You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?A Turing test of whether AI chatbots are behaviorally similar to humans
Qiaozhu Mei qmei@umich.edu, Yutong Xie, Walter Yuan, and Matthew O. Jackson https://orcid.org/0000-0001-9846-4249 jacksonm@stanford.edu Authors Info & AffiliationsContributed by Matthew O. Jackson; received August 12, 2023; accepted January 4, 2024; reviewed by Ming Hsu, Juanjuan Meng, and Arno Riedl
February 22, 2024
121 (9) e2313925121
https://doi.org/10.1073/pnas.2313925121
- Vol. 121 | No. 9
[*]- References
[*] Media
[*] Share
- References
Significance
As AI interacts with humans on an increasing array of tasks, it is important to understand how it behaves. Since much of AI programming is proprietary, developing methods of assessing AI by observing its behaviors is essential. We develop a Turing test to assess the behavioral and personality traits exhibited by AI. Beyond administering a personality test, we have ChatGPT variants play games that are benchmarks for assessing traits: trust, fairness, risk-aversion, altruism, and cooperation. Their behaviors fall within the distribution of behaviors of humans and exhibit patterns consistent with learning. When deviating from mean and modal human behaviors, they are more cooperative and altruistic. This is a step in developing assessments of AI as it increasingly influences human experiences.Abstract
We administer a Turing test to AI chatbots. We examine how chatbots behave in a suite of classic behavioral games that are designed to elicit characteristics such as trust, fairness, risk-aversion, cooperation, etc., as well as how they respond to a traditional Big-5 psychological survey that measures personality traits. ChatGPT-4 exhibits behavioral and personality traits that are statistically indistinguishable from a random human from tens of thousands of human subjects from more than 50 countries. Chatbots also modify their behavior based on previous experience and contexts “as if” they were learning from the interactions and change their behavior in response to different framings of the same strategic situation. Their behaviors are often distinct from average and modal human behaviors, in which case they tend to behave on the more altruistic and cooperative end of the distribution. We estimate that they act as if they are maximizing an average of their own and partner’s payoffs.As Alan Turing foresaw to be inevitable, modern AI has reached the point of emulating humans: holding conversations, providing advice, writing poems, and proving theorems. Turing proposed an intriguing test: whether an interrogator who interacts with an AI and a human can distinguish which one is artificial. Turing called this test the “imitation game” ( 1), and it has become known as a Turing test.
Advancements in large language models have stirred debate. Discussions range from the potential of AI bots to emulate, assist, or even outperform humans, e.g., writing essays, taking the SAT, writing computer programs, giving economic advice, or developing ideas, ( 2– 5), to their potential impact on labor markets ( 6) and broader societal implications ( 7, 8). As some roles for AI involve decision-making and strategic interactions with humans, it is imperative to understand their behavioral tendencies before we entrust them with pilot or co-pilot seats in societal contexts, especially as their development and training are often complex and not transparent ( 9). Do AIs choose similar actions or strategies as humans, and if not how do they differ? Do they exhibit distinctive personalities and behavioral traits that influence their decisions? Are these strategies and traits consistent across varying contexts? A comprehensive understanding of AI’s behavior in generalizable scenarios is vital as we continue to integrate them into our daily lives.
We perform a Turing test of the behavior of a series of AI chatbots. This goes beyond simply asking whether AI can produce an essay that looks like it was written by a human ( 10) or can answer a set of factual questions, and instead involves assessing its behavioral tendencies and “personality.” In particular, we ask variations of ChatGPT to answer psychological survey questions and play a suite of interactive games that have become standards in assessing behavioral tendencies, and for which we have extensive human subject data. Beyond eliciting a “Big Five” personality profile, we have the chatbots play a variety of games that elicit different traits: a dictator game, an ultimatum bargaining game, a trust game, a bomb risk game, a public goods game, and a finitely repeated Prisoner’s Dilemma game. Each game is designed to reveal different behavioral tendencies and traits, such as cooperation, trust, reciprocity, altruism, spite, fairness, strategic thinking, and risk aversion. The personality profile survey and the behavioral games are complementary as one measures personality traits and the other behavioral tendencies, which are distinct concepts; e.g., agreeableness is distinct from a tendency to cooperate. Although personality traits are predictive of various behavioral tendencies ( 11, 12), including both dimensions provides a fuller picture.
