You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?

OmniACT: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop and Web
abs: [2402.17553] OmniACT: A Dataset and Benchmark for Enabling Multimodal Generalist Autonomous Agents for Desktop and Web
A novel dataset of desktop and website applications consisting of over 9.8K natural language tasks, UI screens, and corresponding code snippets collected through human annotation. Comprehensive evaluation of SOTA LLMs is performed, OmniACT is a challenging task for even the best LLM agents today, and existing models are far below human performance.



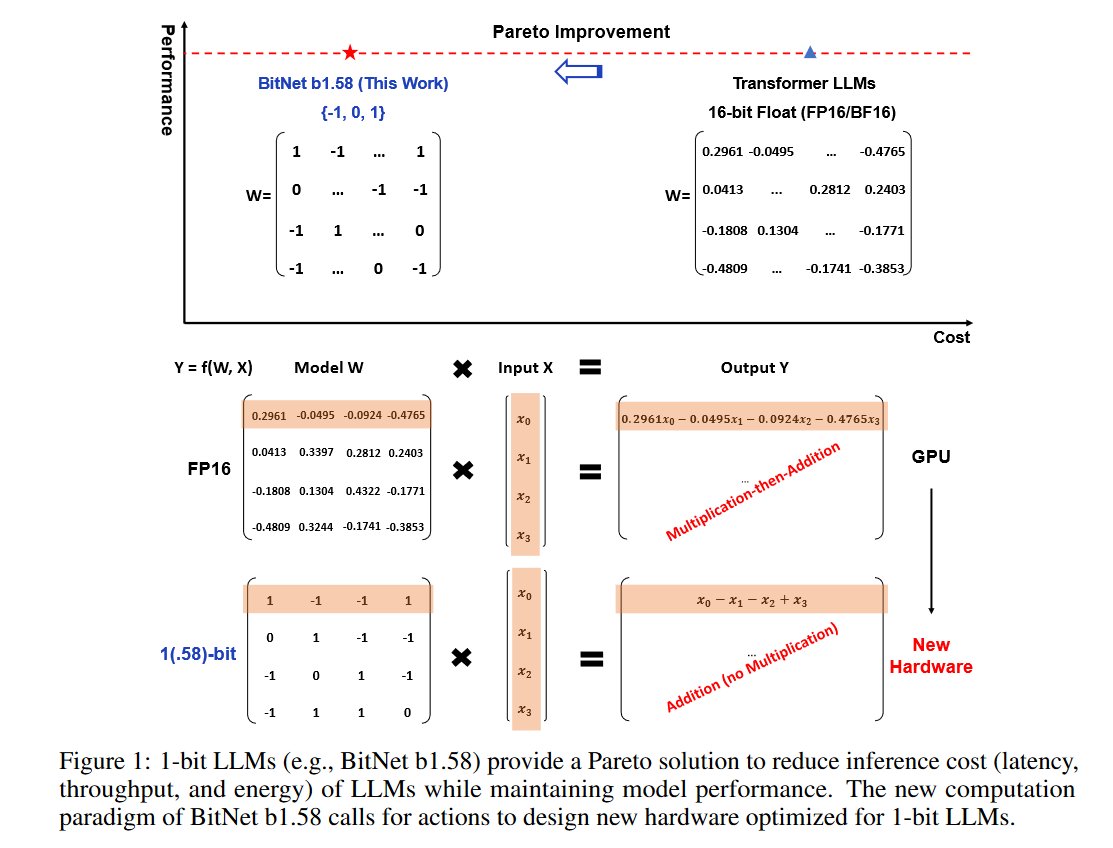
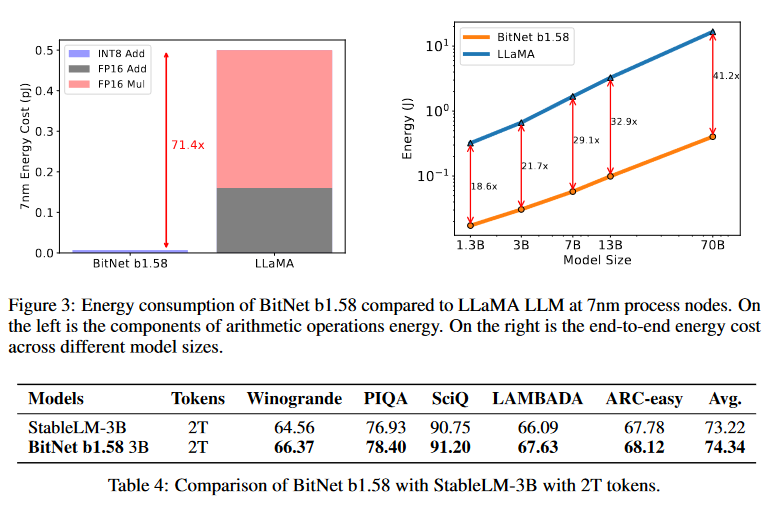
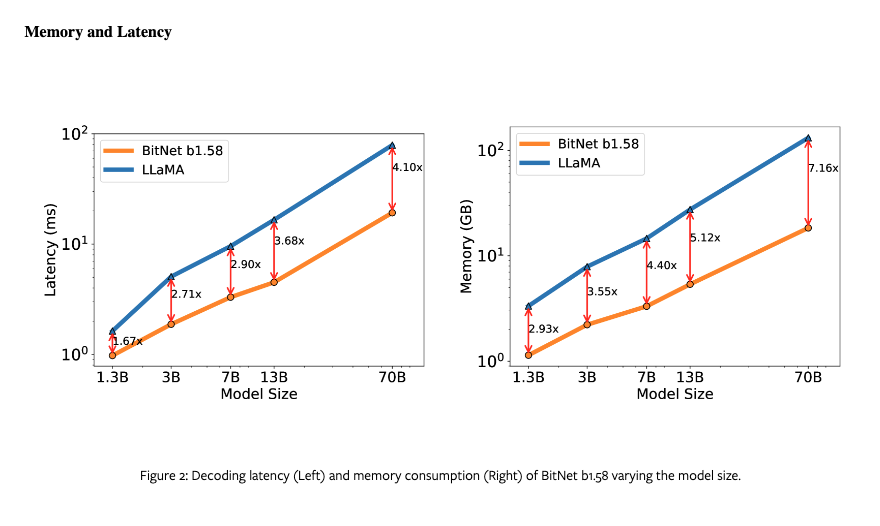
Microsoft presents The Era of 1-bit LLMs
All Large Language Models are in 1.58 Bits
Recent research, such as BitNet, is paving the way for a new era of 1-bit Large Language Models (LLMs). In this work, we introduce a 1-bit LLM variant, namely BitNet b1.58, in which every single parameter (or weight) of the LLM is ternary {-1, 0, 1}. It matches the full-precision (i.e., FP16 or BF16) Transformer LLM with the same model size and training tokens in terms of both perplexity and end-task performance, while being significantly more cost-effective in terms of latency, memory, throughput, and energy consumption. More profoundly, the 1.58-bit LLM defines a new scaling law and recipe for training new generations of LLMs that are both high-performance and cost-effective. Furthermore, it enables a new computation paradigm and opens the door for designing specific hardware optimized for 1-bit LLMs.





Last edited:
How we built “Mistral 7B Fine-Tune Optimized,” the best 7B model for fine-tuning - OpenPipe
Convert expensive LLM prompts into fast, cheap fine-tuned models
 openpipe.ai
openpipe.ai
How we built “Mistral 7B Fine-Tune Optimized,” the best 7B model for fine-tuning
Kyle CorbittDec 18, 2023
Hey there! I’m Kyle, the founder of OpenPipe. OpenPipe is the fully-managed fine-tuning platform for developers. Our users have already saved over $2M in inference costs by switching to our fine-tuned models, and it only takes a few minutes to get started.
