
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?1/1
Congrats
@openai on the new GPT-4o mini release!
GPT-4o mini's early version "upcoming-gpt-mini" was tested in Arena in the past week.
With over 6K user votes, we are excited to share its early score reaching GPT-4-Turbo performance, while offering significant cost reduction (15/60 cent per million input/output tokens).
Its official version "gpt-4o-mini" is now in the Arena. We're re-collecting votes & will update its result to leaderboard soon!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Congrats
@openai on the new GPT-4o mini release!
GPT-4o mini's early version "upcoming-gpt-mini" was tested in Arena in the past week.
With over 6K user votes, we are excited to share its early score reaching GPT-4-Turbo performance, while offering significant cost reduction (15/60 cent per million input/output tokens).
Its official version "gpt-4o-mini" is now in the Arena. We're re-collecting votes & will update its result to leaderboard soon!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196


Many people think AI is already sentient - and that's a big problem
A survey of people in the US has revealed the widespread belief that artificial intelligence models are already self-aware, which is very far from the truth
 www.newscientist.com
www.newscientist.com
Many people think AI is already sentient - and that's a big problem
A survey of people in the US has revealed the widespread belief that artificial intelligence models are already self-aware, which is very far from the truthBy Chris Stokel-Walker
18 July 2024
AIs are not yet artificial minds
Panther Media GmbH / Alamy
Around one in five people in the US believe that artificial intelligence is already sentient, while around 30 per cent think that artificial general intelligences (AGIs) capable of performing any task a human can are already in existence. Both beliefs are false, suggesting that the general public has a shaky grasp of the current state of AI – but does it matter?
Jacy Reese Anthis at the Sentience Institute in New York and his colleagues asked a nationally representative sample of 3500 people in the US their perceptions of…
AI and its sentience. The surveys, carried out in three waves between 2021 and 2023, asked questions like “Do you think any robots/AIs that currently exist are sentient?” and whether it could ever be possible for that technology to reach sentience.

How this moment for AI will change society forever (and how it won't)
There is no doubt that the latest advances in artificial intelligence from OpenAI, Google, Baidu and others are more impressive than what came before, but are we in just another bubble of AI hype?
“We wanted to collect data early to understand how public opinion might shape the future trajectory of AI technologies,” says Anthis.
The findings of the survey were surprising, he says. In 2021, around 18 per cent of respondents said they thought AI or robot systems already in existence were sentient – a number that increased to 20 per cent in 2023, when there were two survey waves. One in 10 people asked in 2023 thought ChatGPT, which launched at the end of 2022, was sentient.
“I think we perceive mind very readily in computers,” says Anthis. “We see them as social actors.” He also says that some of the belief in AI sentience is down to big tech companies selling their products as imbued with more abilities than the underlying technology may suggest they have. “There’s a lot of hype in this space,” he says. “As companies have started building their brands around things like AGI, they have a real incentive to talk about how powerful their systems are.”
“There’s a lot of research showing that when somebody has a financial interest in something happening, they are more likely to think it will happen,” says Carissa Véliz at the University of Oxford. “It’s not even that they might be misleading the public or lying. It’s simply that optimism bias is a common problem for humans.”
Read more
How does ChatGPT work and do AI-powered chatbots “think” like us?
Journalists should also take some of the blame, says Kate Devlin at King’s College London. “This isn’t helped by the kind of media coverage we saw around large language models, with overexcited and panicked reports about existential threats from superintelligence.”
Anthis worries that the incorrect belief that AI has a mind, encouraged by the anthropomorphising of AI systems by their makers and the media, is shaping our perception of their abilities. There is a risk that if people believe AI is sentient, they will put more faith than they ought to in its judgements – a concern when AI is being considered for use in government and policing.
One way to avoid this trap is to recast our thinking, says Anthis. “I think people have hyperfocused on the term ‘artificial intelligence’,” he says, pointing out it was little more than a good branding exercise when the term was first coined in the 1950s. People are often impressed at how AI models perform on human IQ tests or standardised exams. “But those are very often the wrong way of thinking of these models,” he says – because the AIs are simply regurgitating answers found in their vast training data, rather than actually “knowing” anything.
Reference
arXiv DOI: 10.48550/arXiv.2407.08867
[2406.07887] An Empirical Study of Mamba-based Language Models
[Submitted on 12 Jun 2024]
An Empirical Study of Mamba-based Language Models
Roger Waleffe, Wonmin Byeon, Duncan Riach, Brandon Norick, Vijay Korthikanti, Tri Dao, Albert Gu, Ali Hatamizadeh, Sudhakar Singh, Deepak Narayanan, Garvit Kulshreshtha, Vartika Singh, Jared Casper, Jan Kautz, Mohammad Shoeybi, Bryan CatanzaroAbstract:
Selective state-space models (SSMs) like Mamba overcome some of the shortcomings of Transformers, such as quadratic computational complexity with sequence length and large inference-time memory requirements from the key-value cache. Moreover, recent studies have shown that SSMs can match or exceed the language modeling capabilities of Transformers, making them an attractive alternative. In a controlled setting (e.g., same data), however, studies so far have only presented small scale experiments comparing SSMs to Transformers. To understand the strengths and weaknesses of these architectures at larger scales, we present a direct comparison between 8B-parameter Mamba, Mamba-2, and Transformer models trained on the same datasets of up to 3.5T tokens. We also compare these models to a hybrid architecture consisting of 43% Mamba-2, 7% attention, and 50% MLP layers (Mamba-2-Hybrid). Using a diverse set of tasks, we answer the question of whether Mamba models can match Transformers at larger training budgets. Our results show that while pure SSMs match or exceed Transformers on many tasks, they lag behind Transformers on tasks which require strong copying or in-context learning abilities (e.g., 5-shot MMLU, Phonebook) or long-context reasoning. In contrast, we find that the 8B Mamba-2-Hybrid exceeds the 8B Transformer on all 12 standard tasks we evaluated (+2.65 points on average) and is predicted to be up to 8x faster when generating tokens at inference time. To validate long-context capabilities, we provide additional experiments evaluating variants of the Mamba-2-Hybrid and Transformer extended to support 16K, 32K, and 128K sequences. On an additional 23 long-context tasks, the hybrid model continues to closely match or exceed the Transformer on average. To enable further study, we release the checkpoints as well as the code used to train our models as part of NVIDIA's Megatron-LM project.
