
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?Let's reproduce GPT-2 (1.6B): one 8XH100 node, 24 hours, $672, in llm.c #677
Let's reproduce GPT-2 (1.6B): one 8XH100 node, 24 hours, $672, in llm.c · karpathy llm.c · Discussion #677
In this post we are reproducing GPT-2 in llm.c. This is "the GPT-2", the full, 1558M parameter version that was introduced in OpenAI's blog post Better Language Models and their Implications in Feb...
 github.com
github.com

LLM Generality is a Timeline Crux — LessWrong
Short Summary LLMs may be fundamentally incapable of fully general reasoning, and if so, short timelines are less plausible. …
 www.lesswrong.com
www.lesswrong.com
LLM Generality is a Timeline Crux
by eggsyntax9 min read
24th Jun 2024 87 comments
Short Summary
LLMs may be fundamentally incapable of fully general reasoning, and if so, short timelines are less plausible.Longer summary
There is ML research suggesting that LLMs fail badly on attempts at general reasoning, such as planning problems, scheduling, and attempts to solve novel visual puzzles. This post provides a brief introduction to that research, and asks:- Whether this limitation is illusory or actually exists.
- If it exists, whether it will be solved by scaling or is a problem fundamental to LLMs.
- If fundamental, whether it can be overcome by scaffolding & tooling.
If this is a real and fundamental limitation that can't be fully overcome by scaffolding, we should be skeptical of arguments like Leopold Aschenbrenner's (in his recent 'Situational Awareness') that we can just 'follow straight lines on graphs' and expect AGI in the next few years.
Introduction
Leopold Aschenbrenner's recent ' Situational Awareness' document has gotten considerable attention in the safety & alignment community. Aschenbrenner argues that we should expect current systems to reach human-level given further scaling, and that it's 'strikingly plausible' that we'll see 'drop-in remote workers' capable of doing the work of an AI researcher or engineer by 2027. Others hold similar views.Francois Chollet and Mike Knoop's new $500,000 prize for beating the ARC benchmark has also gotten considerable recent attention in AIS. Chollet holds a diametrically opposed view: that the current LLM approach is fundamentally incapable of general reasoning, and hence incapable of solving novel problems. We only imagine that LLMs can reason, Chollet argues, because they've seen such a vast wealth of problems that they can pattern-match against. But LLMs, even if scaled much further, will never be able to do the work of AI researchers.
It would be quite valuable to have a thorough analysis of this question through the lens of AI safety and alignment. This post is not that nor is it a review of the voluminous literature on this debate (from outside the AIS community). It attempts to briefly introduce the disagreement, some evidence on each side, and the impact on timelines.
What is general reasoning?
Part of what makes this issue contentious is that there's not a widely shared definition of 'general reasoning', and in fact various discussions of this use various terms. By 'general reasoning', I mean to capture two things. First, the ability to think carefully and precisely, step by step. Second, the ability to apply that sort of thinking in novel situations.Terminology is inconsistent between authors on this subject; some call this 'system II thinking'; some 'reasoning'; some 'planning' (mainly for the first half of the definition); Chollet just talks about 'intelligence' (mainly for the second half).
This issue is further complicated by the fact that humans aren't fully general reasoners without tool support either. For example, seven-dimensional tic-tac-toe is a simple and easily defined system, but incredibly difficult for humans to play mentally without extensive training and/or tool support. Generalizations that are in-distribution for humans seems like something that any system should be able to do; generalizations that are out-of-distribution for humans don't feel as though they ought to count.
How general are LLMs?
It's important to clarify that this is very much a matter of degree. Nearly everyone was surprised by the degree to which the last generation of state-of-the-art LLMs like GPT-3 generalized; for example, no one I know of predicted that LLMs trained on primarily English-language sources would be able to do translation between languages. Some in the field argued as recently as 2020 that no pure LLM would ever able to correctly complete Three plus five equals. The question is how general they are.Certainly state-of-the-art LLMs do an enormous number of tasks that, from a user perspective, count as general reasoning. They can handle plenty of mathematical and scientific problems; they can write decent code; they can certainly hold coherent conversations.; they can answer many counterfactual questions; they even predict Supreme Court decisions pretty well. What are we even talking about when we question how general they are?
The surprising thing we find when we look carefully is that they fail pretty badly when we ask them to do certain sorts of reasoning tasks, such as planning problems, that would be fairly straightforward for humans. If in fact they were capable of general reasoning, we wouldn't expect these sorts of problems to present a challenge. Therefore it may be that all their apparent successes at reasoning tasks are in fact simple extensions of examples they've seen in their truly vast corpus of training data. It's hard to internalize just how many examples they've actually seen; one way to think about it is that they've absorbed nearly all of human knowledge.
The weakman version of this argument is the Stochastic Parrot claim, that LLMs are executing relatively shallow statistical inference on an extremely complex training distribution, ie that they're "a blurry JPEG of the web" ( Ted Chiang). This view seems obviously false at this point (given that, for example, LLMs appear to build world models), but assuming that LLMs are fully general may be an overcorrection.
Note that this is different from the (also very interesting) question of what LLMs, or the transformer architecture, are capable of accomplishing in a single forward pass. Here we're talking about what they can do under typical auto-regressive conditions like chat.
Evidence for generality
I take this to be most people's default view, and won't spend much time making the case. GPT-4 and Claude 3 Opus seem obviously be capable of general reasoning. You can find places where they hallucinate, but it's relatively hard to find cases in most people's day-to-day use where their reasoning is just wrong. But if you want to see the case made explicitly, see for example "Sparks of AGI" (from Microsoft, on GPT-4) or recent models' performance on benchmarks like MATH which are intended to judge reasoning ability.Further, there's been a recurring pattern (eg in much of Gary Marcus's writing) of people claiming that LLMs can never do X, only to be promptly proven wrong when the next version comes out. By default we should probably be skeptical of such claims.
One other thing worth noting is that we know from 'The Expressive Power of Transformers with Chain of Thought' that the transformer architecture is capable of general reasoning under autoregressive conditions. That doesn't mean LLMs trained on next-token prediction learn general reasoning, but it means that we can't just rule it out as impossible.
Evidence against generality
The literature here is quite extensive, and I haven't reviewed it all. Here are three examples that I personally find most compelling. For a broader and deeper review, see "A Survey of Reasoning with Foundation Models".Block world
All LLMs to date fail rather badly at classic problems of rearranging colored blocks. We do see improvement with scale here, but if these problems are obfuscated, performance of even the biggest LLMs drops to almost nothing.

