Last edited:

You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?Prompt engineering
This guide shares strategies and tactics for getting better results from large language models (sometimes referred to as GPT models) like GPT-4. The methods described here can sometimes be deployed in combination for greater effect. We encourage experimentation to find the methods that work best for you.
Some of the examples demonstrated here currently work only with our most capable model,
Code:
gpt-4. In general, if you find that a model fails at a task and a more capable model is available, it's often worth trying again with the more capable model.
You can also explore example prompts which showcase what our models are capable of:
https://platform.openai.com/examples
Prompt examples
Explore prompt examples to learn what GPT models can do
Six strategies for getting better results
Write clear instructions
These models can’t read your mind. If outputs are too long, ask for brief replies. If outputs are too simple, ask for expert-level writing. If you dislike the format, demonstrate the format you’d like to see. The less the model has to guess at what you want, the more likely you’ll get it.
Tactics:
Include details in your query to get more relevant answers
Ask the model to adopt a persona
Use delimiters to clearly indicate distinct parts of the input
Specify the steps required to complete a task
Provide examples
Specify the desired length of the output
Provide reference text
Language models can confidently invent fake answers, especially when asked about esoteric topics or for citations and URLs. In the same way that a sheet of notes can help a student do better on a test, providing reference text to these models can help in answering with fewer fabrications.
Tactics:
Instruct the model to answer using a reference text
Instruct the model to answer with citations from a reference text
Split complex tasks into simpler subtasks
Just as it is good practice in software engineering to decompose a complex system into a set of modular components, the same is true of tasks submitted to a language model. Complex tasks tend to have higher error rates than simpler tasks. Furthermore, complex tasks can often be re-defined as a workflow of simpler tasks in which the outputs of earlier tasks are used to construct the inputs to later tasks.
Tactics:
Use intent classification to identify the most relevant instructions for a user query
For dialogue applications that require very long conversations, summarize or filter previous dialogue
Summarize long documents piecewise and construct a full summary recursively
Give the model time to "think"
If asked to multiply 17 by 28, you might not know it instantly, but can still work it out with time. Similarly, models make more reasoning errors when trying to answer right away, rather than taking time to work out an answer. Asking for a "chain of thought" before an answer can help the model reason its way toward correct answers more reliably.
Tactics:
Instruct the model to work out its own solution before rushing to a conclusion
Use inner monologue or a sequence of queries to hide the model's reasoning process
Ask the model if it missed anything on previous passes
Use external tools
Compensate for the weaknesses of the model by feeding it the outputs of other tools. For example, a text retrieval system (sometimes called RAG or retrieval augmented generation) can tell the model about relevant documents. A code execution engine like OpenAI's Code Interpreter can help the model do math and run code. If a task can be done more reliably or efficiently by a tool rather than by a language model, offload it to get the best of both.
Tactics:
Use embeddings-based search to implement efficient knowledge retrieval
Use code execution to perform more accurate calculations or call external APIs
Give the model access to specific functions
Test changes systematically
Improving performance is easier if you can measure it. In some cases a modification to a prompt will achieve better performance on a few isolated examples but lead to worse overall performance on a more representative set of examples. Therefore to be sure that a change is net positive to performance it may be necessary to define a comprehensive test suite (also known an as an "eval").
Tactic:
Evaluate model outputs with reference to gold-standard answers
Tactics
Each of the strategies listed above can be instantiated with specific tactics. These tactics are meant to provide ideas for things to try. They are by no means fully comprehensive, and you should feel free to try creative ideas not represented here.
Strategy: Write clear instructions
Tactic: Include details in your query to get more relevant answers
In order to get a highly relevant response, make sure that requests provide any important details or context. Otherwise you are leaving it up to the model to guess what you mean.
CONTINUE READING ON SITE....

VERSES Identifies New Path to AGI and Extends Invitation to OpenAI for Collaboration via Open Letter | Jacques Ludik
Exciting Announcement by VERSES! Gabriel René, Dan Mapes, Jason Fox, Philippe S. "VERSES recently achieved a significant internal breakthrough in Active Inference that we believe addresses the tractability problem of probabilistic AI. This advancement enables the design and deployment of...
 www.linkedin.com
www.linkedin.com
VERSES Identifies New Path to AGI and Extends Invitation to OpenAI for Collaboration via Open Letter | Jacques Ludik
Exciting Announcement by VERSES! Gabriel René, Dan Mapes, Jason Fox, Philippe S. "VERSES recently achieved a significant internal breakthrough in Active Inference that we believe addresses the tractability problem of probabilistic AI. This advancement enables the design and deployment of...
Is this real or marketing hype?

AI cannot be patent 'inventor', UK Supreme Court rules in landmark case
ReutersDecember 20, 20239:31 AM ESTUpdated an hour ago

