
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
The A.I Megathread (LLM , GPT , Development)
More options
Who Replied?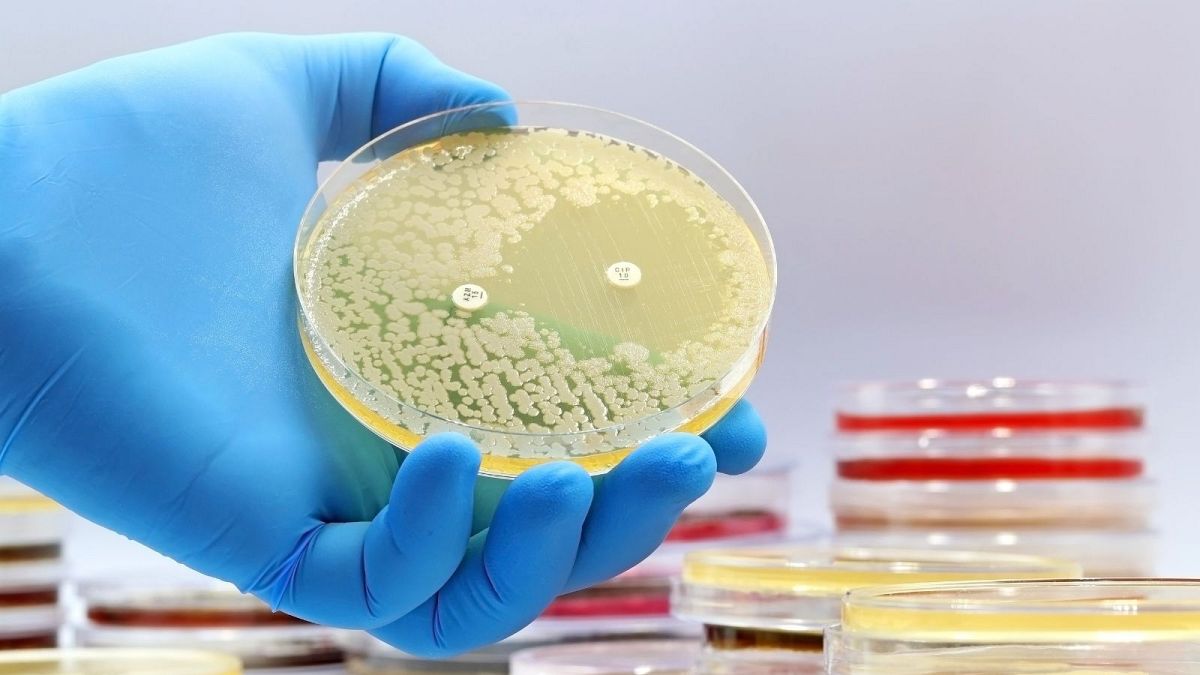
Scientists discover first new antibiotics in over 60 years using AI
A new class of antibiotics for drug-resistant Staphylococcus aureus (MRSA) bacteria which was discovered using more transparent deep learning models.
 www.euronews.com
www.euronews.com
Scientists discover the first new antibiotics in over 60 years using AI
By Oceane Duboust
Published on 20/12/2023 - 17:53•Updated 18:27
Share this articleComments
A new class of antibiotics for drug-resistant Staphylococcus aureus (MRSA) bacteria which was discovered using more transparent deep learning models.
The use of artificial intelligence (AI) is proving to be a game-changer when it comes to medicine with the technology now helping scientists to unlock the first new antibiotics in 60 years.
The discovery of a new compound that can kill a drug-resistant bacterium that kills thousands worldwide every year could prove to be a turning point in the fight against antibiotic resistance.
"The insight here was that we could see what was being learned by the models to make their predictions that certain molecules would make for good antibiotics," James Collins, professor of Medical Engineering and Science at the Massachusetts Institute of Technology (MIT) and one of the study’s authors, said in a statement.
"Our work provides a framework that is time-efficient, resource-efficient, and mechanistically insightful, from a chemical-structure standpoint, in ways that we haven’t had to date".
The results were published today in Nature and co-authored by a team of 21 researchers.
Study aimed to 'open the black box'
The team behind the project used a deep-learning model to predict the activity and toxicity of the new compound.Deep learning involves the use of artificial neural networks to automatically learn and represent features from data without explicit programming.
It is increasingly being applied in drug discovery to accelerate the identification of potential drug candidates, predict their properties, and optimise the drug development process.