| Subjects: | Machine Learning (cs.LG); Computation and Language (cs.CL) |
| Cite as: | arXiv:2406.07887 |
| arXiv:2406.07887v1 | |
| [2406.07887] An Empirical Study of Mamba-based Language Models |
Submission history
From: [v1] [ view email][v1]
https://arxiv.org/pdf/2406.07887
[2403.19887] Jamba: A Hybrid Transformer-Mamba Language Model
[Submitted on 28 Mar 2024 (v1), last revised 3 Jul 2024 (this version, v2)]
Jamba - A Hybrid Transformer-Mamba Language Model
Opher Lieber, Barak Lenz, Hofit Bata, Gal Cohen, Jhonathan Osin, Itay Dalmedigos, Erez Safahi, Shaked Meirom, Yonatan Belinkov, Shai Shalev-Shwartz, Omri Abend, Raz Alon, Tomer Asida, Amir Bergman, Roman Glozman, Michael Gokhman, Avashalom Manevich, Nir Ratner, Noam Rozen, Erez Shwartz, Mor Zusman, Yoav ShohamAbstract:
We present Jamba, a new base large language model based on a novel hybrid Transformer-Mamba mixture-of-experts (MoE) architecture. Specifically, Jamba interleaves blocks of Transformer and Mamba layers, enjoying the benefits of both model families. MoE is added in some of these layers to increase model capacity while keeping active parameter usage manageable. This flexible architecture allows resource- and objective-specific configurations. In the particular configuration we have implemented, we end up with a powerful model that fits in a single 80GB GPU. Built at large scale, Jamba provides high throughput and small memory footprint compared to vanilla Transformers, and at the same time state-of-the-art performance on standard language model benchmarks and long-context evaluations. Remarkably, the model presents strong results for up to 256K tokens context length. We study various architectural decisions, such as how to combine Transformer and Mamba layers, and how to mix experts, and show that some of them are crucial in large scale modeling. We also describe several interesting properties of these architectures which the training and evaluation of Jamba have revealed, and plan to release checkpoints from various ablation runs, to encourage further exploration of this novel architecture. We make the weights of our implementation of Jamba publicly available under a permissive license.
| Comments: | this https URL |
| Subjects: | Computation and Language (cs.CL); Machine Learning (cs.LG) |
| Cite as: | arXiv:2403.19887 |
| arXiv:2403.19887v2 | |
| [2403.19887] Jamba: A Hybrid Transformer-Mamba Language Model |
Submission history
From: [v1] [ view email][v1]
https://arxiv.org/pdf/2403.19887
The current generation of models are stagnating. Once ChatGPT5 or 6 (with reasoning capabilities) comes out the hype will start all over again.
Claude sonnet 3.5 was recently released and has surpassed chatgpt in some cases.