Words reading "Artificial intelligence AI", miniature of robot and toy hand are pictured in this illustration taken December 14, 2023. REUTERS/Dado Ruvic/Illustration Acquire Licensing Rights
LONDON, Dec 20 (Reuters) - A U.S. computer scientist on Wednesday lost his bid to register patents over inventions created by his artificial intelligence system in a landmark case in Britain about whether AI can own patent rights.
Stephen Thaler wanted to be granted two patents in the UK for inventions he says were devised by his "creativity machine" called DABUS.
His attempt to register the patents was refused by the UK's Intellectual Property Office (IPO) on the grounds that the inventor must be a human or a company, rather than a machine.
Thaler appealed to the UK's Supreme Court, which on Wednesday unanimously rejected his appeal as under UK patent law "an inventor must be a natural person".
Judge David Kitchin said in the court's written ruling that the case was "not concerned with the broader question whether technical advances generated by machines acting autonomously and powered by AI should be patentable".
Thaler's lawyers said in a statement that the ruling "establishes that UK patent law is currently wholly unsuitable for protecting inventions generated autonomously by AI machines and as a consequence wholly inadequate in supporting any industry that relies on AI in the development of new technologies".
'LEGITIMATE QUESTIONS'
A spokesperson for the IPO welcomed the decision "and the clarification it gives as to the law as it stands in relation to the patenting of creations of artificial intelligence machines".They added that there are "legitimate questions as to how the patent system and indeed intellectual property more broadly should handle such creations" and the government will keep this area of law under review.
Thaler earlier this year lost a similar bid in the United States, where the Supreme Court declined to hear a challenge to the U.S. Patent and Trademark Office's refusal to issue patents for inventions created by his AI system.
Giles Parsons, a partner at law firm Browne Jacobson, who was not involved in the case, said the UK Supreme Court's ruling was unsurprising.
"This decision will not, at the moment, have a significant effect on the patent system," he said. "That's because, for the time being, AI is a tool, not an agent.
"I do expect that will change in the medium term, but we can deal with that problem as it arises."
Rajvinder Jagdev, an intellectual property partner at Powell Gilbert, said the ruling followed similar decisions by courts in Europe, Australia and the U.S. and has "given certainty that inventors must be a natural person."
But he added: "The judgment does not preclude a person using an AI to devise an invention – in such a scenario, it would be possible to apply for a patent provided that person is identified as the inventor."
In a separate case last month, London's High Court ruled that artificial neural networks can attract patent protection under UK law.
Reporting by Sam Tobin; editing by Kylie MacLellan, Jason Neely and Louise Heavens
Large AI Dataset Has Over 1,000 Child Abuse Images, Researchers Find
The dataset has been used to build popular AI image generators, including Stable Diffusion.
By Davey Alba and Rachel Metz
December 20, 2023 at 7:00 AM EST
A massive public dataset used to build popular artificial intelligence image generators contains at least 1,008 instances of child sexual abuse material, a new report from the Stanford Internet Observatory found.
LAION-5B, which contains more than 5 billion images and related captions from the internet, may also include thousands of additional pieces of suspected child sexual abuse material, or CSAM, according to the report. The inclusion of CSAM in the dataset could enable AI products built on this data — including image generation tools like Stable Diffusion — to create new, and potentially realistic, child abuse content, the report warned.
The rise of increasingly powerful AI tools has raised alarms in part because these services are built with troves of online data — including public datasets such as LAION-5B — that can contain copyrighted or harmful content. AI image generators, in particular, rely on datasets that include pairs of images and text descriptions to determine a wide range of concepts and create pictures in response to prompts from users.
In a statement, a spokesperson for LAION, the Germany-based nonprofit behind the dataset, said the group has a “zero tolerance policy” for illegal content and was temporarily removing LAION datasets from the internet “to ensure they are safe before republishing them.” Prior to releasing its datasets, LAION created and published filters for spotting and removing illegal content from them, the spokesperson said.
Christoph Schuhmann, LAION’s founder, previously told Bloomberg News that he was unaware of any child nudity in the dataset, though he acknowledged he did not review the data in great depth. If notified about such content, he said, he would remove links to it immediately.
A spokesperson for Stability AI, the British AI startup that funded and popularized Stable Diffusion, said the company is committed to preventing the misuse of AI and prohibits the use of its image models for unlawful activity, including attempts to edit or create CSAM. “This report focuses on the LAION-5B dataset as a whole,” the spokesperson said in a statement. “Stability AI models were trained on a filtered subset of that dataset. In addition, we fine-tuned these models to mitigate residual behaviors.”
LAION-5B, or subsets of it, have been used to build multiple versions of Stable Diffusion. A more recent version of the software, Stable Diffusion 2.0, was trained on data that substantially filtered out “unsafe” materials in the dataset, making it much more difficult for users to generate explicit images. But Stable Diffusion 1.5 does generate sexually explicit content and is still in use in some corners of the internet. The spokesperson said Stable Diffusion 1.5 was not released by Stability AI, but by Runway, an AI video startup that helped create the original version of Stable Diffusion. Runway said it was released in collaboration with Stability AI.
“We have implemented filters to intercept unsafe prompts or unsafe outputs when users interact with models on our platform,” the Stability AI spokesperson added. “We have also invested in content labeling features to help identify images generated on our platform. These layers of mitigation make it harder for bad actors to misuse AI.”
LAION-5B was released in 2022 and relies on raw HTML code collected by a California nonprofit to locate images around the web and associate them with descriptive text. For months, rumors that the dataset contained illegal images have circulated in discussion forums and on social media.
“As far as we know, this is the first attempt to actually quantify and validate concerns,” David Thiel, chief technologist of the Stanford Internet Observatory, said in an interview with Bloomberg News.
For their report, Stanford Internet Observatory researchers detected the CSAM material by looking for different kinds of hashes, or digital fingerprints, of such images. The researchers then validated them using APIs dedicated to finding and removing known images of child exploitation, as well as by searching for similar images in the dataset.
Much of the suspected CSAM content that the Stanford Internet Observatory found was validated by third parties like Canadian Centre for Child Protection and through a tool called PhotoDNA, developed by Microsoft Corp., according to the report. Given that the Stanford Internet Observatory researchers could only work with a limited portion of high-risk content, additional abusive content likely exists in the dataset, the report said.
While the amount of CSAM present in the dataset doesn’t indicate that the illicit material “drastically” influences the images churned out by AI tools, Thiel said it does likely still have an impact. “These models are really good at being able to learn concepts from a small number of images,” he said. “And we know that some of these images are repeated, potentially dozens of times in the dataset.”
Stanford Internet Observatory’s work previously found that generative AI image models can produce CSAM, but that work assumed the AI systems were able to do so by combining two “concepts,” such as children and sexual activity. Thiel said the new research suggests these models might generate such illicit images because of some of the underlying data on which they were built. The report recommends that models based on Stable Diffusion 1.5 “should be deprecated and distribution ceased wherever feasible.”
— With assistance from Marissa Newman and Aggi Cantrill[/SIZE]

Largest Dataset Powering AI Images Removed After Discovery of Child Sexual Abuse Material
The model is a massive part of the AI-ecosystem, used by Google and Stable Diffusion. The removal follows discoveries made by Stanford researchers, who found thousands instances of suspected child sexual abuse material in the dataset.
 www.404media.co
www.404media.co
Largest Dataset Powering AI Images Removed After Discovery of Child Sexual Abuse Material
SAMANTHA COLE
·DEC 20, 2023 AT 7:00 AM
The model is a massive part of the AI-ecosystem, used by Google and Stable Diffusion. The removal follows discoveries made by Stanford researchers, who found thousands instances of suspected child sexual abuse material in the dataset.[/SIZE]