In this case, researchers focused on methicillin-resistant Staphylococcus aureus (MRSA).
Infections with MRSA can range from mild skin infections to more severe and potentially life-threatening conditions such as pneumonia and bloodstream infections.
The MIT team of researchers trained an extensively enlarged deep learning model using expanded datasets.
To create the training data, approximately 39,000 compounds were evaluated for their antibiotic activity against MRSA. Subsequently, both the resulting data and details regarding the chemical structures of the compounds were input into the model.
"What we set out to do in this study was to open the black box. These models consist of very large numbers of calculations that mimic neural connections, and no one really knows what's going on underneath the hood," said Felix Wong, a postdoc at MIT and Harvard and one of the study’s lead authors.
Discovering a new compound
To refine the selection of potential drugs, the researchers employed three additional deep-learning models. These models were trained to assess the toxicity of compounds on three distinct types of human cells.By integrating these toxicity predictions with the previously determined antimicrobial activity, the researchers pinpointed compounds capable of effectively combating microbes with minimal harm to the human body.
Using this set of models, approximately 12 million commercially available compounds were screened.
The models identified compounds from five different classes, categorised based on specific chemical substructures within the molecules, that exhibited predicted activity against MRSA.
In experiments involving two mouse models - one for MRSA skin infection and another for MRSA systemic infection - each of these compounds reduced the MRSA population by a factor of 10.


suno/bark · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
huggingface.co
GitHub - suno-ai/bark: 🔊 Text-Prompted Generative Audio Model
🔊 Text-Prompted Generative Audio Model. Contribute to suno-ai/bark development by creating an account on GitHub.
 github.com
github.com
Notice: Bark is Suno's open-source text-to-speech+ model. If you are looking for our new text-to-music model, Chirp, have a look at our Chirp Examples Page and join us on Discord.
 Bark
Bark


Bark is a transformer-based text-to-audio model created by Suno. Bark can generate highly realistic, multilingual speech as well as other audio - including music, background noise and simple sound effects. The model can also produce nonverbal communications like laughing, sighing and crying. To support the research community, we are providing access to pretrained model checkpoints, which are ready for inference and available for commercial use.
GitHub - C0untFloyd/bark-gui: 🔊 Text-Prompted Generative Audio Model with Gradio
🔊 Text-Prompted Generative Audio Model with Gradio - GitHub - C0untFloyd/bark-gui: 🔊 Text-Prompted Generative Audio Model with Gradio
github.com
DEMO:

Bark - a Hugging Face Space by suno
Convert any text into highly realistic, multilingual speech. Provide the text and choose a voice or accent to hear the generated audio.
huggingface.co
Last edited:
Apple’s latest AI research could completely transform your iPhone
Apple researchers have introduced new techniques to create photorealistic 3D avatars from video and enable advanced AI systems to run efficiently on devices with limited memory, such as an iPhone or iPad.
 venturebeat.com
venturebeat.com
Apple’s latest AI research could completely transform your iPhone
Michael Nuñez@MichaelFNunez
December 20, 2023 1:01 PM
Credit: VentureBeat made with Midjourney
Are you ready to bring more awareness to your brand? Consider becoming a sponsor for The AI Impact Tour. Learn more about the opportunities here.
Apple, a company practically synonymous with technological innovation, has once again positioned itself at the forefront of the AI revolution.
The Cupertino, Calif.-based company recently announced significant strides in artificial intelligence research through two new papers introducing new techniques for 3D avatars and efficient language model inference. The advancements could enable more immersive visual experiences and allow complex AI systems to run on consumer devices such as the iPhone and iPad.
In the first research paper, Apple scientists propose HUGS (Human Gaussian Splats) to generate animated 3D avatars from short monocular videos (i.e. videos taken from a single camera). “Our method takes only a monocular video with a small number of (50-100) frames, and it automatically learns to disentangle the static scene and a fully animatable human avatar within 30 minutes,” said lead author Muhammed Kocabas.
The training video (left upper), the reconstructed canonical human avatar (right upper), the reconstructed scene model (left bottom), and the animated reposed human together with the scene (right bottom). (Credit: Apple)
HUGS represents both the human and background scene using 3D Gaussian splatting, an efficient rendering technique. The human model is initialized from a statistical body shape model called SMPL. But HUGS allows the Gaussians to deviate, enabling capture of details like clothing and hair.