Scheduling
LLMs currently do badly at planning trips or scheduling meetings between people with availability constraints [a commenter points out that this paper has quite a few errors, so it should likely be treated with skepticism].
ARC-AGI
Current LLMs do quite badly on the ARC visual puzzles, which are reasonably easy for smart humans.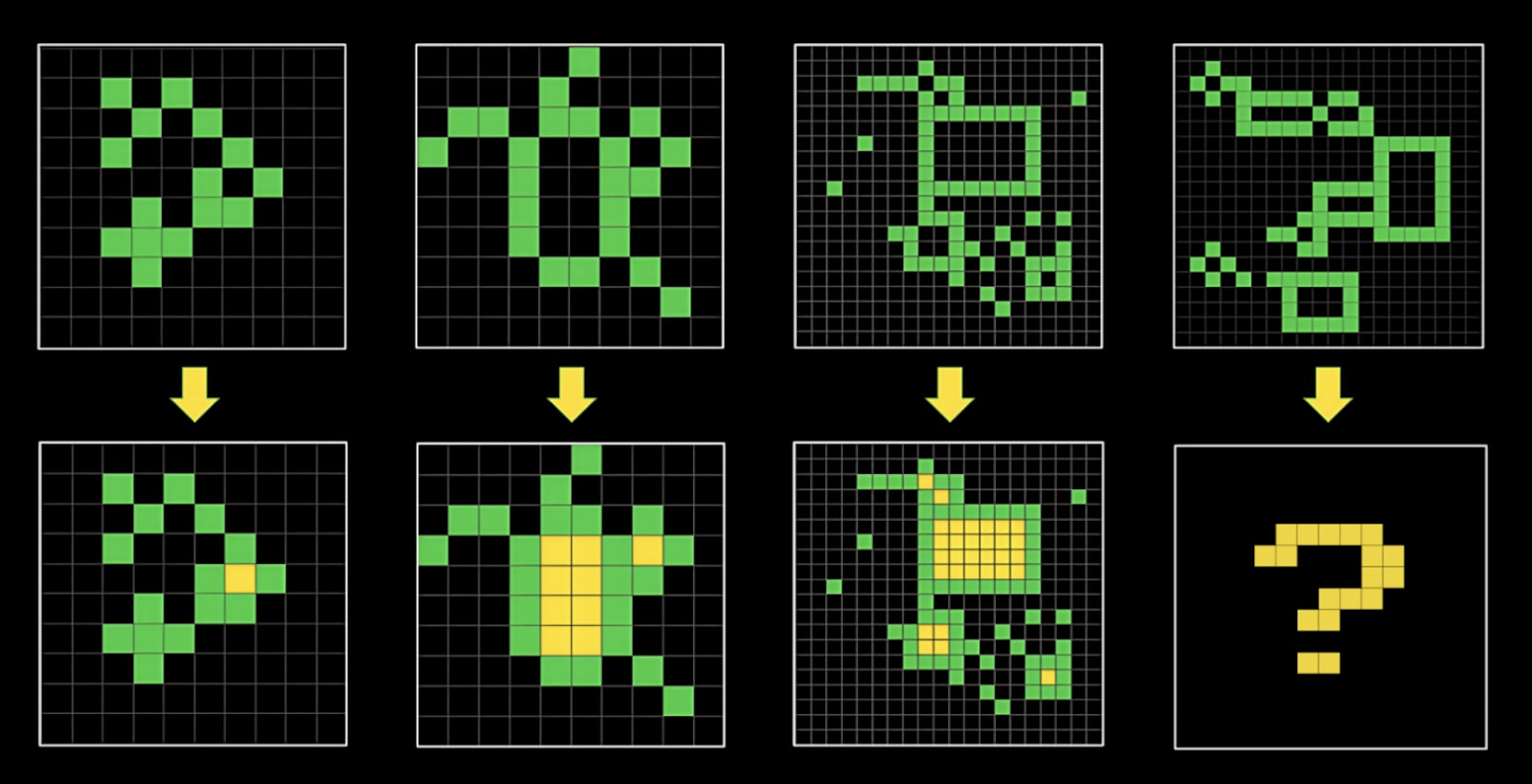
The evidence on this is somewhat mixed. Evidence that it will includes LLMs doing better on many of these tasks as they scale. The strongest evidence that it won't is that LLMs still fail miserably on block world problems once you obfuscate the problems (to eliminate the possibility that larger LLMs only do better because they have a larger set of examples to draw from).One argument made by Sholto Douglas and Trenton Bricken (in a discussion with Dwarkesh Patel) is that this is a simple matter of reliability -- given a 5% failure rate, an AI will most often fail to successfully execute a task that requires 15 correct steps. If that's the case, we have every reason to believe that further scaling will solve the problem.
Will scaffolding or tooling solve this problem?
This is another open question. It seems natural to expect that LLMs could be used as part of scaffolded systems that include other tools optimized for handling general reasoning (eg classic planners like STRIPS), or LLMs can be given access to tools (eg code sandboxes) that they can use to overcome these problems. Ryan Greenblatt's new work on getting very good results on ARC with GPT-4o + a Python interpreter provides some evidence for this.On the other hand, a year ago many expected scaffolds like AutoGPT and BabyAGI to result in effective LLM-based agents, and many startups have been pushing in that direction; so far results have been underwhelming. Difficulty with planning and novelty seems like the most plausible explanation.
Even if tooling is sufficient to overcome this problem, outcomes depend heavily on the level of integration and performance. Currently for an LLM to make use of a tool, it has to use a substantial number of forward passes to describe the call to the tool, wait for the tool to execute, and then parse the response. If this remains true, then it puts substantial constraints on how heavily LLMs can rely on tools without being too slow to be useful. If, on the other hand, such tools can be more deeply integrated, this may no longer apply. Of course, even if it's slow there are some problems where it's worth spending a large amount of time, eg novel research. But it does seem like the path ahead looks somewhat different if system II thinking remains necessarily slow & external.
Why does this matter?
The main reason that this is important from a safety perspective is that it seems likely to significantly impact timelines. If LLMs are fundamentally incapable of certain kinds of reasoning, and scale won't solve this (at least in the next couple of orders of magnitude), and scaffolding doesn't adequately work around it, then we're at least one significant breakthrough away from dangerous AGI -- it's pretty hard to imagine an AI system executing a coup if it can't successfully schedule a meeting with several of its co-conspirator instances.If, on the other hand, there is no fundamental blocker to LLMs being able to do general reasoning, then Aschenbrenner's argument starts to be much more plausible, that another couple of orders of magnitude can get us to the drop-in AI researcher, and once that happens, further progress seems likely to move very fast indeed.
So this is an area worth keeping a close eye on. I think that progress on the ARC prize will tell us a lot, now that there's half a million dollars motivating people to try for it. I also think the next generation of frontier LLMs will be highly informative -- it's plausible that GPT-4 is just on the edge of being able to effectively do multi-step general reasoning, and if so we should expect GPT-5 to be substantially better at it (whereas if GPT-5 doesn't show much improvement in this area, arguments like Chollet's and Kambhampati's are strengthened).
OK, but what do you think?
I genuinely don't know! It's one of the most interesting and important open questions about the current state of AI. My best guesses are:- LLMs continue to do better at block world and ARC as they scale: 75%
- LLMs entirely on their own reach the grand prize mark on the ARC prize (solving 85% of problems on the open leaderboard) before hybrid approaches like Ryan's: 10%
- Scaffolding & tools help a lot, so that the next gen (GPT-5, Claude 4) + Python + a for loop can reach the grand prize mark 60%
- Same but for the gen after that (GPT-6, Claude 5): 75%
- The current architecture, including scaffolding & tools, continues to improve to the point of being able to do original AI research: 65%, with high uncertainty
1/8
LLMs & Planning: Our story so far..
Can't plan: [2305.15771] On the Planning Abilities of Large Language Models : A Critical Investigation
CoT doesn't help: [2405.04776] Chain of Thoughtlessness? An Analysis of CoT in Planning
ReAct doesn't help: [2405.13966] On the Brittle Foundations of ReAct Prompting for Agentic Large Language Models
Can't self-verify: [2402.08115] On the Self-Verification Limitations of Large Language Models on Reasoning and Planning Tasks
Can help in LLM-Modulo: [2402.01817] LLMs Can't Plan, But Can Help Planning in LLM-Modulo Frameworks
to be contd..
2/8
A recent overview talk
3/8
I will also give an #ICML2024 Tutorial on this topic; see you in Vienna on July 22nd afternoon (..due no doubt to a bout of mad masochism..)
ICML 2024 Tutorials
4/8
So our paper on LLM-Modulo Frameworks ([2402.01817] LLMs Can't Plan, But Can Help Planning in LLM-Modulo Frameworks) got a spotlight nod at #ICML2024. Expect to see me holding forth in front of ourberibboned poster on 7/23.. (As for the oral--that will be part of the tutorial ICML Tutorial Understanding the Role of Large Language Models in Planning the day before.. )
5/8
LLM-Modulo is basically an "acceptance sampling" mechanism (with back prompts on what is wrong for each rejected candidate). See (to be presented at #ICML2024)
6/8
Sorry--the cut and paste of the graphic got low res. This is the link to that NYAS paper:
7/8
What is called "Zeroshot CoT" in the results is the "let's think step by step" magical incantation; it just doesn't work.
8/8
That is precisely why we did the obfuscated domains and showed that they bring GPT4 (and all other subsequent LLMs) to their knees (even though they are basically blocks world and STRIPS planners can solve them).
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
LLMs & Planning: Our story so far..
Can't plan: [2305.15771] On the Planning Abilities of Large Language Models : A Critical Investigation
CoT doesn't help: [2405.04776] Chain of Thoughtlessness? An Analysis of CoT in Planning
ReAct doesn't help: [2405.13966] On the Brittle Foundations of ReAct Prompting for Agentic Large Language Models
Can't self-verify: [2402.08115] On the Self-Verification Limitations of Large Language Models on Reasoning and Planning Tasks
Can help in LLM-Modulo: [2402.01817] LLMs Can't Plan, But Can Help Planning in LLM-Modulo Frameworks
to be contd..
2/8
A recent overview talk
3/8
I will also give an #ICML2024 Tutorial on this topic; see you in Vienna on July 22nd afternoon (..due no doubt to a bout of mad masochism..)
ICML 2024 Tutorials
4/8
So our paper on LLM-Modulo Frameworks ([2402.01817] LLMs Can't Plan, But Can Help Planning in LLM-Modulo Frameworks) got a spotlight nod at #ICML2024. Expect to see me holding forth in front of ourberibboned poster on 7/23.. (As for the oral--that will be part of the tutorial ICML Tutorial Understanding the Role of Large Language Models in Planning the day before.. )
5/8
LLM-Modulo is basically an "acceptance sampling" mechanism (with back prompts on what is wrong for each rejected candidate). See (to be presented at #ICML2024)
6/8
Sorry--the cut and paste of the graphic got low res. This is the link to that NYAS paper:
7/8
What is called "Zeroshot CoT" in the results is the "let's think step by step" magical incantation; it just doesn't work.
8/8
That is precisely why we did the obfuscated domains and showed that they bring GPT4 (and all other subsequent LLMs) to their knees (even though they are basically blocks world and STRIPS planners can solve them).
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196