In line with Turing’s suggested test, we are the human interrogators who compare the ChatGPTs’ choices to the choices of tens of thousands of humans who faced the same surveys and game instructions. We say an AI passes the Turing test if its responses cannot be statistically distinguished from randomly selected human responses.
We find that the chatbots’ behaviors are generally within the support of those of humans, with only a few exceptions. Their behavior is more concentrated than the full distribution of humans. However, we are comparing two chatbots to tens of thousands of humans, and so a chatbot’s variation is within subject and the variation in the human distribution is across subjects. The chatbot variation may be similar to what a single individual would exhibit if repeatedly queried. We do an explicit Turing test by comparing an AI’s behavior to a randomly selected human behavior, and ask which is the most likely to be human based on a conditional probability calculation from the data. The behaviors are generally indistinguishable, and ChatGPT-4 actually outperforms humans on average, while the reverse is true for ChatGPT-3. There are several games in which the AI behavior is picked more likely to be human most of the time, and others where it is not. When they do differ, the chatbots’ behaviors tend to be more cooperative and altruistic than the median human, including being more trusting, generous, and reciprocating.
In that vein, we do a revealed-preference analysis in which we examine the objective function that best predicts AI behavior. We find that it is an even average of own and partner’s payoffs. That is, they act as if they are maximizing the total payoff of both players rather than simply their own payoff. Human behavior also is optimized with some weight on the other player, but the weight depends on the preference specification and humans are more heterogeneous and less well predicted.
There are two other dimensions on which we compare AI and human behavior. The first is whether context and framing matter, as they do with humans. For example, when we ask them to explain their choices or tell them that their choices will be observed by a third party, they become significantly more generous. Their behavior also changes if we suggest that they act as if they were faced with a partner of a gender, or that they act as if they were a mathematician, legislator, etc. The second dimension is that humans change their behaviors after they have experienced different roles in a game. The chatbots also exhibit significant changes in behaviors as they experience different roles in a game. That is, once they have experienced the role of a “partner” in an asymmetric game, such as a trust game or an ultimatum game, their behavior shifts significantly.
Finally, it is worth noting that we observe behavioral differences between the versions of ChatGPT that we test, so that they exhibit different personalities and behavioral traits.

Paper page - Beyond A*: Better Planning with Transformers via Search Dynamics Bootstrapping
Join the discussion on this paper page
huggingface.co
Beyond A*: Better Planning with Transformers via Search Dynamics Bootstrapping
While Transformers have enabled tremendous progress in various application settings, such architectures still trail behind traditional symbolic planners for solving complex decision making tasks. In this work, we demonstrate how to train Transformers to solve complex planning tasks. This is...
Computer Science > Artificial Intelligence
[Submitted on 21 Feb 2024]Beyond A*: Better Planning with Transformers via Search Dynamics Bootstrapping
Lucas Lehnert, Sainbayar Sukhbaatar, Paul Mcvay, Michael Rabbat, Yuandong TianWhile Transformers have enabled tremendous progress in various application settings, such architectures still lag behind traditional symbolic planners for solving complex decision making tasks. In this work, we demonstrate how to train Transformers to solve complex planning tasks and present Searchformer, a Transformer model that optimally solves previously unseen Sokoban puzzles 93.7% of the time, while using up to 26.8% fewer search steps than standard A∗ search. Searchformer is an encoder-decoder Transformer model trained to predict the search dynamics of A∗. This model is then fine-tuned via expert iterations to perform fewer search steps than A∗ search while still generating an optimal plan. In our training method, A∗'s search dynamics are expressed as a token sequence outlining when task states are added and removed into the search tree during symbolic planning. In our ablation studies on maze navigation, we find that Searchformer significantly outperforms baselines that predict the optimal plan directly with a 5-10× smaller model size and a 10× smaller training dataset. We also demonstrate how Searchformer scales to larger and more complex decision making tasks like Sokoban with improved percentage of solved tasks and shortened search dynamics.
