Mark Zuckerberg outlines why he believes open source AI is good for developers, Meta and the world.

about.fb.com
Open Source AI Is the Path Forward
July 23, 2024
By Mark Zuckerberg, Founder and CEO
In the early days of high-performance computing, the major tech companies of the day each invested heavily in developing their own closed source versions of Unix. It was hard to imagine at the time that any other approach could develop such advanced software. Eventually though, open source Linux gained popularity – initially because it allowed developers to modify its code however they wanted and was more affordable, and over time because it became more advanced, more secure, and had a broader ecosystem supporting more capabilities than any closed Unix. Today, Linux is the industry standard foundation for both cloud computing and the operating systems that run most mobile devices – and we all benefit from superior products because of it.
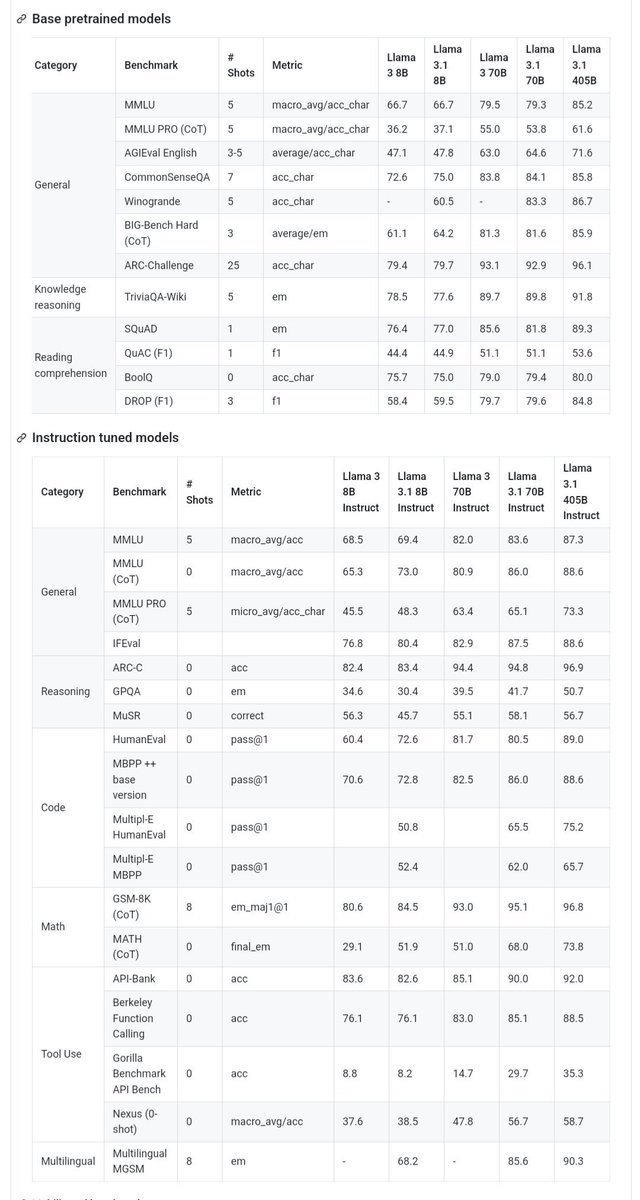
I believe that AI will develop in a similar way. Today, several tech companies are developing leading closed models. But open source is quickly closing the gap. Last year, Llama 2 was only comparable to an older generation of models behind the frontier. This year, Llama 3 is competitive with the most advanced models and leading in some areas. Starting next year, we expect future Llama models to become the most advanced in the industry. But even before that, Llama is already leading on openness, modifiability, and cost efficiency.
Today we’re taking the next steps towards open source AI becoming the industry standard. We’re releasing Llama 3.1 405B, the first frontier-level open source AI model, as well as new and improved Llama 3.1 70B and 8B models. In addition to having significantly better cost/performance relative to closed models, the fact that the 405B model is open will make it the best choice for fine-tuning and distilling smaller models.
Beyond releasing these models, we’re working with a range of companies to grow the broader ecosystem. Amazon, Databricks, and NVIDIA are launching full suites of services to support developers fine-tuning and distilling their own models. Innovators like Groq have built low-latency, low-cost inference serving for all the new models. The models will be available on all major clouds including AWS, Azure, Google, Oracle, and more. Companies like Scale.AI, Dell, Deloitte, and others are ready to help enterprises adopt Llama and train custom models with their own data. As the community grows and more companies develop new services, we can collectively make Llama the industry standard and bring the benefits of AI to everyone.
Meta is committed to open source AI. I’ll outline why I believe open source is the best development stack for you, why open sourcing Llama is good for Meta, and why open source AI is good for the world and therefore a platform that will be around for the long term.
Why Open Source AI Is Good for Developers
When I talk to developers, CEOs, and government officials across the world, I usually hear several themes:
- We need to train, fine-tune, and distill our own models. Every organization has different needs that are best met with models of different sizes that are trained or fine-tuned with their specific data. On-device tasks and classification tasks require small models, while more complicated tasks require larger models. Now you’ll be able to take the most advanced Llama models, continue training them with your own data and then distill them down to a model of your optimal size – without us or anyone else seeing your data.
- We need to control our own destiny and not get locked into a closed vendor. Many organizations don’t want to depend on models they cannot run and control themselves. They don’t want closed model providers to be able to change their model, alter their terms of use, or even stop serving them entirely. They also don’t want to get locked into a single cloud that has exclusive rights to a model. Open source enables a broad ecosystem of companies with compatible toolchains that you can move between easily.