A novel neural deformation module animates the Gaussians in a realistic fashion using linear blend skinning. This coordinated movement avoids artifacts while reposing the avatar. According to Kocabas, HUGS “enables novel-pose synthesis of human and novel view synthesis of both the human and the scene.”
Compared to previous avatar generation methods, HUGS is up to 100 times faster in training and rendering. The researchers demonstrate photorealistic results after optimizing the system for just 30 minutes on a typical gaming GPU. HUGS also outperforms state-of-the-art techniques like Vid2Avatar and NeuMan on 3D reconstruction quality.
The new technology lets people put different digital characters, or “avatars,” into a new scene using just one video of the person and the place. This can be done quickly, with the image updating 60 times every second to make it look smooth and realistic. (Credit: Apple)
The new 3D modeling capabilitiy is a really impressive achievement from Apple researchers. The real-time performance and ability to create avatars from in-the-wild videos could unlock new possibilities for virtual try-on, telepresence, and synthetic media in the relatively near future. Imagine the possibilities if you could create novel 3D scenes like this right on your iPhone camera!
Bridging the memory gap in AI inference
In the second paper, Apple researchers tackled a key challenge in deploying large language models (LLMs) on devices with limited memory. Modern natural language models like GPT-4 contain hundreds of billions of parameters, making inference expensive on consumer hardware.The proposed system minimizes data transfer from flash storage into scarce DRAM during inference. “Our method involves constructing an inference cost model that harmonizes with the flash memory behavior, guiding us to optimize in two critical areas: reducing the volume of data transferred from flash and reading data in larger, more contiguous chunks,” explained lead author Keivan Alizadeh.
Two main techniques are introduced. “Windowing” reuses activations from recent inferences, while “row-column bundling” reads larger blocks of data by storing rows and columns together. On an Apple M1 Max CPU, these methods improve inference latency by 4-5x compared to naive loading. On a GPU, the speedup reaches 20-25x.
“This breakthrough is particularly crucial for deploying advanced LLMs in resource-limited environments, thereby expanding their applicability and accessibility,” said co-author Mehrdad Farajtabar. The optimizations could soon allow complex AI assistants and chatbots to run smoothly on iPhone, iPads, and other mobile devices.
Apple’s strategic vision
Both papers demonstrate Apple’s growing leadership in AI research and applications. While promising, experts caution that Apple will need to exercise great care and responsibility when incorporating these technologies into consumer products. From privacy protection to mitigating misuse, the societal impact must be considered.As Apple potentially integrates these innovations into its product lineup, it’s clear that the company is not just enhancing its devices but also anticipating the future needs of AI-infused services. By allowing more complex AI models to run on devices with limited memory, Apple is potentially setting the stage for a new class of applications and services that leverage the power of LLMs in a way that was previously unfeasible.
Furthermore, by publishing this research, Apple is contributing to the broader AI community, which could stimulate further advancements in the field. It’s a move that reflects Apple’s confidence in its position as a tech leader and its commitment to pushing the boundaries of what’s possible.
If applied judiciously, Apple’s latest innovations could take artificial intelligence to the next level. Photorealistic digital avatars and powerful AI assistants on portable devices once seemed far off — but thanks to Apple’s scientists, the future is rapidly becoming reality.
Apple AI researchers publish papers on using human gaussian splats to generate animated 3D avatars from videos and deploying LLMs on devices with limited memory
By Michael Nuñez / VentureBeat. View the full context on Techmeme.
 www.techmeme.com
www.techmeme.com
Apple Develops Breakthrough Method for Running LLMs on iPhones
Apple GPT in your pocket? It could be a reality sooner than you think. Apple AI researchers say they have made a key breakthrough in deploying large...
 www.macrumors.com
www.macrumors.com
Apple Develops Breakthrough Method for Running LLMs on iPhones
Thursday December 21, 2023 2:26 am PST by Tim Hardwick
Apple GPT in your pocket? It could be a reality sooner than you think. Apple AI researchers say they have made a key breakthrough in deploying large language models (LLMs) on iPhones and other Apple devices with limited memory by inventing an innovative flash memory utilization technique.