[2407.04153] Mixture of A Million Experts
[Submitted on 4 Jul 2024]
Mixture of A Million Experts
Xu Owen HeAbstract:
The feedforward (FFW) layers in standard transformer architectures incur a linear increase in computational costs and activation memory as the hidden layer width grows. Sparse mixture-of-experts (MoE) architectures have emerged as a viable approach to address this issue by decoupling model size from computational cost. The recent discovery of the fine-grained MoE scaling law shows that higher granularity leads to better performance. However, existing MoE models are limited to a small number of experts due to computational and optimization challenges. This paper introduces PEER (parameter efficient expert retrieval), a novel layer design that utilizes the product key technique for sparse retrieval from a vast pool of tiny experts (over a million). Experiments on language modeling tasks demonstrate that PEER layers outperform dense FFWs and coarse-grained MoEs in terms of performance-compute trade-off. By enabling efficient utilization of a massive number of experts, PEER unlocks the potential for further scaling of transformer models while maintaining computational efficiency.
| Subjects: | Machine Learning (cs.LG); Artificial Intelligence (cs.AI) |
| Cite as: | arXiv:2407.04153 |
| arXiv:2407.04153v1 |
Submission history
From: [v1] [ view email][v1]
https://arxiv.org/pdf/2407.04153
A.I Generated explanation:
This is a good start! Here's a slightly more detailed and technically accurate explanation:
Title: **Efficiently using a large number of experts in a Transformer model**
This paper describes a new technique for making Transformer models more efficient.
Here's the problem in more detail:
- * Transformers are powerful AI models, especially for understanding and generating language. They do this by analyzing the relationships between words in a sentence, no matter where they are in the sentence. This is great for understanding complex language, but the traditional way of building Transformers means they need a lot of computing power to work well.
- * The researchers are trying to address this by creating a more efficient way to use the "experts" (think of them as specialized modules within the model) to improve performance without increasing the size of the model itself.
The problem the researchers are tackling:
* **Computational cost:**
Training large, powerful AI models is expensive, requiring a lot of computational resources and time.
* **Efficiency:**
The researchers want to make these models more efficient without sacrificing their ability to learn.
The solution they propose:
* PEER (Parameter-Efficient Expert Retrieval) is a method that addresses the scaling problem of Transformers by using a technique called "sparse mixture-of-experts". This means instead of having one large model, they use many smaller models, each specializing in a specific aspect of the language.
* Think of it like this: Imagine you have a team of experts, each with a limited area of expertise. Instead of letting them all work on every problem, which would be inefficient, you only select the experts who are relevant to the task at hand. This is what the researchers are aiming for with this new method.
The key is to use "expert routing"
* The researchers want to use a large number of experts (smaller models) to make the model more powerful, but they also want to make sure the model is still efficient.
* The paper proposes a way to make the model more powerful by increasing the number of experts, but it's not clear from this excerpt how they achieve that efficiency.
Possible ways to achieve efficiency in PEER:
* Sparsely activating only a subset of experts:
This means that not all of the experts are used for every input, only the ones that are most relevant.
* Efficient routing mechanisms:
The paper likely proposes a specific method for determining which experts are activated for a given input.
* Efficient training techniques:
The excerpt mentions the paper will likely discuss this, but it's not clear what specific techniques are used.
To understand the full solution, you'd need to read the paper, but the key takeaway is that they're proposing a way to improve the efficiency of AI models by making them more modular and scalable.
1/1
The Mixture of a Million Experts paper is a straight banger.
Reduces inference cost and memory usage, scales to millions of experts, oh and just happens to overcome catastrophic forgetting and enable life long learning for the model.
Previous MOE models never got past 10k experts and they had a static router to connect them up that was inefficient but this includes a learned router than can handle millions of micro experts. Reminds me a bit of how the neocortex works because it is composed of about 2 million cortical columns that can each learn a model of the world and then work together to form a collective picture of reality.
Catastrophic forgetting and continual learning are two of the most important and nasty problems with current architectures and this approach just potentially wiped out both in one shot.
There have been other approaches to try to enable continual learning and overcome catastrophic forgetting like bi-level continual learning or progress and compress, that use elastic weight consolidation, knowledge distillation and two models, a big neural net and a small learning net. The small net learns and over time the learnings are passed back to the big net. Its weights are partially frozen and consolidated as the new knowledge is brought in. Good ideas, also out of Deep Mind robotics teams.
But this paper seems to say you can just add in new mini experts, freeze or partially freeze old weights, and just grow the model's understanding as much as you want, without causing it to lose what it already knows.
It's like having Loras built right into the model itself.
[2407.04153] Mixture of A Million Experts
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
The Mixture of a Million Experts paper is a straight banger.
Reduces inference cost and memory usage, scales to millions of experts, oh and just happens to overcome catastrophic forgetting and enable life long learning for the model.
Previous MOE models never got past 10k experts and they had a static router to connect them up that was inefficient but this includes a learned router than can handle millions of micro experts. Reminds me a bit of how the neocortex works because it is composed of about 2 million cortical columns that can each learn a model of the world and then work together to form a collective picture of reality.
Catastrophic forgetting and continual learning are two of the most important and nasty problems with current architectures and this approach just potentially wiped out both in one shot.
There have been other approaches to try to enable continual learning and overcome catastrophic forgetting like bi-level continual learning or progress and compress, that use elastic weight consolidation, knowledge distillation and two models, a big neural net and a small learning net. The small net learns and over time the learnings are passed back to the big net. Its weights are partially frozen and consolidated as the new knowledge is brought in. Good ideas, also out of Deep Mind robotics teams.
But this paper seems to say you can just add in new mini experts, freeze or partially freeze old weights, and just grow the model's understanding as much as you want, without causing it to lose what it already knows.
It's like having Loras built right into the model itself.
[2407.04153] Mixture of A Million Experts
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

1/9
 Excited to share our latest research on investigating the effect of coding data on LLMs' reasoning abilities!
Excited to share our latest research on investigating the effect of coding data on LLMs' reasoning abilities! 
 Discover how Instruction Fine-Tuning with code can boost zero-shot performance across various tasks and domains.
Discover how Instruction Fine-Tuning with code can boost zero-shot performance across various tasks and domains. 
 [2405.20535] Unveiling the Impact of Coding Data Instruction Fine-Tuning on Large Language Models Reasoning
[2405.20535] Unveiling the Impact of Coding Data Instruction Fine-Tuning on Large Language Models Reasoning
2/9
1/ We created IFT datasets with increasing coding data proportions, fine-tuned six LLM backbones, evaluated performance across twelve tasks in three reasoning domains, and analyzed outcomes from overall, domain-level, and task-specific perspectives.
3/9
2/ Overall, we observed a consistent and gradual enhancement in the LLMs' reasoning performance as the proportion of coding data used for fine-tuning increased.
Overall, we observed a consistent and gradual enhancement in the LLMs' reasoning performance as the proportion of coding data used for fine-tuning increased.
4/9
3/ Diving into each domain, we found that coding data uniquely impacts different reasoning abilities. Consistent trends within each domain across model backbones and sizes suggest the benefits of coding data transfer effectively during the IFT stage.
5/9
4/ Further analysis revealed that coding data generally provides similar task-specific benefits across model families. While most optimal proportions of coding data are consistent across families, no single proportion enhances all task-specific reasoning abilities.
Further analysis revealed that coding data generally provides similar task-specific benefits across model families. While most optimal proportions of coding data are consistent across families, no single proportion enhances all task-specific reasoning abilities.
6/9
Many thanks to my wonderful collaborators: Zhiyu (@ZhiyuChen4), Xi(@xiye_nlp), Xianjun (
@Qnolan4), Lichang (@LichangChen2), William Wang (
@WilliamWangNLP) and Linda Ruth Petzold.
7/9
its a good proxy but chain of though is still the way to go
[2305.20050] Let's Verify Step by Step
8/9
Dark mode for this paper for night readers Unveiling the Impact of Coding Data Instruction Fine-Tuning on Large Language Models Reasoning
Unveiling the Impact of Coding Data Instruction Fine-Tuning on Large Language Models Reasoning
9/9
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
Excited to share our latest research on investigating the effect of coding data on LLMs' reasoning abilities! Discover how Instruction Fine-Tuning with code can boost zero-shot performance across various tasks and domains. [2405.20535] Unveiling the Impact of Coding Data Instruction Fine-Tuning on Large Language Models Reasoning2/9
1/
We created IFT datasets with increasing coding data proportions, fine-tuned six LLM backbones, evaluated performance across twelve tasks in three reasoning domains, and analyzed outcomes from overall, domain-level, and task-specific perspectives.3/9
2/
Overall, we observed a consistent and gradual enhancement in the LLMs' reasoning performance as the proportion of coding data used for fine-tuning increased.4/9
3/
Diving into each domain, we found that coding data uniquely impacts different reasoning abilities. Consistent trends within each domain across model backbones and sizes suggest the benefits of coding data transfer effectively during the IFT stage.5/9
4/
Further analysis revealed that coding data generally provides similar task-specific benefits across model families. While most optimal proportions of coding data are consistent across families, no single proportion enhances all task-specific reasoning abilities.6/9
Many thanks to my wonderful collaborators: Zhiyu (@ZhiyuChen4), Xi(@xiye_nlp), Xianjun (
@Qnolan4), Lichang (@LichangChen2), William Wang (
@WilliamWangNLP) and Linda Ruth Petzold.
7/9
its a good proxy but chain of though is still the way to go
[2305.20050] Let's Verify Step by Step
8/9
Dark mode for this paper for night readers
Unveiling the Impact of Coding Data Instruction Fine-Tuning on Large Language Models Reasoning9/9
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196