| Subjects: | Artificial Intelligence (cs.AI) |
| Cite as: | arXiv:2402.14083 [cs.AI] |
| (or arXiv:2402.14083v1 [cs.AI] for this version) | |
| [2402.14083] Beyond A*: Better Planning with Transformers via Search Dynamics Bootstrapping Focus to learn more |
Submission history
From: Lucas Lehnert [view email][v1] Wed, 21 Feb 2024 19:17:28 UTC (758 KB)
Sure, let's break this down:
Transformers are a type of AI model that have been really useful in many areas. But when it comes to making complex decisions, they're not as good as the old-school methods.
In this research, the authors trained a Transformer (which they named "Searchformer") to solve tricky puzzles called Sokoban. It was able to solve these puzzles correctly 93.7% of the time, and it did so using fewer steps than the traditional method (A* search).
Searchformer is a special kind of Transformer that's been trained to mimic the way A* search works. It's then fine-tuned to do even better, using fewer steps but still finding the best solution.
The way they trained it was by teaching it how A* search adds and removes possible solutions during the planning process. They represented this as a sequence of tokens (like a sentence made up of words).
They tested Searchformer on navigating mazes and found it did much better than other methods that try to find the best plan directly. It was able to do this even though it was 5-10 times smaller and trained on a dataset 10 times smaller.
Finally, they showed that Searchformer can handle bigger and more complex tasks, like more difficult Sokoban puzzles. It solved more puzzles and did so more efficiently.

Nemotron-4 15B Technical Report
Published on Feb 26·Featured in Daily Papers on Feb 26
Authors:
Jupinder Parmar , Shrimai Prabhumoye , Joseph Jennings , Mostofa Patwary , Sandeep Subramanian , Dan Su , Chen Zhu , Deepak Narayanan , Aastha Jhunjhunwala , Ayush Dattagupta , Vibhu Jawa , Jiwei Liu , Ameya Mahabaleshwarkar , Osvald Nitski , Annika Brundyn , James Maki , Miguel Martinez , Jiaxuan You , John Kamalu , Patrick LeGresley , Denys Fridman , Jared Casper +5 authors
Abstract
We introduce Nemotron-4 15B, a 15-billion-parameter large multilingual language model trained on 8 trillion text tokens. Nemotron-4 15B demonstrates strong performance when assessed on English, multilingual, and coding tasks: it outperforms all existing similarly-sized open models on 4 out of 7 downstream evaluation areas and achieves competitive performance to the leading open models in the remaining ones. Specifically, Nemotron-4 15B exhibits the best multilingual capabilities of all similarly-sized models, even outperforming models over four times larger and those explicitly specialized for multilingual tasks.Nemotron-4 15B Technical Report
We introduce Nemotron-4 15B, a 15-billion-parameter large multilingual language model trained on 8 trillion text tokens. Nemotron-4 15B demonstrates strong performance when assessed on English, multilingual, and coding tasks: it outperforms all existing similarly-sized open models on 4 out of 7...
The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
Recent research, such as BitNet, is paving the way for a new era of 1-bit Large Language Models (LLMs). In this work, we introduce a 1-bit LLM variant, namely BitNet b1.58, in which every single parameter (or weight) of the LLM is ternary {-1, 0, 1}. It matches the full-precision (i.e., FP16 or...