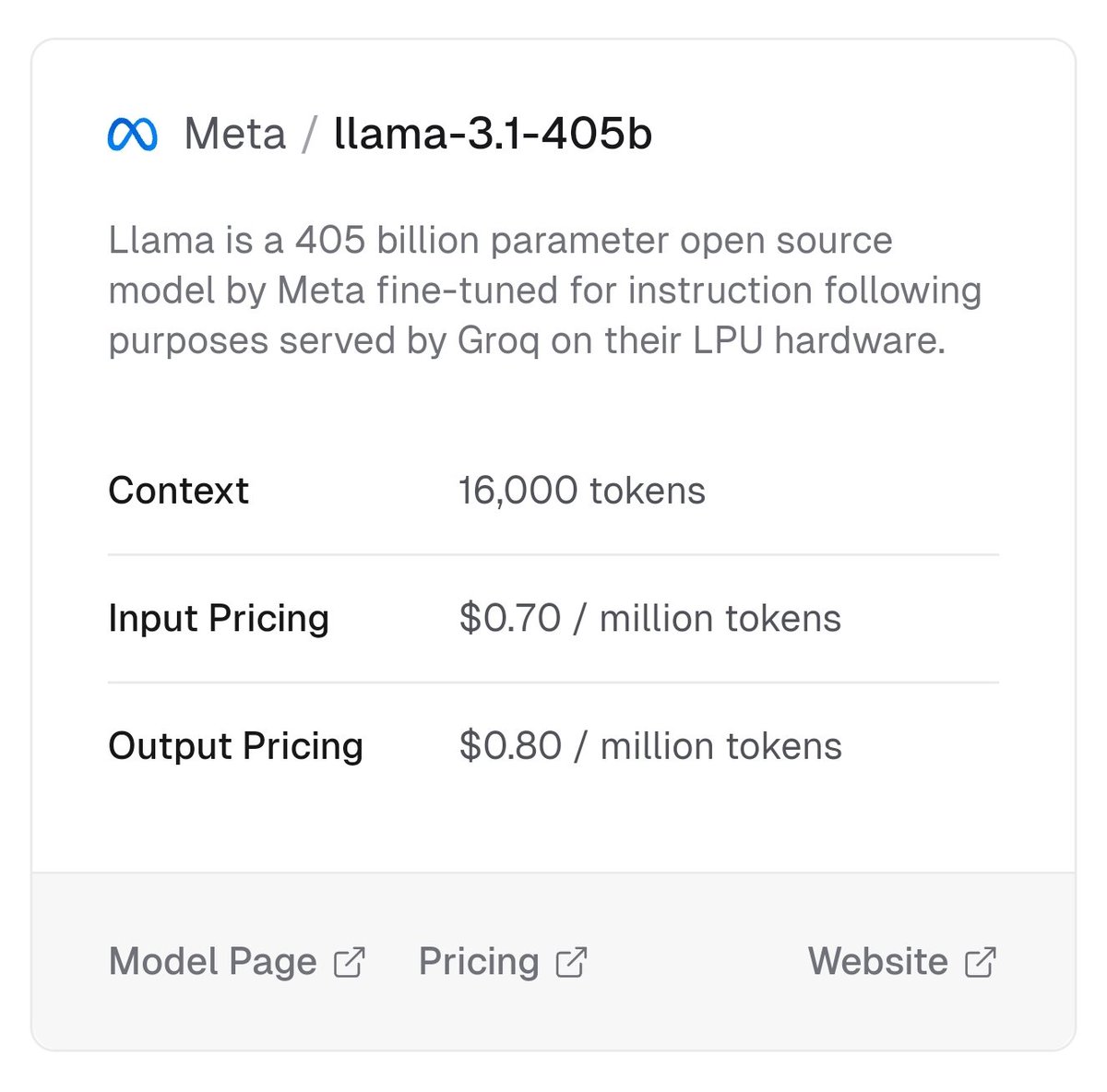
Llama 3.1 405B just got released today!
1/1
We’ve also updated our license to allow developers to use the outputs from Llama models — including 405B — to improve other models for the first time.
We’re excited about how this will enable new advancements in the field through synthetic data generation and model distillation workflows, capabilities that have never been achieved at this scale in open source.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
We’ve also updated our license to allow developers to use the outputs from Llama models — including 405B — to improve other models for the first time.
We’re excited about how this will enable new advancements in the field through synthetic data generation and model distillation workflows, capabilities that have never been achieved at this scale in open source.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/1
LLaMa 3.1 benchmarks side by side.
This is truly a SOTA model.
Beats GPT4 almost on every single benchmark.
Continuously trained with a 128K context length.
Pre-trained on 15.6T tokens (405B).
The fine-tuning data includes publicly available instruction datasets, as well as over 25M synthetically generated examples.
Most SFT examples were using synthetic data.
Trained on 16K H100 GPUs.
License allows output of the model to train other models
It seems like a future version integrated image, video, and speech capabilities using a compositional approach (not released yet).
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
LLaMa 3.1 benchmarks side by side.
This is truly a SOTA model.
Beats GPT4 almost on every single benchmark.
Continuously trained with a 128K context length.
Pre-trained on 15.6T tokens (405B).
The fine-tuning data includes publicly available instruction datasets, as well as over 25M synthetically generated examples.
Most SFT examples were using synthetic data.
Trained on 16K H100 GPUs.
License allows output of the model to train other models
It seems like a future version integrated image, video, and speech capabilities using a compositional approach (not released yet).
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196


1/1
With the introduction of Llama 3.1 405B, we now have an open-source model that beats the best closed-source one available today on selected benchmarks.
What a time.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
With the introduction of Llama 3.1 405B, we now have an open-source model that beats the best closed-source one available today on selected benchmarks.
What a time.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

1/1
This might be the biggest moment for Open-Source AI.
Meta just released Llama 3.1 and a 405 billion parameter model, the most sophisticated open model ever released.
It already outperforms GPT-4o on several benchmarks.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
This might be the biggest moment for Open-Source AI.
Meta just released Llama 3.1 and a 405 billion parameter model, the most sophisticated open model ever released.
It already outperforms GPT-4o on several benchmarks.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/1
Compared leaked Llama 3.1 benchmarks with other leading models, very excited for the release!
We can tier out models by price / 1M output tokens.
O($0.10): 4o-mini and <10B param models. I think 4o-mini will still be best but a strong local 8B will unlock lots of applications.
O($1): 70B class models, Haiku, 3.5-turbo. Distilled 70B looks like a category winner here! This is a nice price-point for lots of AI apps.