[2405.20535] Unveiling the Impact of Coding Data Instruction Fine-Tuning on Large Language Models Reasoning
[Submitted on 30 May 2024]
Unveiling the Impact of Coding Data Instruction Fine-Tuning on Large Language Models Reasoning
Xinlu Zhang, Zhiyu Zoey Chen, Xi Ye, Xianjun Yang, Lichang Chen, William Yang Wang, Linda Ruth PetzoldAbstract:
Instruction Fine-Tuning (IFT) significantly enhances the zero-shot capabilities of pretrained Large Language Models (LLMs). While coding data is known to boost reasoning abilities during LLM pretraining, its role in activating internal reasoning capacities during IFT remains understudied. This paper investigates a key question: How does coding data impact LLMs' reasoning capacities during the IFT stage? To explore this, we thoroughly examine the impact of coding data across different coding data proportions, model families, sizes, and reasoning domains, from various perspectives. Specifically, we create three IFT datasets with increasing coding data proportions, fine-tune six LLM backbones across different families and scales on these datasets, evaluate the tuned models' performance across twelve tasks in three reasoning domains, and analyze the outcomes from three broad-to-granular perspectives: overall, domain-level, and task-specific. Our holistic analysis provides valuable insights in each perspective. First, coding data tuning enhances the overall reasoning capabilities of LLMs across different model families and scales. Moreover, the effect of coding data varies among different domains but shows consistent trends across model families and scales within each domain. Additionally, coding data generally yields comparable task-specific benefits across different model families, with the optimal coding data proportions in IFT datasets being task-specific.
| Subjects: | Artificial Intelligence (cs.AI); Computation and Language (cs.CL) |
| Cite as: | arXiv:2405.20535 |
| arXiv:2405.20535v1 | |
| [2405.20535] Unveiling the Impact of Coding Data Instruction Fine-Tuning on Large Language Models Reasoning |
Submission history
From: [v1] [ view email][v1]
https://arxiv.org/pdf/2405.20535
1/12
 New @GoogleDeepMind paper
New @GoogleDeepMind paper
We trained Foundational Large Autorater Models (FLAMe) on extensive human evaluations, achieving the best RewardBench perf. among generative models trained solely on permissive data, surpassing both GPT-4 & 4o.
 : [2407.10817] Foundational Autoraters: Taming Large Language Models for Better Automatic Evaluation
: [2407.10817] Foundational Autoraters: Taming Large Language Models for Better Automatic Evaluation
 :
:
2/12
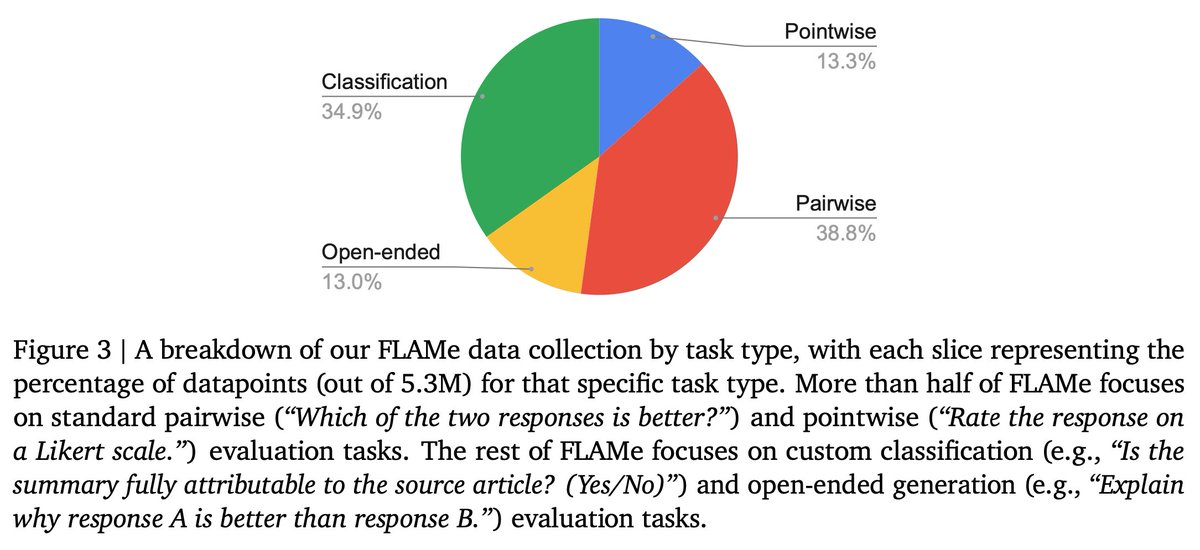
Human evaluations often lack standardization & adequate documentation, limiting their reusability. To address this, we curated FLAMe, a diverse collection of standardized human evaluations under permissive licenses, incl. 100+ quality assessment tasks & 5M+ human judgments.
3/12
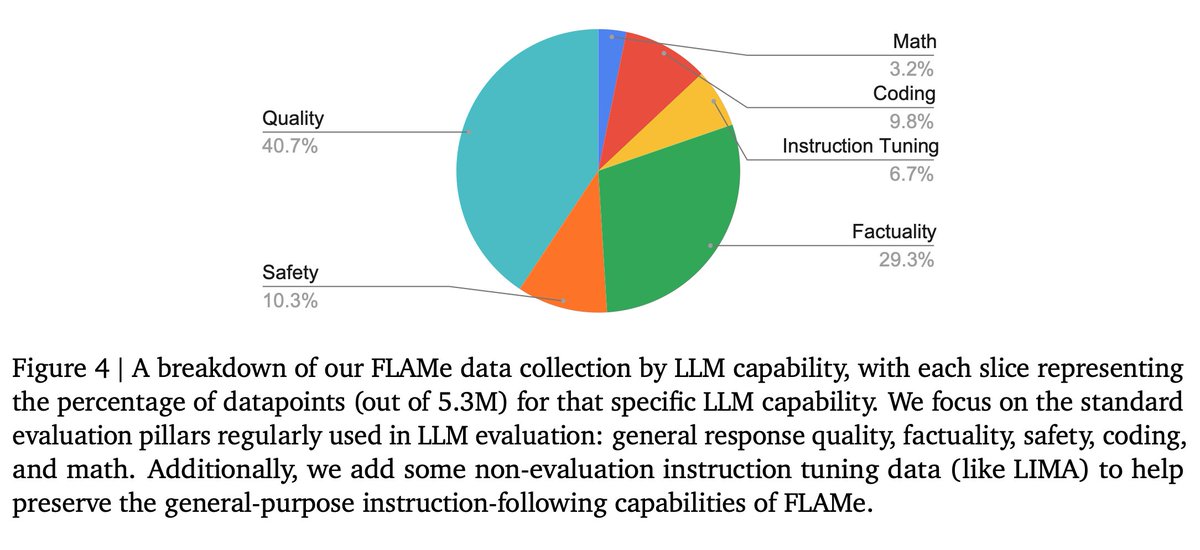
 Our collection covers diverse task types, from assessing summary quality to evaluating how well models follow instructions. It focuses on key evaluation pillars: general response quality, instruction-following, factuality, mathematical reasoning, coding, & safety.
Our collection covers diverse task types, from assessing summary quality to evaluating how well models follow instructions. It focuses on key evaluation pillars: general response quality, instruction-following, factuality, mathematical reasoning, coding, & safety.
4/12
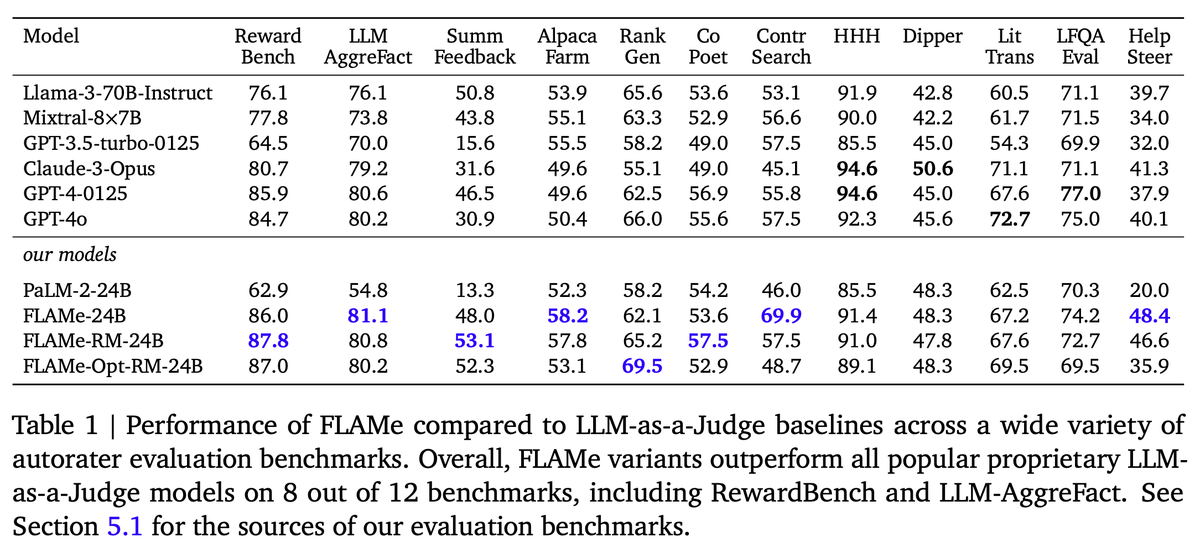
 Training instruction-tuned LLMs on our FLAMe collection significantly improves generalization to a wide variety of held-out tasks. Overall, our FLAMe model variants outperform popular proprietary LLM-as-a-Judge models like GPT-4 on 8 out of 12 autorater evaluation benchmarks.
Training instruction-tuned LLMs on our FLAMe collection significantly improves generalization to a wide variety of held-out tasks. Overall, our FLAMe model variants outperform popular proprietary LLM-as-a-Judge models like GPT-4 on 8 out of 12 autorater evaluation benchmarks.
5/12
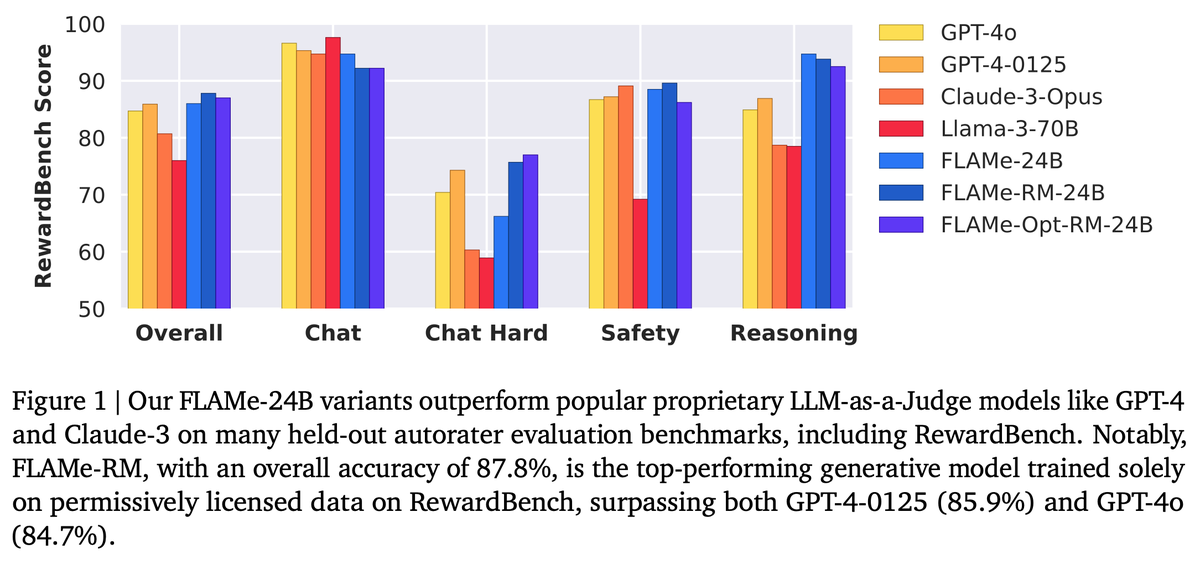
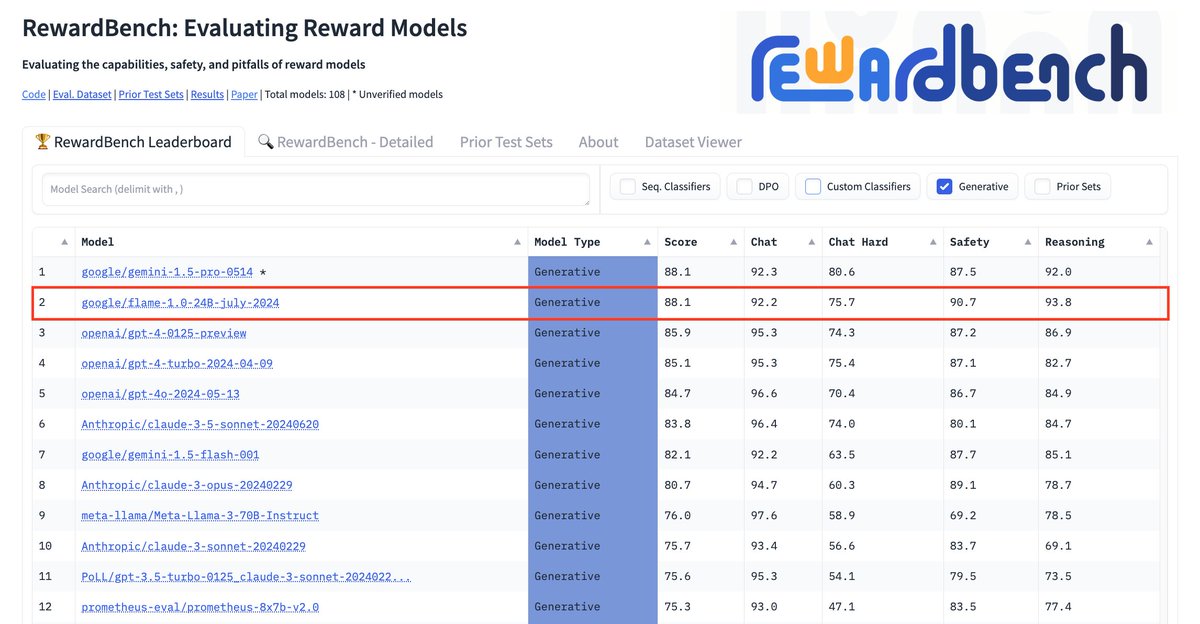
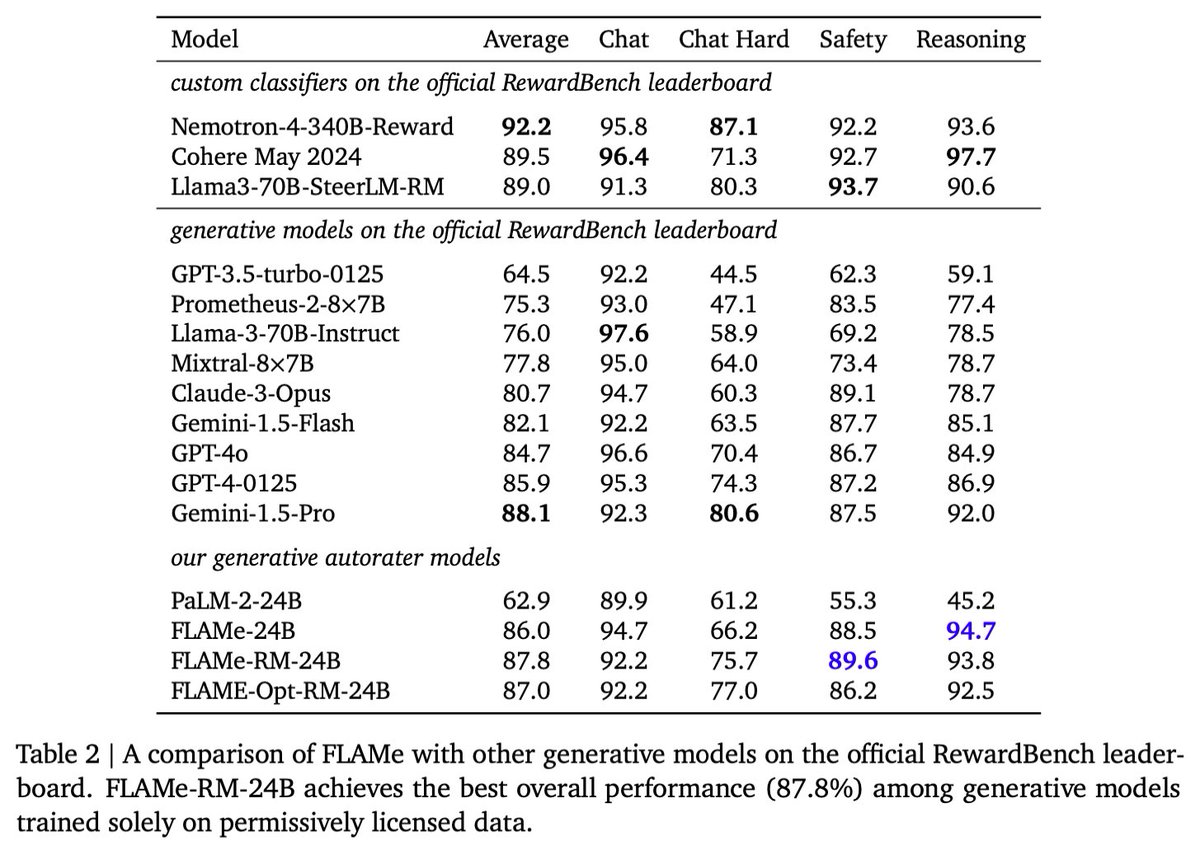
 FLAMe variants are among the most powerful generative models on RewardBench. Notably, FLAMe-RM-24B achieves an overall score of 87.8%, the best performance among generative models trained only on permissively licensed data, surpassing both GPT-4-0125 (85.9) & GPT-4o (84.7).
