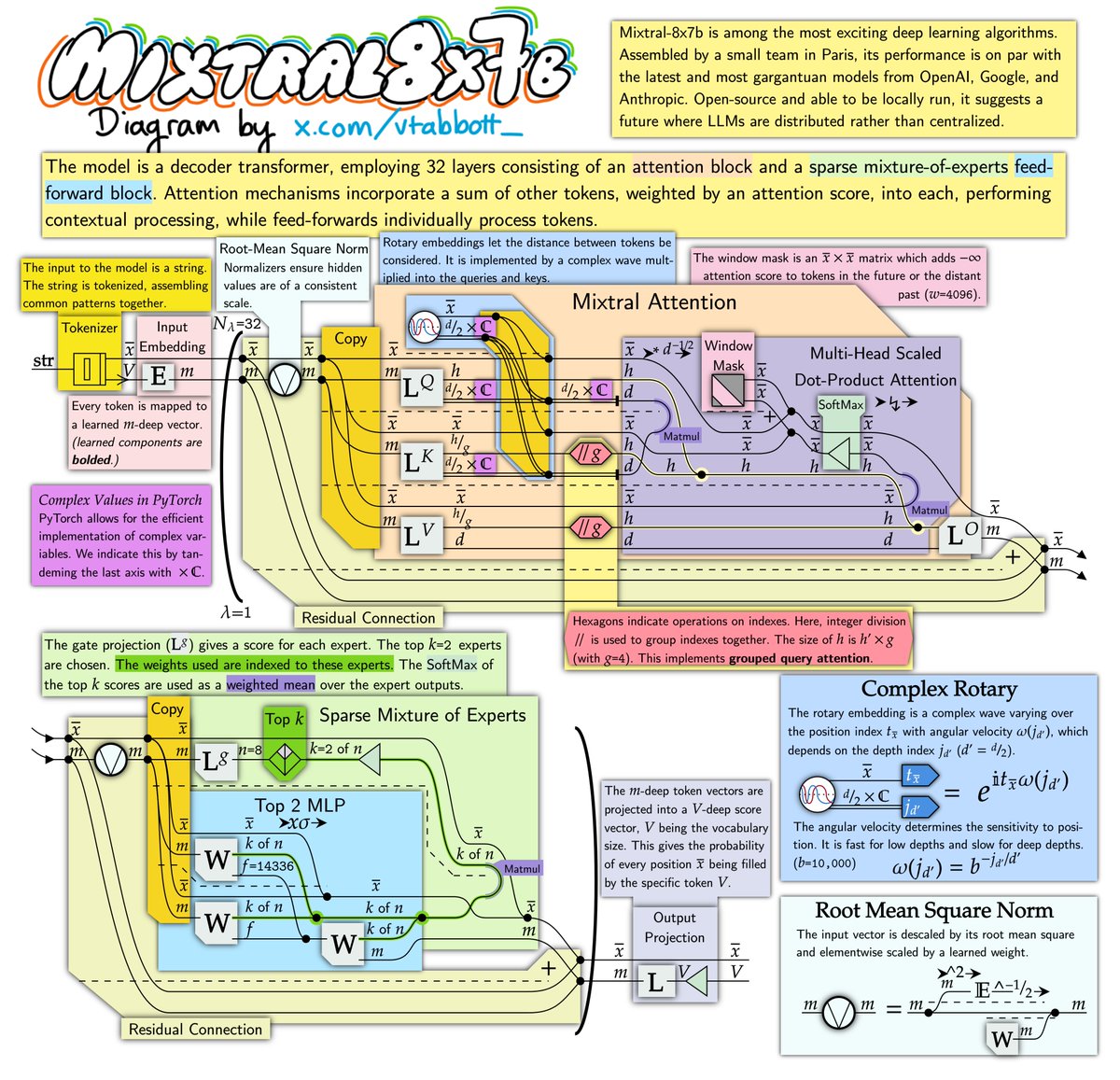
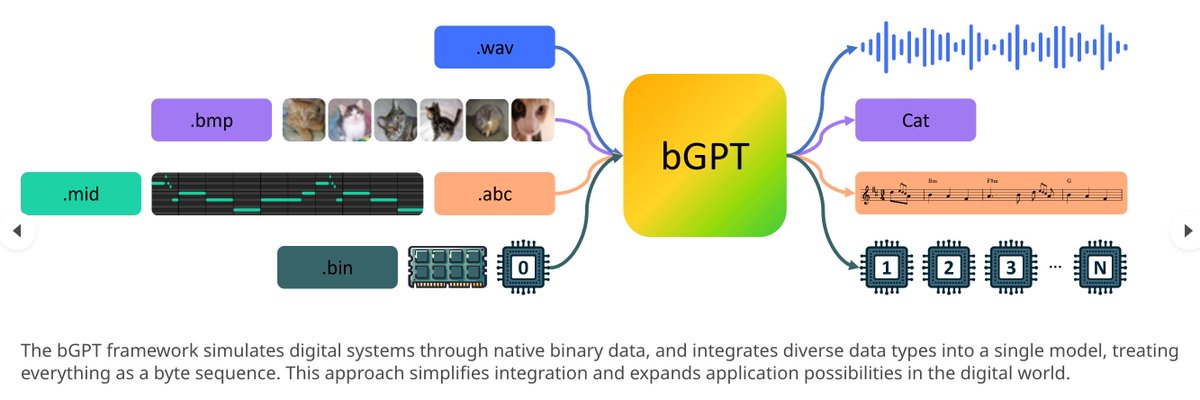
StarCoder 2, the follow-up to StarCoder, is a new family of code-generating models that runs highly efficiently.

techcrunch.com
StarCoder 2 is a code-generating AI that runs on most GPUs
Kyle Wiggers @kyle_l_wiggers / 9:00 AM EST•February 28, 2024
Image Credits: Tippapatt / Getty Images
Developers are adopting AI-powered code generators — services like
GitHub Copilot and
Amazon CodeWhisperer, along with open access models such as Meta’s
CodeLlama — at an
astonishingrate. But the tools are far from ideal. Many aren’t free. Others are, but only under licenses that preclude them from being used in common commercial contexts.
Perceiving the demand for alternatives, AI startup Hugging Face several years ago teamed up with ServiceNow, the workflow automation platform, to create
StarCoder, an open source code generator with a less restrictive license than some of the others out there. The original came online early last year, and work has been underway on a follow-up, StarCoder 2, ever since.
StarCoder 2 isn’t a single code-generating model, but rather a family. Released today, it comes in three variants, the first two of which can run on most modern consumer GPUs:
- A 3-billion-parameter (3B) model trained by ServiceNow
- A 7-billion-parameter (7B) model trained by Hugging Face
- A 15-billion-parameter (15B) model trained by Nvidia, the newest supporter of the StarCoder project.
(Note that “parameters” are the parts of a model learned from training data and essentially define the skill of the model on a problem, in this case generating code.)