O($10): 405B, 4o, 3.5 Sonnet. Have to see how the post-training and harder benches go. Guess 3.5 sonnet is still the best, but 405B might give 4o real competition. This is just vibes, I like Sonnet's RLHF and hate the GPT RLHF.
Other takeaways:
- most benchmarks are saturated and probably not informative. OpenAI only reports harder benchmarks now, other developers should too (eg MATH > GSM8K)
- 405B doesn't look much better than distilled 70B, but harder benches and vibe tests will be better measurements than these tests
- 8B/70B distilled models are substantially better than when trained from scratch. I've wondered if for a given compute budget, it is better to overtrain a X param model or to train a X' (where X' >> X) and distill to X, maybe we will find out
- a lot of people thought that the original 8B saturated the params after 15T tokens. this is good evidence that it did not. softmax with high token count may have been why it did not quantize well. curious if the Llama 4 series will train in FP8 or BF16 -- logistically, serving 400B on 1x8H100 node seems much easier than 2x8H100 and it's much simpler to do this if the model was pretrained quantization-aware
- Gemma models do surprisingly well on MMLU relative to their other scores. most of the innovation in Gemma was supposed to be post-training, so curious if the 27B will hold up vs new 8B-Instruct
- Mistral Nemo 12B and 3.1 8B look somewhat similar, but I'd guess most developers will stick to Llama's better tooling and smaller param count. tough timing
- I am fairly sure that 3.1 was not trained early fusion, and somebody's going to throw up a Llava finetune in 2-3 days.
- personal guess (using other info) is that 405B-Instruct will fall short of Sonnet / 4o. but man, what a good model to have open source, and the gap is closing
- llama3.1405 looks like a Pi joke
all models are base except 4o-class, took the best available score from different repos and averaged MMLU for Llama. all benchmarks are wrong but hopefully useful for an overall picture.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Compared leaked Llama 3.1 benchmarks with other leading models, very excited for the release!
We can tier out models by price / 1M output tokens.
O($0.10): 4o-mini and <10B param models. I think 4o-mini will still be best but a strong local 8B will unlock lots of applications.
O($1): 70B class models, Haiku, 3.5-turbo. Distilled 70B looks like a category winner here! This is a nice price-point for lots of AI apps.
O($10): 405B, 4o, 3.5 Sonnet. Have to see how the post-training and harder benches go. Guess 3.5 sonnet is still the best, but 405B might give 4o real competition. This is just vibes, I like Sonnet's RLHF and hate the GPT RLHF.
Other takeaways:
- most benchmarks are saturated and probably not informative. OpenAI only reports harder benchmarks now, other developers should too (eg MATH > GSM8K)
- 405B doesn't look much better than distilled 70B, but harder benches and vibe tests will be better measurements than these tests
- 8B/70B distilled models are substantially better than when trained from scratch. I've wondered if for a given compute budget, it is better to overtrain a X param model or to train a X' (where X' >> X) and distill to X, maybe we will find out
- a lot of people thought that the original 8B saturated the params after 15T tokens. this is good evidence that it did not. softmax with high token count may have been why it did not quantize well. curious if the Llama 4 series will train in FP8 or BF16 -- logistically, serving 400B on 1x8H100 node seems much easier than 2x8H100 and it's much simpler to do this if the model was pretrained quantization-aware
- Gemma models do surprisingly well on MMLU relative to their other scores. most of the innovation in Gemma was supposed to be post-training, so curious if the 27B will hold up vs new 8B-Instruct
- Mistral Nemo 12B and 3.1 8B look somewhat similar, but I'd guess most developers will stick to Llama's better tooling and smaller param count. tough timing
- I am fairly sure that 3.1 was not trained early fusion, and somebody's going to throw up a Llava finetune in 2-3 days.
- personal guess (using other info) is that 405B-Instruct will fall short of Sonnet / 4o. but man, what a good model to have open source, and the gap is closing
- llama3.1405 looks like a Pi joke
all models are base except 4o-class, took the best available score from different repos and averaged MMLU for Llama. all benchmarks are wrong but hopefully useful for an overall picture.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

1/1
Mark Zuckerberg argues that it doesn't matter that China has access to open weights, because they will just steal weights anyway if they're closed. Pretty remarkable.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Mark Zuckerberg argues that it doesn't matter that China has access to open weights, because they will just steal weights anyway if they're closed. Pretty remarkable.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

1/11
gpt-4o mini scoring #2 on arena is historic. the ai train is passing the human intelligence station.
arena is an AI IQ test *and* a human IQ test.
the median arena voter can no longer distinguish between large, smart models and small, smart-sounding models.
models like:
>claude-3.5-sonnet
>caude-3-opus
>gpt-4-0314
feel *so* much smarter to smart people than:
>gpt-4o-mini
>gemini-1.5-flash
>claude-3-haiku
i whine so often about the death of <big_model_smell>. people largely agree. but gpt-4o-mini's victory is substantial proof, imo, that the median person isn't that bright, and that, for the first time in history, the AIs are smart enough to fool us. kinda wild, kinda historic
2/11
Simpler explanation: OpenAI is overfitting on lmsys arena data
3/11
if you think about it, it’s the same explanation lol
4/11
The biggest question I have for you is whether or not you think llama 405 has <big_model_smell>
5/11
it does. my opinion has improved since we last talked. still imperfect (especially with instruction following), but it's reasoning over context is *chefs kisss*
6/11
Or it's yet another dodgy benchmark, like all benchmarks.