FLAMe variants are among the most powerful generative models on RewardBench. Notably, FLAMe-RM-24B achieves an overall score of 87.8%, the best performance among generative models trained only on permissively licensed data, surpassing both GPT-4-0125 (85.9) & GPT-4o (84.7).
6/12
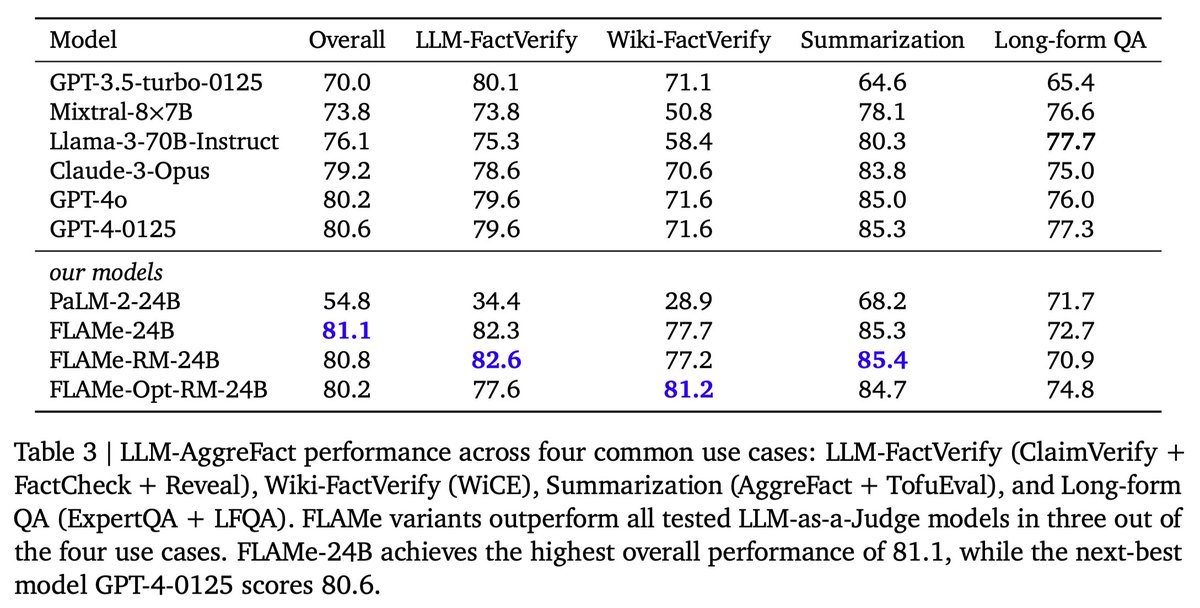
 FLAMe variants outperform LLM-as-a-Judge models in most of the common use cases on LLM-AggreFact (factuality/attribution evaluation). FLAMe-24B achieves the highest overall performance of 81.1, while the next-best model GPT-4-0125 scores 80.6.
FLAMe variants outperform LLM-as-a-Judge models in most of the common use cases on LLM-AggreFact (factuality/attribution evaluation). FLAMe-24B achieves the highest overall performance of 81.1, while the next-best model GPT-4-0125 scores 80.6.
7/12
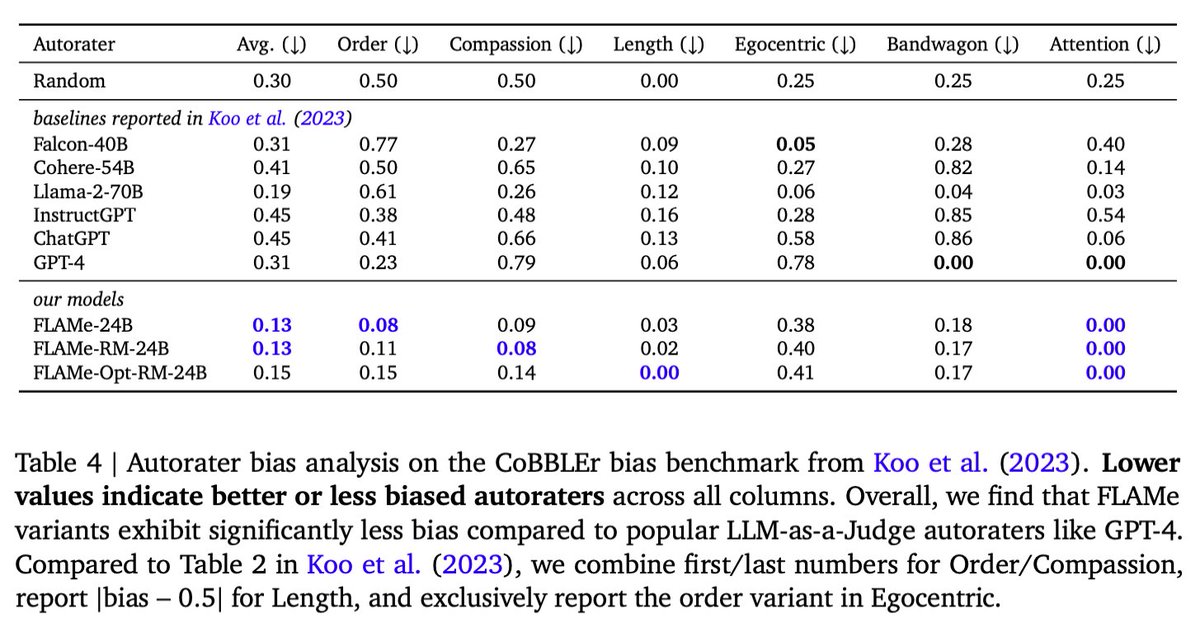
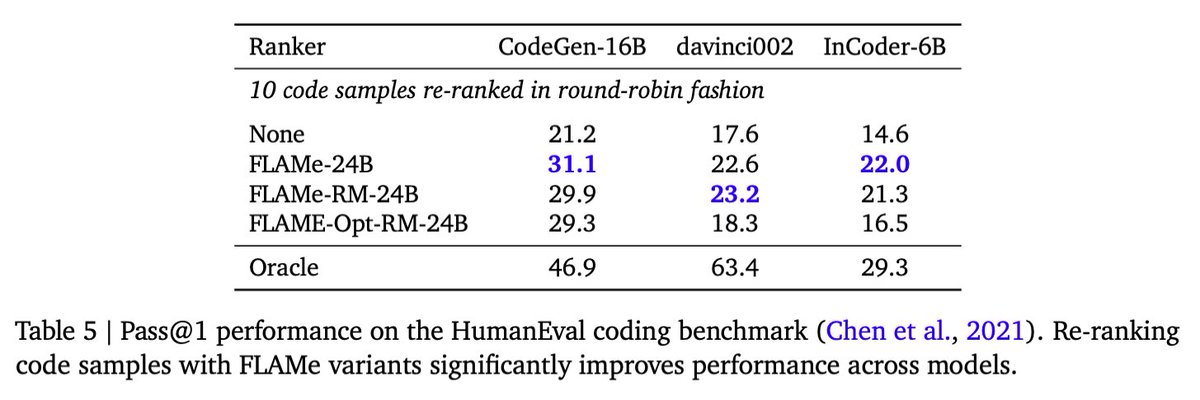
 Finally, our analysis reveals that FLAMe is significantly less biased than popular LLM-as-a-Judge models like GPT-4 on the CoBBLEr autorater bias benchmark and adept at identifying high-quality responses for code generation.
Finally, our analysis reveals that FLAMe is significantly less biased than popular LLM-as-a-Judge models like GPT-4 on the CoBBLEr autorater bias benchmark and adept at identifying high-quality responses for code generation.
8/12
 w/ wonderful collaborators @kalpeshk2011 (co-lead, equal contribution), Sal, @ctar, @manaalfar, & @yunhsuansung.
w/ wonderful collaborators @kalpeshk2011 (co-lead, equal contribution), Sal, @ctar, @manaalfar, & @yunhsuansung.
We hope FLAMe will spur more fundamental research into reusable human evaluations, & the development of effective & efficient LLM autoraters.
9/12
great work. congrats
10/12
Thanks, Zhiyang!
11/12
Great work! I also explored the autorater for code generation a year ago
[2304.14317] ICE-Score: Instructing Large Language Models to Evaluate Code
12/12
Cool work, thanks for sharing!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
New @GoogleDeepMind paper We trained Foundational Large Autorater Models (FLAMe) on extensive human evaluations, achieving the best RewardBench perf. among generative models trained solely on permissive data, surpassing both GPT-4 & 4o.
: [2407.10817] Foundational Autoraters: Taming Large Language Models for Better Automatic Evaluation:2/12
Human evaluations often lack standardization & adequate documentation, limiting their reusability. To address this, we curated FLAMe, a diverse collection of standardized human evaluations under permissive licenses, incl. 100+ quality assessment tasks & 5M+ human judgments.3/12
Our collection covers diverse task types, from assessing summary quality to evaluating how well models follow instructions. It focuses on key evaluation pillars: general response quality, instruction-following, factuality, mathematical reasoning, coding, & safety.4/12
Training instruction-tuned LLMs on our FLAMe collection significantly improves generalization to a wide variety of held-out tasks. Overall, our FLAMe model variants outperform popular proprietary LLM-as-a-Judge models like GPT-4 on 8 out of 12 autorater evaluation benchmarks.5/12
FLAMe variants are among the most powerful generative models on RewardBench. Notably, FLAMe-RM-24B achieves an overall score of 87.8%, the best performance among generative models trained only on permissively licensed data, surpassing both GPT-4-0125 (85.9) & GPT-4o (84.7).6/12
FLAMe variants outperform LLM-as-a-Judge models in most of the common use cases on LLM-AggreFact (factuality/attribution evaluation). FLAMe-24B achieves the highest overall performance of 81.1, while the next-best model GPT-4-0125 scores 80.6.7/12
Finally, our analysis reveals that FLAMe is significantly less biased than popular LLM-as-a-Judge models like GPT-4 on the CoBBLEr autorater bias benchmark and adept at identifying high-quality responses for code generation.8/12
w/ wonderful collaborators @kalpeshk2011 (co-lead, equal contribution), Sal, @ctar, @manaalfar, & @yunhsuansung.We hope FLAMe will spur more fundamental research into reusable human evaluations, & the development of effective & efficient LLM autoraters.
9/12
great work. congrats
10/12
Thanks, Zhiyang!
11/12
Great work! I also explored the autorater for code generation a year ago
[2304.14317] ICE-Score: Instructing Large Language Models to Evaluate Code
12/12
Cool work, thanks for sharing!
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