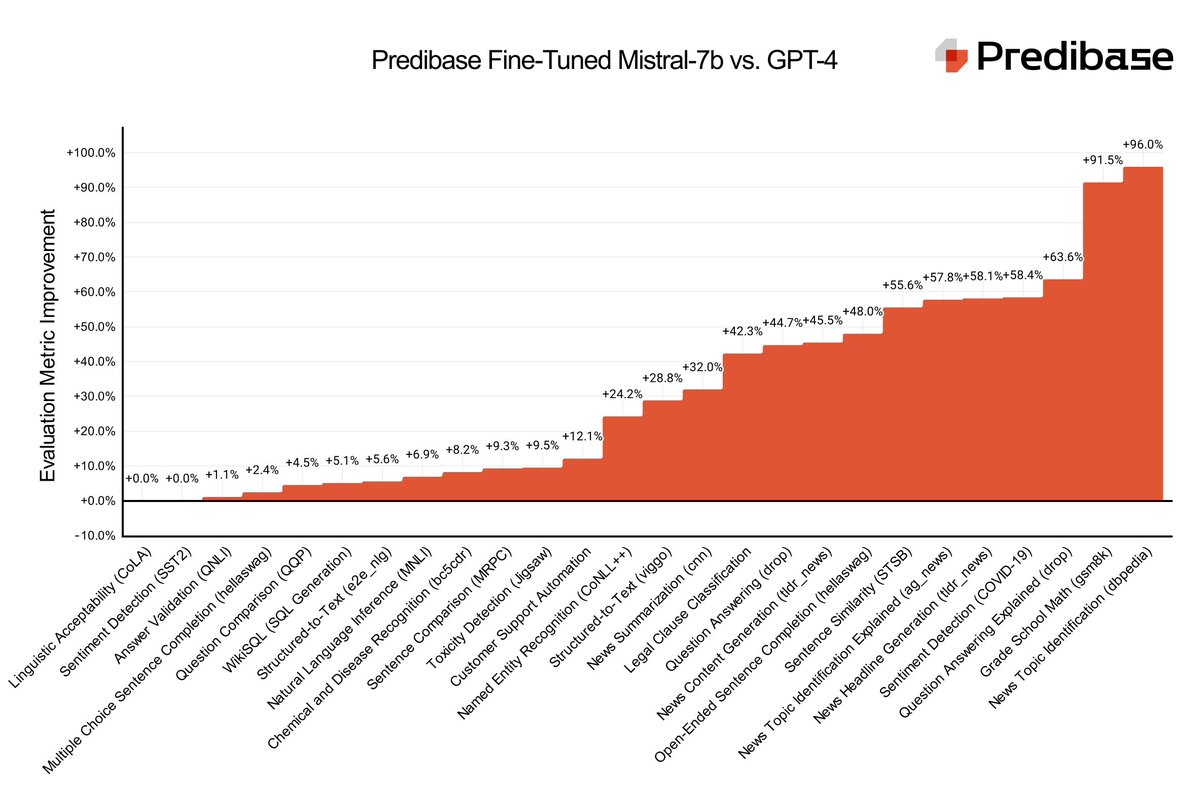
Since its release in September, Mistral 7B has been the model we’ve recommended to most of our customers. Today, we’re excited to announce an even stronger variant: Mistral 7B Fine-Tune Optimized.
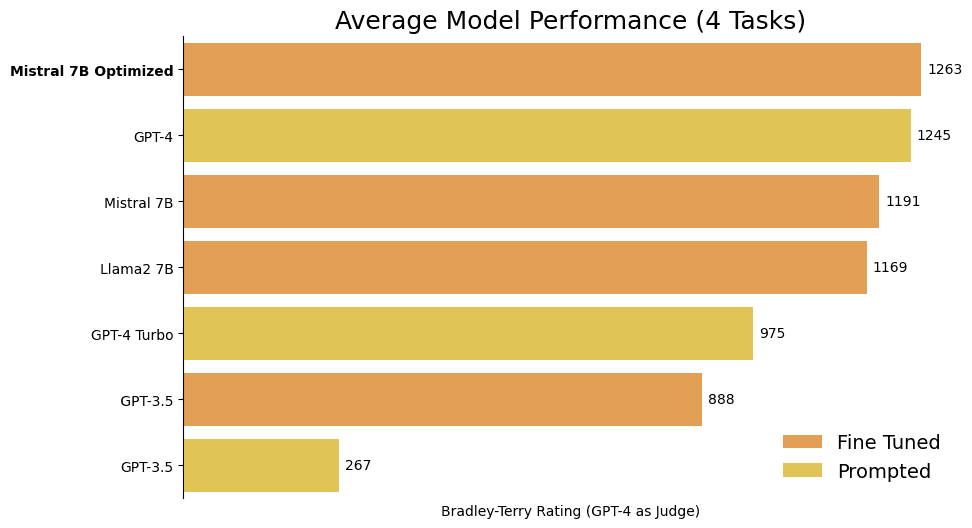
Let’s start with the punchline: averaged across 4 diverse customer tasks, fine-tunes based on our new model are slightly stronger than GPT-4, as measured by GPT-4 itself.