No need to be dramatic about it.
7/11
I think the style of the response ends up being more important than the quality of the thinker behind the response. Claude tends to be less verbose, sometimes hesitant, but in a multi turn conversation is in a different league.
It may be as much about the personality of the LLM as its intelligence going forward.
8/11
i like this take.
cause I defo see a BIG difference between large and small models on complex tasks.
9/11
totally irrelevant but absolutely hilarious how literally no one is mentioning/talking about gemini 1.5 pro
10/11
Almost a kind of Turing test
11/11
history is a lot about people getting fooled by smart-sounding things, so in retrospect it isn't that surprising we are able to overfit AIs to it. it doesn't say much about the model's intelligence tho
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
gpt-4o mini scoring #2 on arena is historic. the ai train is passing the human intelligence station.
arena is an AI IQ test *and* a human IQ test.
the median arena voter can no longer distinguish between large, smart models and small, smart-sounding models.
models like:
>claude-3.5-sonnet
>caude-3-opus
>gpt-4-0314
feel *so* much smarter to smart people than:
>gpt-4o-mini
>gemini-1.5-flash
>claude-3-haiku
i whine so often about the death of <big_model_smell>. people largely agree. but gpt-4o-mini's victory is substantial proof, imo, that the median person isn't that bright, and that, for the first time in history, the AIs are smart enough to fool us. kinda wild, kinda historic
2/11
Simpler explanation: OpenAI is overfitting on lmsys arena data
3/11
if you think about it, it’s the same explanation lol
4/11
The biggest question I have for you is whether or not you think llama 405 has <big_model_smell>
5/11
it does. my opinion has improved since we last talked. still imperfect (especially with instruction following), but it's reasoning over context is *chefs kisss*
6/11
Or it's yet another dodgy benchmark, like all benchmarks.
No need to be dramatic about it.
7/11
I think the style of the response ends up being more important than the quality of the thinker behind the response. Claude tends to be less verbose, sometimes hesitant, but in a multi turn conversation is in a different league.
It may be as much about the personality of the LLM as its intelligence going forward.
8/11
i like this take.
cause I defo see a BIG difference between large and small models on complex tasks.
9/11
totally irrelevant but absolutely hilarious how literally no one is mentioning/talking about gemini 1.5 pro
10/11
Almost a kind of Turing test
11/11
history is a lot about people getting fooled by smart-sounding things, so in retrospect it isn't that surprising we are able to overfit AIs to it. it doesn't say much about the model's intelligence tho
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196



1/10
okay i’m excited for gpt-4o-mini fine-tuning, but chill lol.
the model costs $0.15 per 1M tokens (for openai: even less).
they’re donating at most $0.50 a day to you. (assuming you have a unique 2M token dataset for every day)
2/10
Aren't you conflating inference with training costs here?
3/10
there’s no technical explanation justifying a 20x up charge from standard input prices, beyond nominal hosting costs.
even if it cost them $6 to let you fine-tune, that’s still nothing. ~5% of their customers fine-tune, and of those, <1% will take substantial advantage of this
4/10
if you have a graph rag ready you want to transfer it all now, for free, great deal actually!
5/10
I was hoping they could reach price parity with chat models for inference
the initial cost savings will be long forgotten with 2x inference costs
wait why are we talking about them? I can hear the Llamas calling.
6/10
they are free because they want your ensemble....
7/10
@aidan_mclau, watcha' gonna do w/UR fiddy cent?
8/10
What if I start the fine-tuning at the end of the day and fine-tune it again at the start of the next day, than i would be having 4m tokens free
9/10
They just want you to pump your Llama 405b tokens to OpenAI
10/10
They're giving out free stuff, why complain that they let people know about it?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
okay i’m excited for gpt-4o-mini fine-tuning, but chill lol.
the model costs $0.15 per 1M tokens (for openai: even less).
they’re donating at most $0.50 a day to you. (assuming you have a unique 2M token dataset for every day)
2/10
Aren't you conflating inference with training costs here?
3/10
there’s no technical explanation justifying a 20x up charge from standard input prices, beyond nominal hosting costs.
even if it cost them $6 to let you fine-tune, that’s still nothing. ~5% of their customers fine-tune, and of those, <1% will take substantial advantage of this
4/10
if you have a graph rag ready you want to transfer it all now, for free, great deal actually!
5/10
I was hoping they could reach price parity with chat models for inference
the initial cost savings will be long forgotten with 2x inference costs
wait why are we talking about them? I can hear the Llamas calling.
6/10
they are free because they want your ensemble....
7/10
@aidan_mclau, watcha' gonna do w/UR fiddy cent?
8/10
What if I start the fine-tuning at the end of the day and fine-tune it again at the start of the next day, than i would be having 4m tokens free
9/10
They just want you to pump your Llama 405b tokens to OpenAI
10/10
They're giving out free stuff, why complain that they let people know about it?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

1/11
lmao i dumped a paper into 405's context with no further instructions and instead of summarizing or talking about it, 405 just leaked its entire system message
2/11
As intended, of course, it's designed to be transparent to users about it's system prompt (the new open-prompt model)
3/11
no it leaked the system message i provided
4/11
meta chat interface's system prompt?
this'd be provider-dependent
5/11
no mine
6/11
This is the base model, not instruct, correct?