LLMs and Memory Constraints
LLM-based chatbots like ChatGPT and Claude are incredibly data and memory-intensive, typically requiring vast amounts of memory to function, which is a challenge for devices like iPhones that have limited memory capacity. To tackle this issue, Apple researchers have developed a novel technique that uses flash memory – the same memory where your apps and photos live – to store the AI model's data.Storing AI on Flash Memory
In a new research paper titled "LLM in a flash: Efficient Large Language Model Inference with Limited Memory," the authors note that flash storage is more abundant in mobile devices than the RAM traditionally used for running LLMs. Their method cleverly bypasses the limitation using two key techniques that minimize data transfer and maximize flash memory throughput:- Windowing: Think of this as a recycling method. Instead of loading new data every time, the AI model reuses some of the data it already processed. This reduces the need for constant memory fetching, making the process faster and smoother.
- Row-Column Bundling: This technique is like reading a book in larger chunks instead of one word at a time. By grouping data more efficiently, it can be read faster from the flash memory, speeding up the AI's ability to understand and generate language.
Faster AI on iPhone
The breakthrough in AI efficiency opens new possibilities for future iPhones, such as more advanced Siri capabilities, real-time language translation, and sophisticated AI-driven features in photography and augmented reality. The technology also sets the stage for iPhones to run complex AI assistants and chatbots on-device, something Apple is already said to be working on.Apple's work on generative AI could eventually be incorporated into its Siri voice assistant. Apple in February 2023 held an AI summit and briefed employees on its large language model work. According to Bloomberg, Apple is aiming for a smarter version of Siri that's deeply integrated with AI. Apple is planning to update the way that Siri interacts with the Messages app, allowing users to field complex questions and auto-complete sentences more effectively. Beyond that, Apple is rumored to be planning to add AI to as many Apple apps as possible.
Apple GPT
Apple is reportedly developing its own generative AI model called "Ajax". Designed to rival the likes of OpenAI's GPT-3 and GPT-4, Ajax operates on 200 billion parameters, suggesting a high level of complexity and capability in language understanding and generation. Internally known as "Apple GPT," Ajax aims to unify machine learning development across Apple, suggesting a broader strategy to integrate AI more deeply into Apple's ecosystem.As of the latest reports, Ajax is considered more capable than the earlier generation ChatGPT 3.5. However, it's also suggested that OpenAI's newer models may have advanced beyond Ajax's capabilities as of September 2023.
Both The Information and analyst Jeff Pu claim that Apple will have some kind of generative AI feature available on the iPhone and iPad around late 2024, which is when iOS 18 will be coming out. Pu said in October that Apple is building a few hundred AI servers in 2023, with more to come in 2024. Apple will reportedly offer a combination of cloud-based AI and AI with on-device processing.
Tag: Apple GPT Guide

Apple wants AI to run directly on its hardware instead of in the cloud
iPhone maker wants to catch up to its rivals when it comes to AI.
 arstechnica.com
arstechnica.com
Apple wants AI to run directly on its hardware instead of in the cloud
iPhone maker wants to catch up to its rivals when it comes to AI.
TIM BRADSHAW, FINANCIAL TIMES - 12/21/2023, 9:43 AM
Enlarge / The iPhone 15 Pro.
Apple
87
Apple’s latest research about running large language models on smartphones offers the clearest signal yet that the iPhone maker plans to catch up with its Silicon Valley rivals in generative artificial intelligence.
The paper, entitled “LLM in a Flash,” offers a “solution to a current computational bottleneck,” its researchers write.
Its approach “paves the way for effective inference of LLMs on devices with limited memory,” they said. Inference refers to how large language models, the large data repositories that power apps like ChatGPT, respond to users’ queries. Chatbots and LLMs normally run in vast data centers with much greater computing power than an iPhone.
The paper was published on December 12 but caught wider attention after Hugging Face, a popular site for AI researchers to showcase their work, highlighted it late on Wednesday. It is the second Apple paper on generative AI this month and follows earlier moves to enable image-generating models such as Stable Diffusion to run on its custom chips.
Device manufacturers and chipmakers are hoping that new AI features will help revive the smartphone market, which has had its worst year in a decade, with shipments falling an estimated 5 percent, according to Counterpoint Research.
Despite launching one of the first virtual assistants, Siri, back in 2011, Apple has been largely left out of the wave of excitement about generative AI that has swept through Silicon Valley in the year since OpenAI launched its breakthrough chatbot ChatGPT. Apple has been viewed by many in the AI community as lagging behind its Big Tech rivals, despite hiring Google’s top AI executive, John Giannandrea, in 2018.
While Microsoft and Google have largely focused on delivering chatbots and other generative AI services over the Internet from their vast cloud computing platforms, Apple’s research suggests that it will instead focus on AI that can run directly on an iPhone.
