And that's where tools like AutoGen come in. You build a team of agents who's job is to deal with unconscious incompetence.
It would look something like this:
Agent 1: It's your job to find any issues with code that is being reviewed. Make sure the code uses modern standards. Be extremely critical of the code. Send me a summary of any issues you find in a short email. Include graphs and charts.
Agent2: You're an expert code writer. Write the code according to known best practices. Once you're done give it to Agent 1 to review and implement any changes he recommends.
Agent3: You're the project manager. Work with agent 1 and agent 2 to figure out any issues and send me a summary report at 7PM.

Here's the whitepaper discussing the topic
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
And here's a video explaining the concept

The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?Mamba: The Easy Way
An overview of the big ideas behind Mamba, a brand-new language model architecture.
Computer Science > Computation and Language
[Submitted on 25 Jan 2024 (v1), last revised 28 Jan 2024 (this version, v2)]WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models
Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, Dong YuThe advancement of large language models (LLMs) leads to a new era marked by the development of autonomous applications in the real world, which drives innovation in the creation of advanced web-based agents. Existing web agents typically only handle one input modality and are evaluated only in simplified web simulators or static web snapshots, greatly limiting their applicability in real-world scenarios. To bridge this gap, we introduce WebVoyager, an innovative Large Multimodal Model (LMM) powered web agent that can complete user instructions end-to-end by interacting with real-world websites. Moreover, we propose a new evaluation protocol for web agents to address the challenges of automatic evaluation of open-ended web agent tasks, leveraging the robust multimodal comprehension capabilities of GPT-4V. We create a new benchmark by gathering real-world tasks from 15 widely used websites to evaluate our agents. We show that WebVoyager achieves a 55.7% task success rate, significantly surpassing the performance of both GPT-4 (All Tools) and the WebVoyager (text-only) setups, underscoring the exceptional capability of WebVoyager in practical applications. We found that our proposed automatic evaluation achieves 85.3% agreement with human judgment, paving the way for further development of web agents in a real-world setting.
| Subjects: | Computation and Language (cs.CL); Artificial Intelligence (cs.AI) |
| Cite as: | arXiv:2401.13919 [cs.CL] |
| (or arXiv:2401.13919v2 [cs.CL] for this version) | |
| [2401.13919] WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models Focus to learn more |
Submission history
From: Hongliang He [view email][v1] Thu, 25 Jan 2024 03:33:18 UTC (18,186 KB)
[v2] Sun, 28 Jan 2024 07:57:21 UTC (18,186 KB)

Google Colab
 colab.research.google.com
colab.research.google.com
𝐖𝐢𝐭𝐡 𝐬𝐨 𝐦𝐚𝐧𝐲 𝐦𝐨𝐝𝐞𝐥𝐬 𝐜𝐨𝐦𝐢𝐧𝐠 𝐨𝐮𝐭 𝐢𝐧 𝐭𝐡𝐞 𝐩𝐚𝐬𝐭 𝐟𝐞𝐰 𝐝𝐚𝐲𝐬, 𝐰𝐞 𝐜𝐨𝐮𝐥𝐝𝐧'𝐭 𝐩𝐚𝐬𝐬 𝐨𝐧 𝐚 𝐜𝐡𝐚𝐧𝐜𝐞 𝐭𝐨 𝐣𝐨𝐢𝐧 𝐭𝐡𝐞 𝐩𝐚𝐫𝐭𝐲!
We’re excited to share DeciLM-7B, Deci’s new Apache 2.0-licensed model, the most accurate and fastest 7B LLM to date. With DeciLM-7B combined with Infery-LLM, you no longer need to decide between good performance and affordability!
Here are 4 things you need to know about DeciLM-7B:
 With an average score of 61.55 on the Open LLM Leaderboard, DeciLM-7B outperforms all other base LLMs in the 7 billion-parameter class!
With an average score of 61.55 on the Open LLM Leaderboard, DeciLM-7B outperforms all other base LLMs in the 7 billion-parameter class! Direct PyTorch benchmarks show DeciLM-7B surpassing Mistral 7B and Llama 2 7B, with 1.83x and 2.39x higher throughput, respectively.
Direct PyTorch benchmarks show DeciLM-7B surpassing Mistral 7B and Llama 2 7B, with 1.83x and 2.39x higher throughput, respectively. DeciLM-7B + Infery-LLM boosts speed by 4.4x over Mistral 7B with vLLM, enabling cost-effective, high-volume user interactions.
DeciLM-7B + Infery-LLM boosts speed by 4.4x over Mistral 7B with vLLM, enabling cost-effective, high-volume user interactions. Developed with the assistance of our NAS-powered engine, AutoNAC, DeciLM-7B employs variable Grouped Query Attention.
Developed with the assistance of our NAS-powered engine, AutoNAC, DeciLM-7B employs variable Grouped Query Attention.We can’t wait for the community to try our DeciLM-7B!