Computer Science > Computation and Language
[Submitted on 27 Feb 2024]The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits
Shuming Ma, Hongyu Wang, Lingxiao Ma, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, Furu WeiRecent research, such as BitNet, is paving the way for a new era of 1-bit Large Language Models (LLMs). In this work, we introduce a 1-bit LLM variant, namely BitNet b1.58, in which every single parameter (or weight) of the LLM is ternary {-1, 0, 1}. It matches the full-precision (i.e., FP16 or BF16) Transformer LLM with the same model size and training tokens in terms of both perplexity and end-task performance, while being significantly more cost-effective in terms of latency, memory, throughput, and energy consumption. More profoundly, the 1.58-bit LLM defines a new scaling law and recipe for training new generations of LLMs that are both high-performance and cost-effective. Furthermore, it enables a new computation paradigm and opens the door for designing specific hardware optimized for 1-bit LLMs.
| Comments: | Work in progress |
| Subjects: | Computation and Language (cs.CL); Machine Learning (cs.LG) |
| Cite as: | arXiv:2402.17764 [cs.CL] |
| (or arXiv:2402.17764v1 [cs.CL] for this version) | |
| [2402.17764] The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits Focus to learn more |
Submission history
From: Shuming Ma [view email][v1] Tue, 27 Feb 2024 18:56:19 UTC (201 KB)
Transparent Image Layer Diffusion using Latent Transparency
Paper: https://arxiv.org/abs/2402.17113
Abstract
We present LayerDiffusion, an approach enabling large-scale pretrained latent diffusion models to generate transparent images. The method allows generation of single transparent images or of multiple transparent layers. The method learns a "latent transparency" that encodes alpha channel transparency into the latent manifold of a pretrained latent diffusion model. It preserves the production-ready quality of the large diffusion model by regulating the added transparency as a latent offset with minimal changes to the original latent distribution of the pretrained model. In this way, any latent diffusion model can be converted into a transparent image generator by finetuning it with the adjusted latent space. We train the model with 1M transparent image layer pairs collected using a human-in-the-loop collection scheme. We show that latent transparency can be applied to different open source image generators, or be adapted to various conditional control systems to achieve applications like foreground/background-conditioned layer generation, joint layer generation, structural control of layer contents, etc. A user study finds that in most cases (97%) users prefer our natively generated transparent content over previous ad-hoc solutions such as generating and then matting. Users also report the quality of our generated transparent images is comparable to real commercial transparent assets like Adobe Stock.

GitHub - layerdiffusion/LayerDiffusion: Transparent Image Layer Diffusion using Latent Transparency
Transparent Image Layer Diffusion using Latent Transparency - layerdiffusion/LayerDiffusion
 github.com
github.com
Last edited:

etri-vilab/koala-700m-llava-cap · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co

New AI image generator is 8 times faster than OpenAI's best tool — and can run on cheap computers
Scientists used "knowledge distillation" to condense Stable Diffusion XL into a much leaner, more efficient AI image generation model that can run on low-cost hardware.
New AI image generator is 8 times faster than OpenAI's best tool — and can run on cheap computers
NewsBy Keumars Afifi-Sabet
published about 17 hours ago
Scientists used "knowledge distillation" to condense Stable Diffusion XL into a much leaner, more efficient AI image generation model that can run on low-cost hardware.

The tool can run on low-cost graphics processing units (GPUs) and needs roughly 8GB of RAM to process requests (Image credit: Electronics and Telecommunications Research Institute(ETRI))
A new artificial intelligence (AI) tool can generate images in under two seconds — and it doesn't need expensive hardware to run.
South Korean scientists have used a special technique called knowledge distillation to compress the size of an open source (or publicly available) image generation model known as Stable Diffusion XL — which has 2.56 billion parameters, or variables the AI uses to learn during training.
The smallest version of the new model, known as "KOALA", has just 700 million parameters, meaning it's lean enough to run quickly and without needing expensive and energy-intensive hardware.
Related: AI chatbots need to be much better at remembering things. Have scientists just cracked their terrible memory problem?
The method they used, knowledge distillation, transfers knowledge from a large model to a smaller one, ideally without compromising performance. The benefit of a smaller model is that it takes less time to perform computations and generate an answer.
The tool can run on low-cost graphics processing units (GPUs) and needs roughly 8GB of RAM to process requests — versus larger models, which need high-end industrial GPUs.
The team published their findings in a paper Dec. 7, 2023 to the preprint database arXiv. They have also made their work available via the open source AI repository Hugging Face.