7/11
instruct
8/11
that's actually good for bitcoin
9/11
adorable
10/11
I’ve seen some weirdness with 70b, I put a document into its context and after a few messages it started outputting and hyperfocusing on the same unrelated sections from the document. This was using AnythingLLM’s pinned documents with Ollama as a backend. Possibly related?
11/11
B-but it has state of the art IFEVAL
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
lmao i dumped a paper into 405's context with no further instructions and instead of summarizing or talking about it, 405 just leaked its entire system message
2/11
As intended, of course, it's designed to be transparent to users about it's system prompt (the new open-prompt model)
3/11
no it leaked the system message i provided
4/11
meta chat interface's system prompt?
this'd be provider-dependent
5/11
no mine
6/11
This is the base model, not instruct, correct?
7/11
instruct
8/11
that's actually good for bitcoin
9/11
adorable
10/11
I’ve seen some weirdness with 70b, I put a document into its context and after a few messages it started outputting and hyperfocusing on the same unrelated sections from the document. This was using AnythingLLM’s pinned documents with Ollama as a backend. Possibly related?
11/11
B-but it has state of the art IFEVAL
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

1/11
3.1 8b is under-discussed imo
>crazy benchmarks
>crushing gemma 2 (already great model)
>on groq my response was instant lol
>no streaming
>the response just appeared
>we have instant brains now?
2/11
We finally have SOTA at home
3/11
for QA what we need is multi-stage responses where it generates a presentation then it presents it (optionally). So the presenter would walk you through the presentation, highlighting the points/images and discussing them. even without voice it could be as tap/hover
4/11
Yup, even if it's not THE BEST, we have gpt3.5~ at home
5/11
How clean's the distillation? Does it have that overly-synthetic Phi3/4o/Sonnet3.5 feel?
6/11
Wait till you see what I can do with this model at home. LOL.
7/11
It's insane
You really have to use it live to "feel" the insane speed
8/11
Definitely, model is insane in its category
9/11
i think meta should be putting gpt-4o-mini on the charts instead of 3.5
10/11
mini models are the future, we just need to learn how to go wide with them.
gotta do a bit of unhobbling to coordinate thousands/millions of instances together with the instant outputs.
11/11
And I can actually run it on my PC lmao
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
3.1 8b is under-discussed imo
>crazy benchmarks
>crushing gemma 2 (already great model)
>on groq my response was instant lol
>no streaming
>the response just appeared
>we have instant brains now?
2/11
We finally have SOTA at home
3/11
for QA what we need is multi-stage responses where it generates a presentation then it presents it (optionally). So the presenter would walk you through the presentation, highlighting the points/images and discussing them. even without voice it could be as tap/hover
4/11
Yup, even if it's not THE BEST, we have gpt3.5~ at home
5/11
How clean's the distillation? Does it have that overly-synthetic Phi3/4o/Sonnet3.5 feel?
6/11
Wait till you see what I can do with this model at home. LOL.
7/11
It's insane
You really have to use it live to "feel" the insane speed
8/11
Definitely, model is insane in its category
9/11
i think meta should be putting gpt-4o-mini on the charts instead of 3.5
10/11
mini models are the future, we just need to learn how to go wide with them.
gotta do a bit of unhobbling to coordinate thousands/millions of instances together with the instant outputs.
11/11
And I can actually run it on my PC lmao
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/11
What can you do with Llama quality and Groq speed? You can do Instant. That's what. Try Llama 3.1 8B for instant intelligence on Groq is Fast AI Inference.
2/11
This is so cool. Feeling the AGI - you just talk to your computer and it does stuff, instantly. Speed really makes AI so much more pleasing.
3/11
Well, I stand corrected. I thought it was going to take your team at least 24 hours to get this going, but I should’ve known better.
4/11
Holy crap this is fast AND smart
5/11
Speed like that is going to enable a new wave of innovative uses.
6/11
will u update the pricing for the new llama 3.1 models?
7/11
Very quick.
Very impressive.
Can’t wait to try !
!
8/11
I do like me some 'Guu with Garlic' at 7 pm.
9/11
What's the best way to do custom models (not fine tuned) with Groq chips?
10/11
Extremely impressive!
11/11
ASI will happen soon.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
What can you do with Llama quality and Groq speed? You can do Instant. That's what. Try Llama 3.1 8B for instant intelligence on Groq is Fast AI Inference.
2/11
This is so cool. Feeling the AGI - you just talk to your computer and it does stuff, instantly. Speed really makes AI so much more pleasing.
3/11
Well, I stand corrected. I thought it was going to take your team at least 24 hours to get this going, but I should’ve known better.
4/11
Holy crap this is fast AND smart
5/11
Speed like that is going to enable a new wave of innovative uses.
6/11
will u update the pricing for the new llama 3.1 models?
7/11
Very quick.
Very impressive.
Can’t wait to try
!8/11
I do like me some 'Guu with Garlic' at 7 pm.
9/11
What's the best way to do custom models (not fine tuned) with Groq chips?
10/11
Extremely impressive!
11/11
ASI will happen soon.