- We need to protect our data. Many organizations handle sensitive data that they need to secure and can’t send to closed models over cloud APIs. Other organizations simply don’t trust the closed model providers with their data. Open source addresses these issues by enabling you to run the models wherever you want. It is well-accepted that open source software tends to be more secure because it is developed more transparently.
- We need a model that is efficient and affordable to run. Developers can run inference on Llama 3.1 405B on their own infra at roughly 50% the cost of using closed models like GPT-4o, for both user-facing and offline inference tasks.
- We want to invest in the ecosystem that’s going to be the standard for the long term. Lots of people see that open source is advancing at a faster rate than closed models, and they want to build their systems on the architecture that will give them the greatest advantage long term.
Why Open Source AI Is Good for Meta
Meta’s business model is about building the best experiences and services for people. To do this, we must ensure that we always have access to the best technology, and that we’re not locking into a competitor’s closed ecosystem where they can restrict what we build.
One of my formative experiences has been building our services constrained by what Apple will let us build on their platforms. Between the way they tax developers, the arbitrary rules they apply, and all the product innovations they block from shipping, it’s clear that Meta and many other companies would be freed up to build much better services for people if we could build the best versions of our products and competitors were not able to constrain what we could build. On a philosophical level, this is a major reason why I believe so strongly in building open ecosystems in AI and AR/VR for the next generation of computing.
People often ask if I’m worried about giving up a technical advantage by open sourcing Llama, but I think this misses the big picture for a few reasons:
First, to ensure that we have access to the best technology and aren’t locked into a closed ecosystem over the long term, Llama needs to develop into a full ecosystem of tools, efficiency improvements, silicon optimizations, and other integrations. If we were the only company using Llama, this ecosystem wouldn’t develop and we’d fare no better than the closed variants of Unix.
Second, I expect AI development will continue to be very competitive, which means that open sourcing any given model isn’t giving away a massive advantage over the next best models at that point in time. The path for Llama to become the industry standard is by being consistently competitive, efficient, and open generation after generation.
Third, a key difference between Meta and closed model providers is that selling access to AI models isn’t our business model. That means openly releasing Llama doesn’t undercut our revenue, sustainability, or ability to invest in research like it does for closed providers. (This is one reason several closed providers consistently lobby governments against open source.)
Finally, Meta has a long history of open source projects and successes. We’ve saved billions of dollars by releasing our server, network, and data center designs with Open Compute Project and having supply chains standardize on our designs. We benefited from the ecosystem’s innovations by open sourcing leading tools like PyTorch, React, and many more tools. This approach has consistently worked for us when we stick with it over the long term.You can access the models now at
llama.meta.com.