The Electronics and Telecommunication Research Institute (ETRI), the institution behind the new models, has created five versions including three versions of the "KOALA" image generator — which generates images based on text input — and two versions of "Ko-LLaVA" — which can answer text-based questions with images or video.
RELATED STORIES
— New Chinese AI model 'better than industry leader' in key metrics
— Artificial general intelligence — when AI becomes more capable than humans — is just moments away, Meta's Mark Zuckerberg declares
—L ast year AI entered our lives — is 2024 the year it'll change them?
When they tested KOALA, it generated an image based on the prompt "a picture of an astronaut reading a book under the moon on Mars" in 1.6 seconds. OpenAI's DALL·E 2 generated an image based on the same prompt in 12.3 seconds, and DALL·E 3 generated it in 13.7 seconds, according to a statement.
The scientists now plan to integrate the technology they've developed into existing image generation services, education services, content production and other lines of business.
With the advent of high-quality AI-generated media and the soon-to-be reality of generation on a real-time basis, I'm seeing a version of the same type of questions going around: how will we be able to distinguish real from generated? I think that's the wrong question to ask. It's worth remembering that generated videos have been around for 60+ years. And we are all okay. We actually already have a term for it: computer-generated imagery (CGI). Most movies and shows you watch are partially or entirely generated. Remember those dinosaurs in Jurassic Park? Guess what? They are not real. (yeah, sorry to break that) But sometimes, CGI is harder to find. Look for David Fincher's VFX breakdown of The Social Network, for example. The best CGI is the one you don't notice. And society has been perfectly fine about it.
Under that premise, then, the real concerns do not seem to be how to distinguish what is real from what is not, but what happens when everyone has the tools that a David Fincher movie budget has. What happens when everyone can create anything they can imagine. My long-term position is that what is needed moving forward is a focus on i) digital literacy and ii) social awareness.
i) Digital literacy: you need to adjust your mental models for every new technology. We keep discussing how fast technology changes, but we rarely discuss how fast culture adapts. We tend to underestimate speed of cultural changes and human adaptability. The best way of updating a prior is to have experience and exposure. One of the earliest films ever made was “The Arrival of a Train at La Ciotat Station” by the Lumière brothers in 1895. Legend has it that when the film was first screened, the audience panicked and fled the theater, convinced that the train in the film was going to burst through the screen and run them over. You can cure your fear of trains in films by understanding how movies are made.
ii) Collective awareness: Social verification is key for any malicious type of content. We are already collectively good at sussing out malicious things that are trying to be passed as truth but are not. We get better at collective awareness by exercising more of i). The solution to potential challenges posed by ubiquitous access to high-quality content creation tools is not merely technological but also cultural and educational.
Under that premise, then, the real concerns do not seem to be how to distinguish what is real from what is not, but what happens when everyone has the tools that a David Fincher movie budget has. What happens when everyone can create anything they can imagine. My long-term position is that what is needed moving forward is a focus on i) digital literacy and ii) social awareness.
i) Digital literacy: you need to adjust your mental models for every new technology. We keep discussing how fast technology changes, but we rarely discuss how fast culture adapts. We tend to underestimate speed of cultural changes and human adaptability. The best way of updating a prior is to have experience and exposure. One of the earliest films ever made was “The Arrival of a Train at La Ciotat Station” by the Lumière brothers in 1895. Legend has it that when the film was first screened, the audience panicked and fled the theater, convinced that the train in the film was going to burst through the screen and run them over. You can cure your fear of trains in films by understanding how movies are made.
ii) Collective awareness: Social verification is key for any malicious type of content. We are already collectively good at sussing out malicious things that are trying to be passed as truth but are not. We get better at collective awareness by exercising more of i). The solution to potential challenges posed by ubiquitous access to high-quality content creation tools is not merely technological but also cultural and educational.
StarCoder2 and The Stack v2
Published February 28, 2024
Update on GitHub
lvwerraLeandro von Werra
loubnabnlLoubna Ben Allal
anton-lAnton Lozhkov
nouamanetaziNouamane Tazi

BigCode is releasing StarCoder2 the next generation of transparently trained open code LLMs. All StarCoder2 variants were trained on The Stack v2, a new large and high quality code dataset. We release all models, datasets, and the processing as well as the training code. Check out the paper for details.