Apple’s rivals, such as Samsung, are gearing up to launch a new kind of “AI smartphone” next year. Counterpoint estimated more than 100 million AI-focused smartphones would be shipped in 2024, with 40 percent of new devices offering such capabilities by 2027.
The head of the world’s largest mobile chipmaker, Qualcomm chief executive Cristiano Amon, forecast that bringing AI to smartphones would create a whole new experience for consumers and reverse declining mobile sales.
“You’re going to see devices launch in early 2024 with a number of generative AI use cases,” he told the Financial Times in a recent interview. “As those things get scaled up, they start to make a meaningful change in the user experience and enable new innovation which has the potential to create a new upgrade cycle in smartphones.”
More sophisticated virtual assistants will be able to anticipate users’ actions such as texting or scheduling a meeting, he said, while devices will also be capable of new kinds of photo editing techniques.
Google this month unveiled a version of its new Gemini LLM that will run “natively” on its Pixel smartphones.
Running the kind of large AI model that powers ChatGPT or Google’s Bard on a personal device brings formidable technical challenges, because smartphones lack the huge computing resources and energy available in a data center. Solving this problem could mean that AI assistants respond more quickly than they do from the cloud and even work offline.
Ensuring that queries are answered on an individual’s own device without sending data to the cloud is also likely to bring privacy benefits, a key differentiator for Apple in recent years.
“Our experiment is designed to optimize inference efficiency on personal devices,” its researchers said. Apple tested its approach on models including Falcon 7B, a smaller version of an open source LLM originally developed by the Technology Innovation Institute in Abu Dhabi.
Optimizing LLMs to run on battery-powered devices has been a growing focus for AI researchers. Academic papers are not a direct indicator of how Apple intends to add new features to its products, but they offer a rare glimpse into its secretive research labs and the company’s latest technical breakthroughs.
“Our work not only provides a solution to a current computational bottleneck but also sets a precedent for future research,” wrote Apple’s researchers in the conclusion to their paper. “We believe as LLMs continue to grow in size and complexity, approaches like this work will be essential for harnessing their full potential in a wide range of devices and applications.”
Apple did not immediately respond to a request for comment.








Google DeepMind used a large language model to solve an unsolved math problem
They had to throw away most of what it produced but there was gold among the garbage.
 www.technologyreview.com
www.technologyreview.com
ARTIFICIAL INTELLIGENCE
Google DeepMind used a large language model to solve an unsolved math problem
They had to throw away most of what it produced but there was gold among the garbage.By Will Douglas Heaven
archive page
December 14, 2023

STEPHANIE ARNETT/MITTR
Google DeepMind has used a large language model to crack a famous unsolved problem in pure mathematics. In a paper published in Nature today, the researchers say it is the first time a large language model has been used to discover a solution to a long-standing scientific puzzle—producing verifiable and valuable new information that did not previously exist. “It’s not in the training data—it wasn’t even known,” says coauthor Pushmeet Kohli, vice president of research at Google DeepMind.
Large language models have a reputation for making things up, not for providing new facts. Google DeepMind’s new tool, called FunSearch, could change that. It shows that they can indeed make discoveries—if they are coaxed just so, and if you throw out the majority of what they come up with.
FunSearch (so called because it searches for mathematical functions, not because it’s fun) continues a streak of discoveries in fundamental math and computer science that DeepMind has made using AI. FirstAlphaTensor found a way to speed up a calculation at the heart of many different kinds of code, beating a 50-year record. ThenAlphaDev found ways to make key algorithms used trillions of times a day run faster.
Yet those tools did not use large language models. Built on top of DeepMind’s game-playing AI AlphaZero, both solved math problems by treating them as if they were puzzles in Go or chess. The trouble is that they are stuck in their lanes, says Bernardino Romera-Paredes, a researcher at the company who worked on both AlphaTensor and FunSearch: “AlphaTensor is great at matrix multiplication, but basically nothing else.”
FunSearch takes a different tack. It combines a large language model called Codey, a version of Google’s PaLM 2 that isfine-tuned on computer code, with other systems that reject incorrect or nonsensical answers and plug good ones back in.
“To be very honest with you, we have hypotheses, but we don’t know exactly why this works,” saysAlhussein Fawzi, a research scientist at Google DeepMind. “In the beginning of the project, we didn’t know whether this would work at all.”