Deci/DeciLM-7B-instruct · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
Last edited:

Introducing YOLO-NAS-Sat: Small Object Detection at the Edge
Tailored for the demands of small object detection, YOLO-NAS-Sat delivers SOTA accuracy and speed, serving a range of uses across industries.
 deci.ai
deci.ai
COMPUTER VISION
Introducing YOLO-NAS-Sat for Small Object Detection at the Edge

- By Deci
- Algorithms Team
- February 20, 2024
- 5 min read

Deci is excited to present YOLO-NAS-Sat, the latest in our lineup of ultra-performant foundation models, which includes YOLO-NAS, YOLO-NAS Pose, and DeciSegs. Tailored for the accuracy demands of small object detection, YOLO-NAS-Sat serves a wide array of vital uses, from monitoring urban infrastructure and assessing changes in the environment to precision agriculture. Available in four sizes—Small, Medium, Large, and X-large—this model is designed for peak performance in accuracy and speed on edge devices like NVIDIA’s Jetson Orin series.
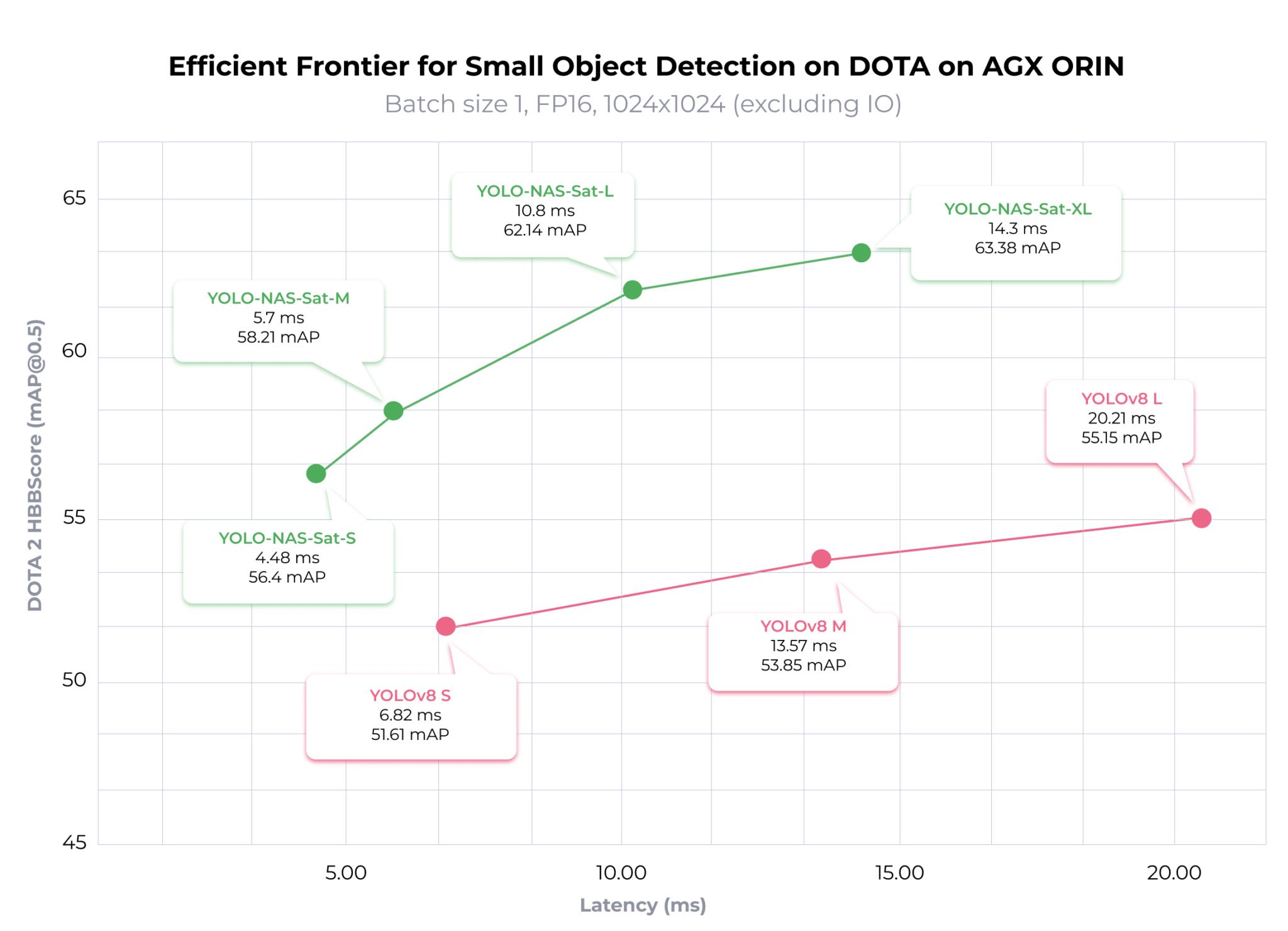
YOLO-NAS-Sat sets itself apart by delivering an exceptional accuracy-latency trade-off, outperforming established models like YOLOv8 in small object detection. For instance, when evaluated on the DOTA 2.0 dataset, YOLO-NAS-Sat L achieves a 2.02x lower latency and a 6.99 higher mAP on the NVIDIA Jetson AGX ORIN with FP16 precision over YOLOV8.
YOLO-NAS-Sat’s superior performance is attributable to its innovative architecture, generated by AutoNAC, Deci’s Neural Architecture Search engine.
If your application requires small object detection on edge devices, YOLO-NAS-Sat provides an off-the-shelf solution that can significantly accelerate your development process. Its specialized design and fine-tuning for small object detection ensure rapid deployment and optimal performance.
Continue reading to explore YOLO-NAS-Sat’s architectural design, training process, and performance.