StarCoder2 and The Stack v2What is StarCoder2?
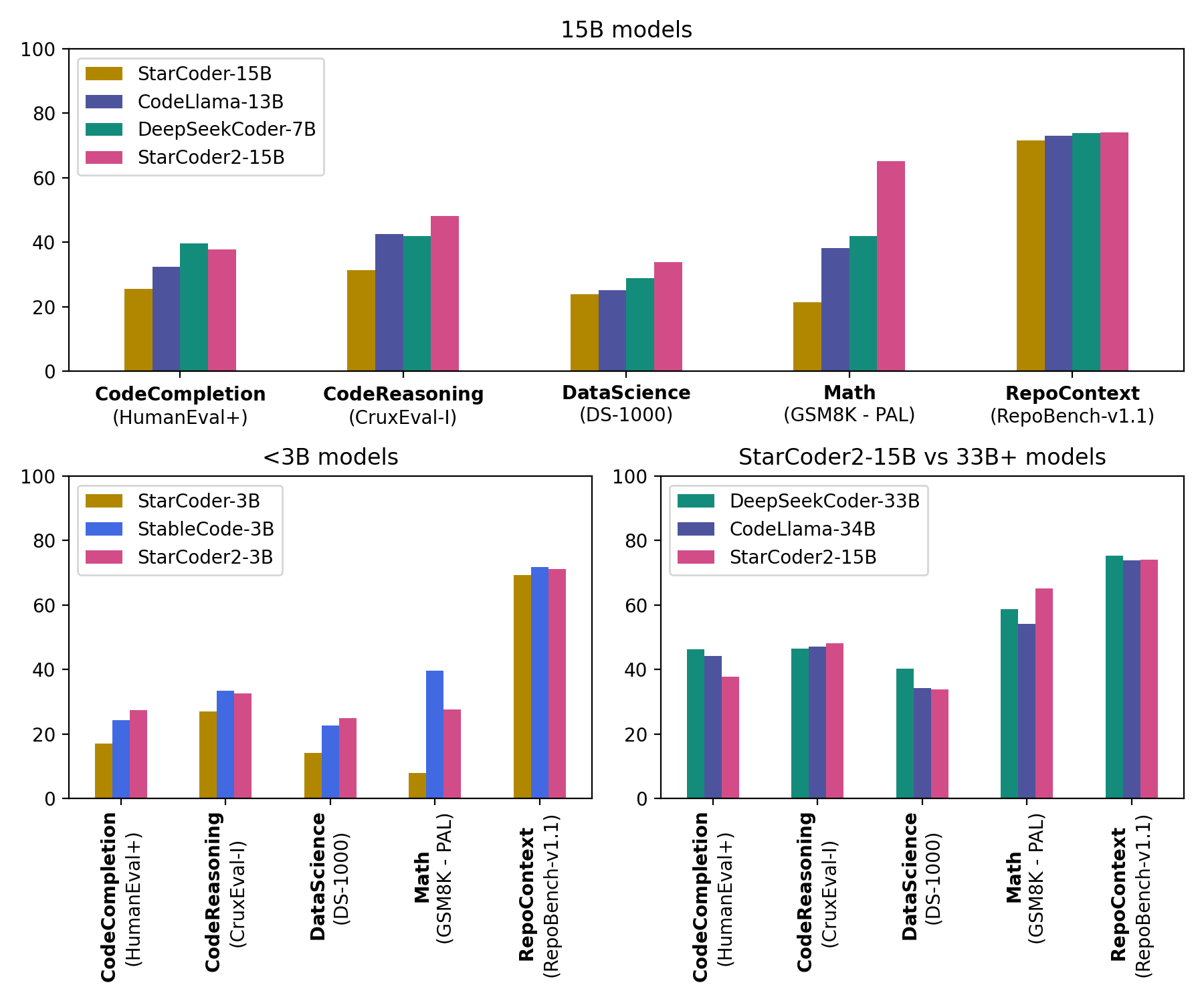
StarCoder2 is a family of open LLMs for code and comes in 3 different sizes with 3B, 7B and 15B parameters. StarCoder2-15B is trained on over 4 trillion tokens and 600+ programming languages from The Stack v2. All models use Grouped Query Attention, a context window of 16,384 tokens with a sliding window attention of 4,096 tokens, and were trained using the Fill-in-the-Middle.
