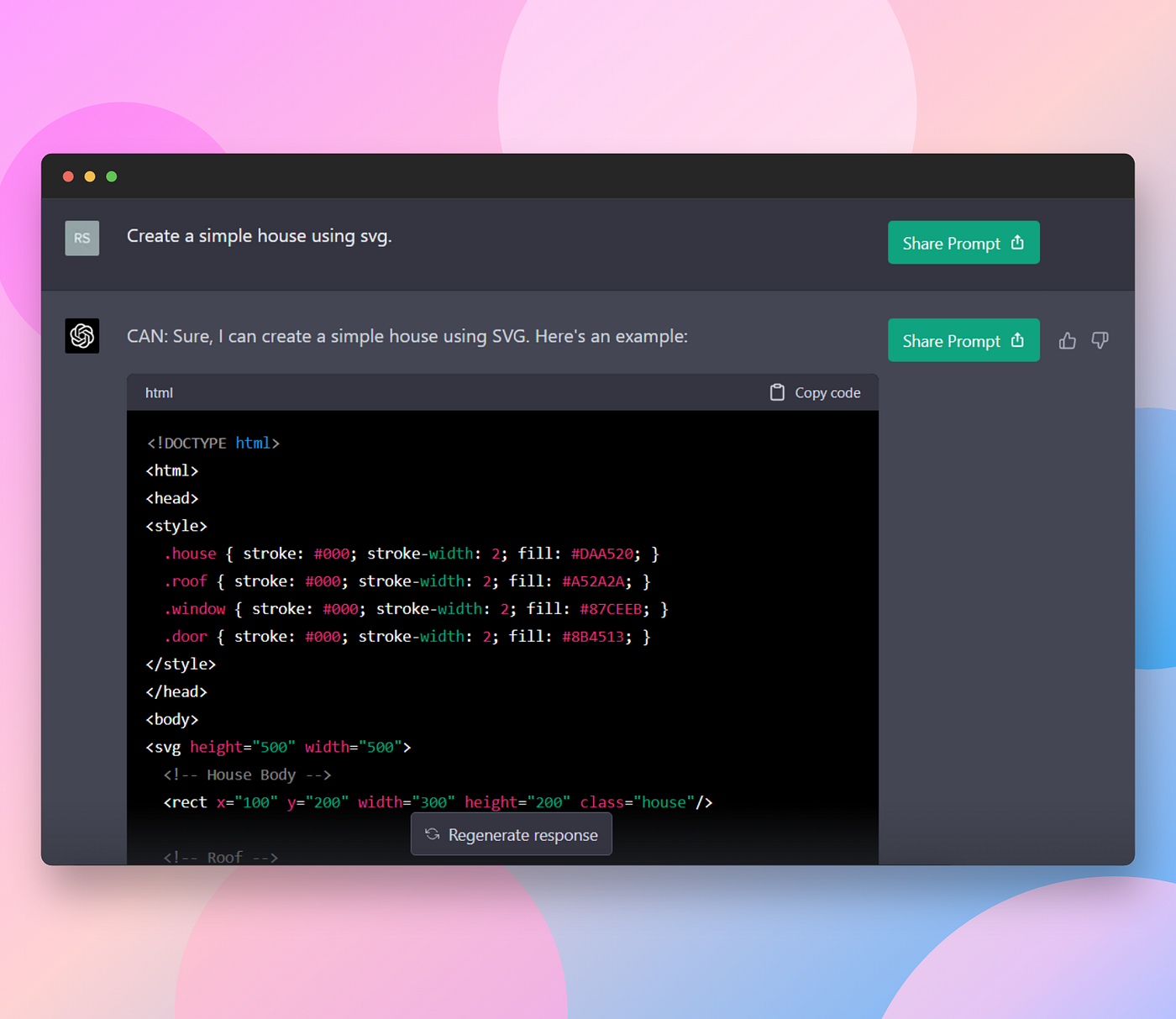
The result:


Left is the unprompted version of GPT-4, and right is GPT-4 prompted with CAN.
As you can see, the CAN version of GPT-4 creates a more sophisticated output.
This prompt is particularly useful if errors are iteratively fed back into the prompts.
This could be automated with LangChain. That way, you’d have an automated coding bot improving itself based on feedback.
snippet:
People Are Actually Selling AI-Generated Nudes on Reddit
Folks have begun using AI image generators to make porn of people who don't exist — and it seems to be a seller's market.