COLLAGE BY 404 MEDIA / IMAGES VIA PEXELS
Become a paid subscriber for unlimited, ad-free articles and access to bonus content. This site is funded by subscribers and you will be directly powering our journalism.
Become a paid subscriber for unlimited, ad-free articles and access to bonus content. This site is funded by subscribers and you will be directly powering our journalism.
This piece is published with support from The Capitol Forum.
The LAION-5B machine learning dataset used by Google, Stable Diffusion, and other major AI products has been removed by the organization that created it after a Stanford study found that it contained 3,226 suspected instances of child sexual abuse material, 1,008 of which were externally validated.
LAION told 404 Media on Tuesday that out of “an abundance of caution,” it was taking down its datasets temporarily “to ensure they are safe before republishing them."
According to a new study by the Stanford Internet Observatory shared with 404 Media ahead of publication, the researchers found the suspected instances of CSAM through a combination of perceptual and cryptographic hash-based detection and analysis of the images themselves.
“We find that having possession of a LAION‐5B dataset populated even in late 2023 implies the possession of thousands of illegal images—not including all of the intimate imagery published and gathered non‐consensually, the legality of which is more variable by jurisdiction,” the paper says. “While the amount of CSAM present does not necessarily indicate that the presence of CSAM drastically influences the output of the model above and beyond the model’s ability to combine the concepts of sexual activity and children, it likely does still exert influence. The presence of repeated identical instances of CSAM is also problematic, particularly due to its reinforcement of images of specific victims.”
The finding highlights the danger of largely indiscriminate scraping of the internet for the purposes of generative artificial intelligence.
Large-scale Artificial Intelligence Open Network, or LAION, is a non-profit organization that creates open-source tools for machine learning. LAION-5B is one of its biggest and most popular products. It is made up of more than five billion links to images scraped from the open web, including user-generated social media platforms, and is used to train the most popular AI generation models currently on the market. Stable Diffusion, for example, uses LAION-5B, and Stability AI funded its development.
“If you have downloaded that full dataset for whatever purpose, for training a model for research purposes, then yes, you absolutely have CSAM, unless you took some extraordinary measures to stop it,” David Thiel, lead author of the study and Chief Technologist at the Stanford Internet Observatory told 404 Media.
Public chats from LAION leadership in the organization’s official Discord server show that they were aware of the possibility of CSAM being scraped into their datasets as far back as 2021.
“I guess distributing a link to an image such as child porn can be deemed illegal,” LAION lead engineer Richard Vencu wrote in response to a researcher asking how LAION handles potential illegal data that might be included in the dataset. “We tried to eliminate such things but there’s no guarantee all of them are out.”
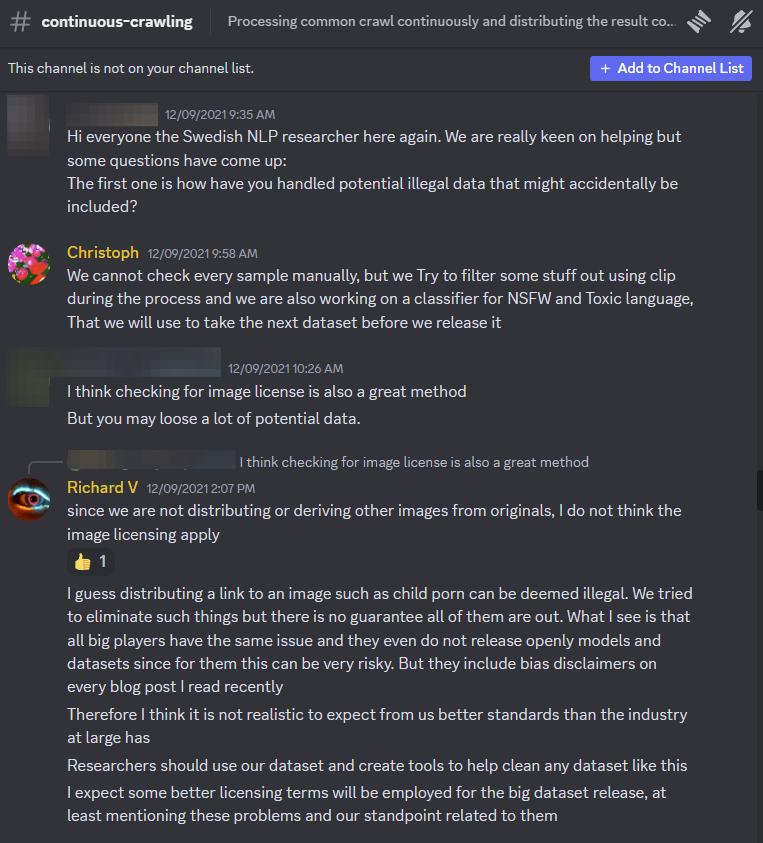
SCREENSHOT VIA THE LAION DISCORD
Most institutions in the US, including Thiel’s team, aren’t legally allowed to view CSAM in order to verify it themselves. To do CSAM research, experts often rely on perceptual hashing, which extracts a unique digital signature, or fingerprint, from an image or video. PhotoDNA is a technology that creates unique hashes for images of child exploitation in order to find those images elsewhere on the web and get them removed or pursue abusers or proliferators.
“With the goal of quantifying the degree to which CSAM is present in the training dataset as well as eliminating it from both LAION‐5B and derivative datasets, we use various complementary techniques to identify potential CSAM in the dataset: perceptual hash‐based detection, cryptographic hash‐based detection, and nearest‐neighbors analysis leveraging the image embeddings in the dataset itself,” the paper says. Through this process, they identified at least 2,000 dataset entries of suspected CSAM, and confirmed those entries with third parties.
To do their research, Thiel said that he focused on URLs identified by LAION’s safety classifier as “not safe for work” and sent those URLs to PhotoDNA. Hash matches indicate definite, known CSAM, and were sent to the Project Arachnid Shield API and validated by Canadian Centre for Child Protection, which is able to view, verify, and report those images to the authorities. Once those images were verified, they could also find “nearest neighbor” matches within the dataset, where related images of victims were clustered together.
LAION could have used a method similar to this before releasing the world’s largest AI training dataset, Thiel said, but it didn’t. “[LAION] did initially use CLIP to try and filter some things out, but it does not appear that they did that in consultation with any child safety experts originally. It was good that they tried. But the mechanisms they used were just not super impressive,” Thiel said. “They made an attempt that was not nearly enough, and it is not how I would have done it if I were trying to design a safe system.”
A spokesperson for LAION told 404 Media in a statement about the Stanford paper:
"LAION is a non-profit organization that provides datasets, tools and models for the advancement of machine learning research. We are committed to open public education and the environmentally safe use of resources through the reuse of existing datasets and models. LAION datasets (more than 5.85 billion entries) are sourced from the freely available Common Crawl web index and offer only links to content on the public web, with no images. We developed and published our own rigorous filters to detect and remove illegal content from LAION datasets before releasing them. We collaborate with universities, researchers and NGOs to improve these filters and are currently working with the Internet Watch Foundation (IWF) to identify and remove content suspected of violating laws. We invite Stanford researchers to join LAION to improve our datasets and to develop efficient filters for detecting harmful content. LAION has a zero tolerance policy for illegal content and in an abundance of caution, we are temporarily taking down the LAION datasets to ensure they are safe before republishing them."
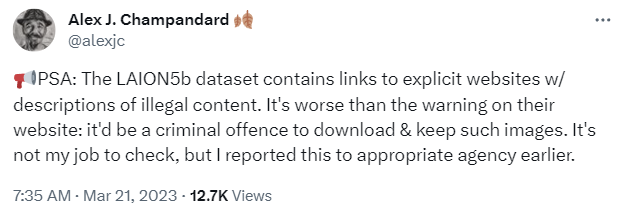
This study follows a June paper by Stanford that examined the landscape of visual generative models that could be used to create CSAM. Thiel told me he continued to pursue the topic after a tip from AI researcher Alex Champandard, who found a URL of an image in LAION-5B on Hugging Face that was captioned with a phrase in Spanish that appeared to describe child exploitation material. LAION-5B is available for download from Hugging Face as an open-source tool.
Champandard told me he noticed a report to Hugging Face on LAION-5B in August 2022, flagging “an example that describes something related to pedophilia.” One of the engineers who worked on LAION-5B responded in March 2023, saying the link was dead but they’d removed it anyway because the caption was inappropriate.
“It took 7 months for that report to get dealt with by Hugging Face or LAION — which I found to be highly questionable,” Champandard said.
Following Champandard’s tweets, Hugging Face’s chief ethics scientist Margaret Mitchell wrote on Mastodon: “I just wanted to pop in to say that there has been a lot of time and energy spent on trying to find CSAM, and none has been found. Some people at HF are being attacked as if pedophiles but it's just...inappropriate cruelty.”
I asked Hugging Face whether, in light of this study and before LAION removed the datasets themselves, it would take action against datasts that were found to have links to CSAM. A spokesperson for the company said, "Yes."
"Datasets cannot be seen by Hugging Face staff (nor anyone accessing the Hub) until they are uploaded, and the uploader can decide to make the content public. Once shared, the platform runs content scanning to identify potential issues. Users are responsible for uploading and maintaining content, and staff addresses issues following the Hugging Face platform’s content guidelines, which we continue to adapt. The platform relies on a combination of technical content analysis to validate that the guidelines are indeed followed, community moderation, and reporting features to allow users to raise concerns. We monitor reports and take actions when infringing content is flagged," the Hugging Face spokesperson said. "Critical to this discussion is noting that the LAION-5B dataset contains URLs to external content, not images, which poses additional challenges. We are working with civil society and industry partners to develop good practices to handle these kinds of cross-platform questions."
The Stanford paper says that the material detected during their process is “inherently a significant undercount due to the incompleteness of industry hash sets, attrition of live hosted content, lack of access to the original LAION reference image sets, and the limited accuracy of ‘unsafe’ content classifiers.”
HOW DID THIS HAPPEN?
Child abuse material likely got into LAION because the organization compiled the dataset using tools that scrape the web, and CSAM isn’t relegated to the realm of the “dark web,” but proliferates on the open web and on many mainstream platforms. In 2022, Facebook made more than 21 million reports of CSAM to the National Center for Missing and Exploited Children (NCMEC) tipline, while Instagram made 5 million reports, and Twitter made 98,050.
In the US, electronic service providers [ESP] are required by law to report “apparent child pornography” to NCMEC’s CyberTipline when they become aware of them, but “there are no legal requirements for proactive efforts to detect this content or what information an ESP must include in a CyberTipline report,” according to NCMEC. A dataset, however, is different from a website, even if it is composed of data from a huge number of websites.
“Because it's the internet, there are going to be datasets that have child porn. Twitter's got it. You know, Facebook has it. It's all sitting there. They don't do a good job of policing for it, even though they claim that they do. And that's now going to be used to train these models,” Marcus Rogers, Assistant Dean for Cybersecurity Initiatives at Purdue University, told 404 Media. Organizations building datasets, however, may be intentionally ignoring the possibility that CSAM could pollute their models, he said. “Companies just don't want to know. Some of it is just, even if they wanted to know they literally have lost control of everything.”