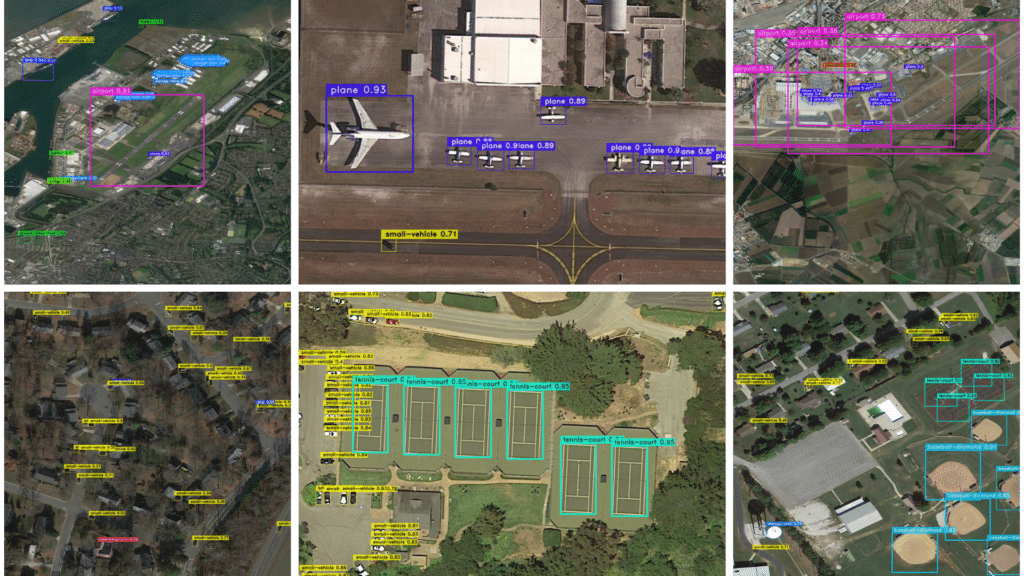
DOTA 2.0 images with YOLO-NAS-Sat XL predictions
YOLO-NAS-Sat’s Specialized Architecture
The Need for A Specialized Architecture for Small Object Detection
Small object detection is the task of detecting objects that take up minimal space in an image, sometimes a mere handful of pixels. This task inherently involves significant challenges, including scant detail for recognition and increased vulnerability to background noise. To meet these challenges, a specialized architecture is required – one that captures and retains small, local details in an image.
From YOLO-NAS to YOLO-NAS-Sat
YOLO-NAS-Sat is based on the YOLO-NAS architecture, which is renowned for its robust performance in standard object detection tasks. The macro-level architecture remains consistent with YOLO-NAS, but we’ve made strategic modifications to better address small object detection challenges:- Backbone Modifications: The number of layers in the backbone has been adjusted to optimize the processing of small objects, enhancing the model’s ability to discern minute details.
- Revamped Neck Design: A newly designed neck, inspired by the U-Net-style decoder, focuses on retaining more small-level details. This adaptation is crucial for preserving fine feature maps that are vital for detecting small objects.
- Context Module Adjustment: The original “context” module in YOLO-NAS, intended to capture global context, has been replaced. We discovered that for tasks like processing large satellite images, a local receptive window is more beneficial, improving both accuracy and network latency.
These architectural innovations ensure that YOLO-NAS-Sat is uniquely equipped to handle the intricacies of small object detection, offering an unparalleled accuracy-speed trade-off.
Leveraging AutoNAC for Architecture Optimization