The researchers started by sketching out the problem they wanted to solve in Python, a popular programming language. But they left out the lines in the program that would specify how to solve it. That is where FunSearch comes in. It gets Codey to fill in the blanks—in effect, to suggest code that will solve the problem.
A second algorithm then checks and scores what Codey comes up with. The best suggestions—even if not yet correct—are saved and given back to Codey, which tries to complete the program again. “Many will be nonsensical, some will be sensible, and a few will be truly inspired,” says Kohli. “You take those truly inspired ones and you say, ‘Okay, take these ones and repeat.’”
After a couple of million suggestions and a few dozen repetitions of the overall process—which took a few days—FunSearch was able to come up with code that produced a correct and previously unknown solution to the cap set problem, which involves finding the largest size of a certain type of set. Imagine plotting dots on graph paper. The cap set problem is like trying to figure out how many dots you can put down without three of them ever forming a straight line.
It’s super niche, but important. Mathematicians do not even agree on how to solve it, let alone what the solution is. (It is also connected to matrix multiplication, the computation that AlphaTensor found a way to speed up.) Terence Tao at the University of California, Los Angeles, who has won many of the top awards in mathematics, including the Fields Medal, called the cap set problem “perhaps my favorite open question” in a 2007blog post.
Tao is intrigued by what FunSearch can do. “This is a promising paradigm,” he says. “It is an interesting way to leverage the power of large language models.”
A key advantage that FunSearch has over AlphaTensor is that it can, in theory, be used to find solutions to a wide range of problems. That’s because it produces code—a recipe for generating the solution, rather than the solution itself. Different code will solve different problems. FunSearch’s results are also easier to understand. A recipe is often clearer than the weird mathematical solution it produces, says Fawzi.
To test its versatility, the researchers used FunSearch to approach another hard problem in math: the bin packing problem, which involves trying to pack items into as few bins as possible. This is important for a range of applications in computer science, from data center management to e-commerce. FunSearch came up with a way to solve it that’s faster than human-devised ones.
Mathematicians are “still trying to figure out the best way to incorporate large language models into our research workflow in ways that harness their power while mitigating their drawbacks,” Tao says. “This certainly indicates one possible way forward.”
The headline of this article has been updated.
Google DeepMind used a large language model to solve an unsolved math problem
They had to throw away most of what it produced but there was gold among the garbage.
www.technologyreview.com
ARTIFICIAL INTELLIGENCE
This new system can teach a robot a simple household task within 20 minutes
The Dobb-E domestic robotics system was trained in real people’s homes and could help solve the field’s data problem.By
December 14, 2023

STEPHANIE ARNETT/MITTR | HELLO ROBOT, ENVATO
A new system that teaches robots a domestic task in around 20 minutes could help the field of robotics overcome one of its biggest challenges: a lack of training data.
The open-source system, called Dobb-E, was trained using data collected from real homes. It can help to teach a robot how to open an air fryer, close a door, or straighten a cushion, among other tasks.
While other types of AI, such as large language models, are trained on huge repositories of data scraped from the internet, the same can’t be done with robots, because the data needs to be physically collected. This makes it a lot harder to build and scale training databases.
Similarly, while it’s relatively easy to train robots to execute tasks inside a laboratory, these conditions don’t necessarily translate to the messy unpredictability of a real home.
To combat these problems, the team came up with a simple, easily replicable way to collect the data needed to train Dobb-E—using an iPhone attached to a reacher-grabber stick, the kind typically used to pick up trash. Then they set the iPhone to record videos of what was happening.
Volunteers in 22 homes in New York completed certain tasks using the stick, including opening and closing doors and drawers, turning lights on and off, and placing tissues in the trash. The iPhones’ lidar systems, motion sensors, and gyroscopes were used to record data on movement, depth, and rotation—important information when it comes to training a robot to replicate the actions on its own.
After they’d collected just 13 hours’ worth of recordings in total, the team used the data to train an AI model to instruct a robot in how to carry out the actions. The model used self-supervised learning techniques, which teach neural networks to spot patterns in data sets by themselves, without being guided by labeled examples.
The next step involved testing how reliably a commercially available robot called Stretch, which consists of a wheeled unit, a tall pole, and a retractable arm, was able to use the AI system to execute the tasks. An iPhone held in a 3D-printed mount was attached to Stretch’s arm to replicate the setup on the stick.