“I think the reason that they probably ignore it is because they don't have a solution,” Bryce Westlake, an associate professor in the Department of Justice Studies and a faculty member of the department's Forensic Science program, told 404 Media. “So they don't want to bring attention to it. Because if they bring attention to it, then something's going to have to be done about that.” The interventions dataset creators could make would be labor intensive, he said, and even with those efforts in place they might not rid the sets of all of it, he said. “It's impossible for them to get rid of all of it. The only answer that society will accept is that you have 0% in there, and it's impossible to do. They're in a no win situation, so they think it's better that people just don't know."
HOW CSAM IN DATASETS AFFECTS REAL PEOPLE
In a dataset of five billion entries, 3,226 might seem like a drop in an ocean of data. But there are several ways CSAM scraped into LAION’s datasets could make things worse for real-life victims.
Dan Sexton, chief technology officer at the UK-based Internet Watch Foundation, told me that the goal for internet safety groups is to prevent more people from viewing or spreading abusive content and to get it offline entirely. We spoke months before Stanford’s paper came out, when we didn’t know for sure that child abuse material was being scraped into large datasets. “[Victims] knowing that their content is in a dataset that's allowing a machine to create other images—which have learned from their abuse—that's not something I think anyone would have expected to happen, but it's clearly not a welcome development. For any child that's been abused and their imagery circulated, excluding it anywhere on the internet, including datasets, is massive,” he said. [/SIZE]
Lloyd Richardson, director of information technology at the Canadian Centre for Child Protection (C3P), told me that he imagines past victims of child sexual abuse would be “absolutely disgusted, no doubt, but probably not necessarily surprised” to learn their images are linked in a dataset like LAION-5B. “They've known for so long that they've had to deal with their images or images and videos circulating on the internet. Some reasonable technical things that could be done for the last well-over a decade, they just haven't been done right,” he said.
“I don't think anyone wants to create a tool that creates images of children being sexually abused, even if it's accidental,” Sexton said. “AI is all about having good data, and if you put bad data in, you're going to get bad data out. Of course, this is bad data. You don't want to generate or scrape images of child sexual abuse.”
Until now, it’s been theorized that AI models that are capable of creating child sexual abuse imagery were combining concepts of explicit adult material and non-explicit images of children to create AI-generated CSAM. According to Stanford’s report, real abuse imagery is helping train models.
Artificially generated CSAM is on the rise, and it has the potential to jam up hotlines and deter resources from reporting agencies that work with law enforcement to find perpetrators and get it taken offline. The Internet Watch Foundation recently released a report saying that AI CSAM is “visually indistinguishable from real CSAM,” even to trained analysts. Earlier this month, a 404 Media investigation found people using popular image generation platform Civitai were creating what “could be considered child pornography.” And in May, the National Center for Missing and Exploited Children, a victim advocacy organization which runs a hotline for reporting CSAM, said it was preparing for a “flood” of artificially generated content.
Richardson told me that actual CSAM training models could mean more realistic abusive deepfakes of victims. “You could have an offender download Stable Diffusion, create a LoRA [Low-Rank Adaptation, a more narrowly-tuned deep learning model] for a specific victim, and start generating new imagery on this victim,” he said. Even if the victim’s abuse was long in the past and now they’re an adult, “now they're having new material created of them based on the existing CSAM that was out there,” he said. “So that's hugely problematic.”
“There's no reason that images of children being sexually abused should ever be in those datasets, both to be sure the models themselves don’t create undesirable results, but also for those victims to make sure their imagery is not continually and still being used for harmful purposes,” Sexton said.
a16z Funded AI Platform Generated Images That “Could Be Categorized as Child Pornography,” Leaked Documents Show
OctoML, the engine that powers a16z funded Civitai, thought the images could qualify as “child pornography,” but ultimately decided to keep working with the company anyway, internal Slack chats and other material shows.
EMANUEL MAIBERG
“Given what it's used to train, you can't argue that it's just like having a copy of the internet, so you're going to have some stuff on there that's bad or somehow illegal,” Thiel said. “You're operationalizing it by training the models on those things. And given that you have images that will repeat over and over in that dataset that makes the model more likely to not just represent the material, but you'd have the potential for resemblance to occur of actual people that were fed into the data set.”
Child abuse material likely got into LAION because the organization compiled the dataset using tools that scrape the web, and CSAM isn’t relegated to the realm of the “dark web,” but proliferates on the open web and on many mainstream platforms. In 2022, Facebook made more than 21 million reports of CSAM to the National Center for Missing and Exploited Children (NCMEC) tipline, while Instagram made 5 million reports, and Twitter made 98,050.
In the US, electronic service providers [ESP] are required by law to report “apparent child pornography” to NCMEC’s CyberTipline when they become aware of them, but “there are no legal requirements for proactive efforts to detect this content or what information an ESP must include in a CyberTipline report,” according to NCMEC. A dataset, however, is different from a website, even if it is composed of data from a huge number of websites.
“Because it's the internet, there are going to be datasets that have child porn. Twitter's got it. You know, Facebook has it. It's all sitting there. They don't do a good job of policing for it, even though they claim that they do. And that's now going to be used to train these models,” Marcus Rogers, Assistant Dean for Cybersecurity Initiatives at Purdue University, told 404 Media. Organizations building datasets, however, may be intentionally ignoring the possibility that CSAM could pollute their models, he said. “Companies just don't want to know. Some of it is just, even if they wanted to know they literally have lost control of everything.”
“I think the reason that they probably ignore it is because they don't have a solution,” Bryce Westlake, an associate professor in the Department of Justice Studies and a faculty member of the department's Forensic Science program, told 404 Media. “So they don't want to bring attention to it. Because if they bring attention to it, then something's going to have to be done about that.” The interventions dataset creators could make would be labor intensive, he said, and even with those efforts in place they might not rid the sets of all of it, he said. “It's impossible for them to get rid of all of it. The only answer that society will accept is that you have 0% in there, and it's impossible to do. They're in a no win situation, so they think it's better that people just don't know."
HOW CSAM IN DATASETS AFFECTS REAL PEOPLE
In a dataset of five billion entries, 3,226 might seem like a drop in an ocean of data. But there are several ways CSAM scraped into LAION’s datasets could make things worse for real-life victims.
Dan Sexton, chief technology officer at the UK-based Internet Watch Foundation, told me that the goal for internet safety groups is to prevent more people from viewing or spreading abusive content and to get it offline entirely. We spoke months before Stanford’s paper came out, when we didn’t know for sure that child abuse material was being scraped into large datasets. “[Victims] knowing that their content is in a dataset that's allowing a machine to create other images—which have learned from their abuse—that's not something I think anyone would have expected to happen, but it's clearly not a welcome development. For any child that's been abused and their imagery circulated, excluding it anywhere on the internet, including datasets, is massive,” he said. [/SIZE]
"There's no reason that images of children being sexually abused should ever be in those datasets"
Lloyd Richardson, director of information technology at the Canadian Centre for Child Protection (C3P), told me that he imagines past victims of child sexual abuse would be “absolutely disgusted, no doubt, but probably not necessarily surprised” to learn their images are linked in a dataset like LAION-5B. “They've known for so long that they've had to deal with their images or images and videos circulating on the internet. Some reasonable technical things that could be done for the last well-over a decade, they just haven't been done right,” he said.
“I don't think anyone wants to create a tool that creates images of children being sexually abused, even if it's accidental,” Sexton said. “AI is all about having good data, and if you put bad data in, you're going to get bad data out. Of course, this is bad data. You don't want to generate or scrape images of child sexual abuse.”
Until now, it’s been theorized that AI models that are capable of creating child sexual abuse imagery were combining concepts of explicit adult material and non-explicit images of children to create AI-generated CSAM. According to Stanford’s report, real abuse imagery is helping train models.
Artificially generated CSAM is on the rise, and it has the potential to jam up hotlines and deter resources from reporting agencies that work with law enforcement to find perpetrators and get it taken offline. The Internet Watch Foundation recently released a report saying that AI CSAM is “visually indistinguishable from real CSAM,” even to trained analysts. Earlier this month, a 404 Media investigation found people using popular image generation platform Civitai were creating what “could be considered child pornography.” And in May, the National Center for Missing and Exploited Children, a victim advocacy organization which runs a hotline for reporting CSAM, said it was preparing for a “flood” of artificially generated content.
Richardson told me that actual CSAM training models could mean more realistic abusive deepfakes of victims. “You could have an offender download Stable Diffusion, create a LoRA [Low-Rank Adaptation, a more narrowly-tuned deep learning model] for a specific victim, and start generating new imagery on this victim,” he said. Even if the victim’s abuse was long in the past and now they’re an adult, “now they're having new material created of them based on the existing CSAM that was out there,” he said. “So that's hugely problematic.”
“There's no reason that images of children being sexually abused should ever be in those datasets, both to be sure the models themselves don’t create undesirable results, but also for those victims to make sure their imagery is not continually and still being used for harmful purposes,” Sexton said.
a16z Funded AI Platform Generated Images That “Could Be Categorized as Child Pornography,” Leaked Documents Show
OctoML, the engine that powers a16z funded Civitai, thought the images could qualify as “child pornography,” but ultimately decided to keep working with the company anyway, internal Slack chats and other material shows.
EMANUEL MAIBERG
“Given what it's used to train, you can't argue that it's just like having a copy of the internet, so you're going to have some stuff on there that's bad or somehow illegal,” Thiel said. “You're operationalizing it by training the models on those things. And given that you have images that will repeat over and over in that dataset that makes the model more likely to not just represent the material, but you'd have the potential for resemblance to occur of actual people that were fed into the data set.”
WHO'S RESPONSIBLE?
Legally, there is no precedent yet for who’s responsible when a scraping tool gathers illegal imagery. As Vencu noted in his Discord message in 2021, LAION is disseminating links, not actual copies of images. “Since we are not distributing or deriving other images from originals, I do not think the image licensing apply,” he said in Discord to the question about whether illegal material was in the dataset.
Copyright infringement has been a major concern for artists and content creators whose imagery is being used to train AI models. In April, a German stock photographer asked LAION to exclude his photos from its datasets, and LAION responded by invoicing him for $979, claiming he filed an unjustified copyright claim. Earlier this year, a group of artists filed a class-action lawsuit against Stability AI, DeviantArt, and Midjourney for their use of image generator Stable Diffusion, which uses LAION’s datasets. And Getty Images recently sued Stability AI, claiming that the company copied more than 12 million images without permission.
“We have issues with those services, how they were built, what they were built upon, how they respect creator rights or not, and how they actually feed into deepfakes and other things like that,” Getty Images CEO Craig Peters told the Associated Press.
Spreading CSAM is a federal crime, and the US laws about it are extremely strict. It is of course illegal to possess or transmit files, but “undeveloped film, undeveloped videotape, and electronically stored data that can be converted into a visual image of child pornography” are also illegal under federal law. It’s not clear where URLs that link to child exploitation images would land under current laws, or at what point anyone using these datasets could potentially be in legal jeopardy.
Because anti CSAM laws are understandably so strict, researchers have had to figure out new ways of studying its spread without breaking the law themselves. Westlake told me he relies on outsourcing some research to colleagues in Canada, such as the C3P, to verify or clean data, where there are CSAM laws that carve out exceptions for research purposes. Stanford similarly sent its methodology to C3P for verification. The Internet Watch Foundation has a memorandum of understanding granted to them by the Crown Prosecution Service, the principal public criminal prosecuting agency in the UK, to download, view, and hold content for its duties, which enables it to proactively search for abusive content and report it to authorities. In the US, viewing, searching for, or possessing child exploitation material, even if accidentally, is a federal crime. [/SIZE]
Rogers and his colleague Kathryn Seigfried-Spellar at Purdue’s forensics department have a unique situation: They’re deputized, and have law enforcement status granted to them by local law enforcement to do their work. They have a physical space in a secure law enforcement facility, with surveillance cameras, key fobs, a secured network, and 12-factor identification where they must go if they want to do work like cleaning datasets or viewing CSAM for research or investigative purposes.
Even so, they’re incredibly careful about what they collect with scraping tools. Siegfried-Spellar told me she’s working on studying knuckles and hands because they often appear in abuse imagery and are as identifiable as faces, and could scrape images from NSFW Reddit forums where people post images of themselves masturbating, but she doesn’t because of the risk of catching underage imagery in the net.
“Even though you have to be over the age of 18 to use Reddit, I am never going to go and scrape that data and use it, or analyze it for my research, because I can't verify that somebody really is over the age of 18 that posted that,” she said. “There have been conversations about that as well: ‘there's pictures on the internet, why can’t I just scrape and use that for my algorithm training?’ But it's because I need to know the age of the sources.”
WHAT TO DO NOW
Because LAION-5B is open-source, lots of copies are floating around publicly, including on Hugging Face. Removing the dataset from Hugging Face, pulling CSAM links to abusive imagery out of the dataset, and then reuploading it, for example, would essentially create a roadmap for someone determined to view those files by comparing the differences between the two.
Thiel told me that he went into this study thinking the goal might be to get abusive material out of datasets, but now he believes it’s too late.
“Now I'm more of the opinion that [the LAION datasets] kind of just need to be scratched,” he said. “Places should no longer host those datasets for download. Maybe there's an argument for keeping copies of it for research capacity, and then you can go through and take some steps to clean it.”
There is a precedent for this, especially when it comes to children’s data. The Federal Trade Commission has a term for model deletion as damage control: algorithm disgorgement. As an enforcement strategy, the FTC has used algorithm disgorgement in five cases involving tech companions that built models on improperly-obtained data, including a settlement with Amazon in May over charges that Alexa voice recordings violated children’s privacy, and a settlement between the FTC and Department of Justice and a children’s weight loss app that allegedly failed to properly verify parental consent. Both cases invoked the Children’s Online Privacy Protection Act (COPPA).
Child safety and AI are quickly becoming the next major battleground of the internet. In April, Democratic senator dikk Durbin introduced the “STOP CSAM Act,” which would make it a crime for providers to “knowingly host or store” CSAM or “knowingly promote or facilitate” the sexual exploitation of children, create a new federal crime for online services that “knowingly promote or facilitate” child exploitation crimes, and amend Section 230—the law that shields platforms from liability for their users’ actions—to allow for civil lawsuits by victims of child exploitation crimes against online service providers. Privacy advocates including the Electronic Frontier Foundation and the Center for Democracy and Technology oppose the act, warning that it could undermine end-to-end encryption services. The inclusion of “apparent” CSAM widens the net too much, they say, and the terms “promote” and “facilitate” are overly broad. It could also have a chilling effect on free speech overall: “First Amendment-protected content involving sexuality, sexual orientation, or gender identity will likely be targets of frivolous takedown notices,” EFF attorneys and surveillance experts wrote in a blog post.
In September, attorneys general from 50 states called on federal lawmakers to study how AI-driven exploitation can endanger children. “We are engaged in a race against time to protect the children of our country from the dangers of AI,” the prosecutors wrote. “Indeed, the proverbial walls of the city have already been breached. Now is the time to act.”
Thiel said he hadn’t communicated with LAION before the study was released. “We're not intending this as some kind of gotcha for any of the parties involved. But obviously a lot of very important mistakes were made in various parts of this whole pipeline,” he said. “And it's really just not how model training in the future should work at all.”
All of this is a problem that’s not going away, even—or especially—if it’s ignored. “They all have massive problems associated with massive data theft, non consensual, intimate images, Child Sexual Abuse material, you name it, it's in there. I’m kind of perplexed at how it's gone on this long,” Richardson said. “It's not that the technology is necessarily bad... it's not that AI is bad. It's the fact that a bunch of things were blindly stolen, and now we're trying to put all these Band-aids to fix something that really never should have happened in the first place.”
Update 12/20, 8:19 a.m. EST: This headline was edited to remove the word "suspected" because 1,008 entries were externally validated.
Update 12/20, 11:20 a.m. EST: This story was corrected to reflect Common Crawl's inability to crawl Twitter, Instagram and Facebook.
Legally, there is no precedent yet for who’s responsible when a scraping tool gathers illegal imagery. As Vencu noted in his Discord message in 2021, LAION is disseminating links, not actual copies of images. “Since we are not distributing or deriving other images from originals, I do not think the image licensing apply,” he said in Discord to the question about whether illegal material was in the dataset.
Copyright infringement has been a major concern for artists and content creators whose imagery is being used to train AI models. In April, a German stock photographer asked LAION to exclude his photos from its datasets, and LAION responded by invoicing him for $979, claiming he filed an unjustified copyright claim. Earlier this year, a group of artists filed a class-action lawsuit against Stability AI, DeviantArt, and Midjourney for their use of image generator Stable Diffusion, which uses LAION’s datasets. And Getty Images recently sued Stability AI, claiming that the company copied more than 12 million images without permission.
“We have issues with those services, how they were built, what they were built upon, how they respect creator rights or not, and how they actually feed into deepfakes and other things like that,” Getty Images CEO Craig Peters told the Associated Press.
Spreading CSAM is a federal crime, and the US laws about it are extremely strict. It is of course illegal to possess or transmit files, but “undeveloped film, undeveloped videotape, and electronically stored data that can be converted into a visual image of child pornography” are also illegal under federal law. It’s not clear where URLs that link to child exploitation images would land under current laws, or at what point anyone using these datasets could potentially be in legal jeopardy.
Because anti CSAM laws are understandably so strict, researchers have had to figure out new ways of studying its spread without breaking the law themselves. Westlake told me he relies on outsourcing some research to colleagues in Canada, such as the C3P, to verify or clean data, where there are CSAM laws that carve out exceptions for research purposes. Stanford similarly sent its methodology to C3P for verification. The Internet Watch Foundation has a memorandum of understanding granted to them by the Crown Prosecution Service, the principal public criminal prosecuting agency in the UK, to download, view, and hold content for its duties, which enables it to proactively search for abusive content and report it to authorities. In the US, viewing, searching for, or possessing child exploitation material, even if accidentally, is a federal crime. [/SIZE]
“Places should no longer host those datasets for download."
Rogers and his colleague Kathryn Seigfried-Spellar at Purdue’s forensics department have a unique situation: They’re deputized, and have law enforcement status granted to them by local law enforcement to do their work. They have a physical space in a secure law enforcement facility, with surveillance cameras, key fobs, a secured network, and 12-factor identification where they must go if they want to do work like cleaning datasets or viewing CSAM for research or investigative purposes.
Even so, they’re incredibly careful about what they collect with scraping tools. Siegfried-Spellar told me she’s working on studying knuckles and hands because they often appear in abuse imagery and are as identifiable as faces, and could scrape images from NSFW Reddit forums where people post images of themselves masturbating, but she doesn’t because of the risk of catching underage imagery in the net.
“Even though you have to be over the age of 18 to use Reddit, I am never going to go and scrape that data and use it, or analyze it for my research, because I can't verify that somebody really is over the age of 18 that posted that,” she said. “There have been conversations about that as well: ‘there's pictures on the internet, why can’t I just scrape and use that for my algorithm training?’ But it's because I need to know the age of the sources.”
WHAT TO DO NOW
Because LAION-5B is open-source, lots of copies are floating around publicly, including on Hugging Face. Removing the dataset from Hugging Face, pulling CSAM links to abusive imagery out of the dataset, and then reuploading it, for example, would essentially create a roadmap for someone determined to view those files by comparing the differences between the two.
Thiel told me that he went into this study thinking the goal might be to get abusive material out of datasets, but now he believes it’s too late.
“Now I'm more of the opinion that [the LAION datasets] kind of just need to be scratched,” he said. “Places should no longer host those datasets for download. Maybe there's an argument for keeping copies of it for research capacity, and then you can go through and take some steps to clean it.”
There is a precedent for this, especially when it comes to children’s data. The Federal Trade Commission has a term for model deletion as damage control: algorithm disgorgement. As an enforcement strategy, the FTC has used algorithm disgorgement in five cases involving tech companions that built models on improperly-obtained data, including a settlement with Amazon in May over charges that Alexa voice recordings violated children’s privacy, and a settlement between the FTC and Department of Justice and a children’s weight loss app that allegedly failed to properly verify parental consent. Both cases invoked the Children’s Online Privacy Protection Act (COPPA).
Child safety and AI are quickly becoming the next major battleground of the internet. In April, Democratic senator dikk Durbin introduced the “STOP CSAM Act,” which would make it a crime for providers to “knowingly host or store” CSAM or “knowingly promote or facilitate” the sexual exploitation of children, create a new federal crime for online services that “knowingly promote or facilitate” child exploitation crimes, and amend Section 230—the law that shields platforms from liability for their users’ actions—to allow for civil lawsuits by victims of child exploitation crimes against online service providers. Privacy advocates including the Electronic Frontier Foundation and the Center for Democracy and Technology oppose the act, warning that it could undermine end-to-end encryption services. The inclusion of “apparent” CSAM widens the net too much, they say, and the terms “promote” and “facilitate” are overly broad. It could also have a chilling effect on free speech overall: “First Amendment-protected content involving sexuality, sexual orientation, or gender identity will likely be targets of frivolous takedown notices,” EFF attorneys and surveillance experts wrote in a blog post.
In September, attorneys general from 50 states called on federal lawmakers to study how AI-driven exploitation can endanger children. “We are engaged in a race against time to protect the children of our country from the dangers of AI,” the prosecutors wrote. “Indeed, the proverbial walls of the city have already been breached. Now is the time to act.”
Thiel said he hadn’t communicated with LAION before the study was released. “We're not intending this as some kind of gotcha for any of the parties involved. But obviously a lot of very important mistakes were made in various parts of this whole pipeline,” he said. “And it's really just not how model training in the future should work at all.”
All of this is a problem that’s not going away, even—or especially—if it’s ignored. “They all have massive problems associated with massive data theft, non consensual, intimate images, Child Sexual Abuse material, you name it, it's in there. I’m kind of perplexed at how it's gone on this long,” Richardson said. “It's not that the technology is necessarily bad... it's not that AI is bad. It's the fact that a bunch of things were blindly stolen, and now we're trying to put all these Band-aids to fix something that really never should have happened in the first place.”
Update 12/20, 8:19 a.m. EST: This headline was edited to remove the word "suspected" because 1,008 entries were externally validated.
Update 12/20, 11:20 a.m. EST: This story was corrected to reflect Common Crawl's inability to crawl Twitter, Instagram and Facebook.
/cdn.vox-cdn.com/uploads/chorus_asset/file/25175086/1258931679.jpg)
Rite Aid hit with five-year facial recognition ban over “reckless” use
Rite Aid allegedly created a database of shoppers it flagged.
Rite Aid hit with five-year facial recognition ban over ‘reckless’ use
The Federal Trade Commission is also requiring the pharmacy chain to delete all the photos and videos it captured of customers.
By Emma Roth, a news writer who covers the streaming wars, consumer tech, crypto, social media, and much more. Previously, she was a writer and editor at MUO.
Dec 19, 2023, 7:09 PM EST|15 Comments / 15 New
:format(webp)/cdn.vox-cdn.com/uploads/chorus_asset/file/25175086/1258931679.jpg)
Image: Getty
Rite Aid isn’t allowed to use AI-powered facial recognition technology for another five years as part of a settlement it reached with the Federal Trade Commission. In a complaint filed on Tuesday, the FTC accuses Rite Aid of using facial surveillance systems in a “reckless” manner from 2012 to 2020.
During this period, the FTC says Rite Aid used facial recognition technology to “capture images of all consumers as they entered or moved through the stores.” It then allegedly created a database of customers identified as shoplifters or exhibiting some other kind of suspicious behavior. For some customers, the database would have “accompanying information,” such as names, birth dates, and the activity deemed suspicious by the store, according to the complaint.
Rite Aid employees allegedly followed flagged customers around stores and performed searches
When a flagged shopper entered a Rite Aid store with facial recognition technology, the FTC says employees would receive a “match alert” sent to their mobile phones. As a result, Rite Aid employees allegedly followed customers around stores, performed searches, publicly accused them of shoplifting, and even asked the authorities to remove certain shoppers, according to the complaint. The FTC says Rite Aid falsely identified people as shoppers who had been previously flagged by the system, with incidents “disproportionality” impacting people of color.
Additionally, the pharmacy chain didn’t inform customers that it used facial recognition technology, and employees were “instructed employees not to reveal” this information, the complaint states. Most Rite Aid stores equipped with facial recognition technology were located in New York City, Los Angeles, Sacramento, Philadelphia, Baltimore, Detroit, Atlantic City, and a handful of other cities.
“Rite Aid’s reckless use of facial surveillance systems left its customers facing humiliation and other harms, and its order violations put consumers’ sensitive information at risk,” Samuel Levine, the FTC’s director of the Bureau of Consumer Protection, says in a statement. “Today’s groundbreaking order makes clear that the Commission will be vigilant in protecting the public from unfair biometric surveillance and unfair data security practices.”
Related
Clearview AI and the end of privacy, with author Kashmir Hill
IBM promised to back off facial recognition — then it signed a $69.8 million contract to provide it
In addition to a five-year ban from using facial recognition technology, the FTC’s proposed order requires Rite Aid to establish “comprehensive safeguards” to protect customers. The company must delete “all photos and videos” of customers collected by its facial recognition system, implement a data security program, and provide a written notice to customers who will have their biometric data enrolled in a database in the future, among other provisions. Since Rite Aid is currently going through bankruptcy proceedings, the FTC says the order will go into effect once the bankruptcy court and federal district court approve the measures.
Aside from Rite Aid, several retail stores have implemented facial recognition as a means to monitor guests. In 2021, Fight for the Future’s Ban Facial Recognition in Stores campaign had over 35 organizations demand that retailers like Albertsons, Macy’s, and Ace Hardware stop using the technology. Some states, including Maine, have carved out laws to regulate the use of facial recognition, while New York City requires that venues and retailers notify customers if biometric data collection is in use.

AI Robot Outmaneuvers Humans in Maze Run Breakthrough
Computers have famously beaten humans at poker, Go and chess. Now they can learn the physical skills to excel at basic games of dexterity.
 www.bloomberg.com
www.bloomberg.com
AI Robot Outmaneuvers Humans in Maze Run Breakthrough
- Robot learned in record time to guide a ball through a maze
- The AI robot used two knobs to manipulate playing surface

The Labyrinth game.Source: ETH Zurich
By Saritha Rai
December 19, 2023 at 7:30 AM EST
Computers have famously beaten humans at poker, Go and chess. Now they can learn the physical skills to excel at basic games of dexterity.
Researchers at ETH Zurich have created an AI robot called CyberRunner they say surpassed humans at the popular game Labyrinth. It navigated a small metal ball through a maze by tilting its surface, avoiding holes across the board, mastering the toy in just six hours, they said.
CyberRunner marked one of the first instances in which an AI beat humans at direct physical applications, said Raffaello D’Andrea and Thomas Bi, researchers at the prominent European institution. In experiments, their robot used two knobs to manipulate the playing surface, requiring fine motor skills and spatial reasoning. The game itself required real-time strategic thinking, quick decisions and precise action.
The duo shared their work in an academic paper published on Tuesday. They built their model on recent advances in a field called model-based reinforcement learning, a type of machine learning where the AI learns how to behave in a dynamic environment by trial and error.
“We are putting our work on an open-source platform to show it’s possible, sharing the details of how it’s done, and making it inexpensive to continue the work,” said D’Andrea, who co-founded Kiva Systems before selling itto Amazon.com Inc. “There will be thousands of these AI systems soon doing collaborative experiments, communicating and sharing best practices.”

Raffaello D’AndreaSource: ETH Zurich
Industrial robots have performed repetitive, precise manufacturing tasks for decades, but adjustments on-the-fly such as the ones CyberRunner demonstrated are next-level, the researchers said. The system can think, learn and self-develop on physical tasks, previously thought achievable only through human intelligence.
CyberRunner learns through experience, through a camera looking down at the labyrinth. During the process, it discovered surprising ways to “cheat” by skipping parts of the maze. The researchers had to step in and explicitly instruct it not to take shortcuts.
The duo’s open-sourced project is now available on their website. For $200, it can help users coordinate large-scale experiments using the CyberRunner platform.
“This is not a bespoke platform that costs a lot of money,” D’Andrea said. “The exciting thing is that we are doing it on a platform that’s open to everyone, and costs almost nothing to further advance the work.”

Seeking a Big Edge in A.I., South Korean Firms Think Smaller
While they lag behind their U.S. counterparts, their focus on non-English languages could help loosen the American grip on artificial intelligence.

The features of Exaone, LG’s generative A.I., were demonstrated at LG A.I. Research in Seoul in September.Credit...Tina Hsu for The New York Times
Seeking a Big Edge in A.I., South Korean Firms Think Smaller
While they lag behind their U.S. counterparts, their focus on non-English languages could help loosen the American grip on artificial intelligence.
The features of Exaone, LG’s generative A.I., were demonstrated at LG A.I. Research in Seoul in September.Credit...Tina Hsu for The New York Times
By John Yoon
Reporting from Seoul
Dec. 20, 2023Updated 3:32 a.m. ET
ChatGPT, Bard, Claude. The world’s most popular and successful chatbots are trained on data scraped from vast swaths of the internet, mirroring the cultural and linguistic dominance of the English language and Western perspectives. This has raised alarms about the lack of diversity in artificial intelligence. There is also the worry that the technology will remain the province of a handful of American companies.
In South Korea, a technological powerhouse, firms are taking advantage of the technology’s malleability to shape A.I. systems from the ground up to address local needs. Some have trained A.I. models with sets of data rich in Korean language and culture. South Korean companies say they’re building A.I. for Thai, Vietnamese and Malaysian audiences. Others are eyeing customers in Brazil, Saudi Arabia and the Philippines, and in industries like medicine and pharmacy.
This has fueled hopes that A.I. can become more diverse, work in more languages, be customized to more cultures and be developed by more countries.
“The more competition is out there, the more systems are going to be robust: socially acceptable, safer, more ethical,” said Byong-Tak Zhang, a computer science professor at Seoul National University.
While there are some prominent non-American A.I. companies, like France’s Mistral, the recent upheaval at OpenAI, the maker of ChatGPT, has highlighted how concentrated the industry remains.
The emerging A.I. landscape in South Korea is one of the most competitive and diverse in the world, said Yong Lim, a professor of law at Seoul National University who leads its AI Policy Initiative. The country’s export-driven economy has encouraged new ventures to seek ways to tailor A.I. systems to specific companies or countries.
South Korea is well positioned to build A.I. technology, developers say, given it has one of the world’s most wired populations to generate vast amounts of data to train A.I. systems. Its tech giants have the resources to invest heavily in research. The government has also been encouraging: It has provided companies with money and data that could be used to train large language models, the technology that powers A.I. chatbots.

Commuters entering the Gangnam metro underground train station in Seoul.Credit...Anthony Wallace/Agence France-Presse — Getty Images

CCTV cameras in the Gangnam district are equipped with artificial intelligence technology to monitor crowd density and detect early signs of crowd control disasters.Credit...Soo-Hyeon Kim/Reuters
Few other countries have the combination of capital and technology required to develop a large language model that can power a chatbot, experts say. They estimate that it costs $100 million to $200 million to build a foundational model, the technology that serves as the basis for A.I. chatbots.
South Korea is still months behind the United States in the A.I. race and may never fully catch up, as the leading chatbots continue to improve with more resources and data.
But South Korean companies believe they can compete. Instead of going after the global market like their American competitors, companies like Naver and LG have tried to target their A.I. models to specific industries, cultures or languages instead of pulling from the entire internet.
“The localized strategy is a reasonable strategy for them,” said Sukwoong Choi, a professor of information systems at the University at Albany. “U.S. firms are focused on general-purpose tools. South Korean A.I. firms can target a specific area.”
Outside the United States, A.I. prowess appears limited in reach. In China, Baidu’s answer to ChatGPT, called Ernie, and Huawei’s large language model have shown some success at home, but they are far from dominating the global market. Governments and companies in other nations like Canada, Britain, India and Israel have also said they are developing their own A.I. systems, though none has yet to release a system that can be used by the public.
About a year before ChatGPT was released, Naver, which operates South Korea’s most widely used search engine, announced that it had successfully created a large language model. But the chatbot based on that model, Clova X, was released only this September, nearly a year after ChatGPT’s debut.

Nako Sung, the executive who leads Naver’s generative A.I. project.Credit...Tina Hsu for The New York Times
Nako Sung, an executive at Naver who has led the company’s generative A.I. project, said the timing of ChatGPT’s release surprised him.
“Up until that point, we were taking a conservative approach to A.I. services and just cautiously exploring the possibilities,” Mr. Sung said. “Then we realized that the timeline had been accelerated a lot,” he added. “We decided we had to move immediately.”
Now, Naver runs an A.I. model built for Korean language speakers from the ground up using public data from the South Korean government and from its search engine, which has scraped the country’s internet since 1999.

Inside Naver’s headquarters in Seongnam, South Korea.Credit...Tina Hsu for The New York Times

Mr. Sung typing a prompt into Naver’s A.I. service.Credit...Tina Hsu for The New York Times

Naver released its A.I. chatbot, Clova X, nearly a year after ChatGPT’s debut.Credit...Tina Hsu for The New York Times
Clova X recognizes Korean idioms and the latest slang — language that American-made chatbots like Bard, ChatGPT and Claude often struggle to understand. Naver’s chatbot is also integrated into the search engine, letting people use the tool to shop and travel.
Outside its home market, the company is exploring business opportunities with the Saudi Arabian government. Japan could be another potential customer, experts said, since Line, a messaging service owned by Naver, is used widely there.
LG has also created its own generative A.I. model, the type of artificial intelligence capable of creating original content based on inputs, called Exaone. Since its creation in 2021, LG has worked with publishers, research centers, pharmaceutical firms and medical companies to tailor its system to their data sets and provide them access to its A.I. system.
The company is targeting businesses and researchers instead of the general user, said Kyunghoon Bae, the director of LG A.I. Research. Its subsidiaries have also begun using its own A.I. chatbots. One of the chatbots, built to analyze chemistry research and chemical equations, has been used by researchers building new materials for batteries, chemicals and medicine.

Honglak Lee, chief scientist of LG A.I. Research, and Kyunghoon Bae, who leads the branch, in their office in Seoul.Credit...Tina Hsu for The New York Times

Se-hui Han and Rodrigo Hormazabal, developers at LG A.I. Research, demonstrating LG’s Exaone Discovery in Seoul.Credit...Tina Hsu for The New York Times
“Rather than letting the best one or two A.I. systems dominate, it’s important to have an array of models specific to a domain, language or culture,” said Honglak Lee, the chief scientist of LG’s A.I. research arm.
Another South Korean behemoth, Samsung, last month announced Samsung Gauss, a generative A.I. model being used internally to compose emails, summarize documents and translate text. The company plans to integrate it into its mobile phones and smart home appliances.
Other major companies have also said they are developing their own large language models, making South Korea one of the few countries with so many companies building A.I. systems. KT, a South Korean telecommunications firm, has said it is working with a Thai counterpart, Jasmine Group, on a large language model specialized in the Thai language. Kakao, which makes an eponymous super app for chats, has said it is developing generative A.I. for Korean, English, Japanese, Vietnamese and Malaysian.
Still, the United States’ dominance in A.I. appears secure for now. It remains to be seen how closely countries can catch up.
“The market is convulsing; it’s very difficult to predict what’s going to happen,” said Mr. Lim, the A.I. policy expert. “It’s the Wild West, in a sense.”

Workers waiting for their company-provided transport after work at a Samsung Electronics campus south of Seoul. Samsung plans to use incorporate its chatbot into cellphones and smart home appliances.Credit...Tina Hsu for The New York Times
Prompt engineering techniques

Prompt engineering techniques with Azure OpenAI - Azure OpenAI Service
Learn about the options for how to use prompt engineering with GPT-3, GPT-35-Turbo, and GPT-4 models
learn.microsoft.com