
1/31
@DrJimFan
That a *second* paper dropped with tons of RL flywheel secrets and *multimodal* o1-style reasoning is not on my bingo card today. Kimi's (another startup) and DeepSeek's papers remarkably converged on similar findings:
> No need for complex tree search like MCTS. Just linearize the thought trace and do good old autoregressive prediction;
> No need for value functions that require another expensive copy of the model;
> No need for dense reward modeling. Rely as much as possible on groundtruth, end result.
Differences:
> DeepSeek does AlphaZero approach - purely bootstrap through RL w/o human input, i.e. "cold start". Kimi does AlphaGo-Master approach: light SFT to warm up through prompt-engineered CoT traces.
> DeepSeek weights are MIT license (thought leadership!); Kimi does not have a model release yet.
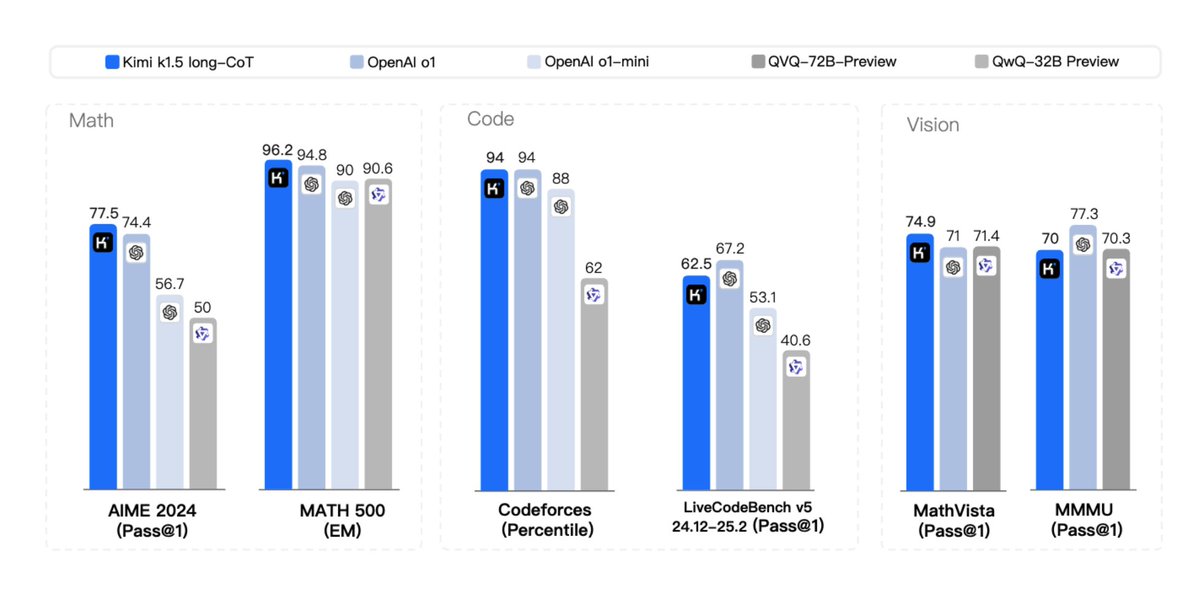
> Kimi shows strong multimodal performance (!) on benchmarks like MathVista, which requires visual understanding of geometry, IQ tests, etc.
> Kimi paper has a LOT more details on the system design: RL infrastructure, hybrid cluster, code sandbox, parallelism strategies; and learning details: long context, CoT compression, curriculum, sampling strategy, test case generation, etc.
Upbeat reads on a holiday!
2/31
@DrJimFan
Whitepaper link: Kimi-k1.5/Kimi_k1.5.pdf at main · MoonshotAI/Kimi-k1.5
3/31
@brendanigraham
DeepSeek-R1 actually does use SFT btw - it's DeepSeek-R1-Zero that doesn't.
For DeepSeek-R1, they SFT on a small amount of nicely-formatted reasoning data (some cleaned up from DeepSeek-R1-Zero, some from few-shot prompting other models) then RLVR + a language consistency signal.
They then use this resulting model to generate a bunch of additional reasoning traces, gather a bunch of other kinds of data (e.g. creative writing), and do some filtering with DSv3.
They then SFT from base again using this data, then do a bunch of RL with signal for rule-based rewards and human preferences (via a reward model)
4/31
@DrJimFan
That’s right
5/31
@Kimi_Moonshot
Kudos! Thanks for sharing! Yep, we're *multimodal* o1-style reasoning
6/31
@roydanroy
What do you mean "no need for"? This model is definitely inferior to o1.
7/31
@JFPuget
R1 has no need for a value model because they do RL in domains where value can be computed via some rules (accuracy of math result, code that compiles and produces the right output).
8/31
@joenorton
Fascinating stuff
9/31
@mark_k
Very excited to hear about the multi-modal reasoning
10/31
@TheAIVeteran
Saves me a few minutes, thanks for the info!
11/31
@C_Quemeneur
Not gonna lie, I was expecting to see more MCTS in these models.
12/31
@vedangvatsa
Overcomplicating RL with tree search and value functions might actually be the smarter route. Simple predictions can’t capture the nuances of complex decisions. Relying solely on groundtruth limits adaptability. The richness of human input is invaluable; cold starts might miss critical context.
13/31
@elichen
This contains a much better description of the acceleration that's currently happening: "Reinforcement Learning with LLMs". Not sure why we are talking about test-time compute scaling..
14/31
@AILeaksAndNews
Loving the MLK Day presents
15/31
@phi_wxyz
which paper do you recommend reading first?
16/31
@rudiranck
Seems like China brought its A-game and elbows for 2025.
17/31
@nobody_qwert
Deepseek is good. I cancelled my 200$ GPT Pro plan.
[Quoted tweet]
ChatGPT o1 Pro vs. DeepSeek R1
Asked to implement a rotating triangle with red ball in it.
Left OpenAI right DeepSeek
https://video.twimg.com/ext_tw_video/1881619983639117824/pu/vid/avc1/1280x720/d9wsM0oT35AZXvUY.mp4
18/31
@sonicshifts
It's a knockoff. They even copied CoPilot's reasoning language.

19/31
@the__sonik
@mirzaei_mani
20/31
@c__bir
I wonder if MCTS and Graph abstractions might become useful or even needed for higher capability levels? Intuitively it seems like it who wouldn't want a system that generates proveably save long horizon task execution programs. Therefore the AI system needs to generate the symbolic abstraction by itself at Inference Time. Not only use symbolic abstractions, but even come up with helpful symbolic abstractions. Therefore the amount of symbolic abstractions should grow with inference time asymptotically. To a manageable size. Best thing: it's human readable. And one can create 100% accurate synthetic Data with it. Which means valuable signal to noise.
who wouldn't want a system that generates proveably save long horizon task execution programs. Therefore the AI system needs to generate the symbolic abstraction by itself at Inference Time. Not only use symbolic abstractions, but even come up with helpful symbolic abstractions. Therefore the amount of symbolic abstractions should grow with inference time asymptotically. To a manageable size. Best thing: it's human readable. And one can create 100% accurate synthetic Data with it. Which means valuable signal to noise.
@karpathy @aidan_mclau
@WolframResearch @stephen_wolfram
21/31
@Bill_ZRK
amazing
22/31
@Extended_Brain
It cannot generate images, but can extract important features of images, such as from geometric problems
23/31
@GlobalFadi
Kimi's and DeepSeek's findings converging on linearization rather than MCTS is mind-blowing! This could massively streamline our AI and RL research.