The researchers tested the robot in 10 homes in New York over 30 days, and it completed 109 household tasks with an overall success rate of 81%. Each task typically took Dobb-E around 20 minutes to learn: five minutes of demonstration from a human using the stick and attached iPhone, followed by 15 minutes of fine-tuning, when the system compared its previous training with the new demonstration.
Large language models combined with confidence scores help them recognize uncertainty. That could be key to making robots safe and trustworthy.
Once the fine-tuning was complete, the robot was able to complete simple tasks like pouring from a cup, opening blinds and shower curtains, or pulling board-game boxes from a shelf. It could also perform multiple actions in quick succession, such as placing a can in a recycling bag and then lifting the bag.
However, not every task was successful. The system was confused by reflective surfaces like mirrors. Also, because the robot’s center of gravity is low, tasks that require pulling something heavy at height, like opening fridge doors, proved too risky to attempt.
The research represents tangible progress for the home robotics field, says Charlie C. Kemp, cofounder of the robotics firm Hello Robot and a former associate professor at Georgia Tech. Although the Dobb-E team used Hello Robot’s research robot, Kemp was not involved in the project.
“The future of home robots is really coming. It’s not just some crazy dream anymore,” he says. “Scaling up data has always been a challenge in robotics, and this is a very creative, clever approach to that problem.”
To date, Roomba and other robotic vacuum cleaners are the only real commercial home robot successes, says Jiajun Wu, an assistant professor of computer science at Stanford University who was not involved in the research. Their job is easier because Roombas don’t interact with objects—in fact,a their aim is to avoid them. It’s much more challenging to develop home robots capable of doing a wider range of tasks, which is what this research could help advance.
The NYU research team has made all elements of the project open source, and they’re hoping others will download the code and help expand the range of tasks that robots running Dobb-E will be able to achieve.
“Our hope is that when we get more and more data, at some point when Dobb-E sees a new home, you don’t have to show it more examples,” says Lerrel Pinto, a computer science researcher at New York University who worked on the project.
“We want to get to the point when we don’t have to teach the robot new tasks, because it already knows all the tasks in most houses,” he says.
Allen & Overy rolls out AI contract negotiation tool in challenge to legal industry
Law firm works with Microsoft and AI start-up Harvey in attempt to ‘disrupt the legal market before someone disrupts us’
Allen & Overy rolls out AI contract negotiation tool in challenge to legal industry
Law firm works with Microsoft and AI start-up Harvey in attempt to ‘disrupt the legal market before someone disrupts us’

Allen & Overy has developed a service that draws on existing templates for contracts to draft new agreements that lawyers can then amend or accept © Robert Evans/Alamy
Cristina Criddle and Suzi Ring in London
YESTERDAY
177Print this page
Allen & Overy has created an artificial intelligence contract negotiation tool, as the magic circle law firm pushes forward with technology that threatens to disrupt the traditional practices of the legal profession.
The UK-headquartered group, in partnership with Microsoft and legal AI start-up Harvey, has developed the service which draws on existing templates for contracts, such as non-disclosure agreements and merger and acquisition terms, to draft new agreements that lawyers can then amend or accept.
The tool, known as ContractMatrix, is being rolled out to clients in an attempt to drive new revenues, attract more business and save time for in-house lawyers. A&O estimated it would save up to seven hours in contract negotiations.
More than 1,000 A&O lawyers are already using the tool, with five unnamed clients from banking, pharma, technology, media and private equity signed up to use the platform from January.
In a trial run, Dutch chipmaking equipment manufacturer ASML and health technology company Philips said they used the service to negotiate what they called the “world’s first 100 per cent AI generated contract between two companies”.
The legal sector is grappling with the rise of generative AI — technology that can review, extract and write large passages of humanlike text — which could result in losses of jobs and revenues by reducing billable hours and entry-level work for junior staff.
But David Wakeling, A&O partner and head of the firm’s markets innovation group, which developed ContractMatrix, said the firm’s goal was to “disrupt the legal market before someone disrupts us”.
“If we look at the impact of AI in law, it is happening and it’s likely to happen in a pretty big way in the next few years, and we are seeing it as an opportunity,” he added.
The firm is also planning to offer the service to the clients it gains from its $3.5bn merger with US outfit Shearman & Sterling, said Wakeling, which is due to complete by May.
The legal sector has been one of the fastest industries to adopt and experiment with generative AI technology off the back of the success of Microsoft-backed OpenAI’s ChatGPT and Google’s Bard. However, while some firms have heavily invested in new products, many are waiting to see what tools will win out.