Read on for the details!
FAQs
GPT-4 is ~100x larger than Mistral. How is this possible?
The intuition here is actually quite straightforward. A general-purpose model like GPT-3.5 or GPT-4 has to be good at everything. It doesn’t know ahead of time what prompt it’ll need to respond to, and so it has to try to encode all of human knowledge. Additionally, every time it gets a new prompt it it has to figure out the right way to respond on the fly—it can’t think deeply about the problem and figure out a repeatable strategy to solve it. It can’t remember the times it has solved the same problem before.The process of fine-tuning, on the other hand, lets a model spend hours of training time learning about a specific task and developing strategies to reliably solve it. Even if it’s a less capable model overall, those hours of GPU time can help a fine-tuned model learn the right tricks to efficiently and successfully solve a specific problem.[1]
There are lots of Mistral fine-tunes. Why another one?
A very healthy ecosystem of Mistral fine-tunes already exists, but they’re typically optimized for direct use. We wanted something different — a model optimized to be the strongest base model for further fine-tunes to be built on. This involves carefully optimizing for instruction understanding and reasoning ability while avoiding “catastrophic forgetting,” the tendency for fine-tuned models to get worse at out-of-domain tasks when you fine-tune them for a specific purpose.Ok, let’s get the details!
You can’t hit a target you can’t see (Metrics)
We started by creating a “test set” of 3 different real OpenPipe customer tasks (with permission). These spanned our most common categories of information extraction, classification, and summarization. The goal was to find or create a new model that, when fine-tuned on these customer tasks, could outperform Mistral-based models on our evals, and become our new default base model.Choose your hero
We started by evaluating existing Mistral variants to see how they’d perform as a base model. After playing around with a number of models we selected six that seemed promising: OpenHermes 2.5, Zephyr, Cybertron, Intel Neural Chat, Hermes Neural, and Metamath Cybertron Starling. We created a fine-tuned version of each of these models on each of the 3 evaluation datasets, using a development build of OpenPipe that supports custom base models. This gave us 18 new models in total.
This dropdown ended up getting really long by the end of this project.

Beauty in the eye of GPT-4 (Evals)
To test each model’s performance, we used our recently released automated LLM-as-judge evals scored by GPT-4, which allowed us to quickly compare our fine-tunes to each other and gauge their strength.
The top model wasn’t consistent from task to task, but we did notice something interesting—two of the best-performing models overall were Hermes Neural and Metamath Cybertron Starling, which were both created not by fine-tuning directly but rather through model merging.
Magical thinking and model merging 

Model merging is, to me, one of the most counterintuitive empirical results in modern deep learning. It turns out that you can actually more-or-less naively merge the weights of two different models and produce a new one that captures some or all of the abilities of its parents! Since we had a candidate set of already-strong models, we decided to merge a few of the best ones and see if we could make one even stronger.We ended up testing 4 models created by merging our candidates and fine-tuning each of them on our 3 datasets, for a total of 12 additional fine-tuned models.
At this stage, evaluating every fine-tune against every other one across our large test sets felt pretty wasteful, since some models were clearly stronger than others. Instead, we ran 9,000 comparisons between our models’ outputs and those of GPT-4, GPT-4-turbo, and GPT-3.5, and ranked them using a Bradley-Terry ranking system, which is conceptually similar to an Elo rating. (You can see our ugly rating calculation code here). Finally, we got our model rankings, which showed one merge in particular was especially strong:

Check yo’self (Validation)
This was a really exciting result—averaged over our three example tasks, one of our merges slightly edged out GPT-4 as the strongest model! But there’s a problem. We’d been testing all our models, including the merges, on the same 3 datasets—was it possible that we’d overfit to those specific tasks?To address this concern we selected a new customer dataset we hadn’t used at all thus far (a structured data extraction task). We trained our new merge model as well as a base Mistral model on the new dataset, to verify whether its strong performance generalized to new tasks. Excitingly, the same results held!

We’re just getting started
We’re excited to announce that as of today we’re freely releasing Mistral Fine-Tune Optimized on Hugging Face and as our new default base model within OpenPipe. We’re excited to see what our users do with it, but this is just the beginning. Over time we’ll continue releasing more base models that are stronger, faster and cheaper. We’re looking forward to continue growing alongside the small-model community!————
[1]: As an aside, there’s an even stronger result that we’ve found through working with our customers: a student model trained on data generated by a teacher model can exceed the performance of the teacher model on its task. We’ve had several customers train a model on GPT-4 outputs, and found that their new model was actually better than GPT-4 at its task. This is likely due to a kind of regularization—the fine-tuned model is more likely to give the “average” answer that GPT-4 would give if prompted many times. This result is different but related to OpenAI’s recently-published research on weak-to-strong generalization.
Can be a revolutionary paper if implementable for all cases - for massively increasing context window of LLMs
Authors trained LLaMA-2 for 10K-steps with 4K context window and
Then it generalized to 400K context window
"Soaring from 4K to 400K: Extending LLM's Context with Activation Beacon"
 "In this work, we propose Activation Beacon, which condenses LLM's raw activations into more compact forms such that it can perceive a much longer context with a limited context window. Activation Beacon is introduced as a plug-and-play module for the LLM.
"In this work, we propose Activation Beacon, which condenses LLM's raw activations into more compact forms such that it can perceive a much longer context with a limited context window. Activation Beacon is introduced as a plug-and-play module for the LLM.
"It fully preserves the LLM's original capability on short contexts while extending the new capability on processing longer contexts. Besides, it works with short sliding windows to process the long context, which achieves a competitive memory and time efficiency in both training and inference. "
"Activation Beacon is learned by the auto-regression task conditioned on a mixture of beacons with diversified condensing ratios. Thanks to such a treatment, it can be efficiently trained purely with short-sequence data in just 10K steps, which consumes less than 9 hours on a single 8xA800 GPU machine."
"The experimental studies show that Activation Beacon is able to extend Llama-2-7B's context length by ×100 times (from 4K to 400K), meanwhile achieving a superior result on both long-context generation and understanding tasks. Our model and code will be available at the BGE repository."
Authors trained LLaMA-2 for 10K-steps with 4K context window and
Then it generalized to 400K context window
"Soaring from 4K to 400K: Extending LLM's Context with Activation Beacon"
"In this work, we propose Activation Beacon, which condenses LLM's raw activations into more compact forms such that it can perceive a much longer context with a limited context window. Activation Beacon is introduced as a plug-and-play module for the LLM. "It fully preserves the LLM's original capability on short contexts while extending the new capability on processing longer contexts. Besides, it works with short sliding windows to process the long context, which achieves a competitive memory and time efficiency in both training and inference. " "Activation Beacon is learned by the auto-regression task conditioned on a mixture of beacons with diversified condensing ratios. Thanks to such a treatment, it can be efficiently trained purely with short-sequence data in just 10K steps, which consumes less than 9 hours on a single 8xA800 GPU machine." "The experimental studies show that Activation Beacon is able to extend Llama-2-7B's context length by ×100 times (from 4K to 400K), meanwhile achieving a superior result on both long-context generation and understanding tasks. Our model and code will be available at the BGE repository."

Fine-tuning LLMs for longer context and better RAG systems
Based on the popular “Needle In a Haystack” benchmark and RAG, we share our process of creating a problem-specific fine-tuning dataset to extend the context of models to build better RAG systems.