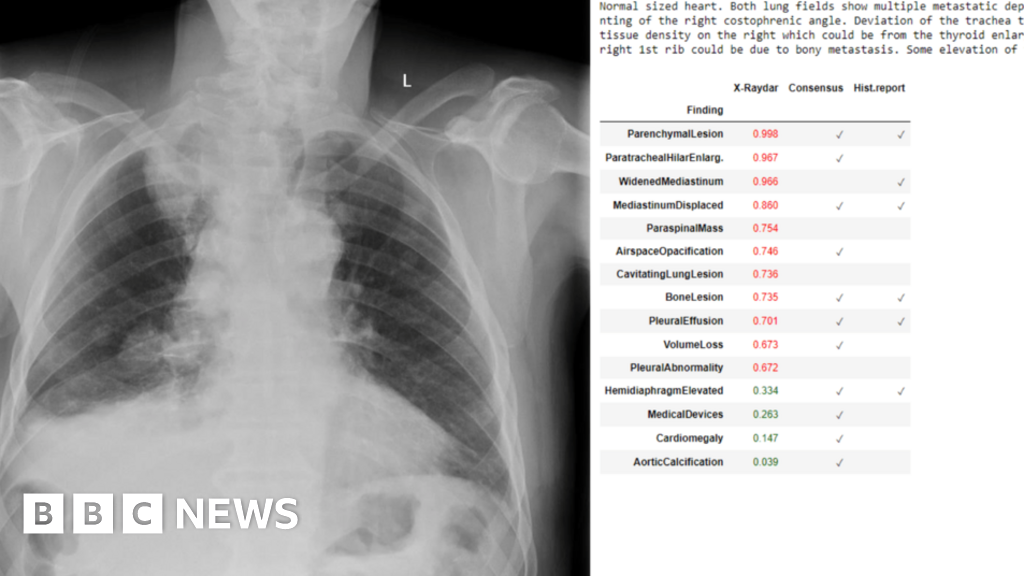
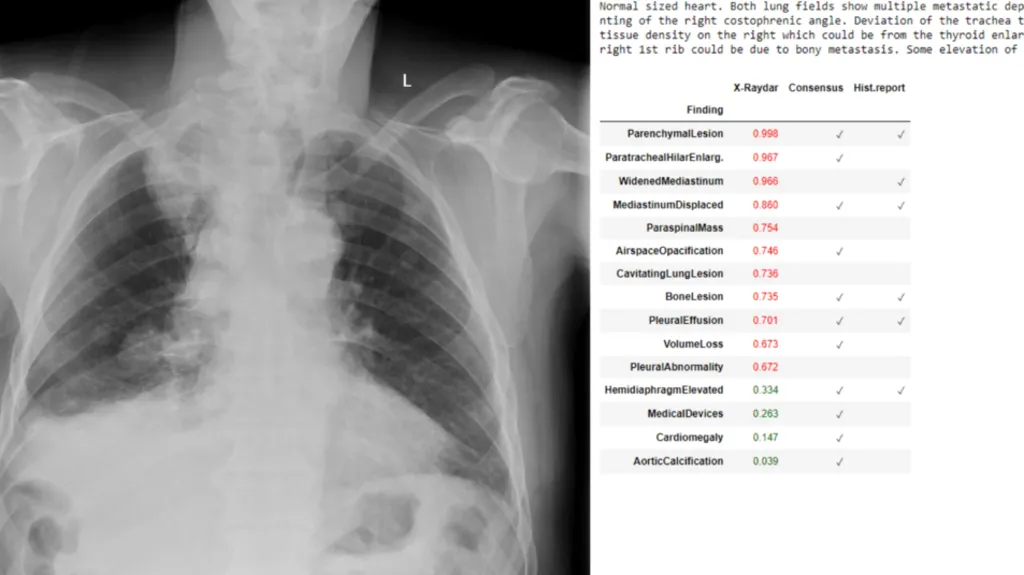
It’s time for developers and enterprises to build with Gemini Pro
Gemini Pro is now available for developers and enterprises to build AI applications.
It’s time for developers and enterprises to build with Gemini Pro
Dec 13, 2023
3 min read
Learn more about how to integrate Gemini Pro into your app or business at ai.google.dev.
Jeanine Banks
VP & GM, Developer X and DevRel
Burak Gokturk
VP & GM, Cloud AI & Industry Solutions