Like most other code generators, StarCoder 2 can suggest ways to complete unfinished lines of code as well as summarize and retrieve snippets of code when asked in natural language. Trained with 4x more data than the original StarCoder (67.5 terabytes versus 6.4 terabytes), StarCoder 2 delivers what Hugging Face, ServiceNow and Nvidia characterize as “significantly” improved performance at lower costs to operate.
StarCoder 2 can be fine-tuned “in a few hours” using a GPU like the Nvidia A100 on first- or third-party data to create apps such as chatbots and personal coding assistants. And, because it was trained on a larger and more diverse data set than the original StarCoder (~619 programming languages), StarCoder 2 can make more accurate, context-aware predictions — at least hypothetically.
“StarCoder 2 was created especially for developers who need to build applications quickly,” Harm de Vries, head of ServiceNow’s StarCoder 2 development team, told TechCrunch in an interview. “With StarCoder2, developers can use its capabilities to make coding more efficient without sacrificing speed or quality.”
Now, I’d venture to say that not every developer would agree with De Vries on the speed and quality points. Code generators promise to streamline certain coding tasks — but at a cost.
A recent Stanford
study found that engineers who use code-generating systems are more likely to introduce security vulnerabilities in the apps they develop. Elsewhere, a
poll from Sonatype, the cybersecurity firm, shows that the majority of developers are concerned about the lack of insight into how code from code generators is produced and “code sprawl” from generators producing too much code to manage.
StarCoder 2’s license might also prove to be a roadblock for some.