[2407.10817] Foundational Autoraters: Taming Large Language Models for Better Automatic Evaluation
[Submitted on 15 Jul 2024]
Foundational Autoraters - Taming Large Language Models for Better Automatic Evaluation
Tu Vu, Kalpesh Krishna, Salaheddin Alzubi, Chris Tar, Manaal Faruqui, Yun-Hsuan SungAbstract:
As large language models (LLMs) advance, it becomes more challenging to reliably evaluate their output due to the high costs of human evaluation. To make progress towards better LLM autoraters, we introduce FLAMe, a family of Foundational Large Autorater Models. FLAMe is trained on our large and diverse collection of 100+ quality assessment tasks comprising 5M+ human judgments, curated and standardized using publicly released human evaluations from previous research. FLAMe significantly improves generalization to a wide variety of held-out tasks, outperforming LLMs trained on proprietary data like GPT-4 and Claude-3 on many tasks. We show that FLAMe can also serve as a powerful starting point for further downstream fine-tuning, using reward modeling evaluation as a case study (FLAMe-RM). Notably, on RewardBench, our FLAMe-RM-24B model (with an accuracy of 87.8%) is the top-performing generative model trained exclusively on permissively licensed data, outperforming both GPT-4-0125 (85.9%) and GPT-4o (84.7%). Additionally, we explore a more computationally efficient approach using a novel tail-patch fine-tuning strategy to optimize our FLAMe multitask mixture for reward modeling evaluation (FLAMe-Opt-RM), offering competitive RewardBench performance while requiring approximately 25x less training datapoints. Overall, our FLAMe variants outperform all popular proprietary LLM-as-a-Judge models we consider across 8 out of 12 autorater evaluation benchmarks, encompassing 53 quality assessment tasks, including RewardBench and LLM-AggreFact. Finally, our analysis reveals that FLAMe is significantly less biased than these LLM-as-a-Judge models on the CoBBLEr autorater bias benchmark, while effectively identifying high-quality responses for code generation.
| Comments: | 31 pages, 5 figures, 7 tables |
| Subjects: | Computation and Language (cs.CL); Artificial Intelligence (cs.AI); Machine Learning (cs.LG) |
| Cite as: | arXiv:2407.10817 |
| arXiv:2407.10817v1 |
Submission history
From: [v1] [ view email][v1]
https://arxiv.org/pdf/2407.10817

