
1/3
@rohanpaul_ai
This paper makes complex Multi-objective reinforcement learning (MORL) policies understandable by clustering them based on both behavior and objectives
When AI gives you too many options, this clustering trick saves the day
 Original Problem:
Original Problem:
Multi-objective reinforcement learning (MORL) generates multiple policies with different trade-offs, but these solution sets are too large and complex for humans to analyze effectively. Decision makers struggle to understand relationships between policy behaviors and their objective outcomes.
-----
 Solution in this Paper:
Solution in this Paper:
→ Introduces a novel clustering approach that considers both objective space (expected returns) and behavior space (policy actions)
→ Uses Highlights algorithm to capture 5 key states that represent each policy's behavior
→ Applies PAN (Pareto-Set Analysis) clustering to find well-defined clusters in both spaces simultaneously
→ Employs bi-objective evolutionary algorithm to optimize clustering quality across both spaces
-----
 Key Insights:
Key Insights:
→ First research to tackle MORL solution set explainability
→ Different policies with similar trade-offs can exhibit vastly different behaviors
→ Combining objective and behavior analysis reveals deeper policy insights
→ Makes MORL more practical for real-world applications
-----
 Results:
Results:
→ Outperformed traditional k-medoids clustering in MO-Highway and MO-Lunar-lander environments
→ Showed comparable performance in MO-Reacher and MO-Minecart scenarios
→ Successfully demonstrated practical application through highway environment case study

2/3
@rohanpaul_ai
Paper Title: "Navigating Trade-offs: Policy Summarization for Multi-Objective Reinforcement Learning"
Generated below podcast on this paper with Google's Illuminate.
https://video.twimg.com/ext_tw_video/1861197491238211584/pu/vid/avc1/1080x1080/56yXAj4Toyxny-Ic.mp4
3/3
@rohanpaul_ai
[2411.04784v1] Navigating Trade-offs: Policy Summarization for Multi-Objective Reinforcement Learning
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@rohanpaul_ai
This paper makes complex Multi-objective reinforcement learning (MORL) policies understandable by clustering them based on both behavior and objectives
When AI gives you too many options, this clustering trick saves the day
Original Problem:Multi-objective reinforcement learning (MORL) generates multiple policies with different trade-offs, but these solution sets are too large and complex for humans to analyze effectively. Decision makers struggle to understand relationships between policy behaviors and their objective outcomes.
-----
Solution in this Paper:→ Introduces a novel clustering approach that considers both objective space (expected returns) and behavior space (policy actions)
→ Uses Highlights algorithm to capture 5 key states that represent each policy's behavior
→ Applies PAN (Pareto-Set Analysis) clustering to find well-defined clusters in both spaces simultaneously
→ Employs bi-objective evolutionary algorithm to optimize clustering quality across both spaces
-----
Key Insights:→ First research to tackle MORL solution set explainability
→ Different policies with similar trade-offs can exhibit vastly different behaviors
→ Combining objective and behavior analysis reveals deeper policy insights
→ Makes MORL more practical for real-world applications
-----
Results:→ Outperformed traditional k-medoids clustering in MO-Highway and MO-Lunar-lander environments
→ Showed comparable performance in MO-Reacher and MO-Minecart scenarios
→ Successfully demonstrated practical application through highway environment case study
2/3
@rohanpaul_ai
Paper Title: "Navigating Trade-offs: Policy Summarization for Multi-Objective Reinforcement Learning"
Generated below podcast on this paper with Google's Illuminate.
https://video.twimg.com/ext_tw_video/1861197491238211584/pu/vid/avc1/1080x1080/56yXAj4Toyxny-Ic.mp4
3/3
@rohanpaul_ai
[2411.04784v1] Navigating Trade-offs: Policy Summarization for Multi-Objective Reinforcement Learning
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
 Ideas discussed in this Paper:
Ideas discussed in this Paper:









 We're releasing a preview of QwQ /kwju:/ — an open model designed to advance AI reasoning capabilities.
We're releasing a preview of QwQ /kwju:/ — an open model designed to advance AI reasoning capabilities.



 . The model doesn’t directly apply a simple counting method it goes letter by letter, analyzing each position as if it doesn’t trust itself to handle the word holistically. After reaching the correct count of 3, it goes back and double-checks every position of “r.”
. The model doesn’t directly apply a simple counting method it goes letter by letter, analyzing each position as if it doesn’t trust itself to handle the word holistically. After reaching the correct count of 3, it goes back and double-checks every position of “r.”



 , I’ll show you how to set up and use Qwq, including downloading the model and integrating it into VSCode.
, I’ll show you how to set up and use Qwq, including downloading the model and integrating it into VSCode.