24/31
@MarMa10134863
25/31
@monday_chen
this day would be perfect if this is open sourced too
26/31
@Qi2ji4Zhe1nni1
a second rl flywheel paper has hit the github
27/31
@wrhall
> No need for complex tree search like MCTS. Just linearize the thought trace and do good old autoregressive prediction
Can you apply this back to chess/go? I need to read paper to fully grok I think
28/31
@Ixin75293630175
> No need for complex tree search like MCTS. Just linearize the thought trace and do good old autoregressive prediction
Because when humans do MCTS they DO remember all discarded branches!
29/31
@2xehpa
Why does all the open models always converge to the same level as what is currently the most advanced *released* model? Why its good as O1 and not O3? I suspect everybody use output from frontier models in the training somehow
30/31
@llm_guruji
Fascinating insights! It's intriguing to see how both approaches converge on simpler methods. Looking forward to exploring the system design details in Kimi's paper.
31/31
@red_durag
first difference is not quite right. deepseek did alphazero approach for r1 zero, not for r1. r1 was fine-tuned on cot data before RL
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@DrJimFan
That a *second* paper dropped with tons of RL flywheel secrets and *multimodal* o1-style reasoning is not on my bingo card today. Kimi's (another startup) and DeepSeek's papers remarkably converged on similar findings:
> No need for complex tree search like MCTS. Just linearize the thought trace and do good old autoregressive prediction;
> No need for value functions that require another expensive copy of the model;
> No need for dense reward modeling. Rely as much as possible on groundtruth, end result.
Differences:
> DeepSeek does AlphaZero approach - purely bootstrap through RL w/o human input, i.e. "cold start". Kimi does AlphaGo-Master approach: light SFT to warm up through prompt-engineered CoT traces.
> DeepSeek weights are MIT license (thought leadership!); Kimi does not have a model release yet.
> Kimi shows strong multimodal performance (!) on benchmarks like MathVista, which requires visual understanding of geometry, IQ tests, etc.
> Kimi paper has a LOT more details on the system design: RL infrastructure, hybrid cluster, code sandbox, parallelism strategies; and learning details: long context, CoT compression, curriculum, sampling strategy, test case generation, etc.
Upbeat reads on a holiday!
2/31
@DrJimFan
Whitepaper link: Kimi-k1.5/Kimi_k1.5.pdf at main · MoonshotAI/Kimi-k1.5
3/31
@brendanigraham
DeepSeek-R1 actually does use SFT btw - it's DeepSeek-R1-Zero that doesn't.
For DeepSeek-R1, they SFT on a small amount of nicely-formatted reasoning data (some cleaned up from DeepSeek-R1-Zero, some from few-shot prompting other models) then RLVR + a language consistency signal.
They then use this resulting model to generate a bunch of additional reasoning traces, gather a bunch of other kinds of data (e.g. creative writing), and do some filtering with DSv3.
They then SFT from base again using this data, then do a bunch of RL with signal for rule-based rewards and human preferences (via a reward model)
4/31
@DrJimFan
That’s right
5/31
@Kimi_Moonshot
Kudos! Thanks for sharing! Yep, we're *multimodal* o1-style reasoning
6/31
@roydanroy
What do you mean "no need for"? This model is definitely inferior to o1.
7/31
@JFPuget
R1 has no need for a value model because they do RL in domains where value can be computed via some rules (accuracy of math result, code that compiles and produces the right output).
8/31
@joenorton
Fascinating stuff
9/31
@mark_k
Very excited to hear about the multi-modal reasoning
10/31
@TheAIVeteran
Saves me a few minutes, thanks for the info!
11/31
@C_Quemeneur
Not gonna lie, I was expecting to see more MCTS in these models.
12/31
@vedangvatsa
Overcomplicating RL with tree search and value functions might actually be the smarter route. Simple predictions can’t capture the nuances of complex decisions. Relying solely on groundtruth limits adaptability. The richness of human input is invaluable; cold starts might miss critical context.
13/31
@elichen
This contains a much better description of the acceleration that's currently happening: "Reinforcement Learning with LLMs". Not sure why we are talking about test-time compute scaling..
14/31
@AILeaksAndNews
Loving the MLK Day presents
15/31
@phi_wxyz
which paper do you recommend reading first?
16/31
@rudiranck
Seems like China brought its A-game and elbows for 2025.
17/31
@nobody_qwert
Deepseek is good. I cancelled my 200$ GPT Pro plan.
[Quoted tweet]
ChatGPT o1 Pro vs. DeepSeek R1
Asked to implement a rotating triangle with red ball in it.
Left OpenAI right DeepSeek
https://video.twimg.com/ext_tw_video/1881619983639117824/pu/vid/avc1/1280x720/d9wsM0oT35AZXvUY.mp4
18/31
@sonicshifts
It's a knockoff. They even copied CoPilot's reasoning language.
19/31
@the__sonik
@mirzaei_mani
20/31
@c__bir
I wonder if MCTS and Graph abstractions might become useful or even needed for higher capability levels? Intuitively it seems like it
who wouldn't want a system that generates proveably save long horizon task execution programs. Therefore the AI system needs to generate the symbolic abstraction by itself at Inference Time. Not only use symbolic abstractions, but even come up with helpful symbolic abstractions. Therefore the amount of symbolic abstractions should grow with inference time asymptotically. To a manageable size. Best thing: it's human readable. And one can create 100% accurate synthetic Data with it. Which means valuable signal to noise.@karpathy @aidan_mclau
@WolframResearch @stephen_wolfram
21/31
@Bill_ZRK
amazing
22/31
@Extended_Brain
It cannot generate images, but can extract important features of images, such as from geometric problems
23/31
@GlobalFadi
Kimi's and DeepSeek's findings converging on linearization rather than MCTS is mind-blowing! This could massively streamline our AI and RL research.
24/31
@MarMa10134863
25/31
@monday_chen
this day would be perfect if this is open sourced too
26/31
@Qi2ji4Zhe1nni1
a second rl flywheel paper has hit the github
27/31
@wrhall
> No need for complex tree search like MCTS. Just linearize the thought trace and do good old autoregressive prediction
Can you apply this back to chess/go? I need to read paper to fully grok I think
28/31
@Ixin75293630175
> No need for complex tree search like MCTS. Just linearize the thought trace and do good old autoregressive prediction
Because when humans do MCTS they DO remember all discarded branches!
29/31
@2xehpa
Why does all the open models always converge to the same level as what is currently the most advanced *released* model? Why its good as O1 and not O3? I suspect everybody use output from frontier models in the training somehow
30/31
@llm_guruji
Fascinating insights! It's intriguing to see how both approaches converge on simpler methods. Looking forward to exploring the system design details in Kimi's paper.
31/31
@red_durag
first difference is not quite right. deepseek did alphazero approach for r1 zero, not for r1. r1 was fine-tuned on cot data before RL
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
1/4
@deanwball
DeepSeek r1 takeaways for policy:
1. Chinese labs will likely continue to be fast followers in terms of reaching similar benchmark performance to US models.
2. The impressive performance of DeepSeek's distilled models (smaller versions of r1) means that very capable reasoners will continue to proliferate widely and be runnable on local hardware, far from the eyes of any top-down control regime (including the US diffusion rule).
3. Open models are going to have strategic value for the US and we need to figure out ways to get more frontier open models out to the world (we rely exclusively on meta for this right now, which, while great, is just one firm). Why do OpenAI/Anthropic not open-source their older models? What would be the harm?
2/4
@muchos_grande
because they're literally piggybacking off of American technology, as usual.
3/4
@RichardAGetz
@xai where are you in this game?
Thank you @AIatMeta for all your open source AI, and I hope you leapfrog R1 soon.
4/4
@MechanicalDao
What is the strategic value in releasing open models?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196
@deanwball
DeepSeek r1 takeaways for policy:
1. Chinese labs will likely continue to be fast followers in terms of reaching similar benchmark performance to US models.
2. The impressive performance of DeepSeek's distilled models (smaller versions of r1) means that very capable reasoners will continue to proliferate widely and be runnable on local hardware, far from the eyes of any top-down control regime (including the US diffusion rule).