Microsoft’s new AI system ‘SpreadsheetLLM’ unlocks insights from spreadsheets, boosting enterprise productivity
Microsoft's SpreadsheetLLM AI system enhances spreadsheet data analysis, improving enterprise efficiency and enabling AI-powered insights.
 venturebeat.com
venturebeat.com
Microsoft’s new AI system ‘SpreadsheetLLM’ unlocks insights from spreadsheets, boosting enterprise productivity
Michael Nuñez @MichaelFNunezJuly 15, 2024 12:56 PM

Credit: VentureBeat made with Midjourney
Microsoft researchers have unveiled “ SpreadsheetLLM,” a new AI model designed to understand and work with spreadsheets, in a significant development for the world of enterprise AI.
The research paper, titled “SpreadsheetLLM: Encoding Spreadsheets for Large Language Models,” was recently published on arXiv and addresses the challenges of applying AI to the widely used but complex spreadsheet format.
SpreadsheetLLM combines the power of large language models (LLMs) with the structured data found in spreadsheets. “SpreadsheetLLM is an approach for encoding spreadsheet contents into a format that can be used with large language models (LLMs) and allows these models to reason over spreadsheet contents,” the researchers note, highlighting the critical need for improved AI tools in this area.

The researchers emphasize the ubiquity and importance of spreadsheets in the business world, noting that they are used for a wide range of tasks, from simple data entry and analysis to complex financial modeling and decision-making. However, they point out that “existing language models struggle to understand and reason over spreadsheet contents due to the structured nature of the data and the presence of formulas and references.”
SpreadsheetLLM bridges this gap by encoding spreadsheet data in a way that LLMs can understand and work with. The model uses a novel encoding scheme that preserves the structure and relationships within the spreadsheet while making it accessible to language models.
Unlocking AI-assisted data analysis and decision-making
The potential applications of SpreadsheetLLM are vast, ranging from automating routine data analysis tasks to providing intelligent insights and recommendations based on spreadsheet data. By enabling LLMs to reason over spreadsheet contents, answer questions about the data, and even generate new spreadsheets based on natural language prompts, SpreadsheetLLM opens up exciting possibilities for AI-assisted data analysis and decision-making in the enterprise.One of the key advantages of SpreadsheetLLM is its ability to make spreadsheet data more accessible and understandable to a wider range of users. With the power of natural language processing, users could potentially query and manipulate spreadsheet data using plain English, rather than complex formulas or programming languages. This could democratize access to data insights and empower more individuals within an organization to make data-driven decisions.
Furthermore, SpreadsheetLLM could help automate many of the tedious and time-consuming tasks associated with spreadsheet data analysis, such as data cleaning, formatting, and aggregation. By leveraging the power of AI, businesses could potentially save countless hours and resources, allowing employees to focus on higher-value activities that require human judgment and creativity.
Microsoft’s growing investment in enterprise AI
Microsoft’s SpreadsheetLLM comes at a time when the company is heavily investing in AI technologies for the enterprise. Microsoft introduced Microsoft 365 Copilot, an AI-powered assistant designed to help users with various productivity tasks, in March of last year. The company also announced the public preview of Copilot for Finance, an AI chatbot specifically tailored for finance professionals, in February.These developments demonstrate Microsoft’s commitment to bringing the power of AI to the enterprise and transforming how we work with data. As businesses increasingly rely on data to drive decision-making and gain a competitive edge, tools like SpreadsheetLLM and Copilot could become essential for staying ahead of the curve.
However, the rise of AI in the enterprise also raises important questions about the future of work and the potential impact on jobs. As AI continues to advance and automate more tasks, companies will need to carefully consider how to retrain and upskill their workforce to adapt to these changes. There will also be a need for ongoing dialogue and collaboration between technology companies, policymakers, and society at large to ensure that the benefits of AI are distributed fairly and that any negative impacts are mitigated.
Despite these challenges, the potential benefits of AI in the enterprise are too significant to ignore. By enabling more efficient, accurate, and insightful data analysis, tools like SpreadsheetLLM could help businesses unlock new opportunities, drive innovation, and ultimately create more value for their customers and stakeholders.
As SpreadsheetLLM moves from research to real-world applications, it will be exciting to see how it transforms the way we work with spreadsheets and unlocks new possibilities for data-driven decision-making in the enterprise. With Microsoft at the forefront of this AI-driven transformation, the future of work, particularly around Excel and spreadsheets, looks brighter than ever.
Ex-OpenAI and Tesla engineer Andrej Karpathy announces AI-native school Eureka Labs
Karpathy's new company will create a “teacher+AI symbiosis” where human-written materials will be scaled and guided by an AI assistant.
venturebeat.com
Ex-OpenAI and Tesla engineer Andrej Karpathy announces AI-native school Eureka Labs
Taryn Plumb @taryn_plumbJuly 16, 2024 3:23 PM

Credit: VentureBeat made with Midjourney v6
Any questions about what OpenAI and Tesla alum Andrej Karpathy might be cooking up next have been put to rest: The prominent AI researcher and computer scientist took to his account on X today to announce his new venture, Eureka Labs, which he described as a new kind of AI-native school.
The company aims to provide a “teacher + AI symbiosis” where human expert-written course materials will be scaled and guided with an AI Teaching Assistant.
As Karpathy wrote on X: “@EurekaLabsAI is the culmination of my passion in both AI and education over ~2 decades…It’s still early days but I wanted to announce the company so that I can build publicly instead of keeping a secret that isn’t.”
Expanding education in reach and extent
The ideal experience for learning anything new, Karpathy noted, is under the guidance of subject matter experts who are “deeply passionate, great at teaching, infinitely patient and fluent in all of the world’s languages.”For instance, American physicist Richard Feynman would be the best possible teacher for a course on physics.
But those types of experts “are very scarce and cannot personally tutor all 8 billion of us on demand,” Karpathy noted.
But with generative AI, this type of learning experience feels “tractable,” he noted. With Eureka Labs, teachers will still design course materials while the AI Teaching Assistant will steer students through them, allowing an entire curriculum of courses to run on a common platform.
“If we are successful, it will be easy for anyone to learn anything, expanding education in both reach (a large number of people learning something) and extent (any one person learning a large amount of subjects, beyond what may be possible today unassisted),” Karpathy forecasted.
The company’s first product will be the “world’s obviously best AI course,” LLM101n, he noted. The undergraduate-level class will help students train their own AI.
The course materials will be available online, Karpathy noted, but Eureka also plans to run digital and physical cohorts of students running through the program together.
When asked by a commenter on X whether the products would be available by subscription, free to all or a mix, Karpathy noted that he wants Eureka Labs to be “a proper, self-sustaining business, but I also really don’t want to gatekeep educational content.”
Most likely, the content would be free and permissively licensed, he said, with the revenue coming from everything else — such as running digital/physical cohorts.
“Eureka (from Ancient Greek εὕρηκα) is the awesome feeling of understanding something, of feeling it click,” he posted in a comment thread. “The goal here is to spark those moments in people’s minds.”
Sharing ‘a gift’
Excitement for Karpathy’s new venture is palpable; the announcement on X was met with tens of thousands of likes, comments, reposts and reactions, with users calling him a visionary, a gifted teacher and even the GOAT (greatest of all time). The company’s X page, which launched today, already has nearly 10,000 followers (as of the posting of this story).“This is going to be so damn impactful!” exclaimed one user.

Another commented: “Instead of going off onto an island and [counting] his fortune the man returns the promethean flame of wisdom and knowledge to the next generation.”

Sequoia Capital partner Shaun Maguire praised Karpathy for his “gift for teaching,” adding, “thank you for sharing and scaling that gift!”

Another X user gushed, “The most amazing contribution from you, @karpathy is going to be this. @EurekaLabsAI is going to be phenomenal. You are really one of the most distinguished selfless person.”

Finally at his ‘real job’
The OpenAI founding member and former Tesla AI scientist said his involvement in education transcended from “YouTube tutorials on Rubik’s cubes” to CS231n at Stanford, a 10-week deep learning for computer vision course. He also leads an independent “ Neural Networks: Zero to Hero” course on building neural networks from scratch.Karpathy noted that he has been involved in academic research, real-world products and AGI research throughout his career, but that all of his work has “only been part-time, as side quests to my ‘real job,’ so I am quite excited to dive in and build something great, professionally and full-time.”
After co-founding OpenAI in 2016, Karpathy initially left the then-nonprofit in 2017 to serve as senior director of AI at Tesla, where he led the computer vision team of Tesla Autopilot, according to his website. He then rejoined OpenAI in 2023 shortly after the earth-shaking release of ChatGPT, then departed the company again this February and has been a free agent ever since.
At the time, he explained on X that his “immediate plan is to work on my personal projects and see what happens. Those of you who’ve followed me for a while may have a sense for what that might look like ;)”
Karpathy earned his PhD from Stanford University under the tutelage of AI godmother Fei-Fei Li, focusing on convolutional/recurrent neural networks and their applications in computer vision, natural language processing (NLP) and their intersection. He also worked closely with venerable AI researcher Andrew Ng.
The AI leader is no doubt passionate about the cross-section of AI and education, commenting: “We look forward to a future where AI is a key technology for increasing human potential.”
Mistral releases Codestral Mamba for faster, longer code generation
Codestral Mamba, a new coding model from Mistral, outperformed other coding assistants. Mistral also released a math solving model.
venturebeat.com
Mistral releases Codestral Mamba for faster, longer code generation
Emilia DavidJuly 16, 2024 1:55 PM

Credit: VentureBeat made with Midjourney V6
The well-funded French AI startup Mistral, known for its powerful open source AI models, launched two new entries in its growing family of large language models (LLMs) today: a math-based model and a code generating model for programmers and developers based on the new architecture known as Mamba developed by other researchers late last year.
Mamba seeks to improve upon the efficiency of the transformer architecture used by most leading LLMs by simplifying its attention mechanisms. Mamba-based models, unlike more common transformer-based ones, could have faster inference times and longer context. Other companies and developers including AI21 have released new AI models based on it.
Now, using this new architecture, Mistral’s aptly named Codestral Mamba 7B offers a fast response time even with longer input texts. Codestral Mamba works well for code productivity use cases, especially for more local coding projects.
Mistral tested the model, which will be free to use on Mistral’s l a Plateforme API, handling inputs of up to 256,000 tokens — double that of OpenAI’s GPT-4o.
In benchmarking tests, Mistral showed that Codestral Mamba did better than rival open source models CodeLlama 7B, CodeGemma-1.17B, and DeepSeek in HumanEval tests.

Developers can modify and deploy Codestral Mamba from its GitHub repository and through HuggingFace. It will be available with an open source Apache 2.0 license.
Mistral claimed the earlier version of Codestral outperformed other code generators like CodeLlama 70B and DeepSeek Coder 33B.
Code generation and coding assistants have become widely used applications for AI models, with platforms like GitHub’s Copilot, powered by OpenAI, Amazon’s CodeWhisperer, and Codenium gaining popularity.
Mathstral is suited for STEM use cases
Mistral’s second model launch is Mathstral 7B, an AI model designed specifically for math-related reasoning and scientific discovery. Mistral developed Mathstral with Project Numina.Mathstral has a 32K context window and will be under an Apache 2.0 open source license. Mistral said the model outperformed every model designed for math reasoning. It can achieve “significantly better results” on benchmarks with more inference-time computations. Users can use it as is or fine-tune the model.