StarCoder 2 is licensed under Hugging Face’s RAIL-M, which aims to promote responsible use by imposing “light touch” restrictions on both model licensees and downstream users. While less constraining than many other licenses, RAIL-M isn’t truly “open” in the sense that it doesn’t
permit developers to use StarCoder 2 for
every conceivable application (medical advice-giving apps are strictly off limits, for example). Some commentators say RAIL-M’s requirements may be too vague to comply with in any case — and that RAIL-M could conflict with AI-related regulations like the EU AI Act.
Setting all this aside for a moment, is StarCoder 2 really superior to the other code generators out there — free or paid?
Depending on the benchmark, it appears to be more efficient than one of the versions of CodeLlama, CodeLlama 33B. Hugging Face says that StarCoder 2 15B matches CodeLlama 33B on a subset of code completion tasks at twice the speed. It’s not clear which tasks; Hugging Face didn’t specify.
StarCoder 2, as an open source collection of models, also has the advantage of being able to deploy locally and “learn” a developer’s source code or codebase — an attractive prospect to devs and companies wary of exposing code to a cloud-hosted AI. In a 2023
survey from Portal26 and CensusWide, 85% of businesses said that they were wary of adopting GenAI like code generators due to the privacy and security risks — like employees sharing sensitive information or vendors training on proprietary data.
Hugging Face, ServiceNow and Nvidia also make the case that StarCoder 2 is more ethical — and less legally fraught — than its rivals.
All GenAI models regurgitate — in other words, spit out a mirror copy of data they were trained on. It doesn’t take an active imagination to see why this might land a developer in trouble. With code generators trained on copyrighted code, it’s entirely possible that, even with filters and additional safeguards in place, the generators could unwittingly recommend copyrighted code and fail to label it as such.
A few vendors, including GitHub, Microsoft (GitHub’s parent company) and Amazon, have
pledged to provide legal coverage in situations where a code generator customer is accused of violating copyright. But coverage varies vendor-to-vendor and is generally limited to corporate clientele.
As opposed to code generators trained using copyrighted code (GitHub Copilot, among others), StarCoder 2 was trained only on data under license from the Software Heritage, the nonprofit organization providing archival services for code. Ahead of StarCoder 2’s training,
BigCode, the cross-organizational team behind much of StarCoder 2’s roadmap, gave code owners a chance to opt out of the training set if they wanted.
As with the original StarCoder, StarCoder 2’s training data is available for developers to fork, reproduce or audit as they please.
Leandro von Werra, a Hugging Face machine learning engineer and co-lead of BigCode, pointed out that while there’s been a proliferation of open code generators recently, few have been accompanied by information about the data that went into training them and, indeed, how they were trained.
“From a scientific standpoint, an issue is that training is not reproducible, but also as a data producer (i.e. someone uploading their code to GitHub), you don’t know if and how your data was used,” Von Werra said in an interview. “StarCoder 2 addresses this issue by being fully transparent across the whole training pipeline from scraping pretraining data to the training itself.”
StarCoder 2 isn’t perfect, that said. Like other code generators, it’s susceptible to bias. De Vries notes that it can generate code with elements that reflect stereotypes about gender and race. And because StarCoder 2 was trained on predominantly English-language comments, Python and Java code, it performs weaker on languages other than English and “lower-resource” code like Fortran and Haksell.
Still, Von Werra asserts it’s a step in the right direction.
“We strongly believe that building trust and accountability with AI models requires transparency and auditability of the full model pipeline including training data and training recipe,” he said. “StarCoder 2 [showcases] how fully open models can deliver competitive performance.”
You might be wondering — as was this writer — what incentive Hugging Face, ServiceNow and Nvidia have to invest in a project like StarCoder 2. They’re businesses, after all — and training models isn’t cheap.
So far as I can tell, it’s a tried-and-true strategy: foster goodwill and build paid services on top of the open source releases.
ServiceNow has already used StarCoder to create Now LLM, a product for code generation fine-tuned for ServiceNow workflow patterns, use cases and processes. Hugging Face, which offers model implementation consulting plans, is providing hosted versions of the StarCoder 2 models on its platform. So is Nvidia, which is making StarCoder 2 available through an API and web front-end.
For devs expressly interested in the no-cost offline experience, StarCoder 2 — the models, source code and more — can be downloaded from the project’s GitHub page.





 github.com
github.com