3. Open models are going to have strategic value for the US and we need to figure out ways to get more frontier open models out to the world (we rely exclusively on meta for this right now, which, while great, is just one firm). Why do OpenAI/Anthropic not open-source their older models? What would be the harm?
2/4
@muchos_grande
because they're literally piggybacking off of American technology, as usual.
3/4
@RichardAGetz
@xai where are you in this game?
Thank you @AIatMeta for all your open source AI, and I hope you leapfrog R1 soon.
4/4
@MechanicalDao
What is the strategic value in releasing open models?
To post tweets in this format, more info here: https://www.thecoli.com/threads/tips-and-tricks-for-posting-the-coli-megathread.984734/post-52211196

 These AI models from China are amazing!
These AI models from China are amazing! Introducing Kimi k1.5 --- an o1-level multi-modal model
Introducing Kimi k1.5 --- an o1-level multi-modal model AIME,
AIME,  LiveCodeBench by a large margin (up to +550%)
LiveCodeBench by a large margin (up to +550%) MathVista,
MathVista, 


 🫡
🫡 @huggingface still has a few To available I guess.
@huggingface still has a few To available I guess.

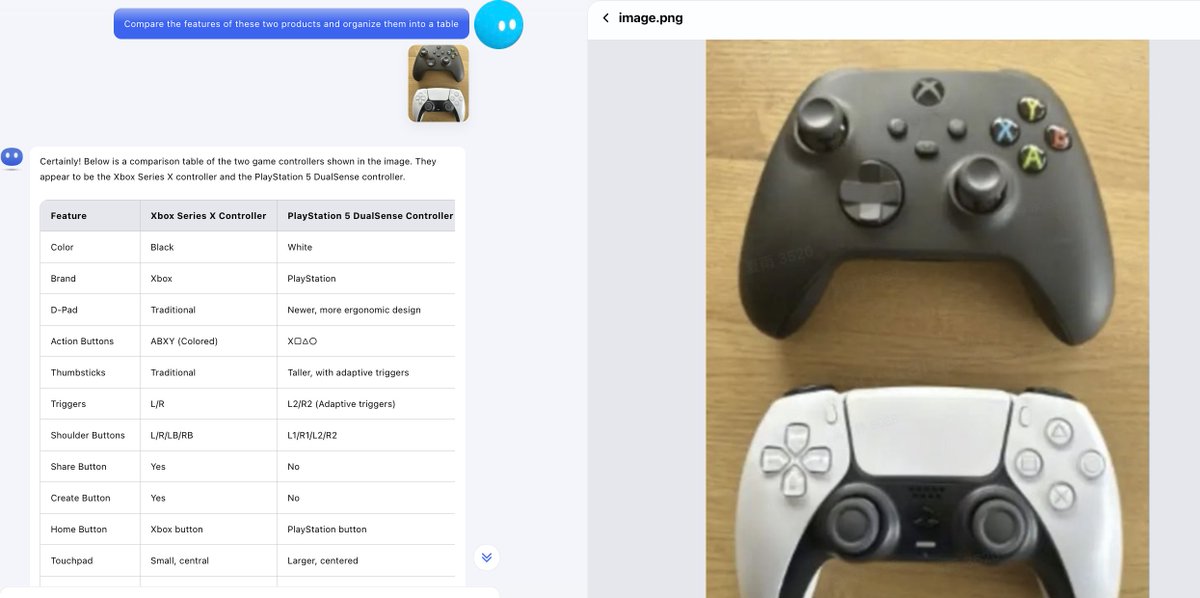
 What can Kimi k1.5 do?
What can Kimi k1.5 do? Image to Code: Convert images into structured code and insights
Image to Code: Convert images into structured code and insights
 Available now on
Available now on 






 /search?q=#PublicAI
/search?q=#PublicAI

 AIME,
AIME, 