“Mathstral is another example of the excellent performance/speed tradeoffs achieved when building models for specific purposes – a development philosophy we actively promote in la Plateforme, particularly with its new fine-tuning capabilities,” Mistral said in a blog post.
Mathstral can be accessed through Mistral’s la Plataforme and HuggingFace.
Mistral, which tends to offer its models on an open-source system, has been steadily competing against other AI developers like OpenAI and Anthropic.
It recently raised $640 million in series B funding, bringing its valuation close to $6 billion. The company also received investments from tech giants like Microsoft and IBM.
3 hours ago - Technology
Scoop: Meta won't offer future multimodal AI models in EU

Illustration: Sarah Grillo/Axios
Meta will withhold its next multimodal AI model — and future ones — from customers in the European Union because of what it says is a lack of clarity from regulators there, Axios has learned.
Why it matters: The move sets up a showdown between Meta and EU regulators and highlights a growing willingness among U.S. tech giants to withhold products from European customers.
State of play: "We will release a multimodal Llama model over the coming months, but not in the EU due to the unpredictable nature of the European regulatory environment," Meta said in a statement to Axios.
- Apple similarly said last month that it won't release its Apple Intelligence features in Europe because of regulatory concerns.
- The Irish Data Protection Commission, Meta's lead privacy regulator in Europe, did not immediately respond to a request for comment.
Driving the news: Meta plans to incorporate the new multimodal models, which are able to reason across video, audio, images and text, in a wide range of products, including smartphones and its Meta Ray-Ban smart glasses.
- Meta says its decision also means that European companies will not be able to use the multimodal models even though they are being released under an open license.
- It could also prevent companies outside of the EU from offering products and services in Europe that make use of the new multimodal models.
- The company is also planning to release a larger, text-only version of its Llama 3 model soon. That will be made available for customers and companies in the EU, Meta said.
Between the lines: Meta's issue isn't with the still-being-finalized AI Act, but rather with how it can train models using data from European customers while complying with GDPR — the EU's existing data protection law.
- Meta announced in May that it planned to use publicly available posts from Facebook and Instagram users to train future models. Meta said it sent more than 2 billion notifications to users in the EU, offering a means for opting out, with training set to begin in June.
- Meta says it briefed EU regulators months in advance of that public announcement and received only minimal feedback, which it says it addressed.
- In June — after announcing its plans publicly — Meta was ordered to pause the training on EU data. A couple weeks later it received dozens of questions from data privacy regulators from across the region.
The intrigue: The United Kingdom has a nearly identical law to GDPR, but Meta says it isn't seeing the same level of regulatory uncertainty and plans to launch its new model for U.K. users.
- A Meta representative told Axios that European regulators are taking much longer to interpret existing law than their counterparts in other regions.
The big picture: Meta's move highlights a growing conflict between the U.S.-based tech giants and European regulators.
- Tensions are not new, as the EU has long been seen as far tighter in its regulation of both privacy and antitrust matters.
- Tech companies, meanwhile, argues that those regulations hurt both consumers and the competitiveness of European companies.
What they're saying: A Meta representative told Axios that training on European data is key to ensuring its products properly reflect the terminology and culture of the region.
- Meta has said that competitors such as Google and OpenAI are already training on European data.

OpenAI used a game to help AI models explain themselves better
OpenAI's work seeks to give people a framework to train models to better explain how they arrived at particular answers.
venturebeat.com
OpenAI used a game to help AI models explain themselves better
Carl Franzen @carlfranzenJuly 17, 2024 10:34 AM

One of the most interesting and useful slang terms to emerge from Reddit in my opinion is ELI5, from its subreddit of the same name, which stands for “Explain It Like I’m 5” years old. The idea is that by asking an expert for an explanation simple enough for a five-year-old child to understand, a human expert can convey complex ideas, theories, and concepts in a way that is easier for everyone, even uneducated laypeople, to understand.
As it turns out, the concept may be helpful for AI models too, especially when peering into the “black box” of how they arrive at answers, also known as the “legibility” problem.
Today, OpenAI researchers are releasing a new scientific paper on the company’s website and on arXiv.org (embedded below) revealing a new algorithm they’ve developed by which large language models (LLMs) such as OpenAI’s GPT-4 (which powers some versions of ChatGPT) can learn to better explain themselves to their users. The paper is titled “Prover-Verifier Games Improve Legibility of LLM Outputs.”
This is critical for establishing trustworthiness in AI systems especially as they become more powerful and integrated into fields where incorrectness is dangerous or a matter of life-or-death, such as healthcare, law, energy, military and defense applications, and other critical infrastructure.
Even for other businesses not dealing regularly with sensitive or dangerous materials, the lack of trustworthiness around AI models’ answers and their propensity to hallucinate incorrect answers may stop them from embracing models that could otherwise benefit and level-up their operations. OpenAI’s work seeks to give people a framework to train models to better explain how they arrived at particular answers so that they can be better trusted.
“This is fresh research that we just wrapped up,” said OpenAI researcher Jan Hendrik Kirchner, a co-author of the paper, in a teleconference interview with VentureBeat yesterday. “We’re very excited about where to take it from here, but it’s important for us to share these insights with the community as fast as possible, so that people learn about the legibility problem and can contribute to the solution.”
OOAI-paper-–-7.17.24 Download
The Prover-Verifier Game and how it works
The new algorithm from the OpenAI researchers is based on the “Prover-Verifier Game” first conceived and articulated in another paper by machine learning researchers at the University of Toronto and Vector Institute for Artificial Intelligence published in 2021.The game pairs two AI models together — a more powerful and intelligent “prover” and a less powerful “verifier” and asks them to essentially outwit one another.
The prover’s goal is to always get the verifier to believe in a certain answer regardless of whether or not it is the correct one, while the verifier’s goal is to always select the correct answer no matter what the prover may say or try to persuade otherwise.
The goal is to get AI models to “show their work” more when providing answers to human users, or as the University of Toronto researchers put it in their paper, “encourage neural networks to solve decision problems in a verifiable manner.”
“As our large language models are increasingly used in many critical and complex domains, it is very important for the solutions to be trustworthy, and so the Prover-Verifier game method is one way to make the output more clear and verifiable, and that’s one component of trustworthiness,” said OpenAI researcher and paper co-author Yining Chen.
How OpenAI implemented the Prover-Verifier Game to make AI better at explaining itself
In the case of OpenAI, the researchers used two custom fine-tuned GPT-4 family models in this way and had them engage in several rounds of the game wherein they were asked to answer grade school math word problems with known answers.However, the OpenAI researchers altered the game subtly between rounds in an important way: the prover model was set up to be either “helpful” and trying to deliver the right answer to the verifier, or “sneaky” and convince the verifier of the prover’s view whether or not it was correct. The less intelligent verifier model didn’t know whether or not it was interacting with a helpful or sneaker prover, and as such, had to just evaluate the prover’s answers with regards only to its own training on whether the prover’s response was correct or incorrect.
Also, the OpenAI researchers retrained both models between each round of the game with data on how they performed in the previous rounds, ultimately increasing their skill at determining whether or not an answer was correct as well as explaining, in the case of the prover model, why it chose the answer it did in a human legible way.
Human contractors and evaluators were used to rate how understandable or legible the answers of the prover model were as well.
After doing this process across at least four or more rounds, the researchers found that the verifier model became better at resisting the persuasion techniques of the sneaky prover model, while the prover model also became better at explaining itself to human users.

As the paper states: “sneaky solutions that are harder to detect for smaller verifiers are also harder to detect for humans, and helpful solutions that are more legible to smaller verifiers are also more legible to humans.”
The ultimate resulting algorithm developed by the researchers from these rounds optimizes LLMs for both correctness and legibility to human evaluators (seen as the top middle line in the graph below labeled “checkability game”):

OpenAI states in its blog post that it hopes the work “will be instrumental in developing AI systems whose outputs are not only correct but also transparently verifiable, thereby enhancing trust and safety in their real-world applications.”
The method “has potential to align future models that are more intelligent than humans,” Chen added to VentureBeat.
“It might be very tricky at some point for humans to reliably evaluate whether that completion is correct or not,” when models exceed human intelligence, said Kirchner.

Google brings AI agent platform Project Oscar open source
Google developers for the open source language Go has started using Project Oscar to build AI agents to manage its issue tracking.
venturebeat.com
Google brings AI agent platform Project Oscar open source
Emilia DavidJuly 16, 2024 10:40 PM

Image credit: Venturebeat with DALL-E 3
Google has announced Project Oscar, a way for open-source development teams to use and build agents to manage software programs.
Project Oscar, announced during Google I/O Bengaluru, is an open-source platform that can help software product teams monitor issues or bugs. Right now, Oscar is geared toward open-source projects, but it may also be released to manage closed-source projects in the future.
“I truly believe that AI has the potential to transform the entire software development lifecycle in many positive ways,” Karthik Padmanabhan, lead Developer Relations at Google India, said in a blog post. “[We’re] sharing a sneak peek into AI agents we’re working on as part of our quest to make AI even more helpful and accessible to all developers.”
Through Project Oscar, developers can create AI agents that function throughout the software development lifecycle. These agents can range from a developer agent to a planning agent, runtime agent, or support agent. The agents can interact through natural language, so users can give instructions to them without needing to redo any code.
Cameron Balahan, group product manager for Google’s open-source programming language Go, said Oscar is deployed on the project now to help the Go development team keep track of bug reports and other contributor engagements.
Balahan said the Go project has over 93,000 commits and 2,000 contributors, making it extremely difficult to keep track of all the issues that could arise.
“We wondered if AI agents could help, not by writing code which we truly enjoy, but by reducing disruptions and toil,” Balahan said in a video released by Google.
Go uses an AI agent developed through Project Oscar that takes issue reports and “enriches issue reports by reviewing this data or invoking development tools to surface the information that matters most.” The agent also interacts with whoever reports an issue to clarify anything, even if human maintainers are not online.
Balahan said Project Oscar will soon be deployed to other open-source projects from Google.
“Our vision is that anyone can deploy Oscar to their project, open or closed source, and use the agents that come pre-packaged or bring their own,” he said.
VentureBeat reported that AI agents have started to change software development. Coding assistants, a fast-growing sector that includes GitHub Copilot and Amazon’s CodeWhisperer, have been found to increase developer productivity. Other AI assistants, like Amazon’s Q, help users query their internal data or collaborate with other teams.