 Any mention of the UK? Although we're no longer subject to directives, I think we still align with most EU policies.
Any mention of the UK? Although we're no longer subject to directives, I think we still align with most EU policies.























 to the futuristic vibe of Image 2
to the futuristic vibe of Image 2  , it's all about loving the process. Stay tuned, as we're cooking up an incredible image hub where images can be easily generated and transformed with AI!
, it's all about loving the process. Stay tuned, as we're cooking up an incredible image hub where images can be easily generated and transformed with AI! 







 .
.
 Hungry for more knowledge on Diffusion Acceleration? Don't miss out on @sedielem's blog for a holistic view of diffusion distillation! Another 1-hour tour that will leave you inspired and equipped with even more insights! :D
Hungry for more knowledge on Diffusion Acceleration? Don't miss out on @sedielem's blog for a holistic view of diffusion distillation! Another 1-hour tour that will leave you inspired and equipped with even more insights! :D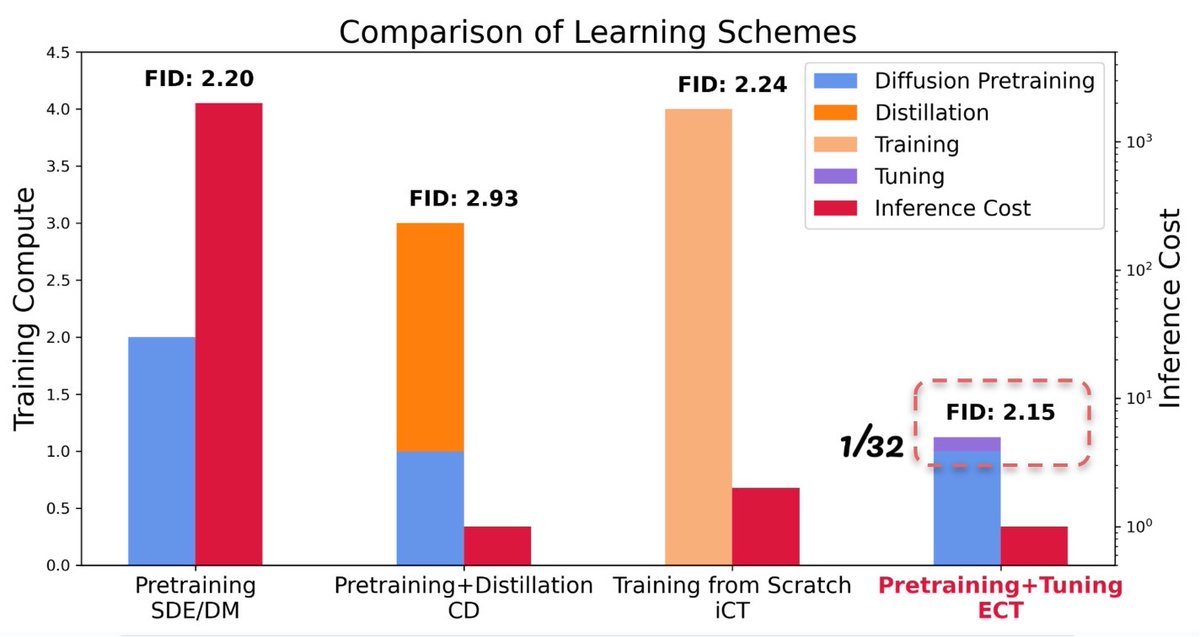


 Presenting 𝐃𝐄𝐏𝐈𝐂𝐓: Diffusion-Enabled Permutation Importance for Image Classification Tasks /search?q=#ECCV2024
Presenting 𝐃𝐄𝐏𝐈𝐂𝐓: Diffusion-Enabled Permutation Importance for Image Classification Tasks /search?q=#ECCV2024 Project Page:
Project Page:  Paper:
Paper:  Github:
Github:  @gregkondas (𝐚𝐩𝐩𝐥𝐲𝐢𝐧𝐠 𝐭𝐨 𝐏𝐡𝐃𝐬!), @msjoding @ellakaz David Fouhey and Jenna Wiens
@gregkondas (𝐚𝐩𝐩𝐥𝐲𝐢𝐧𝐠 𝐭𝐨 𝐏𝐡𝐃𝐬!), @msjoding @ellakaz David Fouhey and Jenna Wiens 


 Artist: Aesthetically Controllable Text-Driven Stylization without Training
Artist: Aesthetically Controllable Text-Driven Stylization without Training