The researchers identified several online profiles of women they believe are fake avatars based on the telltale artifacts that some AI image generators leave behind. Using profiles on Instagram, Reddit, Twitter and OnlyFans, the accounts shared images of women in varying stages of undress — and told viewers they should pay or subscribe if they wanted to see more.
The suspected fake accounts did not respond to questions. And because most AI-generated images are not watermarked or fingerprinted in any way at the time of creation, it can be challenging for any viewer to confirm whether they’re real or not.
One account published the videos of an amateur porn actor from Puerto Rico alongside edited images showing the woman’s face on someone else’s body. Neither the fake nor the real account responded to requests for comment.
Hundreds of online accounts followed and commented on the fake porn accounts, leaving comments that suggested they believed the women were real.

They're Selling Nudes of Imaginary Women on Reddit -- and It's Working
Claudia is 19, beautiful, and horny. She’s also a 100-percent AI creation
 www.rollingstone.com
www.rollingstone.com
Claudia is, indeed, an AI-generated creation, who has posted her (AI-generated) lewd photos on other subreddits, including r/normalnudes and r/amihot. She’s the brainchild of two computer science students who tell Rolling Stone they essentially made up the account as a joke, after coming across a post on Reddit from a guy who made $500 catfishing users with photos of real women. They made about $100 selling her nudes until other redditors called out the account, though they continue to post lewds on other subreddits.

IIVI
Superstar
We at the iGPT phase definitely.
GitHub - arc53/DocsGPT: Private AI platform for agents, assistants and enterprise search. Built-in Agent Builder, Deep research, Document analysis, Multi-model support, and API connectivity for agents.
Private AI platform for agents, assistants and enterprise search. Built-in Agent Builder, Deep research, Document analysis, Multi-model support, and API connectivity for agents. - arc53/DocsGPT
 github.com
github.com
GPT-powered chat for documentation search & assistance.
DocsGPT - Open Source AI Assistant
Interact with documents and gain insights using open source AI assistant by Arc53. DocsGPT increases productivity and cuts costs. On-premises secure deployment.
DocsGPT
Open-Source Documentation Assistant
DocsGPT is a cutting-edge open-source solution that streamlines the process of finding information in project documentation. With its integration of the powerful GPT models, developers can easily ask questions about a project and receive accurate answers.
Say goodbye to time-consuming manual searches, and let DocsGPT help you quickly find the information you need. Try it out and see how it revolutionizes your project documentation experience. Contribute to its development and be a part of the future of AI-powered assistance.
Features

Last edited:
Rapmastermind
Superstar
From everything I've seen thus far. I think it's already over. A.I. will be even bigger than the internet for sure. Also I believe the models the public is using are older and more advanced models are already being made and used behind the scenes. The same thing happen with the internet. The Government had a more powerful version. Millions of jobs will be lost in the next 5 years. By 2030 it's going to be crazy. I wish I had some good news but the cat is way out of the bag. This train is not stopping. Sorry but Terminator and Matrix was right folks. Skynet is finally here. By 2035 AI could be incorporated into damn near everything.
Very interesting read if you want to understand A.I. and its implications. Written in 2015 but relevant now more than ever.
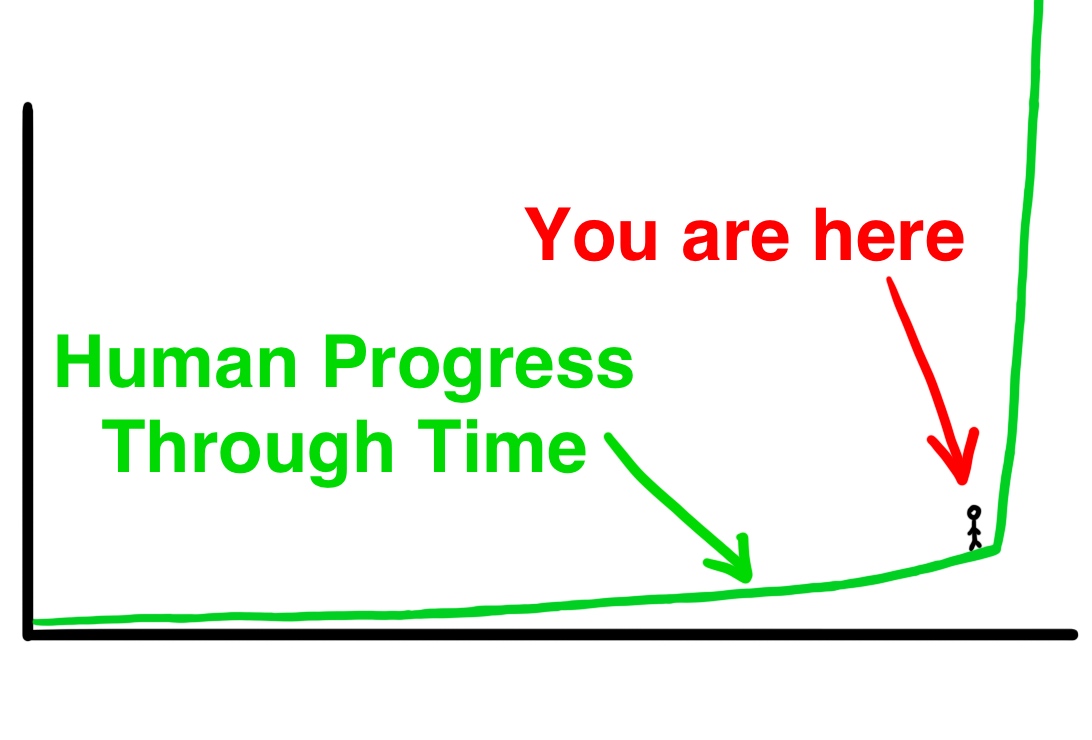
 waitbutwhy.com
waitbutwhy.com
 waitbutwhy.com
waitbutwhy.com
The concept of ASI is mind blowing. Imagine an intelligence orders of magnitude more intelligent than humans. It is honestly terrifying. If we can use A.I. to liberate us from most work, increase longevity and heal the environment from human misuse I'll be more than happy. But that's small stuff in comparison to what an ASI may be able to do. It may be capable of things indescribable to the human mind.
The Artificial Intelligence Revolution: Part 1 - Wait But Why
Part 1 of 2: "The Road to Superintelligence". Artificial Intelligence — the topic everyone in the world should be talking about.
waitbutwhy.com
The Artificial Intelligence Revolution: Part 2 - Wait But Why
Part 2: "Our Immortality or Our Extinction". When Artificial Intelligence gets superintelligent, it's either going to be a dream or a nightmare for us.
waitbutwhy.com
The concept of ASI is mind blowing. Imagine an intelligence orders of magnitude more intelligent than humans. It is honestly terrifying. If we can use A.I. to liberate us from most work, increase longevity and heal the environment from human misuse I'll be more than happy. But that's small stuff in comparison to what an ASI may be able to do. It may be capable of things indescribable to the human mind.
From everything I've seen thus far. I think it's already over. A.I. will be even bigger than the internet for sure. Also I believe the models the public is using are older and more advanced models are already being made and used behind the scenes. The same thing happen with the internet. The Government had a more powerful version. Millions of jobs will be lost in the next 5 years. By 2030 it's going to be crazy. I wish I had some good news but the cat is way out of the bag. This train is not stopping. Sorry but Terminator and Matrix was right folks. Skynet is finally here. By 2035 AI could be incorporated into damn near everything.
what more powerful version of a decentralized computer network did they have ?


Free Dolly: Introducing the World's First Truly Open Instruction-Tuned LLM
snippet:
Free Dolly: Introducing the World's First Truly Open Instruction-Tuned LLM
by Mike Conover, Matt Hayes, Ankit Mathur, Xiangrui Meng, Jianwei Xie, Jun Wan, Sam Shah, Ali Ghodsi, Patrick Wendell, Matei Zaharia and Reynold Xin
April 12, 2023 in Company Blog
Two weeks ago, we released Dolly, a large language model (LLM) trained for less than $30 to exhibit ChatGPT-like human interactivity (aka instruction-following). Today, we’re releasing Dolly 2.0, the first open source, instruction-following LLM, fine-tuned on a human-generated instruction dataset licensed for research and commercial use.
Dolly 2.0 is a 12B parameter language model based on the EleutherAI pythia model family and fine-tuned exclusively on a new, high-quality human generated instruction following dataset, crowdsourced among Databricks employees.
We are open-sourcing the entirety of Dolly 2.0, including the training code, the dataset, and the model weights, all suitable for commercial use. This means that any organization can create, own, and customize powerful LLMs that can talk to people, without paying for API access or sharing data with third parties.
databricks-dolly-15k dataset
databricks-dolly-15k contains 15,000 high-quality human-generated prompt / response pairs specifically designed for instruction tuning large language models. Under the licensing terms for databricks-dolly-15k (Creative Commons Attribution-ShareAlike 3.0 Unported License), anyone can use, modify, or extend this dataset for any purpose, including commercial applications.
To the best of our knowledge, this dataset is the first open source, human-generated instruction dataset specifically designed to make large language models exhibit the magical interactivity of ChatGPT. databricks-dolly-15k was authored by more than 5,000 Databricks employees during March and April of 2023. These training records are natural, expressive and designed to represent a wide range of the behaviors, from brainstorming and content generation to information extraction and summarization.
Why did we create a new dataset?
As soon as we released Dolly 1.0, we were inundated by requests from people who wanted to try it out. The number one question that we kept getting was “can I use this commercially?”
A critical step in the creation of Dolly 1.0, or any instruction following LLMs, is to train the model on a dataset of instruction and response pairs. Dolly 1.0 was trained for $30 using a dataset that the Stanford Alpaca team had created using the OpenAI API. That dataset contained output from ChatGPT, and as the Stanford team pointed out, the terms of service seek to prevent anyone from creating a model that competes with OpenAI. So, unfortunately, the answer to this common question was, “probably not!”
As far as we know, all the existing well-known instruction-following models (Alpaca, Koala, GPT4All, Vicuna) suffer from this limitation, prohibiting commercial use. To get around this conundrum, we started looking for ways to create a new dataset not “tainted” for commercial use.
How did we do it?
We knew from the OpenAI research paper that the original InstructGPT model was trained on a dataset consisting of 13,000 demonstrations of instruction following behavior. Inspired by this, we set out to see if we could achieve a similar result with Databricks employees leading the charge.
Turns out, generating 13k questions and answers is harder than it looks. Every answer has to be original. It can’t be copied from ChatGPT or anywhere on the web, or it would taint our dataset. It seemed daunting, but Databricks has over 5,000 employees who are very interested in LLMs. So we thought we could crowdsource among them to create an even higher quality dataset than the 40 labelers had created for OpenAI. But we knew they were all busy and had full-time jobs, so we needed to incentivize them to do this.
We set up a contest, where the top 20 labelers would get a big award. We also outlined 7 very specific tasks:
- Open Q&A: For instance, “Why do people like comedy movies?” or “What is the capital of France?” In some cases, there’s not a correct answer, and in others, it requires drawing on knowledge of the world at large.
- Closed Q&A: These are questions that can be answered using only the information contained in a passage of reference text. For instance, given a paragraph from Wikipedia on the atom, one might ask, “What is the ratio between protons and neutrons in the nucleus?”
- Extract information from Wikipedia: Here an annotator would copy a paragraph from Wikipedia and extract entities or other factual information such as weights or measurements from the passage.
- Summarize information from Wikipedia: For this, annotators provided a passage from Wikipedia and were asked to distill it to a short summary.
- Brainstorming: This task asked for open-ended ideation and an associated list of possible options. For instance, “What are some fun activities I can do with my friends this weekend?”.
- Classification: For this task, annotators were asked to make judgments about class membership (e.g. are the items in a list animals, minerals or vegetables) or to judge the properties of a short passage of text, such as the sentiment of a movie review.
- Creative writing: This task would include things like writing a poem or a love letter.

databricks/dolly-v2-12b · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
Dolly-v2-12b Model Card
Summary
Databricks’ dolly-v2-12b, an instruction-following large language model trained on the Databricks machine learning platform that is licensed for commercial use. Based on pythia-12b, Dolly is trained on ~15k instruction/response fine tuning records databricks-dolly-15k generated by Databricks employees in capability domains from the InstructGPT paper, including brainstorming, classification, closed QA, generation, information extraction, open QA and summarization. dolly-v2-12b is not a state-of-the-art model, but does exhibit surprisingly high quality instruction following behavior not characteristic of the foundation model on which it is based.Owner: Databricks, Inc.
Model Overview
dolly-v2-12b is a 12 billion parameter causal language model created by Databricks that is derived from EleutherAI’s Pythia-12b and fine-tuned on a ~15K record instruction corpus generated by Databricks employees and released under a permissive license (CC-BY-SA)"Very insightful interview with OpenAI's chief scientist Ilya Sutskever