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/9
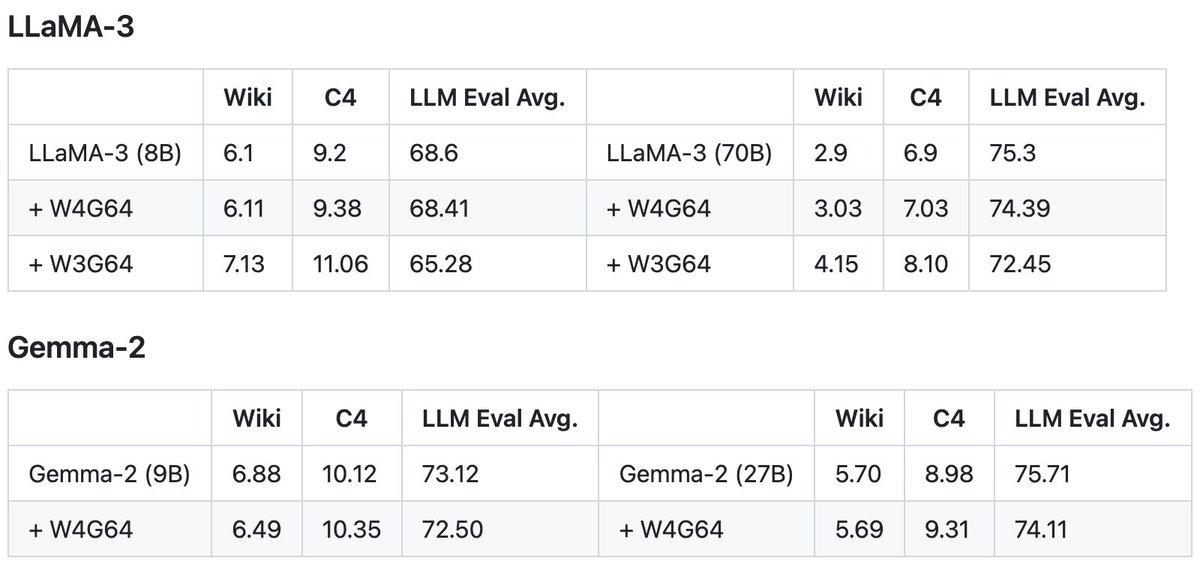
Introducing FLUTE, a CUDA kernel for non-uniformly quantized (via a lookup table) LLM Inference. It accelerates QLoRA's NormalFloat (NF) out of the box and more.
As an application, we extended NF4 and are releasing quantized models for LLaMA-3 (8B/70B) and Gemma-2 (9B/27B).
Highlights:
- Support arbitrary mapping between (de)quantized tensors via a lookup table (INT4, FP4, NF4, etc).
- Up to 2-3x faster than dense GEMM kernels.
- 1.3x to 2.6x end-to-end latency improvement (vLLM).
- Batch inference, 4/3-bits, and various group sizes.
- vLLM integration and 10+ pre-quantized models off-the-shelf.
And, for those who care:
- Almost entirely written in CUTLASS 3 (i.e., CuTe).
- Uses TensorCore, Async Copy, and Stream-K.
- Tailored to Ampere GPUs.
Paper: [2407.10960] Fast Matrix Multiplications for Lookup Table-Quantized LLMs
Code: GitHub - HanGuo97/flute: Fast Matrix Multiplications for Lookup Table-Quantized LLMs
This is in collaboration with @exists_forall @radi_cho @jrk @ericxing @yoonrkim.
2/9
Writing a CUDA kernel is fun but comes with a steep learning curve. Huge thanks to @exists_forall for being my go-to expert on all things CUDA/GPU. Special shoutout to @radi_cho, who just graduated high school and is the brains behind our quantized models — he’s off to Stanford for college, so go work with him if you can! Finally, we also benefited a lot from discussions with Dmytro Ivchenko and Yijie Bei at @FireworksAI_HQ!
3/9
This is amazing! Congratulations Han!
4/9
Thank you!
5/9
Great example of cute!
6/9
Thank you!
And to others, you should take a look at BitBLAS GitHub - microsoft/BitBLAS: BitBLAS is a library to support mixed-precision matrix multiplications, especially for quantized LLM deployment. —- it’s cool!
7/9
YOOOOOO this is sick dude
8/9
Great job!
9/9
Nice job !
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Introducing FLUTE, a CUDA kernel for non-uniformly quantized (via a lookup table) LLM Inference. It accelerates QLoRA's NormalFloat (NF) out of the box and more.
As an application, we extended NF4 and are releasing quantized models for LLaMA-3 (8B/70B) and Gemma-2 (9B/27B).
Highlights:
- Support arbitrary mapping between (de)quantized tensors via a lookup table (INT4, FP4, NF4, etc).
- Up to 2-3x faster than dense GEMM kernels.
- 1.3x to 2.6x end-to-end latency improvement (vLLM).
- Batch inference, 4/3-bits, and various group sizes.
- vLLM integration and 10+ pre-quantized models off-the-shelf.
And, for those who care:
- Almost entirely written in CUTLASS 3 (i.e., CuTe).
- Uses TensorCore, Async Copy, and Stream-K.
- Tailored to Ampere GPUs.
Paper: [2407.10960] Fast Matrix Multiplications for Lookup Table-Quantized LLMs
Code: GitHub - HanGuo97/flute: Fast Matrix Multiplications for Lookup Table-Quantized LLMs
This is in collaboration with @exists_forall @radi_cho @jrk @ericxing @yoonrkim.