At the heart of YOLO-NAS-Sat’s development is Deci’s AutoNAC, an advanced Neural Architecture Search engine. AutoNAC’s efficiency in navigating the vast search space of potential architectures allows us to tailor models specifically to the requirements of tasks, datasets, and hardware. YOLO-NAS-Sat is part of a broader family of highly efficient foundation models, including YOLO-NAS for standard object detection, YOLO-NAS Pose for pose estimation, and DeciSegs for semantic segmentation, all generated through AutoNAC.For YOLO-NAS-Sat, we utilized AutoNAC to identify a neural network within the pre-defined search space that achieves our target latency while maximizing accuracy.
YOLO-NAS-Sat’s Training
We trained YOLO-NAS-Sat from scratch on the COCO dataset, followed by fine-tuning on the DOTA 2.0 dataset. The DOTA 2.0 dataset is an extensive collection of aerial images designed for object detection and analysis, featuring diverse objects across multiple categories. For the fine-tuning phase, we segmented the input scenes into 1024×1024 tiles, employing a 512px step for comprehensive coverage. Additionally, we scaled each scene to 75% and 50% of its original size to enhance detection robustness across various scales.During the training process, we extracted random 640×640 crops from these tiles to introduce variability and enhance model resilience. For the validation phase, we divided the input scenes into uniform 1024×1024 tiles.
YOLO-NAS-Sat’s State-of-the-Art Performance
Accuracy Compared to Fine-tuned YOLOv8
To benchmark YOLO-NAS-Sat against YOLOv8, we subjected YOLOv8 to the same fine-tuning process previously outlined for YOLO-NAS-Sat.Comparing the accuracy of the fine-tuned models, we see that each YOLO-NAS-Sat variant has a higher mAP@0.5 score than the corresponding YOLOv8 variant. YOLO-NAS-Sat-S has 4.79% higher mAP compared to YOLOv8 S; YOLO-NAS-Sat-M mAP’s is 4.36% higher compared to YOLOv8 M , and YOLO-NAS-Sat-L is 6.99% more accurate than YOLOv8 L.

