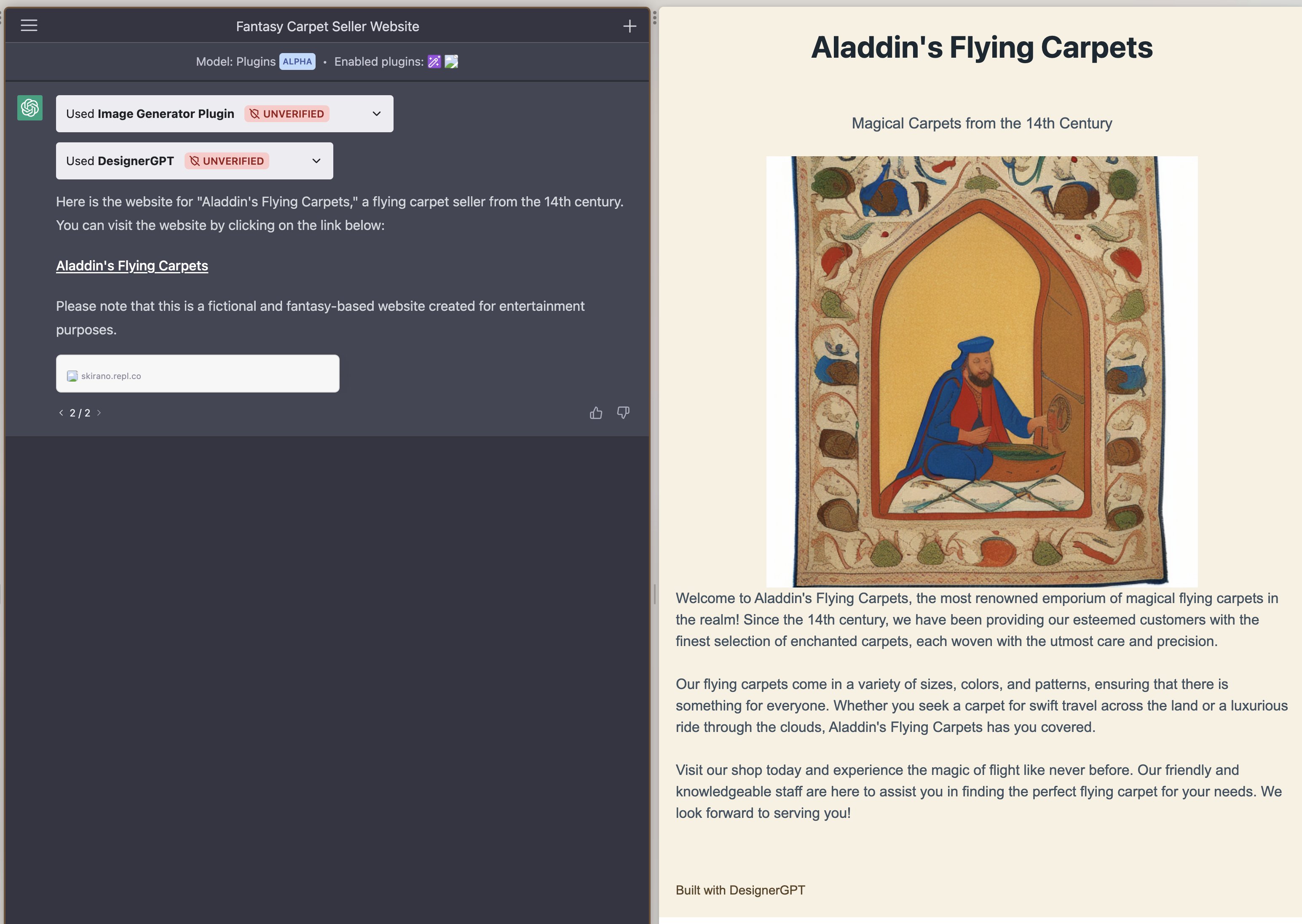
explain a stocks cost to borrow like i'm in third grade.
When you buy a stock, you are buying ownership in a company. When you sell a stock short, you are borrowing shares of a stock from someone else and selling them, hoping to buy them back later at a lower price and return them to the lender. The cost to borrow a stock is the fee you pay to the lender for the privilege of borrowing their shares.
The cost to borrow a stock can vary depending on a number of factors, including the liquidity of the stock, the volatility of the stock, and the demand for the stock. In general, stocks that are more difficult to borrow will have a higher cost to borrow.
The cost to borrow a stock is an important factor to consider when short selling a stock. If the cost to borrow is too high, it can eat into your profits if the stock does decline in price. Conversely, if the cost to borrow is too low, you may be missing out on potential profits if the stock does decline in price.
Here's an example to help you understand cost to borrow. Let's say you want to short sell 100 shares of Apple stock. The current market price of Apple stock is $100 per share. The cost to borrow Apple stock is 2% per year. This means that you will pay the lender $2 per share per year, or $200 per year, to borrow the shares.
If you short sell Apple stock and the price of the stock declines to $90 per share, you will make a profit of $1,000. However, you will also have to pay the lender the $200 cost to borrow the shares. So, your net profit will be $800.
On the other hand, if the price of Apple stock increases to $110 per share, you will lose $1,000. In addition, you will still have to pay the lender the $200 cost to borrow the shares. So, your total loss will be $1,200.
As you can see, the cost to borrow a stock can have a significant impact on your profits or losses when short selling. It is important to factor in the cost to borrow when making a decision to short sell a stock.

 github.com
github.com



 Work in progress.
Work in progress.



 (eg, dog) and part-level
(eg, dog) and part-level (eg, dog head). Furthermore,we build a
(eg, dog head). Furthermore,we build a 
 that flexibly calls various segmentation models when receiving instructions in the form of natural language.
that flexibly calls various segmentation models when receiving instructions in the form of natural language.