2/9
Writing a CUDA kernel is fun but comes with a steep learning curve. Huge thanks to @exists_forall for being my go-to expert on all things CUDA/GPU. Special shoutout to @radi_cho, who just graduated high school and is the brains behind our quantized models — he’s off to Stanford for college, so go work with him if you can! Finally, we also benefited a lot from discussions with Dmytro Ivchenko and Yijie Bei at @FireworksAI_HQ!
3/9
This is amazing! Congratulations Han!
4/9
Thank you!
5/9
Great example of cute!
6/9
Thank you!
And to others, you should take a look at BitBLAS GitHub - microsoft/BitBLAS: BitBLAS is a library to support mixed-precision matrix multiplications, especially for quantized LLM deployment. —- it’s cool!
7/9
YOOOOOO this is sick dude
8/9
Great job!
9/9
Nice job !
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196



1/11
Thanks to the new FLUTE cuda kernel I should be able to run the largest llama 3 model (405B) at home with pretty good throughput (4bit, 10x3090, vLLM)
2/11
Already setting it up GitHub - HanGuo97/flute: Fast Matrix Multiplications for Lookup Table-Quantized LLMs
3/11
Generally speaking the electrical bill is not that bad since the cards are mostly idle even under heavy load with inference (unless it’s constant training) it’s acceptable
4/11
An alternative will be AWQ
5/11
Outside of personal use it will make sense to just use a hosted provider like together or fireworks (maybe groq?)
6/11
Wife gonna love that electricity bill
7/11
You might be interested in this Quad OCuLink box with @AMD /search?q=#W7900 GPUs (48GiB VRAM each.) Box is 96GiB RAM, 16 cores, 2x 4TB Gen5 NVMe. It's also easily powered by single household circuit. W7900 professional GPUs are ~$3400 on Amazon, of course.
Cf. 3 GPUs Montreal Airbnb
8/11
For your setup do you need x16 PCIE risers or can you get away with the x1 ones?
9/11
Context VRAM should be insanely huge even at 4bit 405B params, no?
10/11
I say just use the 70b model using bfloat16, the revised model looks excellent, but let us know if you see significant differences between the two in your use cases
11/11
10…..
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Thanks to the new FLUTE cuda kernel I should be able to run the largest llama 3 model (405B) at home with pretty good throughput (4bit, 10x3090, vLLM)
2/11
Already setting it up GitHub - HanGuo97/flute: Fast Matrix Multiplications for Lookup Table-Quantized LLMs
3/11
Generally speaking the electrical bill is not that bad since the cards are mostly idle even under heavy load with inference (unless it’s constant training) it’s acceptable
4/11
An alternative will be AWQ
5/11
Outside of personal use it will make sense to just use a hosted provider like together or fireworks (maybe groq?)
6/11
Wife gonna love that electricity bill
7/11
You might be interested in this Quad OCuLink box with @AMD /search?q=#W7900 GPUs (48GiB VRAM each.) Box is 96GiB RAM, 16 cores, 2x 4TB Gen5 NVMe. It's also easily powered by single household circuit. W7900 professional GPUs are ~$3400 on Amazon, of course.
Cf. 3 GPUs Montreal Airbnb
8/11
For your setup do you need x16 PCIE risers or can you get away with the x1 ones?
9/11
Context VRAM should be insanely huge even at 4bit 405B params, no?
10/11
I say just use the 70b model using bfloat16, the revised model looks excellent, but let us know if you see significant differences between the two in your use cases
11/11
10…..
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196




Last edited:
1/11
the ramifications of these benchmarks being both true and reproducible are pretty hard to overstate. if the instruct version has the conventional improvements over base, this will represent a monumental shift in ... kind of everything LLM related ...
2/11
Do you think this is par for a 400B model (or basically anything that huge)?
3/11
no, params on their own are useless without the proper data and training pipelines. the meta team appears to have put these params to good use (again, if this proves to be reproducible)
4/11
Yep
5/11
woah
6/11
The low human eval score is worrisome for coding
7/11
Maybe they did something like this? Guess we’ll know soon enough [2406.14491v1] Instruction Pre-Training: Language Models are Supervised Multitask Learners
8/11
Now you know why OpenAI was in such a rush to get 4o Mini out the door!
9/11
holy shyt
10/11
What should I ask
11/11
truth. unlocks lots of things that were almost possible.
feels like christmas eve
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
the ramifications of these benchmarks being both true and reproducible are pretty hard to overstate. if the instruct version has the conventional improvements over base, this will represent a monumental shift in ... kind of everything LLM related ...
2/11
Do you think this is par for a 400B model (or basically anything that huge)?
3/11
no, params on their own are useless without the proper data and training pipelines. the meta team appears to have put these params to good use (again, if this proves to be reproducible)
4/11
Yep
5/11
woah
6/11
The low human eval score is worrisome for coding
7/11
Maybe they did something like this? Guess we’ll know soon enough [2406.14491v1] Instruction Pre-Training: Language Models are Supervised Multitask Learners
8/11
Now you know why OpenAI was in such a rush to get 4o Mini out the door!
9/11
holy shyt
10/11
What should I ask
11/11
truth. unlocks lots of things that were almost possible.
feels like christmas eve
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