A&O had previously introduced an AI-powered chatbot for use within the firm. Other law firms including Addleshaw Goddard, Travers Smith and Macfarlanes have also rolled out generative AI pilots internally.
A&O would not detail specific financial terms around the contract negotiation tool but said clients would pay an annual subscription fee per licence, with a minimum purchase of five users. The law firm is aiming to have subscriptions with hundreds of companies by the end of next year.
The product will also be available more widely to companies through Microsoft’s enterprise software marketplaces, Azure and AppSource, in the first half of 2024. Microsoft said the project would “deliver significant value to [A&O] customers”.
Concerns have been raised around using generative AI in the legal sector because of issues related to data privacy and client confidentiality, as well as so-called hallucinations, where a model generates incorrect information.
Wakeling said that hallucinations could happen with ContractMatrix, but they were significantly reduced because of the templates its underlying technology had been trained on. He added that client data was also not used to train the AI models that underpin the software, and inputs and outputs are encrypted.
However, if clients wished to make the tool more effective and personalised, A&O said it could work with a business to fine-tune the model and train on their data.
“We are seeing it as a big open market opportunity . . . because in-house lawyers need efficiency and productivity gains as well,” Wakeling added. “They can be that much quicker and that much more efficient than their competitors. And you would expect that to be attractive to clients because it’s generally a bit cheaper, a bit faster, a bit better.”
Additional reporting by Tim Bradshaw

Midjourney v6
The Dev Team gonna let the community test an alpha-version of Midjourney v6 model over the winter break, starting tonight.
Midjourney v6
The Dev Team gonna let the community test an alpha-version of Midjourney v6 model over the winter break, starting tonight, December 21st, 2023.To turn it on select
V6 from the dropdown menu under /settings or type --v 6 after your prompt.
What’s new with the Midjourney v6 base model?
- Much more accurate prompt following as well as longer prompts,
- Improved coherence, and model knowledge,
- Improved image prompting and remix mode,
- Minor text drawing ability (you must write your text in “quotations” and
--style rawor lower--stylizevalues may help)
/imagine a photo of the text "Hello World!" written with a marker on a sticky note --ar 16:9 --v 6 - Improved upscalers, with both
'subtle‘ and'creative‘ modes (increases resolution by 2x)
(you’ll see buttons for these under your images after clicking U1/U2/U3/U4)
The following features / arguments are supported at launch:
--ar,--chaos,--weird,--tile,--stylize,--style raw,Vary (subtle),Vary (strong),Remix,/blend,/describe (just the v5 version)
These features are not yet supported, but should come over the coming month:
Pan,Zoom,Vary (region),/tune,/describe (a new v6 version)
Style and prompting for Midjourney Version 6
- Prompting with V6 is significantly different than V5. You will need to ‘relearn’ how to prompt.
- Midjourney v6 is much more sensitive to your prompt. Avoid ‘junk’ like “award winning, photorealistic, 4k, 8k”
- Be explicit about what you want. It may be less vibey but if you are explicit it’s now MUCH better at understanding you.
- If you want something more photographic / less opinionated / more literal you should probably default to using
--style raw - Lower values of
--stylize(default 100) may have better prompt understanding while higher values (up to 1000) may have better aesthetics - Please chat with each other in Official Midjourney Discord Server to figure out how to use Midjourney v6.
Please note
Version 6 is available on Discord.It will be available at https://midjourney.com for billable Subscribers soon.
- This is an alpha test. Things will change frequently and without notice.
- DO NOT rely on this exact model being available in the future. It will significantly change as we take V6 to full release.
- Speed, Image quality, coherence, prompt following, and text accuracy should improve over the next few weeks
- V6 is slower / more expensive vs V5, but will get faster as we optimize. Relax mode is supported! (it’s about 1 gpu/min per imagine and 2 gpu/min per upscale)
Community Standards
- This model can generate much more realistic imagery than anything the dev team released before.
- Engineering team turned up the moderation systems, and will be enforcing our community standards with increased strictness and rigor. Don’t be a jerk or create images to cause drama.
More about Version 6 of Midjourney
- Version 6 is the third model trained from scratch on AI superclusters. It’s been in the works for 9 months.
- V6 isn’t the final step, but devs hope you all feel the progression of something profound that deeply intertwines with the powers of collective imaginations.
Have fun and happy holidays!
Read related articles: