Powered by Ray, Anyscale empowers AI builders to run and scale all ML and AI workloads on any cloud and on-prem.
www.anyscale.com
How to fine tune and serve LLMs simply, quickly and cost effectively using Ray + DeepSpeed + HuggingFace
This is part 4 of our blog series on Generative AI. In the previous blog posts we explained why
Ray is a sound platform for Generative AI,
we showed how it can push the performance limits, and
how you can use Ray for stable diffusion.
In this blog, we share a practical approach on how you can use the combination of HuggingFace, DeepSpeed, and Ray to build a system for fine-tuning and serving LLMs, in 40 minutes for less than $7 for a 6 billion parameter model. In particular, we illustrate the following:
- Using these three components, you can simply and quickly put together an open-source LLM fine-tuning and serving system.
- By taking advantage of Ray’s distributed capabilities, we show how this can be both more cost-effective and faster than using a single large (and often unobtainable) machine.
Here’s what we’ll be doing:
- Discussing why you might want to run your own LLM instead of using one of the new API providers.
- Showing you the evolving tech stack we are seeing for cost-effective LLM fine-tuning and serving, combining HuggingFace, DeepSpeed, Pytorch, and Ray.
- Showing you 40 lines of Python code that can enable you to serve a 6 billion parameter GPT-J model.
- Showing you, for less than $7, how you can fine-tune the model to sound more medieval using the works of Shakespeare by doing it in a distributed fashion on low-cost machines, which is considerably more cost-effective than using a single large powerful machine.
- Showing how you can serve the fine-tuned 6B LLM compiled model binary.
- Showing how the fine-tuned model compares to a prompt engineering approach with large systems.
Why would I want to run my own LLM?
There are
many,
many providers of LLM APIs online. Why would you want to run your own? There are a few reasons:
- Cost, especially for fine-tuned inference: For example, OpenAI charges 12c per 1000 tokens (about 700 words) for a fine-tuned model on Davinci. It’s important to remember that many user interactions require multiple backend calls (e.g. one to help with the prompt generation, post-generation moderation, etc), so it’s very possible that a single interaction with an end user could cost a few dollars. For many applications, this is cost prohibitive.
- Latency: using these LLMs is especially slow. A GPT-3.5 query for example can take up to 30 seconds. Combine a few round trips from your data center to theirs and it is possible for a query to take minutes. Again, this makes many applications impossible. Bringing the processing in-house allows you to optimize the stack for your application, e.g. by using low-resolution models, tightly packing queries to GPUs, and so on. We have heard from users that optimizing their workflow has often resulted in a 5x or more latency improvement.
- Data Security & Privacy: In order to get the response from these APIs, you have to send them a lot of data for many applications (e.g. send a few snippets of internal documents and ask the system to summarize them). Many of the API providers reserve the right to use those instances for retraining. Given the sensitivity of organizational data and also frequent legal constraints like data residency, this is especially limiting. One, particularly concerning recent development, is the ability to regenerate training data from learned models, and people unintentionally disclosing secret information.
OK, so how do I run my own?
The LLM space is an incredibly fast-moving space, and it is currently evolving very rapidly. What we are seeing is a particular technology stack that combines multiple technologies:
What we’ve also seen is a reluctance to go beyond a single machine for training. In part, because there is a perception that moving to multiple machines is seen as complicated. The good news is this is where
Ray.io shines (ba-dum-tish). It simplifies cross-machine coordination and orchestration aspects using not much more than Python and Ray decorators, but also is a great framework for composing this entire stack together.
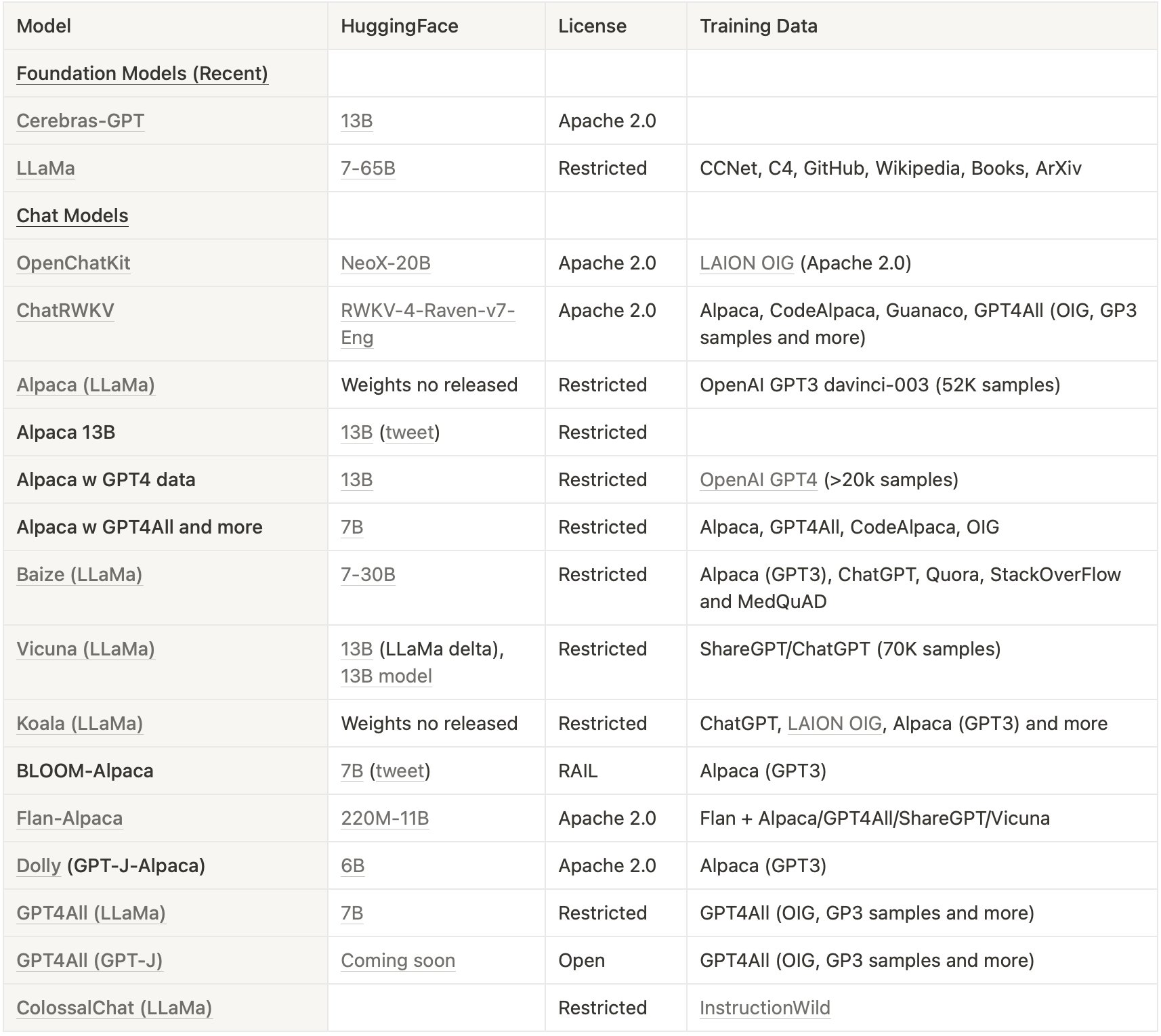
Recent results on
Dolly and
Vicuna (both trained on Ray or trained on models built with Ray like
GPT-J) are small LLMs (relatively speaking – say the open source model GPT-J-6B with 6 billion parameters) that can be incredibly powerful when fine-tuned on the right data. The key is fine-tuning and the right data parts. So you do not always need to use the latest and greatest model with 150 billion-plus parameters to get useful results. Let’s get started!
Serving a pre-existing model with Ray for text generation
The detailed steps on how to serve the GPT-J model with Ray can be found
here, so let’s highlight some of the aspects of how we do that.
Code:
@serve.deployment(ray_actor_options={"num_gpus":1})
classPredictDeployment:
def__init__(self, model_id:str, revision:str=None):
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
self.model = AutoModelForCausalLM.from_pretrained(
"EleutherAI/gpt-j-6B",
revision=revision,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
device_map="auto", # automatically makes use of all GPUs available to the Actor
)
Serving in Ray happens in actors, in this case, one called PredictDeployment. This code shows the __init__ method of the action that downloads the model from Hugging Face. To launch the model on the current node, we simply do:
Code:
deployment = PredictDeployment.bind(model_id=model_id, revision=revision)
serve.run(deployment)
That starts a service on port 8000 of the local machine.
We can now query that service using a few lines of Python
Code:
import requests
prompt = (
“Once upon a time, there was a horse. “
)
sample_input = {"text": prompt}
output = requests.post("http://localhost:8000/", json=[sample_input]).json()
print(output)
And sure enough, this prints out a continuation of the above opening. Each time it runs, there is something slightly different.
Once upon a time, there was a horse.
But this particular horse was too big to be put into a normal stall. Instead, the animal was moved into an indoor pasture, where it could take a few hours at a time out of the stall. The problem was that this pasture was so roomy that the horse would often get a little bored being stuck inside. The pasture also didn’t have a roof, and so it was a good place for snow to accumulate.
This is certainly an interesting direction and story … but now we want to set it in the medieval era. What can we do?
Fine Tuning
Now that we’ve shown how to serve a model, how do we fine-tune it to be more medieval? What about if we train it on 2500 lines from Shakespeare?
This is where
DeepSpeed comes in. DeepSpeed is a set of optimized algorithms for training and fine-tuning networks. The problem is that DeepSpeed doesn’t have an orchestration layer. This is not so much of a problem on a single machine, but if you want to use multiple machines, this typically involves a bunch of bespoke ssh commands, complex managed keys, and so on.
This is where Ray can help.
This
page in the Ray documentation discusses how to fine-tune it to sound more like something from the 15th century with a bit of flair.
Let’s go through the key parts. First, we load the data from hugging face
Code:
from datasets import load_dataset
print("Loading tiny_shakespeare dataset")
current_dataset = load_dataset("tiny_shakespeare")
Skipping the tokenization code, here’s the heart of the code that we will run for each worker.
Code:
def trainer_init_per_worker(train_dataset, eval_dataset=None,**config):
# Use the actual number of CPUs assigned by Ray
model = GPTJForCausalLM.from_pretrained(model_name, use_cache=False)
model.resize_token_embeddings(len(tokenizer))
enable_progress_bar()
metric = evaluate.load("accuracy")
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
compute_metrics=compute_metrics,
tokenizer=tokenizer,
data_collator=default_data_collator,
)
return trainer
And now we create a Ray AIR HuggingFaceTrainer that orchestrates the distributed run and wraps around multiple copies of the training loop above:
Code:
trainer = HuggingFaceTrainer(
trainer_init_per_worker=trainer_init_per_worker,
trainer_init_config={
"batch_size":16, # per device
"epochs":1,
},
scaling_config=ScalingConfig(
num_workers=num_workers,
use_gpu=use_gpu,
resources_per_worker={"GPU":1,"CPU": cpus_per_worker},
),
datasets={"train": ray_datasets["train"],"evaluation": ray_datasets["validation"]},
preprocessor=Chain(splitter, tokenizer),
)
results = trainer.fit()




 Demo on San Francisco City Data:
Demo on San Francisco City Data:  Demo on US Census Data:
Demo on US Census Data: 