 Qwen/QwQ-32B-Preview (full precision)
Qwen/QwQ-32B-Preview (full precision)



 the reasoning is too much fun
the reasoning is too much fun




 an experimental 32B model by the Qwen team that is competitive with o1-mini and o1-preview in some cases.
an experimental 32B model by the Qwen team that is competitive with o1-mini and o1-preview in some cases. 




 oh llama
oh llama


 NOTE - This paper is referring to 01-preview model (not the full version 01)
NOTE - This paper is referring to 01-preview model (not the full version 01)
 430,000x faster than real-time physics simulation, processes 43M FPS on a single RTX 4090
430,000x faster than real-time physics simulation, processes 43M FPS on a single RTX 4090 Built in pure Python, 10-80x faster than existing GPU solutions like Isaac Gym
Built in pure Python, 10-80x faster than existing GPU solutions like Isaac Gym Cross-platform support: Linux, MacOS, Windows, with CPU, NVIDIA, AMD, and Apple Metal backends
Cross-platform support: Linux, MacOS, Windows, with CPU, NVIDIA, AMD, and Apple Metal backends Unified framework combining multiple physics solvers: Rigid body, MPM, SPH, FEM, PBD, Stable Fluid
Unified framework combining multiple physics solvers: Rigid body, MPM, SPH, FEM, PBD, Stable Fluid Extensive robot support: arms, legged robots, drones, soft robots; supports MJCF, URDF, obj, glb files
Extensive robot support: arms, legged robots, drones, soft robots; supports MJCF, URDF, obj, glb files Built-in photorealistic ray-tracing rendering
Built-in photorealistic ray-tracing rendering Takes only 26 seconds to train real-world transferrable robot locomotion policies
Takes only 26 seconds to train real-world transferrable robot locomotion policies Simple installation via pip: pip install genesis-world
Simple installation via pip: pip install genesis-world Physics engine and simulation platform are fully open-sourced
Physics engine and simulation platform are fully open-sourced ”.generate” method/generative framework coming soon.
”.generate” method/generative framework coming soon.


 Training Locomotion Policies with RL — Genesis 0.2.0 documentation
Training Locomotion Policies with RL — Genesis 0.2.0 documentation










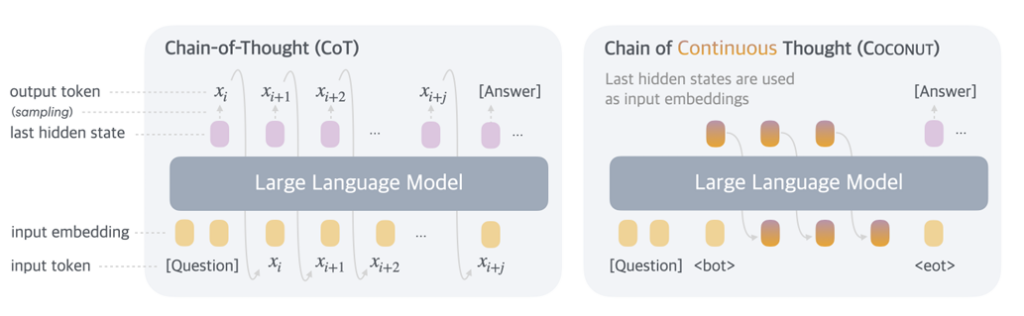
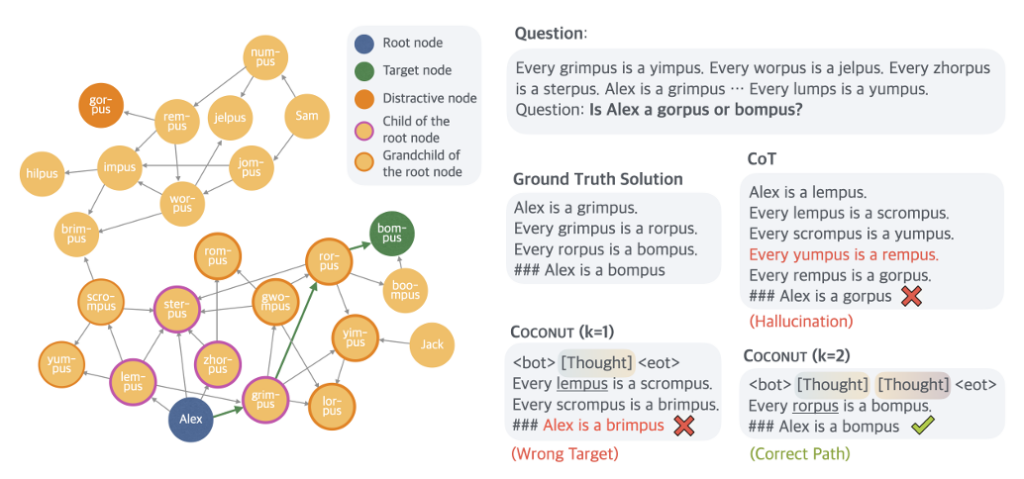
 Happy holidays and we wish you enjoy this year. Before moving to 2025, Qwen has the last gift for you, which is QVQ!
Happy holidays and we wish you enjoy this year. Before moving to 2025, Qwen has the last gift for you, which is QVQ! This may be the first open-weight model for visual reasoning. It is called QVQ, where V stands for vision. It just reads an image and an instruction, starts thinking, reflects while it should, keeps reasoning, and finally it generates its prediction with confidence! However, it is still experimental and this preview version still suffers from a number of limitations (mentioned in our blog), which you should pay attention to while using the model. Feel free to refer to the following links for more information:
This may be the first open-weight model for visual reasoning. It is called QVQ, where V stands for vision. It just reads an image and an instruction, starts thinking, reflects while it should, keeps reasoning, and finally it generates its prediction with confidence! However, it is still experimental and this preview version still suffers from a number of limitations (mentioned in our blog), which you should pay attention to while using the model. Feel free to refer to the following links for more information:













 SoTA open-source multimodal
SoTA open-source multimodal  Capable of step-by-step reasoning
Capable of step-by-step reasoning Competitive MMMU score with o1, GPT-4o and Sonnet 3.5
Competitive MMMU score with o1, GPT-4o and Sonnet 3.5