StarCoder2 offers three model sizes: a 3 billion-parameter model trained by ServiceNow, a 7 billion-parameter model trained by Hugging Face, and a 15 billion-parameter model trained by NVIDIA with NVIDIA NeMo and trained on NVIDIA accelerated infrastructure:
StarCoder2-3B was trained on 17 programming languages from The Stack v2 on 3+ trillion tokens.
StarCoder2-7B was trained on 17 programming languages from The Stack v2 on 3.5+ trillion tokens.
StarCoder2-15B was trained on 600+ programming languages from The Stack v2 on 4+ trillion tokens.
StarCoder2-15B is the best in its size class and matches 33B+ models on many evaluations. StarCoder2-3B matches the performance of StarCoder1-15B:
StarCoder2 and The Stack v2What is The Stack v2?

The Stack v2 is the largest open code dataset suitable for LLM pretraining. The Stack v2 is larger than The Stack v1, follows an improved language and license detection procedure, and better filtering heuristics. In addition, the training dataset is grouped by repositories, allowing to train models with repository context.
| The Stack v1 | The Stack v2 | � |
|---|---|---|
| full | 6.4TB | 67.5TB |
| deduplicated | 2.9TB | 32.1TB |
| training dataset | ~200B tokens | ~900B tokens |
This dataset is derived from the Software Heritage archive, the largest public archive of software source code and accompanying development history. Software Heritage is an open, non profit initiative to collect, preserve, and share the source code of all publicly available software, launched by Inria, in partnership with UNESCO. We thank Software Heritage for providing access to this invaluable resource. For more details, visit the Software Heritage website.
The Stack v2 can be accessed through the Hugging Face Hub.
StarCoder2 and The Stack v2About BigCode
BigCode is an open scientific collaboration led jointly by Hugging Face and ServiceNow that works on the responsible development of large language models for code.
StarCoder2 and The Stack v2Links
StarCoder2 and The Stack v2Models
Paper: A technical report about StarCoder2 and The Stack v2.
GitHub: All you need to know about using or fine-tuning StarCoder2.
StarCoder2-3B: Small StarCoder2 model.
StarCoder2-7B: Medium StarCoder2 model.
StarCoder2-15B: Large StarCoder2 model.
StarCoder2 and The Stack v2Data & Governance
StarCoder2 License Agreement: The model is licensed under the BigCode OpenRAIL-M v1 license agreement.
StarCoder2 Search: Full-text search for code in the pretraining dataset.
StarCoder2 Membership Test: Blazing fast test if code was present in pretraining dataset.
StarCoder2 and The Stack v2Others
VSCode Extension: Code with StarCoder!
Big Code Models Leaderboard You can find all the resources and links at huggingface.co/bigcode!