Latency Compared to YOLOv8
While higher accuracy typically demands a trade-off in speed, the finely tuned YOLO-NAS-Sat models break this convention by achieving lower latency compared to their YOLOv8 counterparts. However, on NVIDIA AGX Orin at TRT FP16 Precision, each YOLO-NAS-Sat variant outpaces the corresponding YOLOv8 variant. As can be seen in the above graph, YOLO-NAS-Sat S outpaces its YOLOv8 counterpart by 1.52x, YOLO-NAS-Sat M by 2.38x, and YOLO-NAS-Sat L by 2.02x. Notably, YOLO-NAS-Sat XL is not only more accurate but also 1.42x faster than YOLOv8 L.
Adopting YOLO-NAS-Sat for small object detection not only enhances accuracy but also substantially improves processing speeds. Such improvements are especially valuable in real-time applications, where rapid data processing is paramount.
Why We Chose mAP@0.5 for Small Object Detection Evaluation
In assessing these small object detection models, we opted for the mAP@0.5 metric over the broader mAP@0.5-0.95. The commonly adopted mAP@0.5-0.95, which evaluates performance across IOU thresholds from 0.5 to 0.95, may not accurately reflect the nuances of small object detection. Minor discrepancies, even as slight as a 1 or 2-pixel shift between the predicted and actual bounding boxes, can significantly impact the IOU score, plummeting it from perfect to 0.8 and thus affecting the overall mAP score adversely.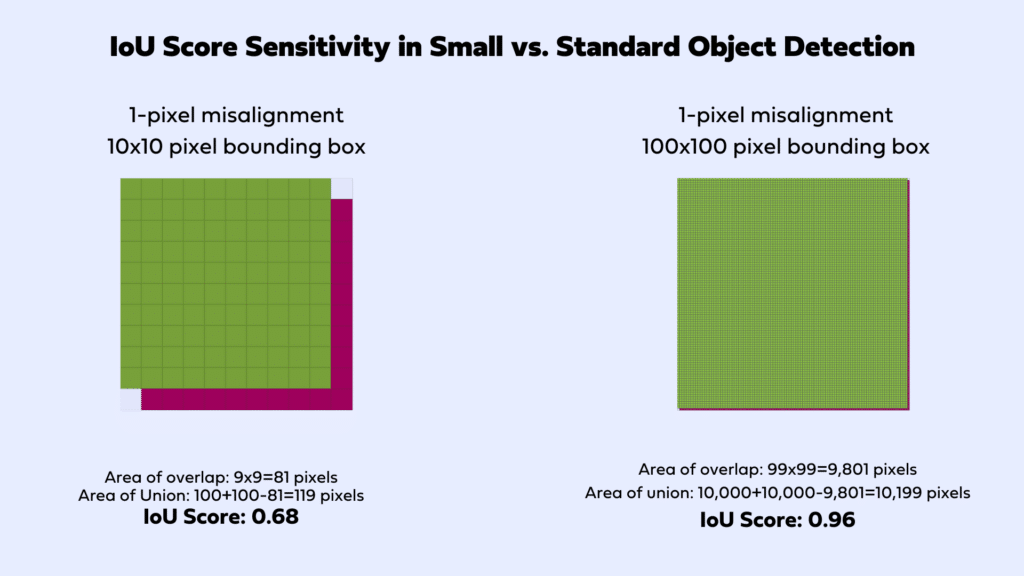
Considering the inherent sensitivities of the IOU metric when detecting small objects, it becomes imperative to adopt an alternative evaluation strategy. Utilizing a singular IOU threshold, such as 0.5, presents a viable solution by diminishing the metric’s vulnerability to small prediction errors, thereby offering a more stable and reliable measure of model performance in the context of small object detection.
YOLO-NAS-Sat’s Potential: Beyond Aerial Images
While YOLO-NAS-Sat excels in satellite imagery analysis, its specialized architecture is also ideally tailored for a wide range of applications involving other types of images:- Satellite Images: Used for environmental monitoring, urban development tracking, agricultural assessment, and security applications.
- Microscopic Images: Essential in medical research for detecting cells, bacteria, and other microorganisms, as well as in material science.
- Radar Images: Applied in meteorology for weather prediction, in aviation for aircraft navigation, and in maritime for ship detection.
- Thermal Images: Thermal imaging finds applications in a variety of fields, including security, wildlife monitoring, and industrial maintenance, as well as in building and energy audits. The unique information provided by thermal images, especially in night-time or low-visibility conditions, underlines its importance and the volume of use.
Gaining Access to YOLO-NAS-Sat
YOLO-NAS-Sat is ready to revolutionize your team’s small object detection projects. If you’re looking to leverage this model’s cutting-edge performance for your applications, we invite you to connect with our experts. You’ll learn how you can use Deci’s platform and foundation models to streamline your development process, achieving faster time-to-market and unlocking new possibilities in your computer vision projects.Google presents Genie
Generative Interactive Environments
introduce Genie, the first generative interactive environment trained in an unsupervised manner from unlabelled Internet videos. The model can be prompted to generate an endless variety of action-controllable virtual worlds described through text, synthetic images, photographs, and even sketches. At 11B parameters, Genie can be considered a foundation world model. It is comprised of a spatiotemporal video tokenizer, an autoregressive dynamics model, and a simple and scalable latent action model. Genie enables users to act in the generated environments on a frame-by-frame basis despite training without any ground-truth action labels or other domain-specific requirements typically found in the world model literature. Further the resulting learned latent action space facilitates training agents to imitate behaviors from unseen videos, opening the path for training generalist agents of the future.