Last week, we announced Gemini, our largest and most capable AI model and the next step in our journey to make AI more helpful for everyone. It comes in three sizes: Ultra, Pro and Nano. We've already started rolling out Gemini in our products: Gemini Nano is in Android, starting with Pixel 8 Pro, and a specifically tuned version of Gemini Pro is in Bard.
Today, we’re making Gemini Pro available for developers and enterprises to build for your own use cases, and we’ll be further fine-tuning it in the weeks and months ahead as we listen and learn from your feedback.
Gemini Pro is available today
The first version of Gemini Pro is now accessible via the Gemini API and here’s more about it:- Gemini Pro outperforms other similarly-sized models on research benchmarks.
- Today’s version comes with a 32K context window for text, and future versions will have a larger context window.
- It’s free to use right now, within limits, and it will be competitively priced.
- It comes with a range of features: function calling, embeddings, semantic retrieval and custom knowledge grounding, and chat functionality.
- It supports 38 languages across 180+ countries and territories worldwide.
- In today’s release, Gemini Pro accepts text as input and generates text as output. We’ve also made a dedicated Gemini Pro Vision multimodal endpoint available today that accepts text and imagery as input, with text output.
- SDKs are available for Gemini Pro to help you build apps that run anywhere. Python, Android (Kotlin), Node.js, Swift and JavaScript are all supported.

Gemini Pro has SDKs that help you build apps that run anywhere.
Google AI Studio: The fastest way to build with Gemini
Google AI Studio is a free, web-based developer tool that enables you to quickly develop prompts and then get an API key to use in your app development. You can sign into Google AI Studio with your Google account and take advantage of the free quota, which allows 60 requests per minute — 20x more than other free offerings. When you’re ready, you can simply click on “Get code” to transfer your work to your IDE of choice, or use one of the quickstart templates available in Android Studio, Colab or Project IDX. To help us improve product quality, when you use the free quota, your API and Google AI Studio input and output may be accessible to trained reviewers. This data is de-identified from your Google account and API key.Google AI Studio is a free, web-based developer tool that enables you to quickly develop prompts and then get an API key to use in your app development.
Build with Vertex AI on Google Cloud
When it's time for a fully-managed AI platform, you can easily transition from Google AI Studio to Vertex AI, which allows for customization of Gemini with full data control and benefits from additional Google Cloud features for enterprise security, safety, privacy and data governance and compliance.With Vertex AI, you will have access to the same Gemini models, and will be able to:
- Tune and distill Gemini with your own company’s data, and augment it with grounding to include up-to-minute information and extensions to take real-world actions.
- Build Gemini-powered search and conversational agents in a low code / no code environment, including support for retrieval-augmented generation (RAG), blended search, embeddings, conversation playbooks and more.
- Deploy with confidence. We never train our models on inputs or outputs from Google Cloud customers. Your data and IP are always your data and IP.
Gemini Pro pricing
Right now, developers have free access to Gemini Pro and Gemini Pro Vision through Google AI Studio, with up to 60 requests per minute, making it suitable for most app development needs. Vertex AI developers can try the same models, with the same rate limits, at no cost until general availability early next year, after which there will be a charge per 1,000 characters or per image across Google AI Studio and Vertex AI.
Big impact, small price: Because of our investments in TPUs, Gemini Pro can be served more efficiently.
Looking ahead
We’re excited that Gemini is now available to developers and enterprises. As we continue to fine-tune it, your feedback will help us improve. You can learn more and start building with Gemini on ai.google.dev, or use Vertex AI’s robust capabilities on your own data with enterprise-grade controls.Early next year, we’ll launch Gemini Ultra, our largest and most capable model for highly complex tasks, after further fine-tuning, safety testing and gathering valuable feedback from partners. We’ll also bring Gemini to more of our developer platforms like Chrome and Firebase.
We’re excited to see what you build with Gemini.







")