Last edited:
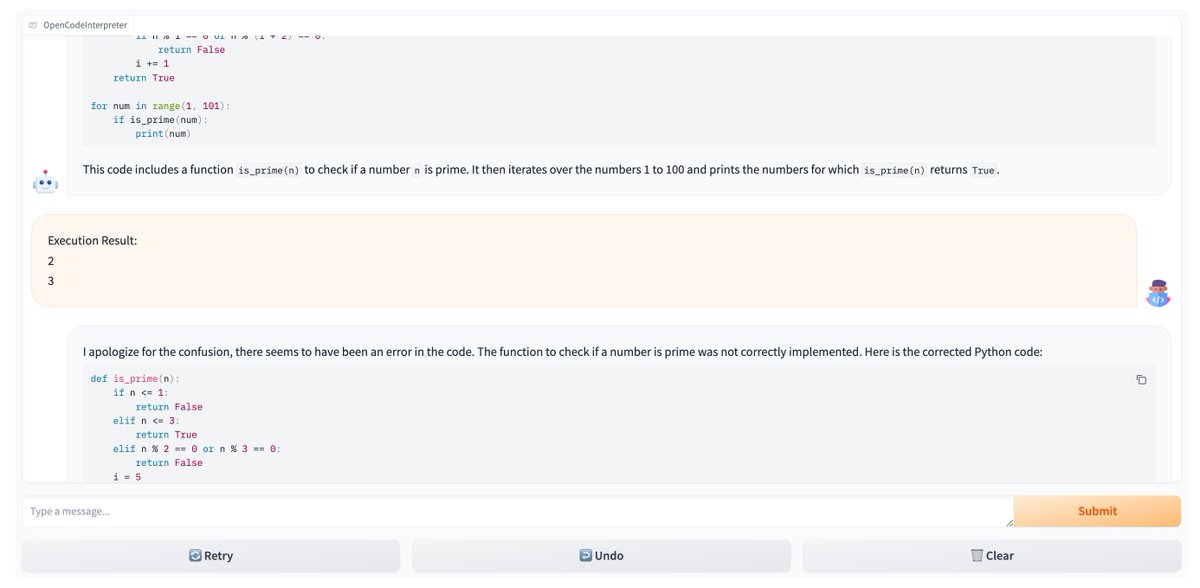




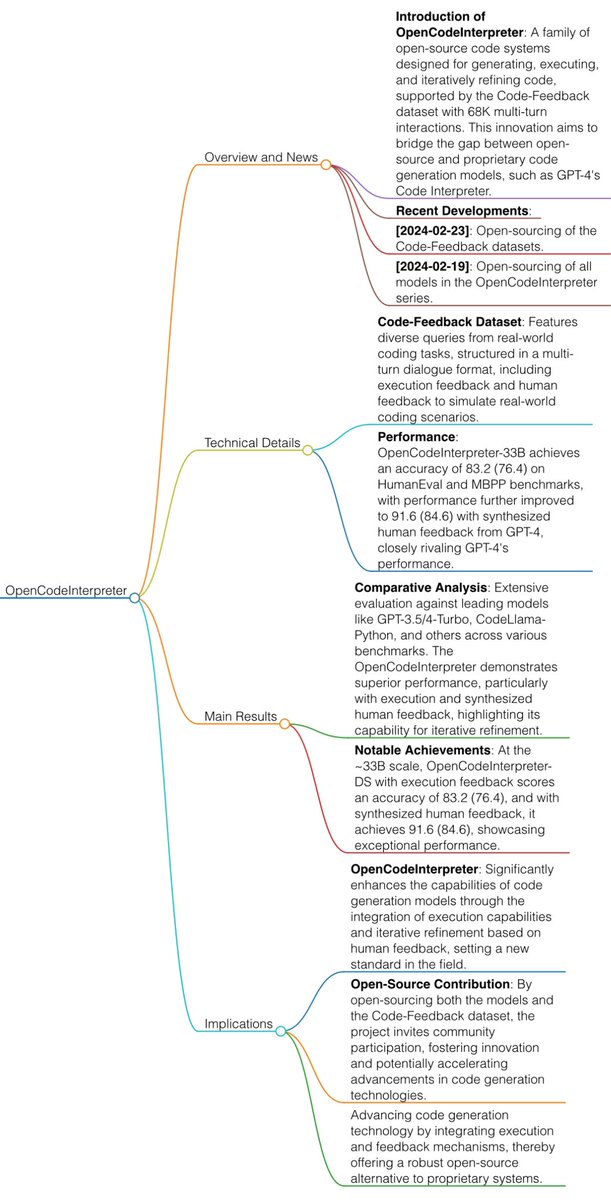
GitHub - OpenCodeInterpreter/OpenCodeInterpreter
Contribute to OpenCodeInterpreter/OpenCodeInterpreter development by creating an account on GitHub.
github.com
OpenCodeInterpreter: Integrating Code Generation with Execution and Refinement