🧞 Genie: Generative Interactive Environments
A Foundation Model for Playable Worlds
 sites.google.com
sites.google.com
Genie: Generative Interactive Environments
Genie Team
We introduce Genie, a foundation world model trained from Internet videos that can generate an endless variety of playable (action-controllable) worlds from synthetic images, photographs, and even sketches.
We introduce Genie, a foundation world model trained from Internet videos that can generate an endless variety of playable (action-controllable) worlds from synthetic images, photographs, and even sketches.

A Foundation Model for Playable Worlds
The last few years have seen an emergence of generative AI, with models capable of generating novel and creative content via language, images, and even videos. Today, we introduce a new paradigm for generative AI, generative interactive environments (Genie), whereby interactive, playable environments can be generated from a single image prompt.Genie can be prompted with images it has never seen before, such as real world photographs or sketches, enabling people to interact with their imagined virtual worlds-–essentially acting as a foundation world model. This is possible despite training without any action labels. Instead, Genie is trained from a large dataset of publicly available Internet videos. We focus on videos of 2D platformer games and robotics but our method is general and should work for any type of domain, and is scalable to ever larger Internet datasets.
Learning to control without action labels
What makes Genie unique is its ability to learn fine-grained controls exclusively from Internet videos. This is a challenge because Internet videos do not typically have labels regarding which action is being performed, or even which part of the image should be controlled. Remarkably, Genie learns not only which parts of an observation are generally controllable, but also infers diverse latent actions that are consistent across the generated environments. Note here how the same latent actions yield similar behaviors across different prompt images.






latent actions: 5, 6, 2, 2, 6, 2, 5, 7, 7, 7
Enabling a new generation of creators
Amazingly, it only takes a single image to create an entire new interactive environment. This opens the door to a variety of new ways to generate and step into virtual worlds, for instance, we can take a state-of-the-art text-to-image generation model and use it to produce starting frames that we can then bring to life with Genie. Here we generate images with Imagen2 and bring them to life with Genie.




But it doesn’t stop there, we can even step into human designed creations such as sketches!

Last edited:
JUST IN: Mistral announces Mistral Large, a new flagship model.
This is the world's second-ranked model generally available through an API (behind GPT-4).
Here is all you need to know:
• 32K tokens context window
• has native multilingual capacities
• strong abilities in reasoning, knowledge, maths, and coding benchmarks
• function calling and JSON format natively supported
• available through Microsoft Azure
• a low-latency model called Mistral Small was also released

- Dec 6, 2023
- 6 min read
Easy Installation of Kohya GUI: Your Pathway to Fine-Tuning Stable Diffusion Models

Kohya GUI: Your Pathway to Fine-Tuning Stable Diffusion Models
Do you want to fine-tune Stable Diffusion models that can generate high-quality text and image pairs? Do you want to do it efficiently and effectively without requiring excessive computational resources and memory? If yes, then you need Kohya GUI, a convenient and powerful interface for LoRA, Dreambooth and Textual Inversion training.Low-Rank Adaptation
- LoRA is an innovative technique that leverages the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture. This reduces the number of trainable parameters and the GPU memory requirement for fine-tuning, while achieving comparable or better performance than full fine-tuning. LoRA also does not introduce any additional inference latency, unlike some other techniques such as adapters.
DreamBooth Training
- DreamBooth is a technique that fine-tunes diffusion models by injecting a custom subject to the model. For example, you can use DreamBooth to put your cat, your car, or your style into a text-to-image model. You only need a few images of your subject to train DreamBooth, and then you can use natural language sentences to guide the image generation. DreamBooth preserves the meaning of the original class, such as animal or vehicle, while adding your personal touch to the model.
Textual Inversion Embedding
- Textual Inversion is a technique that fine-tunes the text embedding part of a diffusion model by adding a new word to represent a concept. For example, you can use Textual Inversion to add a word like “sunset” or “rainbow” to a model that does not have them. You only need a few text and image pairs of your concept to train Textual Inversion, and then you can use the new word in natural language sentences to generate images. Textual Inversion does not affect the rest of the model, so you can still use the existing words and classes.
Kohya_SS GUI
Kohya GUI is a web-based application that enables you to easily integrate LoRA with PyTorch models, such as those from Hugging Face. You can select any model that can generate text and image pairs, such as stabilityai/stable-diffusion-xl-base-1.0, and fine-tune it on your own dataset. You can also monitor the training progress and visualize the generated samples in real-time.How to Install Kohya GUI for LoRa Training
In this tutorial, I will show you how to install Kohya GUI and use it to fine-tune stable diffusion models with DreamBooth, LoRA and Textual Inversion. I will also provide you with links for all my training workflows and provide you with you with beginner to advance tips and tricks to improve your results and avoid common pitfalls. By the end of this tutorial, you will have installed the Kohya_ss GUI and will be ready to start training your own Stable Diffusion models.Table of Contents:
- Prerequisites for Kohya GUI Installation
- Clone the Kohya GUI Repository
- Install Kohya GUI
- Increase Training Speed: Install CUDNN 8.6
- Updating Kohya_ss GUI
- Launch Kohya GUI
Prerequisites for Kohya GUI Installation
Before you start, you need to install the necessary packages for LoRa training. This tutorial requires you to have three packages installed on your system: Microsoft Visual C++ Redistributable, Python 3.10.9, and Git for windows. You can find a detailed guide on how to install them [here].Clone the Kohya GUI Repository

Clone repository using GitHub Desktop
After installing the necessary packages for LoRa training, you can copy the Kohya GitHub repository to your preferred drive using GitHub Desktop. I recommend creating a dedicated folder for Kohya LoRa training in your chosen location.
Kohya GUI Repository [https://github.com/bmaltais/kohya_ss]
- Click on File > Clone repository
- Go to URL tab
- Copy and paste the Kohya GitHub Repository in the first line.
- Choose your Local path for Installation
- Click on Clone.
Ted Xiao
@xiao_ted
I can’t emphasize enough how mind-blowing extremely long token context windows are. For both AI researchers and practitioners, massive context windows will have transformative long-term impact, beyond one or two flashy news cycles.

“More is different”: Just as we saw emergent capabilities when scaling model size, compute, and datasets, I think we’re going to see a similar revolution for in-context learning. The capability shifts we’ll see going from 8k to 32k to 128k to 10M (!!) token contexts and beyond are not just going to be simple X% quantitative improvements, but instead qualitative phase shifts which unlock new abilities altogether and result in rethinking how we approach foundation model reasoning.
Great fundamental research on the relationship between in-context learning (ICL) and in-weight learning is now more relevant than ever, and needs to be extended given that we now operate in an era where the "X-axis" of context length has increased by three orders of magnitude. I highly recommend @scychan_brains 's pioneering work in this area, such as https://arxiv.org/pdf/2205.05055.pdf and https://arxiv.org/pdf/2210.05675.pdf. In fact, there are already data points which suggest our understanding of ICL scaling laws still contains large gaps
 (see )
(see )Also exciting is the connection of long-context ICL to alignment and post-training! I'm curious to see how 10M+ contexts disrupt the ongoing debate about whether foundation models truly learn new capabilities and skills during finetuning/RLHF or whether they purely learn stylistic knowledge (the "Superficial Alignment Hypothesis", https://arxiv.org/pdf/2305.11206.pdf and Re-Align |). The Gemini 1.5 technical report brings new evidence to this discussion as well, showing that an entire new language can be learned completely in context. I'm excited to see better empirical understanding of how foundation models can effectively leverage large-context ICL both during inference but also for "learning to learn" during training
And finally, perhaps the most important point: huge context lengths will have a lasting impact because their applications are so broad. There is no part of modern foundation model research that is not changed profoundly in some capacity by huge contexts! From theoretical underpinnings (how we design pre-training and post-training objectives) to system design (how we scale up long-contexts during training and serving) to application domains (such as robotics), massive context ICL is going to have significant impact and move the needle across the board.
Meta presents MobileLLM
Optimizing Sub-billion Parameter Language Models for On-Device Use Cases
paper addresses the growing need for efficient large language models (LLMs) on mobile devices, driven by increasing cloud costs and latency concerns. We focus on designing top-quality LLMs with fewer than a billion parameters, a practical choice for mobile deployment. Contrary to prevailing belief emphasizing the pivotal role of data and parameter quantity in determining model quality, our investigation underscores the significance of model architecture for sub-billion scale LLMs. Leveraging deep and thin architectures, coupled with embedding sharing and grouped-query attention mechanisms, we establish a strong baseline network denoted as MobileLLM, which attains a remarkable 2.7%/4.3% accuracy boost over preceding 125M/350M state-of-the-art models. Additionally, we propose an immediate block-wise weight sharing approach with no increase in model size and only marginal latency overhead. The resultant models, denoted as MobileLLM-LS, demonstrate a further accuracy enhancement of 0.7%/0.8% than MobileLLM 125M/350M. Moreover, MobileLLM model family shows significant improvements compared to previous sub-billion models on chat benchmarks, and demonstrates close correctness to LLaMA-v2 7B in API calling tasks, highlighting the capability of small models for common on-device use cases.

Paper page - MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases
Join the discussion on this paper page
huggingface.co
Computer Science > Computation and Language
[Submitted on 19 Feb 2024]Same Task, More Tokens: the Impact of Input Length on the Reasoning Performance of Large Language Models
Mosh Levy, Alon Jacoby, Yoav GoldbergThis paper explores the impact of extending input lengths on the capabilities of Large Language Models (LLMs). Despite LLMs advancements in recent times, their performance consistency across different input lengths is not well understood. We investigate this aspect by introducing a novel QA reasoning framework, specifically designed to assess the impact of input length. We isolate the effect of input length using multiple versions of the same sample, each being extended with padding of different lengths, types and locations. Our findings show a notable degradation in LLMs' reasoning performance at much shorter input lengths than their technical maximum. We show that the degradation trend appears in every version of our dataset, although at different intensities. Additionally, our study reveals that traditional perplexity metrics do not correlate with performance of LLMs' in long input reasoning tasks. We analyse our results and identify failure modes that can serve as useful guides for future research, potentially informing strategies to address the limitations observed in LLMs.
| Subjects: | Computation and Language (cs.CL); Artificial Intelligence (cs.AI) |
| Cite as: | arXiv:2402.14848 [cs.CL] |
| (or arXiv:2402.14848v1 [cs.CL] for this version) |
Submission history
From: Mosh Levy [view email][v1] Mon, 19 Feb 2024 16:04:53 UTC (938 KB)
/cdn.vox-cdn.com/uploads/chorus_asset/file/24347780/STK095_Microsoft_04.jpg)
Microsoft partners with Mistral in second AI deal beyond OpenAI
Microsoft makes another AI investment.
Microsoft partners with Mistral in second AI deal beyond OpenAI
Mistral has a Microsoft investment to help commercialize its new AI language models.
By Tom Warren, a senior editor covering Microsoft, PC gaming, console, and tech. He founded WinRumors, a site dedicated to Microsoft news, before joining The Verge in 2012.
Feb 26, 2024, 10:23 AM EST
5 Comments
5 New
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/24347780/STK095_Microsoft_04.jpg)
Illustration: The Verge
Microsoft has announced a new multiyear partnership with Mistral, a French AI startup that’s valued at €2 billion (about $2.1 billion). The Financial Times reports that the partnership will include Microsoft taking a minor stake in the 10-month-old AI company, just a little over a year after Microsoft invested more than $10 billion into its OpenAI partnership.
The deal will see Mistral’s open and commercial language models available on Microsoft’s Azure AI platform, the second company to offer a commercial language model on Azure after OpenAI. Much like the OpenAI partnership, Microsoft’s partnership with Mistral will also be focused on the development and deployment of next-generation large language models.
Mistral is announcing a new AI model today, called Mistral Large. It’s designed to more closely compete with OpenAI’s GPT-4 model. Unlike some of Mistral’s previous models, it won’t be open source. “Mistral Large achieves strong results on commonly used benchmarks, making it the world’s second-ranked model generally available through an API (next to GPT-4),” says the Mistral AI team.
Mistral also has a new AI chatbot
Mistral Large is available on Mistral’s own infrastructure, hosted in Europe, or through Azure AI Studio and Azure Machine Learning. Mistral Small will also be available today, offering improved latency over Mistral’s 8x7B model. Mistral is also releasing a new conversational chatbot, Le Chat, that’s based on various models from Mistral AI.
Mistral’s models have typically been open source, but the partnership with Microsoft means the French AI company can now explore more commercial opportunities. Neither Microsoft nor Mistral are disclosing details of the investment, though.
Microsoft’s investment comes months after a rocky period for its main AI partner, OpenAI. On November 17th, OpenAI’s board abruptly announced that co-founder and CEO Sam Altman was fired, but Altman returned as OpenAI CEO just days later at the end of November. During all the turmoil, Microsoft managed to get a nonvoting observer seat on the nonprofit board that controls OpenAI, providing the software giant with more visibility into OpenAI’s inner workings but with no voting power on big decisions.